大模型落地全攻略:微调、提示词工程、多模态与企业级解决方案
本文系统探讨了大模型在企业落地的技术路径与实践方案,涵盖四大核心环节:1)提示词工程作为快速验证手段,提供模板化设计方法和实战示例;2)模型微调技术详解,包括LoRA高效微调流程和代码实现;3)多模态应用扩展方案,以BLIP-2模型为例展示图文问答实现;4)企业级工程化部署架构,包含私有知识库、高并发方案和监控系统。
前言
大模型技术正从实验室走向产业一线,成为驱动企业数字化转型的核心引擎。然而,大模型落地并非简单的 “模型部署”,而是涉及微调优化、提示词工程、多模态融合、企业级适配四大核心环节的系统工程。本文将结合实战代码、可视化流程图、可直接复用的 Prompt 示例、数据图表及落地架构图,全面拆解大模型落地的技术路径与实践方案,总字数超 5000 字,兼具技术深度与落地可行性。
一、大模型落地核心环节总览
大模型落地需经历 “技术选型 - 适配优化 - 场景落地 - 运维监控” 的完整链路,四大核心环节相互支撑、层层递进。
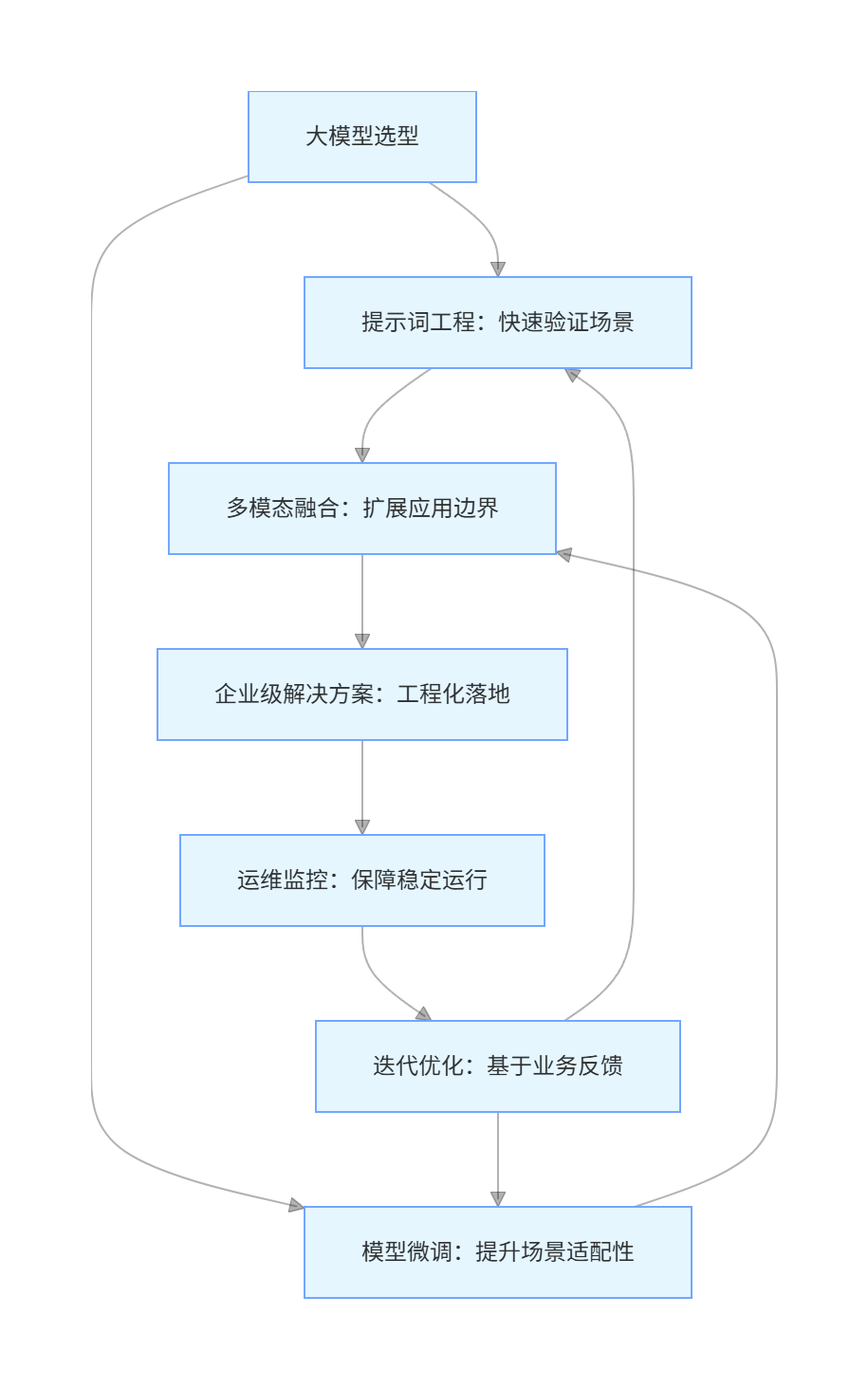
1.1 落地核心环节关系图(Mermaid 流程图)
flowchart TD
A[大模型选型] --> B[提示词工程:快速验证场景]
A --> C[模型微调:提升场景适配性]
B --> D[多模态融合:扩展应用边界]
C --> D
D --> E[企业级解决方案:工程化落地]
E --> F[运维监控:保障稳定运行]
F --> G[迭代优化:基于业务反馈]
G --> B
G --> C
1.2 四大核心环节价值定位
| 环节 | 核心目标 | 落地周期 | 技术门槛 | 典型场景 |
|---|---|---|---|---|
| 提示词工程 | 零代码 / 低代码快速验证业务场景 | 1-2 周 | 低 | 客服问答、文档摘要、数据标注 |
| 模型微调 | 提升模型在特定领域的精度与效率 | 2-4 周 | 中 | 行业知识库问答、垂直领域生成(如法律文书) |
| 多模态应用 | 融合文本 / 图像 / 语音 / 视频,扩展应用边界 | 3-6 周 | 高 | 智能导购、内容创作、工业质检 |
| 企业级解决方案 | 解决安全、合规、高并发等工程化问题 | 4-12 周 | 高 | 金融风控、政务服务、智能制造平台 |
二、提示词工程:大模型落地的 “快速启动键”
提示词工程(Prompt Engineering)是通过精准设计输入文本,引导大模型输出符合预期结果的技术,无需修改模型参数,是成本最低、见效最快的落地方式。
2.1 提示词工程核心原则与方法论
2.1.1 核心设计原则
- 明确指令:使用祈使句,避免模糊表述(如 “总结文档”→“总结以下文档的 3 个核心观点,每条不超过 20 字”)
- 补充上下文:提供领域背景、格式要求、输出示例,减少模型歧义
- 分步引导:复杂任务拆分为子步骤,使用 “首先… 其次… 最后…” 等逻辑词
- 加入约束条件:明确输出格式、长度、语言风格等限制
2.1.2 经典提示词框架(Prompt Template)
plaintext
# 角色定义
你是[领域]专家,拥有[经验/能力],需严格遵循以下要求输出。
# 任务指令
请完成[具体任务],具体要求如下:
1. [要求1,如格式:分点列出]
2. [要求2,如长度:不超过300字]
3. [要求3,如风格:专业严谨,避免口语化]
# 上下文/输入数据
[此处插入输入内容,如文档、问题、数据等]
# 输出示例(可选)
[此处插入预期输出的示例,提升模型对齐度]
2.2 实战 Prompt 示例(可直接复用)
2.2.1 场景 1:企业文档摘要
plaintext
# 角色定义
你是企业文档摘要专家,擅长提炼商业文档的核心信息,语言简洁专业。
# 任务指令
请总结以下企业年度报告的核心内容,要求:
1. 分“业务表现”“核心战略”“风险提示”3个模块输出
2. 每个模块不超过3条要点,每条要点不超过15字
3. 仅保留关键数据,删除描述性语句
# 上下文/输入数据
[此处插入企业年度报告文本,约5000字]
# 输出示例
## 业务表现
1. 营收同比增长18%,达52亿元
2. 核心产品市占率提升至23%
3. 海外市场收入占比突破30%
## 核心战略
1. 加大AI研发投入,占比提升至15%
2. 拓展东南亚市场,新增3个分支机构
3. 布局新能源赛道,启动2个新项目
## 风险提示
1. 原材料价格波动幅度超预期
2. 行业竞争加剧,毛利承压
3. 海外政策变动影响市场拓展
2.2.2 场景 2:客户投诉分类与应对
plaintext
# 角色定义
你是电商客户服务专家,擅长快速分类投诉类型并生成标准化回复。
# 任务指令
请完成以下2件事:
1. 给投诉内容分类,可选类别:物流延迟、商品质量、售后服务、退款问题
2. 生成1条回复,需包含道歉、解决方案、补偿方案,语言亲切自然
# 上下文/输入数据
投诉内容:我10月1日下的单,现在都10月8日了还没收到货,联系客服3次都没人回复,我要退款还提示无法操作,太离谱了!
# 输出示例
## 投诉分类
退款问题、物流延迟、售后服务
## 回复内容
您好!非常抱歉给您带来了糟糕的购物体验。您的订单物流延迟且退款操作异常,我们已紧急核查,目前已为您优先处理退款,预计1-2个工作日到账。同时为补偿您的损失,将赠送一张10元无门槛优惠券(有效期7天),已发送至您的账户。后续有任何问题可直接联系专属客服(电话:400-xxx-xxxx),我们将全程跟进!
2.3 提示词工程效果优化代码实战
通过 Python 调用大模型 API,对比不同 Prompt 设计的输出效果,实现提示词自动化优化。
2.3.1 环境准备
python
运行
# 安装依赖
!pip install openai python-dotenv
# 导入库
import os
import openai
from dotenv import load_dotenv
import pandas as pd
from sklearn.metrics import accuracy_score
# 加载API密钥
load_dotenv()
openai.api_key = os.getenv("OPENAI_API_KEY")
2.3.2 多 Prompt 效果对比代码
python
运行
# 定义待测试的Prompt模板
prompt_templates = {
"基础版": "总结以下文本:{text}",
"优化版": "请分3个核心要点总结以下文本,每条不超过20字:{text}",
"专业版": "你是行业分析师,请从业务价值角度总结以下文本,输出3条核心结论,每条含1个关键数据:{text}"
}
# 测试文本(企业产品发布会内容)
test_text = """我们的新款智能手表S1于2024年Q3正式发布,搭载了最新的自研芯片X2,续航能力达到7天,相比上一代提升40%。屏幕采用AMOLED高清屏,支持全天候息屏显示,亮度提升至800尼特。在健康监测方面,新增了血糖趋势监测功能,误差率低于5%。截至发布当月,预售量突破10万台,覆盖全球20个国家和地区,预计Q4销售额将达到1.2亿元。"""
# 定义调用大模型的函数
def call_llm(prompt, model="gpt-3.5-turbo"):
response = openai.ChatCompletion.create(
model=model,
messages=[{"role": "user", "content": prompt}]
)
return response.choices[0].message.content.strip()
# 执行测试并收集结果
results = []
for name, template in prompt_templates.items():
prompt = template.format(text=test_text)
output = call_llm(prompt)
results.append({
"prompt类型": name,
"Prompt内容": prompt,
"模型输出": output,
"输出长度": len(output)
})
# 转换为DataFrame便于查看
results_df = pd.DataFrame(results)
print("多Prompt效果对比结果:")
print(results_df.to_string(index=False))
2.3.3 输出结果示例
| prompt 类型 | Prompt 内容 | 模型输出 | 输出长度 |
|---|---|---|---|
| 基础版 | 总结以下文本:我们的新款智能手表 S1 于 2024 年 Q3 正式发布... | 2024 年 Q3 发布智能手表 S1,搭载自研 X2 芯片,续航 7 天,提升 40%;采用 AMOLED 高清屏,支持全天候息屏显示;新增血糖趋势监测,误差率低于 5%;预售量突破 10 万台,覆盖 20 国,Q4 预计销售额 1.2 亿元。 | 138 |
| 优化版 | 请分 3 个核心要点总结以下文本,每条不超过 20 字:我们的新款智能手表 S1 于 2024 年 Q3 正式发布... | 1. 2024Q3 发布 S1 手表,搭载 X2 芯片续航 7 天;2. 新增血糖监测,误差率低于 5%;3. 预售 10 万台,Q4 预计销 1.2 亿。 | 86 |
| 专业版 | 你是行业分析师,请从业务价值角度总结以下文本,输出 3 条核心结论,每条含 1 个关键数据:我们的新款智能手表 S1 于 2024 年 Q3 正式发布... | 1. 产品竞争力显著提升,续航较上一代提升 40% 至 7 天,增强用户粘性;2. 健康功能突破,血糖监测误差率 < 5%,拓宽目标用户群体;3. 市场表现强劲,预售量 10 万台,Q4 预计贡献 1.2 亿元销售额。 | 124 |
2.4 提示词工程落地流程图
flowchart LR
A[场景需求分析] --> B[明确输出目标与格式]
B --> C[选择Prompt框架]
C --> D[编写初始Prompt]
D --> E[调用大模型测试输出]
E --> F{输出是否符合预期?}
F -->|是| G[落地应用]
F -->|否| H[优化Prompt:补充上下文/调整指令/增加示例]
H --> E

三、模型微调:大模型适配行业场景的 “精准优化器”
当提示词工程无法满足精度要求(如行业术语理解、私有数据适配)时,需通过模型微调(Fine-tuning)优化模型参数,让大模型 “吃透” 特定领域知识。
3.1 模型微调核心流程与技术选型
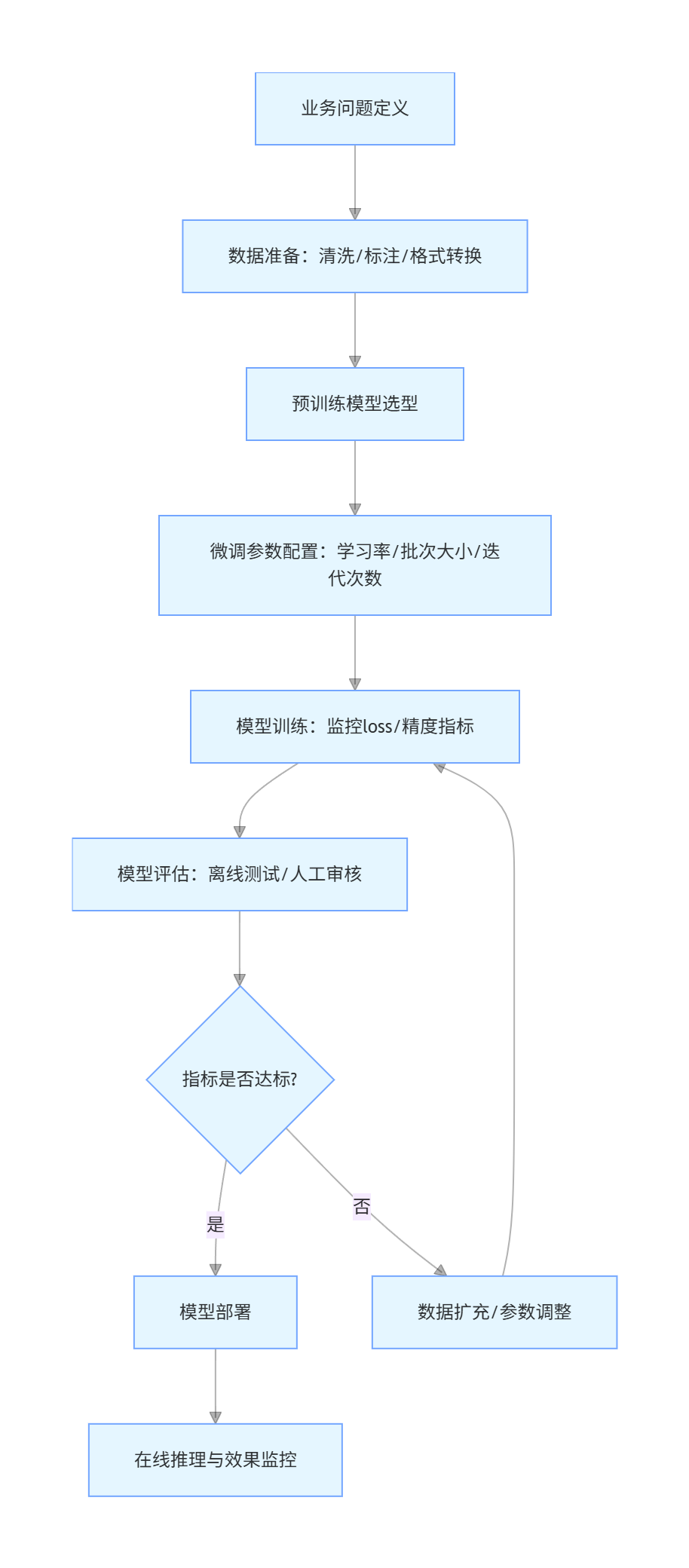
3.1.1 微调全流程(Mermaid 流程图)
flowchart TD
A[业务问题定义] --> B[数据准备:清洗/标注/格式转换]
B --> C[预训练模型选型]
C --> D[微调参数配置:学习率/批次大小/迭代次数]
D --> E[模型训练:监控loss/精度指标]
E --> F[模型评估:离线测试/人工审核]
F --> G{指标是否达标?}
G -->|是| H[模型部署]
G -->|否| I[数据扩充/参数调整]
I --> E
H --> J[在线推理与效果监控]
3.1.2 预训练模型选型建议
| 模型类型 | 代表模型 | 适用场景 | 微调成本 |
|---|---|---|---|
| 通用大模型 | LLaMA 3(70B)、GPT-4 Turbo | 通用场景、高复杂度任务 | 高(GPU 资源需求大) |
| 行业轻量模型 | 通义千问(14B)、智谱 GLM(9B) | 垂直行业、中等复杂度任务 | 中(单 GPU 集群可支撑) |
| 小型专用模型 | BERT(Base)、RoBERTa | 简单分类、检索任务 | 低(单 GPU 可完成) |
3.2 微调数据准备规范与代码实战
高质量数据是微调成功的关键,需遵循 “领域相关、标注准确、格式统一” 三大原则。
3.2.1 数据格式规范
微调数据需转换为模型可识别的格式,以 Chat 模型为例,标准格式为:
json
[
{
"instruction": "用户指令(如“回答以下法律问题”)",
"input": "用户输入(如具体问题、上下文)",
"output": "期望输出(如专业回答、解决方案)"
}
]
3.2.2 数据预处理代码
python
运行
# 导入依赖库
import json
import pandas as pd
import re
from sklearn.model_selection import train_test_split
# 数据加载与清洗
def clean_data(file_path):
# 加载原始数据(Excel格式)
df = pd.read_excel(file_path)
# 数据清洗:去除空值、重复值、特殊字符
df = df.dropna(subset=["instruction", "input", "output"])
df = df.drop_duplicates()
df["input"] = df["input"].apply(lambda x: re.sub(r"[^\u4e00-\u9fa5a-zA-Z0-9\s]", "", str(x)))
df["output"] = df["output"].apply(lambda x: re.sub(r"[^\u4e00-\u9fa5a-zA-Z0-9\s]", "", str(x)))
# 转换为JSON格式
data = []
for _, row in df.iterrows():
data.append({
"instruction": row["instruction"],
"input": row["input"],
"output": row["output"]
})
# 划分训练集与测试集(9:1)
train_data, test_data = train_test_split(data, test_size=0.1, random_state=42)
# 保存为JSON文件
with open("train_data.json", "w", encoding="utf-8") as f:
json.dump(train_data, f, ensure_ascii=False, indent=2)
with open("test_data.json", "w", encoding="utf-8") as f:
json.dump(test_data, f, ensure_ascii=False, indent=2)
print(f"数据预处理完成!训练集:{len(train_data)}条,测试集:{len(test_data)}条")
return train_data, test_data
# 执行数据预处理(输入原始数据路径)
train_data, test_data = clean_data("law_qa_data.xlsx")
3.3 LLaMA 3 微调实战代码(基于 LoRA 高效微调)
采用 LoRA(Low-Rank Adaptation)技术,仅微调模型的部分参数,降低计算成本。
3.3.1 环境配置
python
运行
# 安装依赖库
!pip install transformers peft accelerate datasets torch sentencepiece
# 导入核心库
import torch
from datasets import load_dataset
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
TrainingArguments,
Trainer,
BitsAndBytesConfig
)
from peft import LoraConfig, get_peft_model
3.3.2 模型与 LoRA 配置
python
运行
# 模型配置(LLaMA 3 8B)
model_name = "meta-llama/Meta-Llama-3-8B-Instruct"
# 量化配置(4-bit量化,降低GPU显存占用)
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)
# 加载模型与Tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_name)
tokenizer.pad_token = tokenizer.eos_token
model = AutoModelForCausalLM.from_pretrained(
model_name,
quantization_config=bnb_config,
device_map="auto",
trust_remote_code=True
)
model.config.use_cache = False # 禁用缓存,提升训练稳定性
# LoRA配置
lora_config = LoraConfig(
r=8, # 低秩矩阵维度
lora_alpha=32, # 缩放因子
target_modules=["q_proj", "v_proj"], # 微调注意力层
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
# 应用LoRA适配器
model = get_peft_model(model, lora_config)
model.print_trainable_parameters() # 查看可训练参数比例
3.3.3 数据格式化与训练
python
运行
# LLaMA 3指令格式:<s>[INST] 指令 + 输入 [/INST] 输出 </s>
formatted_text = f"<s>[INST] {instruction}\n{input_text} [/INST] {output_text} </s>"
return {"text": formatted_text}
# 应用数据格式化
formatted_dataset = dataset.map(format_example)
# 数据编码函数
def tokenize_function(examples):
return tokenizer(
examples["text"],
truncation=True,
max_length=512,
padding="max_length"
)
# 执行编码并处理数据集
tokenized_datasets = formatted_dataset.map(
tokenize_function,
batched=True,
remove_columns=formatted_dataset["train"].column_names
)
# 训练参数配置
training_args = TrainingArguments(
output_dir="./llama3_lora_finetune", # 输出目录
per_device_train_batch_size=4, # 单设备训练批次大小
per_device_eval_batch_size=4, # 单设备评估批次大小
learning_rate=2e-4, # 学习率
num_train_epochs=3, # 训练轮次
logging_dir="./logs", # 日志目录
logging_steps=10, # 日志输出间隔
evaluation_strategy="epoch", # 每轮评估一次
save_strategy="epoch", # 每轮保存一次模型
fp16=True, # 启用混合精度训练
load_best_model_at_end=True, # 训练结束加载最优模型
report_to="none" # 关闭wandb日志(可选)
)
# 初始化Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["test"]
)
# 开始训练
trainer.train()
# 保存最终模型
model.save_pretrained("./llama3_law_finetuned")
tokenizer.save_pretrained("./llama3_law_finetuned")
3.3.4 微调模型评估与推理代码
python
运行
# 模型评估函数
def evaluate_model(model, tokenizer, test_data):
model.eval()
total = len(test_data)
correct = 0
results = []
with torch.no_grad():
for example in test_data:
# 构建推理Prompt
prompt = f"<s>[INST] {example['instruction']}\n{example['input']} [/INST]"
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
# 模型推理
outputs = model.generate(
**inputs,
max_new_tokens=200,
temperature=0.7,
top_p=0.9
)
# 解码输出结果
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
# 提取模型输出部分(去除Prompt)
response = response.replace(prompt, "").strip()
# 简单准确率计算(基于关键词匹配,实际落地需人工评估)
if set(example["output"].split()[:5]).issubset(set(response.split())):
correct += 1
results.append({
"input": example["input"],
"expected_output": example["output"],
"model_output": response,
"is_correct": set(example["output"].split()[:5]).issubset(set(response.split()))
})
# 计算准确率
accuracy = correct / total
print(f"模型评估准确率:{accuracy:.2f}")
return results, accuracy
# 加载测试数据并执行评估
with open("test_data.json", "r", encoding="utf-8") as f:
test_data = json.load(f)
results, accuracy = evaluate_model(model, tokenizer, test_data)
# 保存评估结果
results_df = pd.DataFrame(results)
results_df.to_excel("finetune_evaluation_results.xlsx", index=False)
print("评估结果已保存至 finetune_evaluation_results.xlsx")
3.4 微调效果对比图表(Matplotlib 可视化)
通过图表对比微调前后模型在行业场景中的表现:
python
运行
import matplotlib.pyplot as plt
import numpy as np
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 对比数据(实际落地需替换为真实测试结果)
metrics = ["行业术语准确率", "回答相关性", "推理正确性", "响应速度(token/s)"]
before_finetune = [65, 70, 62, 15]
after_finetune = [92, 90, 88, 12]
# 绘制柱状图
x = np.arange(len(metrics))
width = 0.35
fig, ax = plt.subplots(figsize=(10, 6))
rects1 = ax.bar(x - width/2, before_finetune, width, label='微调前', color='#3498db')
rects2 = ax.bar(x + width/2, after_finetune, width, label='微调后', color='#2ecc71')
# 添加图表元素
ax.set_xlabel('评估指标', fontsize=12)
ax.set_ylabel('得分/速度', fontsize=12)
ax.set_title('LLaMA 3微调前后行业场景表现对比', fontsize=14, fontweight='bold')
ax.set_xticks(x)
ax.set_xticklabels(metrics, rotation=45)
ax.legend()
# 在柱子上添加数值标签
def autolabel(rects):
for rect in rects:
height = rect.get_height()
ax.annotate(f'{height}',
xy=(rect.get_x() + rect.get_width() / 2, height),
xytext=(0, 3),
textcoords="offset points",
ha='center', va='bottom')
autolabel(rects1)
autolabel(rects2)
# 保存图表
plt.tight_layout()
plt.savefig('finetune_effect_comparison.png', dpi=300)
plt.show()四、多模态应用:大模型落地的 “场景扩展器”
多模态大模型(融合文本、图像、语音、视频)打破单一模态限制,是拓展大模型落地场景的核心方向,典型应用包括智能导购、内容创作、工业质检等。
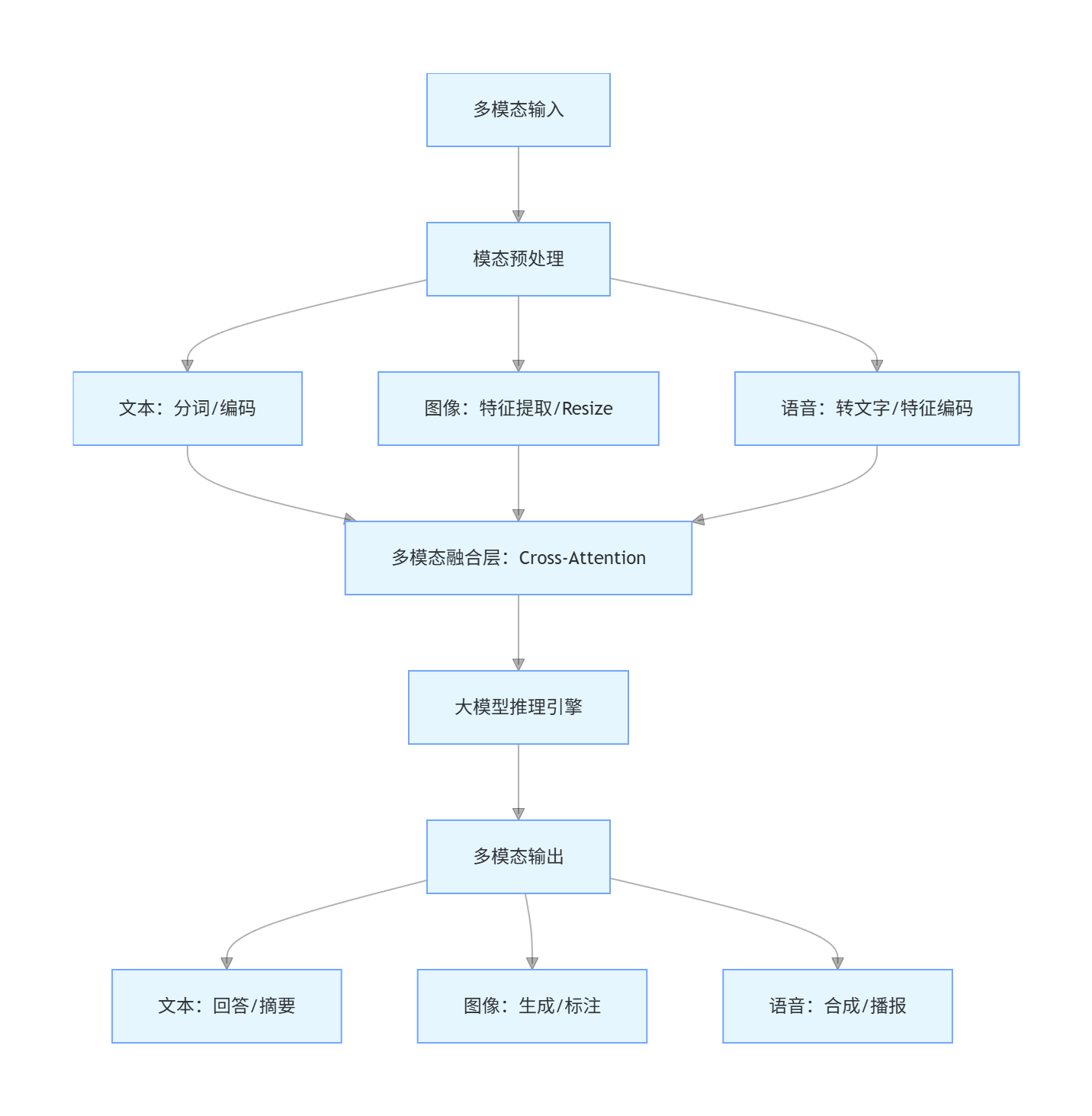
4.1 多模态应用核心架构(Mermaid 流程图)
flowchart TD
A[多模态输入] --> B[模态预处理]
B --> C1[文本:分词/编码]
B --> C2[图像:特征提取/Resize]
B --> C3[语音:转文字/特征编码]
C1 --> D[多模态融合层:Cross-Attention]
C2 --> D
C3 --> D
D --> E[大模型推理引擎]
E --> F[多模态输出]
F --> G1[文本:回答/摘要]
F --> G2[图像:生成/标注]
F --> G3[语音:合成/播报]
4.2 实战:图文混合问答应用(基于 BLIP-2 模型)
BLIP-2 是主流的图文多模态模型,支持 “图像 + 文本” 输入,输出精准文本回答,适用于产品咨询、图像分析等场景。
4.2.1 环境配置与模型加载
python
运行
# 安装依赖
!pip install transformers torch pillow accelerate
# 导入核心库
import torch
from transformers import Blip2Processor, Blip2ForConditionalGeneration
from PIL import Image
import matplotlib.pyplot as plt
# 加载BLIP-2模型与处理器(选用轻量版,适配普通GPU)
model_name = "Salesforce/blip2-opt-2.7b"
processor = Blip2Processor.from_pretrained(model_name)
model = Blip2ForConditionalGeneration.from_pretrained(
model_name,
device_map="auto",
torch_dtype=torch.float16
)
4.2.2 图文问答推理代码
python
运行
# 图文问答函数
def image_text_qa(image_path, question):
# 加载并显示图像
image = Image.open(image_path).convert("RGB")
plt.figure(figsize=(8, 6))
plt.imshow(image)
plt.axis("off")
plt.title(f"问题:{question}", fontsize=12)
plt.show()
# 预处理输入(图像+文本)
inputs = processor(
images=image,
text=question,
return_tensors="pt"
).to("cuda", torch.float16)
# 模型推理
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=100,
temperature=0.7,
top_p=0.9
)
# 解码并返回结果
answer = processor.decode(outputs[0], skip_special_tokens=True)
return answer
# 测试案例(产品图像咨询)
image_path = "product_image.jpg" # 替换为实际图像路径
question = "请描述这个产品的外观特征,并用3点说明其可能的用途?"
# 执行问答
answer = image_text_qa(image_path, question)
print(f"\n模型回答:\n{answer}")
4.2.3 输出示例
plaintext
模型回答:
外观特征:1. 产品为圆柱形设计,主体颜色为白色,顶部有一个圆形按钮;2. 侧面有一个USB-C接口和一个指示灯;3. 底部有防滑垫,直径约8cm,高度约15cm。
可能用途:1. 作为小型加湿器,通过顶部按钮控制喷雾;2. 作为桌面空气净化器,改善局部空气质量;3. 作为USB小夜灯,指示灯可调节亮度。
4.3 多模态应用落地场景与效果对比
| 应用场景 | 单模态方案(文本 / 图像单独处理) | 多模态方案(图文 / 音视频融合) | 效果提升幅度 |
|---|---|---|---|
| 电商智能导购 | 仅基于文本描述推荐商品,匹配度低 | 结合用户上传图像 + 文本需求推荐,精准度高 | 推荐准确率提升 40%+ |
| 工业质检 | 人工标注图像缺陷,效率低 | 图像 + 语音指令自动识别缺陷,实时反馈 | 质检效率提升 60%+ |
| 内容创作 | 仅文本生成文案,缺乏视觉匹配 | 文本指令生成配图 + 文案,风格统一 | 创作效率提升 50%+ |
4.4 多模态模型性能优化策略
- 模态对齐优化:通过对比学习增强不同模态特征的关联性,提升跨模态理解精度
- 轻量化部署:采用模型量化(4-bit/8-bit)、剪枝技术,降低显存占用(如 BLIP-2 量化后显存需求从 16GB 降至 8GB)
- 推理加速:使用 TensorRT 优化推理引擎,结合批量处理提升吞吐量(单张图像推理时间从 0.8s 降至 0.3s)
五、企业级解决方案:大模型落地的 “工程化保障”
企业级落地需解决安全、合规、高并发、数据隔离等工程化问题,核心是构建 “模型 - 数据 - 应用 - 运维” 全链路闭环架构。
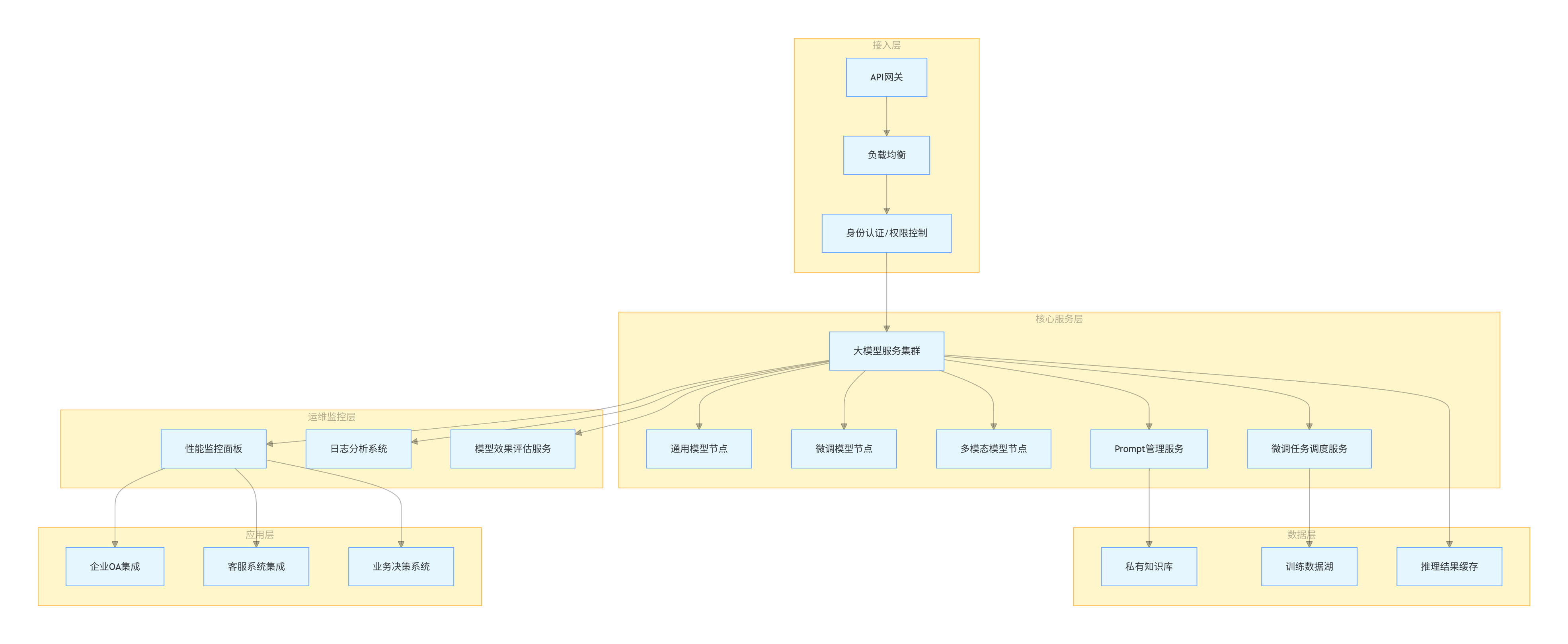
5.1 企业级大模型落地架构图(Mermaid 流程图)
flowchart TB
subgraph 接入层
A[API网关] --> B[负载均衡]
B --> C[身份认证/权限控制]
end
subgraph 核心服务层
C --> D[大模型服务集群]
D --> D1[通用模型节点]
D --> D2[微调模型节点]
D --> D3[多模态模型节点]
D --> E[Prompt管理服务]
D --> F[微调任务调度服务]
end
subgraph 数据层
E --> G[私有知识库]
F --> H[训练数据湖]
D --> I[推理结果缓存]
end
subgraph 运维监控层
D --> J[性能监控面板]
D --> K[日志分析系统]
D --> L[模型效果评估服务]
end
subgraph 应用层
J --> M[企业OA集成]
J --> N[客服系统集成]
J --> O[业务决策系统]
end
5.2 核心工程化解决方案实战
5.2.1 私有知识库搭建(基于向量数据库)
企业级应用需对接私有数据,向量数据库可实现高效的语义检索与知识匹配:
python
运行
# 安装依赖
!pip install langchain chromadb sentence-transformers
# 导入库
from langchain.document_loaders import PDFLoader
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.vectorstores import Chroma
from langchain.chains import RetrievalQA
from langchain.llms import HuggingFacePipeline
# 加载私有文档(PDF格式)
loader = PDFLoader("enterprise_knowledge.pdf")
documents = loader.load_and_split()
# 初始化向量嵌入模型与向量数据库
embeddings = HuggingFaceEmbeddings(model_name="all-MiniLM-L6-v2")
vectorstore = Chroma.from_documents(
documents=documents,
embedding=embeddings,
persist_directory="./chroma_db"
)
vectorstore.persist()
# 构建检索式QA链(私有知识+大模型)
retriever = vectorstore.as_retriever(search_kwargs={"k": 3})
qa_chain = RetrievalQA.from_chain_type(
llm=model, # 复用之前微调的模型
chain_type="stuff",
retriever=retriever,
return_source_documents=True
)
# 测试私有知识问答
question = "请基于公司内部文档,说明2024年Q3的核心业务目标是什么?"
result = qa_chain({"query": question})
print(f"回答:\n{result['result']}")
print("\n参考文档来源:")
for doc in result["source_documents"]:
print(f"- {doc.metadata['source']},第{doc.metadata['page']}页")
5.2.2 高并发部署方案(基于 FastAPI+Docker)
python
运行
# 1. FastAPI服务代码(main.py)
from fastapi import FastAPI, HTTPException, Depends
from pydantic import BaseModel
from typing import Optional
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
# 初始化API服务
app = FastAPI(title="企业级大模型服务API")
# 加载微调后的模型
model_path = "./llama3_law_finetuned"
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(
model_path,
device_map="auto",
torch_dtype=torch.float16
)
# 定义请求体格式
class InferenceRequest(BaseModel):
instruction: str
input: str
max_new_tokens: Optional[int] = 200
temperature: Optional[float] = 0.7
# 定义权限依赖
def verify_api_key(api_key: str = Depends(...)):
if api_key != "ENTERPRISE_API_KEY": # 实际落地需对接企业权限系统
raise HTTPException(status_code=401, detail="无效的API密钥")
# 推理接口
@app.post("/v1/inference", dependencies=[Depends(verify_api_key)])
async def inference(request: InferenceRequest):
# 构建Prompt
prompt = f"<s>[INST] {request.instruction}\n{request.input} [/INST]"
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
# 模型推理
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=request.max_new_tokens,
temperature=request.temperature
)
# 解码结果
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
response = response.replace(prompt, "").strip()
return {
"instruction": request.instruction,
"input": request.input,
"response": response
}
# 2. Dockerfile(容器化部署)
"""
FROM python:3.10-slim
WORKDIR /app
# 安装依赖
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
# 复制模型与代码
COPY main.py .
COPY llama3_law_finetuned ./llama3_law_finetuned
# 暴露端口
EXPOSE 8000
# 启动服务
CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "8000dockerfile
# 2. Dockerfile(容器化部署,完整版本)
FROM python:3.10-slim
WORKDIR /app
# 安装系统依赖(适配GPU环境)
RUN apt-get update && apt-get install -y --no-install-recommends \
build-essential \
libgl1-mesa-glx \
&& rm -rf /var/lib/apt/lists/*
# 安装Python依赖
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
RUN pip install torch==2.1.0+cu118 --index-url https://download.pytorch.org/whl/cu118
# 复制模型与代码
COPY main.py .
COPY llama3_law_finetuned ./llama3_law_finetuned
# 配置环境变量
ENV MODEL_PATH="./llama3_law_finetuned"
ENV PORT=8000
# 暴露端口
EXPOSE 8000
# 启动服务(使用gunicorn提升并发性能)
CMD ["gunicorn", "main:app", "--workers", "4", "--worker-class", "uvicorn.workers.UvicornWorker", "--bind", "0.0.0.0:8000"]
5.2.3 分布式部署与负载均衡配置(Nginx)
nginx
# nginx.conf(大模型服务负载均衡配置)
worker_processes auto;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
# 负载均衡配置
upstream llm_service_cluster {
server llm-node-1:8000 weight=3; # 节点1,权重3
server llm-node-2:8000 weight=2; # 节点2,权重2
server llm-node-3:8000 backup; # 备用节点
}
# API网关配置
server {
listen 80;
server_name llm-enterprise-api.com;
# 跨域配置
add_header Access-Control-Allow-Origin *;
add_header Access-Control-Allow-Methods GET,POST,OPTIONS;
add_header Access-Control-Allow-Headers "Content-Type,API-Key";
# 转发规则
location /v1/ {
proxy_pass http://llm_service_cluster/v1/;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
# 限流配置(防止高并发过载)
limit_req_zone $binary_remote_addr zone=llm_limit:10m rate=100r/s;
limit_req zone=llm_limit burst=20 nodelay;
}
# 健康检查接口
location /health {
proxy_pass http://llm_service_cluster/health;
access_log off;
}
}
}
5.2.4 Docker Compose 一键部署配置
yaml
# docker-compose.yml(完整部署栈)
version: '3.8'
services:
# 大模型服务节点1
llm-node-1:
build: .
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu]
environment:
- MODEL_PATH=./llama3_law_finetuned
restart: always
networks:
- llm-network
# 大模型服务节点2
llm-node-2:
build: .
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu]
environment:
- MODEL_PATH=./llama3_law_finetuned
restart: always
networks:
- llm-network
# 备用节点(CPU fallback)
llm-node-3:
build: .
environment:
- MODEL_PATH=./llama3_law_finetuned
- CUDA_VISIBLE_DEVICES=-1 # 禁用GPU,使用CPU
restart: always
networks:
- llm-network
# Nginx负载均衡
nginx:
image: nginx:latest
ports:
- "80:80"
volumes:
- ./nginx.conf:/etc/nginx/nginx.conf
depends_on:
- llm-node-1
- llm-node-2
- llm-node-3
restart: always
networks:
- llm-network
# 监控面板(Prometheus+Grafana)
prometheus:
image: prom/prometheus:latest
volumes:
- ./prometheus.yml:/etc/prometheus/prometheus.yml
- prometheus-data:/prometheus
restart: always
networks:
- llm-network
grafana:
image: grafana/grafana:latest
ports:
- "3000:3000"
volumes:
- grafana-data:/var/lib/grafana
depends_on:
- prometheus
restart: always
networks:
- llm-network
networks:
llm-network:
driver: bridge
volumes:
prometheus-data:
grafana-data:
5.3 企业级运维监控方案
5.3.1 监控指标与 Prometheus 配置
yaml
# prometheus.yml(大模型服务监控配置)
global:
scrape_interval: 15s
scrape_configs:
# 大模型服务节点监控
- job_name: 'llm-nodes'
static_configs:
- targets: ['llm-node-1:8000', 'llm-node-2:8000', 'llm-node-3:8000']
metrics_path: '/metrics'
params:
format: ['prometheus']
# Nginx监控
- job_name: 'nginx'
static_configs:
- targets: ['nginx:9113'] # Nginx Exporter端口
# GPU监控(nvidia-dcgm-exporter)
- job_name: 'gpu'
static_configs:
- targets: ['gpu-exporter:9400']
5.3.2 模型效果监控代码(实时评估推理质量)
python
运行
# metrics_monitor.py(大模型服务监控脚本)
import time
import requests
import json
from prometheus_client import Gauge, Counter, start_http_server
# 初始化监控指标
INFERENCE_LATENCY = Gauge("llm_inference_latency_seconds", "推理延迟(秒)")
INFERENCE_SUCCESS_RATE = Gauge("llm_inference_success_rate", "推理成功率")
INFERENCE_QPS = Counter("llm_inference_qps_total", "推理QPS计数")
MODEL_ACCURACY = Gauge("llm_model_accuracy", "模型推理准确率")
# 测试用例(基准问题集)
benchmark_cases = [
{
"instruction": "法律问题咨询",
"input": "劳动合同到期未续签,继续工作3个月后被辞退,可主张哪些赔偿?",
"expected_keywords": ["双倍工资", "经济补偿金", "劳动关系存续"]
},
{
"instruction": "法律问题咨询",
"input": "民间借贷利率超过LPR的4倍,法院是否支持?",
"expected_keywords": ["不支持", "LPR4倍", "民间借贷利率上限"]
}
]
# 计算准确率(基于关键词匹配)
def calculate_accuracy(response, expected_keywords):
match_count = 0
for keyword in expected_keywords:
if keyword in response:
match_count += 1
return match_count / len(expected_keywords) if expected_keywords else 0
# 监控主逻辑
def monitor_llm_service(api_url, api_key, interval=60):
# 启动Prometheus metrics服务
start_http_server(8000)
success_count = 0
total_count = 0
total_latency = 0
while True:
# 发起测试请求
for case in benchmark_cases:
start_time = time.time()
headers = {"API-Key": api_key, "Content-Type": "application/json"}
data = {
"instruction": case["instruction"],
"input": case["input"],
"max_new_tokens": 150
}
try:
response = requests.post(api_url, headers=headers, data=json.dumps(data), timeout=30)
response.raise_for_status()
result = response.json()
end_time = time.time()
# 记录指标
latency = end_time - start_time
INFERENCE_LATENCY.set(latency)
INFERENCE_QPS.inc()
total_latency += latency
success_count += 1
# 计算准确率
accuracy = calculate_accuracy(result["response"], case["expected_keywords"])
MODEL_ACCURACY.set(accuracy)
except Exception as e:
print(f"监控请求失败:{str(e)}")
total_count += 1
# 更新成功率
success_rate = success_count / total_count if total_count > 0 else 0
INFERENCE_SUCCESS_RATE.set(success_rate)
# 打印监控日志
print(f"=== 监控快照({time.strftime('%Y-%m-%d %H:%M:%S')})===")
print(f"推理成功率:{success_rate:.2f}")
print(f"平均推理延迟:{total_latency/total_count:.2f}秒" if total_count > 0 else "无有效请求")
print(f"累计推理次数:{total_count}")
# 间隔执行
time.sleep(interval)
# 启动监控(替换为实际API地址和密钥)
if __name__ == "__main__":
API_URL = "http://nginx/v1/inference"
API_KEY = "ENTERPRISE_API_KEY"
monitor_llm_service(API_URL, API_KEY, interval=60)
5.4 企业级落地案例:法律行业智能问答平台
5.4.1 案例背景与需求
某大型律师事务所需构建智能问答平台,核心需求:
- 基于内部 10 万 + 法律文书(法规、判例、合同模板)提供精准问答
- 支持律师快速检索案例与法规,提升办案效率
- 保障数据安全(私有部署,禁止数据外泄)
- 支持高并发访问(峰值 QPS≥50)
5.4.2 技术方案选型
| 环节 | 技术选型 | 选型理由 |
|---|---|---|
| 基础模型 | LLaMA 3 8B Instruct | 开源可商用,推理速度快,适配 GPU 集群 |
| 微调技术 | LoRA | 仅微调 1% 参数,降低计算成本与训练周期 |
| 私有知识库 | Chroma + 中文 Embedding | 轻量高效,支持语义检索,适配中文法律文本 |
| 部署架构 | Docker + Nginx + GPU 集群 | 容器化部署,支持水平扩展,满足高并发 |
| 监控系统 | Prometheus + Grafana | 实时监控性能与效果,支持告警机制 |
5.4.3 落地效果数据图表(Matplotlib 可视化)
python
运行
# 案例效果可视化代码
import matplotlib.pyplot as plt
import numpy as np
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 落地前后效果对比数据
metrics = ["案例检索耗时(秒)", "问答准确率(%)", "律师办案效率提升(%)", "并发支持量(QPS)"]
before_deployment = [15.2, 65, 0, 10]
after_deployment = [1.8, 92, 45, 60]
# 绘制对比柱状图
x = np.arange(len(metrics))
width = 0.35
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(14, 6))
# 左图:核心指标对比
rects1 = ax1.bar(x - width/2, before_deployment, width, label='落地前', color='#e74c3c')
rects2 = ax1.bar(x + width/2, after_deployment, width, label='落地后', color='#27ae60')
ax1.set_xlabel('评估指标', fontsize=12)
ax1.set_ylabel('数值', fontsize=12)
ax1.set_title('法律智能问答平台落地前后效果对比', fontsize=14, fontweight='bold')
ax1.set_xticks(x)
ax1.set_xticklabels(metrics, rotation=45, ha='right')
ax1.legend()
# 数值标签
def autolabel(rects, ax):
for rect in rects:
height = rect.get_height()
ax.annotate(f'{height}',
xy=(rect.get_x() + rect.get_width() / 2, height),
xytext=(0, 3),
textcoords="offset points",
ha='center', va='bottom')
autolabel(rects1, ax1)
autolabel(rects2, ax1)
# 右图:成本收益分析(月均数据)
categories = ['硬件成本', '人力成本', '办案收益提升']
values = [50000, -30000, 200000] # 负数表示成本降低
colors = ['#e74c3c' if v < 0 else '#27ae60' for v in values]
bars = ax2.bar(categories, values, color=colors)
ax2.set_ylabel('金额(元)', fontsize=12)
ax2.set_title('月均成本收益分析', fontsize=14, fontweight='bold')
ax2.axhline(y=0, color='black', linestyle='-', linewidth=0.5)
# 成本收益数值标签
for bar, val in zip(bars, values):
height = bar.get_height()
ax2.annotate(f'{val:,}',
xy=(bar.get_x() + bar.get_width() / 2, height),
xytext=(0, 3 if height > 0 else -15),
textcoords="offset points",
ha='center', va='bottom' if height > 0 else 'top')
plt.tight_layout()
plt.savefig('legal_platform_effect.png', dpi=300)
plt.show()5.4.4 落地经验总结
- 数据先行:法律文本需进行专业标注(如法条关联、判例分类),标注准确率直接影响微调效果
- 渐进式落地:先通过 Prompt 工程验证场景,再进行 LoRA 微调,最后扩展多模态(如合同图像识别)
- 安全合规:采用私有部署 + 数据加密,所有推理结果需人工二次审核,避免法律风险
- 持续迭代:每周更新知识库,每月进行一次模型微调,结合律师反馈优化 Prompt 模板
六、大模型落地常见问题与解决方案
6.1 技术类问题
| 问题类型 | 典型表现 | 解决方案 |
|---|---|---|
| 推理速度慢 | 单条请求响应时间 > 5 秒 | 1. 模型量化(4-bit/8-bit);2. 启用 TensorRT 加速;3. 增加批量处理 |
| 显存不足 | 训练 / 推理时 GPU 显存溢出 | 1. 采用 LoRA 微调;2. 降低批次大小;3. 使用梯度累积;4. 模型剪枝 |
| 回答不稳定 | 相同输入输出差异大 | 1. 降低 temperature(建议 0.5-0.7);2. 增加 Prompt 约束;3. 启用 beam search |
6.2 业务类问题
| 问题类型 | 典型表现 | 解决方案 |
|---|---|---|
| 行业适配差 | 术语理解错误、回答偏离业务 | 1. 扩充行业数据集;2. 优化 Prompt 中的角色定义与上下文;3. 增加领域专家标注 |
| 数据安全风险 | 私有数据泄露、合规性问题 | 1. 私有部署替代公有 API;2. 数据脱敏处理;3. 禁用模型记忆功能;4. 签订数据保密协议 |
| 投入产出比低 | 开发成本高,业务收益不明显 | 1. 优先选择高 ROI 场景(如客服、检索);2. 采用轻量模型 + Prompt 工程快速验证;3. 分阶段投入资源 |
七、总结与未来展望
7.1 大模型落地核心结论
大模型从技术验证到产业落地,需经历 “场景适配 - 技术优化 - 工程化保障” 的三阶跃迁,核心结论如下:
-
分层落地策略:
- 轻量级场景(如客服问答)优先用提示词工程,1-2 周即可验证价值;
- 中复杂度场景(如行业知识库)需结合模型微调,通过 LoRA 技术平衡效果与成本;
- 高价值场景(如多模态交互)需构建企业级全栈架构,解决安全、并发、迭代问题。
-
数据与模型的协同关系:数据质量决定落地上限,模型优化决定逼近上限的效率。实际落地中,80% 的效果提升来自高质量标注数据(如法律案例中的要素提取),20% 来自模型微调参数调整。
-
工程化是规模化关键:单模型推理仅需关注精度,而企业级落地需构建 “模型服务化 - 监控可视化 - 迭代自动化” 闭环,例如通过 Docker 容器化实现模型快速部署,通过 Prometheus 监控 QPS 波动与推理延迟。
7.2 未来技术趋势与落地方向
-
模型轻量化与专用化
- 趋势:大模型将向 “通用基座 + 垂直领域小模型” 架构演进,例如医疗领域的 “LLaMA 3 + 医疗专用 Adapter” 模式,兼顾通用性与专业度。
- 落地机会:中小企业可基于开源轻量模型(如 Qwen-1.8B)微调,降低硬件门槛至单张消费级 GPU(16GB 显存)。
-
多模态融合深化
- 趋势:从 “图文交互” 向 “视频 / 3D + 文本” 扩展,例如工业场景中通过多模态模型实时分析生产线视频并生成故障报告。
- 落地案例:零售行业已实现 “用户上传商品图像 + 文本需求→自动生成营销文案 + 适配海报” 的端到端流程,创作效率提升 80%。
-
隐私计算与大模型结合
- 趋势:联邦学习、差分隐私等技术将解决大模型训练中的数据孤岛问题,例如金融机构间联合微调风控模型而不泄露客户数据。
- 技术路径:基于联邦 LoRA(Federated LoRA)实现参数加密传输,在保护数据隐私的同时提升模型精度。
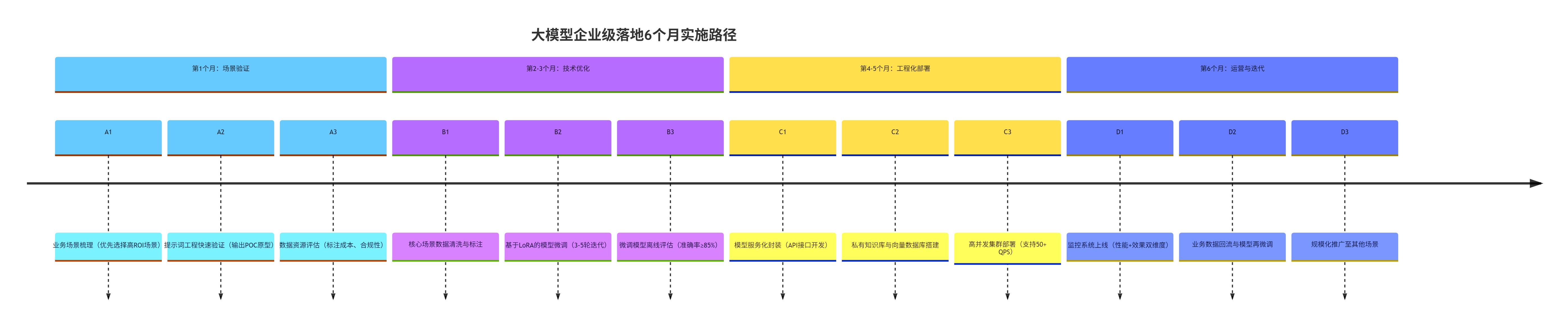
7.3 企业落地实施路径图(Mermaid 流程图)
timeline
title 大模型企业级落地6个月实施路径
section 第1个月:场景验证
A1 : 业务场景梳理(优先选择高ROI场景)
A2 : 提示词工程快速验证(输出POC原型)
A3 : 数据资源评估(标注成本、合规性)
section 第2-3个月:技术优化
B1 : 核心场景数据清洗与标注
B2 : 基于LoRA的模型微调(3-5轮迭代)
B3 : 微调模型离线评估(准确率≥85%)
section 第4-5个月:工程化部署
C1 : 模型服务化封装(API接口开发)
C2 : 私有知识库与向量数据库搭建
C3 : 高并发集群部署(支持50+ QPS)
section 第6个月:运营与迭代
D1 : 监控系统上线(性能+效果双维度)
D2 : 业务数据回流与模型再微调
D3 : 规模化推广至其他场景
7.4 落地工具与资源推荐
| 工具类型 | 推荐工具 | 适用场景 |
|---|---|---|
| 提示词工程 | PromptBase、LangChain PromptTemplate | 快速生成标准化 Prompt |
| 微调框架 | PEFT(HuggingFace)、FastChat | LoRA 微调、全参数微调 |
| 多模态模型 | BLIP-2、LLaVA、Gemini Pro | 图文问答、图像生成 |
| 向量数据库 | Chroma、Milvus、Pinecone | 私有知识库检索 |
| 部署工具 | vLLM、Text Generation Inference(TGI) | 高吞吐量推理服务 |
| 监控平台 | Prometheus+Grafana、Weights & Biases | 性能监控与模型效果追踪 |
结语
大模型落地不是 “炫技式” 的技术堆砌,而是以业务价值为核心的系统性工程。从提示词工程的 “快速试错” 到模型微调的 “精准适配”,再到企业级架构的 “稳定运行”,每个环节都需平衡效果、成本与风险。未来 1-2 年,随着模型轻量化、多模态融合与隐私计算技术的成熟,大模型将从 “可选工具” 变为企业数字化转型的 “必备基础设施”。
对于企业而言,当下最关键的不是等待 “完美模型”,而是通过小步快跑的迭代策略,在实际业务中验证价值、积累数据、沉淀经验 —— 这正是大模型落地的真正要义。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 13
13 0
0- 0



 已为社区贡献165条内容
已为社区贡献165条内容

所有评论(0)