AI是如何精准过滤噪音的?
经常开会,要进行会后整理的大多有这个困扰,录音里有噪音!麦克风杂音、同事键盘打字声、两个人同时的说话声....如果单纯靠耳朵听那是很影响准确率的。这时候就需要依靠专业的转写工具,让它来帮忙过滤掉这些噪音。那究竟是怎么过滤这些噪音的呢?其实可以把降噪过程理解为一场“核心思想:从混合信号中分离出目标信号麦克风收录的声音是一个混合体:纯净语音 + 背景噪音 = 带噪音频。降噪的目标就是从等号左边解出“纯
经常开会,要进行会后整理的大多有这个困扰,录音里有噪音!麦克风杂音、同事键盘打字声、两个人同时的说话声....如果单纯靠耳朵听那是很影响准确率的。这时候就需要依靠专业的转写工具,让它来帮忙过滤掉这些噪音。
那究竟是怎么过滤这些噪音的呢?其实可以把降噪过程理解为一场“语音与噪音的分离手术”。
核心思想:从混合信号中分离出目标信号
麦克风收录的声音是一个混合体:纯净语音 + 背景噪音 = 带噪音频。
降噪的目标就是从等号左边解出“纯净语音”。
一、传统降噪方法(基于信号处理)
这些方法不需要训练,基于固定的数学和声学模型,在计算资源有限的设备上仍有应用。
谱减法
核心思想:非常简单直观。假设噪音是稳定的(如风扇声、空调嗡嗡声),我们先在用户不说话时采集一段“纯噪音”样本,获取其频谱轮廓。然后,在整段音频中,从每个时刻的混合信号频谱中减去这个噪音频谱。
比喻:就像在一张写满字的纸上,如果你知道背景图案的颜色和形状,就可以尝试把它“减掉”,让字迹更清晰。
缺点:对非平稳噪音(如突然的关门声、键盘声)效果差,容易产生“音乐噪声”(一种残留的、类似音乐的残留杂音)。
维纳滤波
核心思想:比谱减法更先进一步。它不仅仅简单相减,而是计算一个最优滤波器。这个滤波器会在估计噪音和语音统计特性的基础上,尽可能让输出信号(即降噪后的信号)接近原始的纯净语音。
比喻:不是一个简单的减法器,而是一个“智能调音台”,它在每个频率点上根据信噪比动态调整旋钮:在信噪比高的地方(语音强),几乎不动;在信噪比低的地方(噪音强),大幅衰减。
缺点:同样依赖于对噪音和语音特性的准确估计,对于复杂多变的噪音环境依然力不从心。
二、现代基于深度学习的降噪方法(当前主流)
这是目前最先进、效果最好的方法,核心是使用深度神经网络 来学习“如何从带噪音频中恢复纯净语音”。
其工作流程可以概括为以下几个步骤:
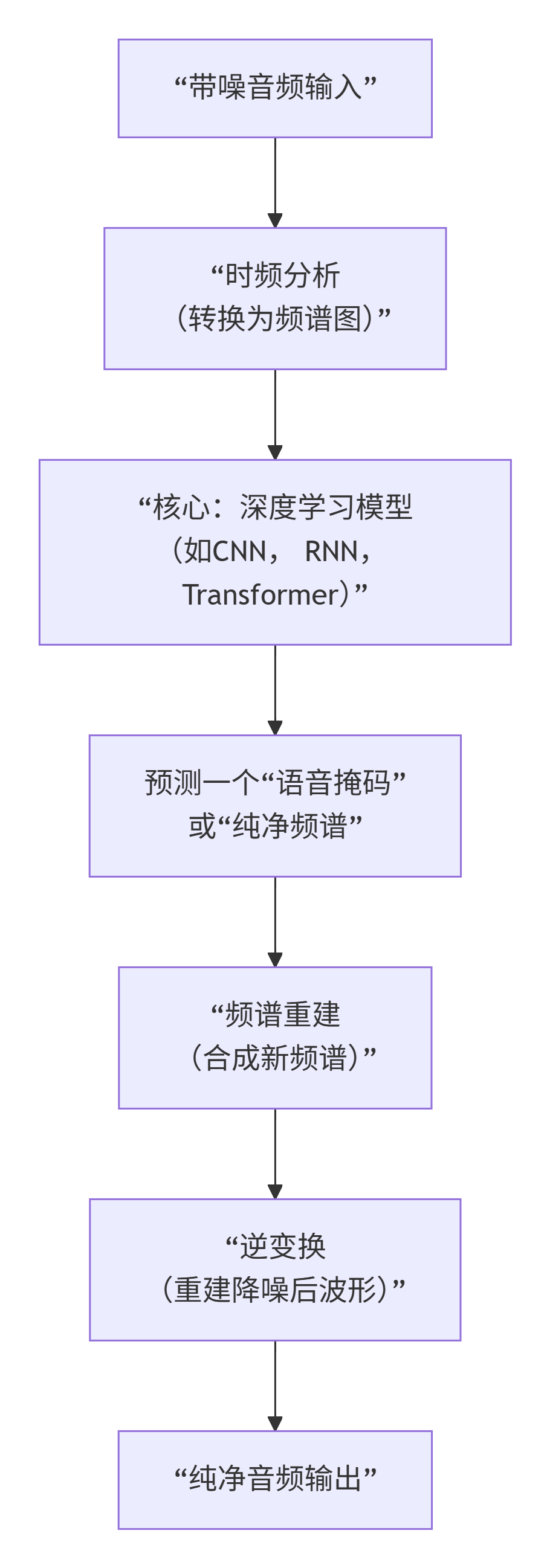
1.特征表示:从波形到频谱图
- 原始音频波形很难直接处理。神经网络的第一步通常是将音频通过短时傅里叶变换 转换为频谱图。
- 频谱图是一个二维图像,X轴是时间,Y轴是频率,颜色深浅代表能量强度。这样,音频降噪问题就变成了一个“图像分割”或“图像增强”问题:如何从一张布满噪音的频谱图中,提取出只属于语音的部分。
2.核心模型:深度学习网络(大脑)
- 网络结构多种多样,常见的有:
- 卷积神经网络:像处理图像一样,识别频谱图中的局部模式(哪些 pattern 是语音,哪些是噪音)。
- 循环神经网络:很好的捕捉语音在时间上的连续性。
- U-Net等编码器-解码器结构:先将频谱图压缩提取高级特征(编码),再将其还原为干净的频谱图(解码)。
- Transformer:强大的注意力机制可以捕捉频谱图中远距离的依赖关系。
- 训练过程:
- 需要海量的训练数据对,即【带噪音频,纯净音频】。
- 通过人工合成,可以将纯净的语音库与各种噪音库(交通、咖啡馆、办公室等)以不同的信噪比混合,制造出训练数据。
- 网络通过学习无数这样的数据对,最终学会了一个复杂的映射函数:输入带噪频谱 → 输出纯净频谱。
3.输出目标:掩码或纯净频谱
- 理想比值掩码(IRM):这是最主流和有效的方法之一。网络不直接生成纯净频谱,而是预测一个介于0和1之间的“掩码”矩阵。
- 掩码就像是一个“语音过滤器”或“蒙版”。这个蒙版与原始的带噪频谱图逐点相乘。
- 原理:在某个时间-频率点上,如果很可能是语音,掩码值就接近1(保留);如果很可能是噪音,掩码值就接近0(抑制)。
- 比喻:就像用Photoshop的蒙版抠图,把人物(语音)抠出来,把背景(噪音)擦掉。
- 频谱映射:另一种方法是直接让网络生成估计的纯净频谱。
4.波形重建
- 得到降噪后的频谱图(无论是通过掩码处理还是直接生成)后,使用逆短时傅里叶变换 将其重新合成为最终的、干净的音频波形。
实际应用中的挑战与技巧
- 噪音类型:
- 稳态噪音(如风扇、机器):最容易去除,传统方法就有效。
- 非稳态噪音(如键盘声、敲门声、他人谈话):很难,需要深度学习模型才能较好处理。
- 人声背景噪音:最难,因为其声学特性与目标语音非常相似,强力降噪可能会损伤目标语音本身,造成“机器人声”或语音断续。
- 端到端模型:现在更前沿的技术是直接输入带噪波形,输出纯净波形,完全跳过频谱图这一步,理论上性能更强,但对数据和算力要求更高。
- 集成在系统中:在录音转文字的全流程中,降噪通常是预处理的第一步。一个干净的音频信号,能极大提升后续声学模型(识别音素)和语言模型(识别词语)的准确率。
总结来说,现代录音转文字服务中的降噪,本质上是一个由海量数据驱动的、高度复杂的AI模型,它学会了如何像人脑一样,从嘈杂的环境中“聚焦”并“提取”出我们想听的那个声音。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)