【AI大模型前沿】小米开源语音大模型 Xiaomi-MiMo-Audio:开启语音领域的LLaMA时刻
Xiaomi-MiMo-Audio 是小米开源的首个原生端到端语音大模型,基于创新预训练架构和上亿小时训练数据,首次在语音领域实现基于 In-Context Learning(ICL)的少样本泛化能力,打破了语音领域依赖大规模标注数据的瓶颈。该模型在多项标准评测基准中表现出色,大幅超越同参数量的开源模型,取得7B最佳性能。小米开源了预训练模型 MiMo-Audio-7B-Base 和指令微调模型
系列篇章💥
目录
前言
在人工智能领域,语音技术一直是研究的热点之一。然而,现有的语音模型大多依赖大规模标注数据,难以快速适应新任务,难以达到类人智能。小米公司近期开源的首个原生端到端语音大模型 Xiaomi-MiMo-Audio,打破了这一瓶颈。
一、项目概述
Xiaomi-MiMo-Audio 是小米开源的首个原生端到端语音大模型,基于创新预训练架构和上亿小时训练数据,首次在语音领域实现基于 In-Context Learning(ICL)的少样本泛化能力,打破了语音领域依赖大规模标注数据的瓶颈。该模型在多项标准评测基准中表现出色,大幅超越同参数量的开源模型,取得7B最佳性能。小米开源了预训练模型 MiMo-Audio-7B-Base 和指令微调模型 MiMo-Audio-7B-Instruct,以及1.2B参数量的 Tokenizer 模型,支持音频重建和音频转文本任务。
二、核心功能
(一)少样本泛化能力
Xiaomi-MiMo-Audio 首次在语音领域实现基于 ICL 的少样本泛化,仅需少量样本即可快速适应新任务,展现出极高的学习效率。这一能力使得模型能够在面对新的语音任务时,通过少量的示例数据快速理解和生成准确的语音内容,极大地提高了模型的灵活性和适应性。
(二)跨模态对齐能力
后训练进一步激发了模型的智商、情商、表现力与安全性等跨模态对齐能力,语音对话在自然度、情感表达和交互适配上呈现极高的拟人化水准。这意味着 MiMo-Audio 不仅能够理解语音内容,还能够以自然、流畅的方式进行语音交互,提供更加人性化的体验。
(三)语音理解和生成
在通用语音理解及对话等多项标准评测基准中,MiMo-Audio 大幅超越同参数量的开源模型,取得7B最佳性能,还超过了一些闭源语音模型。这表明 MiMo-Audio 在语音识别和生成方面具有卓越的性能,能够准确理解和生成高质量的语音内容。
(四)音频复杂推理
在面向音频复杂推理的基准 Big Bench Audio S2T 任务中表现出色,展现了强大的音频复杂推理能力。这一能力使得模型能够处理复杂的音频任务,如语音转文本、语音编辑等,为音频内容的处理和分析提供了强大的支持。
(五)语音续写能力
预训练模型 MiMo-Audio-7B-Base 是目前开源领域第一个有语音续写能力的语音模型。这一功能使得模型能够根据给定的语音片段生成自然流畅的语音续写内容,为语音内容创作提供了新的可能性。
(六)支持混合思考
是首个把 Thinking 同时引入语音理解和语音生成过程中的开源模型,支持混合思考。这一机制使得模型在处理语音任务时能够更加灵活地运用逻辑推理和创造性思维,进一步提升了模型的性能。
(七)音频转文本任务
Tokenizer 模型支持音频转文本(A2T)任务,覆盖超过千万小时语音数据。这一功能使得模型能够高效地将语音内容转换为文本,为语音识别和文本处理提供了强大的支持。
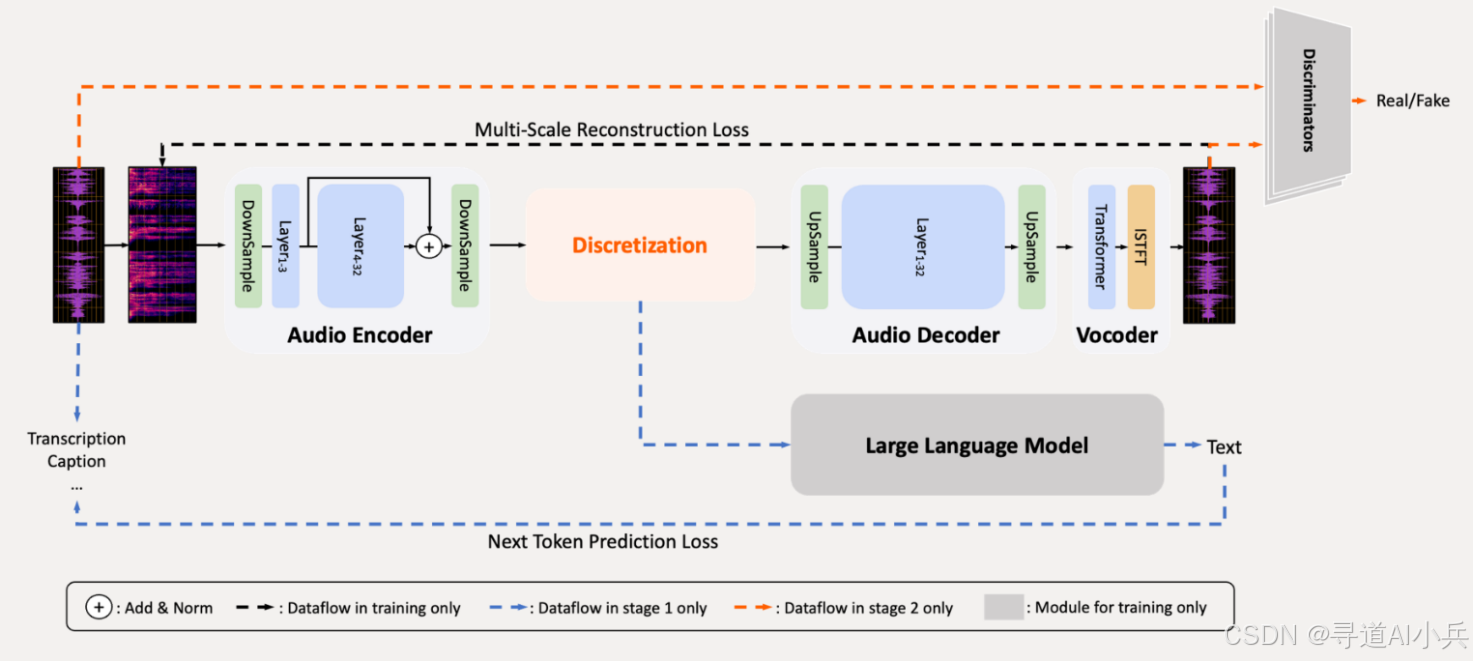
三、技术揭秘
(一)创新预训练架构
Xiaomi-MiMo-Audio 采用创新的预训练架构,包括 patch 编码器 + 大语言模型 + patch 解码器的三段式结构。这一设计在 1 亿多小时多源语料上完成预训练,在突破 7000 亿 token 阈值后出现显著的“能力涌现”。
(二)无损压缩预训练
该模型首次证明了把语音无损压缩预训练扩展至 1 亿小时可以“涌现”出跨任务的泛化性,表现为 Few-Shot Learning 能力。这被认为是语音领域的“GPT-3 时刻”。
(三)Tokenizer 模型
采用 1.2B 参数量的 Transformer 架构 Tokenizer 模型,从头开始训练,覆盖超过千万小时语音数据,同时支持音频重建任务和音频转文本(A2T)任务。
(四)轻量后训练
通过轻量级的后训练(SFT),进一步优化模型性能,使其在语音理解和生成方面表现出色。后训练阶段,模型通过少量的标注数据进行微调,进一步提升模型的性能和适应性。
(五)混合思考机制
将 Thinking 机制同时引入语音理解和语音生成过程中,支持混合思考,提升了模型的复杂推理能力。这一机制使得模型在处理语音任务时能够更加灵活地运用逻辑推理和创造性思维,进一步提升了模型的性能。
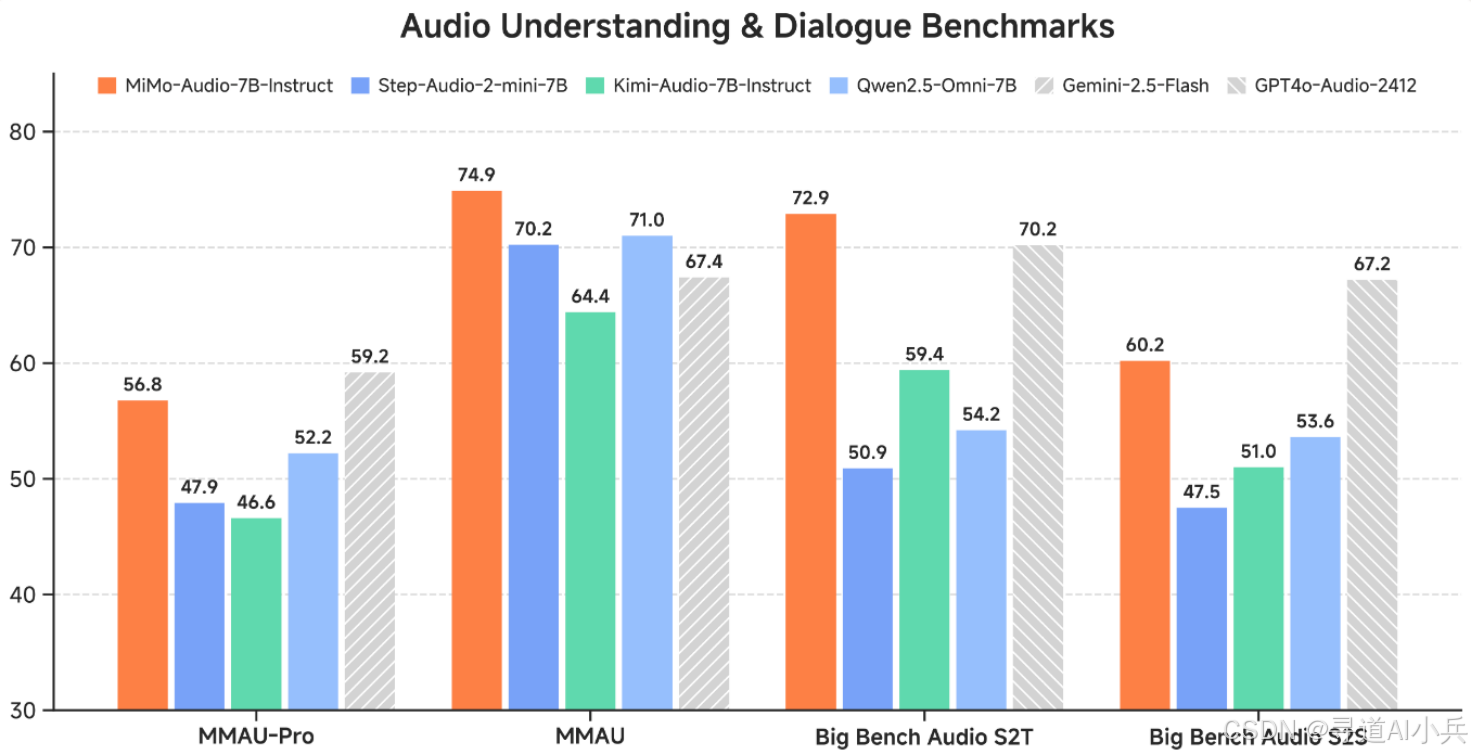
四、性能表现
MiMo-Audio在音频理解基准(MMSU、MMAU、MMAR、MMAU-Pro)、口语对话基准(Big Bench Audio、MultiChallenge Audio)和instruct-TTS评估上实现开源SOTA,接近或超越闭源模型。
五、应用场景
(一)语音交互
可用于智能语音助手,提供更自然、更智能的语音交互体验,支持多种语言和方言的对话。例如,智能语音助手可以通过 MiMo-Audio 实现更加自然流畅的语音对话,提供更加人性化的服务。
(二)语音生成
能生成高质量的语音内容,适用于有声读物、语音播报、语音导航等场景。例如,有声读物可以通过 MiMo-Audio 生成自然流畅的语音内容,提升用户的听觉体验。
(三)语音转文本
支持语音转文本(A2T)任务,可应用于会议记录、语音输入、语音搜索等场景。例如,会议记录可以通过 MiMo-Audio 快速准确地将语音内容转换为文本,提高工作效率。
(四)音频内容创作
帮助内容创作者生成音频脚本或语音内容,提升创作效率。例如,内容创作者可以通过 MiMo-Audio 生成高质量的音频脚本,提升创作效率和质量。
(五)情感表达
在语音对话中展现丰富的情感表达,适用于情感陪伴机器人、客服系统等需要情感交互的场景。例如,情感陪伴机器人可以通过 MiMo-Audio 提供更加自然的情感表达,提升用户的陪伴体验。
(六)语音识别与理解
在音频理解基准测试中表现出色,可用于语音识别、语音指令控制等场景。例如,语音指令控制可以通过 MiMo-Audio 准确识别和理解用户的语音指令,提供更加便捷的交互体验。
六、快速使用
(一)环境准备
Python 3.12:确保安装了 Python 3.12 或更高版本。
CUDA >= 12.0:确保安装了 CUDA 12.0 或更高版本,以支持 GPU 加速。
(二)安装依赖
克隆仓库代码、安装相关依赖
git clone https://github.com/XiaomiMiMo/MiMo-Audio.git
cd MiMo-Audio
pip install -r requirements.txt
pip install flash-attn==2.7.4.post1
(三)运行演示
启动一个本地的 Gradio 界面,您可以通过该界面与 MiMo-Audio 交互。
python run_mimo_audio.py
(四)模型下载
pip install huggingface-hub
hf download XiaomiMiMo/MiMo-Audio-Tokenizer --local-dir ./models/MiMo-Audio-Tokenizer
hf download XiaomiMiMo/MiMo-Audio-7B-Base --local-dir ./models/MiMo-Audio-7B-Base
hf download XiaomiMiMo/MiMo-Audio-7B-Instruct --local-dir ./models/MiMo-Audio-7B-Instruct
七、结语
小米开源的Xiaomi - MiMo - Audio语音大模型,以其创新架构与卓越性能,为语音技术发展带来新契机。它打破依赖大量标注数据的瓶颈,实现少样本泛化,在多项评测中接近或超越闭源模型。其多样化应用场景,如智能交互、语音创作等,展现了广阔前景。开源不仅促进技术共享,还激发开发者创新。随着更多人参与研究,有望推动语音技术取得更大突破,让语音交互更加智能、自然,为生活和工作增添更多便利。
八、项目地址
- 项目官网:https://xiaomimimo.github.io/MiMo-Audio-Demo/
- Github 仓库:https://github.com/XiaomiMiMo/MiMo-Audio
- HuggingFace 模型库:https://huggingface.co/XiaomiMiMo
- 技术论文:https://github.com/XiaomiMiMo/MiMo-Audio/blob/main/MiMo-Audio-Technical-Report.pdf

🎯🔖更多专栏系列文章:AI大模型提示工程完全指南、AI大模型探索之路(零基础入门)、AI大模型预训练微调进阶、AI大模型开源精选实践、AI大模型RAG应用探索实践🔥🔥🔥 其他专栏可以查看博客主页📑
😎 作者介绍:资深程序老猿,从业10年+、互联网系统架构师,目前专注于AIGC的探索(CSDN博客之星|AIGC领域优质创作者)
📖专属社群:欢迎关注【小兵的AI视界】公众号或扫描下方👇二维码,回复‘入群’ 即刻上车,获取邀请链接。
💘领取三大专属福利:1️⃣免费赠送AI+编程📚500本,2️⃣AI技术教程副业资料1套,3️⃣DeepSeek资料教程1套🔥(限前500人)
如果文章内容对您有所触动,别忘了点赞、⭐关注,收藏!加入我们,一起携手同行AI的探索之旅,开启智能时代的大门!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 20
20 0
0- 0



 已为社区贡献30条内容
已为社区贡献30条内容

所有评论(0)