【必学收藏】LangGraph智能体设计模式完全指南:从零构建大模型应用
LangGraph提供了基于图的框架来定义、可视化和调试LLM智能体工作流。文章详细介绍了六种智能体设计模式:提示链将复杂任务分解为步骤;路由与并行化高效处理查询;反思使智能体能自我评估改进;工具使用集成外部API;规划构建可执行序列;多智能体协作协调专业智能体解决复杂问题。每种模式都配有代码示例,帮助开发者构建稳健、灵活且可扩展的AI系统。
前言

Thumbnail
在过去几年构建人工智能(AI)系统的过程中,笔者学到了一件事:模式至关重要。无论我们是在设计传统软件,还是在试验大型语言模型(LLM)智能体,我们组织工作流的方式都决定了它们的稳健性、灵活性和可扩展性。
LangGraph 提供了一个基于图的框架来定义、可视化和调试工作流,而不是用无休止的自定义逻辑将智能体连接在一起。
在本文中,我将引导你了解一些可以在 LangGraph 中实现的最常见的智能体设计模式。我不会深入探讨分步解释——这些内容已在上一篇文章中介绍过——但我会重点说明每种模式的重要性、我在实际系统中的思考方式,以及它们各自的适用场景。我还提供了代码示例,你可以在 Google Colab notebook 上动手实验。
内容摘要 (TL, DR):
构建 AI 智能体颇具挑战,因为该领域尚处早期,架构演进迅速。在本文中,我将展示如何使用 LangGraph 实现经过验证的智能体设计模式,使它们更加稳健并为生产环境做好准备,具体包括:
- • 提示链 (Prompt Chaining) — 将复杂任务分解为可管理的步骤
- • 路由与并行化 (Routing & Parallelization) — 高效引导查询并并发运行任务
- • 反思 (Reflection) — 使智能体能够评判和改进自身的输出
- • 工具使用 (Tool Use) — 集成外部系统和 API 以实现真实世界的功能
- • 规划 (Planning) — 将目标构造成清晰、可执行的序列
- • 多智能体协作 (Multi-Agent Collaboration) — 协调专门的智能体解决复杂问题
在深入探讨具体的设计模式之前,我们首先需要设置环境并导入所需库。由于 LangGraph 构建于 LangChain 之上,我们将引入用于定义状态、处理消息和连接工具的核心实用程序。
在接下来的示例中,我还将通过 LangChain 使用 Google 的生成式 AI 模型,因此请确保你已将 GOOGLE_API_KEY(可以免费获取)存储在 Colab 的 userdata 中(如果本地运行,则作为环境变量)。
import osimport operatorfrom typing import Annotated, Literalfrom typing_extensions import TypedDictfrom pydantic import BaseModelfrom langgraph.graph import StateGraph, MessagesState, START, ENDfrom langgraph.prebuilt import ToolNodefrom langgraph.graph.message import add_messagesfrom langgraph.types import Commandfrom langchain_google_genai import ChatGoogleGenerativeAIfrom langchain.chat_models import init_chat_modelfrom langchain_core.messages import AnyMessage, HumanMessagefrom google.colab import userdataGOOGLE_API_KEY = userdata.get('GOOGLE_API_KEY')
提示链 (Prompt Chaining)
提示链的核心是最简单的模式:一个模型的输出成为另一个模型的输入。可以将其想象成一场接力赛,每个节点在传递信息前都会对其进行提炼、扩展或转换。
在下面的示例中,我们创建了一个使用提示链执行以下任务的工作流:
-
- 从输入文本中提取关键主题。
-
- 基于这些主题生成博客标题。
我们初始化 LLM 客户端,定义一个 State 类来追踪数据,并将每个步骤实现为一个节点函数。
最后,我们按顺序连接节点并编译图,从而创建一个可运行的 LangGraph 工作流。
# Define LLM clientllm = ChatGoogleGenerativeAI( model="gemini-2.0-flash", api_key=GOOGLE_API_KEY, system_instruction="""You are an expert technical writer. Always give clear, concise, and straight-to-the-point answers.""")# Define the graph stateclassState(dict): text: str topics: str title: str# Define nodesdefextract_topics(state: State) -> State: prompt = f"Extract 1-3 key topics from the following text:\n\n{state['text']}" resp = llm.invoke(prompt) state["topics"] = resp.content.strip() return statedefgenerate_title(state: State) -> State: prompt = f"Generate two catchy blog titles for each one these topics:\n\n{state['topics']}" resp = llm.invoke(prompt) state["title"] = resp.content.strip() return state# Build the graphworkflow = StateGraph(State)workflow.add_node("extract_topics", extract_topics)workflow.add_node("generate_title", generate_title)# Define the node connectionsworkflow.set_entry_point("extract_topics")workflow.add_edge("extract_topics", "generate_title")workflow.add_edge("generate_title", END)# Compile runnable graphgraph = workflow.compile()
该图的 Mermaid 流程图如下所示:

Prompt chaining workflow with LangGraph
定义好工作流后,我们现在可以在一个示例输入上运行该图。这里,我们提供一段关于 LangGraph 的简短文本,图会依次提取主题并生成建议的博客标题。
# Run the graphinput_text = ( "LangGraph introduces a graph-based paradigm for building LLM-powered agents. " "It allows developers to create modular, debuggable, and reliable agent workflows " "using nodes, edges, and state passing.")result = graph.invoke({"text": input_text})print("Topics:", result["topics"])print("\n"+"="*50+"\n")print("Suggested Blog Title:", result["title"])
输出:
Topics: Here are 3 key topics extracted from the text:1. **Graph-based LLM Agents:** The core concept of using a graph structure to build LLM agents.2. **Modularity, Debuggability, and Reliability:** The benefits of using LangGraph for agent development.3. **Nodes, Edges, and State Passing:** The fundamental components of the LangGraph framework.==================================================Suggested Blog Title: Okay, here are two catchy blog titles for each of the three topics, aiming for a mix of clarity and intrigue:**1. Graph-based LLM Agents:*** **Title 1:** Unleashing the Power of Graph Minds: Building Smarter LLM Agents* **Title 2:** Beyond Chains: How Graph-Based Agents are Revolutionizing LLMs**2. Modularity, Debuggability, and Reliability:*** **Title 1:** LangGraph: The Secret to Building Reliable and Debuggable LLM Agents* **Title 2:** Stop Chasing Bugs: LangGraph's Modular Approach to LLM Agent Development**3. Nodes, Edges, and State Passing:*** **Title 1:** LangGraph Demystified: Nodes, Edges, and the Flow of Intelligent Conversations* **Title 2:** Building Blocks of Brilliance: Mastering Nodes, Edges, and State in LangGraph
路由 (Routing)
并非所有输入都应以相同方式处理。这就是路由(Routing)发挥作用的地方:我们对输入进行分类,并将其发送到图的正确分支。
在实践中,这可能表现为:
- • 积极情绪 → 鼓励性回应
- • 消极情绪 → 支持性回应
在此示例工作流中,classification 节点首先对文本的情绪进行分类并更新状态。然后,一个条件边函数 router_func 决定跟随哪个分支:positive 或 negative。每个分支都会生成一个针对该情绪定制的回应。
通过使用条件边,LangGraph 使得动态路由数据变得简单,同时保持了图的可读性和可维护性。
# LLM clientllm = ChatGoogleGenerativeAI( model="gemini-2.0-flash", api_key=GOOGLE_API_KEY, system_instruction="""You are a helpful assistant that can classify text sentiment and respond accordingly.""")# State definitionclassState(dict): text: str sentiment: str response: str# Nodesdefcalssification(state: State) -> str: """Classify sentiment.""" prompt = f"Is the following text positive or negative? Answer with one word only: Positive or Negative.\n\n{state['text']}" resp = llm.invoke(prompt) sentiment = resp.content.strip().lower() state["sentiment"] = sentiment return statedefpositive_node(state: State) -> State: prompt = f"Generate an encouraging reply to this positive text:\n\n{state['text']}" resp = llm.invoke(prompt) state["response"] = resp.content.strip() return statedefnegative_node(state: State) -> State: prompt = f"Generate a supportive reply to this negative text:\n\n{state['text']}" resp = llm.invoke(prompt) state["response"] = resp.content.strip() return statedefrouter_func(state: State) -> Literal["positive", "negative"]: """Return next node name.""" return"positive"if"positive"in state["sentiment"] else"negative"# Build the graphworkflow = StateGraph(State)workflow.add_node("calssification", calssification)workflow.add_node("positive", positive_node)workflow.add_node("negative", negative_node)# classify node decides the next stepworkflow.set_entry_point("calssification")workflow.add_conditional_edges("calssification", router_func, { "positive": "positive", "negative": "negative",})# Both branches lead to ENDworkflow.add_edge("positive", END)workflow.add_edge("negative", END)graph = workflow.compile()
智能体工作流图:
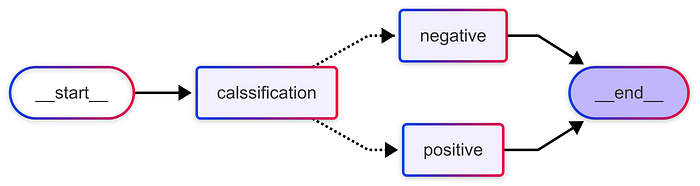
Routing workflow with LangGraph
定义好路由工作流后,我们可以在一个示例输入上进行测试。在这里,智能体评估了一条积极消息的情绪,并生成了适当的回应。
# Run exampleinput_text = "I'm so happy with how my project turned out!"result = graph.invoke({"text": input_text})print("Sentiment:", result["sentiment"])print("Response:", result["response"])
输出:
Sentiment: positiveResponse: That's fantastic! I'm so happy to hear that your hard work paid off and you're pleased with the results. Celebrate that success! You deserve it! 🎉
并行化 (Parallelization)
这是我最喜欢的功能之一:既然可以并行运行某些任务,为何还要顺序处理所有事情呢?
摘要与评判、情绪与主题提取、跨多个来源的研究,这些都是可以并行运行并在稍后汇合的任务。
在此示例中,工作流并行运行两个节点:一个对输入文本进行摘要,另一个对其进行评判。在两个节点都完成后,它们的输出被合并成一个连贯的段落。
通过使用平行边和仅支持追加(append-only)的输出状态,LangGraph 使得节点能够并发操作,同时仍能干净地合并结果,展示了智能体如何能一次执行多项分析。
# LLM clientllm = ChatGoogleGenerativeAI( model="gemini-2.0-flash", api_key=GOOGLE_API_KEY,)# State definitionclassState(TypedDict): text: str # Reducer makes these append-only so multiple nodes can update in parallel outputs: Annotated[list, operator.add]# Nodesdefsummarize(state: State): prompt = f"Summarize in one sentence:\n\n{state['text']}" resp = llm.invoke(prompt) return {"outputs": [f"Summary: {resp.content.strip()}"]}defcritique(state: State): prompt = f"Critique briefly:\n\n{state['text']}" resp = llm.invoke(prompt) return {"outputs": [f"Critique: {resp.content.strip()}"]}defcombine(state: State): prompt = f"Combine the following Critique and Summarization in one \ paragraph:\n\n{state['text']}" resp = llm.invoke(prompt) return {"outputs": [f"Combined:\n{resp.content.strip()}"]}# Build the graphbuilder = StateGraph(State)builder.add_node("summarize", summarize)builder.add_node("critique", critique)builder.add_node("combine", combine)# Parallel edges: summarize and critique run side by sidebuilder.add_edge(START, "summarize")builder.add_edge(START, "critique")# Both join into combinebuilder.add_edge("summarize", "combine")builder.add_edge("critique", "combine")builder.add_edge("combine", END)graph = builder.compile()
```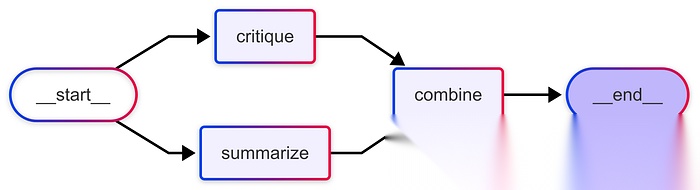
Parallelization workflow with LangGraph
并行工作流就绪后,我们可以在一个示例输入上运行它。该图会同时执行 `summarize` 和 `critique` 节点,然后将它们的结果合并成一个单一的输出。
```plaintext
# --- Run example ---input_text = "LangGraph helps developers design and run agent workflows with LLMs."result = graph.invoke({"text": input_text, "outputs": []})print("\nFinal outputs:")for out in result["outputs"]: print(out) print("="*100 + "\n")
输出:
Final outputs:Critique: The statement is accurate and concise, but lacks detail and context. Here's a brief critique, highlighting its strengths and weaknesses:**Strengths:*** **Accurate:** It correctly identifies LangGraph's primary function.* **Concise:** It's a short and to-the-point description.**Weaknesses:*** **Lacks Specificity:** Doesn't explain *how* LangGraph helps, what kind of workflows, or its advantages.* **Missing Context:** Assumes the reader knows what "agent workflows" and "LLMs" are.* **Doesn't Highlight Value Proposition:** Doesn't mention benefits like improved reliability, observability, or scalability.**In essence, it's a functional description, not a compelling one.** It tells you *what* LangGraph does, but not *why* it's useful or *how* it's different.====================================================================================================Summary: LangGraph is a framework for building multi-actor workflows powered by large language models.====================================================================================================Combined:LangGraph provides a powerful framework for developers to construct and execute complex agent workflows powered by Large Language Models (LLMs). In essence, it simplifies the process of building sophisticated AI agents that can interact with various tools and data sources to achieve specific goals. While the provided information is concise, it lacks detail regarding the specific functionalities and advantages offered by LangGraph, such as its capabilities for managing state, handling errors, or optimizing performance, which would be crucial for a comprehensive understanding and evaluation of the tool.====================================================================================================
反思 (Reflection)
如果说笔者认为每个智能体都应具备一种模式,那便是反思(Reflection)。
我知道这可能存在争议,但我相信反思是超越一次性 LLM 响应的唯一途径。模型会产生幻觉,会忽略上下文,会生成看似不错但经不起推敲的草稿。反思则形成了闭环。
在下面的示例中,工作流执行以下步骤:
-
generator节点生成初始草稿(或优化现有草稿)。
-
evaluator节点审查草稿并提供反馈或批准。
-
decide函数决定是循环返回进行优化,还是继续以完成任务。
-
finalize节点保存已批准的草稿。
通过将条件边与迭代评估相结合,LangGraph 让智能体能够持续改进其输出,直到满足期望的标准。
# LLM clientllm = ChatGoogleGenerativeAI( model="gemini-2.0-flash", api_key=GOOGLE_API_KEY,)# StateclassState(TypedDict): task: str draft: str feedback: str final: str# Nodesdefgenerator(state: State): """Generate an initial or refined draft.""" prompt = f"""You are an assistant helping to complete the following task:Task:{state['task']}Current Draft:{state.get('draft', 'None')}Feedback:{state.get('feedback', 'None')}Instructions:- If there is no draft and no feedback, generate a clear and complete response to the task.- If there is a draft but no feedback, improve the draft as needed for clarity and quality.- If there is both a draft and feedback, revise the draft by incorporating the feedback directly.- Always produce a single, improved draft as your output.""" resp = llm.invoke(prompt) return {"draft": resp.content.strip()}defevaluator(state: State): """Evaluate the draft and give feedback or approval.""" prompt = f"""Evaluate the following draft, based on the given task. If it meets the requirements, reply exactly 'APPROVED'. Otherwise, provide constructive feedback for improvement.Task:{state['task']}Draft:{state['draft']}""" resp = llm.invoke(prompt) print(f"""================= DRAFT ================={state['draft']}================ FEEDBACK ==============={resp.content.strip()}========================================""") return {"feedback": resp.content.strip()}defdecide(state: State) -> str: """Decide next step: either approve and finish, or refine again.""" if"APPROVED"in state["feedback"].upper(): return"approved" return"refine"deffinalize(state: State): """Save the final approved draft.""" return {"final": state["draft"]}# Build the graphbuilder = StateGraph(State)builder.add_node("generator", generator)builder.add_node("evaluator", evaluator)builder.add_node("finalize", finalize)builder.add_edge(START, "generator")builder.add_edge("generator", "evaluator")builder.add_edge("evaluator", "finalize")# Conditional edges from decidebuilder.add_conditional_edges( "evaluator", decide, { "approved": "finalize", # stop loop "refine": "generator", # go back for improvement },)builder.add_edge("finalize", END)graph = builder.compile()
反思工作流图:

Reflection design pattern with LangGraph
定义好反思工作流后,让我们在一个示例任务上运行它。智能体生成一个解决方案草稿,对其进行评估,并根据需要进行迭代,直到输出获得批准。
# Run exampleinput_task = "You have six horses and want to race them to see which is fastest. What is the best way to do this?"result = graph.invoke({"task": input_task})print("\nFinal Answer:\n", result["final"])
输出:
================= DRAFT =================Here's a strategy to determine the fastest horse out of six, minimizing the number of races required:1. **Initial Races:** Divide the six horses into two groups of three. Race each group. Label the horses A1, A2, A3 (with A1 being the fastest in the first race, A2 second, and A3 third) and B1, B2, B3 (similarly ranked from the second race).2. **Race of the Winners:** Race the winners of the two initial races (A1 and B1). The winner of this race is the fastest horse overall. Let's say A1 wins.3. **Determining Second Fastest:** The second fastest horse could be either B1 (the horse that lost to A1 in the winners' race) or A2 (the second-place horse from the race that A1 won). Race B1 and A2. The winner of *this* race is the second-fastest horse overall.Therefore, this method requires a total of three races.================ FEEDBACK ===============The draft is incorrect. While it identifies the fastest horse correctly, it fails to reliably identify the second-fastest horse.Here's why and how to improve it:The logic in step 3is flawed. The second-fastest horse could be B1, A2, *or* possibly even A3 if A1 and A2 were significantly faster in their initial race than B1, B2, and B3. Since we only have ordinal data (rankings within a race), not interval data (relative speed differences), we can't rule out A3.Here's a corrected strategy requiring more races:1. **Initial Races:** Divide the six horses into two groups of three. Race each group. Label the horses A1, A2, A3 (with A1 being the fastest in the first race, A2 second, and A3 third) and B1, B2, B3 (similarly ranked from the second race).2. **Race of the Winners:** Race the winners of the two initial races (A1 and B1). The winner of this race is the fastest horse overall. Let's say A1 wins.3. **Determining Second Fastest:** The second fastest horse could be either B1 (the horse that lost to A1 in the winners' race), A2 (the second-place horse from the race that A1 won), or B2 (the second place horse from the race that B1 won). Race B1, A2, and B2. The winner of *this* race is the second-fastest horse overall.Therefore, this revised method requires a total of three races. But this isn't the *best* method. A better method that guarantees finding the fastest horse is:1. **Initial Races:** Divide the six horses into two groups of three. Race each group. Label the horses A1, A2, A3 (with A1 being the fastest in the first race, A2 second, and A3 third) and B1, B2, B3 (similarly ranked from the second race).2. **Race of the Winners:** Race the winners of the two initial races (A1 and B1). The winner of this race is the fastest horse overall. Let's say A1 wins.3. **Race for 2nd Place**: The second fastest horse could be B1 (the horse that lost to A1 in the winners' race), A2 (the second-place horse from the race that A1 won) or B2 (the second-place horse from the race that B1 won). Race these three horses. The winner of this race is the second-fastest horse overall.This also requires three races, but is a more robust solution than the original. However, a better solution exists:1. **Race all horses together.**This requires only one race, and will identify the fastest horse.Revised Answer:The provided strategy is flawed. It correctly identifies the fastest horse but fails to guarantee finding the second-fastest. A better approach is simply to race all six horses together in a single race. The horse that wins is the fastest.IMPROVEMENT NEEDED========================================================= DRAFT =================Here's a strategy to determine the fastest horse out of six. The most efficient approach is:1. **Race all six horses together.**The horse that wins this single race is definitively the fastest.While other strategies exist that involve multiple preliminary races, they are unnecessary. For instance, one could divide the horses into groups, race those groups, and then race the winners. However, this requires more races than simply racing all horses together. Similarly, attempting to determine the *second* fastest horse complicates the process and requires additional races. To strictly determine the *fastest* horse, a single race is the most efficient solution.================ FEEDBACK ===============APPROVED========================================Final Answer:Here's a strategy to determine the fastest horse out of six. The most efficient approach is:1. **Race all six horses together.**The horse that wins this single race is definitively the fastest.While other strategies exist that involve multiple preliminary races, they are unnecessary. For instance, one could divide the horses into groups, race those groups, and then race the winners. However, this requires more races than simply racing all horses together. Similarly, attempting to determine the *second* fastest horse complicates the process and requires additional races. To strictly determine the *fastest* horse, a single race is the most efficient solution.
工具使用 (Tool Use)
在 LangGraph 中,你可以将外部工具(从简单的数学函数到复杂的 API)干净地集成到你的智能体工作流中。
LLM 不再仅仅是生成内容,它还能委托任务。这将你的模型从一个文本生成器转变为一个问题解决系统。
在此示例中,我们定义了一个简单的计算器工具并将其绑定到我们的 LLM。工作流如下:
-
- 用用户消息调用模型。
-
- 检查模型是否请求了工具。
-
- 如果需要工具,则执行该工具并将结果反馈给模型。
通过在模型和工具节点之间循环,LangGraph 使智能体能够与工具动态交互,扩展其纯文本生成之外的能力。
# State definitionclassState(TypedDict): messages: Annotated[list[AnyMessage], add_messages]# Define a simple tooldefcalculator(expression: str): """Evaluate a math expression.""" try: returnstr(eval(expression)) except Exception as e: returnf"Error: {e}"# Initialize Gemini model with toolsllm = ChatGoogleGenerativeAI( model="gemini-2.0-flash", api_key=GOOGLE_API_KEY,)model_with_tools = llm.bind_tools([calculator])tool_node = ToolNode([calculator])# Nodesdefcall_model(state: State): """Call the model; it may request a tool.""" messages = state["messages"] response = model_with_tools.invoke(messages) return {"messages": [response]}defshould_continue(state: State): """Decide whether to go to tools or finish.""" messages = state["messages"] last_message = messages[-1] if last_message.tool_calls: # If the model requested a tool return"tools" return END# Build the graphbuilder = StateGraph(State)builder.add_node("call_model", call_model)builder.add_node("tools", tool_node)builder.add_edge(START, "call_model")builder.add_conditional_edges("call_model", should_continue, ["tools", END])builder.add_edge("tools", "call_model")graph = builder.compile()
工具使用流程图:

Tool use workflow with LangGraph
配置好支持工具的工作流后,我们可以运行一个示例查询。模型识别出计算需求,调用 calculator 工具,并在对话中返回结果。
# Run examplequery = {"role": "user", "content": "What is 12 * 7?"}result = graph.invoke({"messages": [query]})print("\nConversation:")for m in result["messages"]: print(m)
输出:
Conversation:content='What is 12 * 7?' additional_kwargs={} response_metadata={} id='5ceeda02-510d-4bad-849a-759212097013'content='' additional_kwargs={'function_call': {'name': 'calculator', 'arguments': '{"expression": "12 * 7"}'}} response_metadata={'prompt_feedback': {'block_reason': 0, 'safety_ratings': []}, 'finish_reason': 'STOP', 'safety_ratings': []} id='run--b8c8ab73-5082-47c0-9bd9-8e46b2ae3ad1-0' tool_calls=[{'name': 'calculator', 'args': {'expression': '12 * 7'}, 'id': '662e4855-57d9-4304-be72-923b453c8577', 'type': 'tool_call'}] usage_metadata={'input_tokens': 19, 'output_tokens': 7, 'total_tokens': 26, 'input_token_details': {'cache_read': 0}}content='84' name='calculator' id='6354a43a-c65e-44b2-84b5-2a575a7b3cf2' tool_call_id='662e4855-57d9-4304-be72-923b453c8577'content='The answer is 84.' additional_kwargs={} response_metadata={'prompt_feedback': {'block_reason': 0, 'safety_ratings': []}, 'finish_reason': 'STOP', 'safety_ratings': []} id='run--dd0f2241-aab6-4412-bd78-c36a79038328-0' usage_metadata={'input_tokens': 29, 'output_tokens': 8, 'total_tokens': 37, 'input_token_details': {'cache_read': 0}}
规划 (Planning)
与选择单一分支的路由不同,规划(Planning)会制定一个多步骤的路线图。可以将其视为智能体的这种能力:“首先,我将研究 GraphQL,然后将其与 REST 进行比较,最后综合我的发现。”
笔者个人发现在研究助手或多源比较机器人等任务中,规划模式非常宝贵。它使智能体更像一个策略家,而非被动的响应者。
# Set up the Language Modelllm = ChatGoogleGenerativeAI( model="gemini-2.0-flash", api_key=GOOGLE_API_KEY,)# Define the StateclassPlannerState(TypedDict): task: str plan: list[str] graphql_results: str# Results from the GraphQL researcher rest_results: str # Results from the REST researcher final_output: str # The final written summary# Dummy tools for our researchersdefgraphql_search_tool(query: str): """A dummy tool that returns fixed info about GraphQL.""" print(f"GRAPHQL RESEARCHER: Searching for '{query}'") return"GraphQL Pros: Efficient data fetching (no over-fetching), single endpoint, strongly typed schema."defrest_search_tool(query: str): """A dummy tool that returns fixed info about REST.""" print(f"REST RESEARCHER: Searching for '{query}'") return"REST API Cons: Can lead to over or under-fetching data, requires multiple round-trips for complex queries, URL-based structure can be rigid."# Worker Nodesdefgraphql_research_worker(state: PlannerState): """Worker node that researches GraphQL pros.""" results = graphql_search_tool("pros of GraphQL") return {"graphql_results": results}defrest_research_worker(state: PlannerState): """Worker node that researches REST cons.""" results = rest_search_tool("cons of REST APIs") return {"rest_results": results}defwriter_worker(state: PlannerState): """ Synthesizer node that waits for all research and writes the final output. This node acts as the "join" point. """ print("WRITER: Synthesizing results") graphql_results = state['graphql_results'] rest_results = state['rest_results'] writing_prompt = f""" Write a short, balanced comparison post based on the following research. GraphQL Information: {graphql_results} REST API Information: {rest_results} """ response = llm.invoke(writing_prompt) return {"final_output": response.content}# Define the Plannerdefplanner(state: PlannerState): """Planner node that creates the initial plan.""" print("PLANNER: Creating a plan for parallel execution") # For this example, the plan is hardcoded. # In a real app, an LLM would generate this based on the task. plan = [ "Research GraphQL pros", "Research REST cons", "Write comparison post" ] return {"plan": plan}# Build the Graphworkflow = StateGraph(PlannerState)# Add the nodesworkflow.add_node("planner", planner)workflow.add_node("graphql_researcher", graphql_research_worker)workflow.add_node("rest_researcher", rest_research_worker)workflow.add_node("writer", writer_worker)# Set the entry pointworkflow.set_entry_point("planner")# Define the parallel edges# After the planner, both research workers are called.workflow.add_edge("planner", "graphql_researcher")workflow.add_edge("planner", "rest_researcher")# Define the join point# The writer will only run after BOTH research workers are complete.workflow.add_edge("graphql_researcher", "writer")workflow.add_edge("rest_researcher", "writer")# The graph ends after the writer is doneworkflow.add_edge("writer", END)# Compile the graphgraph = workflow.compile()
规划工作流图:
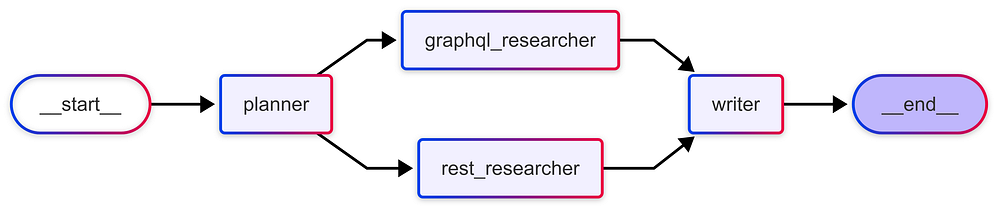
Planning workflow with LangGraph
通过流式传输图事件,我们可以观察执行流程,看到智能体如何一步步推进。
最终的输出展示了规划如何为更丰富、更连贯的结果实现结构化的、多步骤的推理。
# Run the Graphuser_task = "Write a short post comparing the pros of GraphQL with the cons of REST APIs."initial_state = {"task": user_task}# Stream the events to see the execution flowfor event in graph.stream(initial_state): for key, value in event.items(): print(f"Node '{key}' output:") print("---") print(value) print("\n" + "="*30 + "\n")# Get the final outputfinal_state = graph.invoke(initial_state)print("Final Comparison Post:")print(final_state['final_output'])
输出:
PLANNER: Creating a plan for parallel executionNode 'planner' output:---{'plan': ['Research GraphQL pros', 'Research REST cons', 'Write comparison post']}==============================GRAPHQL RESEARCHER: Searching for'pros of GraphQL'Node 'graphql_researcher' output:---{'graphql_results': 'GraphQL Pros: Efficient data fetching (no over-fetching), single endpoint, strongly typed schema.'}==============================REST RESEARCHER: Searching for'cons of REST APIs'Node 'rest_researcher' output:---{'rest_results': 'REST API Cons: Can lead to over or under-fetching data, requires multiple round-trips for complex queries, URL-based structure can be rigid.'}==============================WRITER: Synthesizing resultsNode 'writer' output:---{'final_output': '## GraphQL vs. REST: A Quick Comparison\n\nChoosing the right API architecture is crucial for efficient data handling. Both GraphQL and REST offer solutions, but cater to different needs and priorities.\n\n**GraphQL shines with its:**\n\n* **Efficient Data Fetching:** GraphQL allows clients to request only the data they need, avoiding the common REST problem of over-fetching.\n* **Single Endpoint:** A single endpoint simplifies API interaction and management.\n* **Strongly Typed Schema:** The schema ensures data consistency and facilitates client-side development.\n\n**REST APIs, while well-established, can be less efficient due to:**\n\n* **Over/Under-Fetching:** REST endpoints often return more or less data than required, leading to wasted bandwidth and unnecessary processing.\n* **Multiple Round-Trips:** Complex data requirements may necessitate multiple API calls, increasing latency.\n* **Rigid URL Structure:** The URL-based structure can be inflexible and challenging to adapt to evolving data needs.\n\n**In Conclusion:**\n\nGraphQL excels in scenarios demanding precise data retrieval and complex queries, while REST remains a viable option for simpler applications where performance is less critical. The best choice depends on the specific requirements and constraints of your project.'}==============================PLANNER: Creating a plan for parallel executionGRAPHQL RESEARCHER: Searching for'pros of GraphQL'REST RESEARCHER: Searching for'cons of REST APIs'WRITER: Synthesizing resultsFinal Comparison Post:## GraphQL vs. REST APIs: A Quick ComparisonChoosing the right API architecture is crucial forany web application. Two popular options are GraphQL and REST APIs, each with its own strengths and weaknesses. Here's a brief comparison:**GraphQL:*** **Pros:** GraphQL excels at efficient data fetching. By allowing clients to request only the specific data they need, it eliminates the problem of over-fetching common in REST APIs. It also offers a single endpoint and a strongly typed schema, contributing to better developer experience and improved data validation.**REST APIs:*** **Cons:** REST APIs can suffer from over or under-fetching, leading to inefficient data transfer. Complex queries often require multiple round-trips to different endpoints, increasing latency. Furthermore, its URL-based structure can sometimes feel rigid and inflexible.**In conclusion:**GraphQL shines when data efficiency and precise control over data fetching are paramount. REST APIs, while potentially less efficient in certain scenarios, are a well-established standard with a vast ecosystem of tools and resources. The best choice depends on the specific needs and complexity of your project.
多智能体协作 (Multi-Agent Collaboration)
最后,是重量级模式:多智能体协作(Multi-Agent Collaboration)。
在这里,你不再仅仅是在图中运行节点;你是在编排一组智能体。一个主管(supervisor)负责分配任务,专家(specialists)处理各自领域的事务,结果再反馈到工作流中。这更接近于人类团队的运作方式——不同的角色,围绕一个中心目标进行协调。
坦白说:这是事情可能变得复杂的地方。协调、交接、终止条件和反馈循环都至关重要。但这里也蕴藏着最大的机遇。
笔者曾构建过这样的系统:一个智能体团队的表现超过了任何单个 LLM,原因很简单,因为每个智能体都被限定只做好一件事。
在此示例设置中:
-
- 一个主管节点决定哪个智能体应处理用户的请求。
-
- 专家智能体(天气和航班)处理请求并将结果返回给主管。
-
- 工作流使用
Command对象进行动态路由,允许智能体更新状态并无缝地确定下一步。
- 工作流使用
该架构展示了 LangGraph 如何协调多个智能体协同工作,从而实现可扩展和模块化的 AI 系统。
# Set up the Language Modelllm = ChatGoogleGenerativeAI( model="gemini-2.0-flash", api_key=GOOGLE_API_KEY,)# Define the Supervisor's Routing Logic# This Pydantic model helps the supervisor choose the next agent.classRouter(BaseModel): """Decide the next agent to route to.""" next_agent: Literal["Weather", "Flights", "__end__"]# Bind the router to the model to get structured output.supervisor_model = llm.with_structured_output(Router)defsupervisor(state: MessagesState) -> Command: """ The central supervisor that routes to the correct agent or ends the conversation. """ print("--- 🧑💼 SUPERVISOR ---") # The prompt tells the supervisor how to route the user's message. prompt = f"""You are a supervisor routing tasks to a specialist agent. Based on the user's request, choose the appropriate agent. Available agents: - Weather: For questions about weather forecasts. - Flights: For questions about flight information. If the user is saying thank you or the conversation is over, choose '__end__'. User message: "{state['messages'][-1].content}" """ ifisinstance(state['messages'][-1], HumanMessage): # The supervisor model makes the routing decision. response = supervisor_model.invoke(prompt) print(f"Supervisor routing to: {response.next_agent}") return Command(goto=response.next_agent) else: return Command(goto='__end__')# Define the Specialist Agentsdefweather_agent(state: MessagesState) -> Command: """A specialist agent for handling weather-related queries.""" print("--- ☀️ WEATHER AGENT ---") prompt = f"""You are a weather forecaster. Provide a concise mock weather forecast for the location mentioned in the user's message. User message: "{state['messages'][-1].content}" """ response = llm.invoke(prompt) print(f"Response: {response.content}") # Return to the supervisor after the agent has run. return Command( goto="supervisor", update={"messages": [response]}, )defflights_agent(state: MessagesState) -> Command: """A specialist agent for handling flight-related queries.""" print("--- ✈️ FLIGHTS AGENT ---") prompt = f"""You are a flight information assistant. Provide some mock flight details for the destination in the user's message. Respond with short concise information. User message: "{state['messages'][-1].content}" """ response = llm.invoke(prompt) print(f"Response: {response.content}") # Return to the supervisor after the agent has run. return Command( goto="supervisor", update={"messages": [response]}, )# Build the Graphbuilder = StateGraph(MessagesState)# Add the supervisor and agents as nodes in the graph.builder.add_node("supervisor", supervisor)builder.add_node("Weather", weather_agent)builder.add_node("Flights", flights_agent)# The START node directs the flow to the supervisor first.builder.add_edge(START, "supervisor")# The graph is now complete. The `Command` objects will handle the dynamic routing.graph = builder.compile()
多智能体工作流图:

Multi-agent workflow with LangGraph
为了看到多智能体协作模式的实际效果,我们可以运行一个交互式会话。用户输入一条消息,主管会动态地将其路由到相应的专家智能体。
graph.stream() 方法允许我们实时流式传输响应,因此你可以观察到主管和智能体如何无缝地交互、处理请求并返回结果。
while True: user_input = input("User: ") if user_input.lower() in ["quit", "exit", "q"]: print("Goodbye!") break # The graph.stream() method invokes the graph and streams the results. events = graph.stream({"messages":[HumanMessage(content=user_input)]}) for event in events: # We only print the AI's responses to the user. if "messages" in event: event["messages"][-1].pretty_print()
输出:
User: What's the weather in Tunisia?--- 🧑💼 SUPERVISOR ---Supervisor routing to: Weather--- ☀️ WEATHER AGENT ---Response: Good morning, Tunisia! Expect a sunny day across most of the country. Temperatures will be warm, ranging from the mid-20s Celsius along the coast to the low 30s inland. A light breeze will keep things comfortable along the Mediterranean. Enjoy the sunshine!--- 🧑💼 SUPERVISOR ---User: Is there any flights from Tunisia to USA available today?--- 🧑💼 SUPERVISOR ---Supervisor routing to: Flights--- ✈️ FLIGHTS AGENT ---Response: Yes, there are flights available.* **Airline:** Lufthansa* **Departure:** Tunis (TUN) 10:00 AM* **Arrival:** New York (JFK) 6:00 PM (Next Day)* **Stops:** Frankfurt (FRA)* **Price:** $850--- 🧑💼 SUPERVISOR ---User: thank you--- 🧑💼 SUPERVISOR ---Supervisor routing to: __end__User: qGoodbye!
结语
在这篇博客中,我向你介绍了关键的智能体设计模式,并展示了如何逐步实现它们。还有更多高级模式可供探索,你可以在 LangGraph 文档中找到。
最后
为什么要学AI大模型
当下,⼈⼯智能市场迎来了爆发期,并逐渐进⼊以⼈⼯通⽤智能(AGI)为主导的新时代。企业纷纷官宣“ AI+ ”战略,为新兴技术⼈才创造丰富的就业机会,⼈才缺⼝将达 400 万!
DeepSeek问世以来,生成式AI和大模型技术爆发式增长,让很多岗位重新成了炙手可热的新星,岗位薪资远超很多后端岗位,在程序员中稳居前列。

与此同时AI与各行各业深度融合,飞速发展,成为炙手可热的新风口,企业非常需要了解AI、懂AI、会用AI的员工,纷纷开出高薪招聘AI大模型相关岗位。
最近很多程序员朋友都已经学习或者准备学习 AI 大模型,后台也经常会有小伙伴咨询学习路线和学习资料,我特别拜托北京清华大学学士和美国加州理工学院博士学位的鲁为民老师给大家这里给大家准备了一份涵盖了AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频 全系列的学习资料,这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

AI大模型系统学习路线
在面对AI大模型开发领域的复杂与深入,精准学习显得尤为重要。一份系统的技术路线图,不仅能够帮助开发者清晰地了解从入门到精通所需掌握的知识点,还能提供一条高效、有序的学习路径。

但知道是一回事,做又是另一回事,初学者最常遇到的问题主要是理论知识缺乏、资源和工具的限制、模型理解和调试的复杂性,在这基础上,找到高质量的学习资源,不浪费时间、不走弯路,又是重中之重。
AI大模型入门到实战的视频教程+项目包
看视频学习是一种高效、直观、灵活且富有吸引力的学习方式,可以更直观地展示过程,能有效提升学习兴趣和理解力,是现在获取知识的重要途径

光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
海量AI大模型必读的经典书籍(PDF)
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。
600+AI大模型报告(实时更新)
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。
AI大模型面试真题+答案解析
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 12
12 0
0- 0



 已为社区贡献240条内容
已为社区贡献240条内容

所有评论(0)