AAAI 2026 Oral | 东南大学提出DOC:增强CLIP对抗鲁棒性的方向正交反攻击
本文提出了一种名为“方向正交反攻击”(DOC)的新方法,用于增强视觉-语言预训练模型(VLP)对抗对抗样本的鲁棒性。针对现有测试时反攻击(TTC)方法扰动单一的问题,DOC通过引入正交梯度增强和动量机制,生成更具多样性的反攻击扰动,有效中和多种对抗攻击。
一、导读
视觉-语言预训练模型(Vision-Language Pretraining, VLP),例如 CLIP,在多模态理解和零样本泛化任务中表现卓越,然而它们对对抗样本(即恶意添加的干扰)的敏感性,引发了对其实际可靠性的广泛关注。
目前一种称为“测试时反攻击”(Test-Time Counterattack, TTC)的防御策略,试图通过主动生成扰动将受攻击的输入“推离”危险区域。然而,由于优化目标不统一,该方法生成的扰动缺乏变化,难以应对多样化的攻击方式。
为解决这一问题,本文提出一种名为“方向正交反攻击”(Directional Orthogonal Counterattack, DOC)的新方法。该方法通过在梯度更新过程中引入正交方向与动量机制,增强反攻击扰动的多样性,从而更有效地抵消对抗性扰动的影响。
实验结果显示,DOC 在多个数据集上显著提升了模型的对抗鲁棒性,同时保持了较高的干净样本识别准确率。
二、论文基本信息

-
论文标题:Diversifying Counterattacks: Orthogonal Exploration for Robust CLIP Inference
-
作者:Chengze Jiang, Minjing Dong, Xinli Shi, Jie Gui
-
单位:东南大学、香港城市大学等
-
论文来源:AAAI-2026 Oral
-
代码链接:https://github.com/bookman233/DOC
三、主要贡献与创新
-
提出 DOC 方法,通过正交梯
-
度增强与动量更新提升反攻击多样性。
-
引入基于余弦相似度的方向敏感度评分,自适应调节反攻击强度。
-
在16个数据集上验证 DOC 显著提升对抗
-
鲁棒性,且不影响干净准确率。
-
DOC 无需训练参数,适用于多种视觉语言模型,具有良好的通用性。
四、研究方法与原理
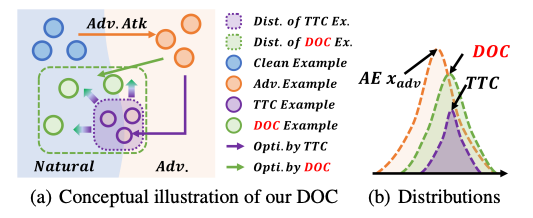
DOC 的核心思路是:在生成反攻击扰动时,不仅沿着梯度方向更新,还引入正交方向的随机扰动和动量机制,以增强扰动多样性,从而更有效地中和对抗攻击。
-
正交梯度增强(Orthogonal Gradient Augmentation)
首先计算归一化梯度:其中 。接着生成一个随机向量 ,并计算其正交分量:
最终更新方向为:
-
动量更新机制
引入动量项以平滑更新方向:反攻击扰动更新为:
-
方向敏感度评分(Directional Sensitivity Score)
对输入样本生成 个噪声版本,计算平均余弦相似度:使用 sigmoid 函数自适应调节反攻击强度:
最终扰动为 。
五、实验设计与结果分析
实验设置
使用16个数据集,包括 CIFAR-10/100、ImageNet、Caltech-101 等。攻击方法包括 PGD-10、CW 和 AutoAttack,攻击预算 。反攻击预算 ,步数为4。
对比实验
DOC 在 PGD-10 攻击下平均鲁棒准确率比 TTC 提升 **9.80%**,在 CW 攻击下提升 **7.58%**,在 AutoAttack 下提升 **4.1%**,且干净准确率保持稳定。
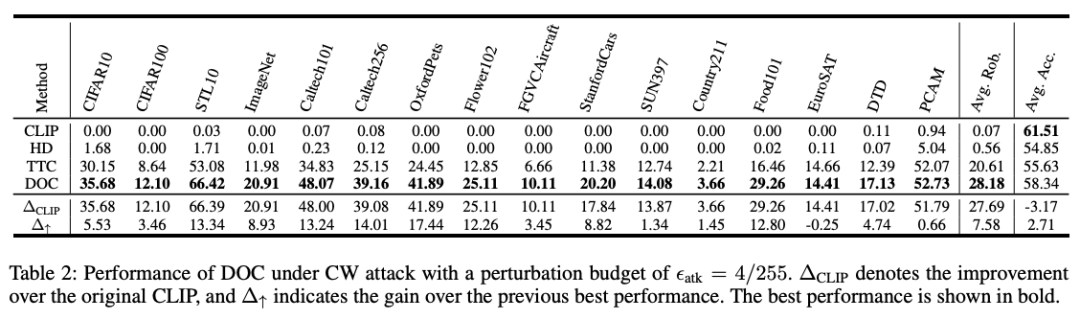
(篇幅有限,完整数据请点击原文查看)
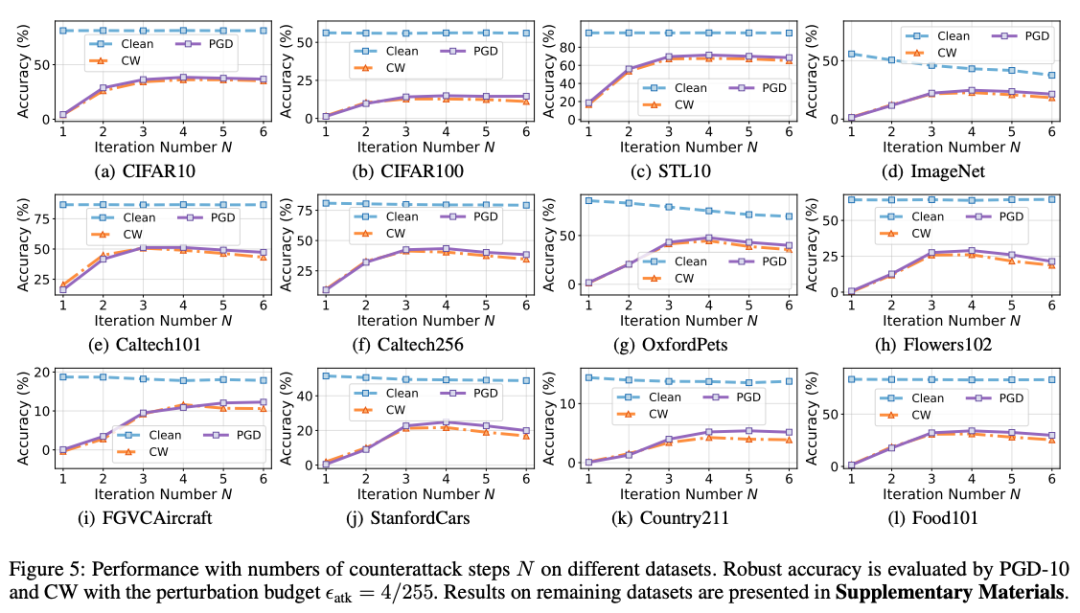
可视化对比
t-SNE 可视化显示 DOC 生成的反攻击扰动分布更分散,多样性更高,MeanCos 值更低,说明其能更好地探索扰动空间。
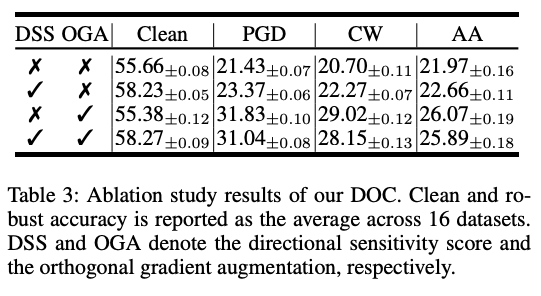
消融实验
分别移除方向敏感度评分(DSS)和正交梯度增强(OGA)后,鲁棒性均下降,说明两者均为 DOC 有效性的关键组成部分。
六、论文结论与评价
总结
DOC 通过引入正交扰动和动量机制,显著提升了反攻击的多样性,使其能更有效地中和多种对抗攻击。在16个数据集上的实验表明,DOC 在保持干净准确率的同时,显著提升了对抗鲁棒性。
评价
该方法的优点在于无需训练、参数无关、适用于多种模型,具有良好的通用性和实用性。缺点是对超参数(如正交因子 、动量因子 )较为敏感,需仔细调参。未来可探索自适应调参机制,进一步提升方法的稳定性和易用性。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 18
18 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)