AI 十大论文精讲(七):Switch Routing 如何破解 MoE 的路由、通信与稳定性三大痛点
《检索增强生成(RAG)在知识密集型NLP任务中的应用》是一篇探讨如何解决大语言模型知识局限性的重要论文。文章指出传统密集模型面临参数规模与计算成本线性绑定的瓶颈,而检索增强生成创新性地提出了"稀疏激活"思路,通过简化路由机制(Switch Routing)实现参数规模与计算成本的解耦。论文详细阐述了三大关键技术:选择性精度训练、初始化缩放与专家正则化、三重并行架构,成功实现了
系列文章前言
在人工智能技术从理论突破走向工程落地的进程中,一篇篇里程碑式的论文如同灯塔,照亮了技术演进的关键路径。为帮助大家吃透 AI 核心技术的底层逻辑、理清行业发展脉络,博主推出「AI 十大核心论文解读系列」,每篇聚焦一篇关键论文的问题背景、核心创新与行业影响。本篇博客解读AI领域十大论文的第五篇——《Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks》(检索增强生成:面向知识密集型NLP任务的解决方案)。
一、引言:密集型模型的瓶颈与稀疏化的破局思路
在大语言模型的发展历程中,“规模即能力”已被多次验证,但传统密集型Transformer架构面临核心瓶颈:模型参数与计算成本(FLOPs)呈线性绑定,每增加一个参数,所有输入token的前向传播都需调用该参数,导致训练万亿参数模型时,计算资源消耗呈指数级增长。混合专家(Mixture of Experts, MoE)模型虽提出“稀疏激活”思路——为每个输入选择部分子网络(专家)运行,实现参数规模与计算成本解耦,但此前的MoE存在三大问题:路由算法复杂(top-k选择需协调多个专家)、跨设备通信成本高、训练过程极易不稳定,限制了其大规模应用。
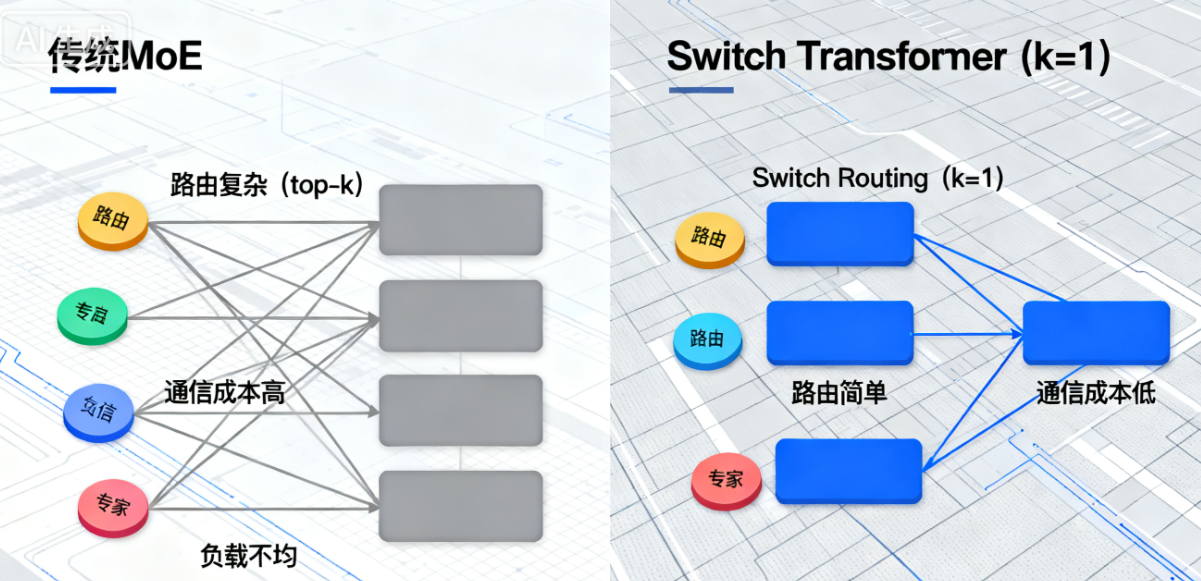
Switch Transformers的核心目标正是解决这些痛点:通过简化MoE的路由机制、优化训练策略、设计高效并行架构,在保持“参数规模大”的同时,让“单token计算成本低”,最终实现万亿参数模型的稳定训练,且预训练速度、下游任务性能均超越同计算预算的密集型模型。
用简单的话来说,早期的MoE模型就像“组建了一个专家团队”——每个专家只擅长一个领域,遇到问题时找几个最相关的专家一起解决,但麻烦的是:怎么选专家(路由)要纠结半天,专家之间沟通成本高(跨设备通信),还经常出现有的专家忙到崩溃、有的闲到摸鱼(训练不稳定)的情况,团队协作效率极低。
而Switch Transformers的思路的是:“优化专家团队的工作模式”——给团队配一个高效“调度员”,每个问题只找一个最擅长的专家解决,不用多个专家协调;同时优化团队分工(并行架构)和工作规则(训练策略),让专家团队既能“人多势众”(万亿参数),又能“高效干活”(单token计算快),花更少的钱办更大的事。
二、论文深度解读
1. 核心创新:Switch Routing——让稀疏化更简单、更高效
Switch Transformer的核心突破是Switch Routing,它对传统MoE的top-k路由进行了颠覆性简化:将“每个token路由到top-k个专家”改为“每个token仅路由到1个专家(k=1)”,这一改动并非妥协,而是经过实证的优化选择。
1.1 路由机制的数学表达与逻辑
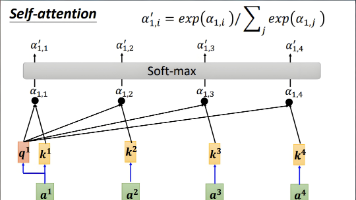
- 路由函数:对于输入token的表征x,通过路由权重Wr计算logits: h ( x ) = W r ⋅ x h(x)=Wr·x h(x)=Wr⋅x,经softmax归一化后得到每个专家的选择概率 p i ( x ) = e ( h ( x ) i ) / Σ j e ( h ( x ) j ) pi(x)=e^(h(x)i)/Σj e^(h(x)j) pi(x)=e(h(x)i)/Σje(h(x)j)
- 选择逻辑:通过argmax选择概率最高的专家,token仅由该专家处理,输出为 y = E i ( x ) ⋅ p i ( x ) y=Ei(x)·pi(x) y=Ei(x)⋅pi(x)(Ei为选中专家的网络输出,pi为路由权重);
- 三大优势:
① 路由计算量从O(k·N)降至O(N)(N为专家数),计算效率提升;
② 每个专家的批处理量至少减半(因每个token仅分配给1个专家),内存利用率更高;
③ 路由实现简化,跨设备通信仅需传递“选中专家的输出”,通信成本显著降低。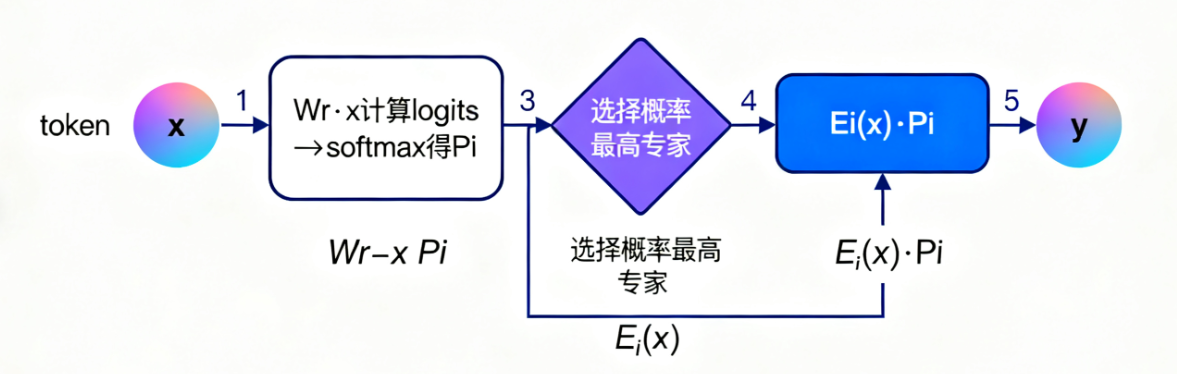
1.2 负载均衡与专家容量设计
为解决“专家负载不均”问题,论文引入两大机制:
- 辅助负载均衡损失:损失函数为 α ⋅ N ⋅ Σ f i ⋅ P i α·N·Σfi·Pi α⋅N⋅Σfi⋅Pi
(fi是分配给专家i的token占比, P i Pi Pi是路由概率分配给专家i的占比, α = 1 e − 2 α=1e-2 α=1e−2),通过梯度下降鼓励 f i fi fi和 P i Pi Pi均趋近于 1 / N 1/N 1/N(均匀分布),避免tokens集中于少数专家;就像公司的“绩效考核”——如果某个专家的任务量(fi)和调度员给的“预期工作量”(Pi)差太多,就扣调度员的分,逼着调度员把任务均匀分配; - 专家容量因子:专家容量=(每批次token数/专家数)×容量因子,容量因子>1.0(通常取1.0-1.5),为每个专家预留“备用处理能力”,避免因token分配不均导致的“专家溢出”(溢出token直接通过残差连接传递,不参与专家计算)。就像给每个专家的办公室留了“备用工位”——比如本来每个专家该处理10个token,容量因子设1.25,就预留12个工位,避免突然来了11个token导致有人没地方坐(溢出),虽然会浪费2个工位,但能保证工作不中断。

2. 关键技术:让万亿参数模型稳定训练的“三大法宝”
稀疏模型的训练天然比密集模型更复杂——路由的离散性、低精度计算的数值不稳定性、超大规模参数的并行难题,都可能导致训练崩溃。Switch Transformer通过三大优化策略,解决了这些问题:
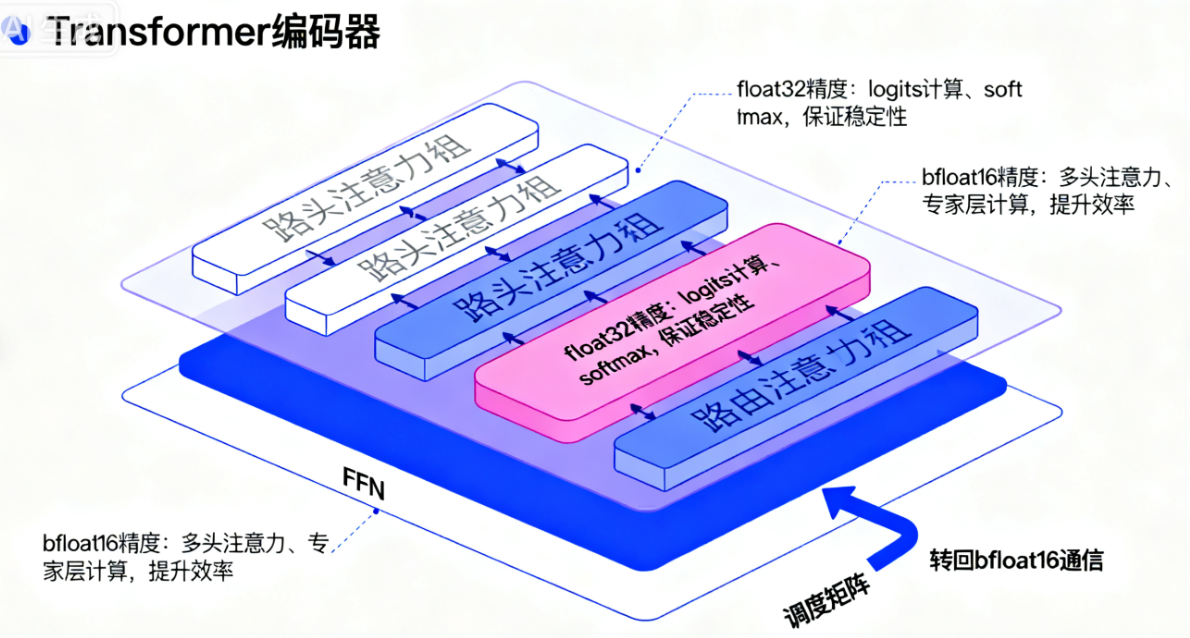
2.1 选择性精度训练(Selective Precision)
低精度格式(bfloat16)能提升计算速度、降低内存占用,但会导致路由模块的softmax计算不稳定(数值溢出或梯度消失)。论文提出“仅路由模块用float32精度,其余部分保持bfloat16”:
- 路由模块的输入、logits计算、softmax均用float32,保证数值稳定性;
- 路由输出的“调度矩阵”(dispatch tensor)和“合并矩阵”(combine tensor)再转回bfloat16,避免跨设备通信时的float32高成本;
- 实验证明:该策略既能达到bfloat16的训练速度(1390 examples/sec),又能获得float32的稳定性(负对数困惑度-1.716,与float32接近)。
2.2 初始化缩放与专家正则化
- 权重初始化:将传统Transformer的权重初始化 scale s从1.0降至0.1,权重标准差σ=√(s/n)(n为输入维度),避免训练初期因权重过大导致的梯度爆炸,实验显示该改动使训练方差从0.68降至0.01,稳定性显著提升;
- 专家dropout:微调阶段,非专家层保持dropout=0.1,专家层dropout提升至0.4,缓解稀疏模型因参数过多导致的过拟合,在GLUE、SuperGLUE等下游任务中性能提升0.5-1.0个百分点。
2.3 三重并行架构(Data + Model + Expert Parallelism)
为支撑万亿参数模型,论文设计了“数据并行+模型并行+专家并行”的混合架构:
- 数据并行:将训练数据拆分到多个设备,每个设备处理部分样本,梯度最后聚合;
- 模型并行:将Transformer的权重(如FFN层的W_in、W_out)拆分到多个设备,解决单设备内存限制;
- 专家并行:将所有专家分布在不同设备,每个设备仅存储部分专家的参数,token通过“all-to-all”通信路由到对应专家设备,实现专家数量与设备数量的线性扩展。
通过这种架构,论文成功训练出1.6万亿参数的Switch-C模型(2048个专家),且每个设备的内存占用保持在可接受范围。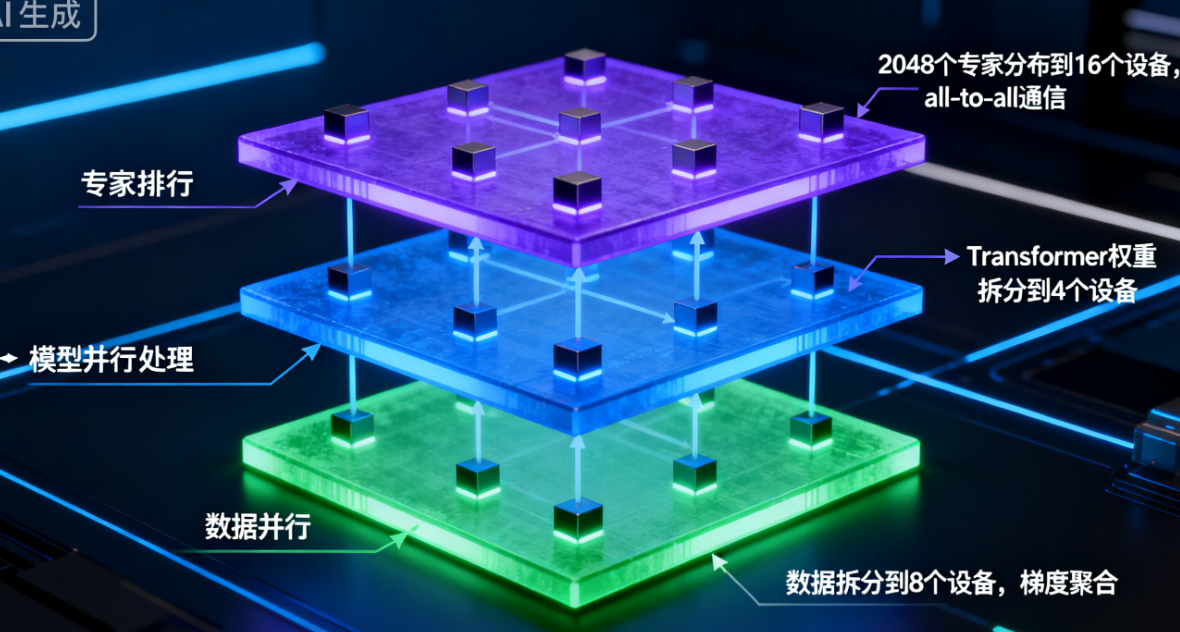
3. 实验结果:稀疏模型的“碾压式”表现
3.1 预训练速度与性能
- 同计算预算下,Switch-Base(7B参数)比T5-Base(0.2B参数)预训练速度提升7倍,在C4数据集上,Switch-Base 64专家模型达到T5-Base相同负对数困惑度(-1.50)仅需1/7的时间;
- 万亿参数模型表现:Switch-XXL(395B参数)比T5-XXL(11B参数)预训练速度提升4倍,500k步后负对数困惑度达-1.008,超越T5-XXL的-1.095;1.6万亿参数的Switch-C模型,在仅训练503B tokens(T5-XXL的一半数据)的情况下,闭卷问答任务(TriviaQA)准确率达47.5%,超越T5-XXL的42.9%。
3.2 下游任务泛化
在10+ NLP任务中,FLOP匹配的Switch模型均优于T5基线:
- SuperGLUE:Switch-Base(7B)比T5-Base(0.2B)提升4.4个百分点(79.5 vs 75.1),Switch-Large(26B)比T5-Large(0.7B)提升2.0个百分点(84.7 vs 82.7);
- 闭卷问答:Switch-Large在TriviaQA上准确率达36.9%,比T5-Large的29.5%提升7.4个百分点;
- 摘要任务:XSum数据集上,Switch-Large的Rouge-2分数达22.3,超越T5-Large的20.9。
3.3 多语言能力
在mC4的101种语言上,mSwitch-Base(FLOP匹配mT5-Base)在所有语言上均实现性能提升,91%的语言预训练速度提升4倍以上,平均速度提升5倍,证明稀疏模型的泛化能力不仅限于单语言,还能迁移到多语言场景。
3.4 模型蒸馏:让大模型的“能力”浓缩到小模型
稀疏模型虽性能强,但部署成本高(需支持动态路由)。论文通过蒸馏将大稀疏模型的知识迁移到小密集模型:
- 将14.7B参数的Switch-Base蒸馏到0.223B参数的T5-Base,保留30%的性能增益,压缩率达99%;
- 微调后的稀疏模型蒸馏:将7.4B参数的Switch-Base(SuperGLUE分数81.3)蒸馏到0.223B的T5-Base,分数达76.6,保留30%的增益,部署成本大幅降低。
4. 工程挑战与行业后续选择
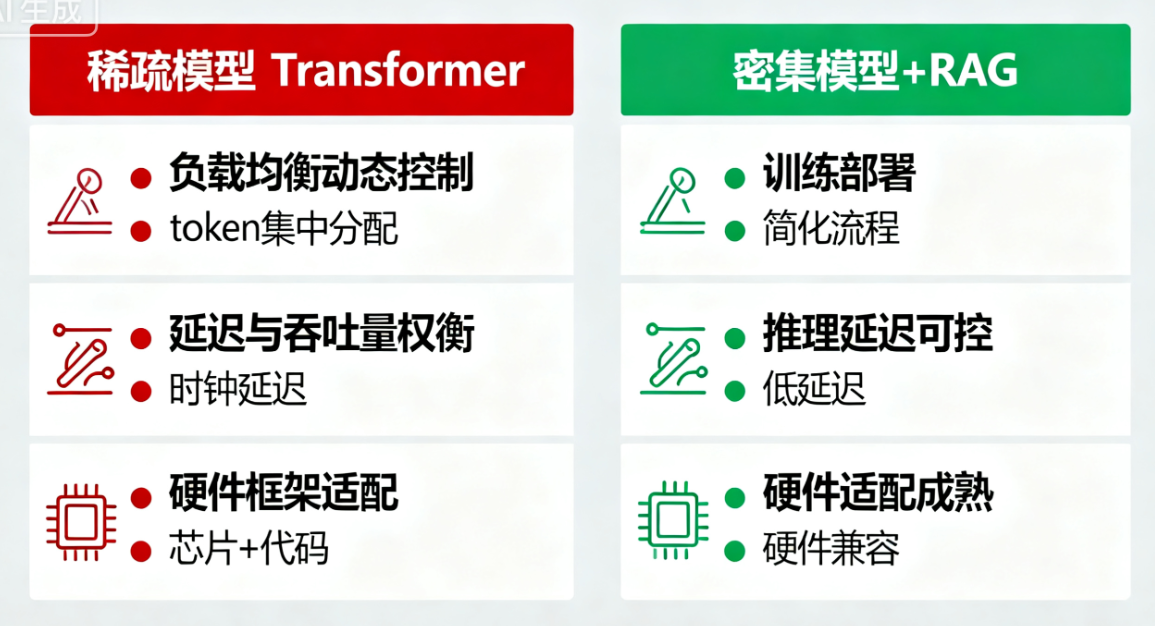
Switch Transformer虽证明了稀疏化的巨大潜力,但后续工业界部署中发现,稀疏模型面临三大工程挑战:
- 负载均衡的动态控制:实际推理时,输入分布可能与预训练分布差异较大,导致路由模块的负载均衡策略失效,部分专家成为性能瓶颈(token集中分配);
- 延迟与吞吐量权衡:动态路由需要实时计算专家分配,跨设备通信的延迟会随专家数量增加而上升,在低延迟场景(如实时对话)中难以满足要求;
- 硬件与框架适配:稀疏激活的计算模式与传统密集型计算的硬件(GPU/TPU)优化方向不一致,现有框架对“动态调度+三重并行”的支持不够成熟,需定制化开发。
这些挑战导致工业界逐渐转向“中等规模密集模型+高效检索+优质工具链”的组合:
- 中等规模密集模型(如10B-100B参数)的训练和部署复杂度低,数值稳定性强,推理延迟可控;
- 高效检索(如Retrieval-Augmented Generation, RAG)能弥补“参数规模不足”导致的知识缺口,通过外部知识库提供实时、准确的信息;
- 优质工具链(如模型压缩、量化、推理优化框架)能进一步降低部署成本,提升吞吐量。
这种组合虽未达到稀疏模型的极致性能,但“性能-成本-复杂度”的权衡更优,实施难度更低,成为当前工业界的主流选择。
三、总结:稀疏化革命的意义与启示
Switch Transformer的核心贡献并非“训练了万亿参数模型”,而是验证了“参数规模与计算成本解耦”的可行性——通过条件计算(仅激活部分参数),模型可以突破密集型架构的参数上限,同时保持高效的推理速度。其技术创新(简化路由、选择性精度、三重并行)为后续稀疏模型的研究奠定了基础,而其工程挑战也为工业界提供了重要启示:模型设计的核心是“权衡”——性能、成本、部署复杂度三者不可兼得,没有绝对最优的方案,只有最适合场景的选择。
尽管当前工业界更倾向于密集型+检索的组合,但Switch Transformer的价值并未过时:在超大规模预训练、知识密集型任务等场景中,稀疏模型仍具有不可替代的优势;而其提出的“专家并行”“负载均衡损失”等技术,也已被广泛应用于各类大模型的并行训练中。未来,随着硬件技术的进步(如专门为稀疏计算设计的芯片)和框架的优化,稀疏模型有望在更多场景中落地,与密集型模型形成互补。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 13
13 0
0- 0



 已为社区贡献24条内容
已为社区贡献24条内容

所有评论(0)