Kubernetes 资源清单-生命周期
本文介绍了Kubernetes中容器的生命周期管理,重点分析了初始化容器(initC)和主容器(mainC)的特性。initC具有线性执行、阻塞主容器和临时性特点,通过实验展示了initC的阻塞特性及其在服务依赖检查中的应用。主容器则具有并行启动和长期运行特性,支持PostStart和PreStop钩子。文章详细讲解了三种探针(启动探针、就绪探针和存活探针)的作用机制,并通过实验演示了就绪探针的工

生命周期
initC
initC 容器
- 线性执行
- Init 容器会按顺序(一个接一个)运行,只有当前一个 Init 容器**成功退出(exit code 0)**后,下一个 Init 容器才会启动。如果任何一个 Init 容器失败,Pod 会根据 restartPolicy 重启(默认是 Always),导致所有 Init 容器重新执行。
- 阻塞主容器
- Pod 的 主容器(main containers) 会在所有 Init 容器成功完成后才会启动。如 nginx、php、mysql 三个容器在一个 pod 里,那他们的执行顺序应该是 mysql 在前, 其它两个在后,因为如果前后端都启动好了,用户操作时候无法与数据库进行交互,就会出问题,所以可以在 initC 里做探测,mysql 启动后在启动其它容器
- 临时性
- initC 不会长时间存在,它只在初始化阶段,可以用来操作一个危险的操作,因为它运行完就销毁,相对安全
mainC
主容器
- 并行启动
- 例如,一个 Pod 里有 nginx 和 php-fpm 两个主容器,它们会同时启动
- 长期运行
- 主容器通常设计为持续运行(如 Web 服务器、数据库、微服务)
- 钩子
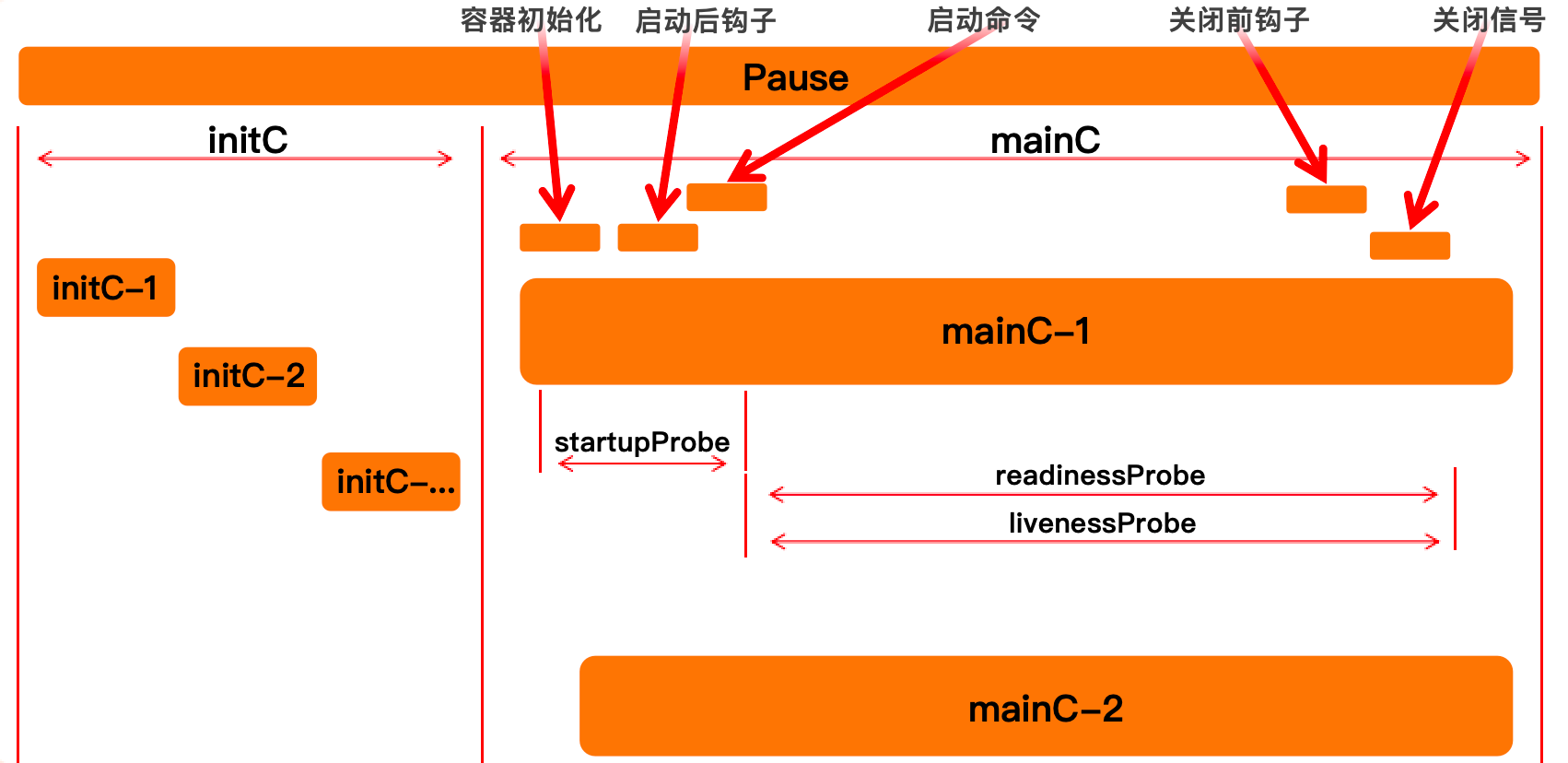
容器初始化、启动后钩子、执行启动命令、关闭前钩子
钩子的类型
- PostStart
- 在容器创建后执行,可能与启动命令并行,比如使用 cp 初始化配置
- PreStop
- 容器终止前执行,用于保存数据、关闭服务
探针
- 启动探针(Startup Probe),容器创建既开始,探测应用是否启动了,保证应用真正启动完成之前,不会开始其它探针
- 开始检测了么?
- 就绪探针(Readiness Probe),老版本就绪后会退出,新版本在开始探测后会一直运行,就算是就绪后也不会退出,就绪后某个节点又死了,也会标记为为未就绪,不断更新 Pod 的就绪状态
- 准备提供服务了么?
- 存活探针(Liveness Probe),判断容器是否“还活着”,“假死”不能提供正常服务但是在运行,或者真死,存活探测会把现在的容器杀死重启,一般的存活探针只有在容器完全启动后才会执行
- 还活着么?
探针是当前 node 节点的 kubelet 对容器的定期诊断,不是 master
ExecAction:在容器内执行指定命令,如果命令退出时状态码为 0,则诊断成功
TCPSocketAction:比如一个服务起了一个端口,它就会去连接,如果 TCP 连接成功,就诊断成功
HTTPGetAction:对指定路径上的容器的 IP 镜像 http get 请求,状态码>=200<400,则诊断成功
- 成功:容器通过诊断
- 失败:容器为通过
- 未知:诊断失败,不会采取任何行动
这些特性不是每个 pod 都需要定义,都是通过当前节点的 kubelet 去执行
initC 实验
阻塞特性实验
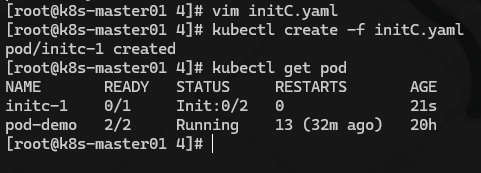
创建一个 pod,定义元数据、别名,定义期望的容器名称、镜像、执行命令,定义了一个initContainers 的初始化容器,指定了一个名字和镜像,初始化命令是循环检测域名是否能够解析,否则阻塞状态,直到能够匹配到在执行下一步,因为 initC 是线性的
另外加了一个 imagePullPolicy: Never,这样 k8s 就不会去拉取远程的镜像了,会用本地的镜像,但是需要注意,本地 master 有这个镜像,不代表所有的 node 节点有,这样就能解决学习过程中 k8s 拉不到镜像的问题
我这里使用的Secrets,所以指定的imagePullSecrets
apiVersion: v1
kind: Pod
metadata:
name: initc-1
labels:
app: initc
spec:
# 使用镜像拉取 Secret
imagePullSecrets:
- name: k8s-wpsec
# 主应用容器
containers:
- name: myapp-container
image: docker.xuanyuan.run/nginx:alpine
command:
- sh
- -c
- |
echo "The app is running!"
sleep 3600
# initContainers 串行执行
initContainers:
- name: init-myservice
image: docker.xuanyuan.run/nginx:alpine
command:
- sh
- -c
- |
echo "Waiting for myservice..."
for i in $(seq 1 30); do
nslookup myservice.default.svc.cluster.local && exit 0
echo "myservice not ready, retrying..."
sleep 2
done
echo "Timeout: myservice not found!"
exit 1
- name: init-mydb
image: docker.xuanyuan.run/nginx:alpine
command:
- sh
- -c
- |
echo "Waiting for mydb..."
for i in $(seq 1 30); do
nslookup mydb.default.svc.cluster.local && exit 0
echo "mydb not ready, retrying..."
sleep 2
done
echo "Timeout: mydb not found!"
exit 1
因为我没有定义 service 的域名,所以这个容器是未就绪状态
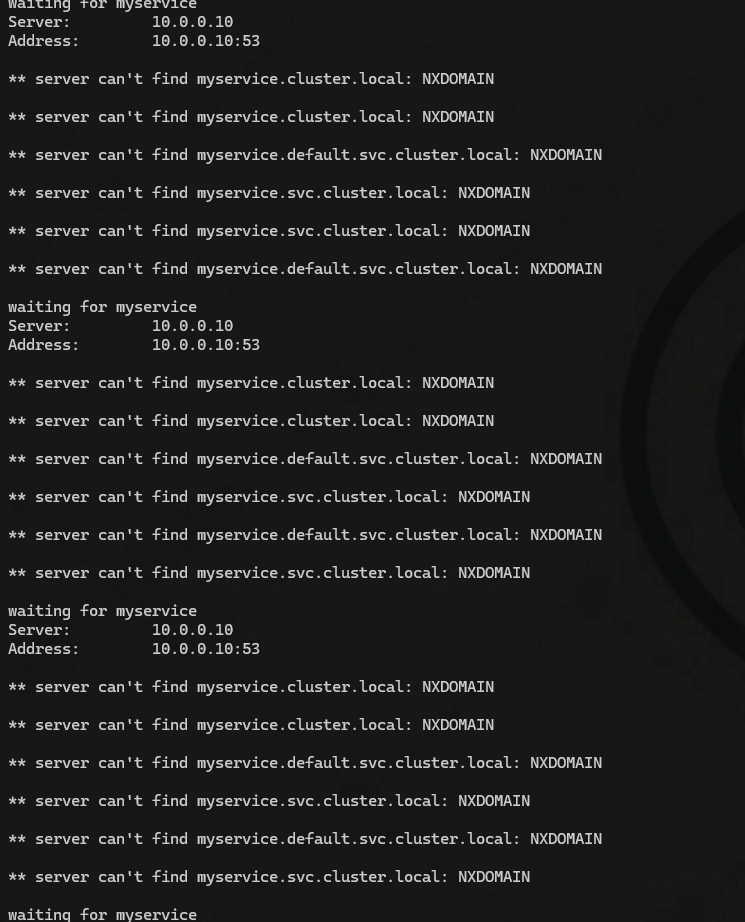
配置一个域名解析的 service
kubectl create svc clusterip myservice --tcp=80:80
这时候就能够解析到域名,到了 initC 的第二步
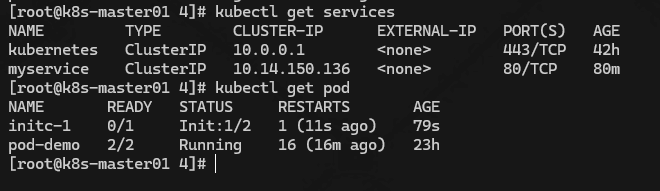
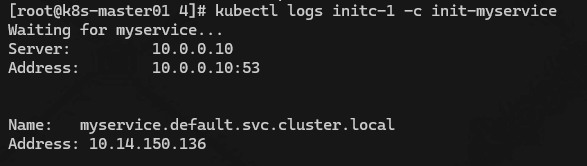
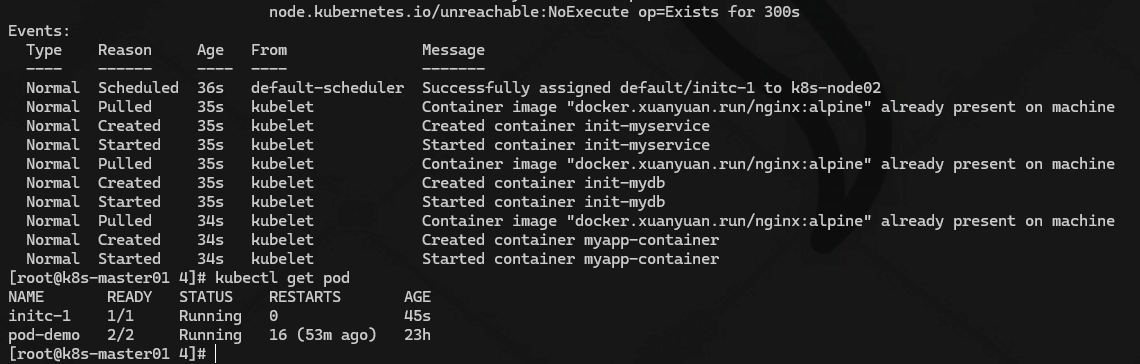
在配置一个解析 mydb 的 dns,在 initC 跑完了后会销毁,只运行一个myapp-container 的主容器
kubectl create svc clusterip mydb --tcp=80:80
就绪探测探针实验
通过就绪探针、解决在扩容时保证给用户的服务都是可用的
如果 pod 内部的容器不添加就绪探测,默认就绪状态
如果添加了就绪探测,当 pod 内所有的容器就绪后,才标记当前 pod 为就绪
成功:就绪
失败:静默
未知:静默
apiVersion: v1
kind: Pod
metadata:
name: test
namespace: default
spec:
containers:
- name: mycontainer
image: docker.xuanyuan.run/nginx:alpine
readinessProbe:
# 状态码就绪探针
httpGet:
# 命令执行就绪探针
exec:
# 端口检测就绪探针
tcpSocket:
readinessProbe 就绪探针
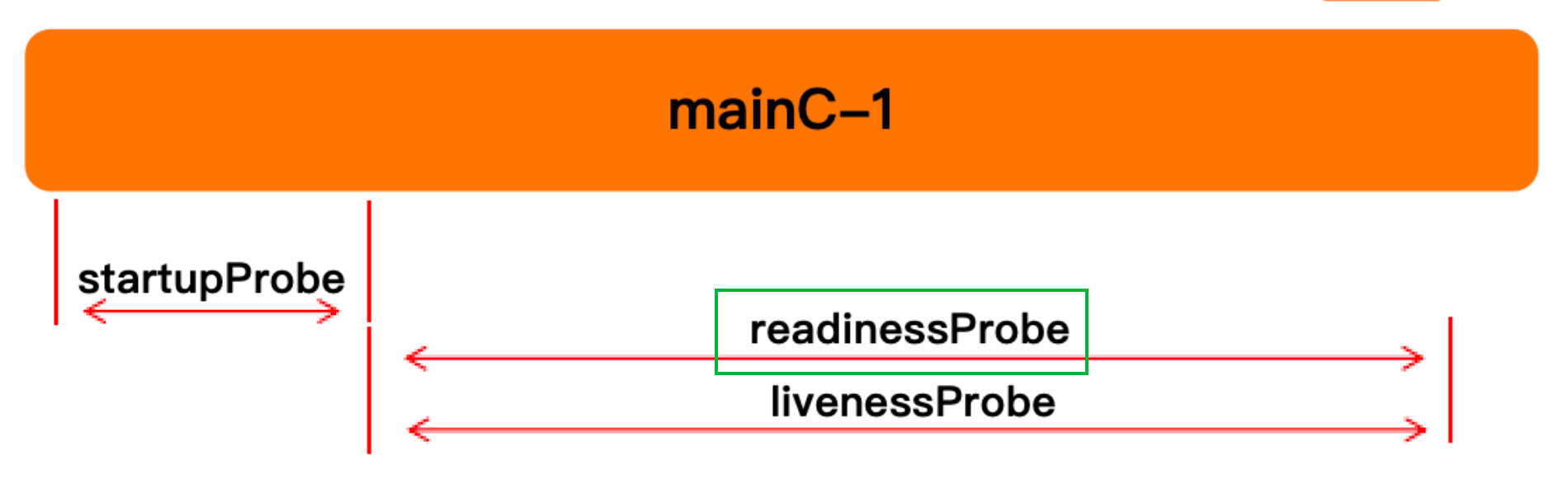
initialDelaySeconds
- 容器启动后,延迟多少时间进行探测探测,单位秒、默认 0
periodSeconds
- 执行探针时,间隔多久一次,单位秒、默认 10s
timeoutSeconds
- 探针执行请求后,等待响应超时时间,单位秒,默认 1s
failureThreshold
- 探针重试次数,重试完后认为失败,默认 3 次,最小 1 次
HTTPGet 就绪探针
创建两个 pod,做一个 server 负载均衡,在 podyaml 元数据中声明一个 labels,app: myapp
pod-1.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-1
namespace: default
labels:
app: myapp
spec:
containers:
- name: mycontainer
image: docker.xuanyuan.run/nginx:alpine
pod-2.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-2
namespace: default
labels:
app: myapp
version: v1
spec:
containers:
- name: mycontainer
image: docker.xuanyuan.run/nginx:alpine
创建 service
这个 service 的名字是 myapp,它会去匹配labels app: myapp 的 pod,将它们形成一个四层负载均衡
kubectl create service clusterip myapp --tcp=80:80
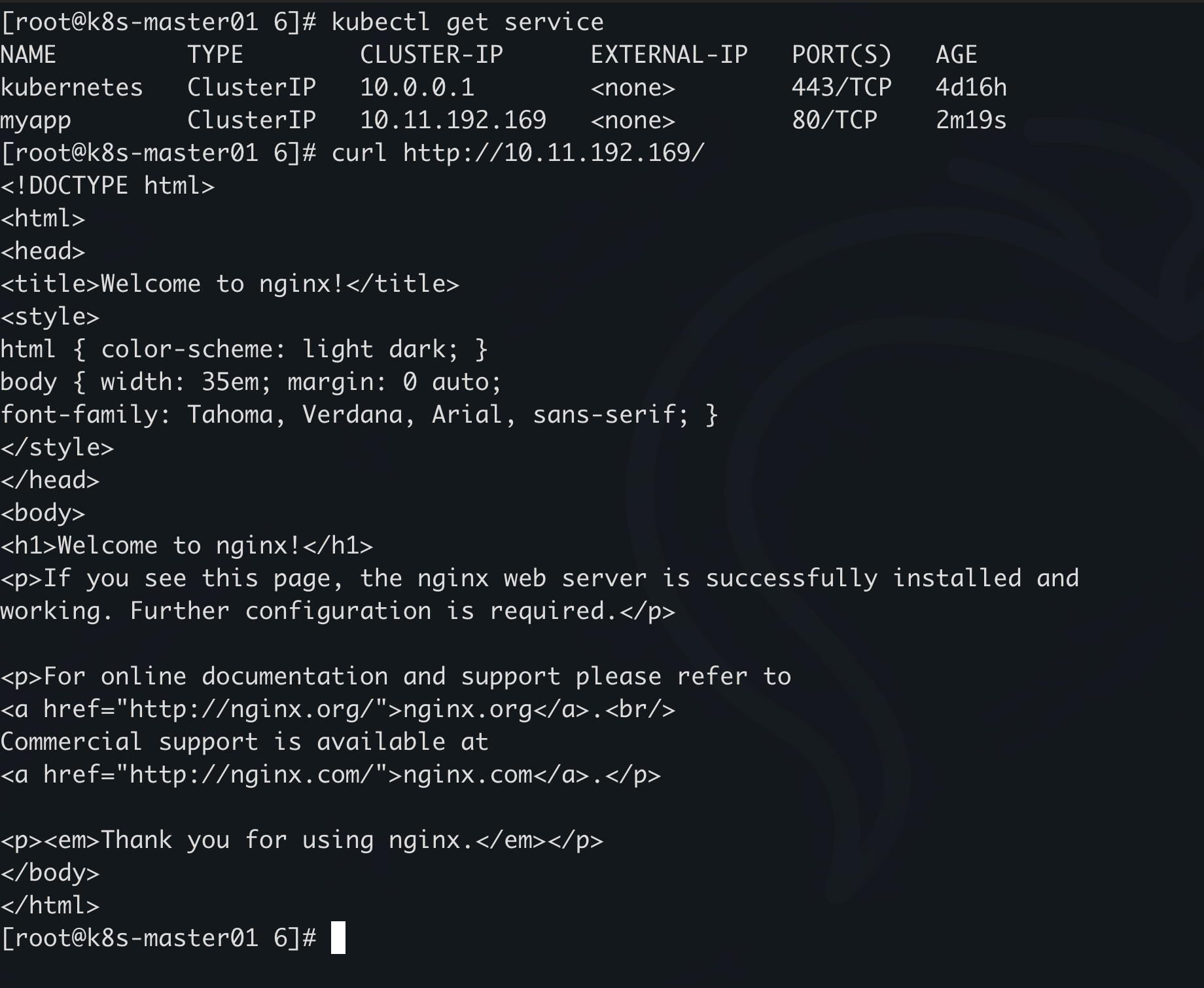
curl3 次这个负载,两次到了 pod2,一次到了 pod1,说明两台都是就绪状态,如果有一个 pod 不就绪,curl 只会给到就绪的 pod 上,因为两个 pod 的labels 都是 myapp,所以会做一个选择器,即使有一个是 v1 版本,有一个没有说明版本,但是他们都有一个共同的labels
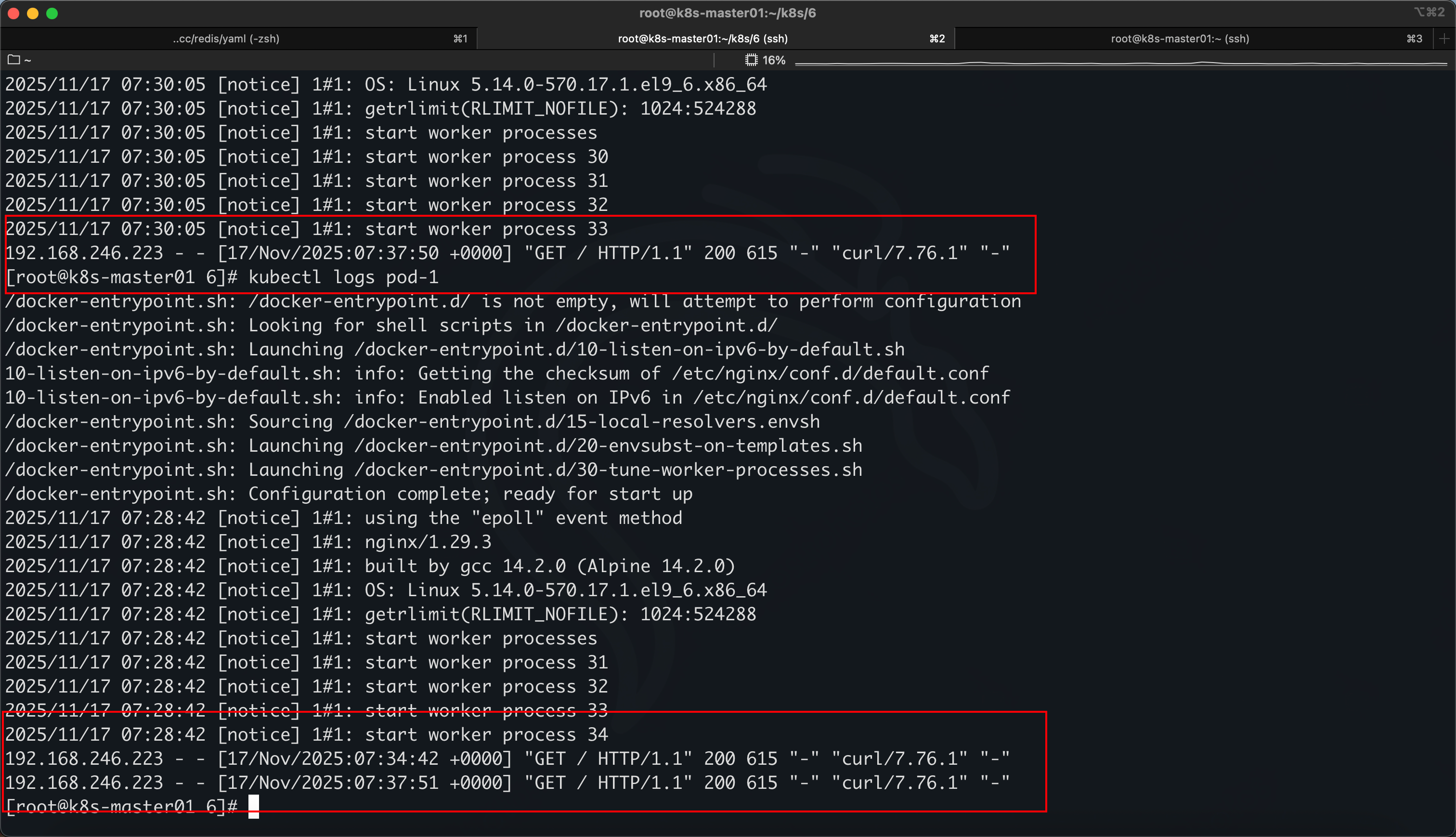
删除 pod2,重新创建新 pod2,新 pod2 会置未就绪状态,因为 pod 里不会有 healthz 这个文件,终会探测失败,即使labels 标签的 app: myapp 能够被匹配,但是因为状态为未就绪,所以不会加入这个 server 的负载中
apiVersion: v1
kind: Pod
metadata:
name: pod-2
namespace: default
labels:
app: myapp
spec:
containers:
- name: mycontainer
image: docker.xuanyuan.run/nginx:alpine
readinessProbe:
# httpGet状态码就绪探针
httpGet:
path: /index2.html
port: 80
initialDelaySeconds: 2
periodSeconds: 3
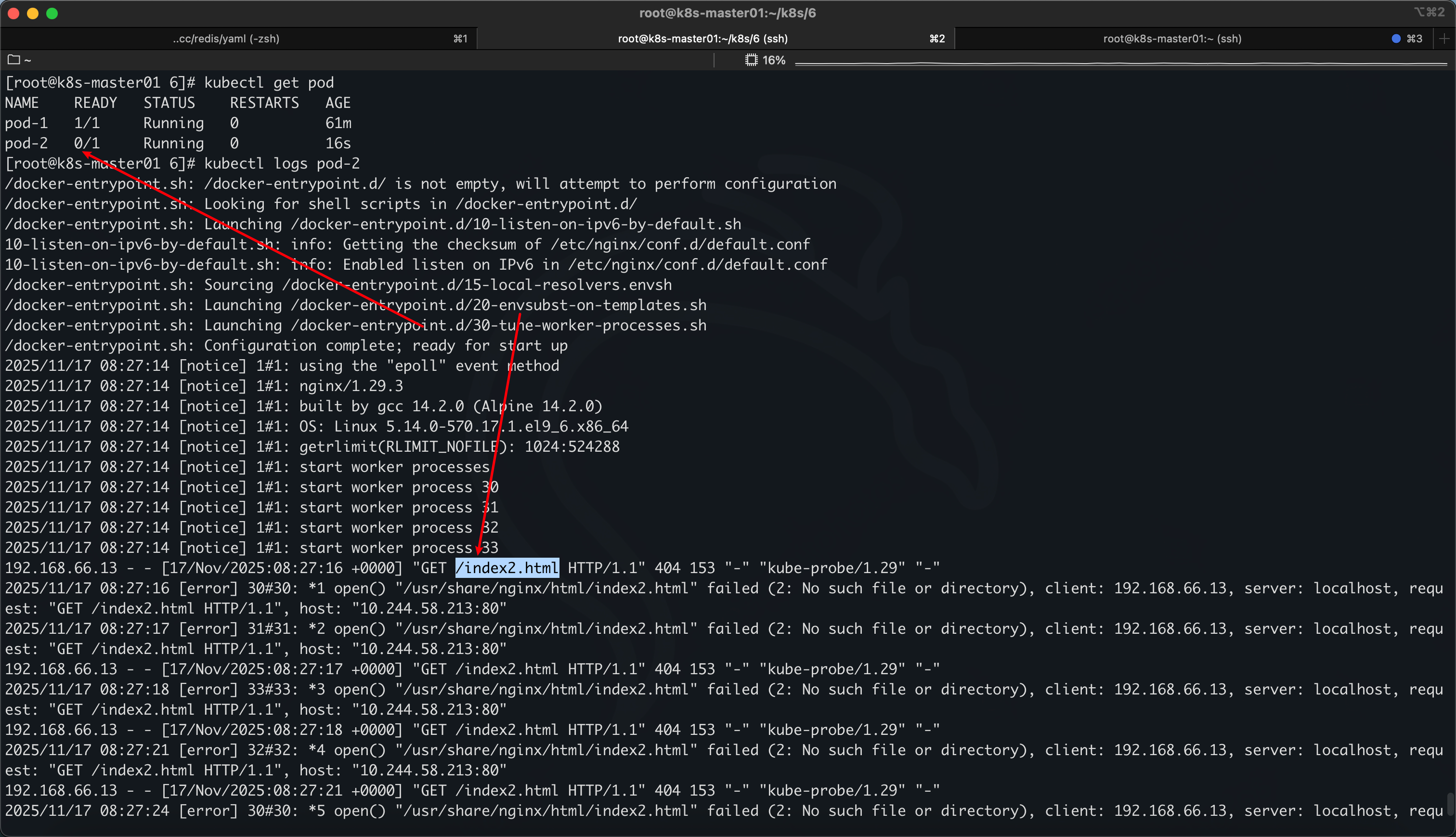
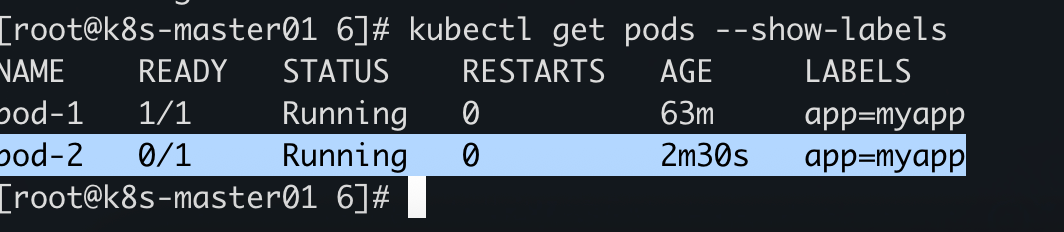
再次 curl,日志会到 pod1,不会交给 pod2 处理,因为 pod2 是未就绪状态,但是通过–show-labels 可以看到,pod2 已经是加入了负载当中了
# 查看所有pod 的labels ,默认namespace为default
kubectl pods --show-labels
其它的就绪就绪探测方式
exec 就绪探针
老版本不会一直检测,通过即为就绪,新版 k8s 会持续探测,只要不就绪,就会标记为未就绪状态
apiVersion: v1
kind: Pod
metadata:
name: pod-exec
namespace: default
labels:
app: myapp
spec:
containers:
- name: mycontainer
image: docker.xuanyuan.run/nginx:alpine
command: ["/bin/sh", "-c"]
args:
- |
# 创建 readiness 文件,使探针最初成功
touch /tmp/ready
echo "Pod is initially READY"
# 等 10 秒后删除文件,使探针失败
sleep 10
rm -f /tmp/ready
echo "Pod is now NOT READY"
# 让容器继续跑,不退出
tail -f /dev/null
readinessProbe:
exec:
command: ["/bin/sh", "-c", "test -f /tmp/ready"]
initialDelaySeconds: 2
periodSeconds: 3
先就绪,后未就绪
TCPSocket 就绪探针
不常用这类方式做探测,端口在,不一定能提供服务
apiVersion: v1
kind: Pod
metadata:
name: pod-tcp
namespace: default
labels:
app: myapp
spec:
containers:
- name: mycontainer
image: docker.xuanyuan.run/nginx:alpine
readinessProbe:
tcpSocket:
port: 80
initialDelaySeconds: 2
periodSeconds: 3
存活探测探针实验
livenessProbe 存活探针
initialDelaySeconds
- 容器启动后,延迟多少秒进行探针,单位秒,默认 0s,最小 0
periodSeconds
- 执行间隔,单位秒,默认 10s,最小 1
timeoutSeconds
- 探针请求后,超时时间,默认 1s,最小 1
successThreshold
- 探测成功次数,默认 1,最小 1
failureThreshold
- 探测重试次数,重试完后认为失败,默认 3,最小 1
如果 pod 内部不指定存活探测,可能会有容器运行,但无法提供服务
成功:静默
失败:根据重启策略重建容器
未知:静默
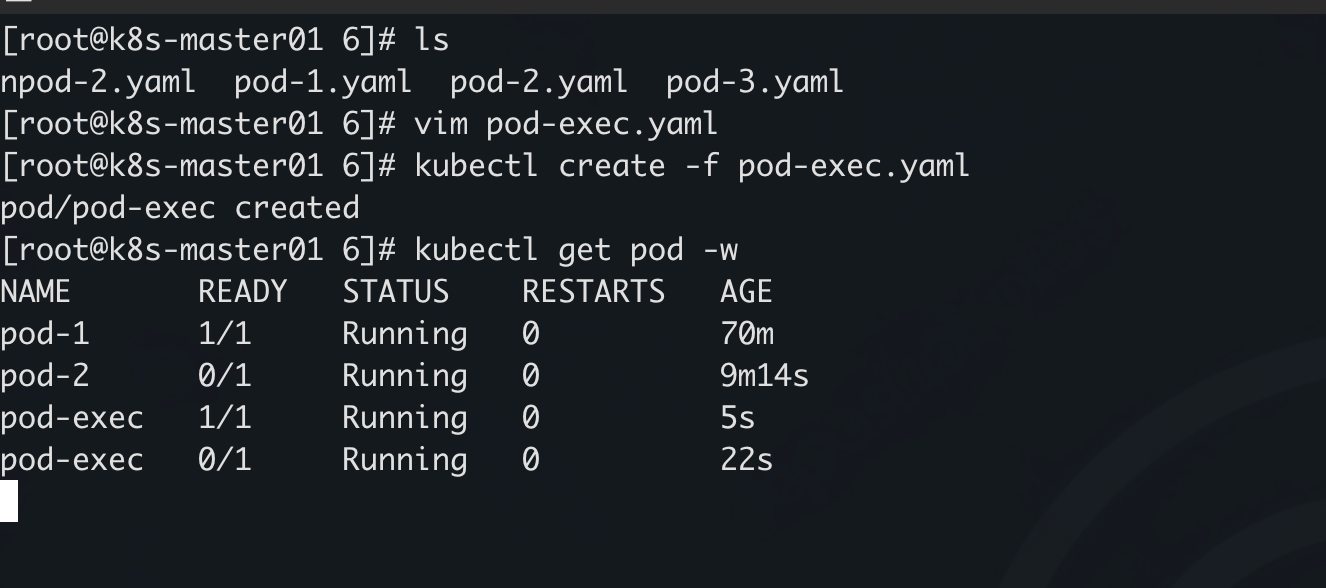
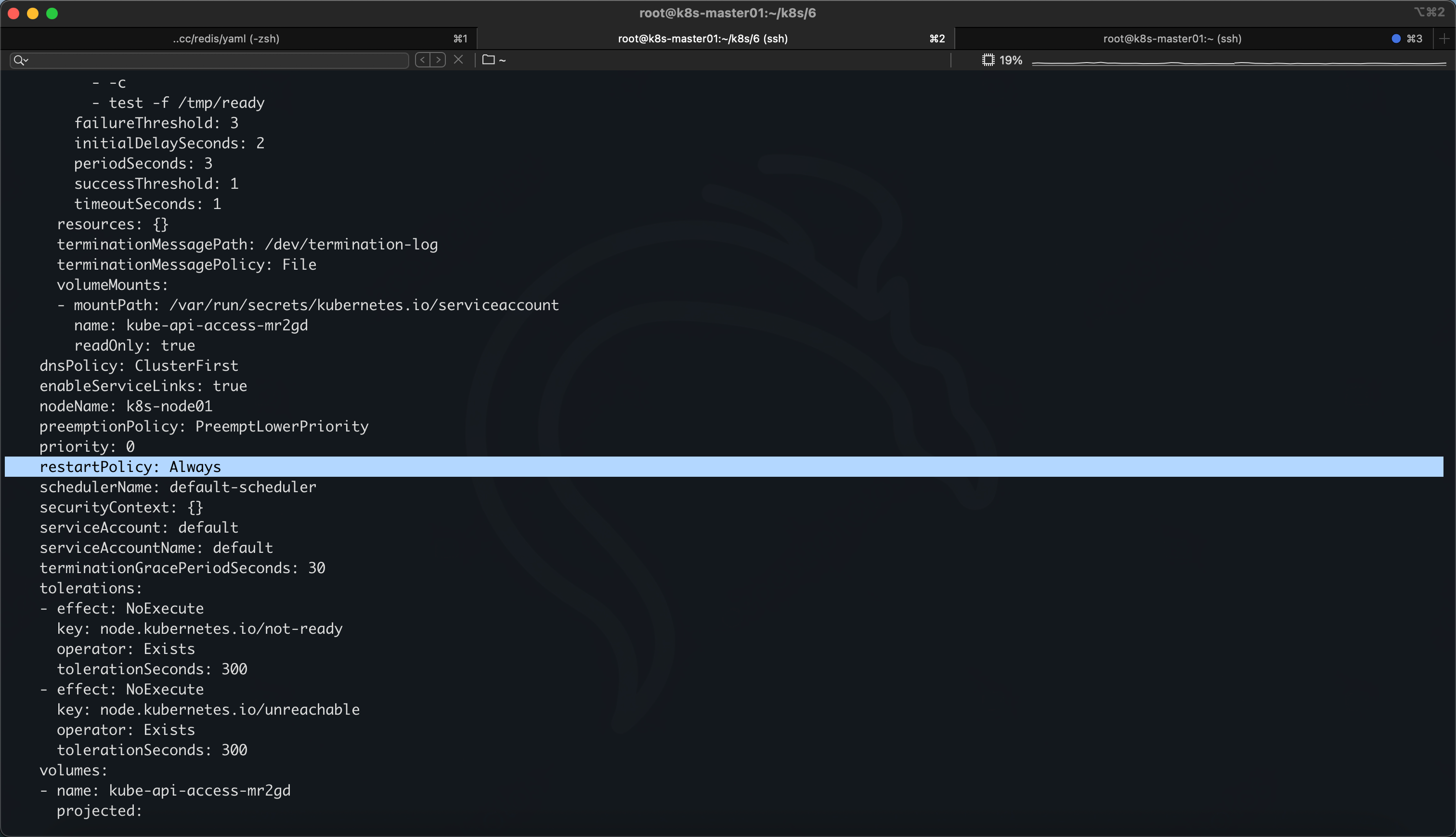
查看默认 namespace pod-exec 的配置文件
kubectl get pod -n default pod-exec -o yaml
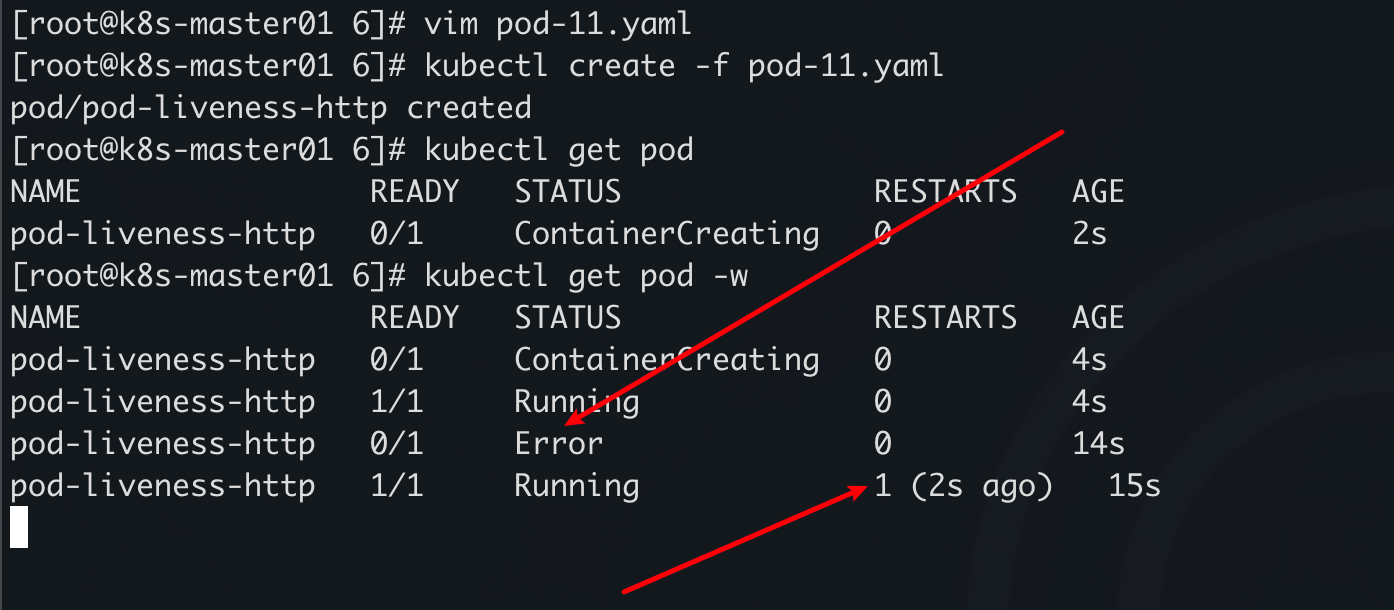
httpGet 存活探针
运行 10 秒后退出,探针探测到容器死了,重启(重构)容器
apiVersion: v1
kind: Pod
metadata:
name: pod-liveness-http
namespace: default
labels:
app: myapp
spec:
containers:
- name: mycontainer
image: docker.xuanyuan.run/nginx:alpine
command: ["/bin/sh", "-c"]
args:
- |
nginx -g 'daemon off;' &
sleep 10
exit 1
livenessProbe:
httpGet:
path: /
port: 80
initialDelaySeconds: 2
periodSeconds: 3
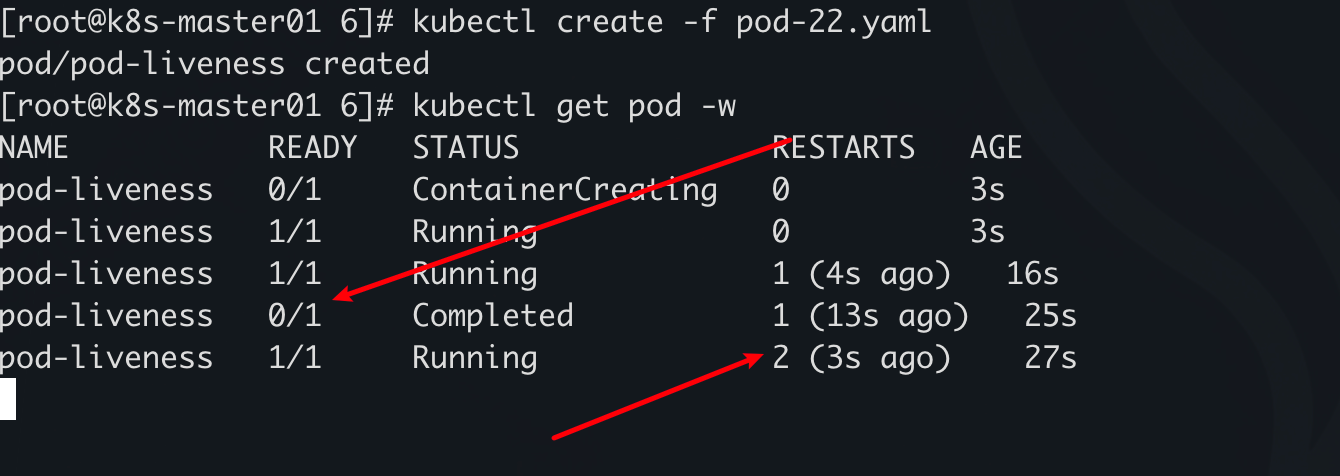
exec 存活探针
apiVersion: v1
kind: Pod
metadata:
name: pod-liveness
namespace: default
labels:
app: myapp
spec:
containers:
- name: mycontainer
image: docker.xuanyuan.run/nginx:alpine
command: ["/bin/sh", "-c"]
args:
- |
# 先正常运行,10秒后模拟挂掉
echo "Pod is alive"
sleep 10
echo "Pod will simulate failure"
# 阻塞模拟容器死掉(sleep infinity 实际上容器没有响应 probe)
kill -STOP 1
livenessProbe:
exec:
command: ["/bin/sh", "-c", "ps aux | grep nginx | grep -v grep"]
initialDelaySeconds: 2
periodSeconds: 3
TCPSocket 探针存活
apiVersion: v1
kind: Pod
metadata:
name: pod-liveness-tcp
namespace: default
labels:
app: myapp
spec:
containers:
- name: mycontainer
image: docker.xuanyuan.run/nginx:alpine
command: ["/bin/sh", "-c"]
args:
- |
# 正常启动 nginx
nginx -g 'daemon off;'
livenessProbe:
tcpSocket:
port: 80
initialDelaySeconds: 2
periodSeconds: 3
启动探测探针实验
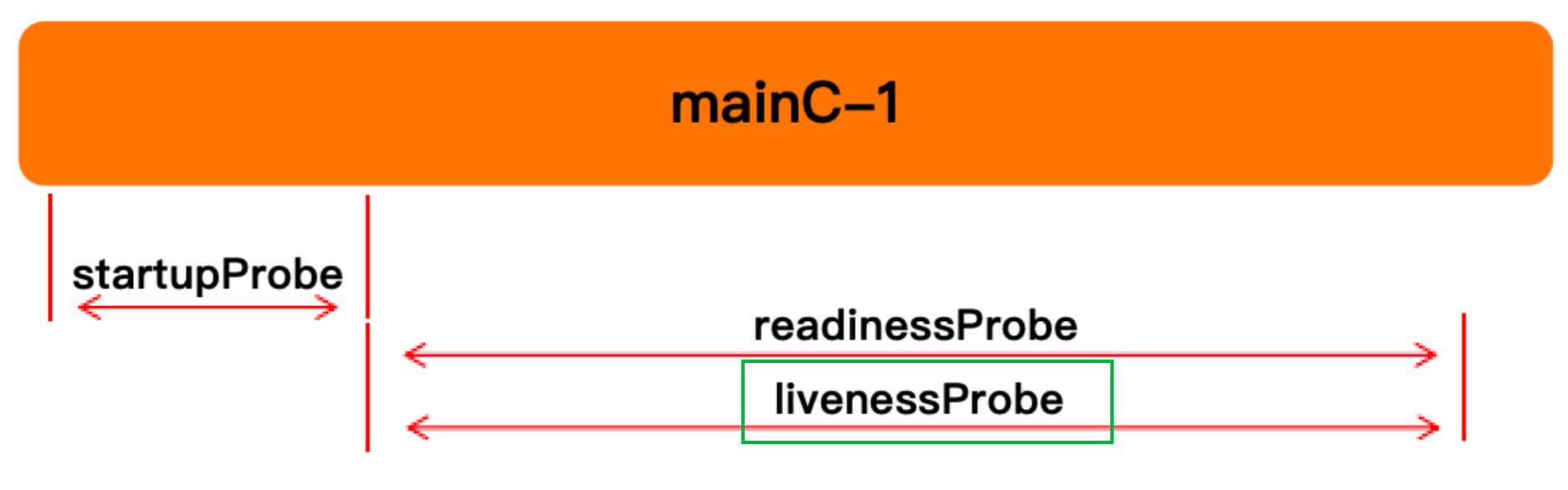
k8s 在 1.16 版本后添加的功能,解决在复杂环境下,就绪探针与存活探针无法判断存活启动的问题
避免就绪探针或存探针在容器没有完全启动前就去做探测,因为有些服务,用延迟去主观的探测不合理,所以有了启动探测
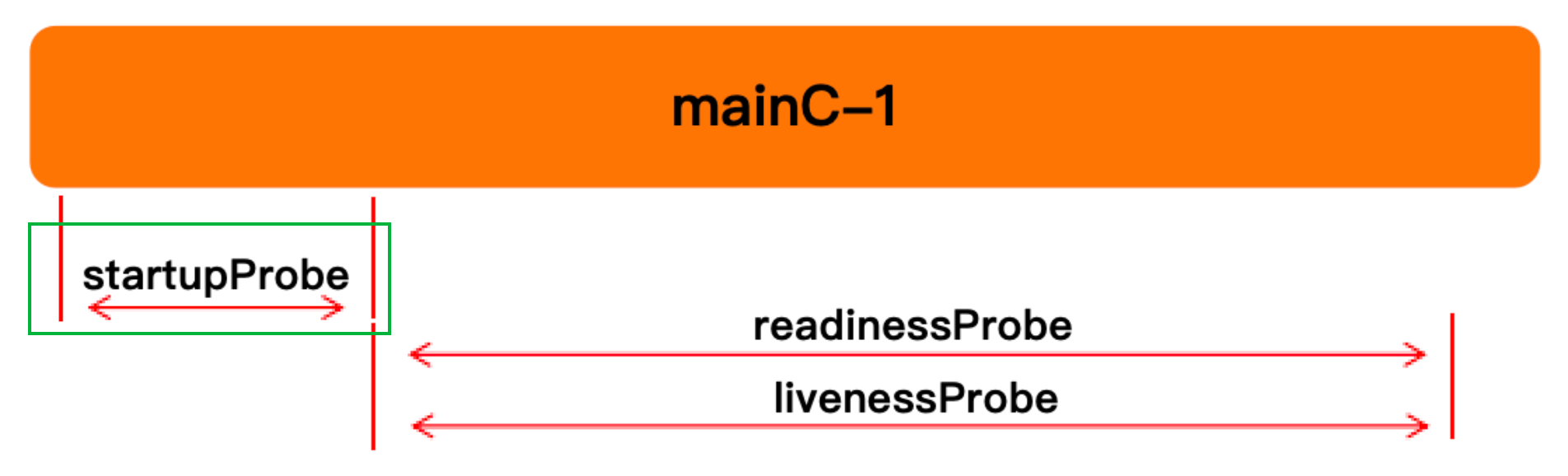
保障存活探针在执行的时候不会因为容器还没启动就去探测,导致循环,或者避免延迟过高影响系统发挥
成功:允许就绪或者存活探测执行
失败:静默
未知:静默
startupProbe 启动探针
initialDelaySeconds
- 容器启动后多久开始探测,单位秒,默认 0
periodSeconds
- 执行探测时间间隔,单位秒,默认 10,最小 1
timeoutSeconds
- 执行探针后的超时,单位秒,默认 1,最小 1
failureThreshold
- 重试次数,重试次数完后认定失败,默认 3,最小 1
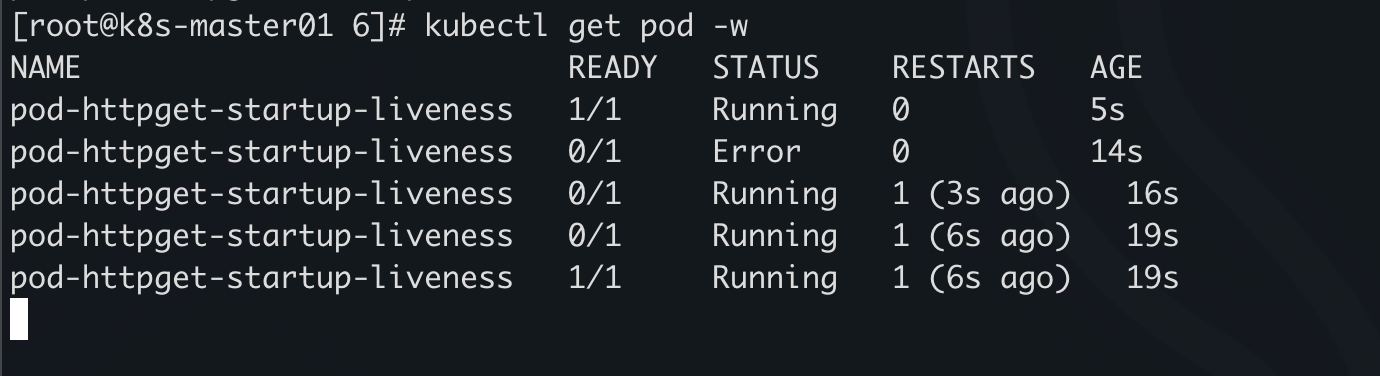
HTTPGet 启动探针
apiVersion: v1
kind: Pod
metadata:
name: pod-httpget-startup-liveness
namespace: default
labels:
app: myapp
spec:
containers:
- name: mycontainer
image: docker.xuanyuan.run/nginx:alpine
command: ["/bin/sh", "-c"]
args:
- |
# 启动 nginx
nginx -g 'daemon off;' &
# 10 秒后退出,触发存活探针失败
sleep 10
exit 1
startupProbe:
httpGet:
path: /
port: 80
initialDelaySeconds: 2
periodSeconds: 2
failureThreshold: 5
livenessProbe:
httpGet:
path: /
port: 80
initialDelaySeconds: 0
periodSeconds: 3
启动 ningx 10 秒,通过启动探针,启动探针通过,进入存活探针,存活探针失败,重启容器
exec 启动探针
apiVersion: v1
kind: Pod
metadata:
name: pod-exec-startup-liveness
namespace: default
labels:
app: myapp
spec:
containers:
- name: mycontainer
image: docker.xuanyuan.run/nginx:alpine
command: ["/bin/sh", "-c"]
args:
- |
nginx -g 'daemon off;' &
sleep 10
exit 1
startupProbe:
exec:
command:
- sh
- -c
- "[ -f /tmp/healthy ]"
initialDelaySeconds: 2
periodSeconds: 2
failureThreshold: 5
livenessProbe:
exec:
command:
- sh
- -c
- "exit 1"
initialDelaySeconds: 0
periodSeconds: 3
执行 10 秒后退出,启动探测获取了一个文件,因为没有这个文件,所以没有进入就绪探测,容器在反复重启,直到 5 次后,ps:第一次启动算启动,不算重启,所以最后有 6 次记录
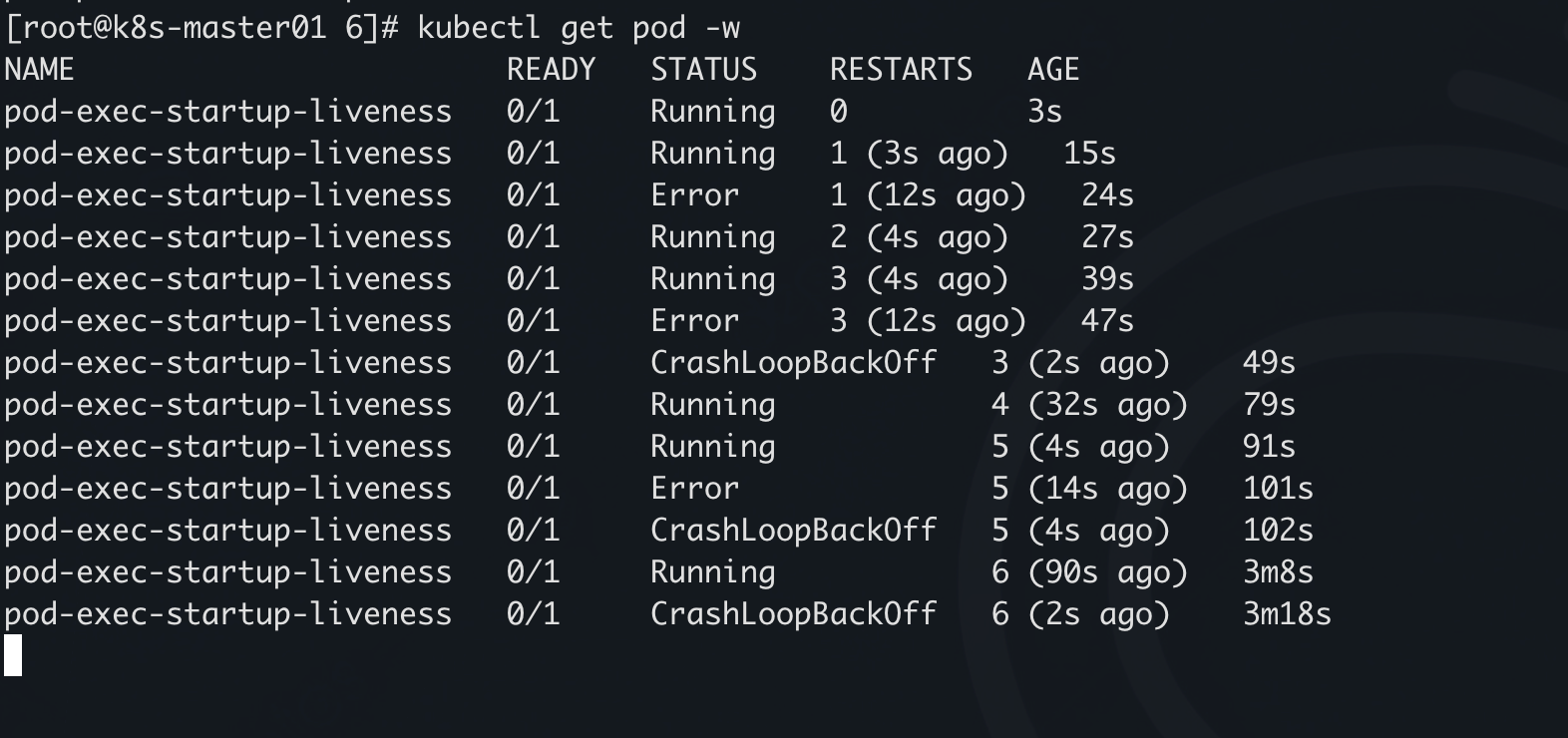
TCPSocket 启动探针
apiVersion: v1
kind: Pod
metadata:
name: pod-tcp-startup-liveness
namespace: default
labels:
app: myapp
spec:
containers:
- name: mycontainer
image: docker.xuanyuan.run/nginx:alpine
command: ["/bin/sh", "-c"]
args:
- |
nginx -g 'daemon off;' &
sleep 10
exit 1
startupProbe:
tcpSocket:
port: 80
initialDelaySeconds: 2
periodSeconds: 2
failureThreshold: 5
livenessProbe:
tcpSocket:
port: 80
initialDelaySeconds: 0
periodSeconds: 3
钩子
pod hook,由当前 pod 的 kubelet 发起
启动后
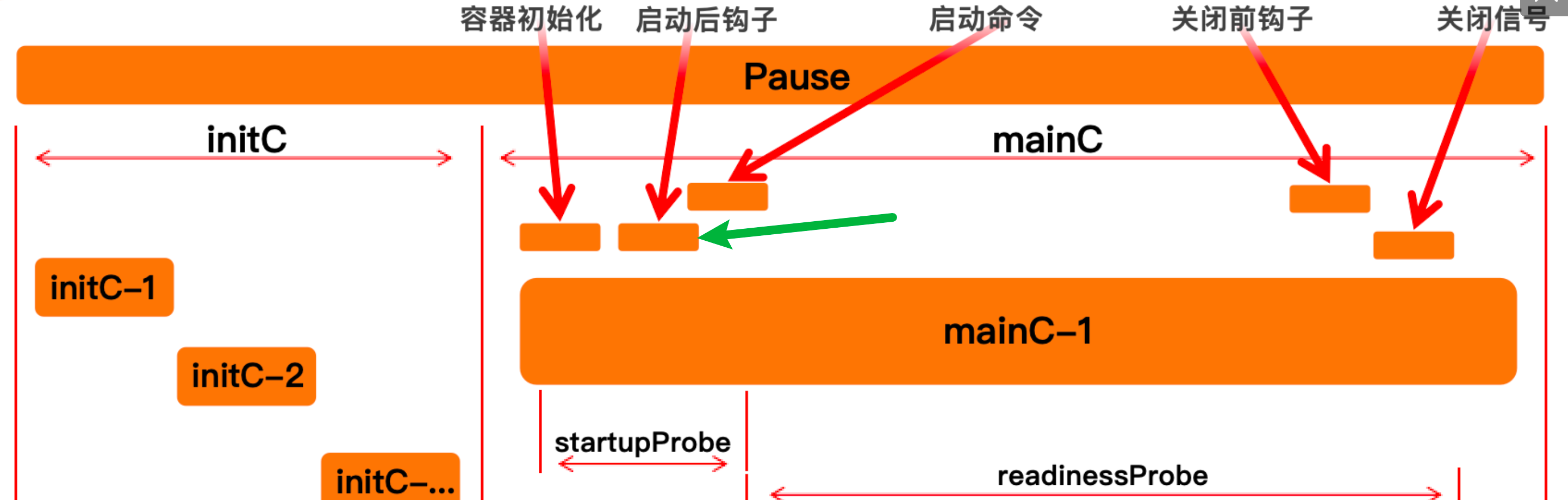
spec:
containers:
- name: mycontainer
image: docker.xuanyuan.run/nginx:alpine
command: ["/bin/sh", "-c"]
args:
- nginx -g 'daemon off;'
# 生命周期配置块,其中钩子在里面进行配置
lifecycle:
# 启动后钩子
postStart:
apiVersion: v1
kind: Pod
metadata:
name: pod-poststart-example
namespace: default
labels:
app: myapp
spec:
containers:
- name: mycontainer
image: docker.xuanyuan.run/nginx:alpine
command: ["/bin/sh", "-c"]
args:
- nginx -g 'daemon off;'
lifecycle:
postStart:
exec:
command:
- /bin/sh
- -c
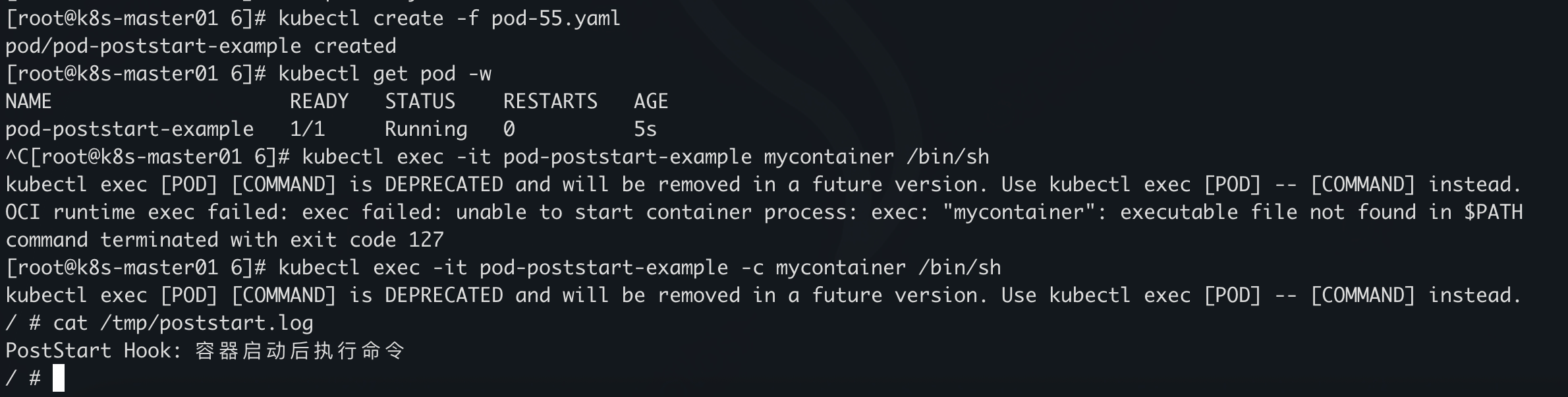
- |
echo "PostStart Hook: 容器启动后执行命令" > /tmp/poststart.log
echo "可以在这里做初始化操作,比如生成配置文件、初始化目录等"
启动后的钩子动作
关闭前
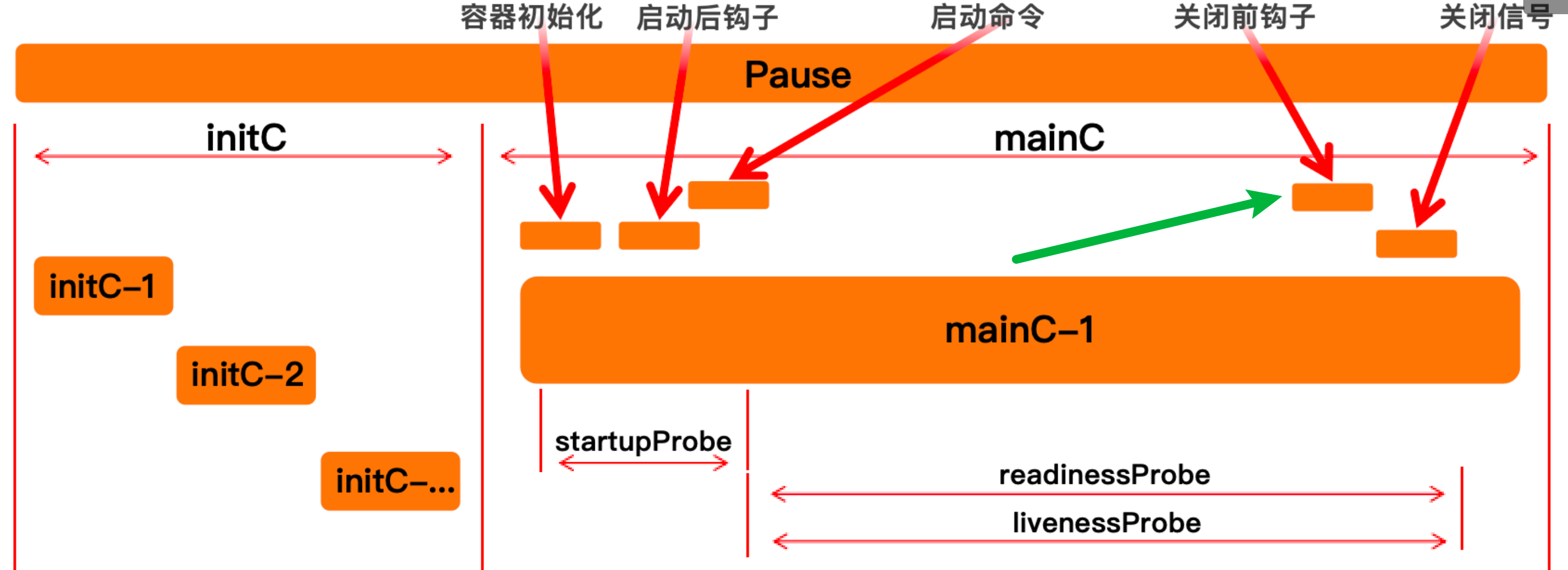
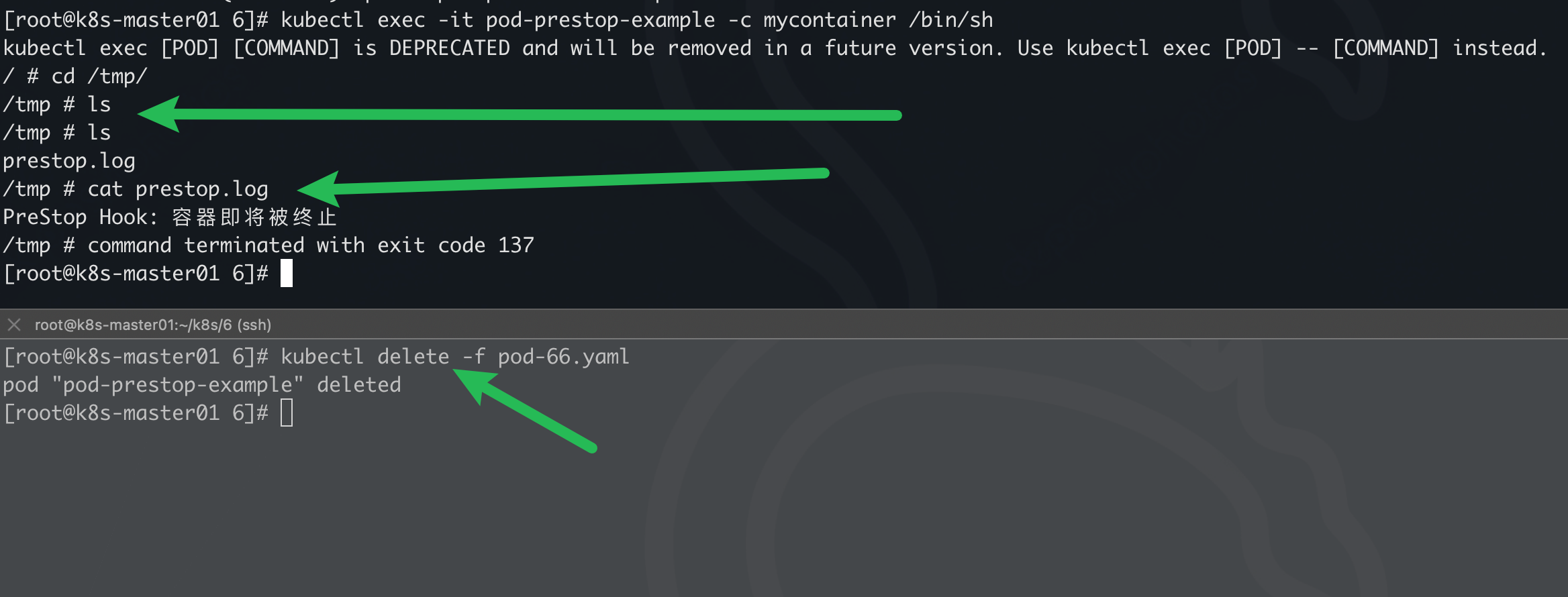
apiVersion: v1
kind: Pod
metadata:
name: pod-prestop-example
namespace: default
labels:
app: myapp
spec:
containers:
- name: mycontainer
image: docker.xuanyuan.run/nginx:alpine
command: ["/bin/sh", "-c"]
args:
- nginx -g 'daemon off;'
lifecycle:
preStop:
exec:
command:
- /bin/sh
- -c
- |
echo "PreStop Hook: 容器即将被终止" > /tmp/prestop.log
echo "可以在这里做清理或通知操作"
sleep 5 # 模拟一些清理时间
容器被杀死前做的操作
HTTPGet 钩子
启动一个容器服务,开放 8080,使用钩子,启动后钩子会访问一下这个容器的 80 的poststart 路径,关闭后,关闭后钩子会访问一下prestop,证明钩子的运行
apiVersion: v1
kind: Pod
metadata:
name: pod-http-hook
namespace: default
labels:
app: myapp
spec:
containers:
- name: mycontainer
image: docker.xuanyuan.run/nginx:alpine
command: ["/bin/sh", "-c"]
args:
- nginx -g 'daemon off;'
lifecycle:
postStart:
httpGet:
host: 192.168.66.11
path: /poststart
port: 8080
preStop:
httpGet:
host: 192.168.66.11
path: /prestop
port: 8080
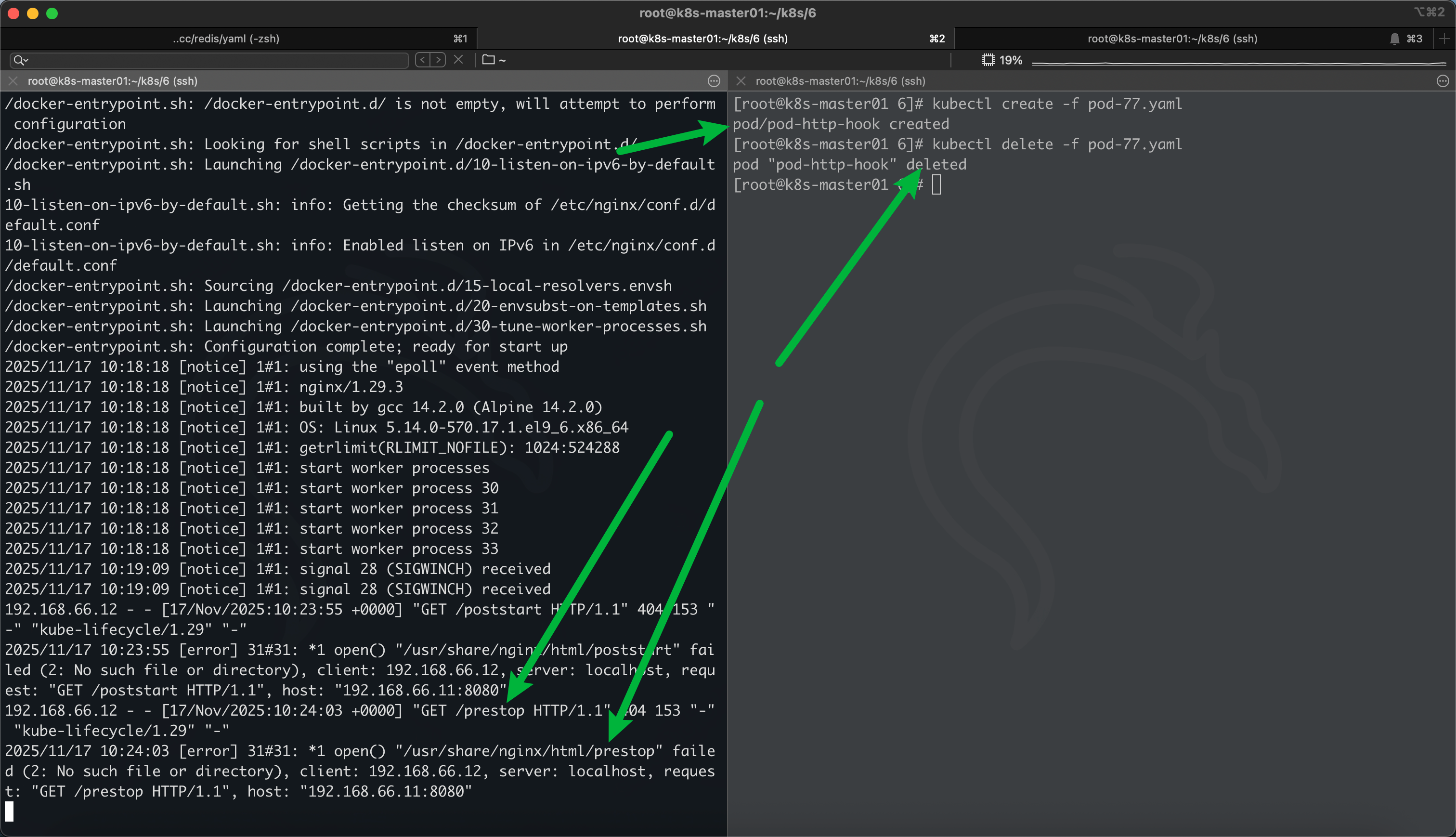
perStop 的作用,在理想情况下,让 pod 优雅退出,pod 卡死了等等问题,杀不了 pod,可以设置一个容忍时间,–grace-period=30,delete 30 秒的容忍
pod 生命周期中的 initC、就绪探针、存活探针、启动探针、hook 都可以并存
一个完整的实验
启动顺序:
initC——》mainC 主容器——〉启动后钩子——》启动探针——〉就绪探针——》存活探针——〉关闭前钩子
apiVersion: v1
kind: Pod
metadata:
name: pod-hook-local
namespace: default
labels:
app: myapp
spec:
containers:
- name: mycontainer
image: docker.xuanyuan.run/nginx:alpine
command: ["/bin/sh", "-c"]
args:
- |
nginx -g 'daemon off;' &
# 模拟 10 秒后触发 livenessProbe
sleep 10
exit 1
lifecycle:
postStart:
exec:
command:
- /bin/sh
- -c
- |
echo "$(date) - PostStart hook executed" >> /tmp/hook.log
touch /tmp/poststart_done
preStop:
exec:
command:
- /bin/sh
- -c
- |
echo "$(date) - PreStop hook executed" >> /tmp/hook.log
touch /tmp/prestop_done
sleep 2
startupProbe:
httpGet:
path: /
port: 80
initialDelaySeconds: 2
periodSeconds: 2
failureThreshold: 5
readinessProbe:
httpGet:
path: /
port: 80
initialDelaySeconds: 2
periodSeconds: 3
livenessProbe:
httpGet:
path: /
port: 80
initialDelaySeconds: 0
periodSeconds: 3

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 7
7 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)