24.模型量化实践
摘要:本文介绍了bitsandbytes模块的量化原理及其在大模型部署中的应用。该工具通过INT8/INT4量化技术显著减少显存占用(INT8为FP32的25%,INT4为12.5%),同时利用GPU的TensorCore加速推理。实验表明,Qwen1.5-14B-Chat模型在INT8和INT4量化后仍保持流畅对话和代码生成能力,而预训练模型Qwen2.5-32B量化后不具备对话能力。使用vLL
1. 量化背景介绍
bitsandbytes 模块量化模型的原理
bitsandbytes 是一个高效的 GPU 加速库,专注于减少深度学习模型的显存占用并提升推理性能,尤其适用于大规模模型的量化。其核心功能是通过低位量化(如 INT8 和 INT4)替代原始的 16 位浮点(FP16)或 32 位浮点(FP32)表示,达到显存和计算效率的优化。
1.1 量化的核心思想
量化的目标是将模型权重从高精度(FP32 或 FP16)转换为低精度整数(如 INT8 或 INT4),从而:
- 减少内存占用:低精度表示需要的存储空间更小。
- 提升计算效率:许多现代 GPU 支持低精度计算加速(如 Tensor Cores 支持 INT8 和 FP16)。
- 保持模型精度:通过精心设计的量化方法,最大限度减少精度损失。
1.2 bitsandbytes 支持的量化模式
- 动态量化(INT8)
- 动态量化是在推理过程中对权重进行量化,只对线性层的权重(
Linear层的权重矩阵)进行 INT8 表示,而不改变激活值。 - 动态量化的过程:
- 将权重矩阵分块。
- 对每个块计算比例因子(scale)和偏移量(zero-point),用于映射 FP16 或 FP32 到 INT8。
- 在推理时恢复到近似的浮点值进行计算。
- 优势:减少显存占用,同时保留较高的计算精度。
- 动态量化是在推理过程中对权重进行量化,只对线性层的权重(
- 静态量化(INT8 和 INT4)
- 静态量化是对权重进行离线量化,即在训练或模型加载时完成量化并保存权重。
bitsandbytes支持 INT4 格式,使用更低的精度进一步压缩模型大小。- 静态量化过程类似动态量化,但在量化后,权重会以低精度整数形式存储。
- 混合量化(4-bit NF4 格式)
bitsandbytes提供了NF4(Normalized Float 4)格式,是一种专门设计的 4-bit 数值表示,用于权重矩阵的量化。- 优势:相比普通的 INT4,
NF4格式更好地表示了原始浮点分布,减少量化误差。
1.3 bitsandbytes 的工作原理
- 块量化(Block-wise Quantization)
块量化是 bitsandbytes 的核心技术,用于将权重矩阵分块后逐块进行量化。
- 分块处理
- 将大矩阵分为较小的子矩阵(如 64x64 或 32x32 块)。
- 每个块单独计算缩放因子(scale)和零点(zero-point)。
-
块级量化公式 对于每个块内的值:
其中:
FP是浮点权重值。scale是块的缩放因子,用于保持动态范围。min(FP)是块内的最小值。- 优点
- 分块方法能够更好地捕捉矩阵中局部数据的动态范围,从而减少量化误差。
-
自定义数据类型支持
bitsandbytes 实现了对低精度数据类型(如 INT8 和 INT4)的支持,并使用 CUDA 加速这些数据类型的运算。具体方法:
- 引入
CUDA Kernels处理低精度矩阵乘法。 -
优化低精度计算与高精度激活值的混合运算。
-
CUDA 支持的高效推理
量化后,bitsandbytes 利用 NVIDIA GPU 的 Tensor Cores 执行 INT8 和 INT4 运算,大幅加速矩阵乘法等关键操作。
1.4 量化的优点与局限
- 优点
- 显存优化
- INT8 权重占用内存大约为 FP32 的 25%,显著减少显存使用。
- INT4 权重进一步减少到 FP32 的 12.5%。
- 推理加速
- 在支持低精度计算的 GPU(如 NVIDIA Ampere 或更高架构)上,可以利用 Tensor Cores 显著提升推理速度。
- 灵活性
- 支持动态量化和静态量化,适应不同的部署需求。
- 局限
- 精度损失
- 低精度表示可能引入量化误差,对精度敏感的任务(如生成任务)可能有一定影响。
- 硬件依赖
- 需要支持低精度计算(如 INT8/INT4)的 GPU,老旧设备可能不兼容。
- 计算开销
- 在计算过程中需要频繁的量化和反量化操作,可能引入一些额外的延迟。
- 总结
bitsandbytes 的核心在于块量化技术(block-wise quantization)和高效的 CUDA 实现。它通过将大规模语言模型的权重转换为低精度(如 INT8 和 INT4)表示,显著降低显存占用,同时在现代 GPU 上保持较高的推理效率。
这使得 bitsandbytes 成为大模型(如 Qwen、Bloom、LLaMA)量化和部署的首选工具之一,特别是在资源受限的环境中。
1.5 量化脚本
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
import bitsandbytes as bnb
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "1"
# 模型名称
model_name = "/data3/model_hub/Qwen1.5-14B-Chat" # 替换为实际的模型路径或名称
output_dir = "/data3/model_hub/Qwen1.5-14B-int8-Chat"
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
bnb_config = BitsAndBytesConfig(
load_in_8bit=True,
# bnb_8bit_compute_dtype="float16",
# bnb_8bit_use_double_quant=True,
# bnb_8bit_quant_type="nf4",
)
model = AutoModelForCausalLM.from_pretrained(
model_name,
quantization_config=bnb_config,
device_map="auto",
)
# 保存量化后的权重
print(f"Saving quantized model to {output_dir}...")
model.save_pretrained(output_dir)
tokenizer.save_pretrained(output_dir)
print("Quantized model saved.")
2. Qwen2.5-32B量化实验
原始模型权重为Qwen2.5-32B
- 分别完成 int8 和 int4 的量化
- 简单测试量化效果,如果量化效果基本满足,再完成模型任务评测
2.1 实验模型及环境介绍
- 环境GPU H100
- Python 3.11.5
- 部署框架 vLLM 0.6.6.post1
- 量化工具 bitsandbytes
- 模型路径为:/data3/model_hub/Qwen2.5-32B
2.2 部署原始模型及测试
python -m vllm.entrypoints.openai.api_server \
--model /data3/model_hub/Qwen2.5-32B \
--served-model-name Qwen2.5-32B \
--trust-remote-code \
--tensor-parallel-size 2 \
--gpu-memory-utilization 0.9 \
--port 19971
 原始模型没有对话能力
原始模型没有对话能力
2.3 量化int8模型部署及测试
- bitsandbytes 量化以后需要指定load-format的格式为bitsandbytes
- 需要选择quantization参数为bitsandbytes
- 只支持tensor-parallel-size=1
python -m vllm.entrypoints.openai.api_server \
--model /data3/model_hub/qwen2.5-32b-int8 \
--served-model-name Qwen2.5-32B-int8 \
--trust-remote-code \
--tensor-parallel-size 1 \
--gpu-memory-utilization 0.9 \
--port 19971 \
--quantization bitsandbytes \
--load-format bitsandbytes

 结论:简单测试发现几乎没有对话能力。
结论:简单测试发现几乎没有对话能力。
2.4 结论
原始的Qwen2.5-32B模型和 int8 量化以后的模型都不具有基本的对话能力,这是因为base 模型只做了模型的预训练,没有做对话数据的训练,不具有对话能力
3. Qwen1.5-14B-Chat 模型量化实验
3.1 原始模型部署及测试
python -m vllm.entrypoints.openai.api_server \
--model /data3/model_hub/Qwen1.5-14B-Chat \
--served-model-name Qwen1.5-14B-Chat \
--trust-remote-code \
--tensor-parallel-size 2 \
--gpu-memory-utilization 0.9 \
--port 19971

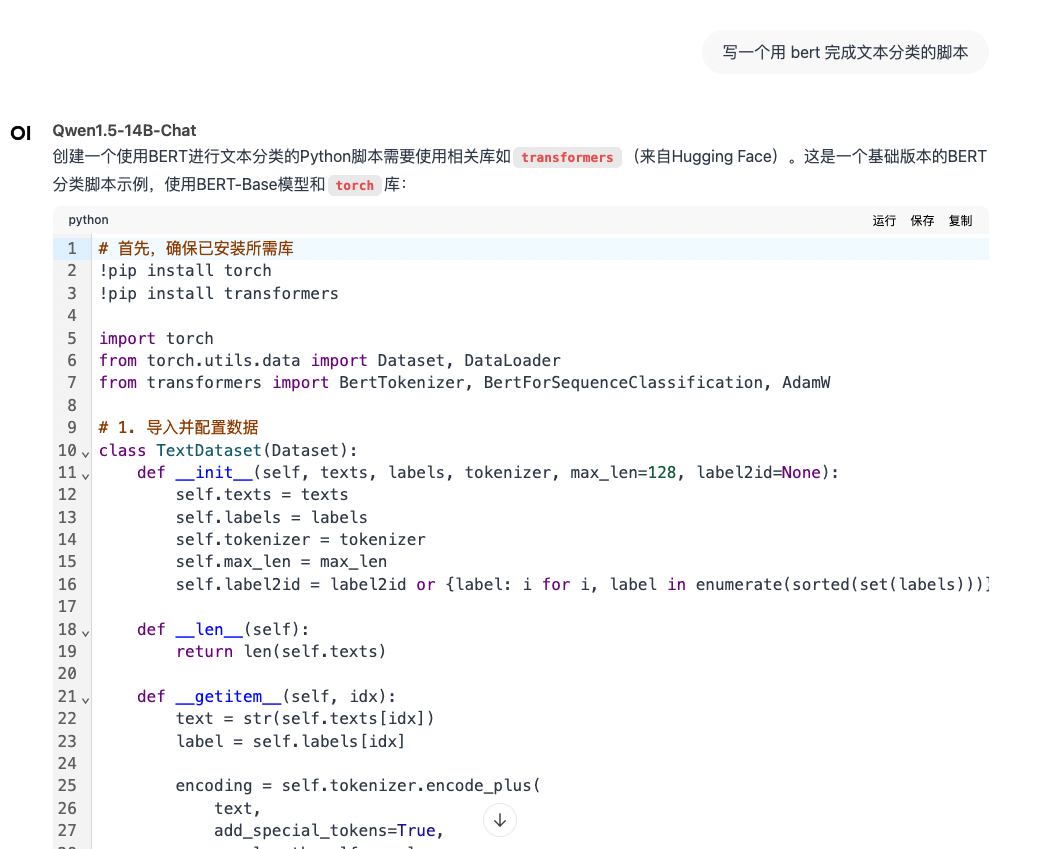 结论:有流畅的对话能力,并且能完成脚本的编写。
结论:有流畅的对话能力,并且能完成脚本的编写。
3.2 量化int8模型部署及测试
python -m vllm.entrypoints.openai.api_server \
--model /data3/model_hub/Qwen1.5-14B-int8-Chat \
--served-model-name Qwen1.5-14B-int8-Chat \
--trust-remote-code \
--tensor-parallel-size 1 \
--gpu-memory-utilization 0.9 \
--port 19971 \
--quantization bitsandbytes \
--load-format bitsandbytes
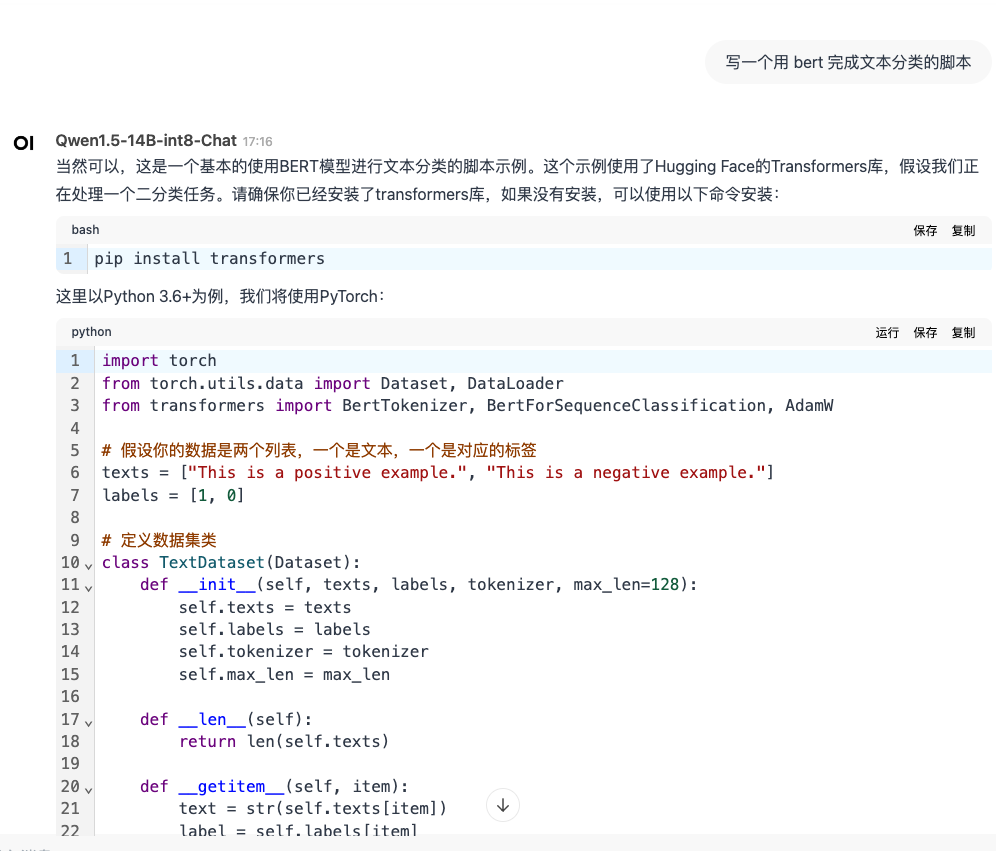
 结论:量化以后任然保持流程的对话能力,以及代码生成的能力,简单测试发现模型量化基本没有问题。
结论:量化以后任然保持流程的对话能力,以及代码生成的能力,简单测试发现模型量化基本没有问题。
3.3 量化 int4模型部署及测试
量化脚本
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
import bitsandbytes as bnb
import os
import torch
os.environ["CUDA_VISIBLE_DEVICES"] = "1"
# 模型名称
model_name = "/data3/model_hub/Qwen1.5-14B-Chat" # 替换为实际的模型路径或名称
output_dir = "/data3/model_hub/Qwen1.5-14B-int4-Chat"
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype="float16",
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
)
model = AutoModelForCausalLM.from_pretrained(
model_name,
quantization_config=bnb_config,
device_map="auto",
)
print(f"memory usage: {torch.cuda.memory_allocated()/1000/1000/1000} GB")
# 保存量化后的权重
print(f"Saving quantized model to {output_dir}...")
model.save_pretrained(output_dir)
tokenizer.save_pretrained(output_dir)
print("Quantized model saved.")
python -m vllm.entrypoints.openai.api_server \
--model /data3/model_hub/Qwen1.5-14B-int4-Chat \
--served-model-name Qwen1.5-14B-int4-Chat \
--trust-remote-code \
--tensor-parallel-size 1 \
--gpu-memory-utilization 0.9 \
--port 19971 \
--quantization bitsandbytes \
--load-format bitsandbytes
# model weights take 9.03GiB; non_torch_memory takes 1.55GiB;
# PyTorch activation peak memory takes 5.07GiB;
# the rest of the memory reserved for KV Cache is 55.54GiB.
 结论:量化 int4 有足够流畅的对话能力,有编程能力。推理性能显著提升。
结论:量化 int4 有足够流畅的对话能力,有编程能力。推理性能显著提升。
3.4 结论
对于有 chat 能力的模型进行量化,通过 int8 和 int4 的量化,初步发现模型都具有流畅的对话能力。
量化模型效果和性能评测,评测工具使用 lm-eval 或者 LLMBox 工具,评测数据选择中文的 ceval,cmmlu,英文数据选择xxx。推理性能评测使用 llmperf 工具。
4. 总结
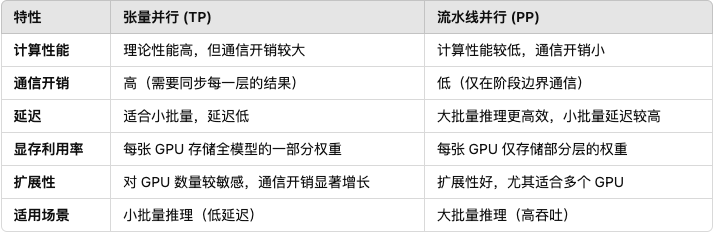
使用bitsandbytes模块量化模型,vLLM 部署的时候需要指定模型量化参数、格式等信息,并且不支持张量并行的部署方式,为了实现多卡部署,只能采用流水线并行的方式实现多卡。这两种方式有各自的使用场景

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 37
37 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)