谷歌云Flink 核心组成及生态发展:实时数据处理的下一代引擎
摘要:Apache Flink作为实时数据处理领域的标杆,其三层架构(部署层、核心API层、流式引擎)提供高性能计算能力。完善的生态系统支持多数据源连接、SQL抽象和运行监控,广泛应用于实时数仓、风控检测和个性化推荐等场景。未来将深化流批一体技术,并加强AI融合,推动实时特征工程和持续学习发展,满足企业数字化转型需求。
目录
在数字化浪潮和 AI 时代的驱动下,企业对实时数据洞察的需求达到前所未有的高度。Apache Flink 正是满足这一需求的理想工具,它作为一个高性能、高吞吐的流式计算框架,已成为实时数据处理领域的事实标准。理解 Flink 的核心组成及其日益繁荣的生态系统,对于构建现代化的数据架构至关重要。
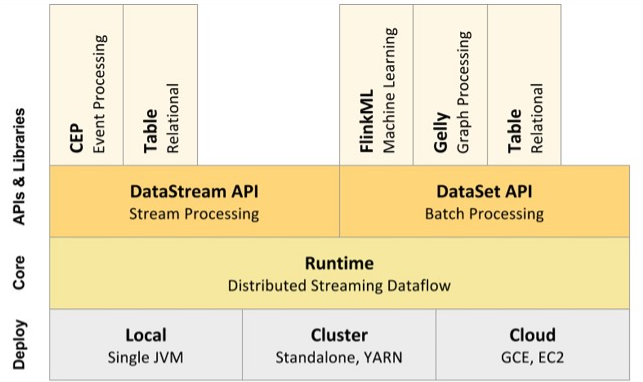
1. 核心架构:三层结构支撑实时计算
Flink 的架构设计清晰而高效,主要由三个层次构成:
部署层(Deployment Layer)
这一层负责 Flink 任务的部署与运行,支持多种集群管理器,包括 Standalone 模式、YARN、Kubernetes 等,确保 Flink 能够灵活地适应不同的基础设施环境。
核心 API 层(Core APIs Layer)
这是开发者直接交互的层面,包含用于流处理的 DataStream API 和用于批处理的 DataSet API(在新版本中,批处理也统一基于 DataStream API 实现)。这些 API 提供了丰富且灵活的转换操作,支持复杂的业务逻辑。
流式处理引擎(Streaming Engine)
位于最底层,是 Flink 性能的核心所在。它负责任务的调度、状态管理(State Management)、容错机制(如 Checkpoint 机制)以及精确一次(Exactly Once)语义的保证,确保流处理任务的高可靠和强一致性。
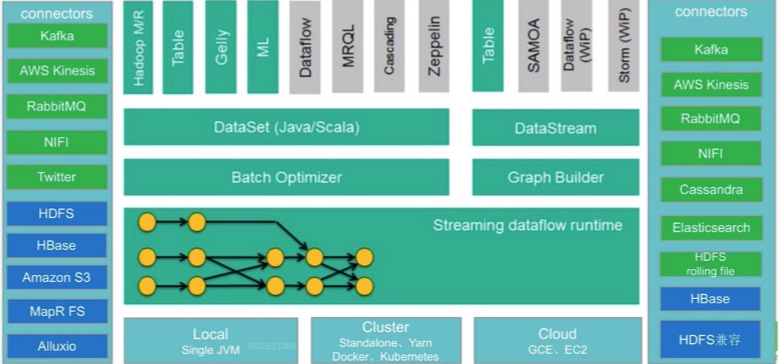
2. 生态集成:全方位连接数据世界
Flink 的成功离不开其开放和强大的生态系统,它致力于成为数据流动的中心枢纽:
连接器与源端
Flink 提供了大量成熟的连接器(Connectors),能够高效且稳定地与 Apache Kafka、Hadoop HDFS、Amazon S3、各类关系型和非关系型数据库(如 MySQL、Redis)以及消息队列等主流数据源进行双向数据交互。
上层应用与抽象
为了简化流处理应用的开发难度,Flink 提供了更高层次的抽象,即 Table API 和 Flink SQL。这使得开发者可以使用声明式的 SQL 语言进行流和批的统一查询与分析,极大地提高了开发效率。
运行时扩展
Flink 与 Prometheus、Grafana 等监控工具紧密集成,便于用户进行实时性能监测和故障排查。
3. 应用场景:驱动企业实时数据战略
Flink 的技术优势使其成为众多关键业务场景的首选:
实时数据仓库与 ETL
企业利用 Flink 构建实时数仓,将数据摄取、清洗、转换和加载(ETL)过程全部实时化,大幅缩短数据到洞察的周期。
实时风控与欺诈检测
金融机构使用 Flink 在毫秒级别对交易流进行分析,识别异常模式,实现实时风险预警和欺诈拦截。
个性化推荐与用户行为分析
互联网公司利用 Flink 实时捕捉用户点击、浏览行为,立即更新用户画像,从而提供即时且精准的个性化推荐服务。
4. 未来发展:流批一体与 AI 融合
Apache Flink 仍在快速发展,并引领着数据处理技术的未来:
流批一体的深化
未来的 Flink 将在统一的 API 和运行时上,实现批处理和流处理的无缝切换与执行,进一步简化用户的数据基础设施。
与 AI 融合
Flink 正加强与机器学习框架(如 TensorFlow、PyTorch)的集成,支持在流数据上进行实时特征工程、模型评分和持续学习,加速 AI 在业务中的落地。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 20
20 0
0- 0



 已为社区贡献24条内容
已为社区贡献24条内容

所有评论(0)