【AI学习】Google 最新的白皮书,《Introduction to Agents》
这里是@黄建同学在微博发的文章,摘录转载一下,做个记录
这里是@黄建同学在微博发的文章,摘录转载一下,做个记录
Google 最新的白皮书
Google 最新的白皮书,很值得收藏!
《Introduction to Agents》 ,这个白皮书几乎可以看作是对“智能体时代”正式宣言。它系统地定义一种新型软件范式——让模型能自主思考、决策和执行。AI 正在从“预测”走向“行动”。
- 从预测式AI到行动式AI
过去的AI是“被动的”:模型接收输入、生成输出,一问一答。但这篇文档开篇就指出,我们正在经历一次范式转变——从“预测AI(Predictive AI)”到“自主智能体(Autonomous Agents)”。智能体的关键区别在于:它不再等人指令,而是能围绕目标自我规划、行动、再评估。
Google 把这类系统定义为一个闭环结构:LLM + 工具 + 编排层 + 部署环境。LLM提供推理,工具执行动作,编排层控制整个“思考—行动—观察”的循环,而部署让智能体能长期运行和被复用。
- 智能体的工作循环:Think–Act–Observe
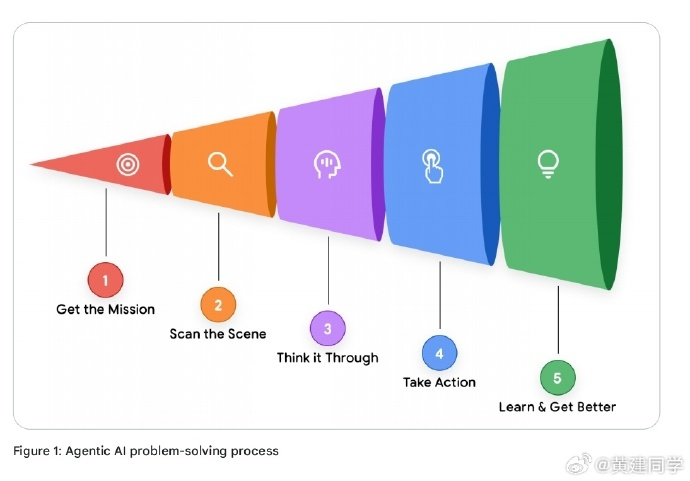
文档用一个非常清晰的五步模型解释智能体的工作方式:
- 获取任务(Get the mission)
- 扫描场景(Scan the scene)
- 思考计划(Think it through)
- 执行动作(Take action)
- 观察反馈(Observe & iterate)
这一循环让智能体具备了真正的“任务感”。举个例子:用户问“我的订单在哪?”,智能体不会立刻回答,而是分解出“查订单→查物流→整合结果→回复”的完整路径。
我特别喜欢它强调的那句话:智能体的本质,是上下文窗口的策展人(curator of context window)。——它不断组织、更新、过滤信息,让模型始终聚焦在当前任务最关键的上下文上。
- 智能体的分级:从单脑到群体
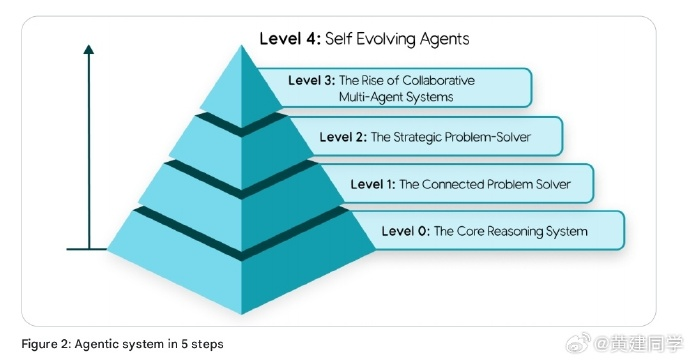
这份白皮书提出了一个五层级的智能体体系:
Level 0:仅推理模型(纯LLM)
Level 1:能调用外部工具的“连接型问题解决者”
Level 2:具备策略规划与上下文工程能力的“战略型智能体”
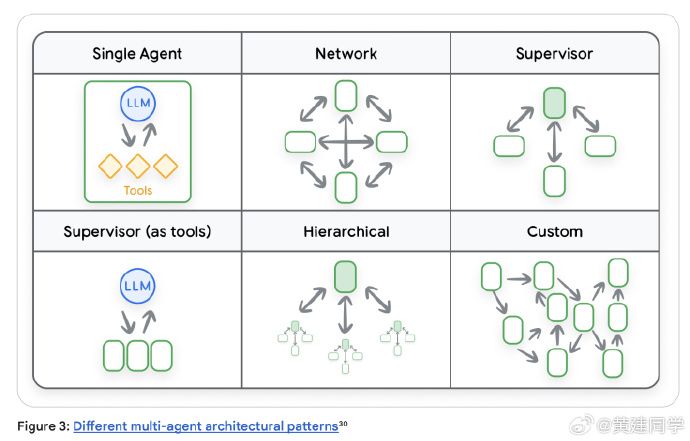
Level 3:多智能体协作系统(类似团队协作)
Level 4:自我演化系统(能创造新工具或子智能体)
这一分级体系几乎可以当作企业部署智能体架构的路线图——从简单的调用API,到让智能体学会分工合作,最后走向能自我改进的“学习型组织”。
-
三大核心组件:脑、手与神经系统
Google 把智能体拆成三个核心部分: -
Model(脑):推理与决策中心,负责思考。
-
Tools(手):执行动作的能力,比如RAG、API、代码执行。
-
Orchestration Layer(神经系统):调度逻辑、记忆与策略,实现“Think–Act–Observe”循环。
有一个关键点:他们认为模型并不是越大越好,而是要根据任务选择最优组合——复杂任务用强模型(如Gemini Pro),高频简单任务则用轻模型(如Gemini Flash)。这种模型分层调度的思路对未来Agent架构很关键。
- Agent Ops:智能体的运维哲学
文档中提出了一个新概念——Agent Ops。它相当于 DevOps 在智能体时代的延伸。
因为智能体行为具有不确定性,传统的“单元测试=预期输出”已经失效。Agent Ops 的目标是通过指标驱动、日志追踪、模型评审和用户反馈闭环,让系统在不确定中保持可靠。
一个新的职位或部门来了?Agent Ops
- 安全与治理:从单Agent到Agent Fleet
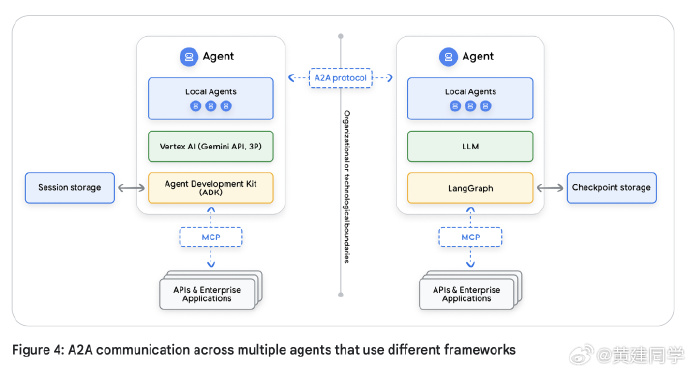
当智能体数量增多,问题就从“怎么造一个Agent”变成“如何管理一群Agent”。Google 提出的解决思路是建立控制面板(Control Plane),统一管理身份、权限和通信协议(MCP/A2A),避免Agent Spraw(智能体泛滥失控)。
有意思的是,文中引入了“Agent作为新型主体(principal)”的概念,认为Agent不只是代码,而是一种能独立被认证、被授信的行动体。
- 学习与自演化:Agent Gym 的想象力
最后几章讨论了“Agent如何自我进化”。Google 提出了一个概念叫 Agent Gym,类似模拟环境,用来让智能体在离线条件下训练、演练、红队测试、吸收人类反馈,从而“成长”。
这两个新的点,之前没深刻理解:
-
Agent = 新的软件范式。过去我们以为“智能体”只是“会用工具的模型”,但Google用这份文档明确告诉大家——Agent是一种新的软件范式。它不是应用AI,而是用AI重新定义应用。
-
Agent的核心不在“思考”,而在编排(orchestration)。未来的开发者更像导演而不是程序员——我们要设计场景、挑演员、布置镜头,让智能体自然演出目标行为。

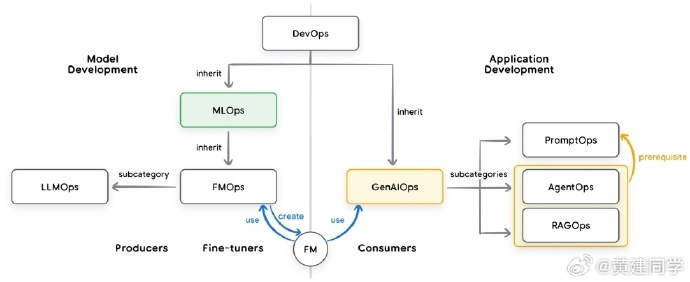
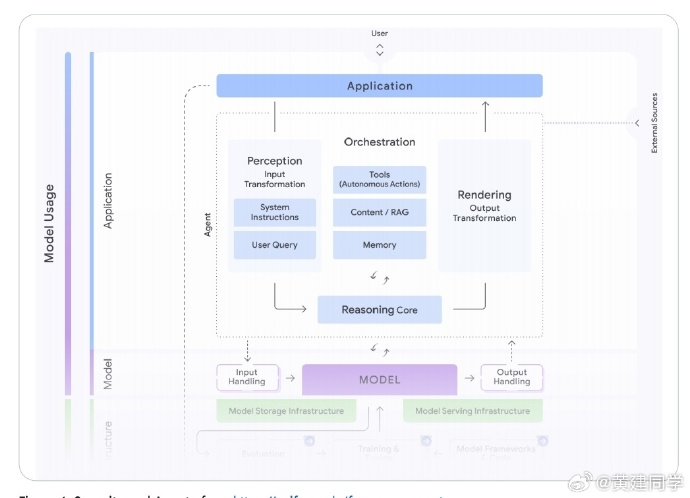
MCP的白皮书: Agent Tools & Interoperability with Model Context Protocol (MCP)
这应该是目前 MCP 体系最系统的白皮书(之一)了吧,通篇结构清晰,既讲了工具在智能体系统中的定义和设计原则,又深入分析了 MCP 在技术架构、安全与治理方面的优势与风险。
-
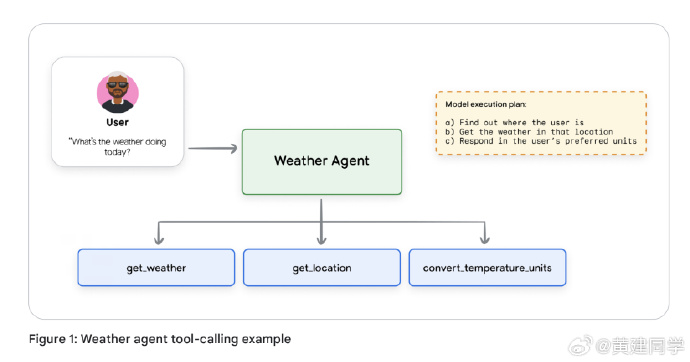
工具是智能体的“手与眼”。
大模型本质上只是一个模式预测引擎,不能主动感知世界或执行动作。工具让模型拥有了外部交互能力,也因此成为智能体系统的核心组件。
文中对工具类型有很清晰的划分:Function Tools(函数调用型)、Built-in Tools(内置工具)和 Agent Tools(智能体级调用)。
特别有意思的是,Agent 本身也可以被封装成一个 Tool,这意味着多智能体系统可以通过“工具接口”彼此互操作。 -
工具设计的关键是可解释与细粒度。
文档强调“Describe actions, not implementations”,也就是工具描述应聚焦行为语义,而非实现细节。
并提出几个值得长期遵守的设计准则:文档清晰、输入输出有 schema 验证、输出简洁、错误信息具引导性。
这些看似“文档规范”的建议,其实是让 LLM 能在推理过程中正确选择与调用工具的前提。 -
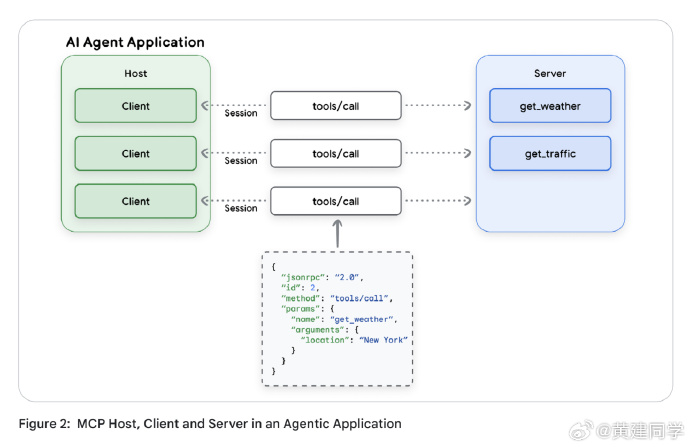
MCP 出现的根本原因,是为了解决“N×M 集成问题”。
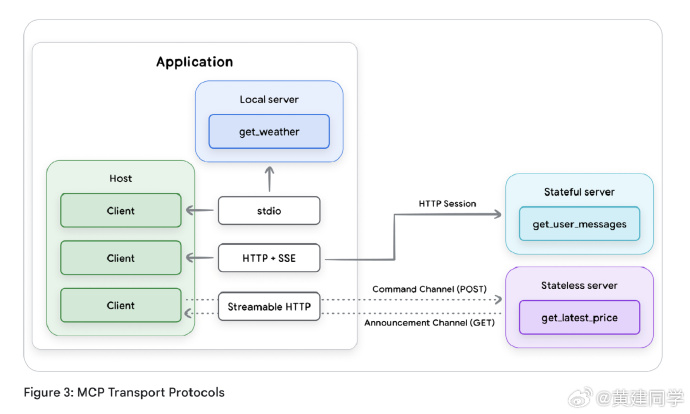
过去模型和外部系统之间的连接高度碎片化,每个工具都要单独适配。MCP 通过标准化接口和通信协议把模型、工具和数据源解耦,形成“Host–Client–Server”的三层结构,从而实现了可复用、可组合、可动态发现的工具生态。 -
MCP 的优势在于生态与扩展性。
它让工具注册、发现与调用变得统一,支持动态工具加载,这使得智能体系统不再需要在部署前定义好所有能力。
文中提到 MCP Registry 的构想(类似 npm 或 PyPI),也许会形成 AI 工具层的“包管理体系”。这将极大加速企业级智能体生态的互通。 -
但 MCP 也带来了新的安全威胁。白皮书后半部分几乎一半篇幅都在讨论风险,包括:
1)Dynamic Capability Injection:服务器可动态更改工具集,导致智能体意外获得高危能力;
2)Tool Shadowing:恶意工具通过相似描述“抢占”合法工具调用;
3)Confused Deputy 问题:智能体误用自身权限代替用户执行越权操作;
4)数据泄露与 prompt 注入:通过工具输入输出通道泄露敏感信息。
文中提出的防御策略(如工具白名单、版本固定、mTLS、HIL 审批、输出净化、最小权限原则等)都是非常实用的企业级落地建议。
-
MCP 的发展路径很可能会复现云计算早期的模式——底层协议开放,但企业实际使用都建立在“托管与治理层”之上。
未来我们也许会看到“安全版 MCP 平台”,它提供身份管理、审计追踪、工具签名验证、访问控制等功能,就像当年的 API Gateway 成为了 REST 的守门人。 -
另一点值得注意的是“上下文膨胀”问题。文中指出,当 MCP 工具数量增多时,所有工具定义都要塞入模型上下文,会导致 tokens 暴涨、推理性能下降。文中提出用“RAG 化的工具检索”替代预加载——先检索,再动态注入。有个名词叫“ToolRAG”。
MCP 已经成为智能体生态走向工业级互操作的关键里程碑,但它还远没到“可直接上生产”的成熟阶段。未来的重点不在于“协议标准”,而在于“安全与治理层”的建设。
只有当工具、智能体与企业系统之间的边界被有效约束,Agent 才能在真正意义上成为可信的“行动者”。






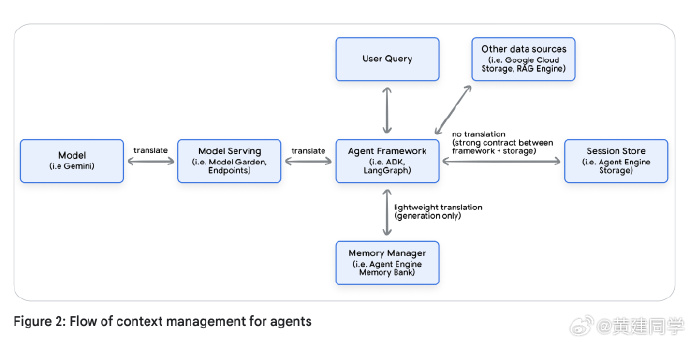
《Context Engineering: Sessions & Memory》
《Context Engineering: Sessions & Memory》,一个Agent做得好,80%看上下文管理!
这个pdf有72页,系统讲述了如何让LLM在交互中形成“状态”“个性”与“持续学习“,想做好AI Agent的别忘记深读一下这个文档。
划线点:
-
上下文工程的核心理念
传统的 Prompt Engineering 只关注如何写出一个最优提示,而 Context Engineering 则是更高维度的概念。它要求开发者在每次模型调用前,动态地拼装完整的上下文——包括系统指令、工具定义、few-shot 示例、外部检索内容、长期记忆以及当前对话历史。
白皮书中有个比喻:如果 Prompt 是食谱,那么 Context Engineering 就是备料,决定了模型能否稳定地产出理想结果。 -
Session vs. Memory
Session 是一场对话的“工作台”,保存着事件日志和临时状态;Memory 是长期的“档案柜”,从这些对话中提炼出可复用的知识。
Session 负责连贯性,Memory 负责持续性。 -
多智能体系统中的会话共享
多个 Agent 协作时,Session 的设计变得更复杂。不同框架(如 ADK、LangGraph)内部的数据结构差异较大,直接共享会导致互操作问题。
文档提出用框架无关的 Memory 层作为共享语义中枢,各 Agent 通过抽象化的记忆数据交换信息,从而实现真正的跨框架协作。 -
长上下文的管理与压缩
模型上下文窗口有限,随着会话增长,成本、延迟和注意力衰减都会出现。有三种压缩策略:
(1)保留最近 N 轮(滑动窗口);
(2)基于 token 数截断;
(3)递归摘要,用 LLM 生成对旧内容的总结。
这些方法共同目标是保留必要、舍弃冗余,让模型始终聚焦关键信息。 -
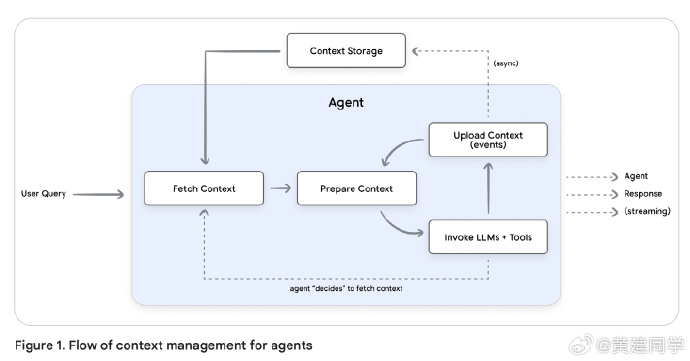
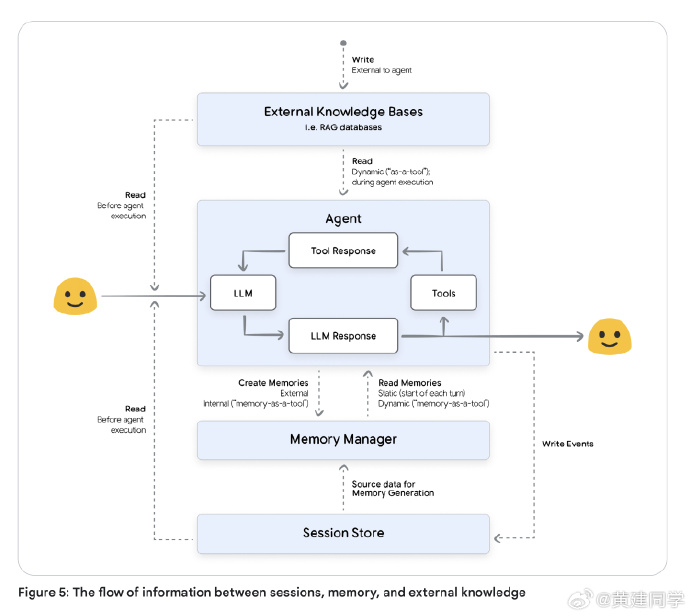
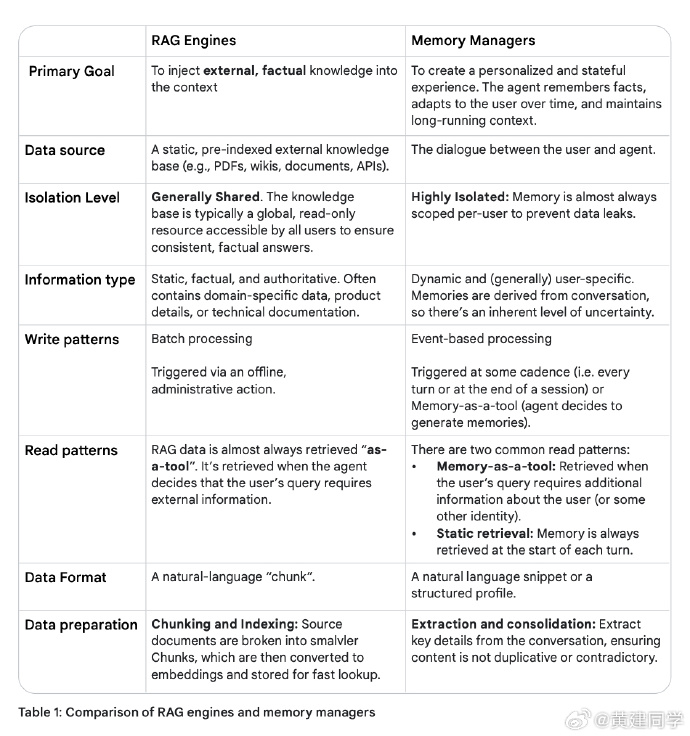
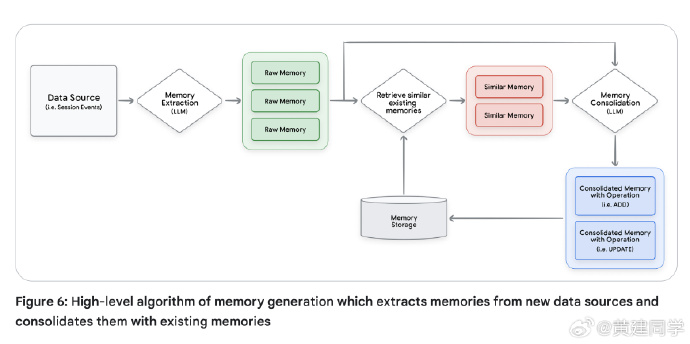
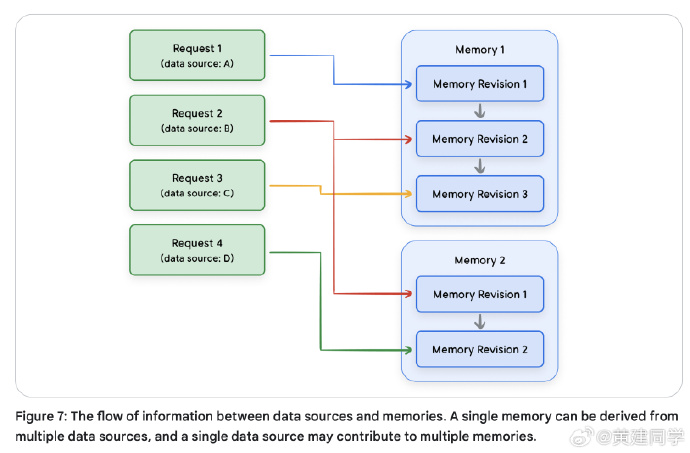
记忆系统的设计与生命周期
记忆并非简单存储,而是一套动态的 LLM 驱动工作流,涵盖提取、整合、存储、检索与遗忘(有点像一个ETL系统)。
提取阶段从原始对话中识别有意义的信息;整合阶段解决重复与冲突;存储可采用向量数据库、知识图谱或混合架构;检索阶段结合语义相似度、时间衰减与重要度评分挑选最合适的记忆。
文档还提出“遗忘”机制——旧记忆会随时间或置信度衰减被归档或删除,以保持知识库的健康。划重点:真正的智能不在于保存全部信息,而在于知道何时、为何、记什么、忘什么。一个理想的 Memory 系统,像人脑的海马体,既能在短期保持上下文,又能在长期过滤、压缩、抽象出模式。
AI Agent的设计应该把动态遗忘作为标准功能来设计,而非可有可无的能力。 -
触发策略与 Memory-as-a-Tool 模式
记忆生成可在会话结束、固定回合、实时、或用户显式命令下触发。频繁触发可保留更多细节,但计算成本高;批量触发更经济,却易失真。
白皮书提出 Memory-as-a-Tool 模式:让 Agent 自行判断何时、为何生成记忆,将“记忆何时发生”的控制权交给模型逻辑本身(划重点!)。 -
信任、来源与隐私
文档专门讨论了 Memory 的来源溯源(Provenance):每条记忆应携带来源类型、时间戳、置信度与可信层级。系统需依据来源权重解决冲突,并对个人敏感信息在写入前脱敏,确保隔离与合规。 -
RAG 与 Memory 的对比
RAG 让模型更懂世界, Memory 让模型更懂你。
前者检索外部事实,后者积累用户语境。Agent 需要二者结合,既具世界知识,又具个人连续性。

Google《Agent Quality》白皮书
我们正在从“写程序”迈向“和系统共建行为”的时代。过去,软件是我们思维的显式翻译:需求 -> 逻辑 -> 代码,代码严格执行既定规则。
而智能体不再是被动执行的对象,它们具备理解、推理、规划与自我状态管理的能力。
工程师不再是“控制每一步”,而是构建一个具备策略空间的系统,与它共同塑造行为边界、学习机制和决策流程。
白皮书关键内容:
-
传统软件 QA 已经不适合评估智能体。
普通软件像一个按步骤执行的流水线,而 Agent 像一个具备自由策略的驾驶员。它的失败往往不是崩溃,而是“看起来正常,但本质错误”的那种隐性风险。
我们要处理的事幻觉、策略偏离、概念漂移、工具调用错误等,这类错误无法用过去的单元测试框架覆盖。 -
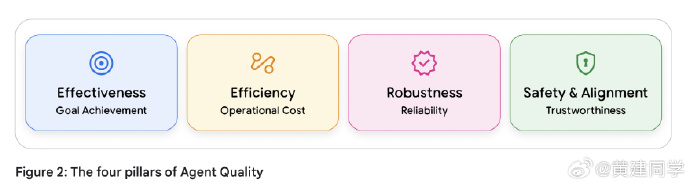
Agent 质量的“四大支柱”:效果、效率、鲁棒性与安全性。
Agent 系统的评价必须从任务完成度和用户体验开始,而不是困在“模型是否更先进”这种问题里。只有把业务目标作为起点,才不会迷失在复杂的技术细节中。
因此这四个指标不是从模型内部看,而是从“是否真正创造价值”来判断。
比如一次飞行预定 Agent,不只是“有没有成功输出”,而是看它是否步骤合理、成本可控、行为稳健、不会越界。 -
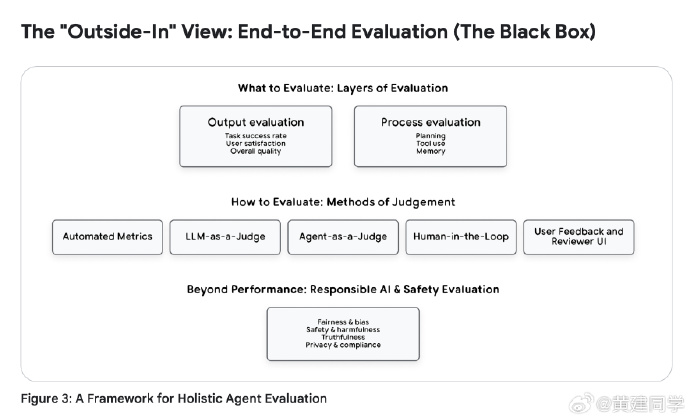
“Outside-In + Inside-Out”的评价框架。
先黑盒评估最终结果,再白盒地看每一步决策过程(trajectory)。
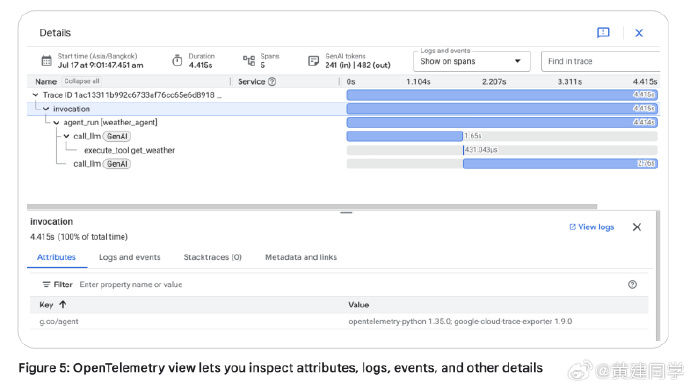
轨迹才是真相。一个最终看似正确的答案,背后的过程可能非常混乱,需要依赖可观测性基础设施来重建事实。 -
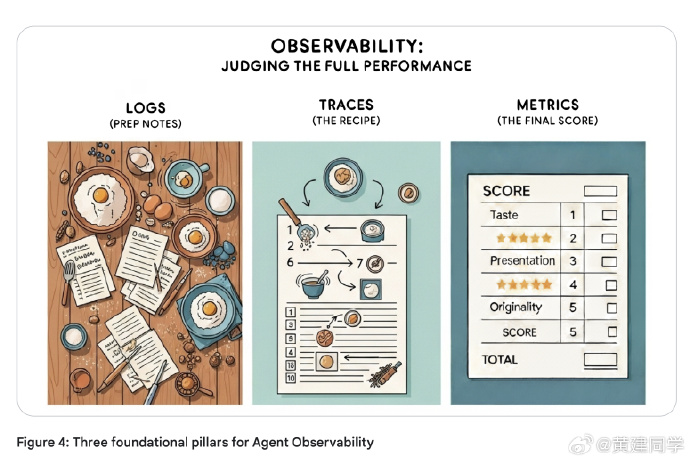
Observability:从监控走向真正的可观察。
这其中包含三大支柱:日志、追踪、指标。日志像日记,追踪是把事件串一条线,指标是聚合后的健康报告。只有具备这三者,才有能力对 Agent 做过程级别的评价。
轨迹可观测性必须从一开始就设计,不能补救。就像文档里说的:F1 赛车不会先造好车再补装传感器。Agent 的 trace、日志结构、工具调用链,需要从架构层面规划,否则后期调试会极度痛苦。 -
动态采样。
没有必要对所有请求都收集全量细粒度日志和追踪,而是对失败 100% 采样,对成功 5-10% 采样,既保持可观察性又不会压垮系统。 -
评估方式系统化:机器指标、LLM-as-a-Judge、Agent-as-a-Judge、HITL 评审、用户反馈。
尤其是 LLM/Agent-as-a-Judge,意味着我们用 AI 来评价 AI,把评估规模化、自动化,用人类做最终仲裁。
有个实用的技巧是采用“对比式 LLM-as-a-Judge”。不是让模型给回答打分,而是让它比较新旧两个版本的回答,并强制选择更好的那一个。这非常接近 A/B 测试思路,也能减少模型自身的偏见。 -
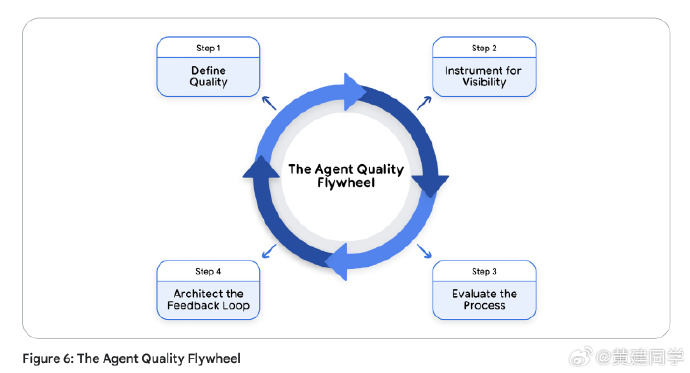
Agent 质量飞轮(Flywheel):从定义质量标准、到接入可观测性、到做过程评估、再到反馈回训练集,这是一套自我强化的循环。
最关键的是每个失败案例会被沉淀进黄金测试集,从一次性错误变成永不再犯的回归测试。
白皮书强调“每次失败都应该进入回归集”。这是一种极强的工程纪律。每一个生产环境下的失败案例,都应该作为正式的测试样例被记录下来,并持续用新版本 agent 去对比,形成不断强化的质量闭环。
白皮书讲了许多技术细节,但底层逻辑其实很简单:Agent 的本质不是函数,而是行为策略。策略的质量不能仅靠输入输出判断,还需要结合轨迹来理解。因此生产级的 Agent 框架都应该采用“可观测性优先”的架构,而非“模型优先”。另外,质量飞轮也非常重要,这也算是一种新的软件工程范式:模型驱动 + 数据回流 + 评估驱动迭代。Agent 的生命周期不再像传统软件那样依靠版本更新,而是依靠不断扩大的评估集、不断回流的数据与不断强化的轨迹判断体系。能否做好这个飞轮,将决定AI Agent能否真正走向稳定。



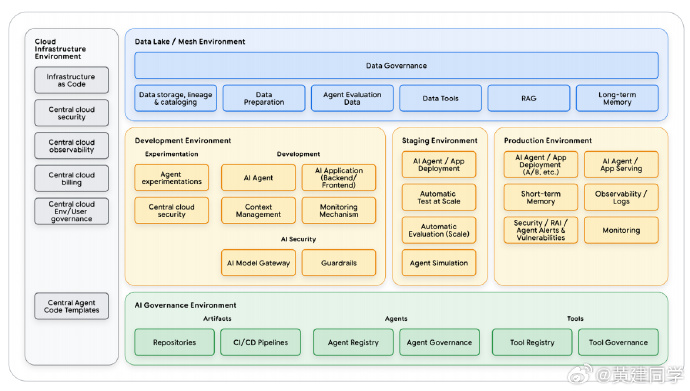
Google AI Agents 《Prototype to Production》
Google AI Agents 《Prototype to Production》,智能体开发的「最后一公里」。
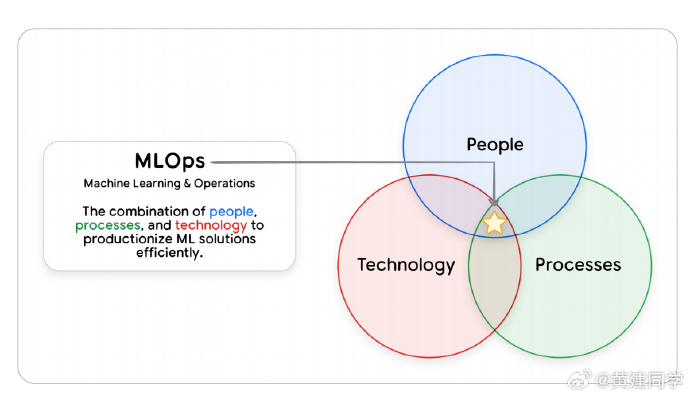
把 AI Agent 从原型推到真正的生产环境,不止是技术问题,更是工程、治理、运营三者叠加的系统性挑战。
-
把原型推到生产,核心难点不在模型,而在“可信度”
构建一个 Agent 很容易,但信任一个 Agent 很难。原型阶段很快,但真正的工程工作集中在安全、验证、监控、版本控制、CI/CD、治理等环节。如果没有这些基础设施,再聪明的 Agent 都无法上生产,甚至会带来严重业务风险。 -
生产化的基础是 Evaluation-Gated Deployment
传统软件靠单元测试,而 Agent 需要评估“行为”。白皮书提出了一个特别关键的思想:任何 Agent 的更新,都必须先经过评估门槛。
(1)手动 pre-PR 评估:适合中小团队,由工程师本地跑评估,把结果贴到 PR。
(2)自动化 Pipeline Gate:成熟团队直接把评估集成到 CI/CD,评估不达标就自动阻断部署。
重点不只是测试结果好不好,而是要观察轨迹、工具调用是否稳定、是否引入新的幻觉问题,安全防护是否生效。 -
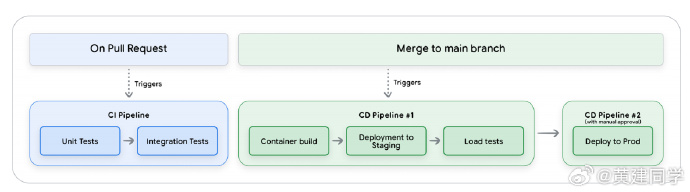
建立三阶段 CI/CD 是“最后一公里”的工程基石
整个管线分三个阶段:
(1)CI 阶段:快速检查,重点在代码、提示词、配置文件是否破坏现有行为。
(2)Staging 阶段:真实环境的集成测试、负载测试、内部试用。
(3)生产部署阶段:人工最后确认,然后把已验证过的 Staging 工件安全地推进生产。
这套流程最关键的能力是“版本可回滚”和“基于 Git 的完全可追踪变更历史”。 -
安全要从第一天开始,不是上线后补丁
Agent 因为具备推理能力,会被提示词注入、数据泄露、工具滥用等方式攻击。
(1)系统指令作为最核心的安全根。
(2)输入过滤、输出过滤、HITL 等作为执法层。
(3)红队、模拟攻击、LLM judge 安全评估作为持续保证。
这套“策略 → 执法 → 持续验证”的结构,才是长期安全的关键。 -
上线后,其实是更困难的阶段:Observe → Act → Evolve
(划重点)这里把生产中的复杂性抽象成一个循环。
(1)Observe:日志、trace、metrics,理解 agent 如何决策,而不是看黑盒输出。
(2)Act:根据观测调整限流、成本控制、熔断、异常处理等。
(3)Evolve:把线上出现的问题转成新的评估案例,提升提示词、工具、策略,然后通过 CI/CD 推回生产。
也就是说,AgentOps 的目标不是“让系统永远不出问题”,而是“让问题一旦发生就能快速闭环”。 -
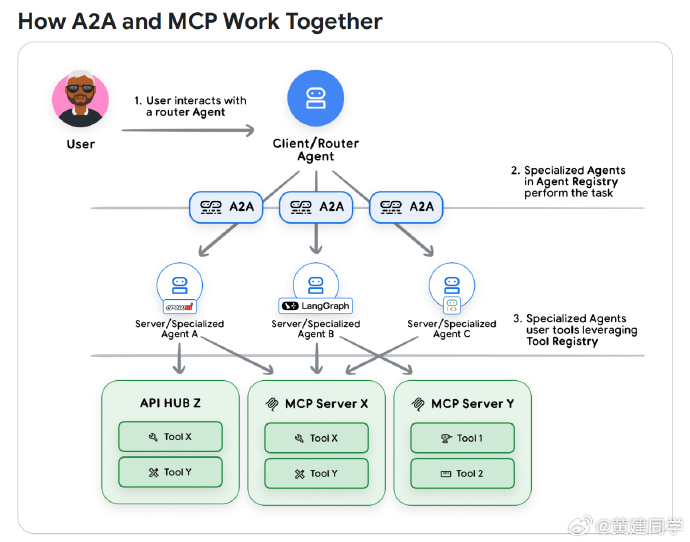
组织规模变大后,就会需要 A2A 和 MCP
MCP 负责“工具级的能力调用”,标准化工具接口;
A2A 负责“Agent 之间的协作”,让不同团队构建的 Agent 可以互相调用,实现真正的“企业 Agent 生态”。
它们不是替代关系,是分层关系。
当企业内部出现很多 Agent 时,没有标准协议就无法协作,会碎片化、重复造轮子。 -
Registry 的价值不是技术,而是规模化治理
工具注册中心(Tool Registry)和 Agent Registry 的意义在于:
(1)避免重复创建工具
(2)统一审计和权限
(3)缩短开发者搜索能力的时间
文档的观点很现实:小团队不需要,但规模大了就离不开。(听说不少大公司已经在搞这些注册中心了) -
AgentOps 真正的价值不是降低风险,而是提高迭代速度
文档最后强调:“速度是最大的价值”。
以前改一个系统可能需要几周,但 AgentOps 成熟后,基于评估驱动、CI/CD、Staging环境、可控上线、快速回滚,可以做到几小时完成一次改进。
这意味着 Agent 不再是“部署一次就放着跑”的系统,而是一套持续演化的产品。
一旦Agent开始上线,工程师们就从“写代码”的角色转变为“如何经营一个有自主性的系统”,路远且难,但一切都有章可循。





有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 18
18 0
0- 0



 已为社区贡献24条内容
已为社区贡献24条内容

所有评论(0)