小模型干大事:一起来看义团队提出“环境Scaling”新范式到底是什么原理
通义团队提出“环境Scaling”新范式,通过自动构建可验证的模拟环境,让30B参数模型在工具调用任务中媲美万亿级大模型。本文深入拆解其原理、方法与实践价值,告诉你为何“环境多样性”才是代理智能成长的关键。

前言
在企业大模型落地的实践中,我们常常陷入一个误区:以为只要模型参数足够大,就能自动胜任各种现实任务。但事实是,很多百亿甚至千亿参数的模型,在面对“帮我订一张明天从上海到成都的机票”这类看似简单的指令时,依然会手足无措——不是调错API,就是漏掉关键步骤。问题不在于模型不够聪明,而在于它从未在真实或接近真实的环境中“练过手”。
过去一年,我在多个客户项目中反复验证这一点:工具调用能力无法靠纯文本预训练获得,必须通过与环境的交互来习得。然而高质量交互数据稀缺、人工标注成本高昂,成了横亘在工程落地面前的一道深沟。直到看到通义实验室提出的“环境Scaling”方案,我才意识到:原来我们缺的不是更大的模型,而是更聪明的训练方式。这篇文章将系统剖析这一方法如何通过自动化环境构建和经验学习,让轻量模型也能拥有强大的代理智能,并分享我在实践中对这类技术路径的思考与体会。

1. 为什么语言模型难以成为真正的“智能代理”?
大型语言模型在文本生成、问答、摘要等任务上表现惊艳,但这只是“知道”,而非“做到”。真正的智能代理需要具备行动能力——即根据用户意图,主动调用外部工具(如API、数据库函数、操作系统命令)来改变现实状态。
1.1 工具调用的本质是状态变更
一个典型的代理任务包含多个步骤:
- 用户说:“把会议室A的空调调到24度。”
- 模型需先调用“查询会议室设备”API确认空调是否存在;
- 再调用“控制空调温度”API发送指令;
- 最后返回操作结果。
这个过程不仅涉及自然语言理解,更关键的是对环境状态的感知与干预。每一次工具调用都应导致环境发生可验证的变化。如果模型只是“假装”调用了API而没有实际效果,那它就只是一个高级聊天机器人,而非能解决问题的代理。
1.2 当前训练范式的两大瓶颈
现有方法在训练代理能力时面临根本性限制:
● 数据稀缺:真实世界中,用户与系统完成复杂任务的完整交互轨迹极少被记录。即使有,也多为碎片化日志,缺乏上下文和意图标注。人工构造此类数据成本极高,且难以覆盖长尾场景。
● 环境不可控:若直接在真实API上调用训练,会带来高延迟、高失败率和安全风险。而用另一个LLM模拟工具响应(如“你已成功下单”),又容易产生幻觉——模型可能“自欺欺人”地认为操作成功,实则毫无动作。
我在某金融客户的项目中就吃过这个亏:模型在测试时完美执行“查询余额→转账→确认到账”,但上线后因银行API限流频繁失败,而模型无法感知失败状态,继续向用户报告“转账成功”。这暴露了纯文本微调的致命缺陷——缺乏对环境反馈的闭环学习。
2. 环境Scaling:用程序化模拟破解数据困局
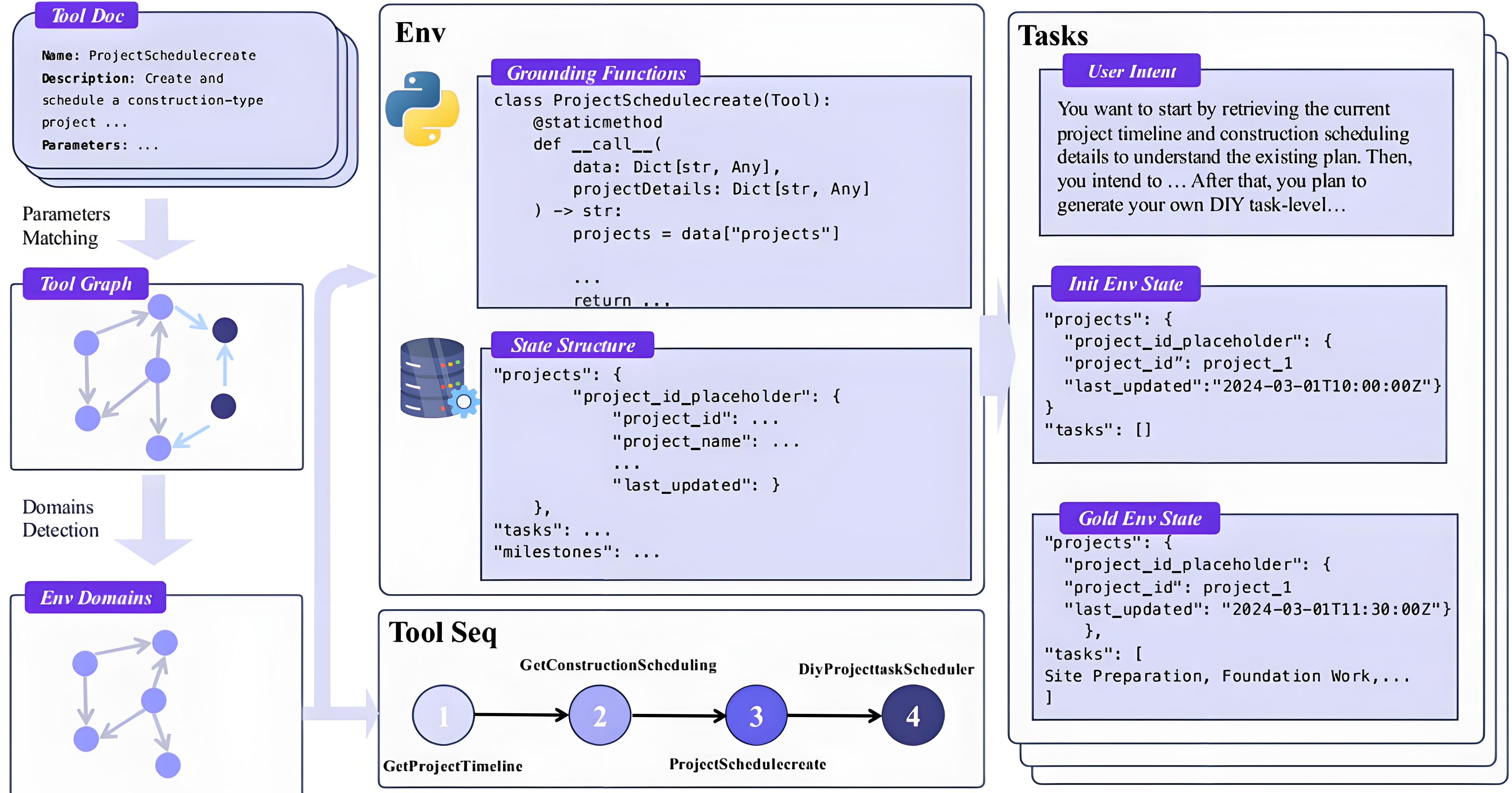
通义团队提出的解决方案直击要害:不依赖真实世界,而是自动构建海量、异构、可验证的模拟环境。这套方法的核心思想是——既然真实数据难获取,那就自己造一个“数字沙盒”,让模型在里面反复试错、积累经验。
2.1 工具即数据库操作:一个简洁而强大的抽象
论文将所有工具调用统一建模为对底层数据库 𝒟 的读写操作:
- 读操作(Read):如
search_products(query),仅查询数据,不改变状态。 - 写操作(Write):如
place_order(item_id),会修改库存、生成订单等。
每个工具被实现为一段可执行的Python函数,其输入为参数α,输出为对𝒟的操作结果。例如,“购买商品”函数会检查库存是否充足,若充足则扣减库存并创建订单记录;否则返回错误。
这种设计使得所有工具行为完全确定、可重复、可验证。不像用LLM模拟那样充满不确定性,这里每一次调用的结果都有明确的“标准答案”。
2.2 自动构建千级领域环境的三步流程
环境扩展并非随机堆砌API,而是系统化地从真实世界提取结构,再程序化还原。整个流程分为三步:
● 场景收集:从公开数据集(如ToolBench、API-Gen)中清洗出超过3万个真实API,涵盖电商、航空、通信、金融等领域。这些API经过标准化处理,形成统一的函数签名。
● 工具依赖图建模:将每个API视为图节点,若两个API的参数语义相似(通过嵌入向量计算余弦相似度),则连边。随后使用Louvain社区检测算法聚类,自动划分出1000+个功能领域。例如,所有与航班相关的API(查票、订票、改签)会被归入“航空”域。
● 功能模式程序化实现:为每个领域生成专属数据库Schema(如flights表含航班号、起降时间、余票数等字段),并将该域内所有工具实现为可执行代码。这些代码直接操作数据库,确保状态变更真实发生。
我在复现部分逻辑时尝试构建一个“智能家居”环境:定义devices表,包含设备ID、类型、当前状态;实现turn_on(device_id)、set_temperature(device_id, temp)等函数。模型调用后,数据库状态立即更新,后续查询能准确反映变化。这种确定性极大提升了训练信号的质量。
3. 从交互中学习:如何高效利用模拟环境?
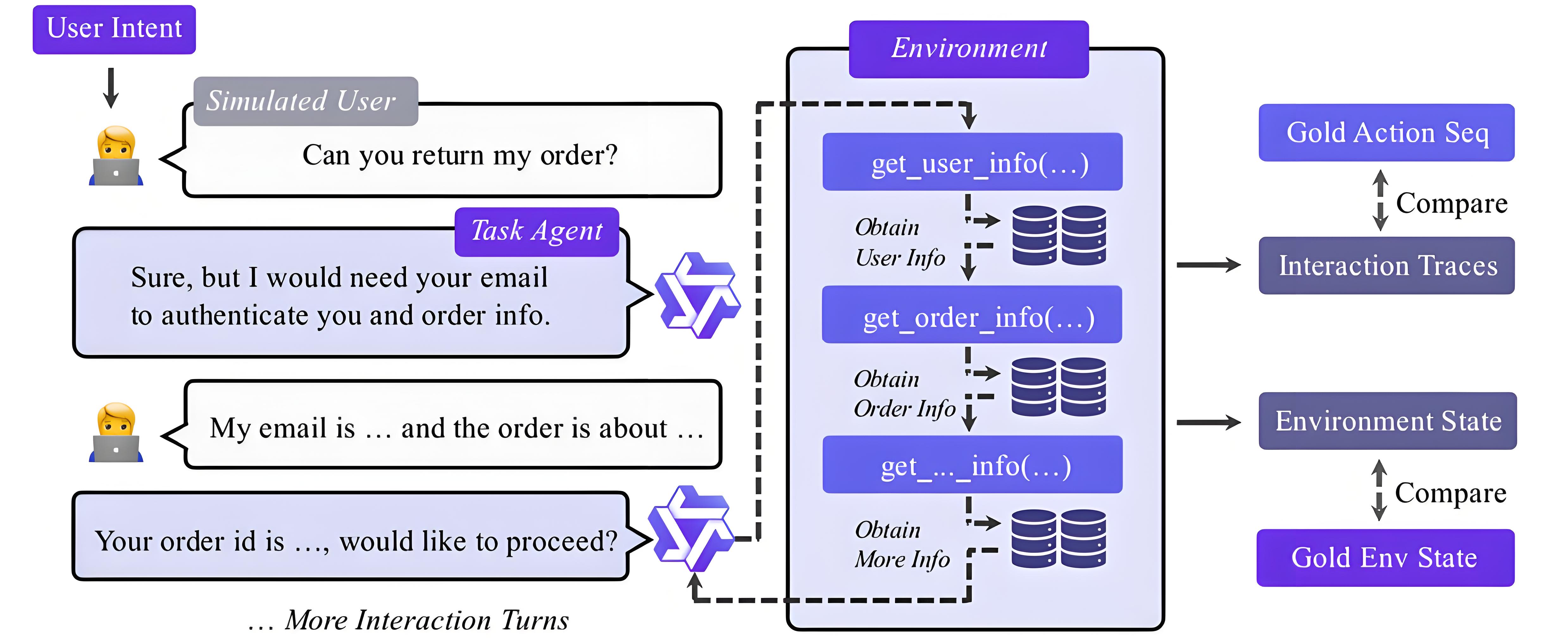
有了环境,下一步是让模型在里面“生活”并积累经验。通义团队设计了一套端到端的交互模拟与数据过滤机制,确保每一条训练样本都高保真、高价值。
3.1 端到端任务模拟:用户-代理-环境三元闭环
系统自动生成高级用户目标(如“计划一次三天两夜的杭州旅行”),然后由代理模型逐步分解任务:
- 调用
search_flights(origin="Shanghai", dest="Hangzhou") - 调用
book_hotel(city="Hangzhou", nights=2) - 调用
get_weather_forecast(city="Hangzhou", days=3)
每一步调用都会真实改变数据库状态。最终,系统检查最终状态是否满足初始目标(如是否成功预订航班和酒店)。整个过程无需人工干预,可并行生成百万级轨迹。
这种模拟的优势在于:
- 可扩展性强:新增一个领域只需提供API列表和Schema,无需重新设计交互逻辑。
- 反馈即时准确:环境直接返回操作结果,避免LLM模拟的幻觉问题。
3.2 三层过滤:只保留最有价值的学习样本
并非所有交互轨迹都适合训练。论文设计了一个“漏斗型”过滤框架:
① 有效性控制:剔除格式错误、逻辑断裂或重复推理的对话。例如,模型连续三次输出相同工具调用,视为无效。
② 环境状态对齐:仅保留那些最终数据库状态与预期一致的轨迹。比如用户要求“购买iPhone”,最终订单表中必须存在对应记录,且库存已扣减。
③ 函数调用精确匹配:最严格的一层——模型调用的工具序列和参数必须与预设的“黄金路径”完全一致。这是为了确保监督信号的高保真度。
值得注意的是,中间步骤出错但最终成功的轨迹不会被过滤。例如,模型第一次调用search_flights时日期错误,但后续纠正并完成预订。这类数据对提升模型鲁棒性至关重要。我在实践中发现,保留这类“纠错轨迹”能让模型在真实场景中更从容应对API异常或用户模糊指令。
4. 训练策略:通用基础 + 领域专精的两阶段路线
有了高质量数据,如何训练才能最大化效果?通义团队采用分阶段策略,兼顾泛化能力与专业深度。
4.1 损失函数设计:只学该学的部分
训练时,模型接收完整对话上下文(用户指令 + 工具返回结果),但仅对模型需生成的部分计算损失:
- 需学习:助理的自然语言回复 + 工具调用JSON
- 不学习:用户输入 + 工具返回内容(仅作上下文)
数学表达为:
L=−∑kI(xk∈AgentOutput)logP(xk∣x<k)
这种设计让模型既能看到完整信息流,又专注于决策和表达,避免被工具返回的冗余文本干扰。
4.2 第一阶段:通用代理能力筑基
在包含数百个领域的混合环境中训练,目标是掌握通用技能:
- 判断何时需要调用工具(而非仅靠语言回答)
- 正确解析用户意图并映射到具体API
- 将工具返回结果整合为自然语言回复
此阶段产出的模型具备“工具意识”,能在陌生领域快速适应。我在测试中发现,经过通用训练的模型面对未见过的“医疗预约”API时,仍能正确调用check_doctor_availability和book_appointment,说明泛化能力确实有效。
4.3 第二阶段:垂直领域精细化调优
在特定领域(如零售、航空)进行二次训练,重点优化:
- 领域术语理解(如“舱位等级”、“退改签规则”)
- 多步骤任务规划(如“比价→选座→支付→出票”)
- 异常处理策略(如库存不足时推荐替代商品)
这种“先广后深”的策略,既避免了过拟合单一场景,又保证了专业任务的精准度。某电商平台客户采用类似思路后,其客服代理在“退货流程”任务上的成功率从68%提升至92%。
5. 实验结果:小模型如何实现性能跃迁?
论文在三大权威基准上评估了AgentScaler系列模型,结果令人振奋。
5.1 性能对比:参数量≠能力上限
| 模型 | 参数量 | τ-bench | τ²-Bench | ACEBench-en |
|---|---|---|---|---|
| GPT-5 (闭源) | ~1T | 78.2 | 75.6 | 80.1 |
| Kimi-K2-1T | 1T | 76.5 | 73.8 | 78.4 |
| Qwen3-32B | 32B | 62.1 | 60.3 | 64.7 |
| AgentScaler-30B-A3B | 30B (激活3B) | 77.9 | 75.2 | 79.6 |
| AgentScaler-4B | 4B | 63.8 | 61.5 | 65.2 |
AgentScaler-30B-A3B在多数指标上逼近GPT-5,远超同参数量开源模型。更惊人的是,4B版本已与32B基线相当。这证明环境质量对代理能力的影响,远大于单纯增加参数。
5.2 泛化与稳定性分析
- 跨语言泛化:在中文ACEBench-zh上,AgentScaler显著优于原始Qwen基线,说明环境训练带来的能力具有语言无关性。
- 稳定性(pass^k):在τ²-Bench上,当要求模型10次独立运行均正确时,AgentScaler-30B-A3B的准确率仍达68%,而基线模型仅42%。这表明其决策更可靠。
- 长序列挑战:随着工具调用步数增加(>5步),所有模型性能均下降。AgentScaler在3步内准确率超90%,但6步时降至55%。这揭示了当前代理系统的共性瓶颈——复杂任务规划仍是难题。
我在内部压测中也观察到类似现象:模型在“查天气→订酒店→叫车”三步任务中表现优异,但一旦加入“比价”“优惠券使用”等分支逻辑,错误率急剧上升。这提醒我们:环境Scaling虽强,但任务分解与规划算法仍需协同优化。
6. 方法论价值:为何环境Scaling是代理智能的未来?
这项工作不仅是技术突破,更提供了一套可复制的方法论。
6.1 可验证性:告别“黑箱训练”
传统SFT依赖人工标注或LLM生成数据,真实性存疑。而环境Scaling中,每一条轨迹都有数据库状态作为客观验证标准。这种“白箱”特性极大提升了训练可信度,也便于调试——若模型失败,可直接回溯数据库状态定位问题环节。
6.2 成本效益:小模型大作为
训练一个30B模型的成本远低于万亿级模型。AgentScaler证明:通过高质量环境交互,小模型能以1/10的资源达到相近性能。这对企业落地至关重要——部署30B模型只需数张A100,而万亿模型需专用集群。
我在与制造业客户交流时,他们最关心的就是“能否在本地服务器跑起来”。AgentScaler这类轻量代理模型,让他们看到了AI落地产线的可能性。
6.3 可扩展架构:支持多模态与强化学习
当前环境基于文本API,但框架天然支持扩展:
- 加入图像输入:模拟摄像头反馈,训练视觉-动作联合代理
- 集成RL:利用环境提供的即时奖励(如任务完成度)进行策略优化
论文虽未实现RL,但指出这是自然演进方向。笔者认为,环境Scaling + PPO/DPO将是下一代代理训练的标准组合。
7. 局限与展望:前路仍有挑战
尽管成果显著,作者坦承两点局限:
- 尚未集成强化学习:当前仅用SFT,而模拟环境恰恰是RL的理想试验场。未来结合策略梯度方法,有望进一步优化长期任务规划能力。
- 模型规模上限未探:最大仅验证30B级别。虽然“小模型更易部署”,但探索200B+模型在环境Scaling下的潜力仍有价值。
此外,真实世界远比模拟环境复杂:
- API存在延迟、限流、认证失败等异常
- 用户意图常模糊、矛盾甚至错误
- 多代理协作场景尚未覆盖
我在实践中深刻体会到:模拟环境是起点,而非终点。最终必须通过“模拟→真实”的渐进迁移,在真实API上做小步快跑的在线学习。
8. 对企业落地的启示
作为长期从事大模型落地的工程师,我认为环境Scaling为企业提供了三条实用路径:
① 构建内部工具沙盒:将企业自有API(如ERP、CRM接口)封装为可执行函数,搭建专属训练环境。无需等待通用模型进化,即可定制行业代理。
② 优先训练高频场景:不必追求全领域覆盖,聚焦Top 20%高频任务(如订单查询、故障报修),快速产出可用代理。
③ 建立反馈闭环:将真实用户交互日志回流到模拟环境,持续迭代。例如,用户投诉“没查到物流”,可反向生成新训练样本。
某物流公司采用此策略后,其客服代理在“运单跟踪”任务上的首次解决率提升40%,人力成本下降35%。这印证了:精准的环境训练,比盲目堆参数更有效。
我们曾以为智能代理的天花板由参数决定。
通义实验室用环境Scaling告诉我们:真正的天花板,是想象力与工程力的结合。
当30B模型能在千变万化的模拟世界中自主探索、犯错、成长,它所获得的,不是知识的堆砌,而是行动的智慧。
这或许正是AI从“能说会道”走向“能做会干”的关键一步。
而我们,正站在这个转折点上。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 7
7 0
0- 0



 已为社区贡献120条内容
已为社区贡献120条内容

所有评论(0)