某个网站的爬虫——fiddler everywhere与mitmproxy的简单使用
就这样,简单地使用一个mitmproxy和fiddler everywhere这两个工具t=P9T8t=P9T8t=P9T8恶心人的sojson_v7http://120.53.92.179/sojson/cp3/index.htmlFiddler Everywhere安装及使用教程_fiddler everywhere使用教程-CSDN博客https://blog.csdn.net/weixin
前言
笔者知道mitmproxy可以修改请求和响应,
那么fiddler everywhere应该也可以,但以前笔者从来没有这么干过,
没有使用fiddler everywhere来修改请求和响应,笔者决定来尝试一下,
为什么是fiddler everywhere不是fiddler,因为笔者觉得更好看,哈哈哈哈哈哈哈。
目标网站
恶心人的sojson_v7![]() http://120.53.92.179/sojson/cp3/index.html
http://120.53.92.179/sojson/cp3/index.html
正文
解决debugger
很多东西不必细说,安装并打开fiddler everywhere。
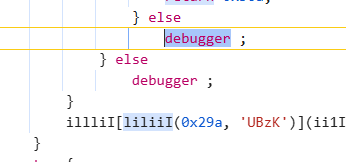
发现有debugger,发现是sojson_view.js这个文件中
找到这个文件,右键,选择选项Add new Rule
当然,也可以现在自己主动添加,没什么区别
选择之后,进入如下页面
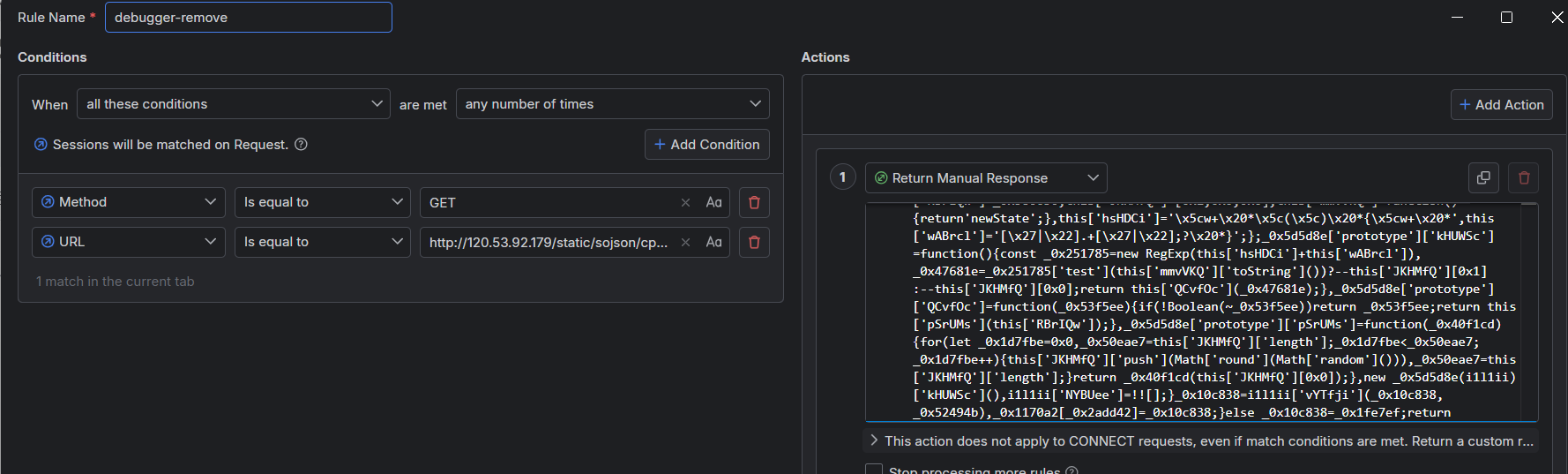 笔者修改Rule name——debugger-remove,名字不重要
笔者修改Rule name——debugger-remove,名字不重要
现在需要找到debugger这个关键字,
笔者已经犯过错了,如果把代码格式化就会阻塞
逆向爬虫27 sojson反调加密-CSDN博客![]() https://blog.csdn.net/weixin_40743639/article/details/123861625因为sojson不准格式化,笔者还不知道。
https://blog.csdn.net/weixin_40743639/article/details/123861625因为sojson不准格式化,笔者还不知道。
总之,不进行格式化,直接找到debugger这个关键字就可以了
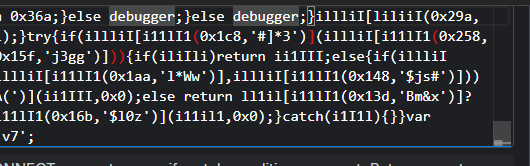
拖到最下面,可以发现,直接修改一下
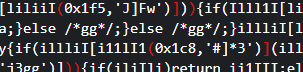
直接把debugger变成gg,然后保存
就会出现一个Rule,如下

刷新,打开F12,就没有了
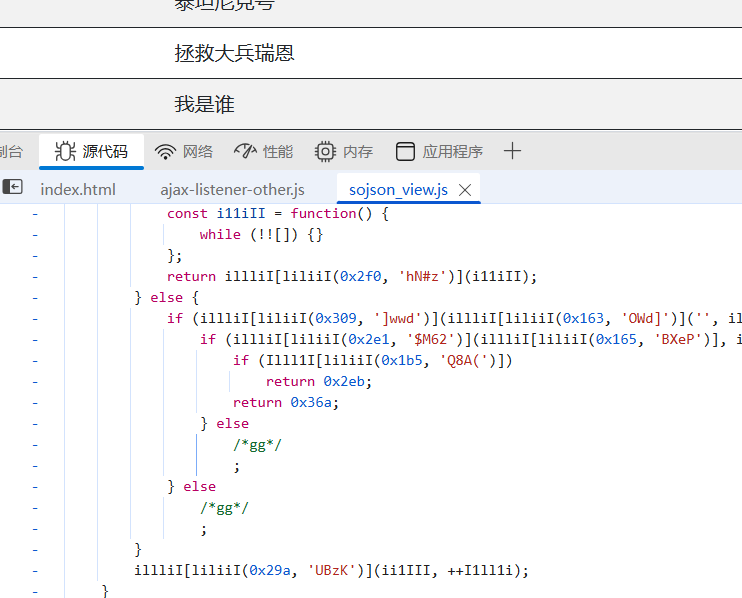
解决页面问题
笔者发现第四页和第5页是点不到的,查看源代码看看
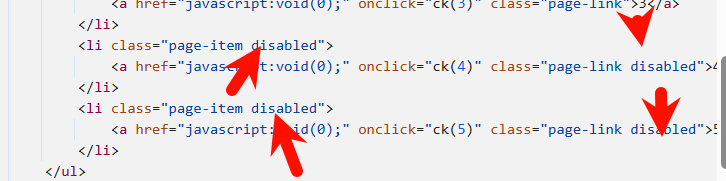
可以发现有几个disabled的,那么直接去掉,添加一个Rule
在Actions里面直接去掉disabled
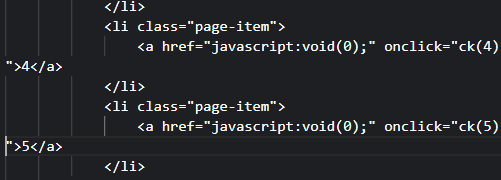
保存,刷新页面,结果如下
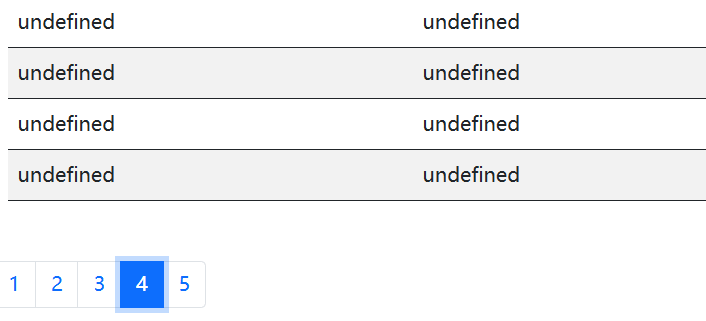
可以发现是点击成功了的,结果undefined是另外的事情
获取第四页和第五页的数据

从提示可以知道,需要把User-Agent改成apecome.com
这就很简单了。
首先,确定请求如下

右键添加一条Rule
因为只需要匹配第四页和第五页,笔者使用正则表达式的方式修改请求
即,如下
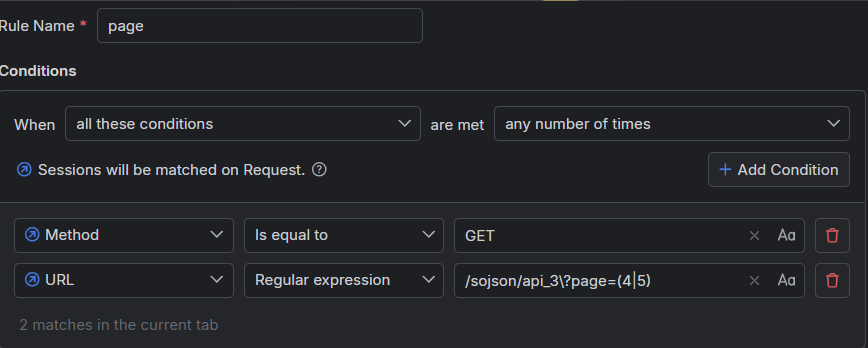
问号前面需要反斜杆。表示是一个普通的问号字符
添加新的Action,选择Unpdate Request Header,结果如下
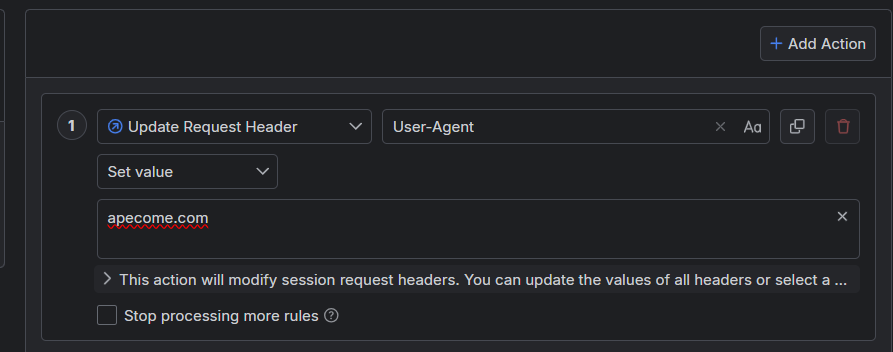
保存,刷新页面,选择第五页,结果如下
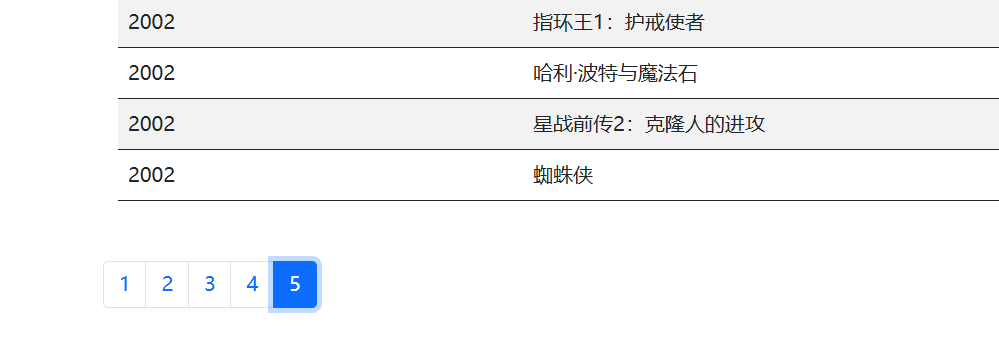
没问题。至于sojson这个解混淆,笔者就算了,不想搞。
使用mitmproxy
类似的,笔者直接给出代码
mitmweb --mode reverse:http://120.53.92.179/ -p 8082 --ssl-insecure -s proxy.py
新建一个proxy.py文件,其中的内容如下
import re
from mitmproxy import http
# 配置需要特殊处理的页面
SPECIAL_PAGES = {'4', '5'}
def request(flow: http.HTTPFlow) -> None:
"""
拦截 /sojson/api_3 请求:
- 将 page=1-5 的请求转发到后端服务器
- 对 page=4,5 设置特殊 User-Agent
"""
# 只处理目标路径
if not flow.request.path.startswith('/sojson/api_3'):
return
# 获取 page 参数
page = flow.request.query.get('page')
# 只处理 page=1-5
if page not in {'1', '2', '3', '4', '5'}:
return
print(f'[→] 拦截请求: {flow.request.path}')
# 修改 URL (使用 f-string 动态构建)
flow.request.url = f'http://120.53.92.179:12345{flow.request.path}'
# 为特定页面设置 User-Agent
if page in SPECIAL_PAGES:
flow.request.headers['User-Agent'] = 'apecome.com'
print(f' 设置 User-Agent: apecome.com')
print(f' 转发到: {flow.request.url}')
def response(flow: http.HTTPFlow):
path=flow.request.path
if path=='/static/sojson/cp3/sojson_view.js':
content_bytes = flow.response.content
# 在字节层面替换
content_bytes = content_bytes.replace(
b'debugger;', # 字节模式
b'/*gg*/;'
)
flow.response.content = content_bytes
if flow.request.path == '/sojson/cp3/index.html':
print('[✓] 拦截 index.html')
# 获取 HTML 内容
html = flow.response.text
# 精确替换 disabled 类(两行搞定)
html = html.replace('class="page-link disabled"', 'class="page-link"')
html = html.replace('class="page-item disabled"', 'class="page-item"')
# 写回修改后的 HTML
flow.response.text = html
print('[✓] 已启用第4、5页链接')笔者发现除了会对80端口发送请求,还会对12345端口发送请求,所以笔者在电脑上设置代理
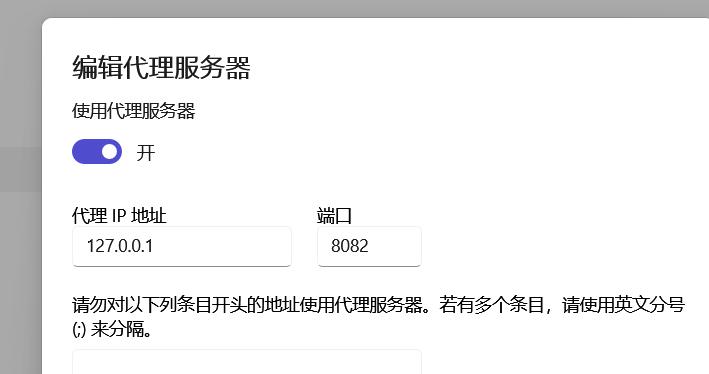
才能获取数据,获取解决12345端口,
笔者搜索发现,这个12345端口是在jquery
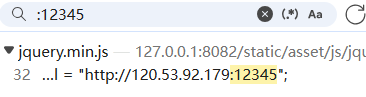
因此,直接替换掉
if path=='/static/asset/js/jquery.min.js':
flow.response.text = flow.response.text.replace(
'http://120.53.92.179:12345',
'http://127.0.0.1:8082'
)都行。
总结
就这样,简单地使用一个mitmproxy和fiddler everywhere这两个工具

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 15
15 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)