【干货收藏】大模型RAG检索增强全解析:解决知识过时与幻觉输出的关键技术
RAG检索增强技术解决大模型知识过时和幻觉问题,通过外部知识库结合生成能力。本文详解RAG基本流程(建立索引、检索生成)、多轮对话优化、全链路改进策略(文档准备、解析切片、向量化存储、检索召回、答案生成),并以企业HR问答系统为例演示实战应用。强调RAG核心价值是让大模型基于真实信息回答,新手可先构建最小原型,再逐步优化提升效果。
前言
检索增强生成(Retrieval-Augmented Generation,简称 RAG)是解决大模型 “知识过时”“幻觉输出” 等问题的关键技术,通过将外部知识库与大模型生成能力结合,让模型基于真实、最新的信息输出答案。本教程将从 RAG 基本流程出发,逐步讲解多轮对话优化、各环节改进策略,帮助你掌握 RAG 应用的构建与优化方法。
一、RAG 基本流程:从索引到生成的完整链路
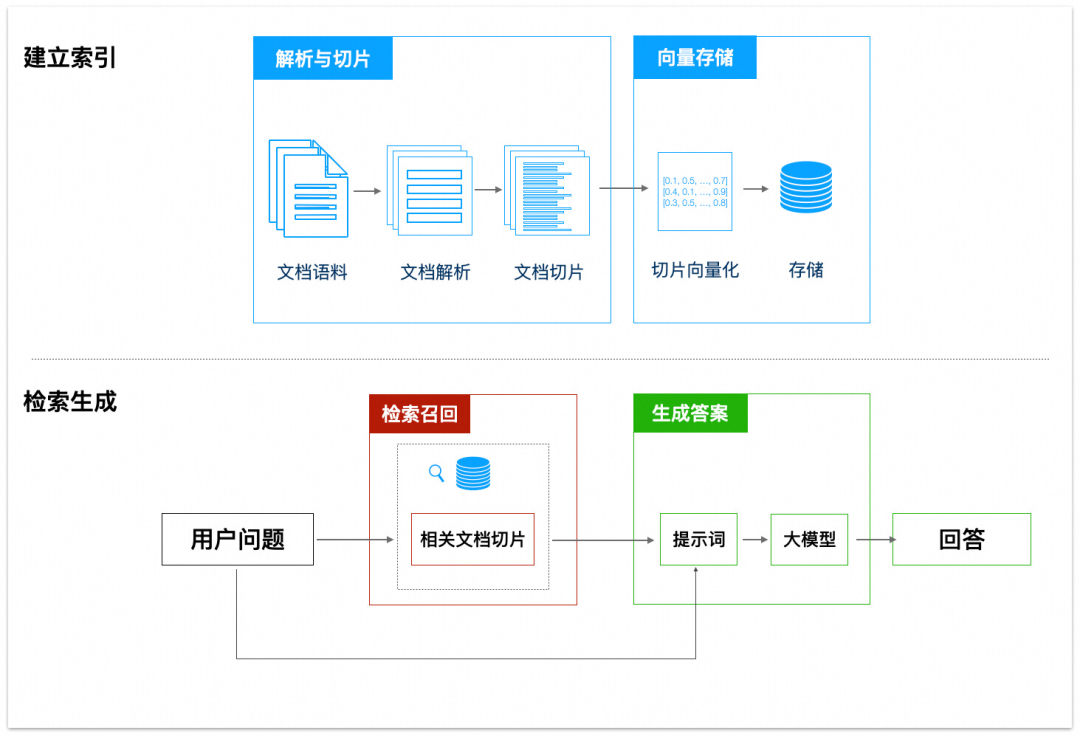
RAG 的核心逻辑是 “先检索、后生成”,整体流程分为建立索引和检索生成两大阶段,辅以 “保存与加载索引” 提升效率,具体步骤如下:
(一)建立索引:为知识库 “打造检索地图”
建立索引是 RAG 的基础,目的是将非结构化的文档转化为可快速检索的向量数据,包含 4 个关键步骤:
-
文档解析
将知识库中的原始文档(如 PDF、Word、TXT 等)加载并解析为纯文字形式。例如,将一份包含表格和图片的产品手册,提取其中的文字内容(表格内容需转化为结构化文本,图片需通过 OCR 提取文字),确保大模型能理解文档核心信息,例如,使用PyPDF2库解析 PDF 文件,示例代码如下。
import PyPDF2def parse_pdf(pdf_path): text = "" with open(pdf_path, 'rb') as file: reader = PyPDF2.PdfReader(file) for page in reader.pages: text += page.extract_text() return text
-
文本分段
对解析后的长文本进行 “切片” 处理。若直接用整文档检索,会导致匹配效率低、无关信息干扰多;若切片过细,又会丢失上下文。常见的切片逻辑包括:按固定字数分割(如每 500 字一段)、按章节 / 段落分割,或结合语义连贯性分割(避免切断完整逻辑),以下是按固定字数分割的 Python 代码示例:
def split_text(text, chunk_size=500): chunks = [] start = 0 while start < len(text): end = min(start + chunk_size, len(text)) chunks.append(text[start:end]) start = end return chunks
-
文本向量化
借助嵌入(Embedding)模型,将每个文本片段和用户问题转化为高维向量(如 768 维、1536 维)。向量的相似度越高,代表文本语义越接近。例如,用Open AI的 Embedding 模型,将 “如何申请年假” 和 “年假申请流程” 转化为向量后,两者的余弦相似度会显著高于与 “薪资计算” 的相似度,如下代码所示,将文字转为向量,将会打印一串整形数字向量:
import openaiopenai.api_key = "YOUR_API_KEY"def get_embedding(text): response = openai.Embedding.create( input=text, model="text - embedding - ada - 002" ) return response['data'][0]['embedding']get_embedding('如何申请年假')
-
存储索引
将向量化后的文本片段存储到向量数据库中,形成可高效检索的 “向量索引”。向量数据库能快速计算用户问题向量与库中所有片段向量的相似度,实现毫秒级召回相关内容。
(二)检索生成:基于真实信息输出答案
当用户提出问题时,RAG 通过 “检索相关片段→结合片段生成答案” 的流程,确保输出的准确性,具体步骤如下:
检索阶段
- 先用 Embedding 模型将用户问题转化为向量;
- 向量数据库计算该向量与库中所有文本片段向量的相似度,召回最相关的 Top N 个片段(如 Top 5、Top 10);
- 例如,用户问 “公司年假有多少天”,检索系统会从向量数据库中召回包含 “年假天数”“年假政策” 的文本片段。
生成阶段
将 “用户问题 + 召回的相关片段” 通过提示词模板组合,输入大模型生成最终答案。此时大模型的核心作用是 “总结整合”,而非依赖自身训练数据,从根源减少幻觉。
典型提示词模板如下:
请严格根据以下参考信息回答用户问题,不添加参考信息外的内容:{召回文本段1}{召回文本段2}...用户的问题是:{question}要求:回答简洁、逻辑清晰,直接回应问题核心。
(三)保存与加载索引:提升复用效率
首次建立索引后,可将索引文件(如向量数据库快照、Embedding 结果)保存到本地或云端。后续使用时直接加载索引,无需重新解析、分段、向量化,能将 RAG 响应速度提升 5-10 倍,尤其适合知识库更新频率低的场景(如固定政策文档、历史案例库)。
二、RAG 多轮对话:解决历史信息丢失问题
在多轮对话中(如 “我能申请年假吗?”→“申请需要什么材料?”),若仅用用户当前问题检索,会丢失前序对话信息,导致检索结果偏差。例如,用户第二次问 “申请需要什么材料” 时,系统可能无法判断是 “年假申请” 还是 “报销申请”。
多轮对话的核心解决方案:问题改写
通过大模型将 “当前问题 + 历史对话” 整合,改写为包含完整意图的新查询(New Query) ,再用新查询执行检索。具体流程如下:
收集历史对话记录(如前 3 轮对话内容);
用提示词引导大模型改写问题:
角色:你是问题改写专家,需结合历史对话,将用户当前问题改写为独立、完整的查询。历史对话:用户:我能申请年假吗?系统:可以,需满足入职满1年的条件。用户当前问题:申请需要什么材料?改写要求:新查询需包含“年假申请”的核心意图,无需冗余信息。改写结果:
大模型输出新查询:“年假申请需要准备什么材料?”;
用新查询执行检索与生成,确保结果准确关联 “年假” 场景。
三、RAG 各环节优化策略:从基础到进阶
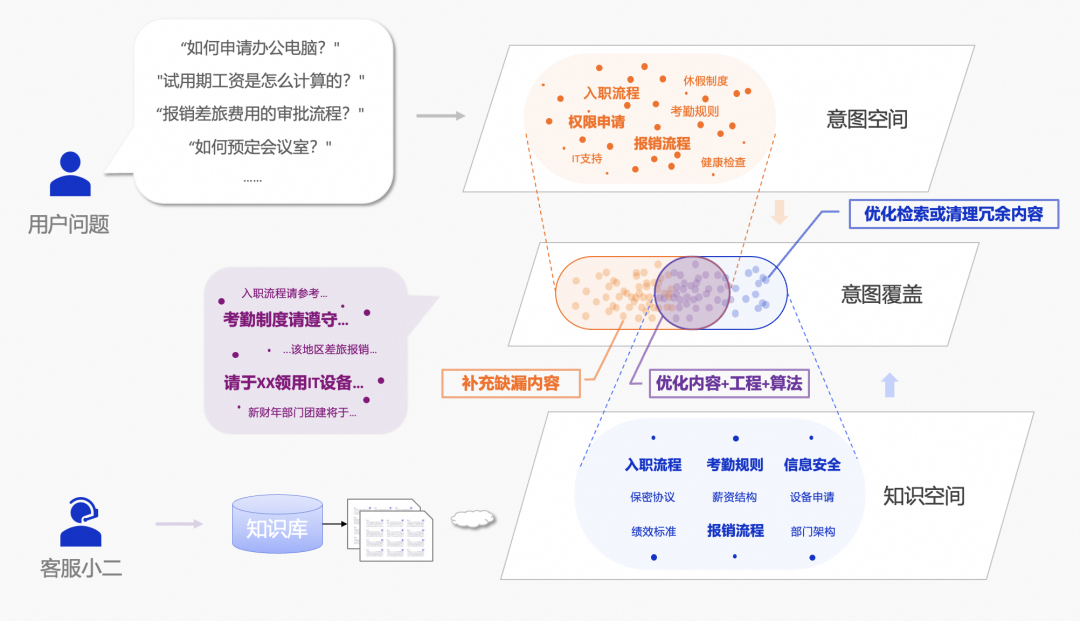
RAG 的效果依赖每个环节的细节优化,以下从 “文档准备→解析切片→向量化存储→检索召回→答案生成” 全链路,提供可落地的改进方案。
(一)文档准备阶段:对齐 “意图空间” 与 “知识空间”
RAG 的本质是 “用知识库的知识满足用户意图”,需先明确两个核心空间的关系,再针对性优化:
| 空间类型 | 定义 | 优化策略 |
|---|---|---|
| 意图空间 | 用户提问背后的真实需求(如 “查年假政策”“问报销流程”) | 1. 建立用户意图收集机制(如对话日志分析、用户反馈调研);2. 邀请领域专家标注高频意图(如 HR 场景的 “薪资”“考勤”“福利”)。 |
| 知识空间 | 知识库中可提供答案的知识点(如段落、章节) | 1. 补充 “未覆盖的意图空间”:若用户常问 “远程办公政策” 但知识库无相关内容,需新增文档;2. 清理 “未利用的知识空间”:删除与用户意图无关的内容(如过期的旧政策)。 |
关键原则:优先通过 “补充知识库内容” 优化效果,再考虑算法改进。若知识库本身缺少用户需要的信息,任何检索算法都无法提升准确性。
(二)文档解析与切片阶段:平衡 “信息完整” 与 “噪声减少”
解析和切片直接影响检索片段的质量,常见问题及解决方案如下:
1. 文档解析问题与改进
| 问题类型 | 改进策略 | 场景示例 |
|---|---|---|
| 格式不支持(如 Keynote、CAD) | 1. 开发专属解析器;2. 批量转换为支持格式(如 PDF、Markdown) | 某企业用 Keynote 存储产品方案,可先将 Keynote 导出为 PDF,再用 PDF 解析器提取文字。 |
| 特殊内容无法提取(表格、图片) | 1. 表格:转化为 Markdown 表格格式;2. 图片:用 OCR 提取文字 + 标注图片主题 | 文档中 “员工薪资等级表”,转化为 Markdown 表格后,检索时能精准匹配 “薪资等级” 相关问题。 |
2. 文本切片优化:选择合适的切片方法
不同切片方法适用于不同场景,需根据文档类型和模型能力选择:
| 切片方法 | 原理 | 适用场景 | 选择建议 |
|---|---|---|---|
| Token 切片 | 按固定 Token 数分割(如每 256 Token 一段) | 模型上下文长度有限(如≤1024 Token) | 避免模型输入超限,适合轻量级模型 |
| 句子切片 | 按句子边界分割(保持句子完整) | 大多数通用场景(如政策文档、新闻) | 新手入门首选,平衡效率与上下文完整性 |
| 句子窗口切片 | 每个切片包含前后 N 个句子作为上下文 | 长文档(如论文、报告),需关联上下文 | 检索 “某结论的推导过程” 时,补充前后文片段 |
| 语义切片 | 按语义相关性分割(如 “章节内子主题”) | 逻辑性强的文档(如技术手册、教程) | 避免切断 “问题 - 解决方案”“原因 - 结果” 等逻辑链 |
| Markdown 切片 | 按 Markdown 语法分割(如 #标题、## 子标题) | Markdown 格式文档(如 GitHub 文档、笔记) | 精准匹配 “某标题下的内容”,提升检索精度 |
优化案例:某技术手册用 “语义切片” 后,用户问 “如何调试 API 接口”,检索系统能召回 “API 调试步骤”“常见错误解决” 两个关联片段,而非零散的句子。
(三)切片向量化与存储阶段:选择工具提升检索效率
向量化和存储的核心是 “选对模型 + 选对数据库”,直接影响检索速度和准确性。
1. Embedding 模型选择
- 核心原则:优先选择与大模型同生态、更新时间近的模型。例如,使用阿里云百炼大模型时,搭配百炼 Embedding 模型,语义匹配度更高;
- 效果差异:新模型(如 Qwen-Embedding-V2)比旧模型(如 BERT-Base)的向量区分度提升 30% 以上,能减少 “相似问题误判”(如 “年假申请” 与 “病假申请”)。
2. 向量数据库选择
根据应用规模选择合适的存储方案,兼顾成本与性能:
| 存储类型 | 特点 | 适用场景 | 推荐方案(阿里云) |
|---|---|---|---|
| 内存向量存储 | 速度快、无运维成本,但重启后数据丢失 | 开发测试、临时验证 | 百炼内置内存向量存储 |
| 本地向量数据库 | 数据持久化、需自行运维 | 小规模应用(日活≤100) | Milvus 本地版、Chroma |
| 云服务向量存储 | 自动扩容、监控完善、按量付费 | 生产环境(高并发、大规模数据) | 向量检索服务(DashVector)、PolarDB 向量功能 |
云服务优势:支持 “向量检索 + 标量过滤” 混合查询(如 “检索‘年假’相关片段,且发布时间≥2024 年”),进一步提升检索精度。
(四)检索召回阶段:精准定位相关片段
检索召回的核心问题是 “如何从海量片段中找到最相关的内容”,可从 “检索前” 和 “检索后” 两个时机优化:
1. 检索前:优化查询,还原真实意图
通过改写、扩写问题,让查询更精准,常见策略如下:
| 策略 | 操作方法 | 示例 |
|---|---|---|
| 问题改写 | 补充模糊信息,明确意图 | “附近有好吃的吗?”→“推荐我公司附近评分≥4.5 的餐厅” |
| 问题扩写 | 增加相关维度,扩大检索范围 | “张伟是哪个部门的?”→“张伟的部门、联系方式、职责是什么?” |
| 基于用户画像扩写 | 结合用户身份补充上下文 | 内容工程师问 “工作注意事项”→“内容工程师的工作注意事项” |
| 提取标签过滤 | 从问题中提取标签,缩小检索范围 | “内容工程师注意事项”→标签:{岗位:内容工程师},检索时先过滤标签 |
2. 检索后:过滤噪声,提升片段质量
召回片段后,通过 “重排序”“补充上下文” 进一步优化:
- 重排序(ReRank):用文本排序模型(如阿里云百炼 ReRank 模型)对召回的 Top 20 片段重新打分,筛选出 Top 3-5 个最相关片段,减少无关信息干扰;
- 滑动窗口检索:召回某片段后,补充其前后 N 个片段作为上下文。例如,检索到 “年假申请需提交申请表”,补充前后的 “申请表下载路径”“提交截止时间”,确保信息完整。
(五)生成答案阶段:避免幻觉,提升输出质量
即使检索到相关片段,仍可能出现 “模型捏造答案”“输出不符合要求” 等问题,可从 3 个维度优化:
选择合适的大模型
- 通用场景(如政策问答):选择平衡速度与准确性的模型(如 Qwen2.5-7B);
- 专业场景(如法律、医疗):选择专业领域微调模型(如百炼法律大模型),减少专业术语错误。
优化提示词模板
明确 “限制条件” 和 “输出格式”,例如:
请根据以下参考信息回答用户问题,严格遵守规则:参考信息:{召回片段1}{召回片段2}用户问题:{question}规则:1. 若参考信息中无答案,直接回复“暂无相关信息”,不编造内容;2. 答案分点列出,每点不超过20字;3. 必须引用参考信息中的具体表述(如“根据第3条:XXX”)。
调整模型参数
- 温度(Temperature):设为 0.1-0.3,降低随机性,避免幻觉;
- 最大生成长度:根据片段长度设置(如片段共 500 字,最大生成长度设为 300 字),避免输出过长或过短。
四、RAG 应用实战:以 “企业 HR 问答系统” 为例
结合上述流程与优化策略,构建一个 “企业 HR 问答系统”,具体步骤如下:
文档准备:收集企业 HR 文档(员工手册、年假政策、薪资计算规则等),补充 “远程办公政策”“新员工入职流程” 等高频意图相关内容;
文档解析与切片:将文档转为 Markdown 格式,用 “Markdown 切片” 按 “# 章节→## 子标题” 分割,每个切片包含 1 个完整子主题(如 “年假申请条件”“年假天数计算”);
向量化与存储:用百炼 Embedding 模型向量化切片,存储到阿里云 DashVector(生产环境);
检索优化:
- 检索前:用户问 “我能休年假吗?”,结合用户画像(入职时间 2 年)改写为 “入职 2 年的员工能否申请年假?”;
- 检索后:召回 Top 10 片段,用 ReRank 模型筛选 Top 3,补充前后 1 个句子作为上下文;
生成答案:用百炼大模型,搭配优化后的提示词模板,输出分点答案,并引用手册条款。
五、总结
RAG 的核心价值是 “让大模型基于真实信息回答”,其效果优化需贯穿 “文档准备→检索→生成” 全链路。新手入门时,可先按 “句子切片 + 内存向量存储 + 基础提示词” 搭建最小原型,再逐步通过 “问题改写、重排序、知识库补充” 提升效果。在生产环境中,优先选择云服务向量数据库和专业 Embedding 模型,兼顾性能与运维效率。
最后
为什么要学AI大模型
当下,⼈⼯智能市场迎来了爆发期,并逐渐进⼊以⼈⼯通⽤智能(AGI)为主导的新时代。企业纷纷官宣“ AI+ ”战略,为新兴技术⼈才创造丰富的就业机会,⼈才缺⼝将达 400 万!
DeepSeek问世以来,生成式AI和大模型技术爆发式增长,让很多岗位重新成了炙手可热的新星,岗位薪资远超很多后端岗位,在程序员中稳居前列。

与此同时AI与各行各业深度融合,飞速发展,成为炙手可热的新风口,企业非常需要了解AI、懂AI、会用AI的员工,纷纷开出高薪招聘AI大模型相关岗位。
最近很多程序员朋友都已经学习或者准备学习 AI 大模型,后台也经常会有小伙伴咨询学习路线和学习资料,我特别拜托北京清华大学学士和美国加州理工学院博士学位的鲁为民老师给大家这里给大家准备了一份涵盖了AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频 全系列的学习资料,这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

AI大模型系统学习路线
在面对AI大模型开发领域的复杂与深入,精准学习显得尤为重要。一份系统的技术路线图,不仅能够帮助开发者清晰地了解从入门到精通所需掌握的知识点,还能提供一条高效、有序的学习路径。

但知道是一回事,做又是另一回事,初学者最常遇到的问题主要是理论知识缺乏、资源和工具的限制、模型理解和调试的复杂性,在这基础上,找到高质量的学习资源,不浪费时间、不走弯路,又是重中之重。
AI大模型入门到实战的视频教程+项目包
看视频学习是一种高效、直观、灵活且富有吸引力的学习方式,可以更直观地展示过程,能有效提升学习兴趣和理解力,是现在获取知识的重要途径

光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
海量AI大模型必读的经典书籍(PDF)
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。
600+AI大模型报告(实时更新)
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。
AI大模型面试真题+答案解析
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 8
8 0
0- 0



 已为社区贡献257条内容
已为社区贡献257条内容

所有评论(0)