即插即用涨点系列 (十一):SCConv 详解!CVPR 2023 高效卷积 ,SRU 空间重建 与 CRU 通道重建 联手消除双重冗余
🔍 AI 即插即用模块"军火库"开源:SCConv详解 本文提出SCConv模块,通过空间重建(SRU)和通道重建(CRU)两阶段处理,有效消除CNN特征中的双重冗余。SRU利用GN的缩放因子γ评估特征图信息量,分离并交叉重建特征;CRU采用非对称双分支结构,低成本融合高低层特征。实验表明,SCConv可替代标准3×3卷积,在ResNet50上降低34%计算量的同时提升精度。
🔥 AI 即插即用 | 你的CV涨点模块“军火库”已开源!🔥
大家好!为了方便大家在CV科研和项目中高效涨点,我创建并维护了一个即插即用模块的GitHub代码仓库。
仓库里不仅有:
- 核心模块即插即用代码
- 论文精读总结
- 架构图深度解析
- 全文逐句翻译与应用实例
更有海量SOTA模型的创新模块汇总,致力于打造一个“AI即插即用”的百宝箱,方便大家快速实验、组合创新!
🚀 GitHub 仓库链接:https://github.com/AITricks/AITricks
觉得有帮助的话,欢迎大家 Star, Fork, PR 一键三连,共同维护!
即插即用涨点系列 (十一):SCConv 详解!CVPR 2023 高效卷积 ,SRU 空间重建 与 CRU 通道重建 联手消除双重冗余
论文原文 (Paper):https://openaccess.thecvf.com/content/CVPR2023/papers/Li_SCConv_Spatial_and_Channel_Reconstruction_Convolution_for_Feature_Redundancy_CVPR_2023_paper.pdf
官方代码 (Code):无,复现代码:见第六章
论文精读:SSConv
1. 核心思想
本文提出了一种名为SCConv(Spatial and Channel reconstruction Convolution)的高效、即插即用的卷积模块,其核心论点是标准卷积网络(CNNs)中广泛存在空间(Spatial)和通道(Channel)两个维度的特征冗余,这导致了巨大的计算浪费。为解决此问题,SCConv创新性地设计了一个两阶段串联流程:首先,**空间重建单元(SRU)**利用“分离-重建”策略来抑制空间维度上的冗余;接着,**通道重建单元(CRU)**采用“拆分-变换-融合”策略来削减通道维度上的冗余。SCConv旨在作为标准卷积的直接替代品,在显著降低模型参数量和计算复杂度(FLOPs)的同时,通过学习更具代表性的特征来提升模型性能。
2. 背景与动机
CNN在计算机视觉任务中取得了巨大成功,但这种成功严重依赖于密集的计算和存储资源。这种高昂成本的部分原因是卷积层在提取特征时产生了大量的“特征冗余”。
现有的解决方案主要分为两类:
- 模型压缩:如剪枝、量化等,但这些作为后处理步骤,其性能通常受限于原始模型,且在高压缩率下精度会大幅下降。
- 轻量化网络设计:如MobileNet(DWC+PWC)、ShuffleNet(通道混洗)、ResNeXt(分组卷积)等,这些方法主要致力于减少“通道”维度上的冗余。
- 空间冗余处理:如OctConv,它将特征分为高频和低频,在低分辨率下处理低频分量,以此来缓解“空间”维度上的冗余。
核心动机(问题):论文指出,以往的工作(如MobileNet, OctConv)要么只关注通道冗余,要么只关注空间冗余,而没有一个方法能够同时、显式地处理这两个维度上的冗余。这使得网络模型依然受困于特征冗余问题。因此,本文的核心动机是设计一个能同时(Jointly)利用空间和通道冗余的统一模块(SCConv),以更小的计算代价学习到更具表征能力的特征。
-
动机图解分析:
论文没有在开头提供一个专门的“动机图”,而是通过Figure 5的特征图可视化对比,直观地展示了“问题”(冗余)和“解决方案的效果”。
- Figure 5 (左侧 - 原始 ResNet50):这张图展示了“问题所在”。在标准ResNet50第一阶段输出的特征图中,我们可以清晰地看到许多“无效”或“高度相似”的特征图。
- 效率瓶颈:大量的特征图是“黑色”的(即低激活或无激活),或者呈现出几乎相同的简单纹理。这意味着网络花费了大量的FLOPs去计算这些几乎不含信息或信息重复的“冗余特征”。
- 表征局限:特征的多样性很低,这限制了模型后续层学习复杂模式的能力。
- Figure 5 (右侧 - 嵌入SRU的 ResNet50):这张图展示了本文解决方案(SRU模块)的效果,直观地回答了“为什么要做”。
- 冗余抑制:无效的“黑色”特征图显著减少。
- 表征增强:特征图被“丰富”(enriched)、“强化”(strengthened)和“多样化”(diversified)。原始ResNet50中模糊不清的轮廓(如狗的形态)在SRU处理后变得更加清晰和聚焦。
- 图解总结:Figure 5的左右对比,为本文的动机提供了强有力的视觉证据。它揭示了标准卷积(左)确实存在严重的空间特征冗余(效率瓶颈),并证明了本文提出的SRU模块(右)能有效解决这个问题,通过抑制冗余并重构特征,从而生成信息密度更高、表征能力更强的特征图。
- Figure 5 (左侧 - 原始 ResNet50):这张图展示了“问题所在”。在标准ResNet50第一阶段输出的特征图中,我们可以清晰地看到许多“无效”或“高度相似”的特征图。
3. 主要贡献点
-
[贡献点 1]:提出SRU(空间重建单元),一种新颖的空间冗余抑制方法。
SRU(Spatial Reconstruction Unit)使用“分离-重建”(Separate-and-Reconstruct)策略来处理空间冗余。
- 创新点:与OctConv基于频率分离不同,SRU创新地利用**群组归一化(Group Normalization, GN)**中的可学习缩放因子 γ \gamma γ 来“度量”每个特征图(Channel)的空间信息丰富度(即方差)。
- 机制:它根据这个度量将特征图“分离”为“信息丰富”和“信息贫乏”(冗余)两组。然后,它不是简单丢弃冗余组,而是通过“交叉重建”(cross reconstruct)操作(如图Figure 2所示),将两组特征进行重组,以此在抑制冗余的同时强化了有效特征的表征。
-
[贡献点 2]:提出CRU(通道重建单元),一种高效的通道冗余削减策略。
CRU(Channel Reconstruction Unit)采用“拆分-变换-融合”(Split-Transform-and-Fuse)策略来处理通道冗余。
- 创新点:它是一种非对称的双分支结构。它将通道“拆分”为两部分:
- 上分支(Rich Feature Extractor):使用GWC(分组卷积)和PWC(逐点卷积)的组合来低成本地提取高层代表性特征。
- 下分支(Supplementary):使用更廉价的PWC,并结合特征复用(将输入 X l o w X_{low} Xlow与变换后的特征拼接),以极低成本提供补充性的浅层细节。
- 机制:最后,它采用一种类SKNet的软注意力机制(SoftMax)来“融合”这两个分支的输出,使网络能够自适应地权衡高层特征和浅层细节的重要性。
- 创新点:它是一种非对称的双分支结构。它将通道“拆分”为两部分:
-
[贡献点 3]:提出SCConv,首个即插即用的空间-通道联合冗余消除模块。
本文最大的贡献是设计了SCConv,这是一个将SRU和CRU串联(Sequential)起来的统一模块,开创性地同时解决了空间和通道两个维度的冗余。
- 即插即用:SCConv被设计为一个独立的即插即用(plug-and-play)单元,可以无缝地、一对一地替换现有CNN架构(如ResNet, DenseNet等)中昂贵的标准 3 × 3 3\times3 3×3 卷积,而无需调整任何网络架构。
- SOTA效能:实验证明(Table 2, 3),在多个基准(CIFAR, ImageNet)和任务(分类, 检测)上,SCConv-Nets(如SCConv-R50)均能在大幅降低参数量和FLOPs(例如在ResNet50上降低约34%)的同时,实现比基线模型更高的准确率。
4. 方法细节
-
整体网络架构:
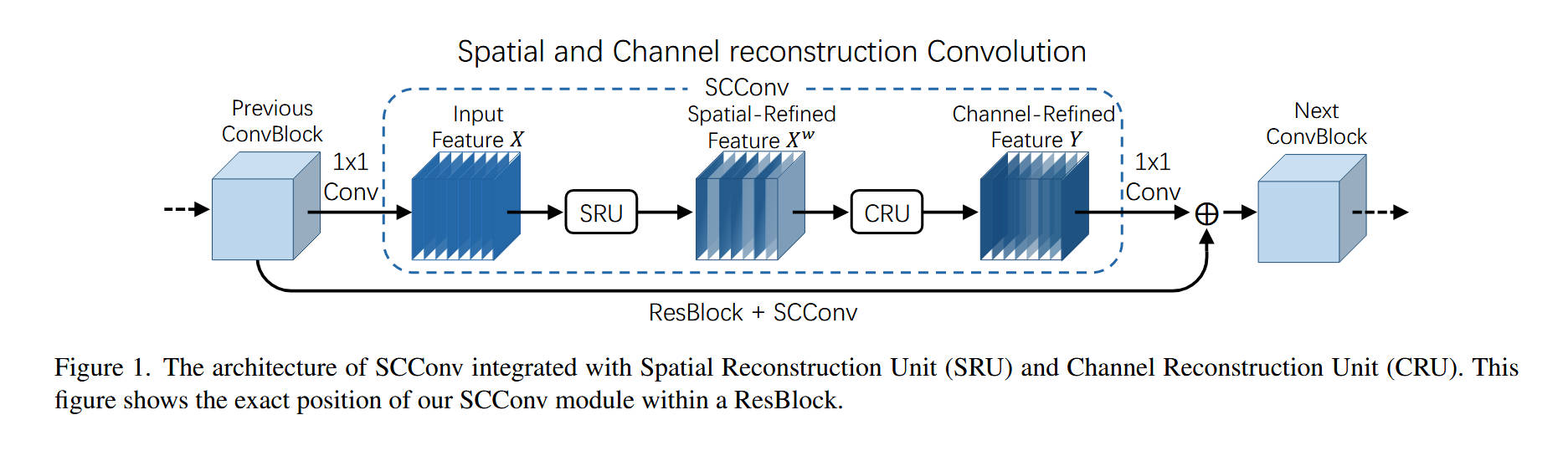
SCConv的整体架构如 Figure 1 所示,它展示了SCConv模块如何作为一个“即插即用”单元嵌入到ResNet的瓶颈块(ResBlock)中,以替代原有的 3 × 3 3\times3 3×3 标准卷积。
完整数据流如下:
- 输入 (Input):数据来自“上一个卷积块 (Previous ConvBlock)”。在ResBlock中,它首先通过一个
1x1 Conv(用于压缩通道),其输出作为Input Feature X。 - 进入 SCConv 模块:
X被送入本文的核心 SCConv 模块。 - SCConv 内部(串联两阶段):
- 阶段一 (SRU):
X首先被送入SRU(空间重建单元)。SRU对X进行处理,抑制其空间冗余,输出Spatial-Refined Feature X^w(空间精炼特征)。 - 阶段二 (CRU):
X^w紧接着被送入CRU(通道重建单元)。CRU对X^w进行处理,削减其通道冗余,输出Channel-Refined Feature Y(通道精炼特征)。
- 阶段一 (SRU):
- 输出 (Output):
Y作为SCConv模块的最终输出,被送入ResBlock的第二个1x1 Conv(用于恢复通道)。 - 残差连接 (ResBlock):该
1x1 Conv的输出,与来自“Previous ConvBlock”的恒等映射(Identity shortcut)进行逐元素相加( ⊕ \oplus ⊕)。 - 最终结果被送往“下一个卷积块 (Next ConvBlock)”。
- 输入 (Input):数据来自“上一个卷积块 (Previous ConvBlock)”。在ResBlock中,它首先通过一个
-
核心创新模块详解(Figure 2 & Figure 3):
-
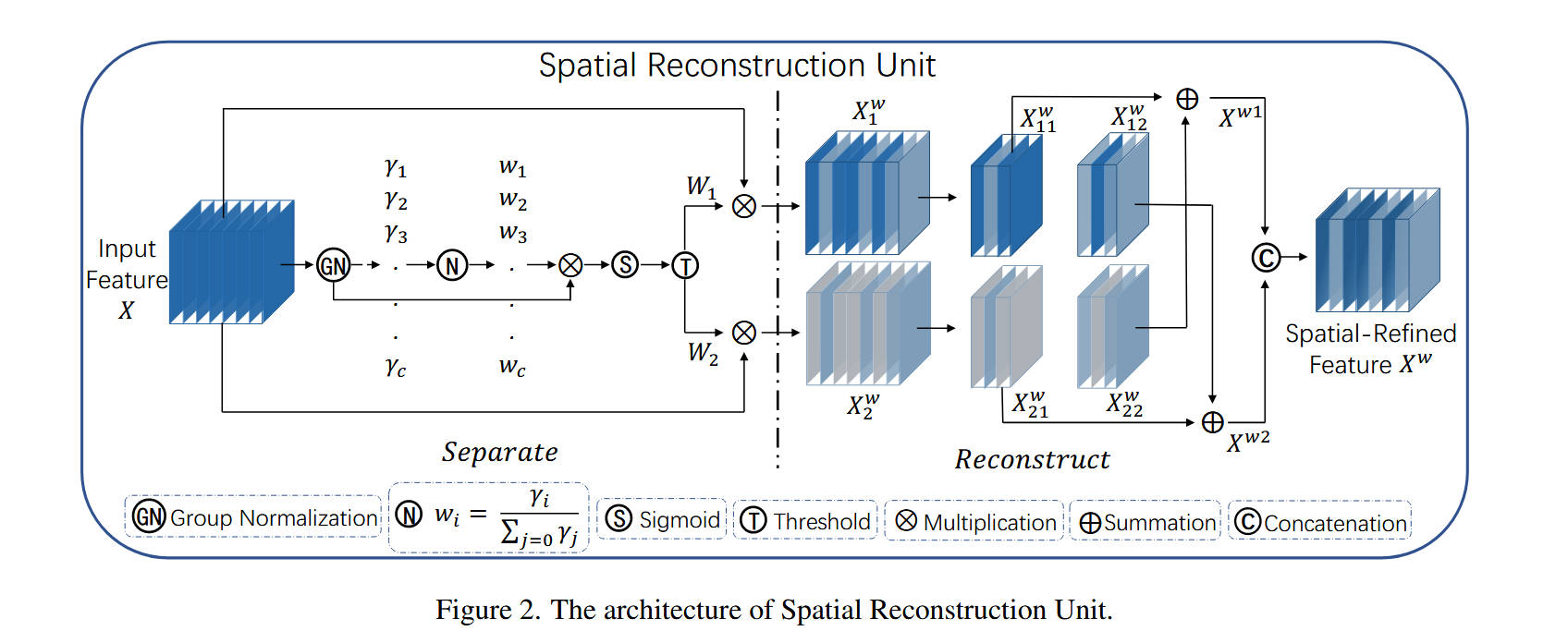
对于 模块 A:SRU (Spatial Reconstruction Unit) (Figure 2):
- 内部结构:该模块由“分离 (Separate)”和“重建 (Reconstruct)”两部分组成。
- 数据流动(Separate 阶段):
Input Feature X首先通过一个GN(Group Normalization)层。- SRU提取GN层中可学习的缩放参数 γ \gamma γ(每个通道一个 γ \gamma γ)。这个 γ \gamma γ 被用作衡量该通道特征图空间信息丰富度的指标( γ \gamma γ越大,方差越大,信息越丰富)。
- γ \gamma γ 向量经过一个归一化层
N(公式(2))得到权重 w i w_i wi,再依次通过Sigmoid(S) 和Threshold(T) (阈值设为0.5) 操作。 - 这产生了两组二元掩码(Mask): W 1 W_1 W1(信息丰富组, w i > 0.5 w_i > 0.5 wi>0.5)和 W 2 W_2 W2(信息冗余组, w i ≤ 0.5 w_i \le 0.5 wi≤0.5)。
- 使用这两个掩码与原始
X进行逐元素乘法( ⊗ \otimes ⊗),将X分离为 X 1 w X_1^w X1w(信息丰富特征)和 X 2 w X_2^w X2w(信息冗余特征)。
- 数据流动(Reconstruct 阶段):
- 该阶段的目的是利用 X 2 w X_2^w X2w 中的残余信息来增强 X 1 w X_1^w X1w。
- 如图所示, X 1 w X_1^w X1w 和 X 2 w X_2^w X2w 分别被(可能按通道)拆分为两半( X 11 w , X 12 w X_{11}^w, X_{12}^w X11w,X12w 和 X 21 w , X 22 w X_{21}^w, X_{22}^w X21w,X22w)。
- 执行“交叉重建”: X 11 w X_{11}^w X11w 与 X 22 w X_{22}^w X22w 相加( ⊕ \oplus ⊕)得到 X w 1 X^{w1} Xw1; X 21 w X_{21}^w X21w 与 X 12 w X_{12}^w X12w 相加得到 X w 2 X^{w2} Xw2。(注意:这里是信息组1的“一半”与信息组2的“另一半”相加)。
- 最后,将 X w 1 X^{w1} Xw1 和 X w 2 X^{w2} Xw2 沿通道维度拼接(Concatenation, C),得到最终的
Spatial-Refined Feature X^w。
- 设计目的:SRU的设计目的不是简单地丢弃冗余特征,而是通过“量化信息-分离-交叉重建”这一精细操作,在抑制空间冗余的同时,保留并强化了有用的特征表达。
-
对于 模块 B:CRU (Channel Reconstruction Unit) (Figure 3):
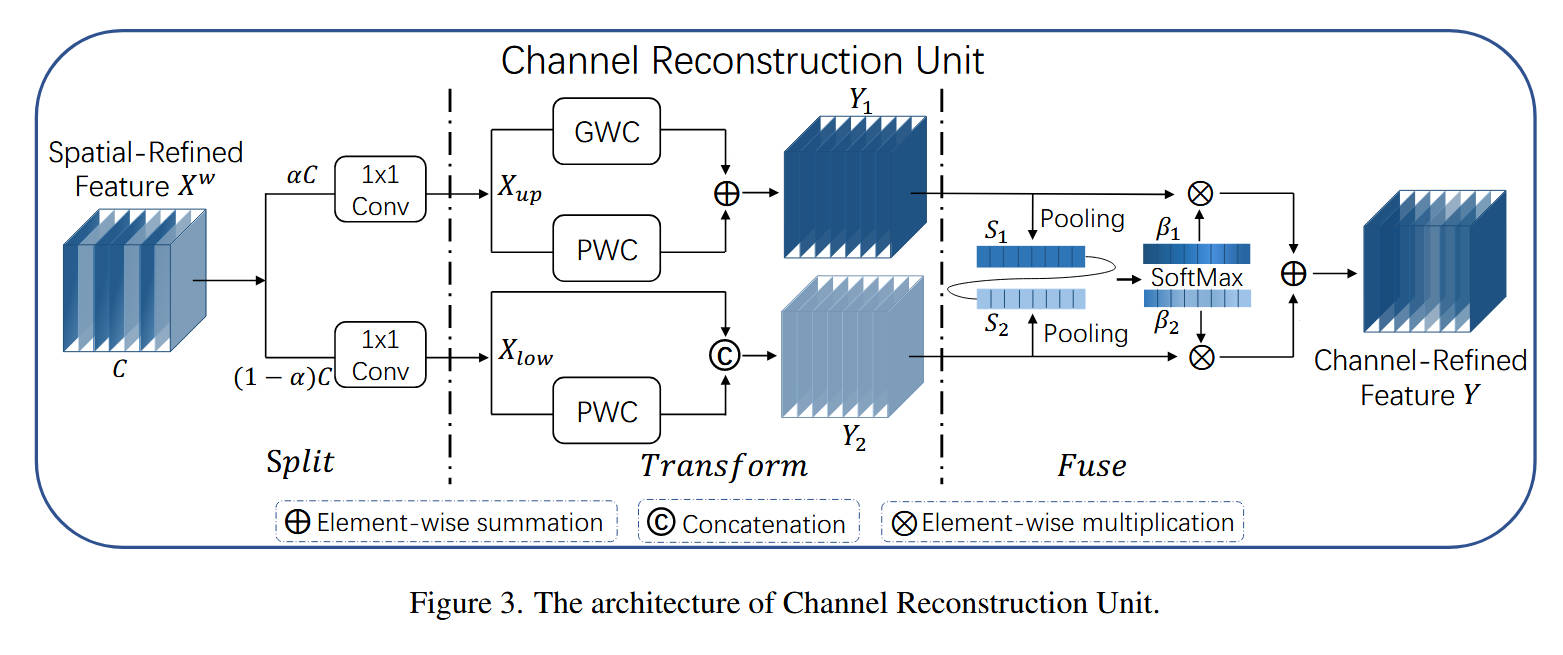
- 内部结构:该模块由“拆分 (Split)”、“变换 (Transform)” 和 “融合 (Fuse)” 三部分组成。
- 数据流动(Split 阶段):
- 来自SRU的
Spatial-Refined Feature X^w(总通道C)根据一个拆分比例 α \alpha α,在通道维度被“拆分”为两部分( α C \alpha C αC 和 ( 1 − α ) C (1-\alpha)C (1−α)C)。 - 这两部分各自通过一个
1x1 Conv进行通道压缩(压缩率 r r r,如 r = 2 r=2 r=2),分别得到上分支输入 X u p X_{up} Xup 和下分支输入 X l o w X_{low} Xlow。
- 来自SRU的
- 数据流动(Transform 阶段):这是一个非对称双分支。
- 上分支 (Rich Feature Extractor): X u p X_{up} Xup 被视为“富特征”。它同时进入一个
GWC(分组卷积)和一个PWC(逐点卷积),两者的输出相加( ⊕ \oplus ⊕),生成 Y 1 Y_1 Y1。此设计用低成本的GWC+PWC组合拳来提取复杂的、高级的特征。 - 下分支 (Supplementary): X l o w X_{low} Xlow 被视为“补充特征”。它进入一个廉价的
PWC,其输出与原始的 X l o w X_{low} Xlow(即特征复用)进行拼接(Concatenation, C),生成 Y 2 Y_2 Y2。此设计用最低的成本保留了浅层细节。
- 上分支 (Rich Feature Extractor): X u p X_{up} Xup 被视为“富特征”。它同时进入一个
- 数据流动(Fuse 阶段):
- Y 1 Y_1 Y1 和 Y 2 Y_2 Y2 需要被自适应地融合。
- Y 1 Y_1 Y1 和 Y 2 Y_2 Y2 各自通过
Global Average Pooling(池化)得到通道描述符 S 1 S_1 S1 和 S 2 S_2 S2。 - 将 S 1 S_1 S1 和 S 2 S_2 S2 堆叠并输入
SoftMax,得到两个注意力权重向量 β 1 \beta_1 β1 和 β 2 \beta_2 β2( β 1 + β 2 = 1 \beta_1 + \beta_2 = 1 β1+β2=1)。 - 最终的
Channel-Refined Feature Y是 Y 1 Y_1 Y1 和 Y 2 Y_2 Y2 的加权和: Y = β 1 Y 1 + β 2 Y 2 Y = \beta_1 Y_1 + \beta_2 Y_2 Y=β1Y1+β2Y2。
- 设计目的:CRU通过“拆分-非对称变换-自适应融合”的策略,实现了通道冗余的削减。它迫使网络将计算资源(GWC+PWC)分配给“富特征”,同时用几乎零成本(复用)的方式处理“补充特征”,并通过注意力机制动态平衡两者,实现高效的通道特征重建。
-
-
理念与机制总结:
- 核心理念:本文的核心理念是“分而治之”,它认为特征冗余同时存在于空间和通道两个正交的维度,必须“对症下药”。
- SRU机制:“空间信息量化”。其创新在于使用GN的 γ \gamma γ 参数作为“信息丰富度”的代理指标,实现了对“空间”冗余的量化和分离。
- CRU机制:“非对称特征重建”。其创新在于非对称地处理拆分后的通道:一边是“精加工”(GWC+PWC),一边是“低成本加工”(PWC+特征复用)。这种非对称设计比MobileNet的对称DWC+PWC更精细,成本控制更优。
- 串联机制 (S+C):SCConv的精髓在于串联(Ablation Study 表1 证明了 S+C 优于 C+S 和并行)。它首先通过SRU“提纯”空间特征(提高特征质量,如Figure 5所示),然后CRU再对这些“高质量”的特征进行通道压缩和重建(提高计算效率)。这个“先提纯质量,再压缩数量”的流程,协同地解决了两个维度的冗余。
-
图解总结:
- 论文首先通过 **Figure 5(左)**向我们展示了问题的根源:标准卷积产生了大量“无效”的(黑色的)或“相似”的(冗余的)空间特征图,这是“效率瓶颈”。
- 为了解决这个问题,Figure 2 (SRU) 设计了一个“空间净化器”。它通过GN的 γ \gamma γ 识别出Figure 5(左)中的无效特征图,并通过“分离-重建”操作,将其“变废为宝”,输出了如 **Figure 5(右)**所示的“信息丰富”的特征图。
- 在空间维度被“净化”后,特征在“通道”维度上依然是冗余的(即特征图数量C依然很多)。
- 因此,Figure 3 (CRU) 登场,它扮演了一个“通道压缩器”的角色。它将SRU输出的“高质量”特征图分为“复杂”和“简单”两组,并使用非对称的廉价操作(GWC、PWC、特征复用)对它们进行高效处理,最后通过注意力机制融合成最终输出。
- 总结:Figure 2 (SRU) 负责提高特征“质量”(由Figure 5验证),Figure 3 (CRU) 负责降低特征“数量”和计算量。两者串联在 Figure 1 的架构中,协同工作,共同解决了标准卷积中空间和通道的双重冗余问题。
5. 即插即用模块的作用
SCConv 模块本身被设计为一个**即插即用(plug-and-play)*的单元,其核心作用是*替代标准 3 × 3 3\times3 3×3 卷积,为现有的CNN架构(Backbones)赋能,在几乎不改变原网络拓扑的前提下,实现“降本增效”。
- 适用场景 1:现有CNN骨干网的轻量化与性能强化
- 具体应用:可以直接应用于任何以 3 × 3 3\times3 3×3 卷积为主要计算瓶颈的CNN架构,如 ResNet (R50, R101), ResNeXt, WideResNet, 甚至 DenseNet。
- 作用:如实验(Table 2)所示,将 ResNet-50 中的所有 3 × 3 3\times3 3×3 卷积替换为 SCConv,得到的 SCConv-R50 模型,在ImageNet上FLOPs降低了34.4%,参数量降低了34.3%,但Top-1准确率反而提升了0.26%( α = 1 / 2 \alpha=1/2 α=1/2时)。这展示了其作为“压缩-增强”模块的强大能力。
- 适用场景 2:资源受限环境下的下游任务(如移动端部署)
- 具体应用:在对计算资源(FLOPs)和内存(Params)高度敏感的下游任务中,如目标检测或语义分割。
- 作用:论文在 RetinaNet(一个目标检测框架)上进行了验证(Table 4, 5)。使用 SCConv-R50 作为骨干网的 RetinaNet,相比使用标准 ResNet-50 的版本:
- 在 PASCAL VOC 数据集上:mAP 提升了近 0.9%,FLOPs 降低了 34.1%。
- 在 MS COCO 数据集上:mAP 提升了 0.4%,FLOPs 降低了 34.4% (减少了22G FLOPs)。
- 这证明了 SCConv 学习到的特征表征更优异,泛化能力更强,使其非常适合部署在算力受限的设备上(如移动电话、边缘计算设备),以实现更高效、更准确的视觉分析。
- 适用场景 3:作为高效网络设计的新“积木”
- 具体应用:在设计全新的、从零开始(from scratch)的高效网络架构时。
- 作用:SRU 和 CRU 两个子模块的设计理念(如用GN γ \gamma γ 量化空间信息、非对称变换、特征复用、注意力融合)可以被拆分和借鉴,作为设计未来轻量化网络的新“积木”(building blocks),启发更高效的CNN架构设计。
6.即插即用模块
import torch
import torch.nn as nn
import torch.nn.functional as F
class GroupBatchnorm2d(nn.Module):
"""
二维组归一化层 (Group Normalization)
根据论文,使用组归一化来处理特征图
"""
def __init__(self, c_num: int, group_num: int = 16, eps: float = 1e-10):
super(GroupBatchnorm2d, self).__init__()
assert c_num >= group_num, f"通道数 {c_num} 必须大于等于组数 {group_num}"
self.group_num = group_num
# gamma参数衡量特征图中空间信息的不同,空间信息越丰富,gamma越大
self.gamma = nn.Parameter(torch.randn(c_num, 1, 1))
self.beta = nn.Parameter(torch.zeros(c_num, 1, 1))
self.eps = eps
def forward(self, x):
N, C, H, W = x.size()
# 重新塑形以便按组计算均值和标准差
x = x.view(N, self.group_num, -1)
mean = x.mean(dim=2, keepdim=True)
std = x.std(dim=2, keepdim=True)
x = (x - mean) / (std + self.eps)
# 恢复原始形状并应用缩放和平移
x = x.view(N, C, H, W)
return x * self.gamma + self.beta
class SRU(nn.Module):
"""
Spatial Reconstruction Unit (空间重构单元)
根据图2的架构:
1. 输入X经过Group Normalization得到gn_x
2. 从gamma计算权重 w_i = γ_i / Σ_j γ_j
3. 计算重加权值 reweights = Sigmoid(gn_x * w_gamma)
4. 通过阈值分离出信息量大和信息量少的特征图
5. 交叉重构得到最终输出
"""
def __init__(self, oup_channels: int, group_num: int = 16, gate_threshold: float = 0.5):
super().__init__()
self.gn = GroupBatchnorm2d(oup_channels, group_num=group_num)
self.gate_threshold = gate_threshold
self.sigmoid = nn.Sigmoid()
def forward(self, x):
# Step 1: Group Normalization
# GN层的可训练参数γ衡量特征图中空间信息的不同,空间信息越是丰富,γ越大
gn_x = self.gn(x)
# Step 2: 计算权重化的gamma
# w_i = γ_i / Σ_j γ_j,归一化每个通道的gamma值
w_gamma = self.gn.gamma.view(1, -1, 1, 1) / torch.sum(self.gn.gamma)
# Step 3: 计算重加权值并应用Sigmoid
# 根据图2,应该是先相乘w_i,然后Sigmoid,然后Threshold
reweights = self.sigmoid(gn_x * w_gamma)
# Step 4: 门控机制,通过阈值分离信息
# 获得信息量大和信息量较少的两个特征图
info_mask = reweights >= self.gate_threshold
noninfo_mask = reweights < self.gate_threshold
x_1 = info_mask.float() * x # 信息丰富的部分
x_2 = noninfo_mask.float() * x # 信息较少的部分
# Step 5: 重构输出
# 根据图2,交叉相乘与cat,获得最终的输出特征
x = self.reconstruct(x_1, x_2)
return x
def reconstruct(self, x_1, x_2):
"""
重构方法:交叉相加
根据图2:X11^W + X22^W 和 X12^W + X21^W,然后concatenate
"""
# 将x_1和x_2各分成两半
x_11, x_12 = torch.split(x_1, x_1.size(1) // 2, dim=1)
x_21, x_22 = torch.split(x_2, x_2.size(1) // 2, dim=1)
# 交叉相加并拼接:能够更加有效地联合两个特征并且加强特征之间的交互
return torch.cat([x_11 + x_22, x_12 + x_21], dim=1)
class CRU(nn.Module):
"""
Channel Reconstruction Unit (通道重构单元)
根据图3的架构,分为三个阶段:
1. Split: 使用1x1 Conv将输入分成Xup和Xlow
2. Transform: 分别对Xup和Xlow进行变换
3. Fuse: 使用attention机制融合Y1和Y2
"""
def __init__(self,
op_channel: int,
alpha: float = 1 / 2, # 分割比例,0 < alpha < 1
squeeze_radio: int = 2, # 压缩率
group_size: int = 2, # 组卷积的组大小
group_kernel_size: int = 3 # 组卷积核大小
):
super().__init__()
self.up_channel = int(alpha * op_channel) # 上半部分通道数
self.low_channel = op_channel - self.up_channel # 下半部分通道数
# Split阶段:使用1x1 Conv来分割通道(根据图3)
self.split_conv_up = nn.Conv2d(op_channel, self.up_channel, kernel_size=1, bias=False)
self.split_conv_low = nn.Conv2d(op_channel, self.low_channel, kernel_size=1, bias=False)
# Transform阶段的压缩卷积
self.squeeze1 = nn.Conv2d(self.up_channel, self.up_channel // squeeze_radio,
kernel_size=1, bias=False)
self.squeeze2 = nn.Conv2d(self.low_channel, self.low_channel // squeeze_radio,
kernel_size=1, bias=False)
# Transform阶段:上半部分(Upper branch)
# GWC: Group-wise Convolution
self.GWC = nn.Conv2d(self.up_channel // squeeze_radio, op_channel,
kernel_size=group_kernel_size, stride=1,
padding=group_kernel_size // 2, groups=group_size, bias=False)
# PWC: Point-wise Convolution
self.PWC1 = nn.Conv2d(self.up_channel // squeeze_radio, op_channel,
kernel_size=1, bias=False)
# Transform阶段:下半部分(Lower branch)
# PWC处理low_channel的一部分,然后与原始low拼接
self.PWC2 = nn.Conv2d(self.low_channel // squeeze_radio,
op_channel - self.low_channel // squeeze_radio,
kernel_size=1, bias=False)
# Fuse阶段:自适应平均池化(用于生成attention权重)
self.adaptive_avg_pool = nn.AdaptiveAvgPool2d(1)
def forward(self, x):
"""
根据图3的流程:
1. Split: 将输入分成Xup和Xlow
2. Transform: 分别变换得到Y1和Y2
3. Fuse: 使用attention融合Y1和Y2
"""
# ========== Split阶段 ==========
# 根据图3,使用1x1 Conv来分割
xup = self.split_conv_up(x) # αC channels
xlow = self.split_conv_low(x) # (1-α)C channels
# ========== Transform阶段 ==========
# 压缩
up = self.squeeze1(xup)
low = self.squeeze2(xlow)
# Upper branch: GWC + PWC,然后element-wise summation
Y1 = self.GWC(up) + self.PWC1(up)
# Lower branch: PWC + 直接通道,然后concatenation
Y2 = torch.cat([self.PWC2(low), low], dim=1)
# ========== Fuse阶段 ==========
# 根据图3,应该分别对Y1和Y2做Pooling得到S1和S2,然后concat,再softmax得到β1和β2
# 然后 Y1*β1 + Y2*β2
# 对Y1和Y2分别做全局平均池化,得到S1和S2
S1 = self.adaptive_avg_pool(Y1) # [B, C, 1, 1] where C = op_channel
S2 = self.adaptive_avg_pool(Y2) # [B, C, 1, 1] where C = op_channel
# 根据图3:S1和S2应该都是op_channel通道,然后concat得到[B, 2C, 1, 1]
# 然后softmax得到两个分支的attention权重
S_concat = torch.cat([S1, S2], dim=1) # [B, 2C, 1, 1]
# 将S_concat reshape为 [B, 2, C, 1, 1],这样可以在dim=1上应用softmax
# 得到每个分支的通道级attention权重
B, C = S1.size(0), S1.size(1)
S_reshaped = S_concat.view(B, 2, C, 1, 1) # [B, 2, C, 1, 1]
beta = F.softmax(S_reshaped, dim=1) # [B, 2, C, 1, 1],在分支维度上softmax
# 提取β1和β2
beta1 = beta[:, 0, :, :, :] # [B, C, 1, 1]
beta2 = beta[:, 1, :, :, :] # [B, C, 1, 1]
# Element-wise multiplication and summation
# Y1 * β1 + Y2 * β2
out = Y1 * beta1 + Y2 * beta2
return out
class SCConv(nn.Module):
"""
SCConv: Spatial and Channel reconstruction Convolution
即插即用的卷积模块,集成了SRU和CRU
根据图1的架构:
输入 -> SRU -> CRU -> 输出
"""
def __init__(self,
op_channel: int, # 操作通道数量
group_num: int = 16, # Group Normalization的组数
gate_threshold: float = 0.5, # SRU的阈值
alpha: float = 1 / 2, # CRU的分割比例
squeeze_radio: int = 2, # CRU的压缩率
group_size: int = 2, # CRU的组卷积组大小
group_kernel_size: int = 3 # CRU的组卷积核大小
):
super().__init__()
self.SRU = SRU(op_channel,
group_num=group_num,
gate_threshold=gate_threshold)
self.CRU = CRU(op_channel,
alpha=alpha,
squeeze_radio=squeeze_radio,
group_size=group_size,
group_kernel_size=group_kernel_size)
def forward(self, x):
"""
前向传播:先经过SRU进行空间重构,再经过CRU进行通道重构
"""
x = self.SRU(x) # 空间重构
x = self.CRU(x) # 通道重构
return x
if __name__ == '__main__':
# 测试代码
print("=" * 50)
print("测试 SCConv 模块")
print("=" * 50)
# 创建测试输入
batch_size = 2
channels = 64
height, width = 128, 128
input_tensor = torch.randn(batch_size, channels, height, width)
print(f"输入形状: {input_tensor.shape}")
# 创建SCConv模块
model = SCConv(op_channel=channels,
group_num=16,
gate_threshold=0.5,
alpha=1/2,
squeeze_radio=2,
group_size=2,
group_kernel_size=3)
# 前向传播
output = model(input_tensor)
print(f"输出形状: {output.shape}")
# 验证输入输出通道数是否一致
assert input_tensor.shape[1] == output.shape[1], \
f"通道数不匹配!输入: {input_tensor.shape[1]}, 输出: {output.shape[1]}"
assert input_tensor.shape[2] == output.shape[2], \
f"高度不匹配!输入: {input_tensor.shape[2]}, 输出: {output.shape[2]}"
assert input_tensor.shape[3] == output.shape[3], \
f"宽度不匹配!输入: {input_tensor.shape[3]}, 输出: {output.shape[3]}"
print("\n✓ 所有测试通过!模块工作正常。")
print("=" * 50)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 11
11 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)