即插即用涨点系列 (十二):TDCNet 详解!AAAI 2026 SOTA,重构时空特征,TDCR 差分卷积与 TDCSTA 注意力刷新移动红外小目标检测精度
本文提出TDCNet网络,通过时间差分卷积重参数化(TDCR)模块和TDC引导的时空注意力(TDCSTA)机制,有效解决移动红外小目标检测中的弱特征和背景干扰问题。TDCR在训练时采用多尺度差分分支,推理时重参数化为单一3D卷积;TDCSTA利用运动特征指导语义增强。实验在新建IRSTD-UAV数据集上达到SOTA性能。该方法计算高效,适用于视频动作识别等场景,相关代码已开源。
🔥 AI 即插即用 | 你的CV涨点模块“军火库”已开源!🔥
大家好!为了方便大家在CV科研和项目中高效涨点,我创建并维护了一个即插即用模块的GitHub代码仓库。
仓库里不仅有:
- 核心模块即插即用代码
- 论文精读总结
- 架构图深度解析
- 全文逐句翻译与应用实例
更有海量SOTA模型的创新模块汇总,致力于打造一个“AI即插即用”的百宝箱,方便大家快速实验、组合创新!
🚀 GitHub 仓库链接:https://github.com/AITricks/AITricks
觉得有帮助的话,欢迎大家 Star, Fork, PR 一键三连,共同维护!
即插即用涨点系列 (十二):TDCNet 详解!AAAI 2026 SOTA,重构时空特征,TDCR 差分卷积与 TDCSTA 注意力刷新移动红外小目标检测精度
论文原文 (Paper):https://arxiv.org/abs/2511.09352
官方代码 (Code):https://github.com/IVPLaboratory/TDCNet
论文精读:TDCNet
1. 核心思想
本文针对移动红外小目标检测(Moving IRSTD)中弱目标特征和复杂背景干扰的挑战,提出了一种名为 TDCNet 的新型网络。其核心论点在于:现有的3D卷积虽然能提取时空特征,但缺乏对时间维度运动动态的“显式感知”;而时间差分法虽能捕捉运动,却丢失了空间语义。为此,论文创新性地提出了 时间差分卷积(TDC),将时间差分操作与3D卷积融合为统一的卷积表示,并通过重参数化技术(TDCR)在推理阶段实现零额外计算成本的多尺度运动上下文建模。此外,通过 TDC引导的时空注意力机制(TDCSTA),利用TDC提取的强运动线索来指导和增强时空特征的语义表达,从而在低信杂比(SCR)场景下实现SOTA性能。
2. 背景与动机
-
文本角度总结:
移动红外小目标检测在无人机监控等领域至关重要,但面临目标微弱和背景杂波剧烈干扰的难题。现有方法主要分为两类:单帧方法(基于2D卷积)忽略了时间信息,容易产生虚警;多帧方法中,单纯的时间差分缺乏空间语义,而标准的3D卷积虽然建模了时空域,但对帧间微小的像素级变化(即运动线索)缺乏显式的归纳偏置。本文的动机是打破这种二元对立,设计一种既能像差分法那样显式捕捉运动,又能像3D卷积那样保留丰富时空特征的统一架构。 -
动机图解分析(基于 Figure 1):
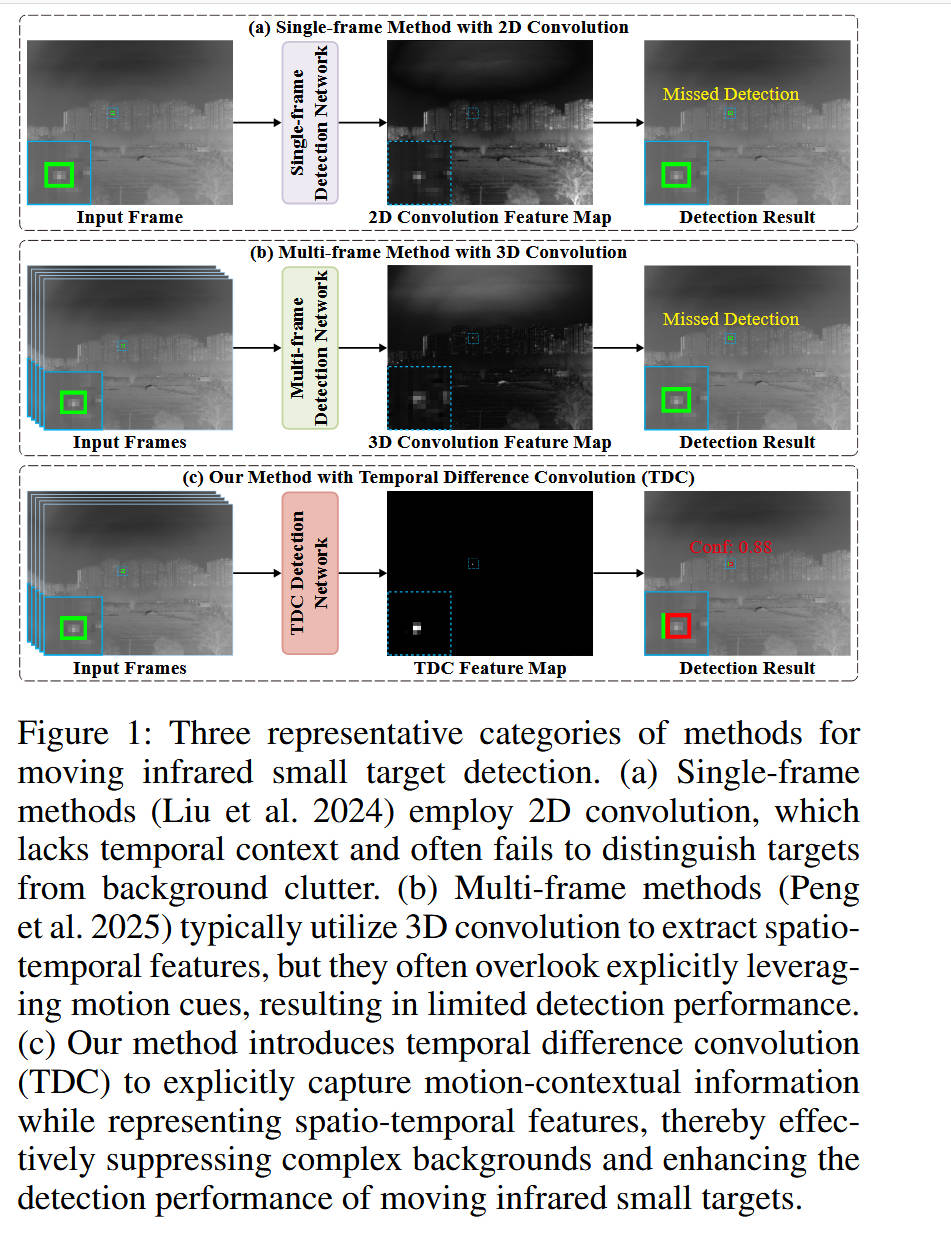
- 图表描述:Figure 1 展示了三种不同检测范式的对比。
- (a)单帧方法(2D Conv):如图所示,输入单帧图像,经过2D网络后,特征图中背景杂波依然强烈,导致目标被淹没(Missed Detection)。这说明仅靠空间特征难以区分类似目标的背景噪声。
- (b)多帧方法(3D Conv):输入多帧序列,使用标准3D卷积。虽然利用了时间信息,但特征图中目标依然不显著(Missed Detection)。这直观地揭示了标准3D卷积在提取微弱运动信号时的局限性——它“混合”了时空信息,却未“强调”变化。
- (c)本文方法(TDC):引入时间差分卷积后,特征图中背景被极大地抑制(变黑),而运动目标的响应被显著保留(Detection Result)。
- 总结:这组对比图清晰地指出了现有方法的**“语义鸿沟”(2D缺乏时间语义)和“运动感知瓶颈”**(3D缺乏显式运动建模),引出了本文利用TDC进行显式运动建模并抑制静态背景的核心解决思路。
3. 主要贡献点
-
[贡献点 1]:提出了TDCNet网络架构
提出了一种全新的移动红外小目标检测网络。该网络并非简单地堆叠模块,而是构建了一个三流架构(2D空间流、3D时空流、TDC运动流),专门用于在抑制复杂背景的同时有效地提取和增强时空特征。 -
[贡献点 2]:设计了时间差分卷积重参数化(TDCR)模块
这是本文的核心算子创新。作者设计了短时(S-TDC)、中时(M-TDC)和长时(L-TDC)三个并行分支,分别捕捉不同时间跨度的运动依赖。关键在于,这些分支在训练时独立工作,但在推理时通过重参数化技术等效融合为一个单一的3D卷积核。这使得模型具备了显式的多尺度差分能力,却保持了与普通3D卷积相同的推理计算量。 -
[贡献点 3]:提出了TDC引导的时空注意力(TDCSTA)机制
设计了一种新颖的交叉注意力机制。不同于常规的特征融合,该模块利用 TDC Backbone 提取的特征(具备强运动感知、高信杂比)作为 Query,去查询和细化 3D Backbone(时空特征)和 2D Backbone(空间特征)中的语义信息。这种设计有效地建立了运动线索与全局语义之间的依赖关系,指导网络聚焦于关键的目标区域。 -
[贡献点 4]:构建了IRSTD-UAV基准数据集
为了弥补现有数据集场景单一的缺陷,作者构建了一个包含15,106帧真实红外图像的新数据集。该数据集涵盖了多种类型的无人机目标和复杂的动态背景(如城市、树木、云层),为该领域提供了更具挑战性的评估基准。
4. 方法细节(最重要)
-
整体网络架构(基于 Figure 2)
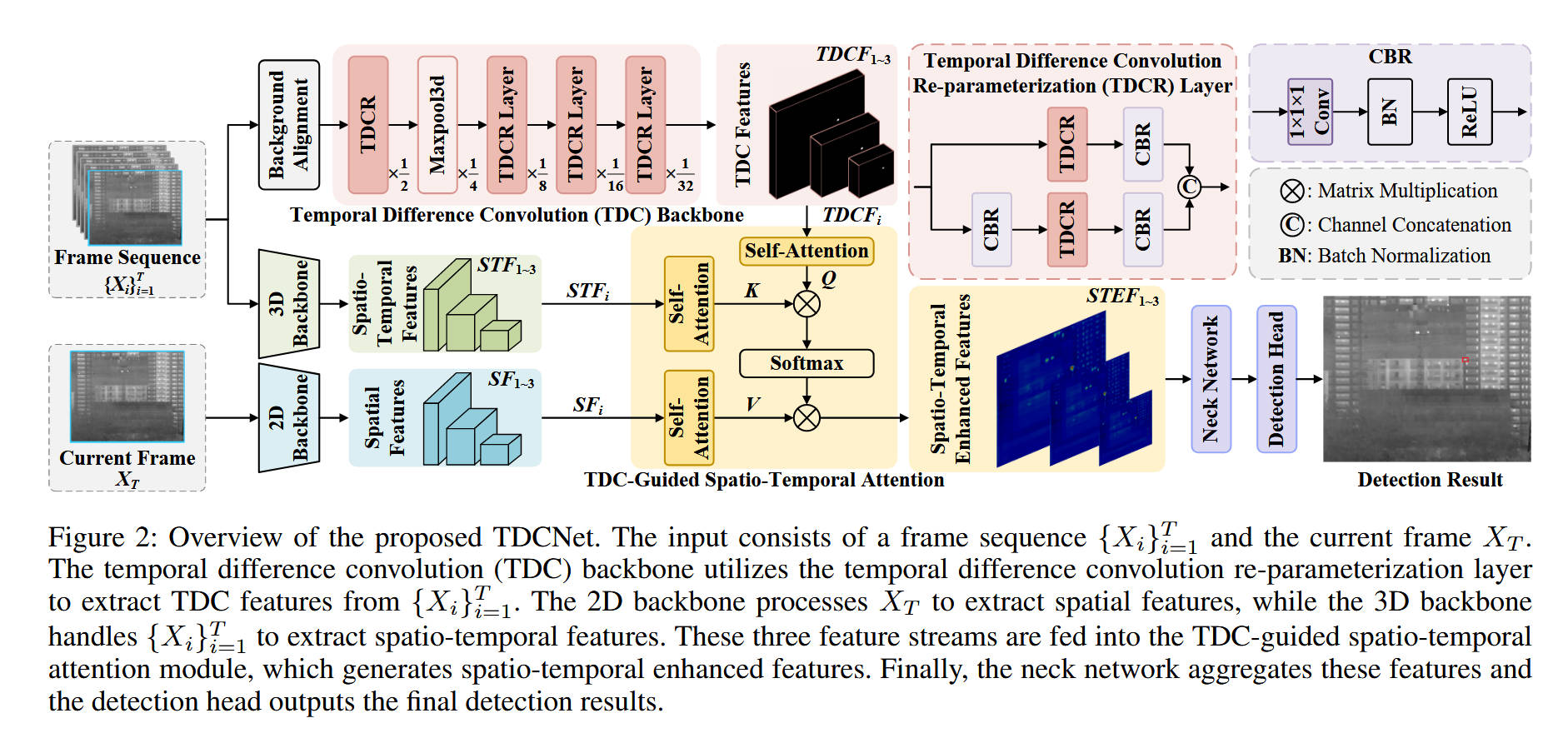
- 输入流:网络接收一个帧序列和当前帧作为输入。
- 骨干网络(Backbones):包含三条并行的路径:
- TDC Backbone:核心路径,由堆叠的 TDCR 层组成,专门从帧序列中提取显式的运动特征(TDC Features)。在此之前有背景对齐操作。
- 3D Backbone:处理帧序列,提取常规的时空特征(Spatio-Temporal Features)。
- 2D Backbone:仅处理当前帧,提取细粒度的空间特征(Spatial Features)。
- 特征融合(TDCSTA):上述三路特征被送入 TDC-Guided Spatio-Temporal Attention 模块。
- 输出层:增强后的特征(STEF)进入 Neck 网络进行聚合,最后由 Detection Head 输出检测结果。
-
核心创新模块详解
-
模块 A:时间差分卷积重参数化 (TDCR) 模块(基于 Figure 3 & Figure 4)
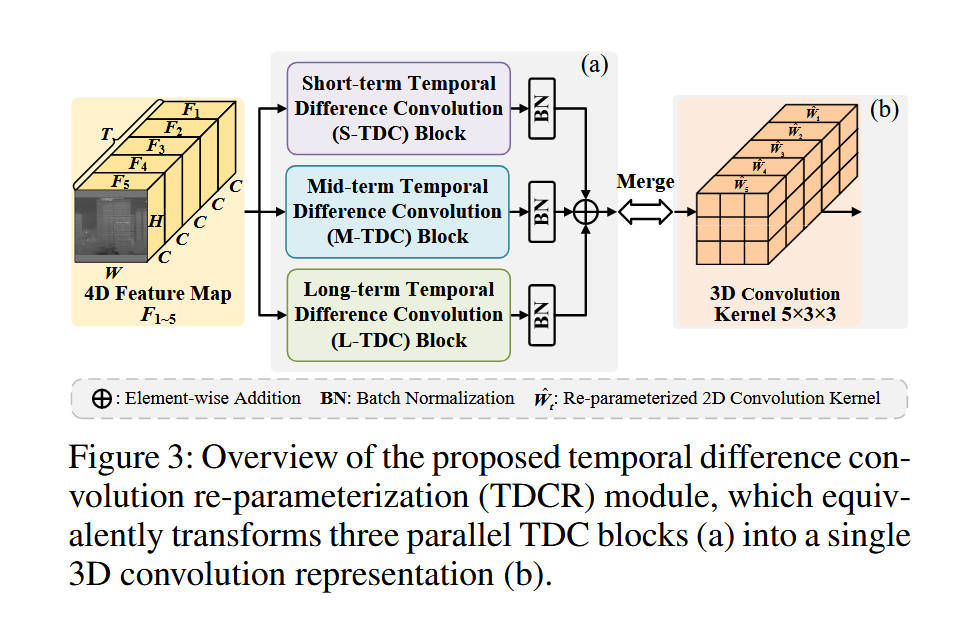
-
内部结构:该模块在训练阶段由三个并行的分支组成:S-TDC(短时)、M-TDC(中时)和 L-TDC(长时)。
-
数据流动与设计目的:
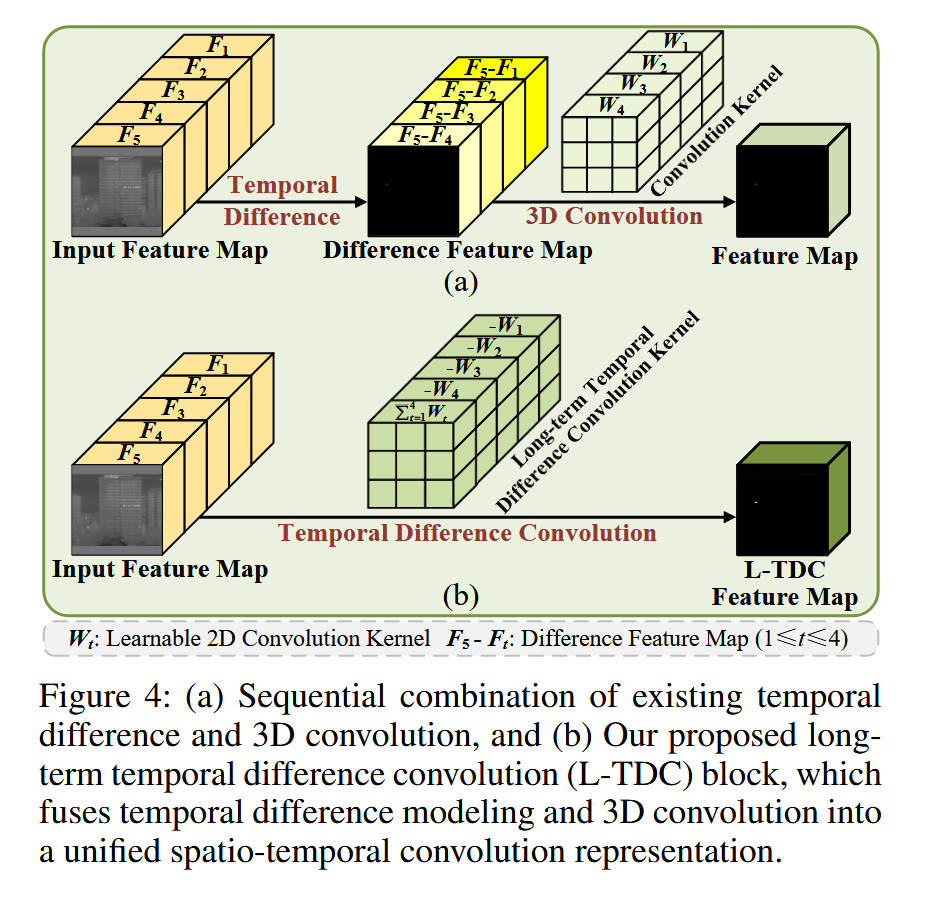
- 以 L-TDC 为例(Figure 4b),它并不进行显式的减法操作。而是通过精心设计的卷积核权重配置,将“当前帧与所有过去帧的差分”这一数学操作内嵌到卷积运算中。
- S-TDC 关注相邻帧差异,捕捉快速运动。
- M-TDC 关注间隔帧差异,捕捉中速运动。
-
重参数化机制:在推理阶段,利用卷积的线性特性,这三个分支(包括BN层)的参数被合并为一个标准的 5 × 3 × 3 5 \times 3 \times 3 5×3×3 3D卷积核。这实现了“训练时多尺度差分增强,推理时单卷积高效计算”。
-
-
模块 B:TDC引导的时空注意力 (TDCSTA) 模块(基于 Figure 2)
- 内部结构:包含自注意力(Self-Attention)和交叉注意力(Cross-Attention)两个阶段。
- 数据流动:
- 首先,TDC特征 ( T D C F TDCF TDCF)、时空特征 ( S T F STF STF) 和空间特征 ( S F SF SF) 分别通过自注意力机制增强自身的语义表达。
- 进入交叉注意力阶段:这是关键设计。将 TDCF 作为 Query (Q),而将 STF 作为 Key (K),SF 作为 Value (V)。(核心逻辑是用“运动特征”去检索“时空/空间特征”中的相关部分)。
- 设计理念:由于 TDCF 经过差分卷积处理,背景杂波已被大幅抑制,目标区域显著(即“哪里有目标”的信息最准)。利用它作为 Query,可以指导网络从含噪量较大的 STF 和 SF 中准确地提取出目标的详细外观和时空信息,实现“运动指导语义”的特征细化。
-
-
理念与机制总结
本文的核心理念是 “显式差分卷积化”。传统的差分是 I n p u t t − I n p u t t − 1 Input_t - Input_{t-1} Inputt−Inputt−1,是无参数的预处理。本文提出的 TDC 将其转化为 W ∗ ( I n p u t t − I n p u t t − 1 ) W * (Input_t - Input_{t-1}) W∗(Inputt−Inputt−1),并进一步重构为 W ′ ∗ I n p u t S e q u e n c e W' * Input_{Sequence} W′∗InputSequence。- 公式解读:论文展示了如何通过学习一组特定的权重,使得卷积操作的输出等价于对“差分特征图”的卷积。
- 工作机制:这种机制赋予了卷积核“并在”时空域中直接感知“变化量”的能力,强行引入了由运动产生的归纳偏置,从而在特征提取的早期阶段就有效地过滤掉静态背景。
-
图解总结
论文的设计通过图解展示了完美的协同工作:TDCR模块(Figure 3) 解决了“如何高效提取纯净运动特征”的问题(对应解决 Figure 1 中背景干扰大的痛点);TDCSTA模块(Figure 2) 解决了“如何利用运动特征找回丢失的细节”的问题。两者结合,前者负责“抑制背景”,后者负责“增强目标”,共同实现了复杂背景下的高灵敏度检测。
5. 即插即用模块的作用
本文提出的创新点具有很强的通用性,可作为即插即用模块应用于多种视频分析任务:
-
TDCR (Temporal Difference Convolution Re-parameterization) 模块:
- 适用场景:任何基于3D卷积或视频序列的特征提取任务,特别是对运动敏感但计算资源受限的场景。
- 具体应用:
- 视频动作识别:替换现有的 C3D 或 (2+1)D 卷积层,增强网络对细微动作(如手势识别)的捕捉能力,且不增加推理延时。
- 视频显著性目标检测:用于在动态背景下快速定位移动的前景对象。
- 视频异常检测:利用其对运动模式的敏感性,检测监控视频中的异常运动事件(如突然奔跑、跌倒)。
-
TDCSTA (TDC-Guided Spatio-Temporal Attention) 机制:
- 适用场景:多模态或多流网络架构,其中一个流具有高信噪比(如运动流、深度流)但语义弱,另一个流语义强但噪声大。
- 具体应用:
- RGB-红外/RGB-热成像 融合跟踪:利用红外流(对热源敏感)作为 Query,指导 RGB 流(纹理丰富)的特征提取,提高全天候跟踪性能。
- 视频去雨/去雾:利用差分特征作为 Query,指导网络关注雨滴/雾气的动态区域,从而更精准地恢复背景细节。
6. 即插即用模块
"""
Collection of plug-and-play modules distilled from the original TDCNet
implementation. These modules correspond to the key building blocks shown
across Figures 1-4 of the paper:
- Temporal Difference Convolution (TDC) block
- Temporal Difference Convolution Re-parameterization (TDCR / RepConv3D)
- TDC-guided Self-Attention and Cross-Attention modules
They are copied from the source files under ``model/TDCNet`` so they can be
imported independently wherever lightweight reuse is needed.
"""
from functools import reduce
from operator import mul
import time
import torch
import torch.nn as nn
import torch.nn.functional as F
# ---------------------------------------------------------------------------
# Temporal Difference Convolution (Figure 4)
# ---------------------------------------------------------------------------
class TDC(nn.Module):
def __init__(
self,
in_channels,
out_channels,
kernel_size=(5, 3, 3),
stride=1,
padding=(2, 1, 1),
groups=1,
bias=False,
step=1,
):
super().__init__()
self.conv = nn.Conv3d(
in_channels,
out_channels,
kernel_size=kernel_size,
stride=stride,
padding=padding,
groups=groups,
bias=bias,
)
self.step = step
self.groups = groups
def get_time_gradient_weight(self):
weight = self.conv.weight
kT, kH, kW = weight.shape[2:]
grad_weight = torch.zeros_like(weight, device=weight.device, dtype=weight.dtype)
if kT == 5:
if self.step == -1:
grad_weight[:, :, :, :, :] = -weight[:, :, :, :, :]
grad_weight[:, :, 4, :, :] = (
weight[:, :, 0, :, :]
+ weight[:, :, 1, :, :]
+ weight[:, :, 2, :, :]
+ weight[:, :, 3, :, :]
+ weight[:, :, 4, :, :]
)
elif self.step == 1:
grad_weight[:, :, 4, :, :] = weight[:, :, 4, :, :]
grad_weight[:, :, 3, :, :] = weight[:, :, 3, :, :] - weight[:, :, 4, :, :]
grad_weight[:, :, 2, :, :] = weight[:, :, 2, :, :] - weight[:, :, 3, :, :]
grad_weight[:, :, 1, :, :] = weight[:, :, 1, :, :] - weight[:, :, 2, :, :]
grad_weight[:, :, 0, :, :] = -weight[:, :, 1, :, :]
elif self.step == 2:
grad_weight[:, :, 4, :, :] = weight[:, :, 4, :, :]
grad_weight[:, :, 3, :, :] = weight[:, :, 3, :, :]
grad_weight[:, :, 2, :, :] = weight[:, :, 2, :, :] - weight[:, :, 4, :, :]
grad_weight[:, :, 1, :, :] = -weight[:, :, 3, :, :]
grad_weight[:, :, 0, :, :] = -weight[:, :, 2, :, :]
else:
grad_weight = weight
bias = self.conv.bias
if bias is None:
bias = torch.zeros(weight.shape[0], device=weight.device, dtype=weight.dtype)
return grad_weight, bias
def forward(self, x):
weight, bias = self.get_time_gradient_weight()
x_diff = F.conv3d(
x,
weight,
bias,
stride=self.conv.stride,
groups=self.groups,
padding=self.conv.padding,
)
return x_diff
# ---------------------------------------------------------------------------
# Temporal Difference Convolution Re-parameterization (Figure 3)
# ---------------------------------------------------------------------------
class RepConv3D(nn.Module):
def __init__(
self,
in_channels,
out_channels,
kernel_size=(5, 3, 3),
stride=1,
padding=(2, 1, 1),
groups=1,
deploy=False,
):
super(RepConv3D, self).__init__()
self.deploy = deploy
self.in_channels = in_channels
self.out_channels = out_channels
self.stride = stride
self.groups = groups
if self.deploy:
self.conv_reparam = nn.Conv3d(
in_channels,
out_channels,
kernel_size,
stride,
padding,
groups=groups,
bias=True,
)
else:
self.l_tdc = nn.Sequential(
TDC(
in_channels,
out_channels,
kernel_size,
stride,
padding,
groups=groups,
bias=False,
step=-1,
),
nn.BatchNorm3d(out_channels),
)
self.s_tdc = nn.Sequential(
TDC(
in_channels,
out_channels,
kernel_size,
stride,
padding,
groups=groups,
bias=False,
step=1,
),
nn.BatchNorm3d(out_channels),
)
self.m_tdc = nn.Sequential(
TDC(
in_channels,
out_channels,
kernel_size,
stride,
padding,
groups=groups,
bias=False,
step=2,
),
nn.BatchNorm3d(out_channels),
)
def forward(self, x):
if self.deploy:
out = F.relu(self.conv_reparam(x))
else:
out = self.s_tdc(x) + self.m_tdc(x) + self.l_tdc(x)
out = F.relu(out)
return out
def get_equivalent_kernel_bias(self):
kernel_s_tdc, bias_s_tdc = self._fuse_conv_bn(self.s_tdc)
kernel_m_tdc, bias_m_tdc = self._fuse_conv_bn(self.m_tdc)
kernel_l_tdc, bias_l_tdc = self._fuse_conv_bn(self.l_tdc)
kernel = kernel_s_tdc + kernel_m_tdc + kernel_l_tdc
bias = bias_s_tdc + bias_m_tdc + bias_l_tdc
return kernel, bias
def switch_to_deploy(self):
if self.deploy:
return
kernel, bias = self.get_equivalent_kernel_bias()
self.conv_reparam = nn.Conv3d(
self.in_channels,
self.out_channels,
(5, 3, 3),
self.stride,
(2, 1, 1),
groups=self.groups,
bias=True,
)
self.conv_reparam.weight.data = kernel
self.conv_reparam.bias.data = bias
self.deploy = True
del self.s_tdc
del self.m_tdc
del self.l_tdc
@staticmethod
def _fuse_conv_bn(branch):
if branch is None:
return 0, 0
def find_conv(module):
if isinstance(module, nn.Conv3d):
return module
for child in module.children():
conv = find_conv(child)
if conv is not None:
return conv
return None
conv = find_conv(branch[0])
bn = branch[1]
if hasattr(branch[0], "get_time_gradient_weight"):
w, bias = branch[0].get_time_gradient_weight()
else:
w = conv.weight
if conv.bias is not None:
bias = conv.bias
else:
bias = torch.zeros_like(bn.running_mean)
mean = bn.running_mean
var_sqrt = torch.sqrt(bn.running_var + bn.eps)
gamma = bn.weight
beta = bn.bias
w = w * (gamma / var_sqrt).reshape(-1, 1, 1, 1, 1)
bias = (bias - mean) / var_sqrt * gamma + beta
return w, bias
# ---------------------------------------------------------------------------
# TDC-Guided Spatio-Temporal Attention (Figure 2)
# ---------------------------------------------------------------------------
class WindowAttention3D(nn.Module):
def __init__(
self,
dim,
window_size,
num_heads,
qkv_bias=True,
qk_scale=None,
attn_drop=0.0,
proj_drop=0.0,
):
super().__init__()
self.dim = dim
self.window_size = window_size # (T, H, W)
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
self.relative_position_bias_table = nn.Parameter(
torch.zeros(
(2 * window_size[0] - 1)
* (2 * window_size[1] - 1)
* (2 * window_size[2] - 1),
num_heads,
)
)
coords_t = torch.arange(self.window_size[0])
coords_h = torch.arange(self.window_size[1])
coords_w = torch.arange(self.window_size[2])
coords = torch.stack(torch.meshgrid(coords_t, coords_h, coords_w, indexing="ij"))
coords_flatten = torch.flatten(coords, 1)
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :]
relative_coords = relative_coords.permute(1, 2, 0).contiguous()
relative_coords[:, :, 0] += self.window_size[0] - 1
relative_coords[:, :, 1] += self.window_size[1] - 1
relative_coords[:, :, 2] += self.window_size[2] - 1
relative_coords[:, :, 0] *= (
2 * self.window_size[1] - 1
) * (2 * self.window_size[2] - 1)
relative_coords[:, :, 1] *= 2 * self.window_size[2] - 1
relative_position_index = relative_coords.sum(-1)
self.register_buffer("relative_position_index", relative_position_index)
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
self.softmax = nn.Softmax(dim=-1)
nn.init.trunc_normal_(self.relative_position_bias_table, std=0.02)
def forward(self, x, k=None, v=None, mask=None):
B_, N, C = x.shape
if k is None or v is None:
qkv = (
self.qkv(x)
.reshape(B_, N, 3, self.num_heads, C // self.num_heads)
.permute(2, 0, 3, 1, 4)
)
q, k, v = qkv[0], qkv[1], qkv[2]
else:
q = x.reshape(B_, N, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3)
k = k.reshape(B_, N, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3)
v = v.reshape(B_, N, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3)
q = q * self.scale
attn = q @ k.transpose(-2, -1)
relative_position_bias = self.relative_position_bias_table[
self.relative_position_index[:N, :N].reshape(-1)
].reshape(N, N, -1)
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous()
attn = attn + relative_position_bias.unsqueeze(0)
if mask is not None:
nW = mask.shape[0]
attn = attn.view(B_ // nW, nW, self.num_heads, N, N) + mask.unsqueeze(1).unsqueeze(0)
attn = attn.view(-1, self.num_heads, N, N)
attn = self.softmax(attn)
else:
attn = self.softmax(attn)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B_, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
def window_partition(x, window_size):
B, T, H, W, C = x.shape
window_size = list(window_size)
if T < window_size[0]:
window_size[0] = T
if H < window_size[1]:
window_size[1] = H
if W < window_size[2]:
window_size[2] = W
x = x.view(
B,
T // window_size[0] if window_size[0] > 0 else 1,
window_size[0],
H // window_size[1] if window_size[1] > 0 else 1,
window_size[1],
W // window_size[2] if window_size[2] > 0 else 1,
window_size[2],
C,
)
windows = (
x.permute(0, 1, 3, 5, 2, 4, 6, 7)
.contiguous()
.view(-1, reduce(mul, window_size), C)
)
return windows
def window_reverse(windows, window_size, B, T, H, W):
x = windows.view(
B,
T // window_size[0],
H // window_size[1],
W // window_size[2],
window_size[0],
window_size[1],
window_size[2],
-1,
)
x = x.permute(0, 1, 4, 2, 5, 3, 6, 7).contiguous().view(B, T, H, W, -1)
return x
def get_window_size(x_size, window_size, shift_size=None):
use_window_size = list(window_size)
if shift_size is not None:
use_shift_size = list(shift_size)
for i in range(len(x_size)):
if x_size[i] <= window_size[i]:
use_window_size[i] = x_size[i]
if shift_size is not None:
use_shift_size[i] = 0
if shift_size is None:
return tuple(use_window_size)
else:
return tuple(use_window_size), tuple(use_shift_size)
class SelfAttention(nn.Module):
def __init__(
self,
dim,
window_size=(2, 8, 8),
num_heads=8,
qkv_bias=True,
qk_scale=None,
attn_drop=0.0,
proj_drop=0.0,
use_shift=False,
shift_size=None,
mlp_ratio=2.0,
norm_layer=nn.LayerNorm,
):
super().__init__()
self.dim = dim
self.window_size = window_size
self.num_heads = num_heads
self.use_shift = use_shift
self.shift_size = (
shift_size
if shift_size is not None
else tuple([w // 2 for w in window_size]) if use_shift else tuple([0] * len(window_size))
)
self.attn1 = WindowAttention3D(
dim,
window_size=self.window_size,
num_heads=num_heads,
qkv_bias=qkv_bias,
qk_scale=qk_scale,
attn_drop=attn_drop,
proj_drop=proj_drop,
)
self.attn2 = WindowAttention3D(
dim,
window_size=self.window_size,
num_heads=num_heads,
qkv_bias=qkv_bias,
qk_scale=qk_scale,
attn_drop=attn_drop,
proj_drop=proj_drop,
)
self.norm1 = norm_layer(dim)
self.norm2 = norm_layer(dim)
self.norm3 = norm_layer(dim)
self.norm4 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp1 = nn.Sequential(
nn.Linear(dim, mlp_hidden_dim),
nn.GELU(),
nn.Linear(mlp_hidden_dim, dim),
)
self.mlp2 = nn.Sequential(
nn.Linear(dim, mlp_hidden_dim),
nn.GELU(),
nn.Linear(mlp_hidden_dim, dim),
)
def create_mask(self, x_shape, device):
B, T, H, W, C = x_shape
img_mask = torch.zeros((1, T, H, W, 1), device=device)
cnt = 0
t_slices = (
slice(0, -self.window_size[0]),
slice(-self.window_size[0], -self.shift_size[0]),
slice(-self.shift_size[0], None),
)
h_slices = (
slice(0, -self.window_size[1]),
slice(-self.window_size[1], -self.shift_size[1]),
slice(-self.shift_size[1], None),
)
w_slices = (
slice(0, -self.window_size[2]),
slice(-self.window_size[2], -self.shift_size[2]),
slice(-self.shift_size[2], None),
)
for t in t_slices:
for h in h_slices:
for w in w_slices:
img_mask[:, t, h, w, :] = cnt
cnt += 1
mask_windows = window_partition(img_mask, self.window_size)
mask_windows = mask_windows.squeeze(-1)
attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2)
attn_mask = attn_mask.masked_fill(attn_mask != 0, float(-100.0)).masked_fill(
attn_mask == 0, float(0.0)
)
return attn_mask
def forward(self, x):
B, T, H, W, C = x.shape
window_size, shift_size = get_window_size((T, H, W), self.window_size, self.shift_size)
shortcut = x
x = self.norm1(x)
pad_t = (window_size[0] - T % window_size[0]) % window_size[0]
pad_h = (window_size[1] - H % window_size[1]) % window_size[1]
pad_w = (window_size[2] - W % window_size[2]) % window_size[2]
x = F.pad(x, (0, 0, 0, pad_w, 0, pad_h, 0, pad_t))
shortcut = F.pad(shortcut, (0, 0, 0, pad_w, 0, pad_h, 0, pad_t))
_, Tp, Hp, Wp, _ = x.shape
x_windows = window_partition(x, window_size)
attn_windows = self.attn1(x_windows, mask=None)
attn_windows = attn_windows.view(-1, *(window_size + (C,)))
x = window_reverse(attn_windows, window_size, B, Tp, Hp, Wp)
x = shortcut + x
x = x + self.mlp1(self.norm2(x))
shortcut = x
x = self.norm3(x)
if self.use_shift and any(i > 0 for i in shift_size):
shifted_x = torch.roll(
x, shifts=(-shift_size[0], -shift_size[1], -shift_size[2]), dims=(1, 2, 3)
)
attn_mask = self.create_mask((B, Tp, Hp, Wp, C), x.device)
x_windows = window_partition(shifted_x, window_size)
attn_windows = self.attn2(x_windows, mask=attn_mask)
attn_windows = attn_windows.view(-1, *(window_size + (C,)))
shifted_x = window_reverse(attn_windows, window_size, B, Tp, Hp, Wp)
x = torch.roll(
shifted_x, shifts=(shift_size[0], shift_size[1], shift_size[2]), dims=(1, 2, 3)
)
if pad_t > 0:
x = x[:, :T, :, :, :]
shortcut = shortcut[:, :T, :, :, :]
if pad_h > 0:
x = x[:, :, :H, :, :]
shortcut = shortcut[:, :, :H, :, :]
if pad_w > 0:
x = x[:, :, :, :W, :]
shortcut = shortcut[:, :, :, :W, :]
x = shortcut + x
x = x + self.mlp2(self.norm4(x))
return x
class CrossAttention(nn.Module):
def __init__(
self,
dim,
window_size=(2, 8, 8),
num_heads=8,
qkv_bias=True,
qk_scale=None,
attn_drop=0.0,
proj_drop=0.0,
mlp_ratio=2.0,
norm_layer=nn.LayerNorm,
):
super().__init__()
self.dim = dim
self.window_size = window_size
self.num_heads = num_heads
self.norm1_q = norm_layer(dim)
self.norm1_k = norm_layer(dim)
self.norm1_v = norm_layer(dim)
self.attn = WindowAttention3D(
dim,
window_size=self.window_size,
num_heads=num_heads,
qkv_bias=qkv_bias,
qk_scale=qk_scale,
attn_drop=attn_drop,
proj_drop=proj_drop,
)
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = nn.Sequential(
nn.Linear(dim, mlp_hidden_dim),
nn.GELU(),
nn.Linear(mlp_hidden_dim, dim),
)
def forward(self, q, k, v):
B, T, H, W, C = q.shape
window_size = get_window_size((T, H, W), self.window_size)
shortcut = v
q = self.norm1_q(q)
k = self.norm1_k(k)
v = self.norm1_v(v)
pad_t = (window_size[0] - T % window_size[0]) % window_size[0]
pad_h = (window_size[1] - H % window_size[1]) % window_size[1]
pad_w = (window_size[2] - W % window_size[2]) % window_size[2]
q = F.pad(q, (0, 0, 0, pad_w, 0, pad_h, 0, pad_t))
k = F.pad(k, (0, 0, 0, pad_w, 0, pad_h, 0, pad_t))
v = F.pad(v, (0, 0, 0, pad_w, 0, pad_h, 0, pad_t))
_, Tp, Hp, Wp, _ = q.shape
q_windows = window_partition(q, window_size)
k_windows = window_partition(k, window_size)
v_windows = window_partition(v, window_size)
attn_windows = self.attn(q_windows, k_windows, v_windows)
attn_windows = attn_windows.view(-1, *(window_size + (C,)))
shifted_x = window_reverse(attn_windows, window_size, B, Tp, Hp, Wp)
x = shifted_x
if pad_t > 0:
x = x[:, :T, :, :, :]
if pad_h > 0:
x = x[:, :, :H, :, :]
if pad_w > 0:
x = x[:, :, :, :W, :]
x = shortcut + x
x = x + self.mlp(self.norm2(x))
return x
# ---------------------------------------------------------------------------
# Simple benchmark entry point
# ---------------------------------------------------------------------------
def _benchmark_module(name, module, *inputs, warmup=5, iters=20):
module.eval()
with torch.no_grad():
for _ in range(warmup):
module(*inputs)
start = time.time()
for _ in range(iters):
module(*inputs)
end = time.time()
avg = (end - start) / iters * 1000
print(f"{name}: {avg:.3f} ms/iter over shape {[tuple(i.shape) for i in inputs]}")
if __name__ == "__main__":
torch.manual_seed(0)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
dummy_video = torch.randn(1, 64, 5, 32, 32).to(device)
rep = RepConv3D(64, 128).to(device)
_benchmark_module("RepConv3D", rep, dummy_video)
# Attention modules expect [B, T, H, W, C]
dummy_feat = torch.randn(1, 4, 16, 16, 128).to(device)
sa = SelfAttention(128, window_size=(2, 4, 4), num_heads=4, use_shift=True).to(device)
_benchmark_module("SelfAttention", sa, dummy_feat)
ca = CrossAttention(128, window_size=(2, 4, 4), num_heads=4).to(device)
_benchmark_module("CrossAttention", ca, dummy_feat, dummy_feat, dummy_feat)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 21
21 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)