突破AI视频一致性瓶颈:“无废话”四步电影级工作流
AI视频生成技术仍面临"场景一致性"瓶颈,无法直接取代影视制作。资深创作者JeffSu提出了一套四步专业工作流:首先用图像工具创建静态角色锚点;其次通过精确参考技术将角色融入场景;然后使用文生视频工具生成动画;最后用语音合成统一角色声音。该流程揭示了AI内容制作的核心矛盾:单个工具无法解决连贯性问题,必须通过多工具协同工作。即使Sora2等新技术出现,专业工作流仍是制作高质量A
引言/导读
在AI技术飞速发展的浪潮中,关于“AI将在几分钟内取代好莱坞”的头条新闻层出不穷。然而,资深科技创作者Jeff Su一针见血地指出:抛开那些旨在最大化股东价值的华丽演示,当前的AI视频生成能力远未达到取代影视行业的水平。目前,AI视频领域面临的“场景一致性”(Consistency)瓶颈,是阻碍其产出高质量、连贯性内容的最大障碍。
本文将深入剖析Jeff Su分享的“无废话”实战指南,揭示如何通过一套多工具、多步骤的专业工作流程,克服角色外观、背景环境和声音在不同场景中不一致的问题。对于寻求将AI视频生成从演示推向实战的开发者、产品经理和内容创作者而言,这套流程提供了超越单个AI工具限制的深度解决方案。
一、AI视频制作的残酷现实:一致性是“单核”痛点
AI视频模型无疑拥有令人难以置信的强大功能。例如,使用Google Flow应用可以快速生成一段细节丰富、配音逼真的达斯·维德(Darth Vader)短片。然而,当你试图像在ChatGPT中要求续写场景那样,让AI模型延续视频故事时,问题就出现了。
1.1 续写场景时的“失忆症”
核心问题在于,目前的视频模型无法“记住”它们刚刚生成的场景的任何细节。当尝试延续达斯·维德的场景时,即使使用完全相同的提示词,结果也可能令人失望:
- 光剑位置错误或消失。
- 角色外形在不同场景间发生细微变化,破坏了视觉连贯性。
- 背景环境和角色声音完全改变。
这种“角色不一致性”正是阻碍AI视频制作迈向好莱坞级别的核心障碍。要实现像在Chatbot中保持叙事连贯性那样的视频连贯性,必须引入一套外部的、精细化的流程。
1.2 警惕“一体化”工具的局限性
市场上存在声称提供“一体化解决方案”的AI视频工具(如Open Art、Hyalura和Cling)。虽然这些工具能简化生成过程,但若想制作出精良的、可用于商业用途的视频,仍然需要大量的手动工作,比如生成初始角色和修复音频。AI视频工具只是工具,掌握关键在于了解每个工具的优势,并将其整合到高效的工作流中。
二、Jeff Su的四步多工具一致性工作流实战
要实现角色在外观和声音上的高度一致性(Consistency),Jeff Su提出了一套四步工作流。该流程整合了图像生成、精确参考、文生视频和语音合成等多个环节。
2.1 第一步:生成固定角色形象(静态图像锚定)
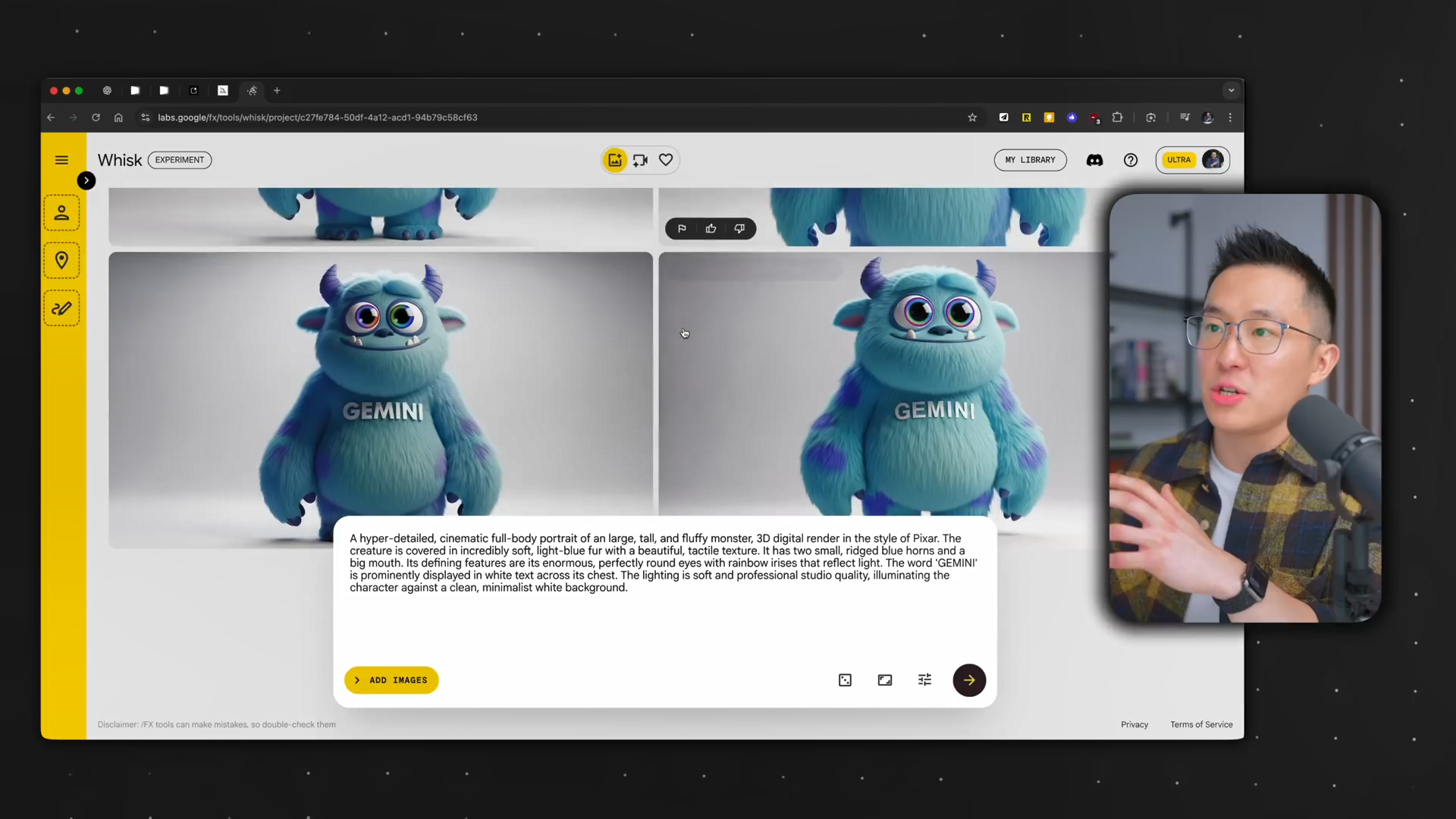
视频制作的第一步反而是使用图像生成工具(如Midjourney或Google Whisk)创建一个静态图像作为角色的“锚点”。
- 初始创作阶段:应暂时禁用“精确参考”(Precise Reference)功能,给予AI最大的创作自由度,生成满意的初始形象。
- 形象优化阶段:如果需要对角色进行微调(例如,改变毛发的颜色),则应启用精确参考。这是因为该技术(在Google Whisk中,它使用的是nano banana模型)擅长在保留角色主体特征的同时,进行指定细节的修改,从而维持静止图像中的角色一致性。
- 角色选择技巧:选择一个正面、完整的角色形象图,这有助于后续步骤的顺利进行。
2.2 第二步:创建场景起始帧(精确参考的应用)
在有了固定角色形象后,下一步是将其放入具体的场景中,生成视频的起始帧。
- 图像锚定:将第一步生成的角色图像拖拽或上传到图像生成工具的“角色框”中,明确告诉AI:“我需要让这个精确的角色出现在接下来的场景中”。
- 启用精确参考:必须确保启用精确参考功能,这能保证在不同的场景提示词下,角色形象不会发生变化。
- 重要性展示:如果禁用精确参考或不指定参考图像,AI将从头开始创建角色,导致同一批次内的角色外观都可能不一致,甚至面部特征出现错乱。
- 多角色一致性:如果需要创建两个或更多一致性角色,只需将多个角色图像上传到Whisk中作为参考,原理相同。
2.3 第三步:将帧转化为视频片段(文生视频与提示词优化)
在获得了视觉一致的起始帧后,接下来使用帧转视频(Frame-to-Video)模型(如Google Flow V3)来生成动画片段。
- 模型选择:虽然Flow V3模型是付费版本,但其免费版本(V3 Fast)也同样适用该工作流。
- 操作模式:选择“帧转视频”(Frame-to-Video)选项,上传起始帧,并输入详细的文生视频提示词(Text-to-Video Prompt),描述场景的对话和动作。
- 效率策略:为了提高可用片段的产出率,建议一次生成多个输出(例如四份),因为并非所有AI生成的视频都能用。
- Prompt工程优化:为确保提示词效果最大化,可以使用定制化的AI辅助工具(如定制的Gemini Gem)。通过上传起始帧图像和场景脚本,让AI根据Google VO模型(Flow V3底层模型)的最佳实践,生成详细且优化的提示词。
2.4 第四步:实现声音一致性(语音合成与手动编辑)
在第三步中,角色形象实现了视觉一致,但Flow生成的不同视频片段中的角色配音仍可能不同。因此,最后一步是统一角色声音。
- 使用Eleven Labs:利用语音合成工具(如Eleven Labs)的“语音变声器”(Voice Changer)功能。
- 统一选择:将Flow生成的视频上传到Eleven Labs,并为角色选择一个固定的声音模板(例如,视频中使用的“怪兽”声音)。
- 跨场景重复:对所有场景视频重复此过程。关键是确保在所有场景中,都使用完全相同的声音模板,从而保证角色声音的一致性。
- 视频剪辑与替换:将原始的(音频不一致的)视频片段和新的(统一音频的)音频文件导入视频编辑软件(如Final Cut Pro)。
- 手动精修:手动分离原始音频,然后只用新的、统一的“怪兽”声音替换AI角色的台词部分。这样可以保留场景中人类角色的原始配音,同时确保AI吉祥物的声音在整个短片中保持一致,并通过添加环境音效来增强场景的真实感。
三、深度分析与深刻洞察
Jeff Su的这套工作流不仅仅是一个操作指南,它揭示了当前AI内容制作领域最深层的两个结构性矛盾:“工具”与“工作流”的矛盾,以及“演示”与“生产”的矛盾。
3.1 矛盾一:AI工作流的“非原子性”
该工作流最大的特点是非原子性,即无法用一个工具或一个提示词完成所有任务。为了制作一个高质量的多场景短片,我们必须组合使用至少六种独立的工具或技术:Google Whisk(两次)、定制的Gemini Gem、Google Flow、Eleven Labs和视频编辑软件(如Final Cut Pro)。
这一现实说明,尽管AI模型(如Flow V3)在单次生成中表现强大,但它们在跨时间、跨情境的上下文记忆上仍存在根本性缺陷。因此,提示工程(Prompt Engineering)的边界正在扩展:它不仅是撰写描述文本,更包括在工作流中精确地嵌入和切换不同工具,利用每个工具的专业化能力(如Whisk的精确参考、Eleven Labs的语音克隆)来弥补模型在连贯性上的不足。
3.2 矛盾二:Sora 2时代下的工作流永存
OpenAI发布的Sora 2引入了针对一致性的新功能,例如Cameo和Recut。
- Cameo:使用真实人物的面部和声音记录,保持一致性,但其限制在于只适用于真人和宠物,无法用于生成视频中的AI吉祥物或虚构角色。
- Recut:允许用户将上一段视频的最后几秒加载到下一个提示词中,以维持场景连续性。如果这一功能有效,将是向前迈出的重要一步。
然而,Jeff Su的观点是,这些功能是“特性”(features),而非“解决方案”(workflow)的替代品。即使有了Recut,用户仍需负责:生成固定角色、撰写强大的视频提示词、修复音频等多个环节。
深刻洞察:AI视频的未来发展趋势并非是“一键成片”,而是高度模块化和集成化。顶级的AI内容创作者将是那些能够熟练掌握各种专业化AI工具,并像经验丰富的电影剪辑师一样,将这些工具的优势在多步骤的工作流中高效整合的人。AI正在降低创意门槛,但它也提升了对流程设计和工具组合策略的要求。
四、总结与展望
Jeff Su的“无废话指南”为AI视频生成领域带来了急需的务实主义。它明确指出,要制作出具有专业水准、视觉和听觉高度一致的多场景AI视频,核心不在于单个AI模型的强大,而在于建立一套严谨、多工具协作的工作流。
这套流程的精髓在于通过“静态图像锚定”和“精确参考”技术锁定角色形象,并通过语音合成工具消除跨场景的音频差异。它将AI视频制作从单一的“文生视频”任务,转化为了一个复杂的**“图像锚定+提示工程+帧转视频+音频后期”**的集成系统。
展望:随着AI模型持续迭代,对“一致性”的内在记忆能力必然会增强。但在此之前,以及在面向高度定制化的角色和叙事需求时,对专业工作流的掌握,将是区分普通爱好者和专业内容创作者的关键能力。
那么,在不断涌现的新工具和新功能面前,我们应该追求的是“单键生成”的幻想,还是掌握“工具箱”并设计高效流程的实战能力?答案不言自明。
要点摘要
- 核心瓶颈:当前AI视频最大的障碍是场景一致性(Consistency),即角色外观、背景和声音在不同片段中难以保持连贯。
- 工作流至上:不要相信“一键取代好莱坞”的炒作。高质量AI视频产出的关键在于使用多个工具构建的四步专业工作流。
- 静态锚定:工作流始于使用图像生成工具创建静态角色图像,作为后续视频生成的视觉参考。
- 精确参考:**精确参考(Precise Reference)**是视觉一致性的核心技术,必须在生成起始帧时启用,以保证角色形象在场景中被精确复制。
- 音频修复:视频生成后,需使用Eleven Labs等专业工具统一角色声音,并通过视频编辑软件手动替换仅限角色本身的台词音频,以解决声音不一致问题。
- Sora 2的定位:Sora 2的Cameo和Recut是强大的功能,但它们仍是工作流中的组件,无法取代整个多步骤、多工具的制作流程。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 3
3 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)