深度学习之人工神经网络总结
本文介绍了神经网络的基本原理与优化方法。主要内容包括:1)神经网络模型构建,包括神经元计算(线性加权+非线性激活)和层级结构设计;2)激活函数的选择策略,隐藏层推荐ReLU,输出层根据任务类型选择Sigmoid或Softmax;3)参数初始化方法,如Kaiming和Xavier初始化;4)损失函数设计,包括分类任务中的交叉熵损失和回归任务中的SmoothL1损失;5)优化方法,重点介绍了动量法、自
一、神经网络介绍
1.1 什么是神经网络模型
-
深度学习计算模型,仿生生物学神经元构造
-
通过模拟生物神经网络的处理信息方式,建立的计算模型
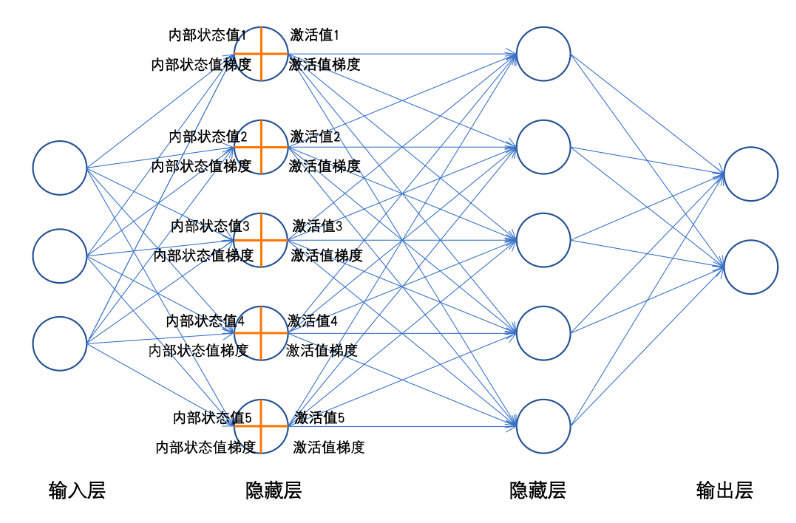
1.2 如何构造神经网络模型
神经元基本结构
-
由多个神经元构成
-
每个神经元计算过程:
-
加权求和:
z = wx + b(线性因素) -
激活值计算:通过激活函数(引入非线性因素)
-
网络层级结构
| 层级 | 作用 | 特点 |
|---|---|---|
| 输入层 | 输入样本初始特征值x | 仅一层 |
| 隐藏层 | 提取复杂的特征值 | 可多层,每层神经元数量决定提取特征的复杂度 |
| 输出层 | 输出模型预测结果 | 根据任务类型设计 |

二、激活函数
2.1 作用
给模型增加非线性功能, 让模型(神经元)既可以做分类, 还可以做回归问题
2.2 常见激活函数
"""
案例:
绘制激活函数ReLU的 函数图像 和 导数图像.
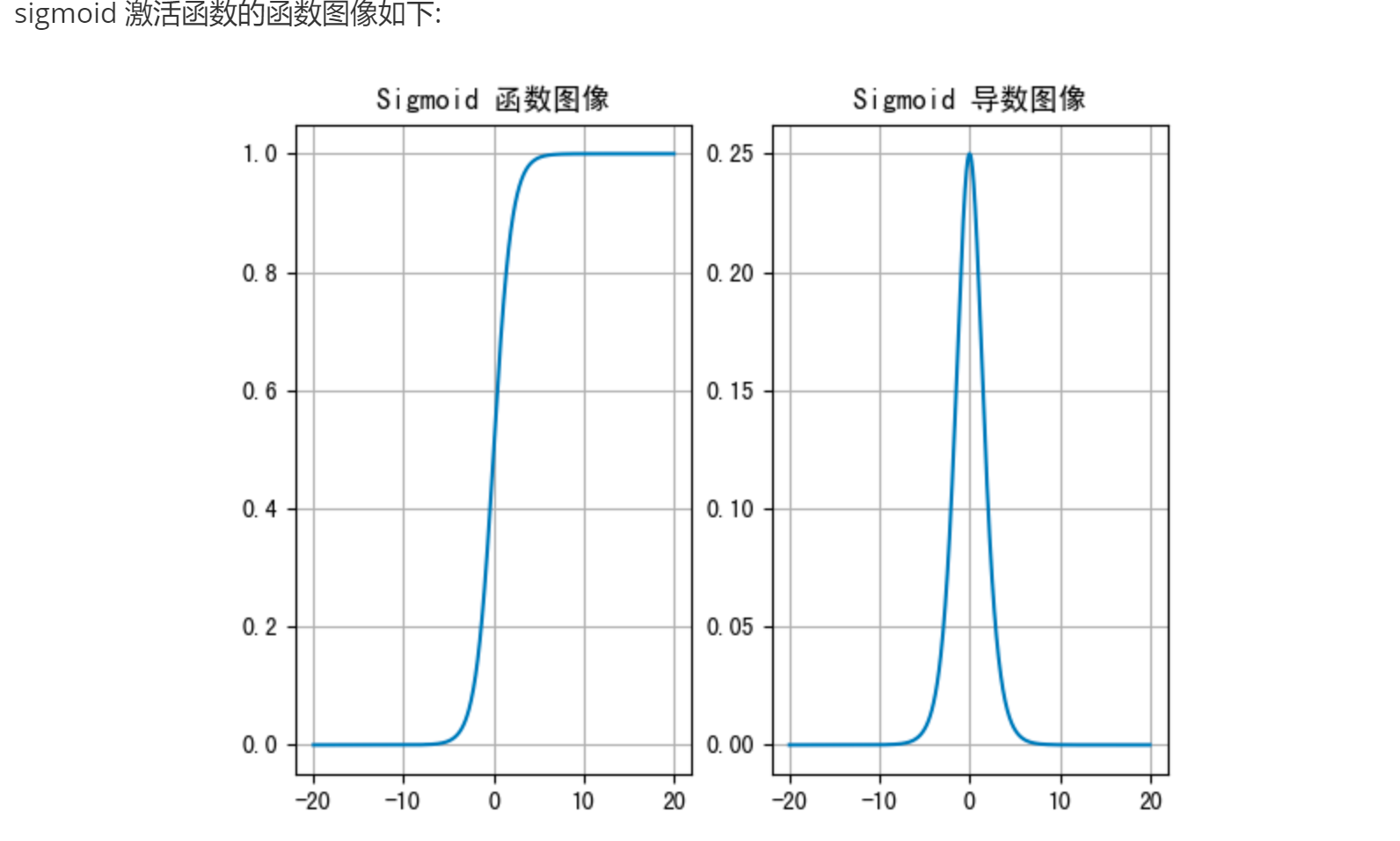
Sigmoid激活函数介绍:
激活函数的目的:
给模型增加非线性功能, 让模型(神经元)既可以做分类, 还可以做回归问题.
激活函数的分类:
Sigmoid:
ReLU:
Tanh:
Softmax:
Sigmoid激活函数:
主要应用于 二分类的输出层, 且适用于 浅层神经网络(不超过5层).
数据在 [-6, 6]之间有效果, 在[-3, 3]之间效果明显, 会将数据值映射到: [0, 1]
求导后范围在 [0, 0.25]
Tanh:
主要应用于 隐藏层, 且适用于 浅层神经网络(不超过5层).
数据在 [-3, 3]之间有效果, 在[-1, 1]之间效果明显, 会将数据值映射到: [-1, 1]
求导后范围在 [0, 1], 较之于Sigmoid, 收敛速度快.
ReLU:
计算公式为: max(0, x), 计算量相对较小, 训练成本低. 多应用于 隐藏层, 且适合 深层神经网络.
求导后, 值要么是0, 要么是1, 较之于Tanh, 收敛速度更快.
默认情况下ReLU只考虑 正样本, 可以使用LeakyReLU, PReLU 来考虑 正负样本.
Softmax:
将多分类的结果以概率的形式展示, 且概率和相加为1, 最终选取概率值最大的分类 作为最终结果.
记忆: 如何选择激活函数
隐藏层:
ReLU > Leaky ReLU > PReLU > Tanh > Sigmoid
输出层:
二分类: Sigmoid
多分类: Softmax
回归问题: identity
"""
# 导包
import torch
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
# 1. 创建画布和坐标轴, 1行2列.
fig, axes = plt.subplots(1, 2)
# 2. 生成 -20 ~ 20之间的 1000个数据点.
x = torch.linspace(-20, 20, 1000)
# print(f'x: {x}')
# 3. 计算上述1000个点, ReLU激活函数处理后的值.
# y = torch.sigmoid(x) # 激活函数处理后的值.
# y = torch.tanh(x)
y = torch.relu(x)
# print(f'y: {y}')
# 4. 在第1个子图中绘制ReLU激活函数的图像.
axes[0].plot(x, y)
axes[0].set_title('ReLU激活函数图像')
axes[0].grid()
# 5. 在第2个图上, 绘制ReLU激活函数的导数图像.
# 5.1 重新生成 -20 ~ 20之间的 1000个数据点.
# 参1: 起始值, 参2: 结束值, 参3: 元素的个数, 参4: 是否需要求导.
x = torch.linspace(-20, 20, 1000, requires_grad=True)
# 5.2 具体的计算上述1000个点, ReLU激活函数导数后的值.
# torch.sigmoid(x).sum().backward()
# torch.tanh(x).sum().backward()
torch.relu(x).sum().backward()
# 5.3 绘制图像.
axes[1].plot(x.detach(), x.grad)
axes[1].set_title('ReLU激活函数导数图像')
axes[1].grid()
plt.show()
# 绘制激活函数Softmax的 函数图像 和 导数图像
# 1. 定义张量, 记录: 分类数据.
scores = torch.tensor([[0.2, 0.35, 0.1, 0.46], [0.1, 0.13, 0.05, 2.79]])
# 2. dim = 0, 按行计算
probabilities = torch.softmax(scores, dim=1)
print(probabilities)Sigmoid
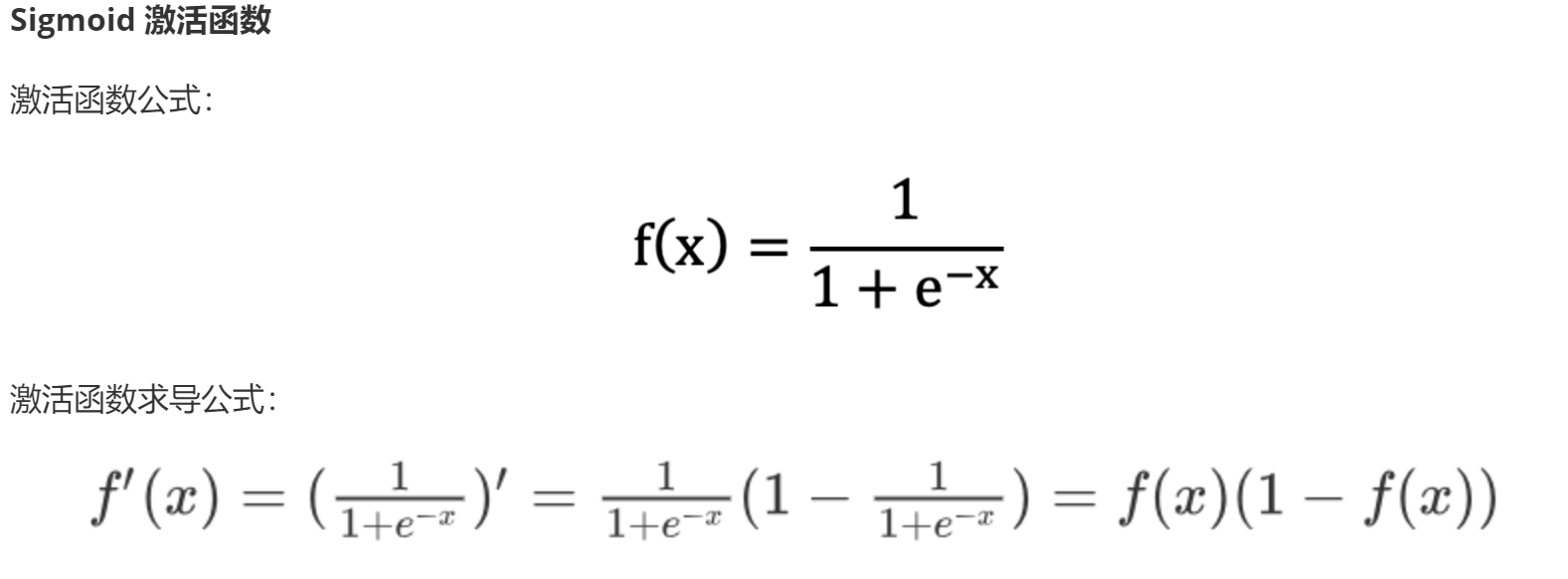
 主要应用于 二分类的输出层
主要应用于 二分类的输出层
且适用于 浅层神经网络(不超过5层)
数据在 [-6, 6]之间有效果, 在[-3, 3]之间效果明显,
激活值x=0作为本层神经网络的输出值,会导致正反向传播wx=0 ,信息丢失
会将数据值映射到: [0, 1]
求导后范围在 [0, 0.25],神经网络超过5层,反向传播因为链式法则有个激活值累乘的过程,0.25的5次方会很小很小,传播中断.
Tanh
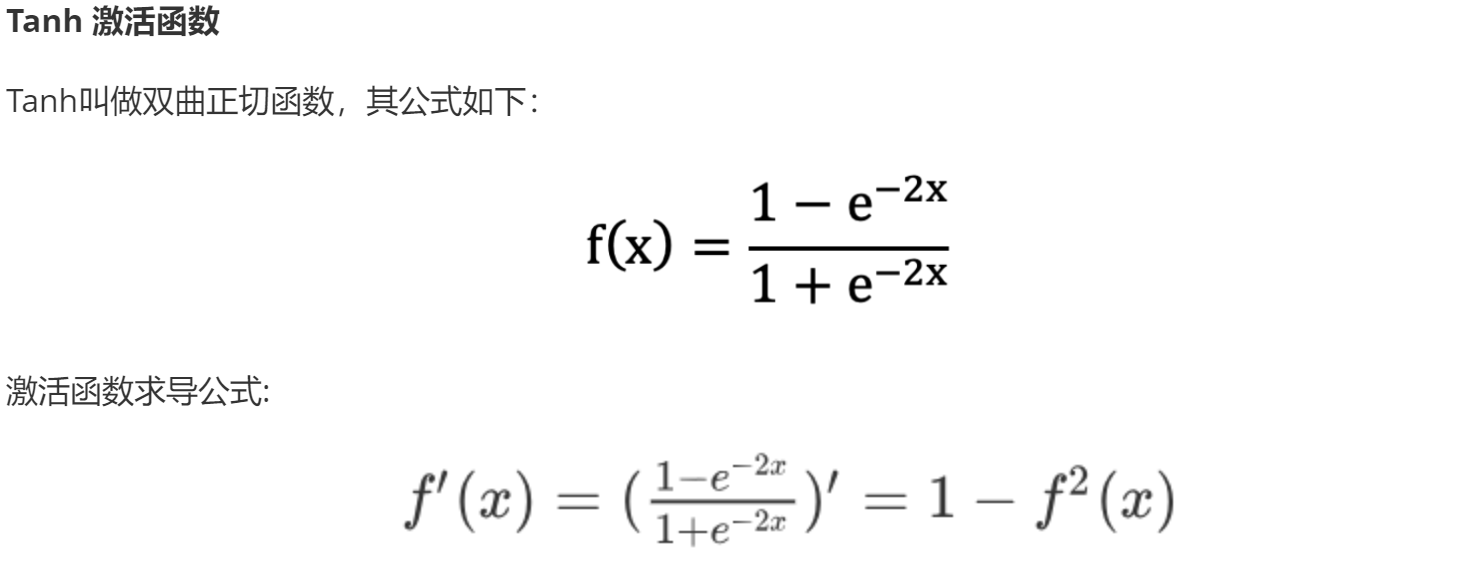
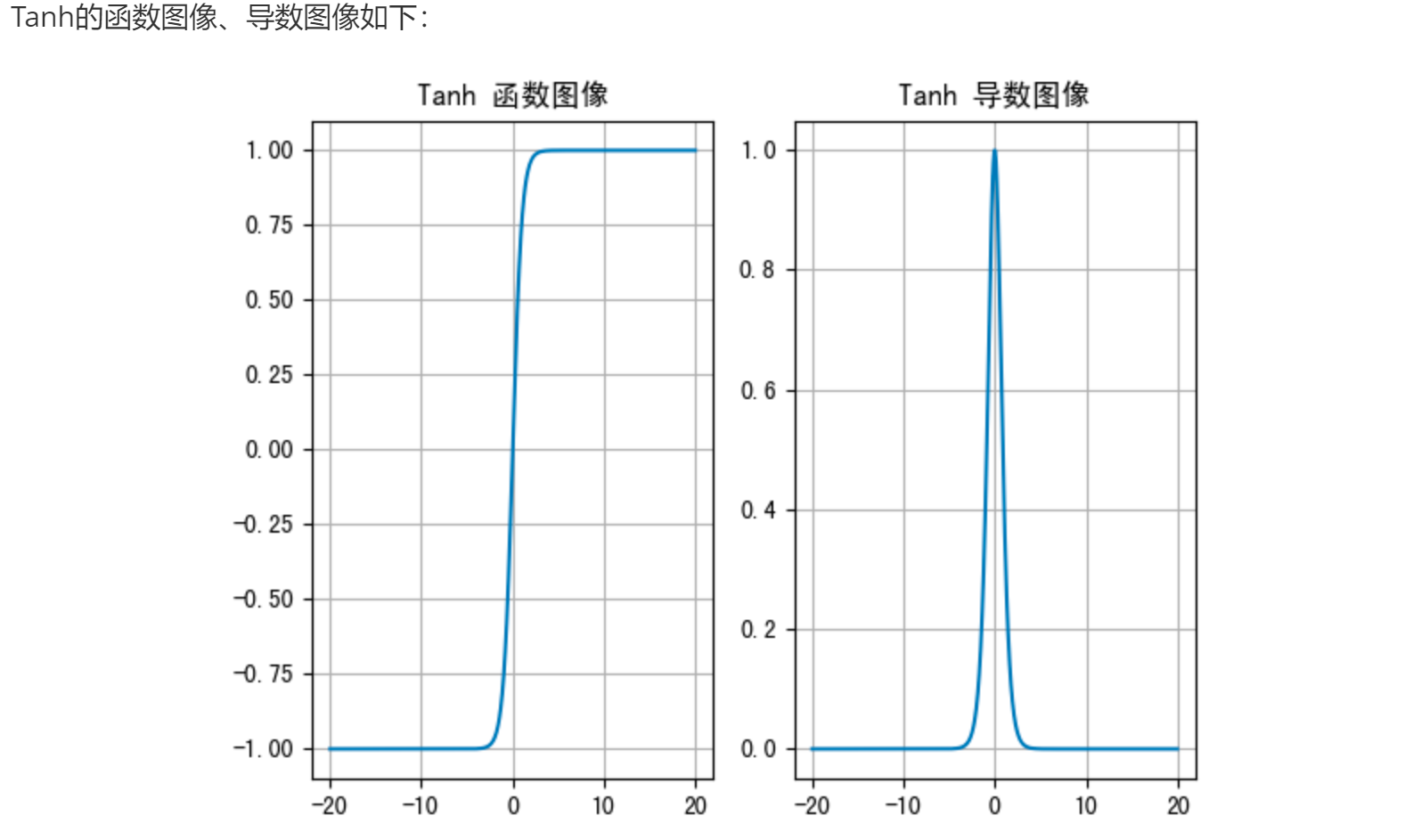
主要应用于 隐藏层, 且适用于 浅层神经网络(不超过5层).
数据在 [-3, 3]之间有效果, 在[-1, 1]之间效果明显, 会将数据值映射到: [-1, 1]
求导后范围在 [0, 1], 较之于Sigmoid, 收敛速度快.激活函数的导数上限较0.25大,收敛快
ReLU / Leaky ReLU / PReLU
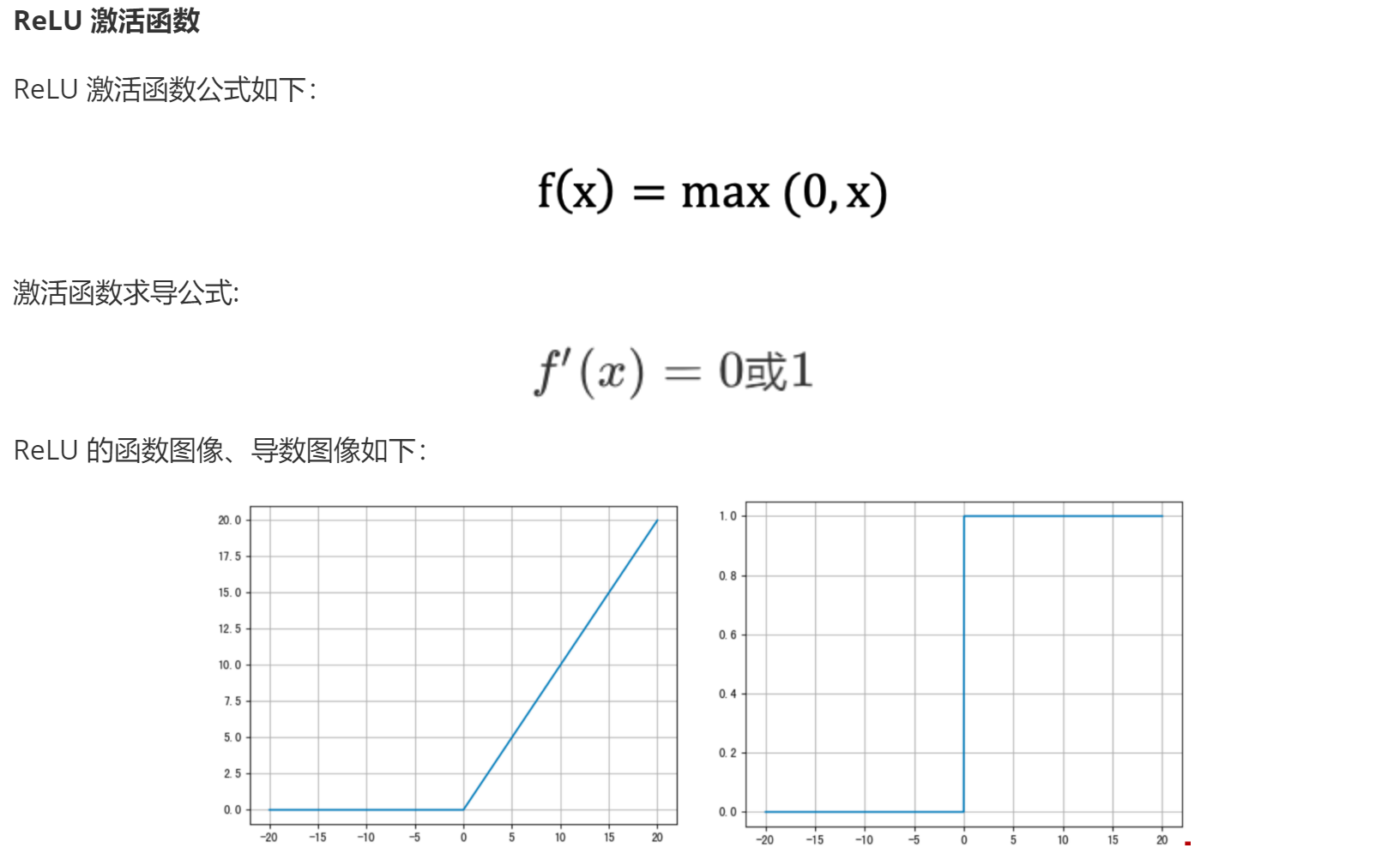
计算公式为: max(0, x), 计算量相对较小, 训练成本低. 多应用于 隐藏层, 且适合 深层神经网络.
求导后, 值要么是0, 要么是1, 较之于Tanh, 收敛速度更快.
默认情况下ReLU只考虑 正样本, 可以使用LeakyReLU, PReLU 来考虑 正负样本.
导数为1,梯度下降较快,收敛效果好,导数为0,神经元死亡,无法学习特征
Softmax
-
作用:将线性层输出值转换成概率,且概率和为1
-
使用:
softmax(dim=1) -
适用场景:多分类输出层
如何选择激活函数
隐藏层: ReLU > Leaky ReLU > PReLU > Tanh > Sigmoid
输出层:
二分类: Sigmoid
多分类: Softmax
回归问题: identity
三、参数初始化
3.1 作用
-
防止梯度消失或梯度爆炸
-
打破对称性:
-
使每个神经元学习不同特征
-
每个神经元权重不一样,更新结果也不一样
-
3.2 初始化方法
kaiming 何恺明(Kaiming He) 又叫he 初始化
kaiming 和xavier都是只针对权重 w 的初始化,其他的可针对 w 和 b
| 初始化方法 | 分布类型 | 参数范围 | 适用场景 |
|---|---|---|---|
| 随机初始化 | 均匀分布 | 默认(0,1),推荐(-1/√d, 1/√d) d是dim | 通用 |
| 正态分布 | 均值0,标准差1 N(0,1) | 通用 | |
| 全0/1/指定值 | - | 指定值 | 仅测试环境,训练易导致对称性 |
| Kaiming初始化 | 均匀分布 | (-√(6/n_in), √(6/n_in)) | ReLU系列 |
| 正态分布 | N(0, √(2/n_in)) | ReLU系列 | |
| Xavier初始化 | 均匀分布 | (-√(6/(n_in+n_out)), √(6/(n_in+n_out))) | Sigmoid/Tanh |
| 正态分布 | N(0, √(2/(n_in+n_out))) | Sigmoid/Tanh |

"""
参数初始化的目的:
1. 防止梯度消失 或者 梯度爆炸.
2. 提高收敛速度.
3. 打破对称性.
参数初始化的方式:
无法打破对称性的:
全0, 全1, 固定值
可以打破对称性的:
随机初始化, 正态分布初始化, kaiming初始化, xavier初始化
总结:
1. 记忆 kaiming初始化, xavier初始化, 全0初始化.
2. 关于初始化的选择上:
激活函数ReLU及其系列: 优先用 kaiming
激活函数非ReLU: 优先用 xavier
如果是浅层网络: 可以考虑使用 随机初始化
"""
# 导包
import torch.nn as nn # neural network: 神经网络
import torch.nn as nn
# 1. 均匀分布随机初始化
def dm01():
# 1. 创建1个线性层, 输入维度5, 输出维度3
linear = nn.Linear(5, 3)
# 2. 对权重(w)进行随机初始化, 从0-1均匀分布产生参数
nn.init.uniform_(linear.weight)
# 3. 对偏置(b)进行随机初始化, 从0-1均匀分布产生参数
nn.init.uniform_(linear.bias)
# 4. 打印生成结果.
print(linear.weight.data)
print(linear.bias.data)
# 2. 固定初始化
def dm02():
# 1. 创建1个线性层, 输入维度5, 输出维度3
linear = nn.Linear(5, 3)
# 2. 对权重(w)进行初始化, 设置固定值为: 3
nn.init.constant_(linear.weight, 3)
# 3. 对偏置(b)进行初始化, 设置固定值为: 3
nn.init.constant_(linear.bias, 3)
# 4. 打印生成结果.
print(linear.weight.data)
print(linear.bias.data)
# 3. 全0初始化
def dm03():
# 1. 创建1个线性层, 输入维度5, 输出维度3
linear = nn.Linear(5, 3)
# 2. 对权重(w)进行初始化, 全0初始化
nn.init.zeros_(linear.weight)
# 3. 对偏置(b)进行初始化, 全0初始化
nn.init.zeros_(linear.bias)
# 4. 打印生成结果.
print(linear.weight.data)
print(linear.bias.data)
# 4. 全1初始化
def dm04():
# 1. 创建1个线性层, 输入维度5, 输出维度3
linear = nn.Linear(5, 3)
# 2. 对权重(w)进行初始化, 全1初始化
nn.init.ones_(linear.weight)
# 3. 打印生成结果.
print(linear.weight.data)
# 5. 正态分布随机初始化
def dm05():
# 1. 创建1个线性层, 输入维度5, 输出维度3
linear = nn.Linear(5, 3)
# 2. 对权重(w)进行初始化, 正态分布初始化(均值为0, 标准差为1)
nn.init.normal_(linear.weight)
# 3. 打印生成结果.
print(linear.weight.data)
# 6. kaiming 初始化
def dm06():
# 1. 创建1个线性层, 输入维度5, 输出维度3
linear = nn.Linear(5, 3)
# 2. 对权重(w)进行初始化, 正态分布初始化(均值为0, 标准差为1)
# kaiming 正态分布初始化
# nn.init.kaiming_normal_(linear.weight)
# kaiming 均匀分布初始化
nn.init.kaiming_uniform_(linear.weight)
# 3. 打印生成结果.
print(linear.weight.data)
# 7. xavier 初始化
def dm07():
# 1. 创建1个线性层, 输入维度5, 输出维度3
linear = nn.Linear(5, 3)
# 2. 对权重(w)进行初始化, 正态分布初始化(均值为0, 标准差为1)
# xavier 正态分布初始化
# nn.init.xavier_normal_(linear.weight)
# xavier 均匀分布初始化
nn.init.xavier_uniform_(linear.weight)
# 3. 打印生成结果.
print(linear.weight.data)
# 测试
if __name__ == '__main__':
# dm01() # 均匀分布随机初始化
# dm02() # 固定初始化
# dm03() # 全0初始化
# dm04() # 全1初始化
# dm05() # 正态分布
# dm06() # kaiming初始化
dm07() # xavier初始化3.3深度学习步骤
1. 准备数据 2. 搭建神经网络 3. 模型训练 4. 模型测试
3.4 搭建神经网络模型
1. 定义一个类, 继承: nn.Module
2. 在__init__()方法中, 搭建神经网络.
3. 在 forward()方法中,完成: 前向传播,实例化类的时候自动调用forward方法(类似init)
"""
案例:
演示神经网络搭建流程.
深度学习案例的4个步骤:
1. 准备数据.
2. 搭建神经网络
3. 模型训练
4. 模型测试
神经网络搭建流程:
1. 定义一个类, 继承: nn.Module
2. 在__init__()方法中, 搭建神经网络.
3. 在 forward()方法中,完成: 前向传播.
"""
# 导包
import torch
import torch.nn as nn
from torchsummary import summary # 计算模型参数,查看模型结构, pip install torchsummary -i https://mirrors.aliyun.com/pypi/simple/
# todo: 1.搭建神经网络, 即: 自定义继承 nn.Module
class ModelDemo(nn.Module):
# todo: 1.1 在init魔法方法中, 完成初始化: 父类成员, 及 神经网络搭建.
def __init__(self):
# 1.1 初始化父类成员.
super().__init__()
# 1.2 搭建神经网络 -> 隐藏层 + 输出层
# 隐藏层1: 输入特征数 3, 输出特征数 3
self.linear1 = nn.Linear(3, 3)
# 隐藏层2: 输入特征数 3, 输出特征数 2
self.linear2 = nn.Linear(3, 2)
# 输出层: 输入特征数 2, 输出特征数 2
self.output = nn.Linear(2, 2)
# 1.3 对隐藏层进行参数初始化.
# 隐藏层1
nn.init.xavier_normal_(self.linear1.weight)
nn.init.zeros_(self.linear1.bias)
# 隐藏层2
nn.init.kaiming_normal_(self.linear2.weight)
nn.init.zeros_(self.linear2.bias)
# todo: 1.2 前向传播: 输入层 -> 隐藏层 -> 输出层
def forward(self, x):
# 1.1 第1层 隐藏层计算: 加权求和 + 激活函数(Sigmoid)
# 分解版写法.
# x = self.linear1(x) # 加权求和
# x = torch.sigmoid(x) # 激活函数
# 合并版写法.
x = torch.sigmoid(self.linear1(x))
# 1.2 第2层 隐藏层计算: 加权求和 + 激活函数(ReLu)
x = torch.relu(self.linear2(x))
# 1.3 第3层 输出层计算: 加权求和 + 激活函数(Softmax)
# dim=-1, 表示按行计算, 一条样本一条样本的处理.
x = torch.softmax(self.output(x), dim=-1)
# 1.4 返回预测值.
return x
# todo: 2.模型训练.
def train():
# 1. 创建模型对象.
my_model = ModelDemo()
# print(f'my_model: {my_model}')
# 2. 创建数据集样本, 随机生成.
data = torch.randn(size=(5, 3))
print(f'data: {data}')
print(f'data.shape: {data.shape}') # (5行, 3列)
print(f'data.requires_grad: {data.requires_grad}') # False
# 3. 调用神经网络模型 -> 进行模型训练.
output = my_model(data) # 底层自动调用了 forward()方法, 进行 前向传播.
print(f'output: {output}')
print(f'output.shape: {output.shape}') # (5行, 2列)
print(f'output.requires_grad: {output.requires_grad}') # True
print('-' * 30)
# 4. 计算 和 查看模型参数.
print('=================== 计算模型参数 ===================')
# 参1: (神经网络)模型对象, 参2: 输入数据维度(5行3列)
summary(my_model, input_size=(5, 3))
print('=================== 查看模型参数 ===================')
for name, param in my_model.named_parameters():
print(f'name: {name}')
print(f'param: {param} \n')
# todo: 3.测试
if __name__ == '__main__':
train()
四、损失函数
4.1 什么是损失函数
-
衡量模型参数质量的函数
-
别名:损失函数、代价函数、误差函数、成本函数
-
作用:计算损失值,结合反向传播和梯度下降实现参数更新
4.2 分类损失函数
在多分类任务通常使用softmax将logits(输出层总结的加权求和值)转换为概率的形式,所以多分类的交叉熵损失也叫做softmax损失

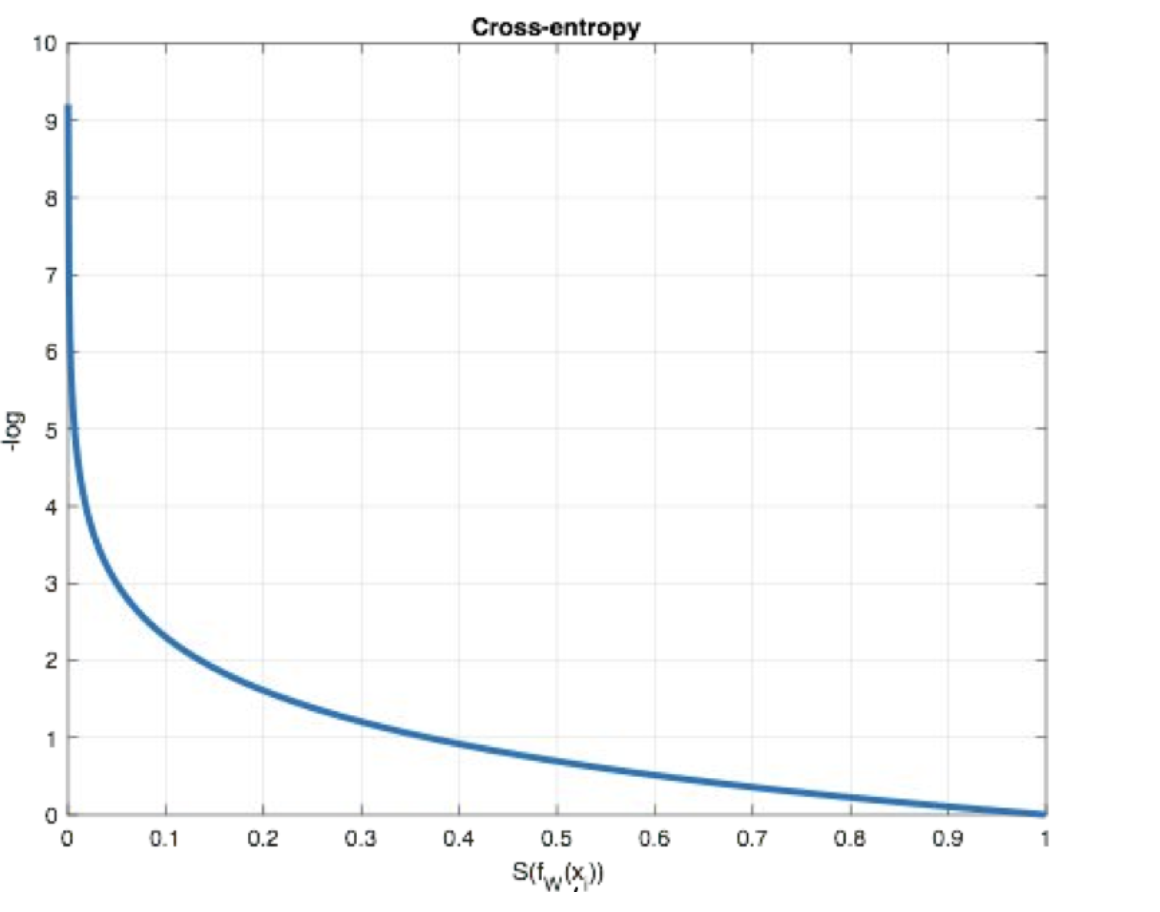

| 类型 | 损失函数 | 特点 |
|---|---|---|
| 多分类交叉熵损失 | nn.CrossEntropyLoss(reduction='mean') |
实现softmax+损失计算 |
| 二分类交叉熵损失 | nn.BCELoss(reduction='mean') |
二分类任务 |
"""
案例:
演示 多分类任务的交叉熵损失函数.
损失函数介绍:
概述:
损失函数也叫成本函数, 目标函数, 代价函数, 误差函数, 就是用来衡量 模型好坏(模型拟合情况)的.
分类:
分类问题:
多分类交叉熵损失: CrossEntropyLoss
二分类交叉熵损失: BCELoss
回归问题:
MAE: Mean Absolute Error, 平均绝对误差.
MSE: Mean Squared Error, 均方误差.
Smooth L1: 结合上述两个的特点做的升级, 优化.
多分类交叉熵损失: CrossEntropyLoss
设计思路:
Loss = - Σylog(S(f(x)))
简单记忆:
x: 样本
f(x): 加权求和
S(f(x)): 处理后的概率
y: 样本x属于某一个类别的 真实概率.
大白话解释:
损失函数结果 = 最小化 正确类别所对应的 预测概率的对数的 负值(损失值最小)...
细节:
CrossEntropyLoss = Softmax() + 损失计算, 后续如果用这个损失函数, 则: 输出层就不用额外调用 softmax()激活函数了.
"""
# 导包
import torch
import torch.nn as nn
# 1. 定义函数, 演示: 多分类交叉熵损失.
def dm01():
# 1. 手动创建样本的真实值 -> 就是上述公式中的 y
y_true = torch.tensor([[0, 1, 0], [1, 0, 0]], dtype=torch.float)
# y_true = torch.tensor([1, 2])
# 2. 手动创建样本的预测值 -> 就是上述公式中的 f(x)
y_pred = torch.tensor([[0.1, 0.8, 0.1], [0.7, 0.2, 0.1]], requires_grad=True, dtype=torch.float)
# 3. 创建多分类交叉熵损失函数.
criterion = nn.CrossEntropyLoss() # 平均损失, 来源于参数: reduction: str = "mean",
# 4. 计算损失值.
loss = criterion(y_pred, y_true)
print(f'损失值: {loss}')
# 2. 测试
if __name__ == '__main__':
dm01()"""
案例:
演示二分类任务的损失函数.
二分类任务的损失函数(BCELoss):
公式:
Loss = -ylog(预测值) - (1 - y)log(1 - 预测值)
细节:
因为公式中没有包含Sigmoid激活函数, 所以使用BCELoss的时候, 还需要手动指定 Sigmoid.
"""
# 导包
import torch
import torch.nn as nn
# 1. 定义函数, 演示: 二分类任务的损失函数.
def dm01():
# 1. 设置真实值.
y_true = torch.tensor([0, 1, 0], dtype=torch.float)
# 2. 设置预测值(概率)
y_pred = torch.tensor([0.6901, 0.5423, 0.2639])
# 3. 创建二分类交叉熵损失函数.
criterion = nn.BCELoss() # reduction: str = "mean" -> 均值
# 4. 计算损失值.
loss = criterion(y_pred, y_true)
print(f'损失值: {loss}')
# 2. 测试
if __name__ == '__main__':
dm01()4.3 回归损失函数
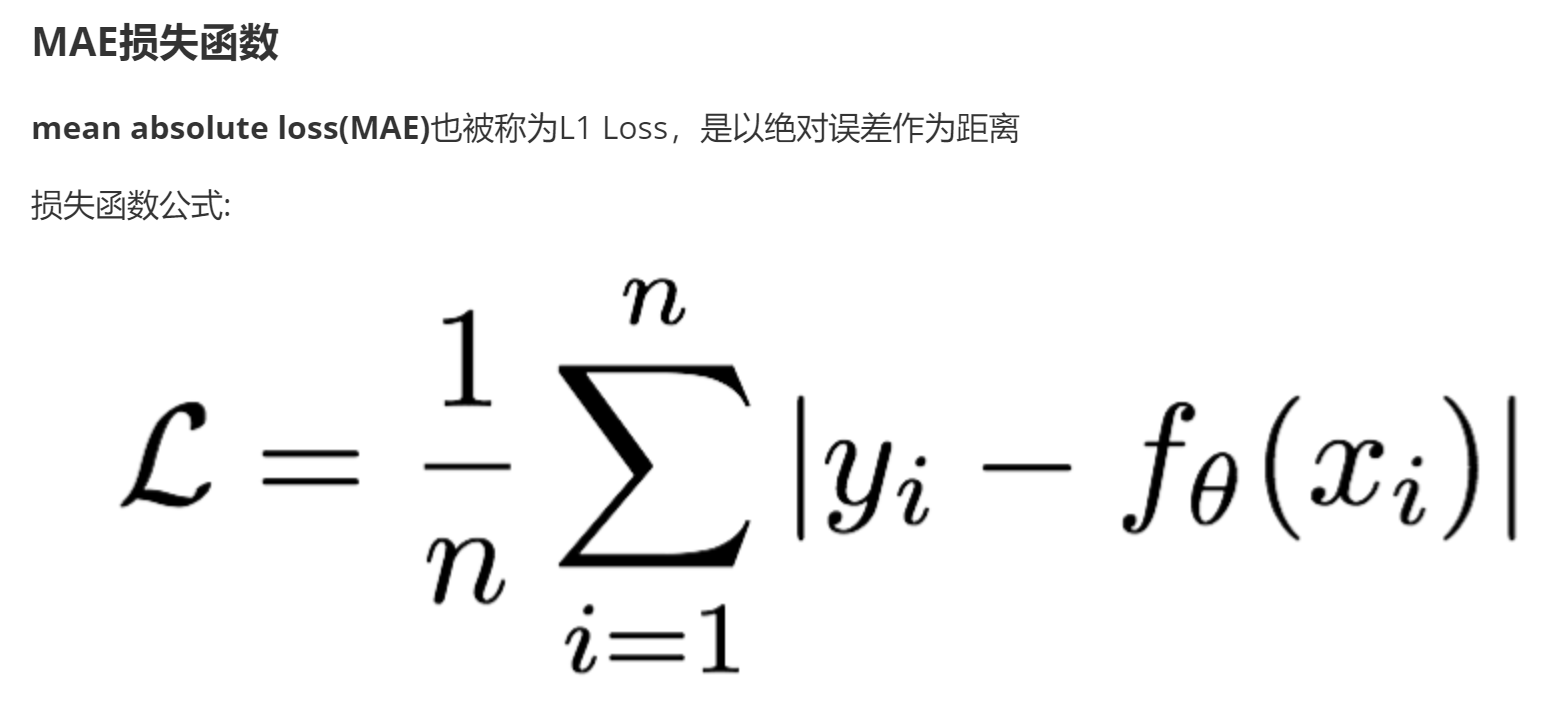
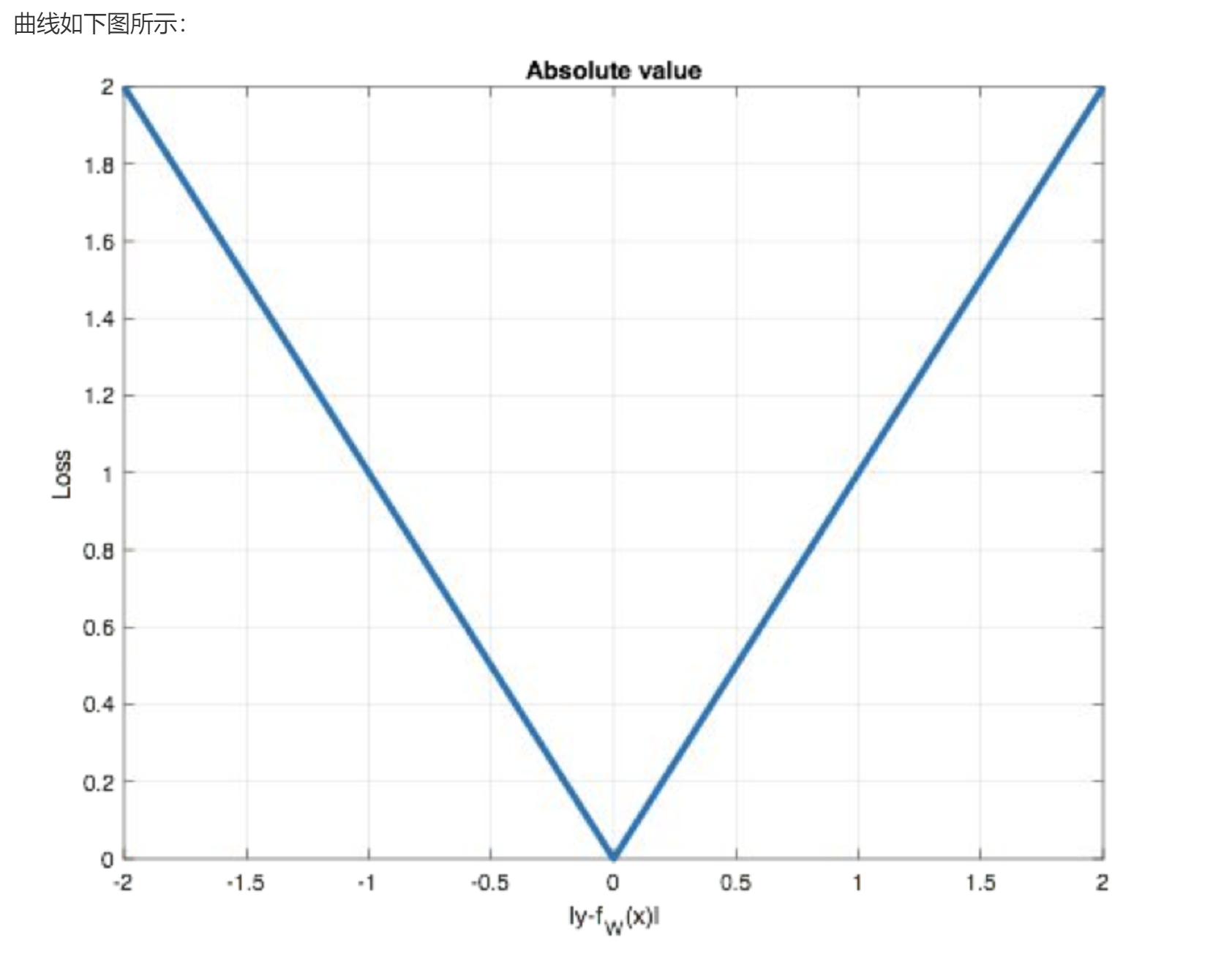
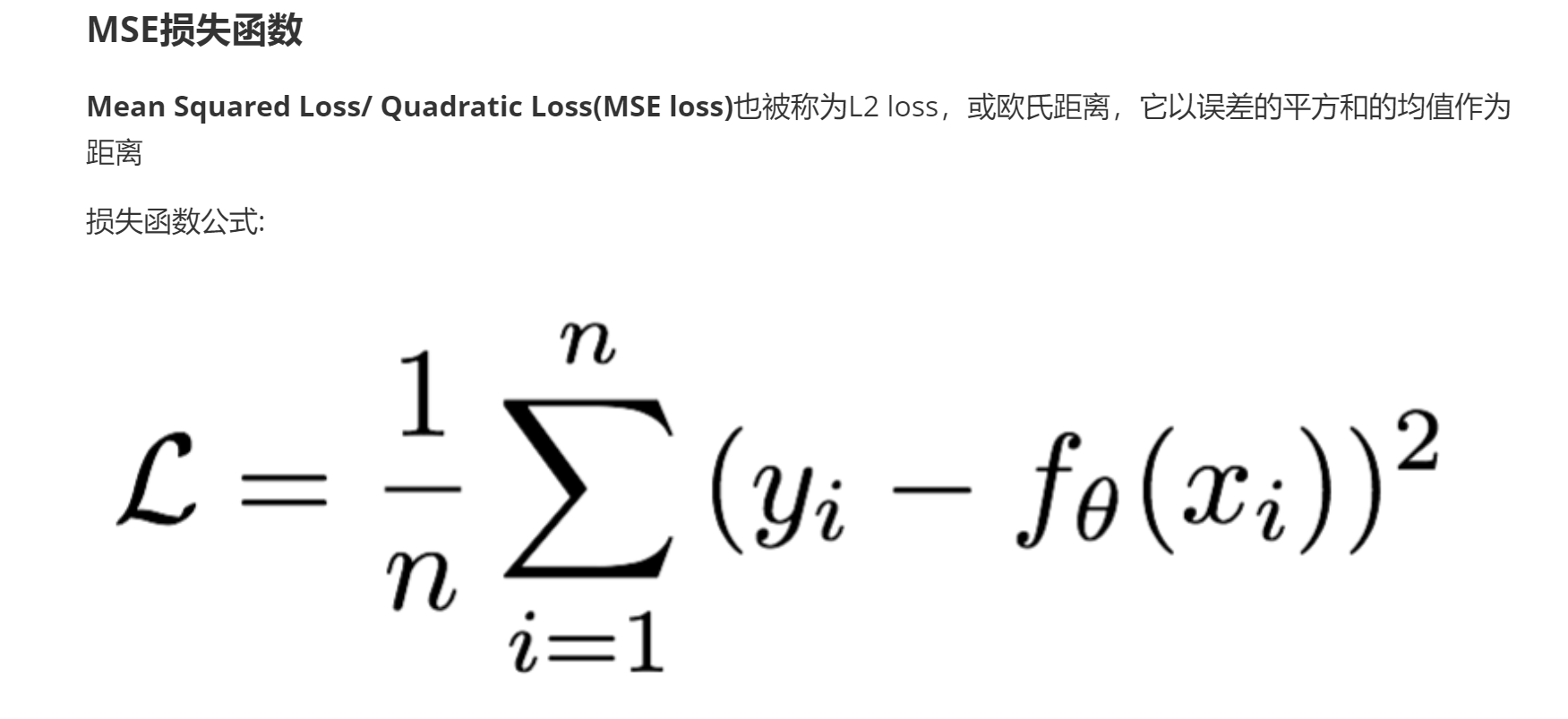
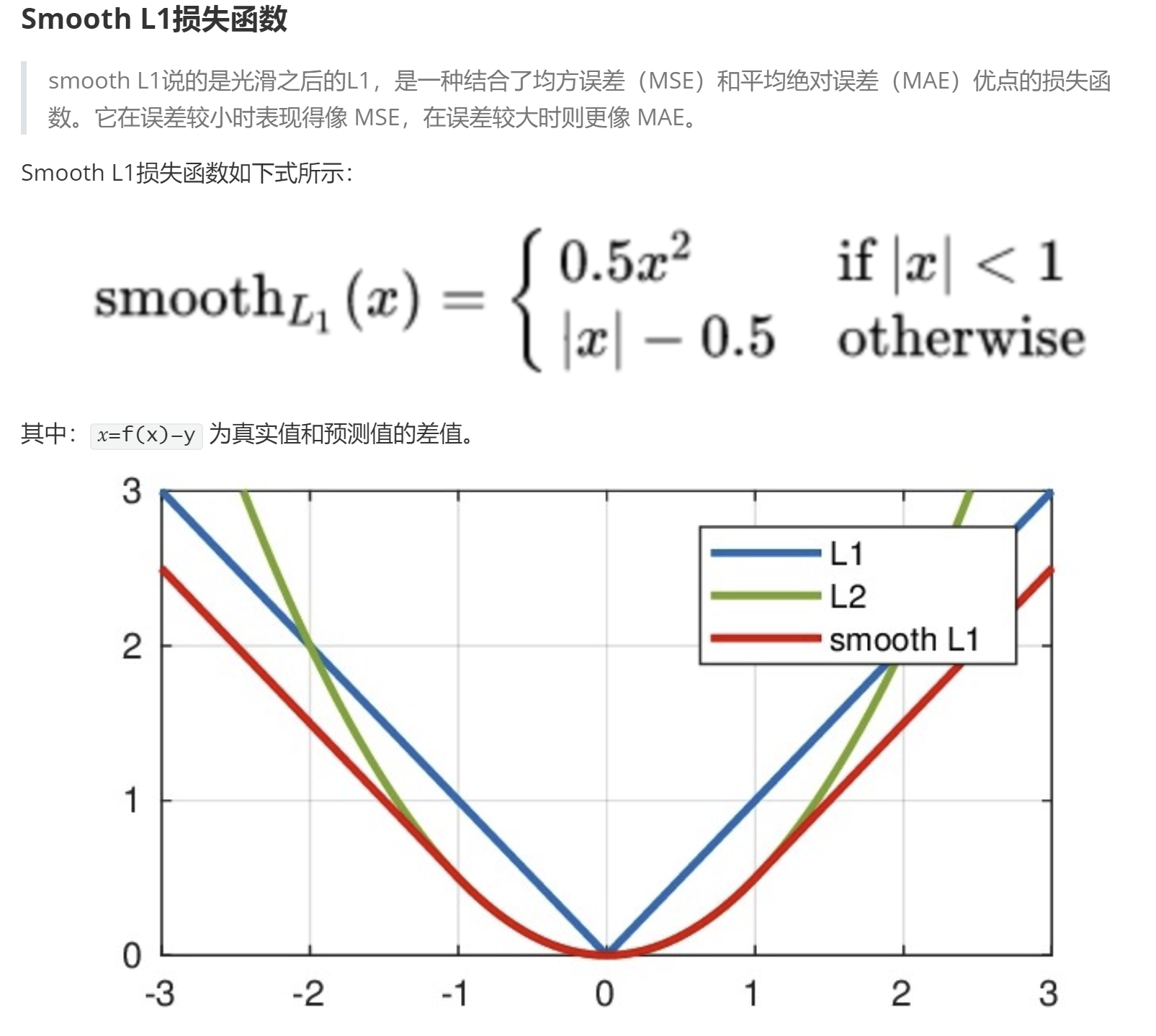
SmoothL1Loss在[-1,1]之间实际上就是L2损失,这样解决了L1的不光滑问题
SmoothL1Loss在[-1,1]区间外,实际上就是L1损失,这样就解决了离群点梯度爆炸的问题
| 损失函数 | 特点 | 优点 | 缺点 | PyTorch实现 |
|---|---|---|---|---|
| MAE损失 | 平均绝对误差 | 对异常样本效果好,不会放大异常样本误差 L1正则化:特征筛选 |
0点不可导 | nn.L1Loss() |
| MSE损失 | 均方误差 | 任意位置可导,loss越大导数越大 | 放大异常样本误差 L2正则化:权重接近0 |
nn.MSELoss() |
| Smooth L1损失 | MAE+MSE结合 | 任意位置可导 对异常样本效果好 无梯度爆炸,不易跳过最低点 |
- | nn.SmoothL1Loss() |
"""
案例:
演示 回归任务的损失函数介绍.
回归任务常用损失函数如下:
MAE: Mean Absolute Error, 平均绝对误差.
公式:
误差绝对值之和 / 样本总数
类似于L1正则化, 权重可以降为0, 数据会变得稀疏.
弊端:
在0点不平滑(不可导), 可能错过最小值.
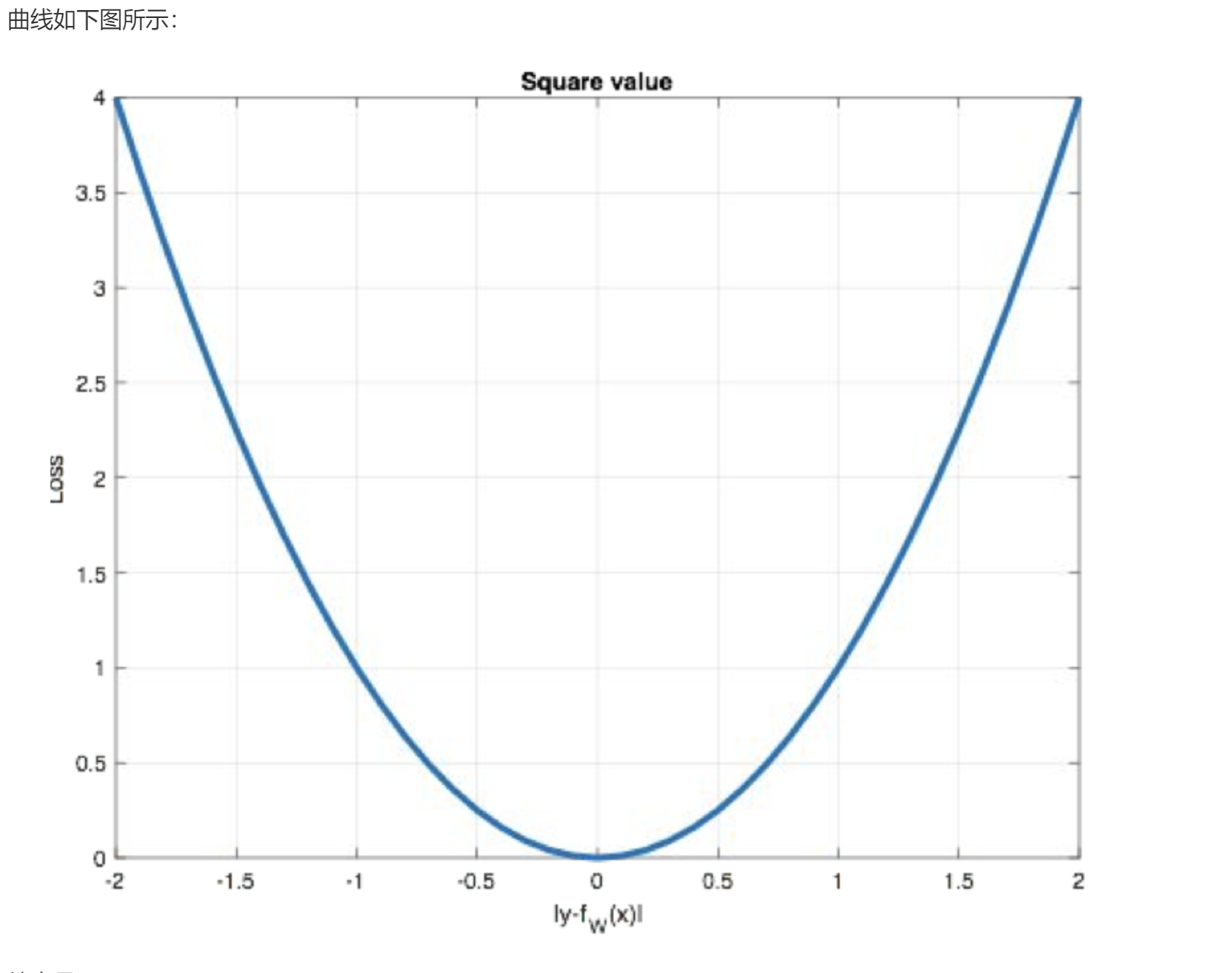
MSE: Mean Squared Error, 均方误差.
公式:
误差平方之和 / 样本总数
弊端:
如果差值过大, 可能存在梯度爆炸的情况.
Smooth L1:
就是基于MAE 和 MSE做的综合, 在 [-1, 1]是 L2(MSE), 其它段时L1.
这样即解决了L1不平滑的问题(0点不可导, 可能错过最小值)
又解决了L2(MSE)的 梯度爆炸的问题.
"""
# 导包
import torch
import torch.nn as nn
# 1. 定义函数, 演示: MAE 损失函数.
def dm01():
# 1. 定义变量, 记录: 真实值.
y_true = torch.tensor([2.0, 2.0, 2.0], dtype=torch.float)
# 2. 定义变量, 记录: 预测值.
y_pred = torch.tensor([1.0, 1.0, 1.9], requires_grad=True)
# 3. 创建MAE损失函数对象.
criterion = nn.L1Loss()
# 4. 计算损失.
loss = criterion(y_pred, y_true)
# 5. 输出损失.
print(f'MAE: {loss}')
# 2. 定义函数, 演示: MSE 损失函数.
def dm02():
# 1. 定义变量, 记录: 真实值.
y_true = torch.tensor([2.0, 2.0, 2.0], dtype=torch.float)
# 2. 定义变量, 记录: 预测值.
y_pred = torch.tensor([1.0, 1.0, 1.9], requires_grad=True)
# 3. 创建MSE损失函数对象.
criterion = nn.MSELoss()
# 4. 计算损失.
loss = criterion(y_pred, y_true)
# 5. 输出损失.
print(f'MSE: {loss}')
# 3. 定义函数, 演示: Smooth L1 损失函数.
def dm03():
# 1. 定义变量, 记录: 真实值.
y_true = torch.tensor([2.0, 2.0, 2.0], dtype=torch.float)
# 2. 定义变量, 记录: 预测值.
y_pred = torch.tensor([1.0, 1.0, 1.9], requires_grad=True)
# 3. 创建Smooth L1损失函数对象.
criterion = nn.SmoothL1Loss()
# 4. 计算损失.
loss = criterion(y_pred, y_true)
# 5. 输出损失.
print(f'Smooth L1: {loss}')
# 4. 测试
if __name__ == '__main__':
# dm01() # 0.699999988079071
# dm02() # 0.6700000166893005
dm03() # 0.33500000834465027五、网络模型优化方法
"""
案例:
演示 梯度下降优化方法.
梯度下降相关介绍:
概述:
梯度下降是结合 本次损失函数的导数(作为梯度) 基于学习率 来更新权重的.
公式:
W新 = W旧 - 学习率 * (本次的)梯度
存在的问题:
1. 遇到平缓区域, 梯度下降(权重更新)可能会慢.
2. 可能会遇到 鞍点(梯度为0)
3. 可能会遇到 局部最小值.
解决思路:
从上述的 学习率 或者 梯度入手, 进行优化, 于是有了: 动量法Momentum, 自适应学习率AdaGrad, RMSProp, 综合衡量: Adam
动量法Momentum:
动量法公式:
St = β * St-1 + (1 - β) * Gt
解释:
St: 本次的指数移动加权平均结果.
β: 调节权重系数, 越大, 数据越平缓, 历史指数移动加权平均 比重越大, 本次梯度权重越小.
St-1: 历史的指数移动加权平均结果.
Gt: 本次计算出的梯度(不考虑历史梯度).
加入动量法后的 梯度更新公式:
W新 = W旧 - 学习率 * St
自适应学习率: AdaGrad(Adaptive Gradient Estimation)
公式:
累计平方梯度:
St = St-1 + Gt * Gt
解释:
St: 累计平方梯度
St-1: 历史累计平方梯度.
Gt: 本次的梯度.
学习率:
学习率 = 学习率 / (sqrt(St) + 小常数)
解释:
小常数: 1e-10, 目的: 防止分母变为0
梯度下降公式:
W新 = W旧 - 调整后的学习率 * Gt
缺点:
可能会导致学习率过早, 过量的降低, 导致模型后期学习率太小, 较难找到最优解.
自适应学习率: RMSProp(Root Mean Square Propagation) -> 可以看做是 对AdaGrad做的优化, 加入 调和权重系数.
公式:
指数加权平均 累计历史平方梯度:
St = β * St-1 + (1 - β) * Gt * Gt
解释:
St: 累计平方梯度
St-1: 历史累计平方梯度.
Gt: 本次的梯度.
β: 调和权重系数.
学习率:
学习率 = 学习率 / (sqrt(St) + 小常数)
解释:
小常数: 1e-10, 目的: 防止分母变为0
梯度下降公式:
W新 = W旧 - 调整后的学习率 * Gt
优点:
RMSProp通过引入 衰减系数β, 控制历史梯度 对 历史梯度信息获取的多少.
自适应矩估计: Adam(Adaptive Moment Estimation)
思路:
即优化学习率, 又优化梯度.
公式:
一阶矩: 算均值.
Mt = β1 * Mt-1 + (1 - β1) * Gt 充当: 梯度
St = β2 * St-1 + (1 - β2) * Gt * Gt 充当: 学习率
二阶矩: 梯度的方差.
Mt^ = Mt / (1 - β1 ^ t)
St^ = St / (1 - β2 ^ t)
权重更新公式:
W新 = W旧 - 学习率 / (sqrt(St^) + 小常数) * Mt^
大白话翻译:
Adam = RMSProp + Momentum
总结: 如何选择梯度下降优化方法
简单任务和较小的模型:
SGD, 动量法
复杂任务或者有大量数据:
Adam
需要处理稀疏数据或者文本数据:
AdaGrad, RMSProp
"""
# 导包
import torch
import torch.nn as nn
import torch.optim as optim
# 1. 定义函数, 演示: 梯度下降优化方法 -> 动量法(Momentum)
def dm01_momentum():
# 1. 初始化权重参数.
w = torch.tensor([1.0], requires_grad=True, dtype=torch.float32)
# 2. 定义损失函数
criterion = ((w ** 2) / 2.0)
# 3. 创建优化器(函数对象) -> 基于SGD(随机梯度下降), 加入参数 momentum, 就是 动量法.
# 参1: (待优化的)参数列表, 参2: 学习率, 参3: 动量参数.
optimizer = optim.SGD(params=[w], lr=0.01, momentum=0.9) # 细节: momentum=0(默认), 只考虑: 本次梯度.
# 4. 计算梯度值: 梯度清零 + 反向传播 + 参数更新
optimizer.zero_grad()
criterion.sum().backward()
optimizer.step()
print(f'w: {w}, w.grad: {w.grad}')
# 5.重复上述的步骤, 第2次 更新权重参数.
# 5.1 定义损失函数.
criterion = ((w ** 2) / 2.0)
# 5.2 计算梯度值: 梯度清零 + 反向传播 + 参数更新
optimizer.zero_grad()
criterion.sum().backward()
optimizer.step()
# 5.3 打印结果.
print(f'w: {w}, w.grad: {w.grad}')
# 2. 定义函数, 演示: 梯度下降优化方法 -> 自适应学习率(AdaGrad)
def dm02_adagrad():
# 1. 初始化权重参数.
w = torch.tensor([1.0], requires_grad=True, dtype=torch.float32)
# 2. 定义损失函数
criterion = ((w ** 2) / 2.0)
# 3. 创建优化器(函数对象)
# 思路1: 基于SGD(随机梯度下降), 加入参数 momentum, 就是 动量法.
# 参1: (待优化的)参数列表, 参2: 学习率, 参3: 动量参数.
# optimizer = optim.SGD(params=[w], lr=0.01, momentum=0.9) # 细节: momentum=0(默认), 只考虑: 本次梯度.
# 思路2: 基于AdaGrad(自适应学习率).
optimizer = optim.Adagrad(params=[w], lr=0.01)
# 4. 计算梯度值: 梯度清零 + 反向传播 + 参数更新
optimizer.zero_grad()
criterion.sum().backward()
optimizer.step()
print(f'w: {w}, w.grad: {w.grad}')
# 5.重复上述的步骤, 第2次 更新权重参数.
# 5.1 定义损失函数.
criterion = ((w ** 2) / 2.0)
# 5.2 计算梯度值: 梯度清零 + 反向传播 + 参数更新
optimizer.zero_grad()
criterion.sum().backward()
optimizer.step()
# 5.3 打印结果.
print(f'w: {w}, w.grad: {w.grad}')
# 3. 定义函数, 演示: 梯度下降优化方法 -> 自适应学习率(RMSProp)
def dm03_rmsprop():
# 1. 初始化权重参数.
w = torch.tensor([1.0], requires_grad=True, dtype=torch.float32)
# 2. 定义损失函数
criterion = ((w ** 2) / 2.0)
# 3. 创建优化器(函数对象)
# 思路1: 基于SGD(随机梯度下降), 加入参数 momentum, 就是 动量法.
# 参1: (待优化的)参数列表, 参2: 学习率, 参3: 动量参数.
# optimizer = optim.SGD(params=[w], lr=0.01, momentum=0.9) # 细节: momentum=0(默认), 只考虑: 本次梯度.
# 思路2: 基于AdaGrad(自适应学习率).
# optimizer = optim.Adagrad(params=[w], lr=0.01)
# 思路3: 基于RMSProp(自适应学习率).
optimizer = optim.RMSprop(params=[w], lr=0.01, alpha=0.99)
# 4. 计算梯度值: 梯度清零 + 反向传播 + 参数更新
optimizer.zero_grad()
criterion.sum().backward()
optimizer.step()
print(f'w: {w}, w.grad: {w.grad}')
# 5.重复上述的步骤, 第2次 更新权重参数.
# 5.1 定义损失函数.
criterion = ((w ** 2) / 2.0)
# 5.2 计算梯度值: 梯度清零 + 反向传播 + 参数更新
optimizer.zero_grad()
criterion.sum().backward()
optimizer.step()
# 5.3 打印结果.
print(f'w: {w}, w.grad: {w.grad}')
# 4. 定义函数, 演示: 梯度下降优化方法 -> 自适应矩估计(Adam)
def dm04_adam():
# 1. 初始化权重参数.
w = torch.tensor([1.0], requires_grad=True, dtype=torch.float32)
# 2. 定义损失函数
criterion = ((w ** 2) / 2.0)
# 3. 创建优化器(函数对象)
# 思路1: 基于SGD(随机梯度下降), 加入参数 momentum, 就是 动量法.
# 参1: (待优化的)参数列表, 参2: 学习率, 参3: 动量参数.
# optimizer = optim.SGD(params=[w], lr=0.01, momentum=0.9) # 细节: momentum=0(默认), 只考虑: 本次梯度.
# 思路2: 基于AdaGrad(自适应学习率).
# optimizer = optim.Adagrad(params=[w], lr=0.01)
# 思路3: 基于RMSProp(自适应学习率).
# optimizer = optim.RMSprop(params=[w], lr=0.01, alpha=0.99)
# 思路4: 基于Adam(自适应矩估计).
optimizer = optim.Adam(params=[w], lr=0.01, betas=(0.9, 0.999)) # betas=(梯度用的 衰减系数, 学习率用的 衰减系数)
# 4. 计算梯度值: 梯度清零 + 反向传播 + 参数更新
optimizer.zero_grad()
criterion.sum().backward()
optimizer.step()
print(f'w: {w}, w.grad: {w.grad}')
# 5.重复上述的步骤, 第2次 更新权重参数.
# 5.1 定义损失函数.
criterion = ((w ** 2) / 2.0)
# 5.2 计算梯度值: 梯度清零 + 反向传播 + 参数更新
optimizer.zero_grad()
criterion.sum().backward()
optimizer.step()
# 5.3 打印结果.
print(f'w: {w}, w.grad: {w.grad}')
# 5. 测试
if __name__ == '__main__':
dm01_momentum()
# dm02_adagrad()
# dm03_rmsprop()
# dm04_adam()5.1 梯度下降法
-
公式:
w₁ = w₀ - lr × grad-
w₀:上一版模型参数 -
lr:学习率 -
grad:反向传播计算的梯度
-
5.2 基本概念
| 术语 | 含义 |
|---|---|
| epoch | 训练次数 |
| iteration | 每次训练需要迭代的次数 = 样本数/batch_size(向上取整) |
| batch_size | 每次迭代需要的样本数 |
5.3 优化方法对比
| 优化方法 | 原理 | 特点 | 适用场景 |
|---|---|---|---|
| Momentum |
St = β * St-1 + (1 - β) * Gt |
即使当前梯度为0,仍能参考历史梯度继续更新 | 通用 |
| Adagrad |
St = St-1 + Gt * Gt 学习率 = 学习率 / (sqrt(St) + 小常数) |
自动调整学习率:前期大,后期小,可能导致学习率过早衰减 | 高维稀疏数据、文本数据 |
| RMSprop |
St = β * St-1 + (1 - β) * Gt * Gt 学习率 = 学习率 / (sqrt(St) + 小常数) |
避免Adagrad学习率下降过快 | 高维稀疏数据、文本数据 |
| Adam | Momentum + RMSprop | 综合两者优点,优先选择 | 通用 |
5.4 反向传播算法(BP)
-
根据损失值计算梯度
-
损失值和权重参数求导过程
-
梯度连乘:
-
∂loss/∂w = (loss对a) × (a对z) × (z对w) = (损失对激活值) × (激活函数斜率) × (输入x)
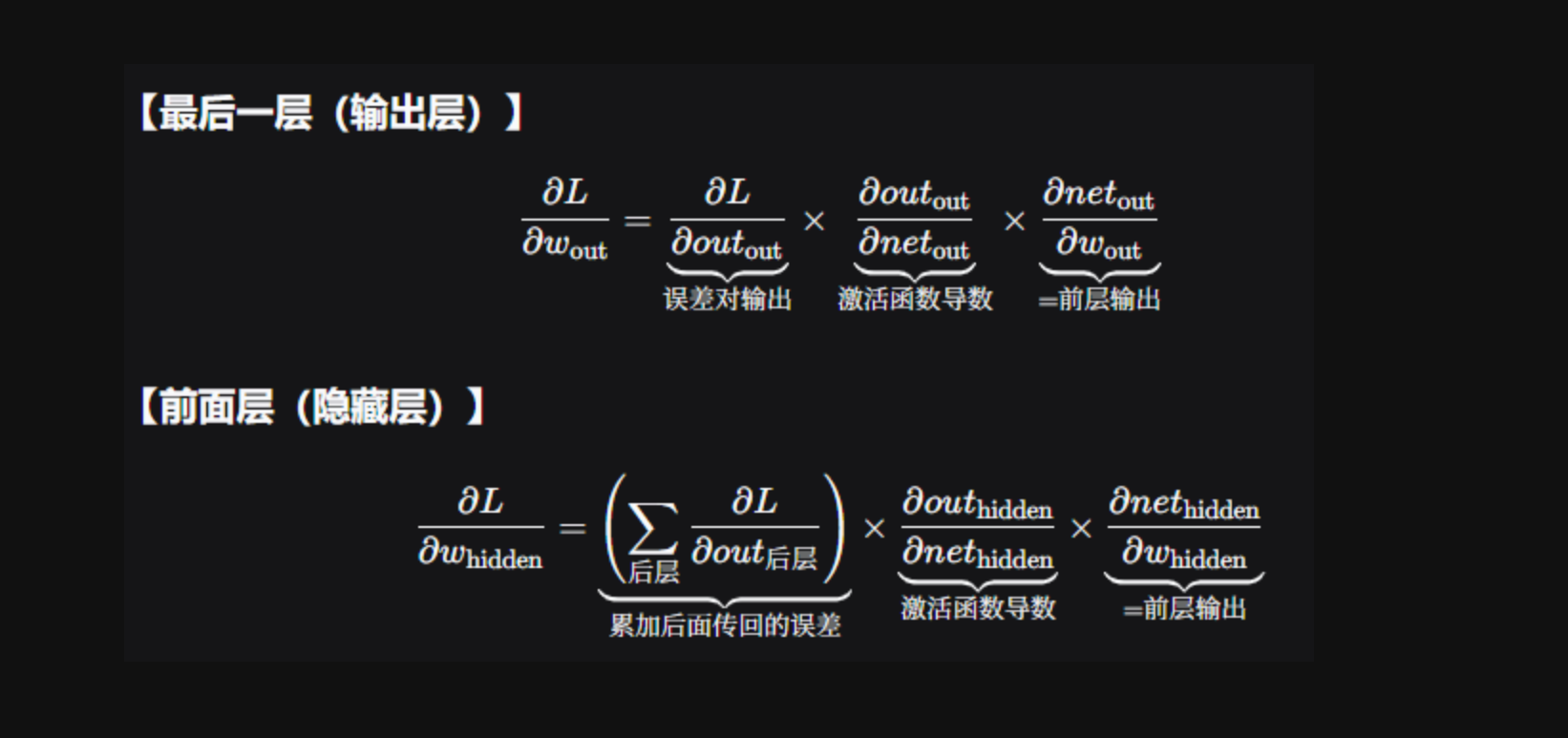
| 层位置 | 核心公式 | 难点 |
|---|---|---|
| 输出层 | 梯度 = (输出误差) × (激活导数) × (前层输出) | 直接算,简单 |
| 隐藏层 | 梯度 = [累加后面所有路径的误差] × (激活导数) × (前层输出) | 需要逐层反向累加 |
5.5 学习率衰减策略
学习率越小, 梯度下降越慢.
学习率越大, 梯度下降越快, 可能会越过最小值, 造成震荡, 甚至不收敛(梯度爆炸)| 策略 | 公式 | 特点 | PyTorch实现 |
|---|---|---|---|
| 等间隔衰减 | lr = lr × gamma |
步长相等,学习率随训练次数减小 | StepLR(optimizer, step_size=50, gamma=0.5) |
| 指定间隔衰减 | lr = lr × gamma |
自定义训练次数步长 | MultiStepLR(optimizer, milestones=[50,100,160], gamma=0.5) |
| 指数衰减 | lr = lr × gamma^epoch |
前期减小快,后期减小慢 | ExponentialLR(optimizer, gamma=0.9) |
"""
案例:
演示学习率衰减策略.
学习率衰减策略介绍:
目的:
较之于AdaGrad, RMSProp, Adam方式, 我们可以通过 等间隔, 指定间隔, 指数等方式, 来手动控制学习率的调整.
分类:
等间隔学习率衰减
指定间隔学习率衰减
指数学习率衰减
等间隔学习率衰减:
step_size: 间隔的轮数, 即: 多少轮调整一次学习率.
gamma: 学习率衰减系数, 即: lr新 = lr旧 * gamma
指定间隔学习率衰减:
milestones = [50, 125, 160] 里边定义的是要调整学习率的 轮数.
gamma: 学习率衰减系数, 即: lr新 = lr旧 * gamma
指数间隔学习率衰减:
前期学习率衰减快, 中期慢, 后期更慢, 更符合梯度下降规律.
公式:
lr新 = lr旧 * gamma ** epoch
总结:
等间隔学习率衰减:
优点:
直观, 易于调试, 适用于 大批量数据.
缺点:
学习率变化较大, 可能跳过最优解.
应用场景:
大型数据集, 较为简单的任务.
指定间隔学习率衰减:
优点:
易于调试, 稳定训练过程.
缺点:
在某些情况下可能衰减过快, 导致优化提前停滞.
应用场景:
对应训练平稳性要求较高的任务.
指数学习率衰减:
优点:
平滑, 且考虑历史更新, 收敛稳定性较强.
缺点:
超参调节较为复杂, 可能需要更多的资源.
应用场景:
高精度训练, 避免过快收敛.
"""
# 导包
import torch
from torch import optim
import matplotlib.pyplot as plt
# 1. 定义变量, 记录初始的 学习率, 训练的轮数, 每轮训练的批次数.
lr, epochs, iteration = 0.1, 200, 10
# 2. 创建数据集. y_true, x, w
# 真实值.
y_true = torch.tensor([0])
# 输入特征
x = torch.tensor([1.0], dtype=torch.float32)
# 权重参数w, 需要自动微分(求导)
w = torch.tensor([1.0], requires_grad=True, dtype=torch.float32)
# 3. 创建优化器对象, 动量法 -> 加速模型的收敛, 减少震荡.
# 参1: 待优化的参数, 参2: 学习率, 参3: 动量系数
optimizer = optim.SGD([w], lr=lr, momentum=0.9)
# 4. 创建学习率衰减对象.
# 思路1: 创建等间隔学习率衰减对象.
# 参1: 优化器对象, 参2: 间隔的轮数(多少轮调整一次学习率), 参3: 学习率衰减系数.
# scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=50, gamma=0.5) # [0.1, 0.1, 0.1... 0.05...]
# 定义变量, 记录要修改学习率的轮数.
# 思路1: 创建等间隔学习率衰减对象.
# scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=50, gamma=0.5) # [0.1, 0.1, 0.1... 0.05...]
# 思路2: 创建指定间隔学习率衰减对象.
# milestones = [50, 125, 160]
# scheduler = optim.lr_scheduler.MultiStepLR(optimizer, milestones=milestones, gamma=0.5)
# 思路3: 创建指数衰减学习率对象.
scheduler = optim.lr_scheduler.ExponentialLR(optimizer, gamma=0.95)
# 5. 创建两个列表, 分别表示: 训练轮数, 每轮训练用的学习率
# epoch_list = [0, 1, 2, 3.... 50, 51, 52...100, 101, 101... 150, 151...199]
# lr_list = [0.1, 0.1, 0.1, 0.05........,0.025........., 0.0125...]
lr_list, epoch_list = [], []
# 6. 循环遍历训练轮数, 进行具体的训练.
for epoch in range(epochs): # epoch: 0 ~ 199
# 7. 获取当前轮数 和 学习率, 并保存到列表中.
epoch_list.append(epoch)
lr_list.append(scheduler.get_last_lr()) # 获取最后的lr(learning rate, 学习率)
# 8. 循环遍历, 每轮每批次进行训练.
for batch in range(iteration):
# 9. 先计算预测值, 然后基于损失函数计算损失.
y_pred = w * x
# 10. 计算损失, 最小二乘法.
loss = (y_pred - y_true) ** 2
# 11. 梯度清零 + 反向传播 + 优化器更新参数.
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 12. 更新学习率.
scheduler.step()
# 13. 打印结果:
print(f'lr_list: {lr_list}') # [0.1, 0.1, 0.1..., 0.05........,0.025........., 0.0125...]
# 14. 可视化.
# x轴: 训练的轮数, y轴: 每轮训练用的学习率
plt.plot(epoch_list, lr_list)
plt.xlabel('Epoch')
plt.ylabel('Learning Rate')
plt.show()
六、学习要点总结
关键概念
-
神经元计算:线性部分 + 非线性激活
-
网络结构:输入层 → 隐藏层 → 输出层
-
激活函数选择:隐藏层优先ReLU,输出层根据任务选择
-
初始化方法:根据激活函数选择Kaiming或Xavier
-
优化器选择:优先Adam
-
学习率策略:结合衰减策略提升训练效果
常见问题与解决方案
-
梯度消失:使用ReLU、合理初始化、残差结构
-
梯度爆炸:梯度裁剪、合理初始化、Smooth L1损失
-
神经元死亡:使用Leaky ReLU、调整学习率
-
过拟合:正则化、Dropout、数据增强

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 15
15 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)