这是一篇写给AI大模型入门的新手小白手册(附文档)
本文系统梳理了AI大模型学习的完整框架,分为六个循序渐进的部分:从深度学习基础(如Transformer架构)、NLP基础知识(如BERT模型),到大模型核心技术(训练框架、微调方法)、推理流程(KVCache机制)、应用开发(Langchain工具),最后是前沿技术追踪(顶会论文)。作者针对当前AI人才缺口大的现状,指出大模型是重要发展方向,并提供了包含学习路线、面试题等资源的完整学习资料包,帮
学AI大模型也有一段时间了,之前学大模型一直都是东一榔头,西一棒槌,这学一点那学一点,网上很多名义上说是系统化大模型教程的,到后面也是零零散散,拼拼凑凑的教程,我花了几个月的时间才构建起对大模型的整体认知,但不够细致…
所以,为了让大家避免我之前踩过的坑,今天特地梳理了一下大致的学习框架,让大家有目的有方向的学习,这样可以节省很多的时间。
首先,大家应该明白一件事,大模型技术是人工智能技术的一个分支,是目前主流的一个研究方向,但并不是唯一的方向。
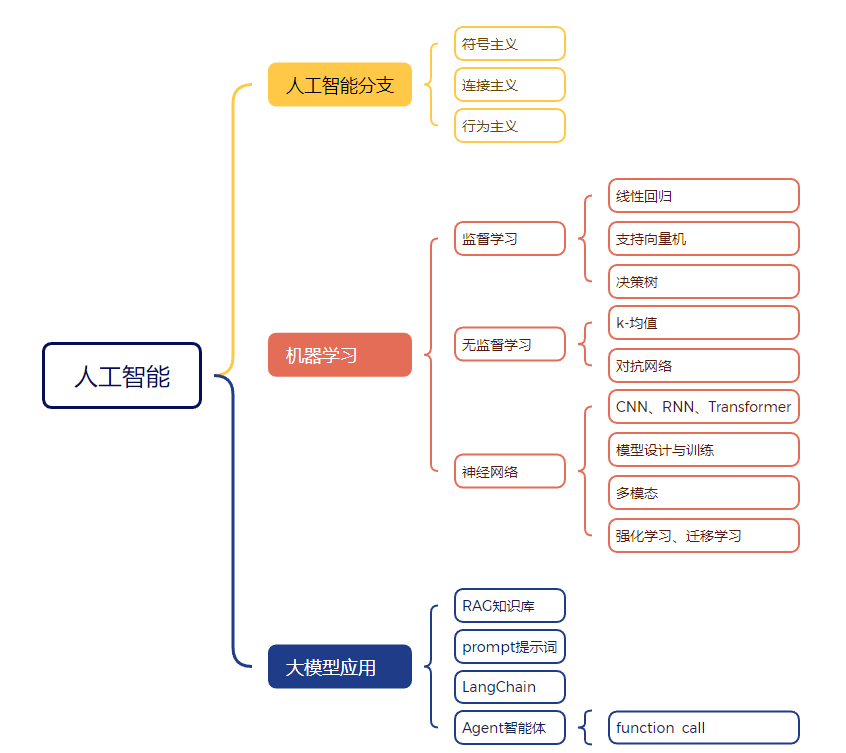
以上都是可以深入学习的方向。
下面来给大家讲讲AI大模型入门手册的具体内容,主要分为六个部分:

第一章:深度学习基础知识 (难度⭐⭐)
Transformer作为当前大模型的核心基础框架,主流大模型均围绕Transformer架构进行衍生改进。此外,还需掌握神经网络的基础知识,例如Batch Normalization(BN)与Layer Normalization(LN)的差异、不同优化器的性能对比等。相较于初级的深度学习入门内容,这部分知识的复杂度有所提升。
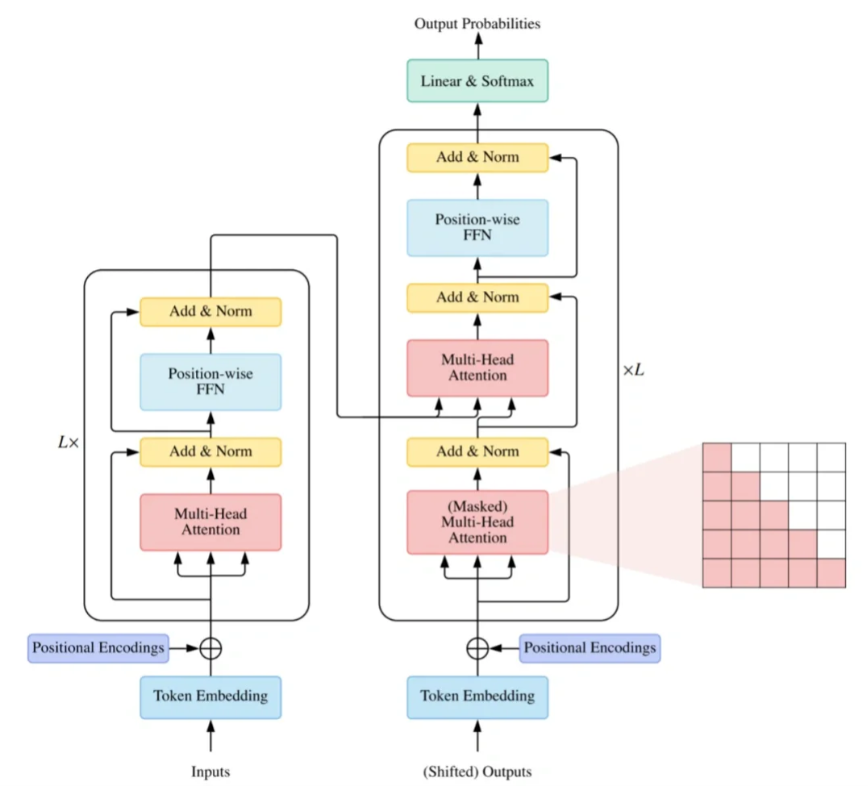
第二章:自然语言处理基础知识 (难度⭐⭐⭐)
掌握NLP的基础知识是学习LLM的前提条件,例如需要熟悉分词器(Tokenizer)的工作原理。此外,当前主流的NLP模型如Bert(Bidirectional Encoder Representations from Transformers)具有里程碑意义——该模型的问世验证了大模型通过预训练(Pre-training)与微调(Fine-tuning)相结合的范式可行性。最后,在自然语言处理任务中,困惑度(Perplexity)作为核心评估指标,其重要性不可忽视。
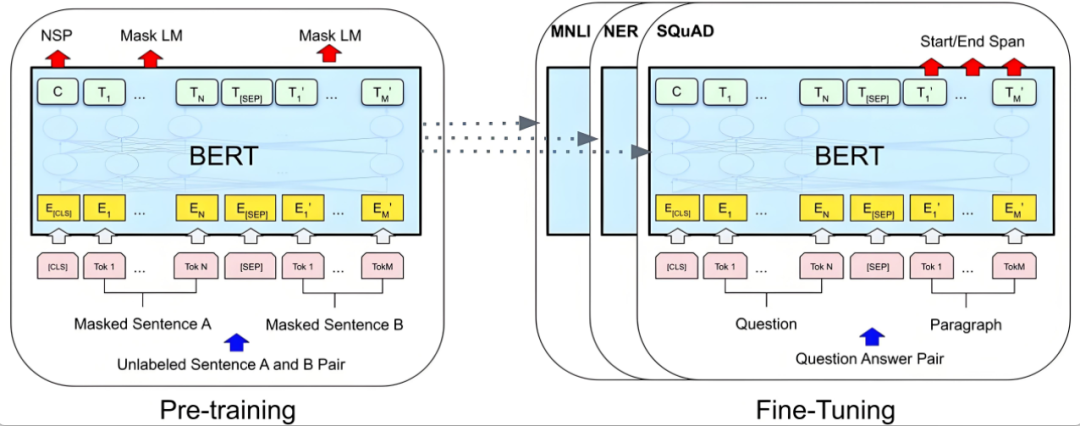
第三章:大语言模型基础知识 (难度⭐⭐⭐⭐)
这部分的内容包括大模型训练框架,比如Megatron-LM, DeepSpeed, 高效参数微调的方法,当前主流的开源大模型,RLHF流程的介绍,COT和TOT的介绍,监督微调的训练,最后是混合专家模型MOE。
第四章:大语言模型推理 (难度⭐⭐⭐)
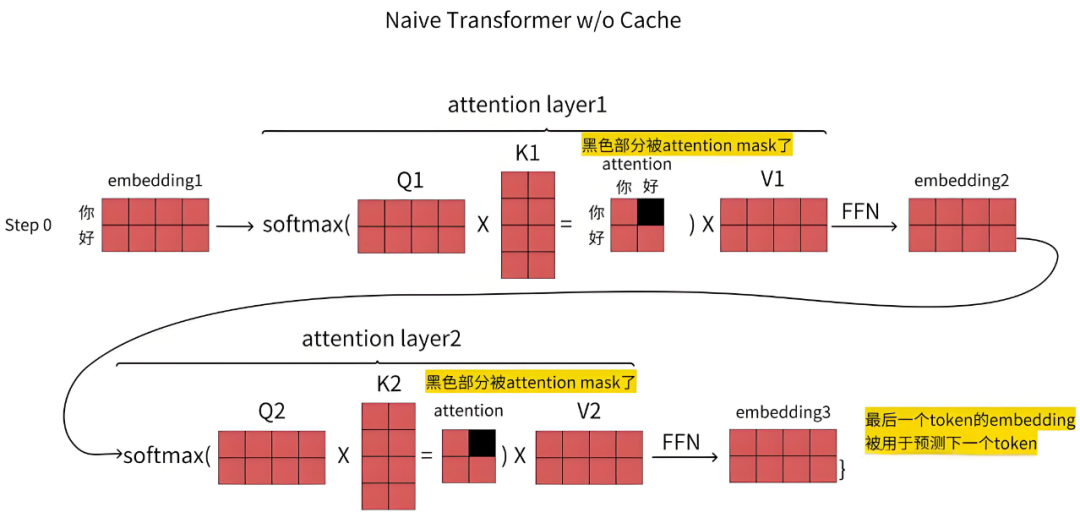
在完成模型训练后,大模型的输出结果即构成推理流程。本节将重点说明HuggingFace的推理参数配置、推理过程中KVCache机制的作用,以及LLM推理所需付出的成本代价。实际应用中的核心考量因素始终在于推理速度与资源消耗的平衡。
第五章:大语言模型应用(难度⭐⭐⭐)
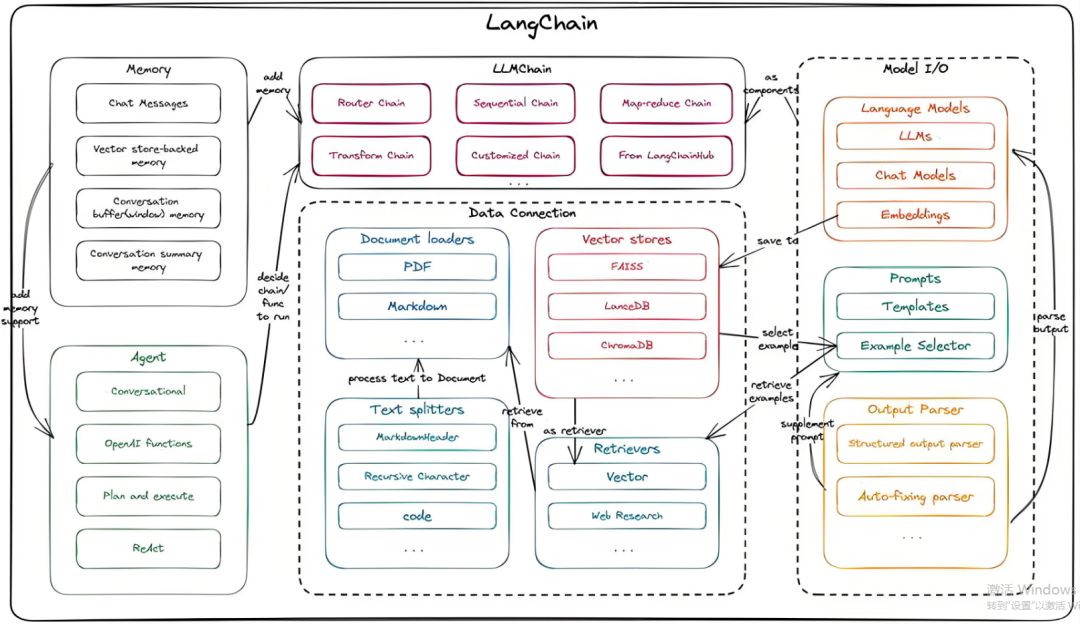
不同大模型的数据格式,API接口等都不一样,可以通过Langchain来统一管理这些,支持大模型的统一化调用,支持便捷的prompt模版设置,还有智能体的高阶应用,建议结合相关视频教程来学习langchain
第六章:大语言模型前沿(难度⭐⭐⭐)
本部分聚焦于LLM(大语言模型)相关博客的推荐。由于大模型技术迭代迅速,建议通过阅读专业博客主动跟进学习,同时关注顶会(如NeurIPS、ACL等)的前沿论文。当前可参考的资料较为有限,后续可逐步补充完善。
最近两年,大家都可以看到AI的发展有多快,我国超10亿参数的大模型,在短短一年之内,已经超过了100个,现在还在不断的发掘中,时代在瞬息万变,我们又为何不给自己多一个选择,多一个出路,多一个可能呢?
与其在传统行业里停滞不前,不如尝试一下新兴行业,而AI大模型恰恰是这两年的大风口,整体AI领域2025年预计缺口1000万人,其中算法、工程应用类人才需求最为紧迫!
学习AI大模型是一项系统工程,需要时间和持续的努力。但随着技术的发展和在线资源的丰富,零基础的小白也有很好的机会逐步学习和掌握。【点击蓝字获取】
【2025最新】AI大模型全套学习籽料(可白嫖):LLM面试题+AI大模型学习路线+大模型PDF书籍+640套AI大模型报告等等,从入门到进阶再到精通,超全面存下吧!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 21
21 0
0- 0



 已为社区贡献56条内容
已为社区贡献56条内容

所有评论(0)