第191期 Kimi K2 Thinking 模型重磅发布:性能超越 Claude 4.5,对标 GPT-5(成本直降75%)
摘要: 月之暗面推出开源AI模型Kimi K2 Thinking,主打深度推理与工具协同调度能力,支持200-300次连续工具调用且保持逻辑连贯。该模型采用原生INT4量化技术,推理速度提升2倍,在智能代理搜索任务中表现优于Claude和GPT系列,编码能力接近顶级水平。其定价竞争力强,输入tokens成本低至每百万1.15美元,为开发者提供高效长上下文处理方案。基准测试显示,K2 Thinkin
*大家好,我是AI拉呱,一个专注于人工智领域与网络安全方面的博主,现任资深算法研究员一职,热爱机器学习和深度学习算法应用,拥有丰富的AI项目经验,希望和你一起成长交流。关注AI拉呱,评论+转发此文即可私信获取一份教程+一份学习书单!

Kimi K2 Thinking 模型已正式发布。就在我们以为 AI 模型发布节奏逐渐放缓之际,月之暗面(Moonshot AI)突然推出了这款 Kimi K2 Thinking 模型。
该模型在“思考型模型”领域迅速崭露头角,成为极具竞争力的一员。
我快速给它分配了一项简单的编码任务,其输出结果的速度与准确性可与 Claude 4.5、GPT-5 及 GLM 相媲美。

自今年7月月之暗面首次发布 Kimi 模型以来,我便一直关注着这家公司的动态。
初代 K2 模型已展现出不俗潜力,而此次推出的“思考版”(Thinking 版本)同样令人印象深刻。
它被专门训练去攻克大多数模型难以应对的难题:在数百个连续步骤中,将深度推理与工具协同调度能力相结合。
具体来说,它能在单个任务中处理 200-300 次工具调用,且全程保持逻辑连贯。
即便是来自 OpenAI 和 Anthropic 的前沿模型,也鲜少能达到这一水平。
月之暗面并非在现有模型基础上简单叠加“扩展思维链”(extended chain of thought)功能,而是对 K2 Thinking 模型进行了端到端训练,使其能够将推理过程与函数调用无缝交织。
最终呈现的模型,能够在持续数百步的工作流程中自主完成研究、编码与内容创作任务。
作为参考,大多数模型在连续调用 30-50 次工具后,性能便会开始下降。
而 K2 Thinking 模型即便远超这一阈值,仍能保持稳定的、目标导向的运行状态。
多项基准测试结果也印证了这一点:在“人类终极考试”(Humanity’s Last Exam)工具启用场景下,K2 Thinking 获得 44.9 分,超越 Claude Sonnet 4.5,且逼近 GPT-4.5。
在 BrowseComp 等智能代理搜索任务(agentic search tasks)中,它的表现也优于 Claude 和 OpenAI 的所有模型。
更重要的是,这是一款开源模型——你可以直接下载,亲自进行测试。
其定价同样极具竞争力:月之暗面将输入 tokens 的 API 费率下调了高达 75%,其中 turbo 版本的输入 tokens 费用仅为每百万 tokens 1.15 美元。
也就是说,只需花费远低于 Claude 模型的成本,就能获得与之相当的智能水平。
在本文中,我将深入解析 K2 Thinking 模型的亮点所在、它与竞品的性能对比,以及对于正在开发智能代理(agents)或处理长上下文编码任务的开发者而言,这款模型意味着什么。
首先,我们先来了解一下这款模型的核心功能。
一、什么是 Kimi K2 Thinking 模型?
Kimi K2 聊天界面截图
K2 Thinking 是一款混合专家模型(mixture-of-experts model),总参数量达 1 万亿,每个 token 激活的参数量为 320 亿。
该模型架构包含 384 个“专家模块”,每个 token 会筛选出 8 个专家模块参与计算,同时设有 1 个适用于所有操作的共享专家模块;支持 256K 上下文窗口,并采用原生 INT4 量化技术。
1.1 深度推理 + 工具协同调度
大多数“思考型模型”仅具备“扩展思维链推理”能力,即先将问题逐步拆解,再给出答案。
K2 Thinking 不仅能做到这一点,还能在推理过程中穿插工具调用——也就是说,它可以先推理、调用搜索工具、基于搜索结果继续推理、执行 Python 代码、根据代码输出调整推理方向、发起新一轮搜索,如此循环往复,完成数百步任务。
月之暗面将这种能力称为“带工具调用的交织式思维链”(interleaved chain-of-thought with tool calls)。
该模型通过端到端训练专门适配这种工作流程,而非在基础模型上“额外嫁接”工具使用功能。
当给大多数模型分配需要多工具协作的复杂任务时,它们要么会提前规划好所有步骤(一旦条件变化便会失效),要么在几十步后就会失去逻辑连贯性。
而 K2 Thinking 模型在连续调用 200-300 次工具的情况下,仍能保持稳定的目标导向行为。
这是月之暗面官方给出的性能指标,且多项基准测试已证实其准确性。
1.2 原生 INT4 量化技术
K2 Thinking 模型采用“量化感知训练”(Quantization-Aware Training, QAT)技术,原生支持 INT4 量化。
这与“事后量化”(post-hoc quantization)不同——后者是对已训练完成的模型进行压缩,性能能否保持全凭运气;而 QAT 技术在模型训练阶段就已将量化需求纳入考量,最终能在保证精度损失最小的前提下,将推理速度提升约 2 倍。
后续你将看到的所有基准测试结果,均来自该模型的 INT4 版本。
对于需要生成冗长推理链的“思考型模型”而言,推理速度至关重要——K2 Thinking 模型将量化版本设为默认选项,正是为了应对这一需求。
该模型采用“压缩张量格式”(compressed-tensors format),可与 vLLM、SGLang 及其他主流推理引擎兼容。
若你需要更高精度(如 FP8 或 BF16),也可对权重文件进行解包与格式转换。
1.3 架构细节
K2 Thinking 模型采用“多头潜在注意力”(Multi-Head Latent Attention, MLA)机制,包含 64 个注意力头与 7168 维隐藏层。
每个专家模块的隐藏层维度为 2048,激活函数采用 SwiGLU;词汇表规模为 16 万 tokens,共设有 61 层网络(含 1 个全连接层)。
其 256K 上下文窗口不仅领先于大多数开源模型,与前沿闭源模型相比也具备竞争力。
对于开发智能代理或处理大型代码库的开发者而言,“长上下文长度”与“工具协同调度能力”是该模型最核心的两大优势——它能在执行多步骤调试或重构任务时,保留大量代码上下文信息,且全程不偏离目标。
二、性能表现与基准测试
在推理、智能代理搜索与编码三大任务领域,K2 Thinking 模型均以 GPT-4.5 和 Claude Sonnet 4.5 为对标对象。
基准测试结果显示,它不仅具备竞争力,在多个领域甚至实现了性能超越。
2.1 推理性能
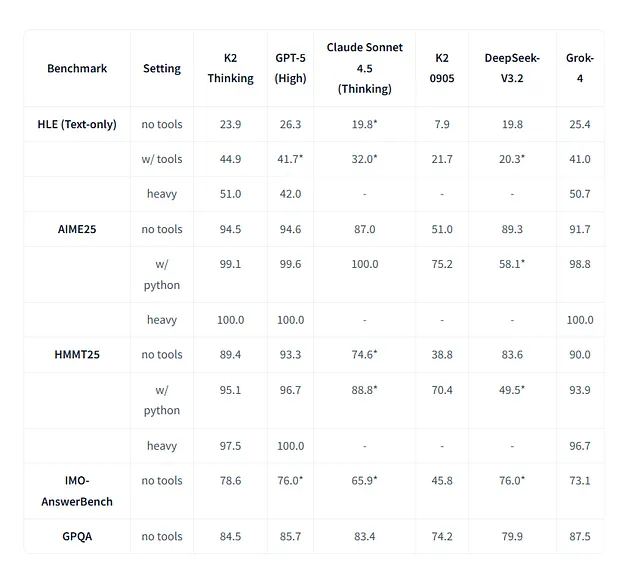
推理性能测试图
在“人类终极考试”(Humanity’s Last Exam, HLE)工具启用场景下,K2 Thinking 得分为 44.9 分。
这一成绩高于 Claude Sonnet 4.5(32.0 分),且接近 GPT-4.5(41.7 分);在不启用工具的纯文本测试中,其得分为 23.9 分,虽低于 GPT-4.5(26.3 分),但仍高于 Claude Sonnet 4.5(19.8 分)。
在允许“延长推理时间”的“重度模式”(heavy setting)下,K2 Thinking 得分进一步提升至 51.0 分。
数学基准测试方面:在可调用 Python 的 2025 年美国数学邀请赛(AIME 2025)中,该模型得分为 99.1 分;在 2025 年哈佛-麻省理工数学锦标赛(HMMT 2025)中得分为 95.1 分。
按下回车键或点击即可查看完整尺寸图片
推理性能测试结果图
这两项得分均使其跻身当前顶级模型行列。在面向研究生水平的科学基准测试 GPQA Diamond 中,K2 Thinking 得分为 84.5 分,与 Claude Sonnet 4.5(83.4 分)基本持平,且接近 GPT-4.5(85.7 分)。
2.2 智能代理搜索任务性能
按下回车键或点击即可查看完整尺寸图片
智能代理搜索任务测试图
这一领域是 K2 Thinking 模型的核心优势所在。
在测试网页搜索与信息整合能力的 BrowseComp 基准中,K2 Thinking 得分为 60.2 分——远超 Claude Sonnet 4.5(24.1 分),且高于 GPT-4.5(54.9 分)。
在中文版本测试(BrowseComp-ZH)中,K2 Thinking 得分为 62.3 分,与 GPT-4.5(63.0 分)基本持平,显著高于 Claude Sonnet 4.5(42.4 分)。
在金融搜索任务基准(FinSearchComp-T3)中,K2 Thinking 得分为 47.4 分,虽略低于 GPT-4.5(48.5 分),但仍高于 Claude Sonnet 4.5(44.0 分)。
按下回车键或点击即可查看完整尺寸图片
智能代理搜索任务测试结果图
当任务需要多步骤工具使用、搜索协同与结果推理时,K2 Thinking 模型的性能达到甚至超越了前沿模型水平。
月之暗面表示,这一优势源于模型在“交织式推理与工具调度”方面的专项训练——大多数模型将工具调用视为独立操作,而 K2 Thinking 则将其纳入推理过程的一部分。
2.3 编码性能
按下回车键或点击即可查看完整尺寸图片
编码性能测试图
在测试真实世界软件工程任务的 SWE-bench Verified 基准中,K2 Thinking 得分为 71.3 分——虽低于 Claude Sonnet 4.5(77.2 分)和 GPT-4.5(74.9 分),但高于 DeepSeek-V3.2(67.8 分),仍是顶级模型阵营中的有力竞争者。
在多语言编码基准(SWE-bench Multilingual)中,K2 Thinking 得分为 61.1 分——Claude Sonnet 4.5 以 68.0 分领先,但 K2 Thinking 仍高于 GPT-4.5(55.3 分)。
在测试“多代码库同时处理能力”的 Multi-SWE-bench 基准中,K2 Thinking 得分为 41.9 分。
按下回车键或点击即可查看完整尺寸图片
编码性能测试结果图
该基准中,Claude Sonnet 4.5 以 44.3 分领先,但 K2 Thinking 仍高于 GPT-4.5(39.3 分)和 DeepSeek-V3.2(30.6 分)。
在竞赛编程基准(LiveCodeBench v6)中,K2 Thinking 得分为 83.1 分——虽低于 GPT-4.5(87.0 分),但显著高于 Claude Sonnet 4.5(64.0 分)。
总体来看,尽管未在所有编码基准中夺冠,但 K2 Thinking 模型已具备处理复杂软件任务的能力。
2.4 支持 200-300 次连续工具调用
月之暗面官方称,K2 Thinking 模型能执行 200-300 次连续工具调用,且全程保持逻辑连贯。
大多数模型在调用 30-50 次工具后便会性能衰减,具体表现为:偏离初始目标、重复操作或输出内容逻辑混乱。
而 K2 Thinking 模型通过专项训练,能够将模糊问题拆解为清晰的子任务,用合适的工具执行任务,并在全程保持对总目标的把控。
对于“长周期智能代理任务”(如研究内容整合、多文件代码重构、复杂数据分析流程)而言,这种稳定性至关重要。
四、总结与展望
K2 Thinking 模型彻底改变了 AI 编码的成本逻辑——你只需花费一小部分成本,就能获得与 GPT-4.5 同级别的性能,且支持自行部署。
其“200-300 次工具调用稳定性”还拓展了全新应用场景:例如,跨大型代码库的多文件重构、整合数十个信息源的研究型智能代理、执行复杂转换的数据分析流程等。
对于开发智能代理系统的开发者而言,这种稳定性无疑是极具吸引力的替代方案;而仅需 0.60 美元/百万输入 tokens 的成本,也让你能够将整个代码库输入模型,无需担心成本失控。
你是否已在工作流程中测试过 K2 Thinking 模型?欢迎分享你的使用体验——无论是亮点还是不足,都期待你的反馈。
关注“AI拉呱”,评论+转发此文即可私信获取一份教程+一份学习书单!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 17
17 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)