自家电脑能跑大模型吗?LLM 本地部署指南
摘要 本地部署大型语言模型(LLM)需要合理规划硬件配置和搭建软件环境。硬件方面,不同规模模型对应不同需求:1B-3B模型需8GB内存,7B需32GB内存和RTX 3060显卡,70B+模型则需要128GB内存和专业级GPU。文中提供了硬件需求表和优化策略,包括量化技术和内存管理。软件环境搭建需要完整的工具链支持,包括PyTorch框架、CUDA驱动、量化组件和交互界面库。通过合理的硬件配置和软件
·
硬件要求与配置规划
基础硬件配置分析
本地部署LLM的首要挑战是硬件资源需求。不同规模的模型对硬件的要求差异显著,合理的配置选择是成功部署的关键。
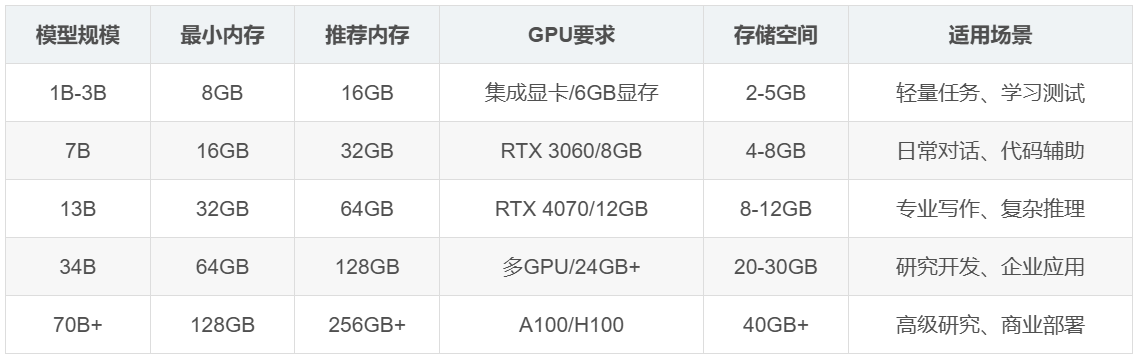
详细硬件需求表
| 模型规模 | 最小内存 | 推荐内存 | GPU要求 | 存储空间 | 适用场景 |
|---|---|---|---|---|---|
| 1B-3B | 8GB | 16GB | 集成显卡/6GB显存 | 2-5GB | 轻量任务、学习测试 |
| 7B | 16GB | 32GB | RTX 3060/8GB | 4-8GB | 日常对话、代码辅助 |
| 13B | 32GB | 64GB | RTX 4070/12GB | 8-12GB | 专业写作、复杂推理 |
| 34B | 64GB | 128GB | 多GPU/24GB+ | 20-30GB | 研究开发、企业应用 |
| 70B+ | 128GB | 256GB+ | A100/H100 | 40GB+ | 高级研究、商业部署 |
内存与显存优化策略
import psutil
import torch
import gc
class HardwareOptimizer:
def __init__(self):
self.available_ram = psutil.virtual_memory().available / (1024**3)
self.available_vram = self.get_available_vram()
def get_available_vram(self):
"""获取可用显存"""
if torch.cuda.is_available():
return torch.cuda.get_device_properties(0).total_memory / (1024**3)
return 0
def calculate_model_memory(self, model_size_in_billions, precision='int4'):
"""计算模型内存需求"""
# 不同精度下的内存系数
precision_factors = {
'fp32': 4.0,
'fp16': 2.0,
'int8': 1.0,
'int4': 0.5
}
base_memory_gb = model_size_in_billions * precision_factors[precision]
return base_memory_gb
def recommend_quantization(self, model_size):
"""推荐量化策略"""
required_memory_fp16 = self.calculate_model_memory(model_size, 'fp16')
if self.available_vram >= required_memory_fp16:
return 'fp16', 'gpu'
elif self.available_ram >= required_memory_fp16:
return 'fp16', 'cpu'
else:
# 需要量化
for precision in ['int8', 'int4']:
required = self.calculate_model_memory(model_size, precision)
if self.available_ram >= required:
return precision, 'cpu'
return None, None # 硬件不足
def optimize_loading(self, model_path, model_class):
"""优化模型加载策略"""
config = model_class.config_class.from_pretrained(model_path)
# 根据可用内存选择加载方式
if self.available_vram > 0:
return model_class.from_pretrained(
model_path,
torch_dtype=torch.float16,
device_map="auto",
low_cpu_mem_usage=True
)
else:
# CPU-only加载
return model_class.from_pretrained(
model_path,
torch_dtype=torch.float32,
device_map=None,
low_cpu_mem_usage=True
)
软件环境搭建
开发环境配置
本地部署LLM需要完整的软件栈支持,从底层驱动到上层应用框架。
# requirements.txt - 核心依赖包
"""
torch>=2.0.0
transformers>=4.30.0
accelerate>=0.20.0
bitsandbytes>=0.39.0
sentencepiece>=0.1.99
protobuf>=3.20.0
gradio>=3.35.0
"""
class EnvironmentSetup:
def __init__(self):
self.required_packages = {
'基础框架': ['torch', 'transformers', 'accelerate'],
'量化支持': ['bitsandbytes', 'sentencepiece'],
'界面开发': ['gradio', 'streamlit'],
'工具库': ['numpy', 'pandas', 'tqdm']
}
def check_cuda_support(self):
"""检查CUDA支持"""
cuda_available = torch.cuda.is_available()
if cuda_available:
cuda_version = torch.version.cuda
gpu_name = torch.cuda.get_device_name(0)
return {
'available': True,
'cuda_version': cuda_version,
'gpu_name': gpu_name
}
return {'available': False}
def setup_environment(self, use_gpu=True):
"""设置运行环境"""
env_info = {}
# 检查GPU
if use_gpu:
gpu_info = self.check_cuda_support()
env_info['gpu'] = gpu_info
# 检查内存
memory_info = psutil.virtual_memory()
env_info['memory'] = {
'total_gb': memory_info.total / (1024**3),
'available_gb': memory_info.available / (1024**3)
}
# 检查存储
disk_info = psutil.disk_usage('/')
env_info['storage'] = {
'total_gb': disk_info.total / (1024**3),
'free_gb': disk_info.free / (1024**3)
}
return env_info
def install_dependencies(self):
"""安装依赖包"""
import subprocess
import sys
for category, packages in self.required_packages.items():
print(f"安装{category}包...")
for package in packages:
try:
subprocess.check_call([
sys.executable, "-m", "pip", "install", package
])
print(f"✓ {package} 安装成功")
except subprocess.CalledProcessError:
print(f"✗ {package} 安装失败")
模型选择与下载
适合本地部署的模型推荐
并非所有LLM都适合本地部署,需要考虑模型大小、性能、许可证等多个因素。
class ModelSelector:
def __init__(self):
self.recommended_models = {
'轻量级': [
{
'name': 'Qwen-1.8B',
'size': '1.8B',
'ram_required': 4,
'vram_required': 2,
'license': 'Apache 2.0',
'huggingface_url': 'Qwen/Qwen-1_8B-Chat'
},
{
'name': 'Phi-2',
'size': '2.7B',
'ram_required': 6,
'vram_required': 3,
'license': 'MIT',
'huggingface_url': 'microsoft/phi-2'
}
],
'平衡型': [
{
'name': 'Llama-2-7B',
'size': '7B',
'ram_required': 14,
'vram_required': 8,
'license': 'Custom',
'huggingface_url': 'meta-llama/Llama-2-7b-chat-hf'
},
{
'name': 'Qwen-7B',
'size': '7B',
'ram_required': 14,
'vram_required': 8,
'license': 'Apache 2.0',
'huggingface_url': 'Qwen/Qwen-7B-Chat'
}
],
'高性能': [
{
'name': 'Llama-2-13B',
'size': '13B',
'ram_required': 26,
'vram_required': 14,
'license': 'Custom',
'huggingface_url': 'meta-llama/Llama-2-13b-chat-hf'
}
]
}
def select_model(self, hardware_constraints, use_case):
"""根据约束选择模型"""
suitable_models = []
for category, models in self.recommended_models.items():
for model in models:
if (model['ram_required'] <= hardware_constraints['ram'] and
model['vram_required'] <= hardware_constraints['vram']):
suitable_models.append(model)
# 根据用例排序
if use_case == 'chat':
suitable_models.sort(key=lambda x: x['size'])
elif use_case == 'coding':
suitable_models.sort(key=lambda x: x['size'], reverse=True)
return suitable_models[:3] # 返回前3个推荐
def download_model(self, model_info, save_path):
"""下载模型"""
from transformers import AutoTokenizer, AutoModelForCausalLM
print(f"开始下载模型: {model_info['name']}")
try:
tokenizer = AutoTokenizer.from_pretrained(
model_info['huggingface_url'],
trust_remote_code=True
)
model = AutoModelForCausalLM.from_pretrained(
model_info['huggingface_url'],
trust_remote_code=True,
torch_dtype=torch.float16,
device_map="auto" if torch.cuda.is_available() else None
)
# 保存到本地
model.save_pretrained(save_path)
tokenizer.save_pretrained(save_path)
print(f"模型已保存到: {save_path}")
return True
except Exception as e:
print(f"下载失败: {e}")
return False
部署实战:完整示例
基础部署流程
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
from threading import Thread, Lock
import queue
class LocalLLM:
def __init__(self, model_path, model_name):
self.model_path = model_path
self.model_name = model_name
self.model = None
self.tokenizer = None
self.is_loaded = False
self.lock = Lock()
def load_model(self, quantize=False):
"""加载模型"""
print(f"正在加载模型: {self.model_name}")
try:
# 加载tokenizer
self.tokenizer = AutoTokenizer.from_pretrained(
self.model_path,
trust_remote_code=True
)
# 配置加载参数
load_kwargs = {
'torch_dtype': torch.float16,
'device_map': 'auto',
'trust_remote_code': True,
'low_cpu_mem_usage': True
}
if quantize:
load_kwargs.update({
'load_in_8bit': True,
'llm_int8_enable_fp32_cpu_offload': True
})
# 加载模型
self.model = AutoModelForCausalLM.from_pretrained(
self.model_path,
**load_kwargs
)
self.is_loaded = True
print("模型加载完成")
except Exception as e:
print(f"模型加载失败: {e}")
self.is_loaded = False
def generate_response(self, prompt, max_length=512, temperature=0.7):
"""生成回复"""
if not self.is_loaded:
return "错误: 模型未加载"
with self.lock:
try:
# 编码输入
inputs = self.tokenizer.encode(prompt, return_tensors="pt")
# 生成参数
generation_config = {
'max_length': max_length,
'temperature': temperature,
'do_sample': True,
'top_p': 0.9,
'pad_token_id': self.tokenizer.eos_token_id
}
# 生成文本
with torch.no_grad():
outputs = self.model.generate(
inputs,
**generation_config
)
# 解码输出
response = self.tokenizer.decode(
outputs[0],
skip_special_tokens=True
)
# 提取新生成的部分
response = response[len(prompt):].strip()
return response
except Exception as e:
return f"生成失败: {e}"
def chat_loop(self):
"""交互式聊天循环"""
if not self.is_loaded:
print("请先加载模型")
return
print("聊天模式已启动,输入 'quit' 退出")
while True:
try:
user_input = input("\n用户: ").strip()
if user_input.lower() in ['quit', 'exit', '退出']:
break
if not user_input:
continue
print("AI: ", end="", flush=True)
response = self.generate_response(user_input)
print(response)
except KeyboardInterrupt:
print("\n\n聊天结束")
break
except Exception as e:
print(f"\n错误: {e}")
Web界面部署
import gradio as gr
import time
class WebInterface:
def __init__(self, llm_instance):
self.llm = llm_instance
self.chat_history = []
def predict(self, message, history):
"""处理用户输入并生成回复"""
# 构建对话上下文
context = self.build_context(history, message)
# 生成回复
start_time = time.time()
response = self.llm.generate_response(context)
end_time = time.time()
# 记录性能信息
generation_time = end_time - start_time
performance_info = f"\n\n[生成时间: {generation_time:.2f}秒]"
return response + performance_info
def build_context(self, history, new_message):
"""构建对话上下文"""
context = ""
# 添加历史对话
for user_msg, bot_msg in history:
context += f"用户: {user_msg}\n助手: {bot_msg}\n"
# 添加新消息
context += f"用户: {new_message}\n助手: "
return context
def launch_interface(self, share=False):
"""启动Web界面"""
with gr.Blocks(title="本地LLM聊天助手", theme=gr.themes.Soft()) as demo:
gr.Markdown("# 🚀 本地LLM聊天助手")
gr.Markdown("在您的电脑上运行的AI助手,完全离线,保护隐私")
with gr.Row():
with gr.Column(scale=4):
chatbot = gr.Chatbot(
label="对话记录",
height=500,
show_copy_button=True
)
with gr.Row():
msg = gr.Textbox(
label="输入消息",
placeholder="在这里输入您的问题...",
scale=4
)
submit_btn = gr.Button("发送", variant="primary", scale=1)
with gr.Row():
clear_btn = gr.Button("清空对话")
export_btn = gr.Button("导出对话")
with gr.Column(scale=1):
gr.Markdown("### 参数设置")
max_length = gr.Slider(
minimum=64, maximum=1024, value=512,
label="生成长度"
)
temperature = gr.Slider(
minimum=0.1, maximum=1.0, value=0.7,
label="创造性"
)
gr.Markdown("### 系统信息")
status = gr.Textbox(
label="状态",
value="就绪",
interactive=False
)
# 事件处理
submit_event = msg.submit(
self.predict,
[msg, chatbot],
chatbot
).then(lambda: "", None, msg)
submit_btn.click(
self.predict,
[msg, chatbot],
chatbot
).then(lambda: "", None, msg)
clear_btn.click(lambda: None, None, chatbot, queue=False)
demo.launch(
server_name="0.0.0.0",
server_port=7860,
share=share,
inbrowser=True
)
性能优化技巧
内存与速度优化
class PerformanceOptimizer:
def __init__(self, model, tokenizer):
self.model = model
self.tokenizer = tokenizer
def apply_8bit_quantization(self):
"""应用8位量化"""
from transformers import BitsAndBytesConfig
quantization_config = BitsAndBytesConfig(
load_in_8bit=True,
llm_int8_threshold=6.0,
llm_int8_has_fp16_weight=False,
)
self.model = self.model.from_pretrained(
self.model.config.name_or_path,
quantization_config=quantization_config,
device_map="auto"
)
return self.model
def apply_4bit_quantization(self):
"""应用4位量化"""
from transformers import BitsAndBytesConfig
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.float16
)
self.model = self.model.from_pretrained(
self.model.config.name_or_path,
quantization_config=quantization_config,
device_map="auto"
)
return self.model
def optimize_inference(self):
"""优化推理性能"""
# 启用评估模式
self.model.eval()
# 启用CUDA图(如果可用)
if torch.cuda.is_available():
torch.backends.cudnn.benchmark = True
# 编译模型(PyTorch 2.0+)
if hasattr(torch, 'compile'):
self.model = torch.compile(self.model, mode="reduce-overhead")
return self.model
def memory_cleanup(self):
"""内存清理"""
if torch.cuda.is_available():
torch.cuda.empty_cache()
torch.cuda.synchronize()
gc.collect()
应用场景与实践案例
个人知识库助手
class PersonalKnowledgeAssistant:
def __init__(self, llm_instance, knowledge_base_path):
self.llm = llm_instance
self.knowledge_base = self.load_knowledge_base(knowledge_base_path)
def load_knowledge_base(self, path):
"""加载个人知识库"""
# 支持多种格式:txt, md, pdf等
knowledge_items = []
for file_path in Path(path).glob("**/*"):
if file_path.suffix in ['.txt', '.md']:
content = file_path.read_text(encoding='utf-8')
knowledge_items.append({
'source': file_path.name,
'content': content[:1000] # 限制长度
})
return knowledge_items
def search_knowledge(self, query, top_k=3):
"""在知识库中搜索相关内容"""
# 简单的基于关键词的搜索
relevant_items = []
for item in self.knowledge_base:
if query.lower() in item['content'].lower():
relevant_items.append(item)
return relevant_items[:top_k]
def answer_with_context(self, question):
"""基于知识库回答问题"""
# 搜索相关知识
context_items = self.search_knowledge(question)
if not context_items:
return self.llm.generate_response(question)
# 构建上下文丰富的提示
context = "\n".join([
f"来自 {item['source']}:\n{item['content']}"
for item in context_items
])
prompt = f"""基于以下信息回答问题:
{context}
问题:{question}
答案:"""
return self.llm.generate_response(prompt)
故障排除与维护
常见问题解决方案
| 问题类型 | 症状 | 解决方案 | 预防措施 |
|---|---|---|---|
| 内存不足 | 程序崩溃、响应缓慢 | 使用量化、增加虚拟内存 | 选择合适模型、监控内存使用 |
| 显存溢出 | CUDA out of memory | 降低批次大小、使用CPU卸载 | 优化模型加载、使用梯度检查点 |
| 加载失败 | 模型文件损坏 | 重新下载、检查文件完整性 | 验证文件哈希、使用可靠源 |
| 响应质量差 | 输出无意义 | 调整温度参数、检查提示工程 | 选择高质量模型、微调参数 |

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 23
23 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)