从0开始机器学习--2.ai模型概念+基础(什么是机器学习、特征选择、超参数、交叉验证?机器学习的类型有哪些?训练集-验证集-测试集?SOTA?Pipeline?backbone?zero-shot)
这篇文章总结了机器学习中的一些基础概念和关键技术,帮助读者构建一个初步的框架,尤其适合在面对实际应用和面试时作为概念性指导。在阅读论文时对于一些名词不会疑惑。
写在前面
这篇文章是该系列基础部分的第二篇,也应该是最后一篇,正如我在上一篇中所提到的,我个人认为机器学习基础分为三部分:python基础(更好的看懂现成的代码,有能力上手实践一番)、机器学习概念基础(便于理解一些博文中的专业术语,针对性的理解代码中某一个点的作用)、数学基础(线性代数:如矩阵运算;运筹于优化:如梯度下降法;概率论与数理统计:如贝叶斯定理)。对于数学基础的部分还是建议大家系统性的扎扎实实地跟随课程学习。
从这一篇开始,我们就正式进入了机器学习的范围中。这一篇文章是一篇统领式的概念介绍,主要的来源是一些对机器学习部分的面经,其中会出现一些概念大家可能初次接触时不知道是什么,不用过度纠结于这些概念,了解即可,我会在后面的笔记中介绍和详细分享这些内容。
在下一篇的内容中就会开始出现代码和实战的部分,敬请期待和继续关注!!!
- 1.python基础;
- 2.ai模型概念+基础;
- 3.数据预处理;
- 4.机器学习模型--1.编码(嵌入);2.聚类;3.降维;4.回归(预测);5.分类;
- 5.正则化技术;
- 6.神经网络模型--1.概念+基础;2.几种常见的神经网络模型;
- 7.对回归、分类模型的评价方式;
- 8.简单强化学习概念;
- 9.几种常见的启发式算法及应用场景;
- 10.机器学习延申应用-数据分析相关内容--1.A/B Test;2.辛普森悖论;3.蒙特卡洛模拟;
- 11.数据挖掘--关联规则挖掘
- 12.数学建模--决策分析方法,评价模型
- 13.主动学习(半监督学习)
- 以及其他的与人工智能相关的学习经历,如数据挖掘、计算机视觉-OCR光学字符识别、大模型等。
目录
机器学习
在学习机器学习之前,我们应该先有个概念,什么是机器学习?借用周志华老师《机器学习(西瓜书)》中这样的一段定义:“假设用𝑃 :来评估计算机程序在某任务类𝑇上的性能,若一个程序通过利用经验𝑬 在𝑇中任务上获得了性能改善,则我们就说关于𝑇和𝑃,该程序对𝐸进行了学习”。
看似有些拗口和抽象,实则就是通过计算手段,将对于我们人类来说是经验、对于计算机来说是数据的东西,用来改善系统自身的性能,这就是机器学习算法。





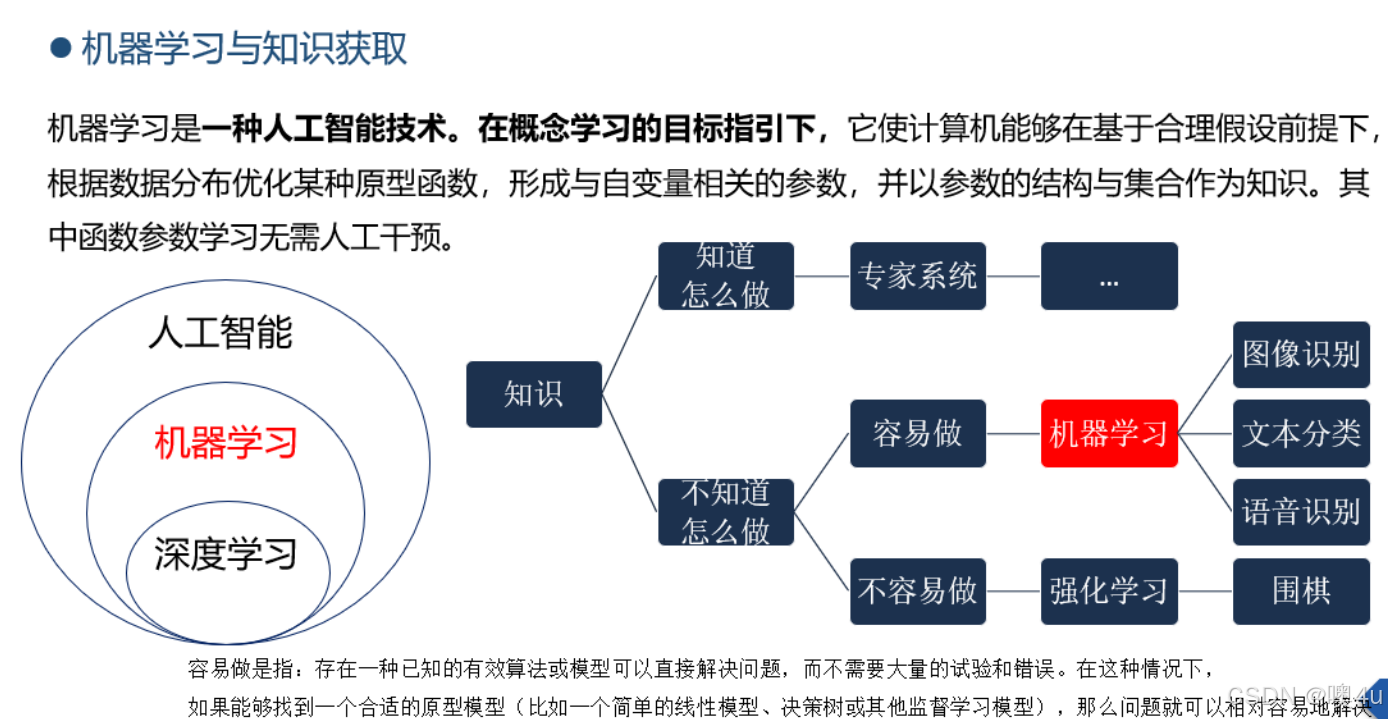
典型的机器学习过程
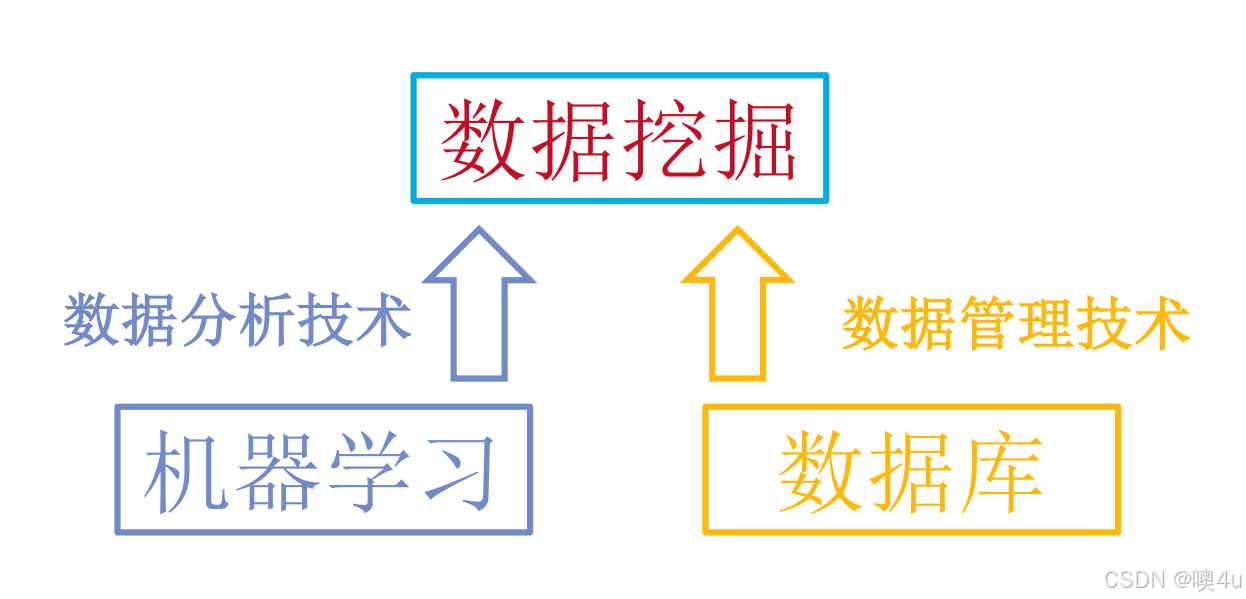
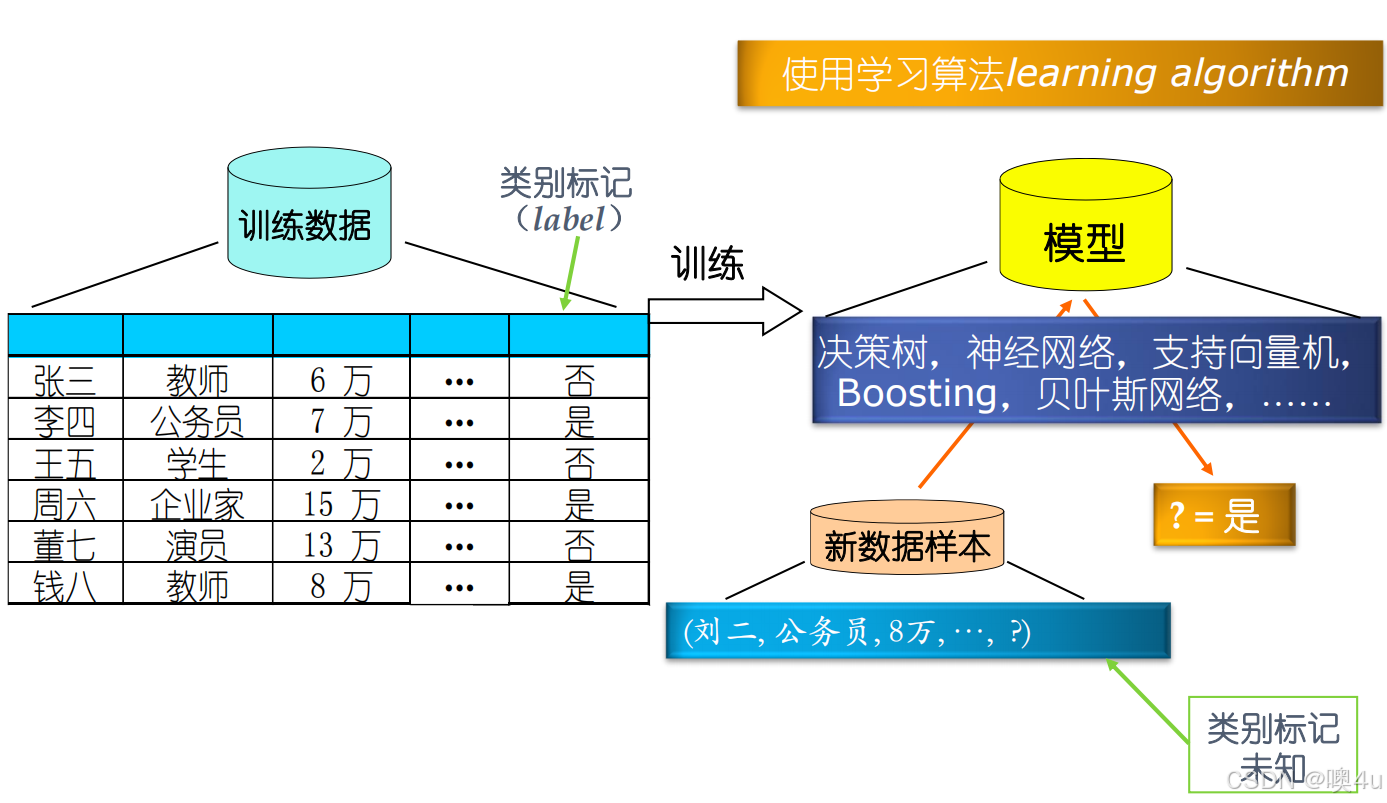
ai 模型概念
参数模型v.s.非参数模型
- 参数模型:通常假设数据遵循某种特定的分布(如正态分布,或线性回归OLS那些假设(会在第四篇《机器学习模型--回归》中具体介绍)),因此需要对模型的形式进行假设。复杂度相对较低,由于参数数量有限,模型更易于解释和理解。线性回归、逻辑回归、ARIMA模型等。
- 非参数模型:不依赖于特定的分布假设,更加灵活,适用于数据分布不明确的情况。复杂度较高,可能会随着数据量的增加而增加,更适合捕捉复杂的模式。K均值聚类(会在第四篇《机器学习模型--回归》中具体介绍)、核密度估计、最近邻算法等。
超参数
指在机器学习模型训练之前设定的参数,它们影响模型的学习过程和性能,但在训练过程中不会被模型直接学习。超参数通常需要通过实验来调整和优化。在后续模型介绍的章节中,会具体介绍在各个模型中哪些属于超参数。
调整超参数通常采用以下方法:
- 1. 网格搜索(Grid Search):系统地遍历预定义的超参数组合。如果超参数是连续的,可以将参数离散化,共有m*n*......种超参数组合。
from sklearn import datasets from sklearn.model_selection import GridSearchCV, train_test_split from sklearn.svm import SVC from sklearn.metrics import classification_report # 加载数据集(这里以鸢尾花数据集为例) iris = datasets.load_iris() X = iris.data y = iris.target # 将数据集分为训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42) # 定义模型(这里以支持向量机为例) model = SVC() # 定义要搜索的超参数网格 param_grid = { 'C': [0.1, 1, 10, 100], # 正则化参数 'gamma': [1, 0.1, 0.01, 0.001], # 核系数 'kernel': ['rbf', 'linear', 'poly'] # 核类型 } # 创建网格搜索对象 grid_search = GridSearchCV( estimator=model, param_grid=param_grid, cv=5, # 5折交叉验证 scoring='accuracy', # 评估指标 verbose=2, # 输出详细日志 n_jobs=-1 # 使用所有可用的CPU核心 ) # 在训练集上执行网格搜索 grid_search.fit(X_train, y_train) # 输出最佳参数和最佳得分 print("Best parameters found: ", grid_search.best_params_) print("Best accuracy score: ", grid_search.best_score_) # 使用最佳模型在测试集上进行预测 best_model = grid_search.best_estimator_ y_pred = best_model.predict(X_test) # 输出分类报告 print("\nClassification Report:") print(classification_report(y_test, y_pred)) - 2. 随机搜索(Random Search):在超参数空间中随机选择组合进行测试。
- 3. 贝叶斯优化(Bayesian Optimization):利用概率模型高效地探索超参数空间。
-
Optuna 是一个用于超参数优化的开源框架,特别适用于机器学习和深度学习领域,能够自动调整搜索策略以找到最佳的超参数组合。其核心是定义一个目标函数,该函数接受一组超参数并返回一个评估值(如验证集上的损失)。
import optuna from sklearn import datasets from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score import xgboost as xgb # 加载数据集(这里以鸢尾花数据集为例) iris = datasets.load_iris() X = iris.data y = iris.target # 划分训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42) # 定义 Optuna 目标函数 def objective(trial): # 定义待优化的超参数 params = { 'objective': 'multi:softmax', # 多分类任务 'num_class': 3, # 类别数 'eval_metric': 'mlogloss', # 评估指标 'booster': trial.suggest_categorical('booster', ['gbtree', 'gblinear', 'dart']), 'lambda': trial.suggest_float('lambda', 1e-8, 1.0, log=True), 'alpha': trial.suggest_float('alpha', 1e-8, 1.0, log=True), 'max_depth': trial.suggest_int('max_depth', 3, 10), 'eta': trial.suggest_float('eta', 1e-3, 0.1, log=True), 'gamma': trial.suggest_float('gamma', 1e-8, 1.0, log=True), 'grow_policy': trial.suggest_categorical('grow_policy', ['depthwise', 'lossguide']), 'subsample': trial.suggest_float('subsample', 0.5, 1.0), 'colsample_bytree': trial.suggest_float('colsample_bytree', 0.5, 1.0), 'min_child_weight': trial.suggest_int('min_child_weight', 1, 10), } # 训练 XGBoost 模型 model = xgb.XGBClassifier(**params) model.fit(X_train, y_train) # 在验证集上评估 y_pred = model.predict(X_test) accuracy = accuracy_score(y_test, y_pred) return accuracy # Optuna 会最大化这个值(可以返回 `-accuracy` 改为最小化) # 创建 Optuna study 并运行优化 study = optuna.create_study(direction='maximize') # 最大化 accuracy study.optimize(objective, n_trials=100) # 运行 100 次试验 # 输出最佳超参数和最佳准确率 print("Best trial:") trial = study.best_trial print(f" Accuracy: {trial.value:.4f}") print(" Params: ") for key, value in trial.params.items(): print(f" {key}: {value}") # 使用最佳参数训练最终模型 best_params = trial.params best_model = xgb.XGBClassifier(**best_params) best_model.fit(X_train, y_train) # 在测试集上评估 y_pred = best_model.predict(X_test) final_accuracy = accuracy_score(y_test, y_pred) print(f"\nFinal Model Accuracy: {final_accuracy:.4f}")Optuna 默认使用 TPE(Tree-structured Parzen Estimator)算法 ,其核心思想是通过历史试验结果将超参数空间划分为 高低表现区域概率模型 p(x∣y), 预测哪些超参数组合可能更好。具体步骤如下:- 首先随机选择一组超参数组合进行试验,记录其表现。
- 然后构建高低表现组的概率密度函数模型,对于每个超参数组合 x,计算其期望提升(Expected Improvement,EI)值:
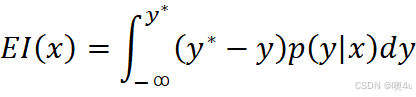
- 选择 EI 值最大的组合进行下一轮试验,直到达到预设试验次数或收敛条件。
-
- 4. 动态资源分配
- 5. 神经网络架构搜索
交叉验证
帮助评估模型的泛化能力和调整超参数,但不能完全防止过拟合(会在第四篇《机器学习模型--分类》中具体介绍)。
- 交叉验证(cross-validation):将数据集分为训练集和测试集(具体函数如何实现会在第四篇《机器学习模型--回归》中具体介绍),训练集用于训练模型,测试集用于评估模型的性能。
- K折交叉验证(K-fold cross-validation):将数据集分为K个子集,每次用K-1个子集训练模型,用剩余的一个子集测试模型。此处只介绍这样一个简单的概念,具体会在《7.评估》中介绍。
- k个模型取平均值得到最终测试集的大致性能。
梯度下降
更详细的梯度会在《6.1》中详细涉及。
梯度下降是机器学习中用来优化模型的一个算法。它的主要目的是找到模型参数的最佳值,让模型的预测误差最小化。
简单来说,梯度下降就像下山,每一步都朝着误差最小的方向走,直到找到最低点。每次迭代,算法根据误差的大小调整参数,逐渐让模型表现得更好。分别对不同的参数进行优化,而不是一起优化。
- 批量梯度下降(gradient descent):每次更新所有样本的梯度,计算代价函数的梯度。但由于每次考虑所有样本,速度很慢。
- 随机梯度下降(stochastic g d):每次更新一个样本的梯度,计算代价函数的梯度。迭代速度快,但不一定每次都朝着收敛方向进行。(离群点、噪音点)
- 小批量梯度下降(mini batch g d):每次更新一小部分样本的梯度,计算代价函数的梯度。(batch:批,会在第六篇《神经网络模型--基础》中具体介绍)
学习率(步长)
会在第六篇《神经网络模型--基础》中具体介绍。
- 学习率决定了更新的幅度,太大会导致震荡,太小会导致收敛慢。
- 梯度下降的方向*步长=更新的具体幅度
三种不同的学习类型对比
机器学习主要有三大类型,监督学习、非监督学习、强化学习,在此系列文章中都会有所涉及,以下是对他们概念上的对比:
1. 训练数据上:
- 监督学习和无监督学习的数据是静态的,不需要与环境交互;
- 强化学习的数据是时序的,不是独立同分布的数据。
2. 学习方式上(定义、数据类型):
- 监督学习致力于从已知标签中学习(分类、回归),目标是学习输入到输出的映射关系;
- 无监督学习致力于从无标签的数据中找到数据间的隐藏关系(聚类、降维、特征学习),目标是发现数据中的潜在结构或模式;
- 强化学习通过尝试来发现哪些动作带来更多的奖励,有延迟奖励的机制(下棋)。
数据集种类
我们在读文章的时候,经常会看到类似这样的语句:“我们将数据集划分为训练集-验证集-测试集:70-15-15”,这句话的意思就是按70%-15%-15%的比例,将整个数据集(通常是随机)划分为训练集-验证集-测试集三部分,以下是每部分的简单介绍:
- 训练集:让模型学习,并从中发现经验的集合,直接出现在模型的训练过程中。
- 验证集:检验模型学习到的经验规律是否有效的集合,若无效或效果不好,则重新去训练集中学习,以“参照、评估”的形式出现在模型的训练过程中。
- 测试集:全新的集合,评估模型在同类问题、未知数据上的泛化能力。绝对不出现在模型的训练过程中。
具体的划分函数其实在sklearn库中已经打包好了,会在本专栏《4.3回归》中出现代码时具体介绍。
如何验证是另一个专题,会在本专栏《7.评估》中介绍。
特征选择
特征分为:
- 有关特征:对该机器学习任务有正向作用
- 无关特征:对该任务无用
- 冗余特征:可通过其他特征组合或运算等手段获得
特征选择的过程
特征选择的过程: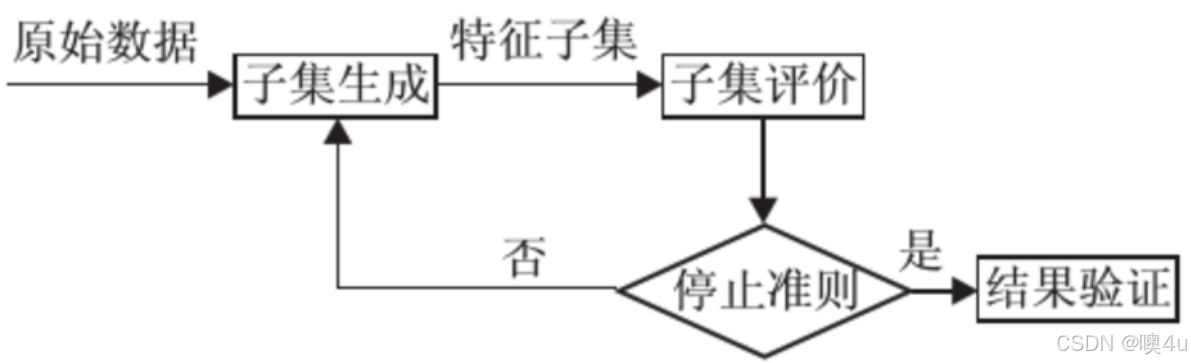
- 划分子集
- 评价子集(用信息熵-信息增益来评价)(具体可见本专栏文章《信息论研讨》)
- 根据子集评价结果重新划分子集
- 2-4循环直至停止条件
常见的特征选择方法主要分为三类: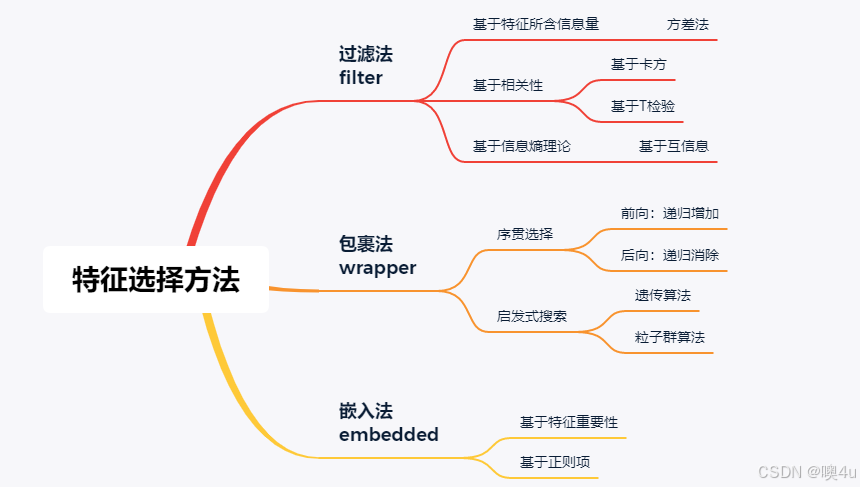
filter-based:
1.基础筛选法(方差):
·移除常量;
·移除准常量;
2.单变量统计法:
·SelectKBest(F检验-p值/卡方检验);
·SelectPercentile;
·稀疏数据的特征选择(卡方/互信息);
·误差控制方法(假阳性率/错误发现率/族系误差);
·通用选择器GenericUnivariateSelect;
3.信息增益法(互信息):
·互信息分类mutual_info_classif;
·互信息回归mutual_info_regression;
4.Fisher评分法(卡方检验):
·协同结合于SelectKBest方法SelectKBest(chi2, k);
5.ANOVA方差分析F值法(F=组内方差÷组间方差):
·SelectKBest(f_classif, k),评估线性相关性;
6.热力图相关系数矩阵(相关性):
·识别冗余变量--好的特征应与目标变量高度相关,特征间应低相关;
·皮尔逊相关系数(要求正态分布,仅检测线性);
·斯皮尔曼相关系数(适合有明显离群点、怀疑有非线性关系的情况);
wrapper_based:
1.前向选择;
2.后向消除;
3.穷举特征选择;
4.递归特征消除;
5.带交叉验证的递归消除;
embedded_based:
1.LASSO回归;
2.随机森林重要性得分。
- 过滤式:不依赖学习器也不依赖学习任务。计算“相关统计量”,赋阈值,进行筛选。

- Relief (Relevant Features) 方法,其时间开销随采样次数和原始特征数线性增长,运行效率很高。
- 基本思想是:好的特征应该使同类样本的"距离"更近,而异类样本的"距离"更远。它通过统计量来衡量特征的重要性,统计量越大表示特征越重要。
- 对于一个随机样本R,在同类样本中寻找R的最近邻H(nearest hit),在异类样本中寻找R的最近邻M(nearest miss)
- 对于每个特征A,更新其权重(执行m次迭代):W[A] = W[A] - diff(A,R,H)/m + diff(A,R,M)/m。其中diff(A,R1,R2)计算样本R1和R2在特征A上的差异。每次迭代根据最近邻的差异进行更新,最终权重范围在[-1,1]之间,值越大特征越重要。
- 连续型特征:diff(A,R1,R2) = |R1[A] - R2[A]| / (max(A) - min(A))
- 离散型特征:diff(A,R1,R2) = 0 (如果R1[A] == R2[A]);1 (其他情况)
- Relief (Relevant Features) 方法,其时间开销随采样次数和原始特征数线性增长,运行效率很高。
- 包裹式:给定学习器的特定方法,对于当前学习器的性能比过滤式方法好,但是计算开销大。
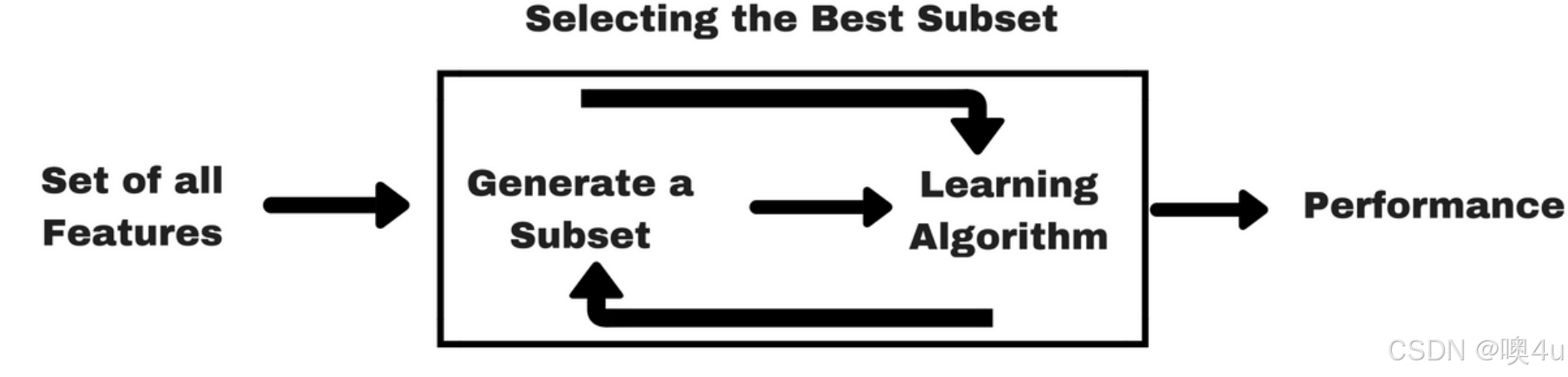
- LVW (拉斯维加斯框架) 方法:
- 其核心思想是:将特征选择看作一个搜索优化问题,直接使用最终学习器的性能作为评价标准,采用随机策略在特征子集空间中进行搜索。
- 启发式搜索部分具体可见本专栏文章《9.启发式算法》
- LVW (拉斯维加斯框架) 方法:
- 嵌入式:将特征选择的过程与学习器训练过程融为一体。
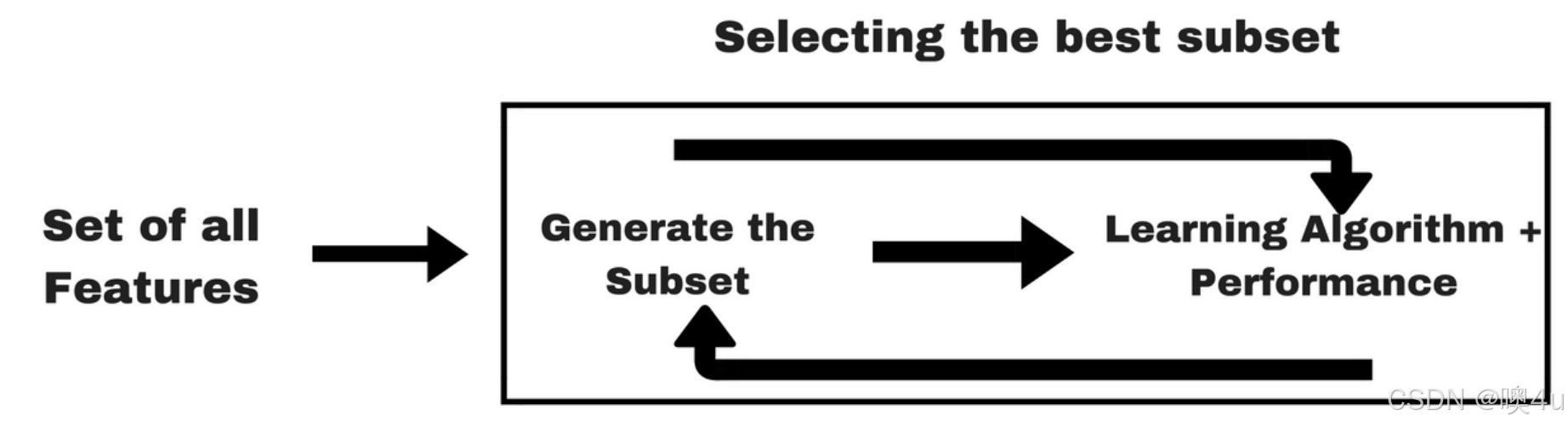
- 例子可见本专栏《5.正则化方法》-L1正则化。
Python代码支持
可以用Scikit-learn的VarianceThreshold方法来识别并删除数据中的常量特征(即所有样本取值完全相同的特征)。(or准常量特征--如设置阈值为0.1)
from sklearn.feature_selection import VarianceThreshold
sel = VarianceThreshold(threshold=0)
sel.fit(X_train)
# 查看被移除的特征
constant_columns = [column for column in X_train.columns
if column not in X_train.columns[sel.get_support()]]
print(f"Removed {len(constant_columns)} constant features: {constant_columns}")
# 获取筛选后的特征
X_train_filtered = sel.transform(X_train) # 返回NumPy数组
# 或
X_train_filtered = pd.DataFrame(sel.transform(X_train),
columns=X_train.columns[sel.get_support()]) # 保留列名单特征选择
- SelectKBest:选择统计检验得分最高的K个特征
- SelectPercentile:选择得分最高的前n%特征
from sklearn.datasets import load_digits
from sklearn.feature_selection import SelectKBest, chi2
from sklearn.feature_selection import SelectPercentile, chi2
X, y = load_digits(return_X_y=True)
X_new = SelectKBest(chi2, k=2).fit_transform(X, y)
X_new = SelectPercentile(chi2, percentile=10).fit_transform(X, y)-
基于F检验的方法
-
仅能检测线性相关性
-
计算效率高
-
需要满足正态分布假设
-
-
互信息方法
-
可检测任意统计依赖关系(非线性/非单调)
-
属于非参数方法
-
需要更大样本量保证估计准确性
-
当处理稀疏数据(以稀疏矩阵表示的数据)时,以下方法可以直接处理而无需转换为密集矩阵:
-
卡方检验 (chi2)
-
适用于分类问题
-
直接处理稀疏特征矩阵
-
-
互信息回归 (mutual_info_regression)
-
适用于回归问题
-
保持数据稀疏性
-
-
互信息分类 (mutual_info_classif)
-
适用于分类问题
-
支持稀疏输入
-
from sklearn.feature_selection import mutual_info_classif
# 计算特征与目标的互信息
mi_scores = mutual_info_classif(X, y)
print(f"Top feature MI scores: {np.sort(mi_scores)[-5:]}")
from sklearn.feature_selection import mutual_info_regression
# 计算特征与连续目标变量的互信息
mi_scores = mutual_info_regression(
X,
y,
n_neighbors=5, # 近邻数(默认3)
random_state=42
)
# 筛选Top 15%特征
from sklearn.feature_selection import SelectPercentile
selector = SelectPercentile(mutual_info_regression, percentile=15)
X_reduced = selector.fit_transform(X, y)根据相关系数
# Load iris data
from sklearn.datasets import load_iris
iris = load_iris()
# Create features and target
X = iris.data
y = iris.target
# Convert feature matrix into DataFrame
df = pd.DataFrame(X)
# View the data frame
print(df)
# Create correlation matrix
corr_matrix = df.corr()
print(corr_matrix)
# Create correlation heatmap
plt.figure(figsize=(8,6))
plt.title('Correlation Heatmap of Iris Dataset')
a = sns.heatmap(corr_matrix, square=True, annot=True, fmt='.2f', linecolor='black')
a.set_xticklabels(a.get_xticklabels(), rotation=30)
a.set_yticklabels(a.get_yticklabels(), rotation=30)
plt.show()
# Select upper triangle of correlation matrix
upper = corr_matrix.where(np.triu(np.ones(corr_matrix.shape), k=1).astype(bool))
# np.ones(corr_matrix.shape) 创建与相关系数矩阵同维度的全1矩阵
# np.triu(..., k=1) 提取主对角线(k=0)之上的元素(k=1从第一条对角线开始),下方元素置0
# astype(bool) 将0/1矩阵转换为False/True矩阵,满足where()方法的条件输入要求
# Find index of feature columns with correlation greater than 0.9
to_drop = [column for column in upper.columns if any(upper[column].abs() > 0.9)]
print(to_drop)
# Drop Marked Features
df1 = df.drop(df.columns[to_drop], axis=1)
print(df1)
mlxtend 库有 Sequential Feature Selection (SFS) 方法可以逐步选择最优特征子集(前向or后向)。
from mlxtend.feature_selection import SequentialFeatureSelector as SFS
# 初始化Sequential Feature Selector (SFS)
sfs1 = SFS(
estimator=RandomForestRegressor(), # 使用的基模型(随机森林回归)
k_features=10, # 最终选择的特征数量
forward=True, # 使用前向选择(若False则为后向消除)
floating=False, # 是否启用浮动搜索(允许增删特征)
verbose=2, # 日志详细程度(0静默,1简略,2详细)
scoring='r2', # 评估指标(回归问题用R²)
cv=3 # 交叉验证折数
)
# 在训练集上执行特征选择(需将X_train转为numpy数组)
sfs1 = sfs1.fit(np.array(X_train), y_train)
# 输出选择的特征
print(sfs1.k_feature_idx_)
print(X_train.columns[list(sfs1.k_feature_idx_)])
#tips####################################################
# k_features='best' # 自动选择最佳数量
# 或
# k_features=(5, 15) # 限制选择5-15个特征穷举特征选择:ExhaustiveFeatureSelector
from mlxtend.feature_selection import ExhaustiveFeatureSelector as EFS
# 穷举特征选择(适合特征数<20的情况)
efs = EFS(
estimator=RandomForestRegressor(), # 基础模型
min_features=10, # 最少选择10个特征
max_features=10, # 最多选择10个特征(固定输出10个)
scoring='r2', # 评估指标(回归用r2,分类用accuracy)
cv=3, # 交叉验证折数
print_progress=True # 显示进度条
)
# 执行特征选择(X_train需为numpy数组或DataFrame)
efs = efs.fit(np.array(X_train), y_train)
# 输出结果
print("\n最佳10个特征的列索引:", efs.best_idx_)
print("对应特征名称:", [X_train.columns[i] for i in efs.best_idx_])
print("最佳R²分数:", efs.best_score_)
# 获取筛选后的数据集
X_train_efs = X_train.iloc[:, list(efs.best_idx_)]“SOTA”
在机器学习领域中,“SOTA” 通常是 “State of the Art” 的缩写,意为 “当前最优” 或 “最先进” 的方法或成果。在学术论文或技术报告中,人们常用这个词来表示在特定任务或数据集上达到的最高水平或最佳性能。它不一定只指某一个具体的模型,而是指在该领域(或该任务)中,目前已知能够取得最高指标、最优结果的方法、模型或系统。
pipeline
用于将多个数据处理步骤和机器学习模型封装为一个整体。
- - 顺序执行:按照定义的步骤依次执行(如特征编码 → 特征工程 → 偏态校正 → 独热编码)。
- - 避免数据泄漏:确保测试数据仅在transform阶段使用,防止预处理步骤误用全局统计量(如用测试集的均值填充训练集)。
- - 减少重复代码:无需手动逐个调用转换器。
- - 一键式操作:只需调用fit或transform一次,即可完成所有步骤。
- - 联合参数搜索:可通过GridSearchCV同时调整流水线中所有步骤的参数(如skewness的偏态阈值)。
from sklearn.pipeline import make_pipeline, Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import Ridge
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
import numpy as np
from sklearn.datasets import load_boston
# 加载数据
X, y = load_boston(return_X_y=True)
# 拆分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建一个包含预处理(标准化)和回归模型的pipeline
pipeline = make_pipeline(
StandardScaler(),
Ridge(alpha=1.0)
)
# 拟合训练数据
pipeline.fit(X_train, y_train)
# 预测
y_pred = pipeline.predict(X_test)
# 评估性能
rmse = np.sqrt(mean_squared_error(y_test, y_pred))
print("RMSE:", rmse)
backbone
Backbone,中文常译为“骨干网络”或“主干网络”,指的是一个深度学习模型中负责从原始输入数据中提取核心、分层特征的部分。
你可以把它想象成一个人的 “脊柱” 或一棵树的 “主干”。
- 脊柱/主干 本身不是完成最终动作(如走路、思考)的器官,但它为所有器官提供了核心支撑和信号传递通道。
- 同样,Backbone 本身通常不直接完成最终任务(如分类、检测),但它为后续的 “头部” 提供了处理任务所必需的信息基础。
Backbone 的关键特性:
- 分层特征提取:这是Backbone最重要的特性。通过层层堆叠的神经网络(如卷积层),它能够从低级到高级、从具体到抽象地理解数据。
- 可迁移性/通用性:一个在大型数据集(如ImageNet)上预训练好的Backbone,学到的“如何看图像”的能力是通用的。我们可以把它拿过来,接上不同的Head,去解决各种各样的下游任务(车辆分类、医疗影像分析、卫星图像识别等)。这极大地节省了时间和计算资源,这就是 “迁移学习” 的核心。
- 与Head的协作:
- 模型 = Backbone + Head
- Backbone 是通用的特征提取器。它不关心最终任务是“分类”还是“检测”,它的核心职责就是“看懂”图片,并把看懂的结果(特征)交给下游。
- Head 是特定的任务求解器。它接收Backbone提供的特征,并专门解决某个具体任务。
zero-shot
依赖预训练阶段从海量通用数据中学到的先验知识和泛化能力,针对当前这个具体任务的示例数量为零的情况下,直接完成该任务。
总结
这篇文章总结了机器学习中的一些基础概念和关键技术,帮助读者构建一个初步的框架,尤其适合在面对实际应用和面试时作为概念性指导。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 32
32 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)