AI炼金术的秘密:扩散模型、CLIP与高维空间中的时间逆转
摘要 扩散模型通过逆转物理学中的布朗运动原理,实现了从文本到图像的跨模态生成。CLIP模型构建了512维共享嵌入空间,将文本和图像语义映射为可计算的向量表达。关键技术突破包括:DDPM预测总噪声的逆向去噪机制,DDIM通过确定性采样提升效率,以及无分类器引导和负面提示实现对生成过程的精准控制。这些方法共同构成了现代生成式AI的核心框架,使语言成为新的创作媒介,大幅降低了内容创作门槛。未来发展方向将
引言/导读
在短短几年内,人工智能已在将文字转化为逼真图像和视频方面取得了惊人的成就。这些成果的核心技术是一系列被称为“扩散模型”(Diffusion Models)的生成系统,它们巧妙地利用了物理学中粒子扩散的原理,并在高维向量空间中逆转时间。
本篇深度博客文章将作为AI生成技术的一份详尽路线图,不仅深入解析扩散模型(如DDPM、DDIM)的工作原理及其与布朗运动的深刻关联,更将揭示OpenAI的CLIP模型如何为这一过程提供强大的语义导航能力。我们将探讨从随机噪声到清晰图像的每一步迭代背后的数学和工程智慧,以及决定最终生成质量的关键机制——无分类器引导和负面提示。对于所有对AI前沿技术怀有好奇心的开发者、产品经理和行业爱好者来说,理解这些核心原理是把握生成式AI浪潮的关键。
一、跨模态桥梁:CLIP模型与嵌入空间几何
要让AI从文本理解“宇航员骑马”的视觉概念,首先需要弥合文本和图像之间的鸿沟。OpenAI在2021年发布的CLIP(Contrastive Language–Image Pre-training)模型正是实现这一目标的核心。
1. 对比学习构建共享语言
CLIP并非单一模型,而是由两个独立训练的组件构成:一个处理文本,一个处理图像。
- 训练目标:CLIP在包含 4 亿张图片及其标题对的数据集上进行训练。其核心思想是,匹配的图像及其标题的向量(嵌入向量)应该在共享空间中相似,而不匹配的向量则应该差异最大。
- 对比机制:模型通过对比学习(Contrastive Learning)优化,使用余弦相似度来衡量向量间的相似性。如果文本向量和图像向量指向同一方向,相似度得分最大值为 1。
- 潜在空间:每个模型的输出是一个长度为 512 的向量。这个共享的、高维的向量空间被称为潜空间(Latent space)或嵌入空间(Embedding space)。
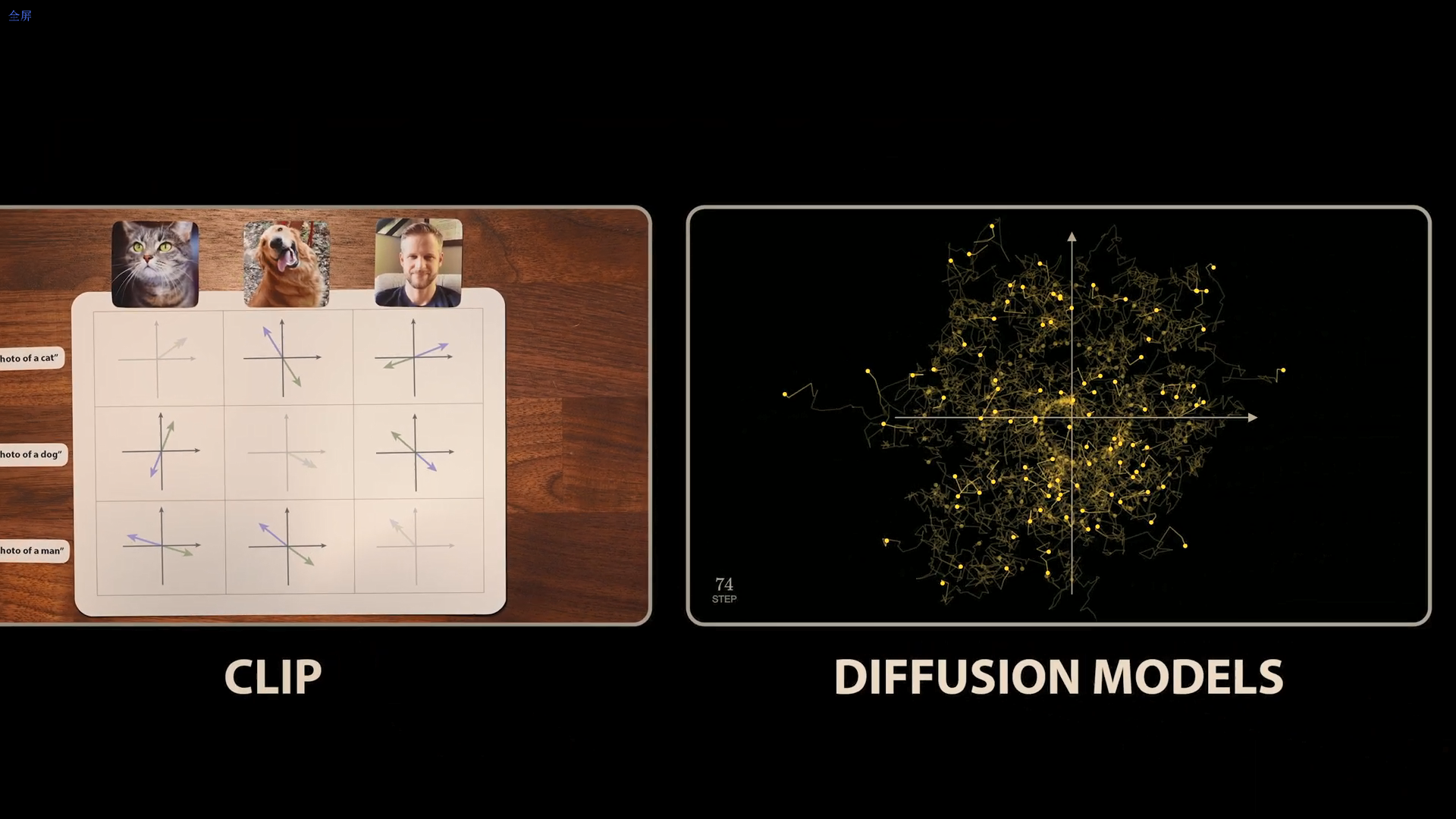
2. 高维度的概念代数
CLIP嵌入空间的几何结构具有惊人的特性,允许对纯粹的概念进行数学运算。
分析发现,通过对嵌入向量进行加减法操作,可以实现对概念的转换。例如,将“戴帽子的照片”的向量减去“不戴帽子的照片”的向量,得到的差异向量,在与数百个常用词进行余弦相似度计算时,相似度最高的词是“hat”(帽子),其次是“cap”和“helmet”。这一发现表明,CLIP能够将图像内容差异(如是否有帽子)转化为嵌入空间中向量间的实际距离,为后续的生成模型提供了强大的语义理解和分类能力。
二、扩散模型的核心机制:高维空间中的时间逆转
尽管CLIP为我们提供了将文本转化为概念向量的能力,但它只能单向地将图像和文本映射到嵌入空间,无法反向生成图像。要实现生成,我们需要依赖扩散模型。
1. 布朗运动的逆转与去噪过程
扩散模型的核心灵感来源于物理学中的布朗运动,但将其过程在时间上逆转。
- 正向扩散:模型训练首先从一组清晰的训练图像开始,逐步向其添加随机噪声,直到图像完全被破坏(变为纯噪声)。
- 逆向去噪:神经网络(通常是Transformer或U-Net结构)被训练来逆转这一过程。以开源模型WAN 2.1生成视频为例,过程从一个纯噪声视频开始,通过变压器(Transformer)的迭代,一步步将噪声转化为逼真的视频。
2. 学习时变向量场与DDPM的突破
早期对扩散模型的简单理解是训练模型一步步去除噪声,但这在实践中被证明是无效的。伯克利团队在2020年发布的DDPM(Denoising Diffusion Probabilistic Models)论文提出了一个里程碑式的有效方法。
- 预测总噪声:DDPM并没有训练模型去预测前一步的图像,而是要求模型预测添加到原始“干净”图像(X0)中的总噪声。
- 分数函数与向量场:从几何角度看,可以将图像视为高维空间中的一个点。向图像添加噪声相当于在高维空间中进行随机游走。扩散模型实际上学习的是一个时变向量场。这个向量场被称为“分数函数”(Score Function),它指向数据分布中更有可能、噪声更少(即更像真实图像)的方向。
- 提升效率:通过训练模型直接预测指向原始起点(X0)的向量,即使训练数据是嘈杂的,也能大大减少训练示例的方差,从而使模型学习更加高效。
三、效率与质量的平衡:DDPM到DDIM的演进
DDPM方法证明了扩散模型生成高质量图像的可行性,但其计算成本高昂,因为需要大量的步骤(每一步都需要通过庞大的神经网络)。对图像生成算法的改进是模型走向实用化的关键。
1. 随机噪声:防止收敛到平均值
在DDPM的图像生成算法中,一个反直觉但至关重要的步骤是,在每一步去噪后,必须向图像添加额外的随机噪声。
- 结果分析:如果移除这个随机噪声步骤,所有生成的点都会迅速移动到数据分布的中心或平均值。在图像空间中,平均值表现为模糊不清的非现实图像(例如,移除噪声后,生成的树变得模糊且令人伤心)。
- 理论依据:数学上可以证明,由于正向扩散过程中添加的是高斯噪声,反向过程的每一步实际上是在学习预测正态分布的平均值。为了真正从该分布中采样,必须在预测值上添加零均值高斯噪声,这正是DDPM中随机噪声步骤的作用。
2. 从随机微分到确定性采样:DDIM
为了解决计算效率问题,研究人员利用物理学和统计力学中的理论找到了突破口。
- 微分方程转换:DDPM的生成过程可以用一个包含随机成分的随机微分方程(Stochastic Differential Equation, SDE)表示。谷歌大脑团队利用福克-普朗克方程(Fokker-Planck equation)证明,存在一个常微分方程(Ordinary Differential Equation, ODE),即不含随机成分的方程,其最终的点分布与 SDE 相同。
- DDIM的优势:基于此,DDIM(Denoising Diffusion Implicit Models)方法被提出。DDIM生成过程是完全确定性的,不需要在每一步添加随机噪声,并且通过优化步长缩放,能够以更少的步骤生成高质量结果。
- 实用价值:DDIM(或其通用化方法如流量匹配,被WAN 2.1使用)的出现,显著降低了扩散模型运行的计算要求,使其得以在更广泛的范围内应用。
四、提示工程的灵魂:条件化与无分类器引导
仅仅能生成图像还不够,模型必须能够精准地响应文本提示(Prompt)的需求。
1. 文本条件化与局限
最直接的方法是“调节”(Conditioning):将CLIP的文本嵌入向量作为额外的输入(条件)传递给扩散模型,以帮助模型去噪时获取更多上下文信息。
然而,实际应用表明,仅靠简单的条件化不足以达到DALL-E 2等模型所展示的精准度。例如,如果仅对Stable Diffusion进行条件化,模型可能只生成沙漠和阴影,但却“忘记”了提示中要求生成的“树”。
2. 无分类器引导:放大意图的方向
为了更有效地引导扩散过程,需要一种更强大的机制,即无分类器引导(Classifier-Free Guidance)。
- 双模型差值:该方法的核心在于利用两个模型输出的差异:有条件模型(Conditional Model,输入包含文本提示)和无条件模型(Unconditional Model,输入不含文本或类别信息)。
- 分离和放大:无条件模型学习指向一般数据分布(如螺旋的整体结构),而有条件模型学习指向特定类别。通过将有条件向量减去无条件向量,得到一个“差异向量”。这个差异向量代表了从一般数据方向到目标类别方向的纯粹“意图”。
- 引导尺度:通过乘以一个缩放因子 $ \alpha $(引导尺度),可以放大这个差异方向,从而更有力地将生成过程导向提示所描述的细节。实验显示,随着引导尺度 $ \alpha $ 的增加,图像中树的大小和细节都会得到显著改善。
3. 负面提示:明确“不要什么”
WAN 2.1 等先进的视频生成模型将引导机制推向了新的高度:使用负面提示(Negative Prompts)。
- 反向引导:模型不是减去无条件模型的输出,而是利用用户明确写出的“不希望出现的特征”作为负面提示。
- 提高质量:通过从模型的条件输出中减去这些负面提示向量并放大结果,扩散过程被主动引导远离这些不理想的特征(例如,多指、倒退等,有趣的是,WAN 2.1的标准负面提示甚至是中文输入的)。这极大地提高了视频的连贯性和逼真度。
深度分析与行业洞察
扩散模型所展现的惊人能力并非来自于单一的技术突破,而是多条复杂技术线索的完美缝合与高效协同。
1. 跨学科的机器融合
生成式AI的崛起,本质上是一场计算科学与基础物理学的深度融合。
- 物理学的根基:将图像生成过程建模为布朗运动的逆转,这一基于随机微分方程(SDE)的视角,为AI提供了强大的理论框架,并催生了如DDIM这类极具效率的确定性采样算法。这种与物理学的紧密联系,远超简单的表面类比,是获得算法灵感的真正来源。
- 语义与视觉的统一:CLIP的对比学习机制,成功在高维空间中创造了一个“想法的向量空间”,使得复杂的文本指令能够被量化和导航。
- 工程的精妙:无分类器引导机制是工程上的巨大胜利。它通过利用两个模型(有条件与无条件)之间的差值,实现了对生成结果的超控能力。这允许用户在生成质量(依赖于模型本身对数据的理解)与提示遵循度(依赖于引导强度)之间进行灵活调节。
2. 创作媒介的范式转变
扩散模型及其配套技术的结合,创造出了一种全新的“机器”。
传统上,制作栩栩如生或美轮美奂的图像和视频,需要相机、画笔、绘画技巧或动画软件。而现在,所需的仅仅是语言。
这种转变带来的影响是深远的:
- 创作的民主化:它极大地降低了内容创作的门槛,使得任何拥有精确语言表达能力的人都能成为创作者。
- 提示工程的复杂化:随着模型能力的提升,如何有效利用“引导”机制(特别是负面提示)成为一门艺术。成功的提示工程(Prompt Engineering)不再仅仅是描述你想要什么,更需要明确指出你不想要什么。这种对引导尺度的精细控制,将成为未来AI设计师和用户的核心技能。
3. 未来的挑战与趋势
未来的发展将继续围绕效率和控制力展开。
- 效率革命:基于流的模型(Flow-based models)和更快的确定性采样方法(如DDIM)将继续减少生成高质量内容所需的计算步骤和时间。
- 控制力的精进:负面提示(通过引导机制实现)的引入,表明了人类对AI生成过程的主动干预和细致控制的需求。未来的生成模型可能会集成更多复杂且灵活的引导机制,使输出不仅符合提示,更能遵循复杂的叙事逻辑和风格要求。
总结与展望
从伯克利团队的DDPM论文在2020年夏天发表以来,扩散模型领域取得了令人震撼的进步,最终形成了我们今天所见的文本到视频生成模型。这些成就的基石在于:强大的共享表示法(CLIP)、物理学启发的逆向去噪过程(DDPM/DDIM)、以及精妙的引导机制(无分类器引导与负面提示)。这些原本独立的复杂组件能够完美地拼接在一起,共同在高维空间中将纯粹的噪声塑造为我们所需的逼真内容,这本身就是一场科学的奇迹。
我们正站在一个新时代的门槛上,语言成为了新的创作工具。
未来,我们是否能通过更少的引导,让AI更精确地捕捉人类的微观意图,从而真正实现“所想即所得”的终极创作自由?
要点摘要
- 核心原理:扩散模型(Diffusion Models)通过逆转物理学中的布朗运动,在高维空间中学习时变向量场(Score Function),将纯噪声转化为图像/视频。
- 语义理解:CLIP模型利用对比学习构建了图像和文本的 512 维共享嵌入空间,使概念可以被数学化处理。
- 算法演进:DDPM(去噪扩散概率模型)是里程碑,其训练目标是预测总噪声。DDIM(去噪扩散隐式模型)则实现了确定性采样,大幅提高了生成效率和计算可行性。
- 引导精髓:无分类器引导机制通过放大有条件模型与无条件模型之间的差异,极大地增强了模型对文本提示的遵循能力。
- 高级控制:负面提示(Negative Prompts)通过主动引导生成过程远离不希望出现的特征,是提升现代视频和图像模型质量的关键技术。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 18
18 0
0- 0



 已为社区贡献31条内容
已为社区贡献31条内容

所有评论(0)