实验室gpu服务器管理方案
采用docker,一个必要的步骤就是需要安装nvidia-container-toolkit,这样才能实现容器内的gpu访问。支持gpu共享,用户环境内能够正常访问宿主机 GPU,支持 PyTorch、TensorFlow 等深度学习框架的 GPU 功能。考虑了lxd,lxc,docker,Determined等方案,由于一些客观因素,这次计划采用docker进行管理。2.进行配置,这里只针对do
实验室目前有一台主力的gpu服务器,由于还有项目的需求,不能让所有人共用一个账号,目前需求是这样的:
-
用户隔离,每个用户能够拥有root权限,即使一个用户崩了也不会影响到其他人。
-
方便管理,可以轻松实现用户初始化,增删用户。或进一步分配gpu、存储空间。
-
支持gpu共享,用户环境内能够正常访问宿主机 GPU,支持 PyTorch、TensorFlow 等深度学习框架的 GPU 功能。
考虑了lxd,lxc,docker,Determined等方案,由于一些客观因素,这次计划采用docker进行管理。
采用docker,一个必要的步骤就是需要安装nvidia-container-toolkit,这样才能实现容器内的gpu访问。结合这个先验,我们进行一下步骤的安装。
1 安装nvidia-container-toolkit。
sudo apt install -y nvidia-container-toolkit
#不用指定版本,自动匹配你的nVidia驱动但是直接用apt安装的时候往往会报错:

apt源里边没有这个,那么就按照官方步骤进行安装:
-
安装依赖
sudo apt-get update sudo apt-get install -y curl gnupg2 -
添加 NVIDIA 容器工具链仓库 key 和 apt 源(安装 NVIDIA 容器工具包 — NVIDIA 容器工具包)
#ubuntu/Debian curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \ && curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \ sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \ sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list-
更新 apt 索引
sudo apt-get update -
安装 nvidia-container-toolkit
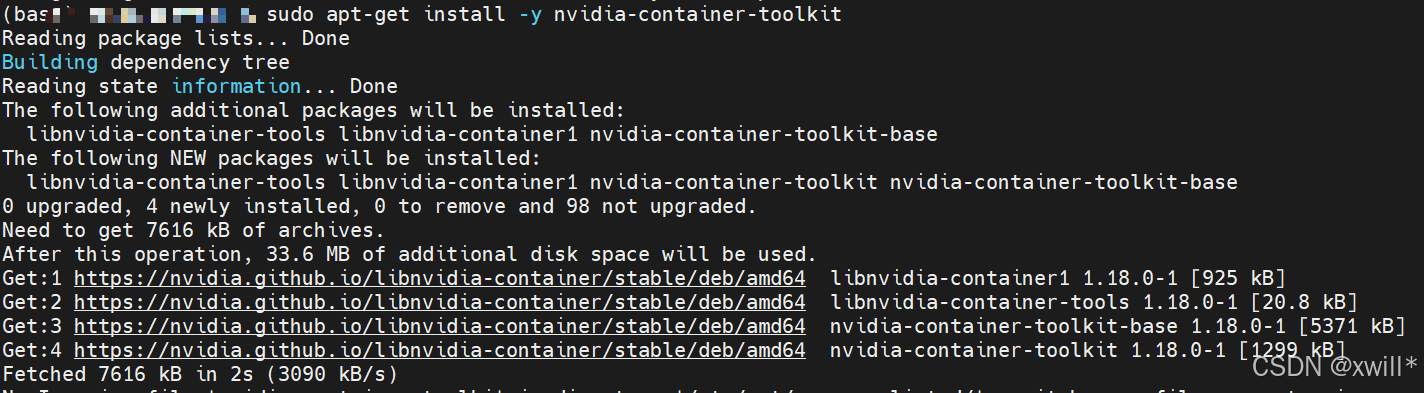
sudo apt-get install -y nvidia-container-toolkit针对RHEL/CentOS、Fedora、Amazon Linux
-
Install the prerequisites for the instructions below:
#发现我要安装的机器不是ubuntu的 sudo dnf install -y \ curl-
配置仓库源
curl -s -L https://nvidia.github.io/libnvidia-container/stable/rpm/nvidia-container-toolkit.repo | \ sudo tee /etc/yum.repos.d/nvidia-container-toolkit.repo-
安装
sudo dnf install -y nvidia-container-toolkit
-
-
2 配置
1.先安装好一个容器引擎,可以是Docker、Containerd、CRI-O、Podman
2.进行配置,这里只针对docker了,如果想配k8s什么的,可以看一下官方文档。
sudo nvidia-ctk runtime configure --runtime=docker
#nvidia-ctk 是 NVIDIA Container Toolkit 提供的命令行工具(CLI)
#runtime configure 表示你要配置容器运行时,也就是让 Docker 或其他容器运行时能够使用 NVIDIA GPU。
#--runtime=docker 表示配置 Docker 使用 NVIDIA Container Runtime。
#执行这个命令后,它会修改 Docker 的配置文件,主要是 /etc/docker/daemon.json,加入 NVIDIA 运行时支持:
3.重启docker生效
sudo systemctl restart docker补充了一下Rootless Docker的配置方案,
要注意,是否用sduo运行docker 的配置是不一样的。
普通 Docker:需要 root 权限运行 Docker 守护进程(daemon),容器的进程也可能用 root。
Rootless Docker:Docker 守护进程和容器都以普通用户权限运行,不需要 root。这在共享服务器或实验室环境中更安全。
区别:Rootless 模式下,Docker 的配置文件路径、守护进程启动方式都会和普通 Docker 不一样。
1 配置容器运行时
nvidia-ctk runtime configure --runtime=docker --config=$HOME/.config/docker/daemon.json #告诉 Rootless Docker 如何使用 NVIDIA GPU。 #--runtime=docker:配置 Docker 使用 NVIDIA runtime。 #--config=$HOME/.config/docker/daemon.json:Rootless Docker 的守护进程配置文件默认在用户目录下,而不是 /etc/docker/daemon.json,所以要指定路径。2 重启 Rootless Docker 守护进程
systemctl --user restart docker #Rootless Docker 的服务是 用户级的 systemd 服务,所以要用 --user。 #重启后,Docker 才能读取新配置,使 GPU 功能生效。3 配置 NVIDIA runtime 兼容 Rootless Docker
sudo nvidia-ctk config --set nvidia-container-cli.no-cgroups --in-place #修改 NVIDIA runtime 的内部配置,使其在 Rootless Docker 下工作。 #--set nvidia-container-cli.no-cgroups:Rootless 模式下容器无法完全使用 cgroups(控制组)管理资源。这个选项告诉 NVIDIA runtime 不要依赖 cgroups。 #--in-place:直接修改原配置文件(通常是 /etc/nvidia-container-runtime/config.toml),而不是输出到其他地方 #确保 NVIDIA runtime 在没有 root 权限和 cgroups 限制的情况下也能正常访问 GPU。
3 容器
装好之后,可以用运行一个示例来测试是否成功。
sudo docker run --rm --runtime=nvidia --gpus all ubuntu nvidia-smi
#输出以下结果。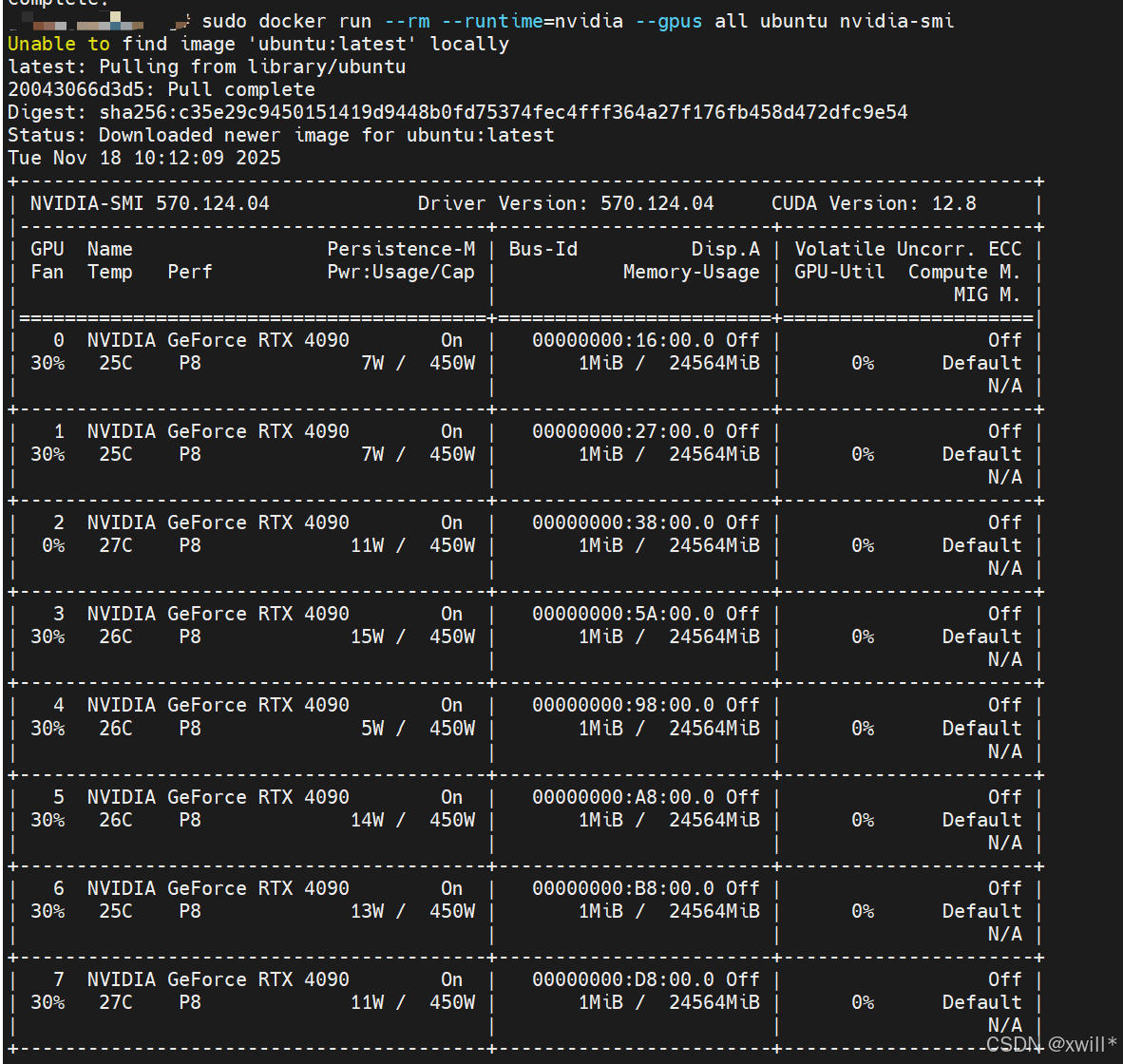
2 开始配置,我们从nvidia/cuda去选择并下载镜像,要注意镜像的版本比宿主机驱动默认支持的cuda版本要低。
先去找个镜像源:nvidia/cuda - Docker Image | Docker Hub

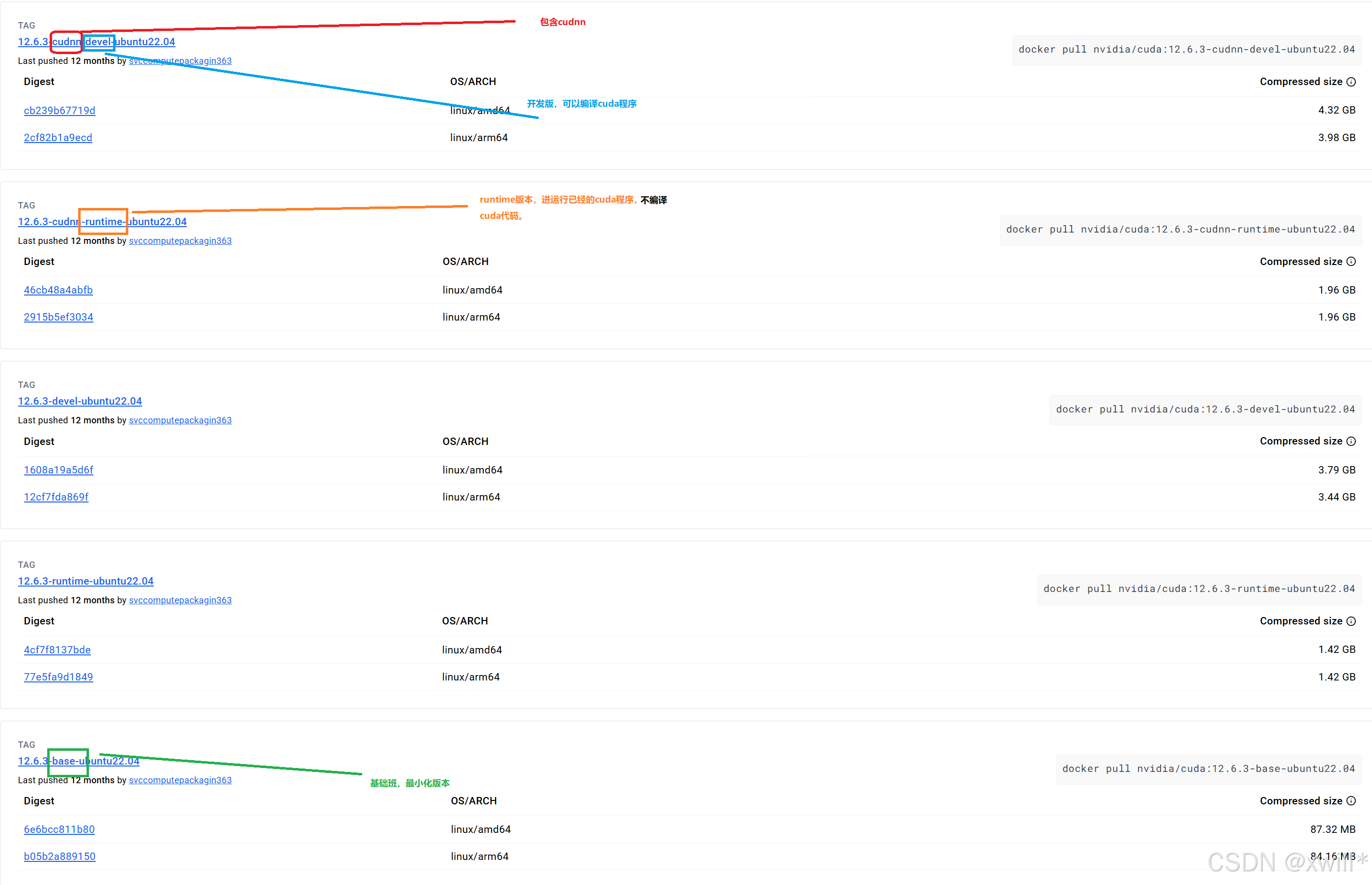
![]()
拉去成功后,可以创建一个容器:
# 创建并进入容器
docker run -it --gpus all --name my_container nvidia/cuda:12.6.3-cudnn-runtime-ubuntu22.04 bash
#-it:交互模式 + 分配终端
#--gpus all: 让容器使用 GPU
#--name my_container: 给容器起个名字
#bash: 启动容器后进入 bash简单回忆以下docker的命令:
docker stop my_container #停止容器 docker rm my_container #删除容器
命令 说明 示例 docker ps查看正在运行的容器 docker psdocker ps -a查看所有容器,包括停止的 docker ps -adocker run -it 镜像 /bin/bash从镜像创建并进入容器 docker run -it ubuntu:22.04 /bin/bashdocker run -it --name 名称 镜像 /bin/bash给容器指定名字 docker run -it --name user1 ubuntu:22.04 /bin/bashdocker stop 容器名/ID停止运行中的容器 docker stop user1docker start -ai 容器名/ID启动已停止容器并进入 docker start -ai user1docker restart 容器名/ID重启容器 docker restart user1docker rm 容器名/ID删除已停止的容器 docker rm user1docker rm -f 容器名/ID强制删除运行中容器 docker rm -f user1docker logs 容器名/ID查看容器日志 docker logs user1docker exec -it 容器名/ID /bin/bash进入正在运行的容器 docker exec -it user1 /bin/bash
命令 说明 示例 docker images或者docker image list查看本地镜像 docker imagesdocker pull 镜像拉取镜像 docker pull nvidia/cuda:12.6.3-runtime-ubuntu22.04docker rmi 镜像名/ID删除镜像 docker rmi ubuntu:22.04docker build -t 镜像名:标签 Dockerfile路径从 Dockerfile 构建镜像 docker build -t mycuda:latest .docker commit 容器 镜像名:标签将容器保存为新镜像 docker commit user1 mycuda:latest
命令 说明 示例 docker run --gpus all 镜像允许容器访问所有 GPU docker run -it --gpus all nvidia/cuda:12.6.3-runtime-ubuntu22.04 /bin/bashdocker run --gpus '"device=0,1"' 镜像指定容器访问 GPU 0 和 1 docker run -it --gpus '"device=0,1"' ...nvidia-smi容器内查看 GPU 状态 docker exec -it user1 nvidia-smi
命令 说明 示例 docker volume create 卷名创建卷 docker volume create user1_datadocker run -v /宿主机路径:/容器路径 镜像挂载宿主机路径 docker run -it -v /mnt/user1:/workspace ...docker rm -v 容器名删除容器同时删除匿名卷 docker rm -v user1
之后对容器进行一些简单的配置,让它成为一个标准的模板。
1 首先禁止root登陆,创建一个普通用户加入sudo权限。
创建普通用户并添加 sudo 权限
# 创建用户,例如 user1
useradd -m -s /bin/bash user1
# 设置密码
echo "user1:123456" | chpasswd
# 添加到 sudo 组
usermod -aG sudo user1-
-m→ 创建 home 目录/home/user1 -
-s /bin/bash→ 设置默认 shell -
sudo组默认有管理员权限,可以执行sudo命令
安装 sudo(如果镜像没有)
某些轻量级镜像可能没有 sudo:
apt update && apt install -y sudo切换到普通用户
-
临时切换:
su - user12 修改一下时区。
容器内使用tzdata
apt update && apt install -y tzdata
ln -fs /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
dpkg-reconfigure -f noninteractive tzdata

3 设置ssh,并禁止root直接登陆。
安装 OpenSSH Server
进入容器后(或者在 Dockerfile 中写):
apt update
apt install -y openssh-server-
安装完成后,SSH 服务的配置文件位于
/etc/ssh/sshd_config -
默认 root 是允许登录的,需要修改--非root更安全。
修改 SSH 配置禁止 root 登录
编辑 /etc/ssh/sshd_config:
# 禁止 root 远程登录
PermitRootLogin no
# 可选:允许使用密码登录(或者只允许 key 登录)
PasswordAuthentication yes然后重启 SSH 服务:
service ssh restart4 打包成标准镜像--直接本地管理,不放docker hub。
1)打包成镜像
docker commit gpu_container mycontn:latest
#mycontn: 镜像名称
#latest: 标签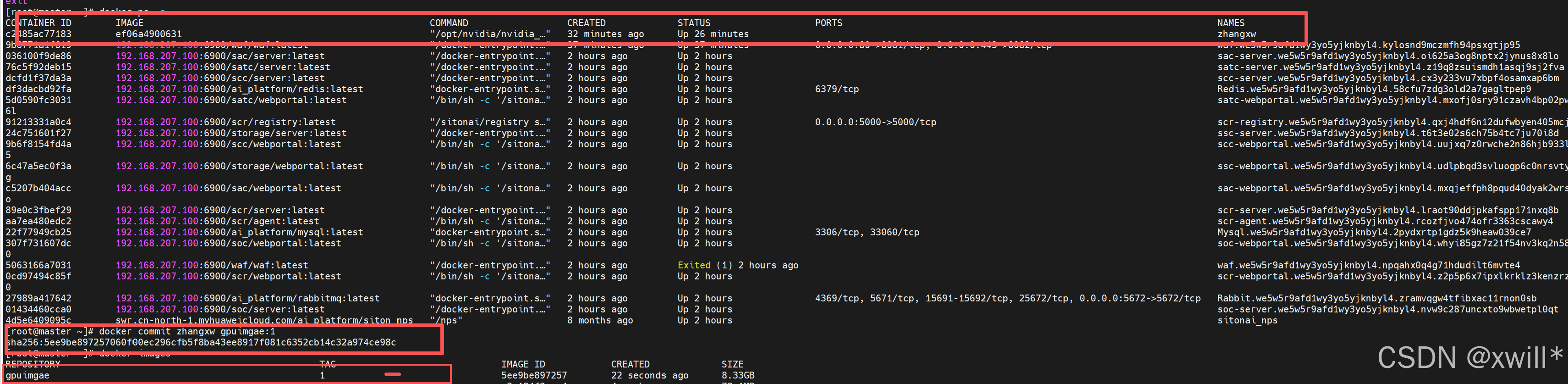
把宿主机文件复制到容器内; 忘记安装anaconda了,因此安装一个anaocnda
docker cp <宿主机路径> <容器名或ID>:<容器路径>
2)映射端口
1 启动的时候直接映射
启动容器时指定:
docker run -d --name rongqi-name -p 2222:22 --gpus all jingxiang-name
#-p 2222:22 : 宿主机端口 2222,映射到容器的端口22
#-d :Detached 模式,即后台运行容器。
docker run -d --name zhangxw668 -p 1001:22 --gpus all gpuimage:1 tail -f /dev/null #保持运行不退出
docker run -d --name zhangxw668 -p 1001:22 --gpus all gpuimage:1 /usr/sbin/sshd -D #使用ssh保持运行不退出

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 30
30 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)