【datawhale学习-post training】task4-GRPO
Topic-GRPO
本文基于 DeepLearning.AI 出品的短课 《Post‑training of LLMs》,并在datawhale组织帮助下学习:github
前言
首先,我们得区别一下RL for LLM中的online learning和offline learning。这里的online和offline是依靠数据是否实时生成来区分:
- online:实时生成新的回答,随后根据生成的回答拿到奖励,用这个去更新模型参数。
- offline:预先收集(prompt, response, reward)三元组,随后用这个已有的数据去更新模型参数。
同时,我们还得区分一下RL里面的on-policy和off-policy。这里的on和off是根据行为策略和数据策略是否一致来区分的:
- on-policy: 强化学习中的行为策略(生成数据)和目标策略(学习的策略)是相同的。代表有SARSA,PPO。
- off-policy: 行为策略与目标策略不同,可以使用来自其他策略生成的数据。代表有Q-learning,DQN,DDPG。
具体on-policy和off-policy的区别详见我另外一个博客:
总之我们要知道online/offline learning和on/off-policy是不同的概念。
我们今天的重点是探讨online learning for LLM,由于我们已经在上一章节探讨过PPO在RLHF中的使用,所以我们今天主要关注GRPO。
| 项目 | PPO / GRPO (Online) | DPO (Offline) |
|---|---|---|
| 是否需要实时生成数据 | ✔ 必须 | ✘ 不需要 |
| 数据来自 | 当前策略 | 静态偏好对 |
| 是否 on-policy | ✔ 是 | ✘ 否 |
| 是否可离线训练 | ❌ 不可能 | ✔ 完全可以 |
| 资源成本 | 极高 | 极低 |
| 稳定性 | 较差 | 极高 |
定义
GRPO 首次提出于 DeepSeek 的论文《DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models》。
论文中是如此介绍GRPO算法的:
We introduce Group Relative Policy Optimization (GRPO), an efficient and effective reinforcement learning algorithm. GRPO foregoes the critic model, instead estimating the baseline from group scores, significantly reducing training resources compared to Proximal Policy Optimization (PPO).
我们可以得到如下关键点:
- GRPO放弃了PPO里面的critic(value) model (之前在PPO里面是作为baseline使用的)
- 现在把baseline设置为同组回答之间的相对比较(group-relative advantage)
- 于是节约了很多训练资源
正文
PPO
让我们先来回顾一下PPO的来历:
PPO属于actor-critic框架,其loss为:
L clip ( θ ) = E [ min ( r ( θ ) A , clip ( r ( θ ) , 1 − ϵ , 1 + ϵ ) A ) ] L^{\operatorname{clip}}(\theta)=\mathbb{E}\left[\min(r(\theta)A,\operatorname{clip}(r(\theta),1-\epsilon,1+\epsilon)A)\right] Lclip(θ)=E[min(r(θ)A,clip(r(θ),1−ϵ,1+ϵ)A)]
其中最重要的trick有以下三点:
5. 采用advantage,即 A t = R − V ( s t ) A_t=R-V(s_t) At=R−V(st), 采用这种在均值之上和在均值之下的方式去降低训练方差,提高稳定性。
6. 采用ratio r t = π θ ( a t ∣ s t ) π θ o l d ( a t ∣ s t ) r_t=\frac{\pi_\theta(a_t|s_t)}{\pi_{\theta_{\mathrm{old}}}(a_t|s_t)} rt=πθold(at∣st)πθ(at∣st),即旧模型和新模型在同一个动作下的概率比,用于衡量新模型是否变化太大。
7. 采用clip,即把 r ( θ ) r(\theta) r(θ) 限制在 ( 1 − ϵ , 1 + ϵ ) (1-\epsilon,1+\epsilon) (1−ϵ,1+ϵ)范围里。
但实际上:
- Advantage trick → 来自 Actor–Critic(AC)结构 + GAE 演化
- Policy Ratio → 来自 TRPO 的“importance sampling ratio”
- Clip → 这才是 PPO 的原创核心
Policy Gradient
↓
Actor–Critic(Advantage function)
↓
GAE(更稳定的 Advantage)
↓
TRPO(policy ratio + trust region)
↓
PPO(把 trust region 用 clip 实现)
PPO的advantage是怎么回事?
GRPO主要解决的是Advantage 的 baseline 选择问题。所以这不是PPO原创带来的问题,而是PPO这一支(actor-critic架构)都有的问题。
所以我们先来分析一下Advantage是怎么来的。我简单带过一下,具体的可以看lilian的policy-based algorithm一脉的推导
这其实要从policy最基础的reinforce说起:
目标:我们要最大化期望回报:
J ( θ ) = E τ ∼ π θ [ R ( τ ) ] J(\theta) = \mathbb{E}_{\tau \sim \pi_\theta} [R(\tau)] J(θ)=Eτ∼πθ[R(τ)]
通过对数导数技巧,我们可以将上述式子变为:
∇ θ J ( θ ) = E τ ∼ π θ [ ∑ t = 0 T − 1 ∇ θ log π θ ( a t ∣ s t ) R ( τ ) ] . \nabla_\theta J(\theta) =\mathbb{E}_{\tau\sim \pi_\theta}\left[\sum_{t=0}^{T-1}\nabla_\theta \log \pi_\theta(a_t|s_t) R(\tau)\right]. ∇θJ(θ)=Eτ∼πθ[t=0∑T−1∇θlogπθ(at∣st)R(τ)].
随后利用因果性:
在时刻 ( t ) (t) (t) 的动作 ( a t ) (a_t) (at) 不会影响之前的奖励 ( r 0 , … , r t − 1 ) ({r_0,\dots,r_{t-1}}) (r0,…,rt−1)。因此,把 ( R ( τ ) ) (R(\tau)) (R(τ)) 拆成两段并丢掉与 ( ∇ θ log π θ ( a t ∣ s t ) ) (\nabla_\theta \log \pi_\theta(a_t|s_t)) (∇θlogπθ(at∣st)) 无关的过去部分,不改变期望:记“从 ( t ) (t) (t) 开始的回报-到-去”(return-to-go): G t ≜ ∑ t ′ = t T γ t ′ − t r t ′ . G_t \triangleq \sum_{t'=t}^{T} \gamma^{t'-t} r_{t'}. Gt≜∑t′=tTγt′−trt′.
可得
∇ θ J ( θ ) = E τ ∼ π θ [ ∑ t = 0 T − 1 ∇ θ log π θ ( a t ∣ s t ) G t ] . \nabla_\theta J(\theta) =\mathbb{E}_{\tau\sim \pi_\theta}\left[\sum_{t=0}^{T-1}\nabla_\theta \log \pi_\theta(a_t|s_t) G_t\right]. ∇θJ(θ)=Eτ∼πθ[t=0∑T−1∇θlogπθ(at∣st)Gt].
然后为了降低方差,我们利用减方差技巧:
由于对任意函数 ( b ( s t ) ) (b(s_t)) (b(st))(不依赖 a t a_t at),有
E a t ∼ π θ ( ⋅ ∣ s t ) [ ∇ θ log π θ ( a t ∣ s t ) b ( s t ) ] = 0 , \mathbb{E}_{a_t\sim \pi_\theta(\cdot|s_t)}\big[\nabla_\theta \log \pi_\theta(a_t|s_t) b(s_t)\big]=0, Eat∼πθ(⋅∣st)[∇θlogπθ(at∣st)b(st)]=0,
因此我们直接减去 b ( s t ) b(s_t) b(st) 不改变无偏性:
∇ θ J ( θ ) = E τ ∼ π θ [ ∑ t = 0 T − 1 ∇ θ log π θ ( a t ∣ s t ) ( G t − b ( s t ) ) ] . \nabla_\theta J(\theta) =\mathbb{E}_{\tau\sim \pi_\theta}\left[\sum_{t=0}^{T-1}\nabla_\theta \log \pi_\theta(a_t|s_t) \big(G_t - b(s_t)\big)\right]. ∇θJ(θ)=Eτ∼πθ[t=0∑T−1∇θlogπθ(at∣st)(Gt−b(st))].
这个 b ( s t ) b(s_t) b(st) 就被我们称为baseline,最常见的选择是 ( b ( s t ) = V π ( s t ) ) (b(s_t)=V^\pi(s_t)) (b(st)=Vπ(st)),相当于当前状态动作平均后的价值,那么我们定义优势函数advantage ( A ^ t = G t − V ^ ( s t ) ) (\hat A_t=G_t-\hat V(s_t)) (A^t=Gt−V^(st)) 意味着评价模型某个动作比平均水平更好还是更差,则结果为:
∇ θ J ( θ ) ≈ E [ ∑ t ∇ θ log π θ ( a t ∣ s t ) A ^ t ] , \nabla_\theta J(\theta)\approx \mathbb{E}\left[\sum_{t}\nabla_\theta \log \pi_\theta(a_t|s_t) \hat A_t\right], ∇θJ(θ)≈E[t∑∇θlogπθ(at∣st)A^t],
如果advantage 为正,则梯度为正,该动作被强化。advantage 为负 → 被弱化
这里由于我们要计算advantage类似评价当前动作相对平均水平的好坏,,就要额外训练一个 V π ( s t ) V^\pi(s_t) Vπ(st)模型充当baseline,所以此时就出现了actor-critic架构。critic训练value model,actor训练 policy model。
更改baseline成为GRPO!
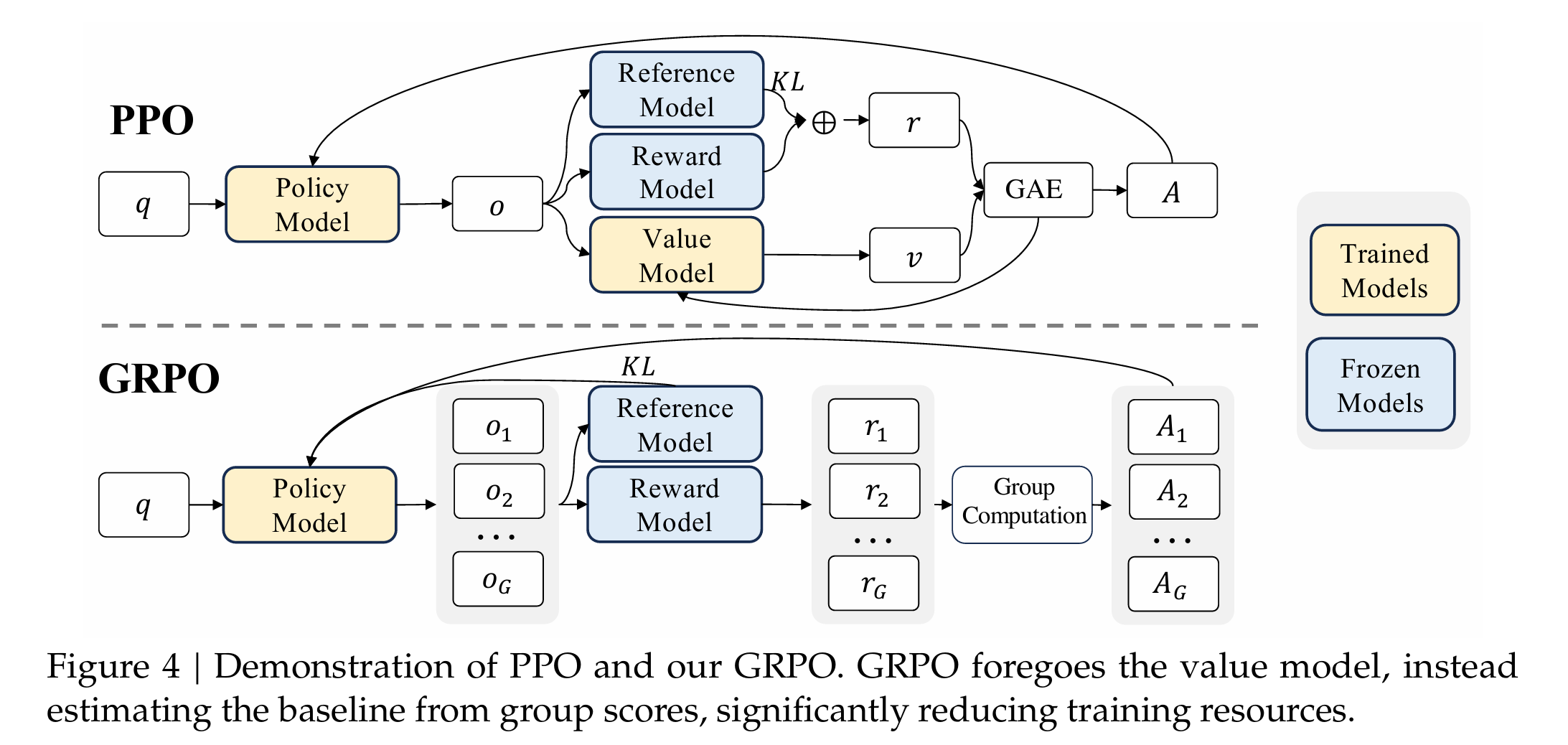
J P P O ( θ ) = E [ q ∼ P ( Q ) , o ∼ π θ o l d ( O ∣ q ) ] 1 ∣ o ∣ ∑ t = 1 ∣ o ∣ min [ π θ ( o t ∣ q , o < t ) π θ o l d ( o t ∣ q , o < t ) A t , c l i p ( π θ ( o t ∣ q , o < t ) π θ o l d ( o t ∣ q , o < t ) , 1 − ε , 1 + ε ) A t ] , \mathcal{J}_{PPO}(\theta)=\mathbb{E}[q\sim P(Q),o\sim\pi_{\theta_{\mathrm{old}}}(O|q)]\frac{1}{|o|}\sum_{t=1}^{|o|}\min\left[\frac{\pi_\theta(o_t|q,o_{<t})}{\pi_{\theta_{\mathrm{old}}}(o_t|q,o_{<t})}A_t,\mathrm{clip}\left(\frac{\pi_\theta(o_t|q,o_{<t})}{\pi_{\theta_{\mathrm{old}}}(o_t|q,o_{<t})},1-\varepsilon,1+\varepsilon\right)A_t\right], JPPO(θ)=E[q∼P(Q),o∼πθold(O∣q)]∣o∣1t=1∑∣o∣min[πθold(ot∣q,o<t)πθ(ot∣q,o<t)At,clip(πθold(ot∣q,o<t)πθ(ot∣q,o<t),1−ε,1+ε)At],
我们结合上图来说, 蓝色的相当于模型参数会被冻住,黄色的会在过程中也被训练。但之前拿训练 V π ( s t ) V^\pi(s_t) Vπ(st)模型充当baseline的方法在LLM中会有一个最主要的问题。相当于我训练一个policy model(LLM)已经要消耗很大的资源了,那么我还要训练一个value model,那么内存和计算成本将直接翻倍。所以一个新的问题,在LLM设定下,能否有其他的东西充当baseline?
GRPO的核心思想是:用一个局部的、经验性的“群体基线”来代替全局的、学习出来的“价值基线” V ( s ) V(s) V(s)。
所以GRPO的GR( Group Relative) 由此而来。
PPO的采样 (Actor-Critic):
- 对于一个状态 s s s(例如一个Prompt),Actor π θ o l d \pi_{\theta_{old}} πθold 采样1个动作 a a a(例如1个Response)。
- 用Reward Model 给 ( s , a ) (s, a) (s,a) 打分,得到奖励 R R R。用Critic V ϕ V_\phi Vϕ 估计 V ( s ) V(s) V(s)。
- 计算优势 A ^ = R − V ( s ) \hat{A} = R - V(s) A^=R−V(s) (此处为简化版)。
GRPO的采样 (Critic-Free):
- 对于同一个状态 s s s(同一个Prompt),Actor π θ o l d \pi_{\theta_{old}} πθold 采样一个Group”,即 G G G 个不同的动作(例如 G = 8 G=8 G=8 个Responses)。
- 用Reward Model 给这 G G G 个Response全部打分,得到一组奖励 { R 1 , R 2 , … , R G } \{R_1, R_2, \dots, R_G\} {R1,R2,…,RG}。
- 关键: 在这个“群体”内部,当场计算这组奖励的均值 μ group \mu_{\text{group}} μgroup 和标准差 σ group \sigma_{\text{group}} σgroup。对于这个群体中的每一个样本 i i i,它的“advantage”被定义为其标准分 (z-score): A ^ i = R i − μ group σ group \hat{A}_i = \frac{R_i - \mu_{\text{group}}}{\sigma_{\text{group}}} A^i=σgroupRi−μgroup
| 特性 | PPO (Actor-Critic) | GRPO (Critic-Free) |
|---|---|---|
| 优势 (A^t) 来源 | 依赖 Critic 网络 V ( s ) V(s) V(s) | 依赖 群体采样(group baseline) |
| 优势 (A^t) 计算 | A t = R reward − V A^t = R_{\text{reward}}-V At=Rreward−V | A ^ i , t = R i , t − μ group σ group \hat{A}_{i,t} = \frac{R_{i,t} - \mu_{\text{group}}}{\sigma_{\text{group}}} A^i,t=σgroupRi,t−μgroup |
| 内存开销 | ~2 倍(Actor + Critic) | 1 倍(只有 Actor) |
| 适用场景 | 通用 RL 任务 | LLM |
论文中的loss
从LLM的视角来看,PPO的总体loss为
J P P O ( θ ) = E [ q ∼ P ( Q ) , o ∼ π θ o l d ( O ∣ q ) ] 1 ∣ o ∣ ∑ t = 1 ∣ o ∣ min [ π θ ( o t ∣ q , o < t ) π θ o l d ( o t ∣ q , o < t ) A t , c l i p ( π θ ( o t ∣ q , o < t ) π θ o l d ( o t ∣ q , o < t ) , 1 − ε , 1 + ε ) A t ] , \mathcal{J}_{PPO}(\theta)=\mathbb{E}[q\sim P(Q),o\sim\pi_{\theta_{\mathrm{old}}}(O|q)]\frac{1}{|o|}\sum_{t=1}^{|o|}\min\left[\frac{\pi_\theta(o_t|q,o_{<t})}{\pi_{\theta_{\mathrm{old}}}(o_t|q,o_{<t})}A_t,\mathrm{clip}\left(\frac{\pi_\theta(o_t|q,o_{<t})}{\pi_{\theta_{\mathrm{old}}}(o_t|q,o_{<t})},1-\varepsilon,1+\varepsilon\right)A_t\right], JPPO(θ)=E[q∼P(Q),o∼πθold(O∣q)]∣o∣1t=1∑∣o∣min[πθold(ot∣q,o<t)πθ(ot∣q,o<t)At,clip(πθold(ot∣q,o<t)πθ(ot∣q,o<t),1−ε,1+ε)At],
- π θ \pi_\theta πθ 和 π θ o l d \pi_{\theta_{old}} πθold 分别是当前和旧的策略模型
- q 和 o 是从问题数据集中采样的question和output,o采样自旧策略 π θ o l d \pi_{\theta_{old}} πθold。
- ϵ \epsilon ϵ 是 PPO-clipping相关的超参数。
- A t A_t At 是优势函数,通过应用“广义优势估计”(Generalized Advantage Estimation, GAE)来计算的, A t = r t − V A_t=r_t-V At=rt−V.
- r t = r φ ( q , o ≤ t ) − β log π θ ( o t ∣ q , o < t ) π r e f ( o t ∣ q , o < t ) , r_t=r_\varphi(q,o_{\leq t})-\beta\log\frac{\pi_\theta(o_t|q,o_{<t})}{\pi_{ref}(o_t|q,o_{<t})}, rt=rφ(q,o≤t)−βlogπref(ot∣q,o<t)πθ(ot∣q,o<t), 其中 r ϕ r_\phi rϕ 是奖励模型, π r e f \pi_{ref} πref 是参考模型(通常是初始的 SFT 模型)。为什么要在reward里面减去正则项?我们在上一个博客里面写到我们的最优目标其实就是reward减去正则项(原因见上一篇博客)
而GRPO的loss为
J G R P O ( θ ) = E [ q ∼ P ( Q ) , { o i } i = 1 G ∼ π θ o l d ( O ∣ q ) ] 1 G ∑ i = 1 G 1 ∣ o i ∣ ∑ t = 1 ∣ o i ∣ { min [ π θ ( o i , t ∣ q , o i , t ) π θ o l d ( o i , t ∣ q , o i , t ) A ^ i , t clip ( π θ ( o i , t ∣ q , o i , < t ) π θ o l d ( o i , t ∣ q , o i , < t ) , 1 − ε , 1 + ε ) A ^ i , t ] − β D K L [ π θ ∣ ∣ π r e f ] } , , \begin{aligned}\mathcal{J}_{GRPO}(\theta)&=\mathbb{E}[q\sim P(Q),\textcolor{red}{\{o_{i}\}_{i=1}^{G}}\sim\pi_{\theta_{old}}(O|q)]\textcolor{red}{\frac{1}{G}\sum_{i=1}^{G}}\frac{1}{|o_{i}|}\sum_{t=1}^{|o_{i}|}\left\{\min\left[\frac{\pi_{\theta}(o_{i,t}|q,o_{i,t})}{\pi_{\theta_{old}}(o_{i,t}|q,o_{i,t})}\textcolor{red}{\hat{A}_{i,t}}\operatorname{clip}\left(\frac{\pi_{\theta}(o_{i,t}|q,o_{i,<t})}{\pi_{\theta_{old}}(o_{i,t}|q,o_{i,<t})},1-\varepsilon,1+\varepsilon\right)\textcolor{red}{\hat{A}_{i,t}}\right]\textcolor{red}{-\beta\mathbb{D}_{KL}\left[\pi_{\theta}||\pi_{ref}\right]}\right\},\end{aligned}, JGRPO(θ)=E[q∼P(Q),{oi}i=1G∼πθold(O∣q)]G1i=1∑G∣oi∣1t=1∑∣oi∣{min[πθold(oi,t∣q,oi,t)πθ(oi,t∣q,oi,t)A^i,tclip(πθold(oi,t∣q,oi,<t)πθ(oi,t∣q,oi,<t),1−ε,1+ε)A^i,t]−βDKL[πθ∣∣πref]},,
红色项为相较PPO更改的项。
- 更改的优势函数为: A ^ i , t = r ~ i = R i − m e a n ( r ) s t d ( r ) \hat{A}_{i,t}=\widetilde{r}_{i}=\frac{R_{i}-\mathrm{mean}(\mathbf{r})}{\mathrm{std}(\mathbf{r})} A^i,t=r i=std(r)Ri−mean(r),用组内的相对优势代替了全局的相对优势
- 最后一项正则项:GRPO不像PPO一样在奖励中添加 KL 惩罚,而是通过将 KL 散度直接添加到训练策略和参考策略之间的策略损失(policy loss)中来进行正则化。
大统一框架
Deepseek这篇文章里面还干了一件比较有趣的事情:
We provide a unified paradigm to understand different methods, such as RFT, DPO, PPO, and GRPO.
他们用一个公式去统一理解RFT, DPO, PPO, and GRPO:
∇ θ J A ( θ ) = E ( q , o ) ∼ D ⏟ Data Source ( 1 ∣ o ∣ ∑ t = 1 ∣ o ∣ G C A ( q , o , t , r ϕ ) ⏟ Gradient Coefficient ∇ θ log π θ ( o t ∣ q , o < t ) ) . \nabla_\theta \mathcal{J}\textcolor{red}{_{\mathcal{A}(\theta)}}= \mathbb{E}_{\underbrace{(q, o) \sim \textcolor{red}{\mathcal{D}}}_{\text{Data Source}}} \left( \frac{1}{|o|} \sum_{t=1}^{|o|} \underbrace{GC_\mathcal{A}(q, o, t, r_\phi)}_{\text{Gradient Coefficient}} \nabla_\theta \log \pi_\theta(o_t | q, o_{<t}) \right). ∇θJA(θ)=EData Source (q,o)∼D ∣o∣1t=1∑∣o∣Gradient Coefficient GCA(q,o,t,rϕ)∇θlogπθ(ot∣q,o<t) .
- 数据源 D \mathcal{D} D
- 奖励函数 r ϕ r_\phi rϕ
- 算法 A \mathcal{A} A:它处理训练数据和奖励信号,以得到梯度系数 G C GC GC, G C GC GC 决定了对数据进行惩罚或强化的幅度。
- SFT: 在人类选择的 SFT 数据上对预训练模型进行微调。
- DPO: DPO 使用成对(pair-wise)的 DPO 损失,微调sft。
- PPO/GRPO: 使用从实时策略模型中采样的输出,微调sft。
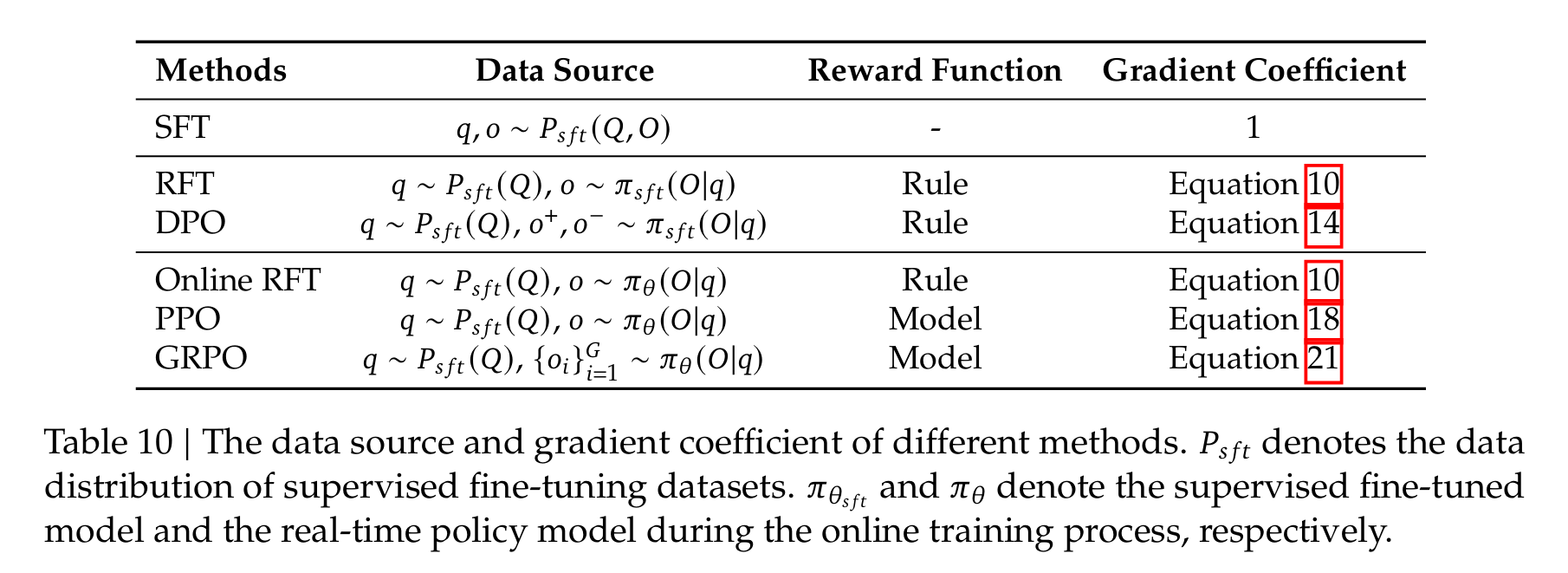
具体公式可以详见论文。
题外话:区别LLM和RL里面的R
在经典强化学习中,优势函数定义为 A = G − V A = G - V A=G−V,其中 G G G 表示从当前状态出发的累计回报(return)。
但在 LLM 的 RLHF 场景中情况不同:每次生成完整回复本质上就是一条完整的 trajectory,而 RLHF 并没有逐步的环境奖励。因此没有传统 RL 的 step-wise reward 结构,只有最后由 reward model 给出的一个评分 R R R,这个评分对应整条生成序列的质量。
换句话说,reward model 给出的 R ( prompt , response ) R(\text{prompt}, \text{response}) R(prompt,response)实际上就是对整个 trajectory 的回报评估,等价于传统 RL 中的累计回报 G G G。
因此:
- 传统 RL 中的 R ( s , a ) R(s,a) R(s,a)是“当前状态下执行动作得到的即时奖励”;
- LLM RLHF 中的 R ( prompt , response ) R(\text{prompt}, \text{response}) R(prompt,response) 则是“对整条轨迹的综合打分”,其角色与传统 RL 中的 (G) 更加对应。
题外话:GRPO可以用在传统RL上吗?
Q:GRPO 的核心就是把 Advantage 的 baseline V 换成组内 baseline,那从 baseline 的角度来看,它能不能迁移到传统 RL?
A:?
如果把GRPO的思想引入RL中,就相当于:在同一个 state A 反复 reset,然后从 A 开始 roll out K 条 trajectory,然后算它们 G 的组内平均,再计算advantage。
这里有一篇文章讲传统RL使用GRPO:Learning Without Critics? Revisiting GRPO in Classical Reinforcement Learning Environments
题外话:GRPO的无偏性
我们之前要求baseline b ( s ) b(s) b(s)不依赖于 a a a,这样才能保证不改变期望梯度(unbiased gradient),才能保证无偏性。如果使用GRPO的思想:
“组内平均 return baseline”是:
G ˉ = 1 K ∑ i = 1 K G i \bar{G} = \frac{1}{K} \sum_{i=1}^K G_i Gˉ=K1i=1∑KGi
注意:
每个 G i G_i Gi 都是由某个动作序列 a 1 , a 2 , … a T \mathbf{a}^1, \mathbf{a}^2, \dots \mathbf{a}^T a1,a2,…aT 产生的 return。因此 baseline 依赖于动作(a),而不是只依赖 state。所以破坏了无偏性。如果硬要说可以,就是平均这件事抹去了动作action的价值,这要求有很多回答平均才能近似吧?有理论可以推导出偏差吗?
如果有小伙伴有一些想法的话欢迎在评论区留言。
GRPO的后续改进
可以参考:PPO,GRPO,GSPO的演变–从方差,偏差,router和clip几个视角谈论其演进 - 东川路第一伊蕾娜的文章 - 知乎
总结
我们要明确的一点是GRPO是专门为LLM环境改造过的 PPO,不符合大多数 传统 RL 环境的结构,所以本章节讲的还是属于RL领域的算法改进。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 10
10 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)