【珍藏指南】构建智能SQL生成器:使用LangChain和OpenAI实现自然语言转SQL,让AI帮你写SQL查询
文章介绍了如何借鉴Pinterest Text-to-SQL工程团队思路,构建一个将自然语言转换为SQL查询的系统。系统经历了两个版本:第一版需用户手动选择相关表,第二版采用RAG技术自动查找相关表。文章详细使用Python、LangChain和OpenAI搭建了Text-to-SQL系统,包括环境设置、数据库模拟、核心链构建、RAG增强表选择功能,以及将各组件组合成RAG驱动的完整流程,为非SQ
前言
数据对于现代商业决策是至关重要的。然而,许多职场的”牛马“大多都不熟悉 SQL,这就导致了“需求”和“解决方案”之间的脱钩了。Text-to-SQL 系统就可以解决了这个问题,它能将简单的自然语言问题转换成数据库查询。
接下来,我们将借鉴 Pinterest Text-to-SQL 工程团队的实现思路,来探讨如何构建一个自己的SQL生成器。
了解 Pinterest
Pinterest 希望公司内的每个人都能轻松的访问其内部的数据,并能够按需从海量的数据集中获取洞见,然而大多数人并非SQL方面的专家,因此,也就无法充分的数据的价值。这一问题间接的促成了 Pinterest Text-to-SQL 平台的诞生,他们的发展历程为我们构建类似工具提供了绝佳的蓝图。
第一版本
他们的第一个系统相当直观。用户提出一个问题,并手动列出他们认为相关的数据库表。然后,系统会生成一个 SQL 查询。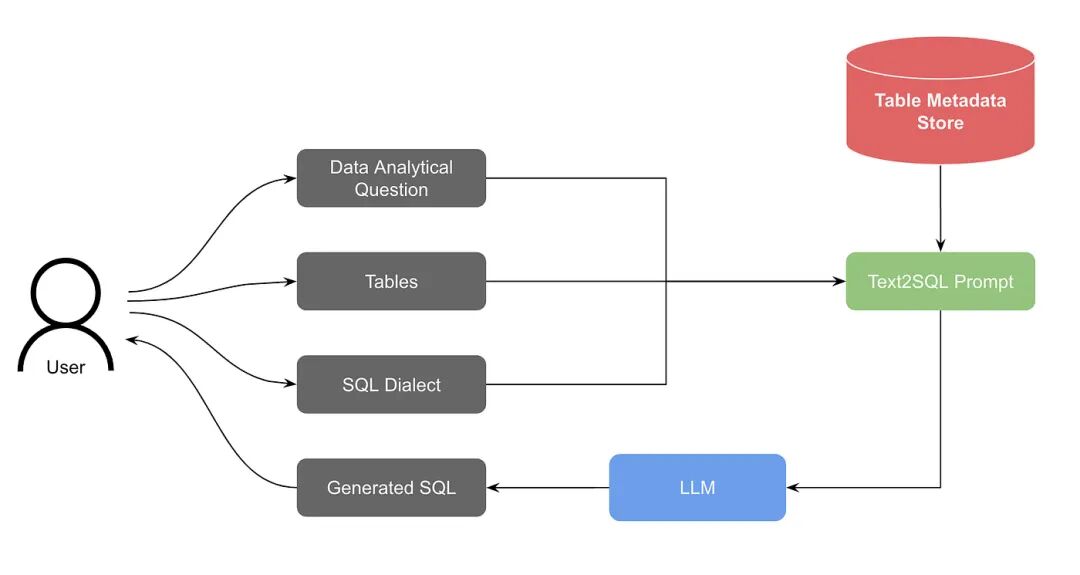
我们来看看它的架构:
- 用户提出分析性问题,并选择要使用的表。
- 系统从表元数据存储中检索相关表的 Schema(结构)。
- 将问题、选定的 SQL 方言和表 Schema 编译成一个 Text-to-SQL 提示词(Prompt)。
- 提示词被输入到 LLM(大型语言模型)中。
- 生成并向用户显示流式响应。
这种方法确实可行,但存在一个重大缺陷:用户往往不知道哪些表包含他们需要的答案。
第二版本
为了解决这个问题,他们的团队构建了一个更智能的系统,它采用了一种名为 检索增强生成(Retrieval-Augmented Generation, RAG) 的技术。系统不再要求用户提供表名,而是自动找到它们。它会搜索一个表格描述的集合,找出与用户问题最相关的描述。这种利用 RAG 进行表选择的方法,极大地提高了工具的用户友好性。
- 通过一个离线作业,生成一个包含表摘要和历史查询记录的向量索引。
- 如果用户未指定任何表,系统会将用户问题转换为 Embedding(嵌入向量),并对向量索引执行相似性搜索,以推断出最合适的 Top-N 个候选表。
- 将 Top-N 个表、表 Schema 和分析性问题编译成提示词,供 LLM 选择出最相关的 Top-K 个表。
- 将 Top-K 个表返回给用户进行验证或修改。
- 使用用户确认的表,继续标准的 Text-to-SQL 流程。
我们将复刻这个强大的两步方法。
我们的方案
我们将分两部分构建一个 SQL 生成器。首先,我们将创建核心引擎,负责将自然语言转换为 SQL。其次,我们将添加智能的表查找功能。
核心系统(Core System)
我们将构建一个基本链(chain),它接收一个问题和一张表名列表,并生成一个 SQL 查询。
- 用户输入: 提供分析性问题、选定的表和 SQL 方言。
- Schema 检索: 系统从元数据存储中获取相关的表 Schema。
- 提示词组装: 将问题、Schema 和方言组合成一个提示词。
- LLM 生成: 模型输出 SQL 查询。
- 验证与执行: 检查查询的安全性,执行查询并返回结果。
RAG 增强系统(RAG-Enhanced System)
我们将添加一个检索器(Retriever)。该组件可以为任何问题自动推荐正确的表。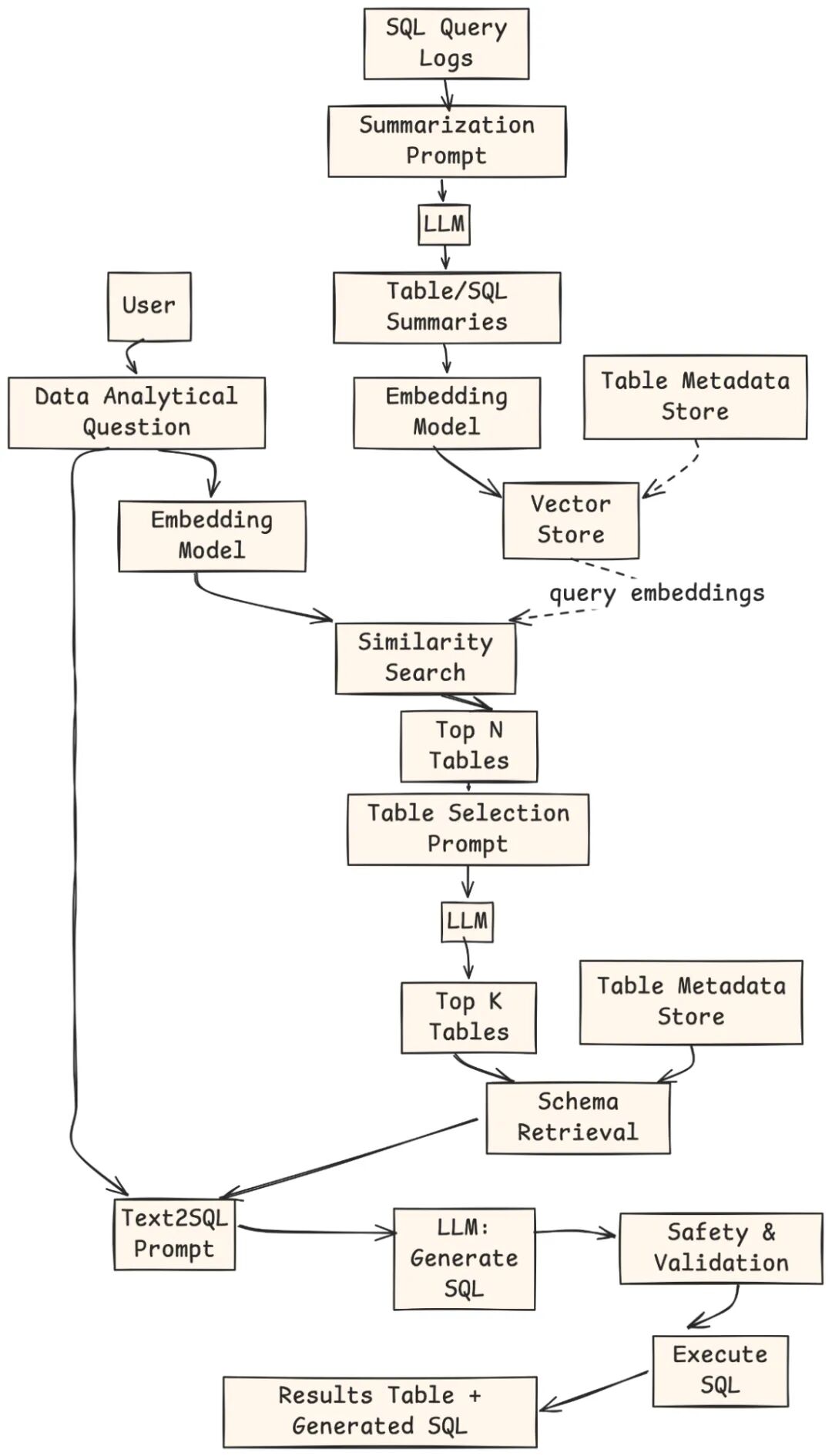
- 离线索引: SQL 查询日志被 LLM 总结、嵌入,并与元数据一起存储在向量索引中。
- 用户查询: 用户提供一个自然语言的分析性问题。
- 检索: 问题被嵌入,与向量存储进行匹配,返回 Top-N 个候选表。
- 表选择: LLM 对这些表进行排序和筛选,选出 Top-K 个最相关的表。
- Schema 检索与提示词构建: 系统获取这些表的 Schema,并构建 Text-to-SQL 提示词。
- SQL 生成: LLM 生成 SQL 查询。
- 验证与执行: 检查、执行查询,并将结果和 SQL 返回给用户。
我们将使用 Python、LangChain 和 OpenAI 来搭建这个 Text-to-SQL 系统。一个内存中的 SQLite 数据库将作为我们的数据源。
构建自己的 SQL 生成器
我们开始构建系统。请按照以下步骤创建一个可工作的原型。
步骤 1: 设置您的环境
首先,我们安装必要的 Python 库。LangChain 帮助我们连接各个组件。Langchain-openai 提供与 LLM 的连接。FAISS 帮助我们创建检索器,而 Pandas 用于美观地显示数据。
!pip install -qU langchain langchain-openai faiss-cpu pandas langchain_community
接下来,您必须配置您的 OpenAI API 密钥。该密钥允许我们的应用程序使用 OpenAI 的模型。
import osfrom getpass import getpassOPENAI_API_KEY = getpass("Enter your OpenAI API key: ")os.environ["OPENAI_API_KEY"] = OPENAI_API_KEY
步骤 2: 模拟数据库
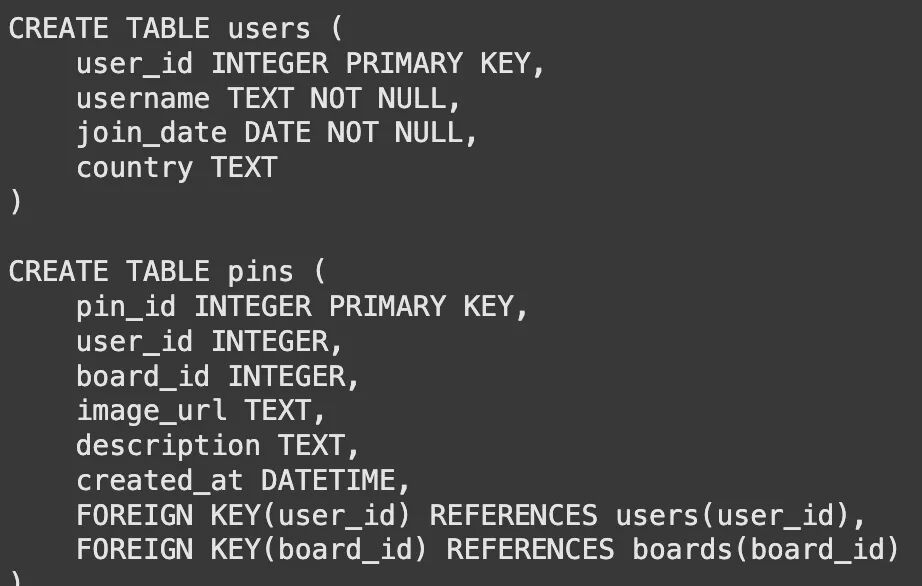
Text-to-SQL 系统需要一个可供查询的数据库。在本演示中,我们创建一个简单的内存式 SQLite 数据库。它将包含三个表:users(用户)、pins(图钉)和 boards(画板)。这个设置模仿了 Pinterest 数据结构的一个基本版本。
import sqlite3import pandas as pd# 创建一个连接到内存式 SQLite 数据库conn = sqlite3.connect(':memory:')cursor = conn.cursor()# 创建表cursor.execute('''CREATE TABLE users ( user_id INTEGER PRIMARY KEY, username TEXT NOT NULL, join_date DATE NOT NULL, country TEXT)''')cursor.execute('''CREATE TABLE pins ( pin_id INTEGER PRIMARY KEY, user_id INTEGER, board_id INTEGER, image_url TEXT, description TEXT, created_at DATETIME, FOREIGN KEY(user_id) REFERENCES users(user_id), FOREIGN KEY(board_id) REFERENCES boards(board_id))''')cursor.execute('''CREATE TABLE boards ( board_id INTEGER PRIMARY KEY, user_id INTEGER, board_name TEXT NOT NULL, category TEXT, FOREIGN KEY(user_id) REFERENCES users(user_id))''')# 插入示例数据cursor.execute("INSERT INTO users (user_id, username, join_date, country) VALUES (1, 'alice', '2023-01-15', 'USA')")cursor.execute("INSERT INTO users (user_id, username, join_date, country) VALUES (2, 'bob', '2023-02-20', 'Canada')")cursor.execute("INSERT INTO boards (board_id, user_id, board_name, category) VALUES (101, 1, 'DIY Crafts', 'DIY')")cursor.execute("INSERT INTO boards (board_id, user_id, board_name, category) VALUES (102, 1, 'Travel Dreams', 'Travel')")cursor.execute("INSERT INTO pins (pin_id, user_id, board_id, description, created_at) VALUES (1001, 1, 101, 'Handmade birthday card', '2024-03-10 10:00:00')")cursor.execute("INSERT INTO pins (pin_id, user_id, board_id, description, created_at) VALUES (1002, 2, 102, 'Eiffel Tower at night', '2024-05-15 18:30:00')")cursor.execute("INSERT INTO pins (pin_id, user_id, board_id, description, created_at) VALUES (1003, 1, 101, 'Knitted scarf pattern', '2024-06-01 12:00:00')")conn.commit()print("Database created and populated successfully.")
输出:
步骤 3: 构建核心 Text-to-SQL 链
语言模型无法直接查看我们的数据库。它需要了解表的结构,即 Schema。我们创建一个函数来获取 CREATE TABLE 语句。这些信息将告知模型关于列、数据类型和键的信息。
def get_table_schemas(conn, table_names): """Fetches the CREATE TABLE statement for a list of tables.""" schemas = [] cursor = conn.cursor() # Get cursor from the passed connection for table_name in table_names: query = f"SELECT sql FROM sqlite_master WHERE type='table' AND name='{table_name}';" cursor.execute(query) result = cursor.fetchone() if result: schemas.append(result[0]) return"\n\n".join(schemas)# 示例用法sample_schemas = get_table_schemas(conn, ['users', 'pins'])print(sample_schemas)
输出:
有了 Schema 函数,我们就可以构建我们的第一个链。一个提示词模板会指导模型完成任务。它将 Schema 和用户问题组合在一起。然后,我们将这个提示词连接到模型。
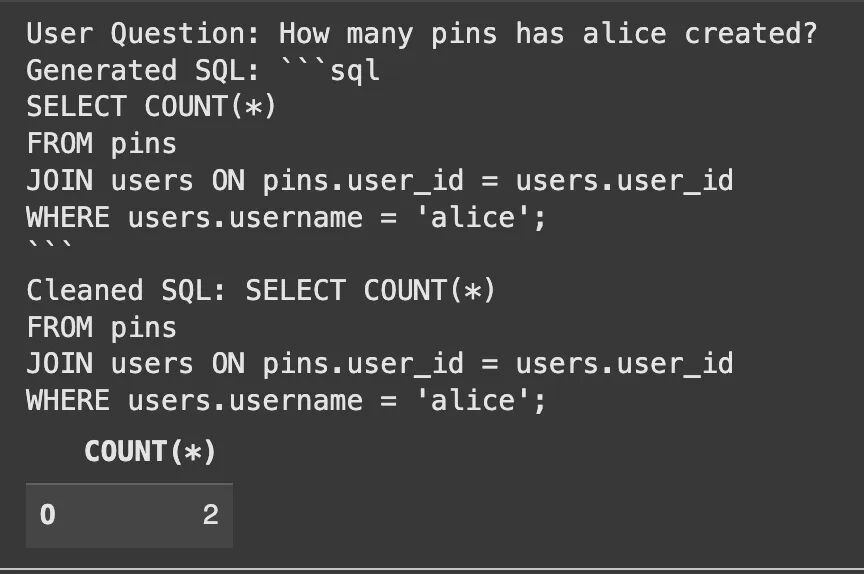
from langchain_core.prompts import ChatPromptTemplatefrom langchain_openai import ChatOpenAIfrom langchain_core.output_parsers import StrOutputParserfrom langchain_core.runnables import RunnablePassthrough, RunnableLambdaimport sqlite3 # Import sqlite3template = """You are a master SQL expert. Based on the provided table schema and a user's question, write a syntactically correct SQLite SQL query.Only return the SQL query and nothing else.Here is the database schema:{schema}Here is the user's question:{question}"""prompt = ChatPromptTemplate.from_template(template)llm = ChatOpenAI(model="gpt-4.1-mini", temperature=0)sql_chain = prompt | llm | StrOutputParser()# 让我们用一个明确提供表名的问题来测试我们的链。user_question = "How many pins has alice created?"table_names_provided = ["users", "pins"]# 在调用链之前,在主线程中检索 Schemaschema = get_table_schemas(conn, table_names_provided)# 将 Schema 直接传递给链generated_sql = sql_chain.invoke({"schema": schema, "table_names": table_names_provided, "question": user_question})print("User Question:", user_question)print("Generated SQL:", generated_sql)# 清理生成的 SQL,去除 markdown 代码块语法cleaned_sql = generated_sql.strip()if cleaned_sql.startswith("```sql"): cleaned_sql = cleaned_sql[len("```sql"):].strip()if cleaned_sql.endswith("```"): cleaned_sql = cleaned_sql[:-len("```")].strip()print("Cleaned SQL:", cleaned_sql)# 运行生成的 SQL 以验证其是否有效try: result_df = pd.read_sql_query(cleaned_sql, conn) # display(result_df) # Assuming a notebook environment print("\nQuery Result:") print(result_df)except Exception as e: print(f"Error executing SQL query: {e}")
输出示例:
步骤 4: 用 RAG 增强表选择功能
我们的核心系统运行良好,但它要求用户知道表名。这正是 Pinterest Text-to-SQL 团队解决的问题。现在,我们将实现 RAG 来进行表选择。我们首先为每个表编写简单、自然语言的摘要。这些摘要抓住了每个表内容的含义。
table_summaries = { "users": "Contains information about individual users, including their username, join date, and country of origin.", "pins": "Contains data about individual pins, linking to the user who created them and the board they belong to. Includes descriptions and creation timestamps.", "boards": "Stores information about user-created boards, including the board's name, category, and the user who owns it."}
接下来,我们创建一个向量存储。这个工具将我们的摘要转换为数字表示(Embedding)。通过相似性搜索,它允许我们为用户的提问找到最相关的表摘要。
from langchain_openai import OpenAIEmbeddingsfrom langchain_community.vectorstores import FAISSfrom langchain.schema import Document# 为每个摘要创建 LangChain Document 对象summary_docs = [ Document(page_content=summary, metadata={"table_name": table_name}) for table_name, summary in table_summaries.items()]embeddings = OpenAIEmbeddings()vector_store = FAISS.from_documents(summary_docs, embeddings)retriever = vector_store.as_retriever()print("Vector store created successfully.")
步骤 5: 将所有组件组合成 RAG 驱动的链
现在,我们构建最终的智能链。这个链将整个过程自动化。它接收一个问题,使用检索器找到相关表,获取它们的 Schema,然后将所有内容传递给我们的 sql_chain。
def get_table_names_from_docs(docs): """Extracts table names from the metadata of retrieved documents.""" return [doc.metadata['table_name'] for doc in docs]# 我们需要一种方法,在链中利用表名和连接来获取 Schema# 使用函数来获取 Schemadef get_schema_for_rag(x): table_names = get_table_names_from_docs(x['table_docs']) # 调用函数获取 Schema schema = get_table_schemas(conn, table_names) return {"question": x['question'], "table_names": table_names, "schema": schema}full_rag_chain = ( RunnablePassthrough.assign( table_docs=lambda x: retriever.invoke(x['question']) ) | RunnableLambda(get_schema_for_rag) # 使用 RunnableLambda 调用 Schema 获取函数 | sql_chain # 将包含 question, table_names, 和 schema 的字典传递给 sql_chain)# 让我们测试完整的系统。我们提出一个问题,但没有提到任何表。系统应该处理一切。user_question_no_tables = "Show me all the boards created by users from the USA."# 在字典中传递用户问题final_sql = full_rag_chain.invoke({"question": user_question_no_tables})print("User Question:", user_question_no_tables)print("Generated SQL:", final_sql)# 清理生成的 SQL,去除 markdown 代码块语法,使其更具鲁棒性cleaned_sql = final_sql.strip()if cleaned_sql.startswith("```sql"): cleaned_sql = cleaned_sql[len("```sql"):].strip()if cleaned_sql.endswith("```"): cleaned_sql = cleaned_sql[:-len("```")].strip()# 还要处理清理后可能存在的行首/行尾的换行符cleaned_sql = cleaned_sql.strip()print("Cleaned SQL:", cleaned_sql)# 验证生成的 SQLtry: result_df = pd.read_sql_query(cleaned_sql, conn) # display(result_df) # Assuming a notebook environment print("\nQuery Result:") print(result_df)except Exception as e: print(f"Error executing SQL query: {e}")
输出示例: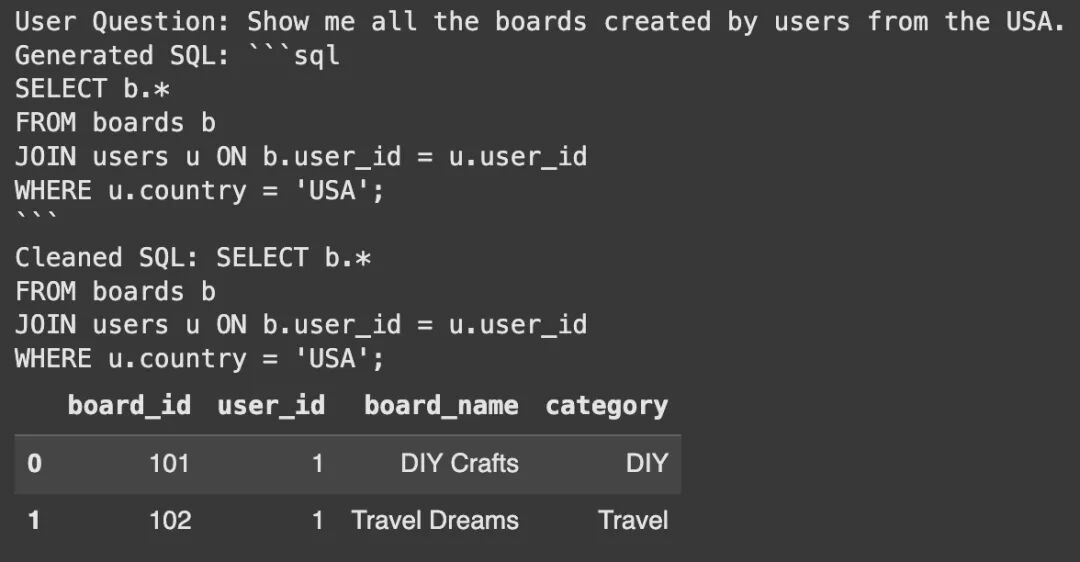
成功了! 系统自动识别了 users 和 boards 表。然后,它生成了正确的查询来回答问题。这展示了使用 RAG 进行表选择的强大能力。
总结
我们成功构建了一个原型,展示了如何搭建一个 SQL 生成器。要将其投入生产环境,还需要更多步骤,例如您可以自动化表摘要过程,也可以在向量存储中包含历史查询以提高准确性。这遵循了 Pinterest Text-to-SQL 团队所走的道路。这个基础为创建强大的数据工具提供了清晰的路径。
常见问题
1. Text-to-SQL 系统的工作原理是什么?
它通过大型语言模型(LLM)将自然语言问题(如“谁是我的顶级客户?”)作为输入,结合数据库 Schema(结构信息),生成一个可执行的 SQL 查询。
2. RAG 在 Text-to-SQL 中有什么作用?
检索增强生成(RAG)用于智能地选择最相关的数据库表。它不再要求用户手动指定表名,而是根据用户问题,在表的描述或历史查询记录中进行相似性搜索,从而自动推断出需要查询的表,极大地提高了易用性。
3. LangChain 在这个系统中扮演什么角色?
LangChain 是一个用于开发由语言模型驱动的应用程序的框架。在本指南中,它用于连接不同的组件(如提示词模板、LLM、向量存储和检索器),并将它们组织成一个可执行的链(chain),从而实现整个 Text-to-SQL 流程。
最后
为什么要学AI大模型
当下,⼈⼯智能市场迎来了爆发期,并逐渐进⼊以⼈⼯通⽤智能(AGI)为主导的新时代。企业纷纷官宣“ AI+ ”战略,为新兴技术⼈才创造丰富的就业机会,⼈才缺⼝将达 400 万!
DeepSeek问世以来,生成式AI和大模型技术爆发式增长,让很多岗位重新成了炙手可热的新星,岗位薪资远超很多后端岗位,在程序员中稳居前列。

与此同时AI与各行各业深度融合,飞速发展,成为炙手可热的新风口,企业非常需要了解AI、懂AI、会用AI的员工,纷纷开出高薪招聘AI大模型相关岗位。
最近很多程序员朋友都已经学习或者准备学习 AI 大模型,后台也经常会有小伙伴咨询学习路线和学习资料,我特别拜托北京清华大学学士和美国加州理工学院博士学位的鲁为民老师给大家这里给大家准备了一份涵盖了AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频 全系列的学习资料,这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

AI大模型系统学习路线
在面对AI大模型开发领域的复杂与深入,精准学习显得尤为重要。一份系统的技术路线图,不仅能够帮助开发者清晰地了解从入门到精通所需掌握的知识点,还能提供一条高效、有序的学习路径。

但知道是一回事,做又是另一回事,初学者最常遇到的问题主要是理论知识缺乏、资源和工具的限制、模型理解和调试的复杂性,在这基础上,找到高质量的学习资源,不浪费时间、不走弯路,又是重中之重。
AI大模型入门到实战的视频教程+项目包
看视频学习是一种高效、直观、灵活且富有吸引力的学习方式,可以更直观地展示过程,能有效提升学习兴趣和理解力,是现在获取知识的重要途径

光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
海量AI大模型必读的经典书籍(PDF)
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。
600+AI大模型报告(实时更新)
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。
AI大模型面试真题+答案解析
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 16
16 0
0- 0



 已为社区贡献244条内容
已为社区贡献244条内容

所有评论(0)