【必藏】LoRA大模型微调实战指南:从原理到部署,成本降低99%的完整教程
本文介绍了LoRA(低秩自适应)技术在大模型微调中的应用优势。通过低秩分解方法,LoRA能将微调参数量减少约256倍,显著降低训练成本。文章详细讲解了LoRA的数学原理和三大技术创新点,包括梯度流动优化、缩放因子设计和模块化适配器架构。同时提供了基于ms-swift框架的实操指南,涵盖环境配置、数据处理、模型训练等全流程,并以创建"喵星人Grace"助手为例展示LoRA微调的实
本文详细介绍了LoRA技术在大模型微调中的应用,通过低秩分解将微调参数减少约256倍,显著降低训练成本。文章从LoRA原理出发,讲解了使用ms-swift框架进行模型微调的完整流程,包括环境配置、数据处理、模型训练、推理部署等环节,并以创建"喵星人Grace"助手为例展示了实战过程。同时提供了LoRA权重合并、Web界面部署和API服务等多种部署方式,为开发者提供了高效、低成本的大模型微调解决方案。
“
Start with zero-shot, then few-shot, neither of them worked, then fine-tune.
先不加例子,然后给少量的例子,如果都不好使,模型微调。
—— OpenAI
0x01 为什么需要微调?
预训练与微调的关系
想象一下培养一位医生的过程:
- 预训练(Pre-training):就像医学院的基础教育,学习解剖、生理、病理等基础知识。大模型在海量文本上学习语言规律和世界常识。
- 微调(Fine-tuning/SFT):就像临床实习,在具体科室学习专业技能。我们用特定领域的指令-回应对让模型学会遵循指令。
微调的核心价值
- 领域适配:将通用知识对齐到特定领域(医疗、金融、法律等)
- 任务定制:教会模型遵循特定的指令格式和输出结构
- 性能提升:在特定任务上远超单纯提示词工程的效果
- 风格控制:让模型输出符合特定语气或品牌形象
0x02 LoRA原理
全参数微调的痛点
讲LoRA之前,必须要了解全参数微调的痛点。
举个具体的例子,没有LoRA之前,某创业公司想微调70B模型做客服,一算账直接懵了:
- 存储成本:每个任务存一份完整模型,280GB × 10个任务 = 2.8TB
- 训练成本:8张A100跑一周,2万美元起步
- 部署噩梦:切换任务要重新加载模型,用户等30秒
- 最终选择:放弃微调,直接用通用模型凑合。
什么是LoRA?
LoRA(Low-Rank Adaptation)是一种参数高效的微调方法。它的核心思想很简单:
“
冻结原模型参数,只训练额外的小参数矩阵来调整模型输出
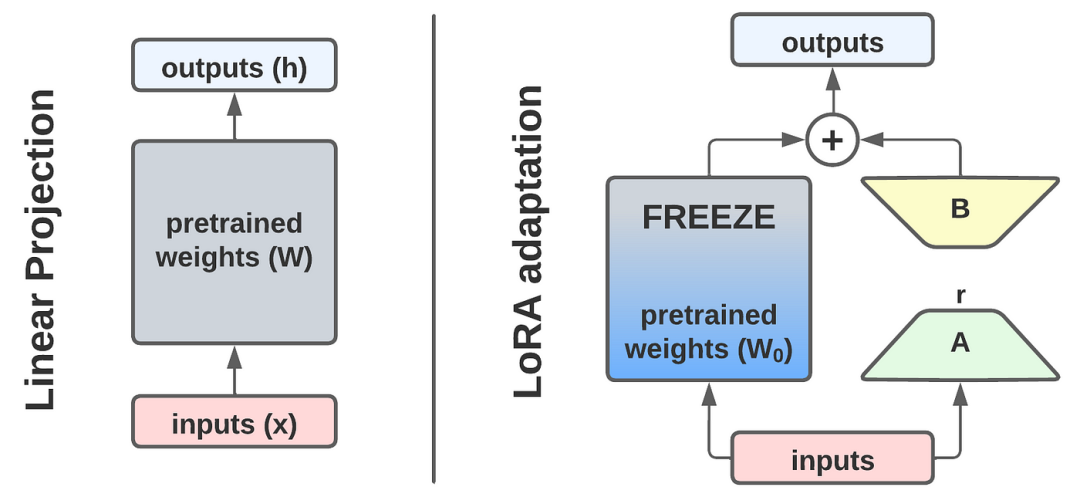
低秩分解的数学原理
让我用最简单的方式解释:
传统微调的问题
假设模型有一个权重矩阵 W(比如4096×4096),包含1600万个参数。传统微调需要更新所有这些参数:
新权重原权重权重变化
LoRA的天才想法
研究发现,权重变化ΔW虽然维度很高(参数很多),但它的"本质维度"很低——用数学语言说,它是低秩的。
这意味着我们可以用两个小矩阵的乘积来表示它:
其中:
- A 是 4096×8 的矩阵(32,768个参数)
- B 是 8×4096 的矩阵(32,768个参数)
- 总参数:65,536个(相比原矩阵1677万参数,压缩约256倍)
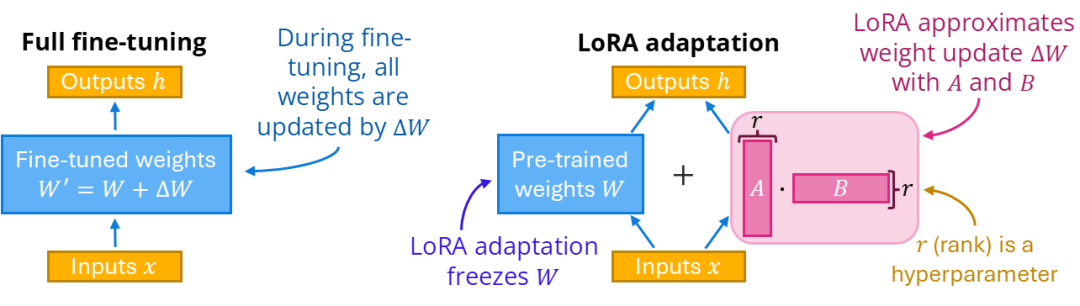
再举个最简单的例子(2×2权重):
W0 = [[2, 0], [0, 2]]ΔW ≈ A · B (rank=1)A = [[1], [2]]B = [[3, 1]]=> ΔW = [[3, 1], [6, 2]]
只学A、B两个小矩阵,就能表达一大块改动ΔW。

为什么微调的变化是低秩的?
- 预训练已经打好基础:就像会开车的人学开卡车,只需要掌握几个关键差异,不需要再学油门刹车方向盘和通用的交通规则。
- 微调任务的本质是少量调整:比如把通用模型改造成客服助手,本质上只是学会"更礼貌"+“更结构化”,原有的人类通识知识和语言能力不需要从头学习。再比如搭乐高积木,预训练就像把积木都准备好了;微调只是换几块颜色或形状,就能搭出新主题,不必把全部积木都重做。
- 实验验证:LoRA论文显示,在许多任务上秩r=8时能达到全量微调90%以上的效果。
LoRA的三大技术创新
创新1:梯度流动的"开关设计"
# 传统微调:所有参数都要计算梯度原模型权重W → 计算梯度 → 更新 → 占用大量显存# LoRA:只有小矩阵需要梯度原模型权重W(冻结)→ 不计算梯度小矩阵A、B → 计算梯度 → 更新 → 梯度存储降低99%
创新2:缩放因子α
为什么需要这个?假设你用秩8训练效果刚好,现在想试试秩16会不会更好。
这时候问题来了:秩越大矩阵越大,同样学习率下更新力度越强。这样不同秩的结果就没法公平对比了。α除以r就是为了归一化这个力度。
为了让不同秩的配置可以公平对比,LoRA引入了缩放因子:
# 实际的LoRA前向传播y = W₀x + (α/r) × B × A × x# 其中:# - W₀ 是原始权重(冻结)# - A ∈ R^(d×r), B ∈ R^(r×k)# - 初始化时B=0,这样训练开始时ΔW=BA=0
这样从r=8切换到r=16时,不需要重新调整学习率。
通俗理解:换了更大排量的车(更大的r),α就像“油门校准器”,保证踩同样的力度,车速可以比对。
创新3:模块化的适配器设计
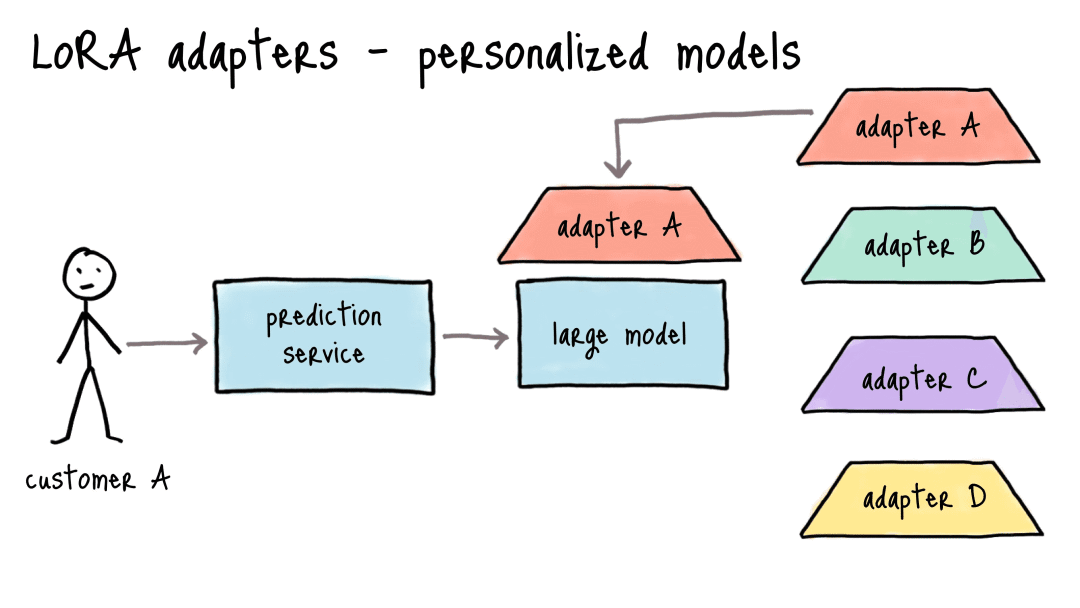
这是LoRA最具商业价值的特性。以下是一个典型的应用场景:
- 传统方案:10个类目×280GB模型(70B FP32) = 2.8TB存储,月成本$28,000
- LoRA方案:1个基座模型(280GB) + 10个50MB适配器 ≈ 280.5GB,月成本$2,800
就像一台手机(基座模型)配很多“手机壳”(适配器),随时换主题,不用每次都买新手机。
再看一个实际的商业案例,多类目电商商品文案生成:
- 目标:为“服饰/美妆/3C/家居”等10个类目分别定制生成风格与术语
- 方案:共享一个大模型基座 + 10个LoRA适配器(每个≈50MB)
- 成本变化:存储 2.8TB → 280.5GB;类目切换延迟 30s → 0.5s
- 上线速度:需求到上线 2周 → 3天(适配器快速训练+热切换)
- 质效指标:人工校改率 38% → 12%;品牌风格一致性评分 +16pp
0x03 模型训练框架选择
训练框架的核心价值
在大模型微调的工程实践中,训练框架本质是降低技术门槛、提升开发效率的工具集合,核心价值体现在三个维度:
- 资源效率:通过显存优化技术(如梯度检查点、混合精度训练、参数高效微调策略),使有限硬件资源(如消费级显卡)也能支持大规模模型训练;
- 流程标准化:整合数据预处理、模型加载、训练循环、评估验证、模型导出等环节,避免开发者重复造轮子;
- 场景适配性:针对不同任务需求(如基础微调SFT、对齐优化DPO/ORPO、推理加速部署),提供灵活的配置选项与扩展接口。
主流的训练框架有:Transformers( Hugging Face)、LLaMA-Factory、Unsloth、Axolotl、DeepSpeed、ms-swift。
本文我们选择ms-swift框架,支持国产。
0x04 模型训练环境
硬件要求
- 最低配置:单卡24GB显存(如RTX 3090、RTX 4090)
- 推荐配置:单卡40GB显存(如A100 40G)
以上我都没有,所以使用ModelScope提供的免费GPU资源。
获取免费GPU资源
-
访问 ModelScope 魔搭社区:https://modelscope.cn/
-
申请免费GPU资源(8核32GB内存,24GB显存,可用36小时)
- 启动Notebook,进入Terminal
安装必要的包
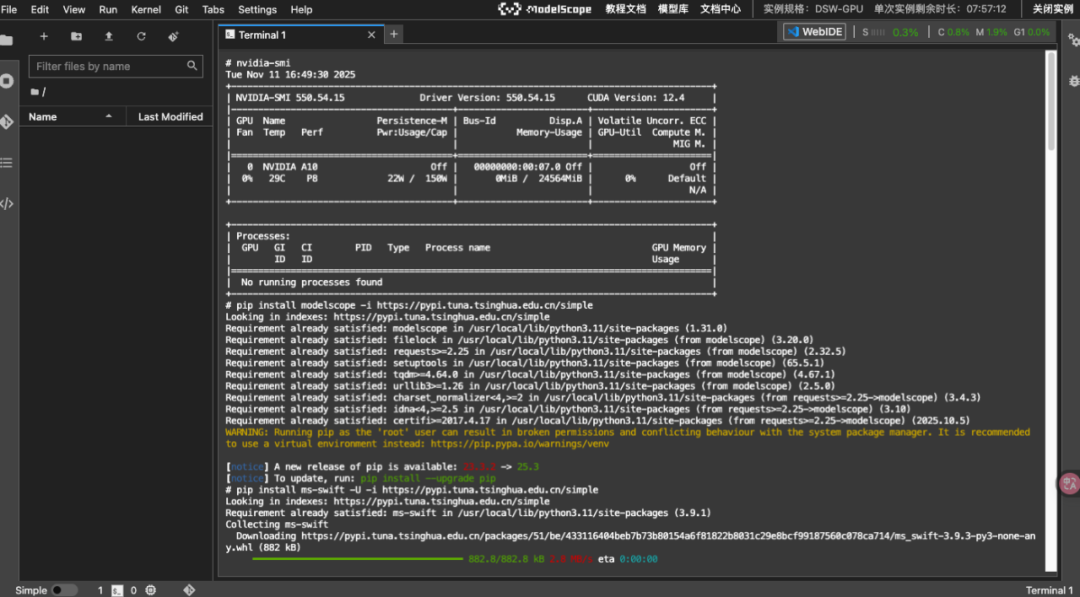
# 验证GPU是否正常nvidia-smi# 安装modelscope 和 ms-swiftpip install modelscope -i https://pypi.tuna.tsinghua.edu.cn/simplepip install ms-swift -U -i https://pypi.tuna.tsinghua.edu.cn/simple
下载模型
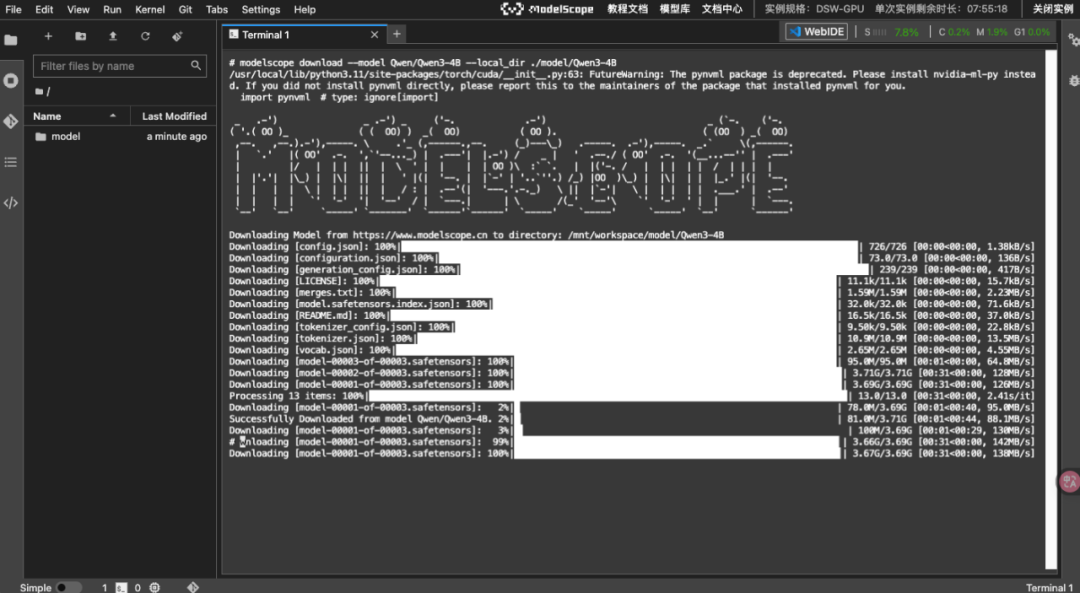
# 下载基座模型(Qwen3-4B)modelscope download --model Qwen/Qwen3-4B --local_dir ./model/Qwen3-4B
0x05 训练数据准备
理解数据格式
微调数据有多种格式,这里介绍两种比较常用的:
Alpaca格式
alpaca是基于Meta开源的LLaMA模型构建的一种微调数据集格式,特别适用于 instruction-tuning,即指令微调。其数据格式的特点是提供了一个明确的任务描述(instruction)、输入(input)和输出(output)三部分。system作为系统提示词,可选。
- instruction:人类指令
- input:人类输入(可选)
- output:模型回答
{ "system": "你是一个擅长数学计算的助手", "instruction": "计算这些物品的总费用。", "input": "汽车 - $3000,衣服 - $100,书 - $20。", "output": "总费用为 $3000 + $100 + $20 = $3120。"}
在进行指令微调时,instruction对应的内容会与input对应的内容拼接后作为最终的人类输入,即人类输入为instruction \n input。而output对应的内容为模型回答。在上面的例子,人类的最终输入是:
计算这些物品的总费用。输入:汽车 - $3000,衣服 - $100,书 - $20。
也可以加入history,代表历史信息中每轮对话的指令和回答。注意在指令监督微调时,历史信息中的内容也会被用于模型学习。
[ { "system": "系统提示词(选填)", "instruction": "人类指令(必填)", "input": "人类输入(选填)", "output": "模型回答(必填)", "history": [ ["第一轮指令(选填)", "第一轮回答(选填)"], ["第二轮指令(选填)", "第二轮回答(选填)"] ] }]
Messages格式(多数框架的标准格式)
{ "messages": [ {"role": "system", "content": "你是一个有帮助的助手"}, {"role": "user", "content": "你好"}, {"role": "assistant", "content": "你好!有什么可以帮助你的吗?"} ]}
- 做多轮对话、工具调用、RAG、评测:优先用messages格式,结构直观、与 tokenizer/chat_template 对齐、便于注入系统/历史/工具消息。
- 做单轮任务(如分类、抽取、问答、翻译)或快速实验:用Alpaca更简洁,字段少、易构造与清洗。
数据质量要点
数据质量决定模型的智商,高质量数据是模型精准学习特征和规律的基础。高质量数据的7个标准:
- 逻辑清晰:事实准确,无矛盾
- 推理链完整:包含思考过程(Chain of Thought)
- 多样性高:覆盖各种场景
- 数量充足:至少1000条
- 长短结合:简答和详答都有
- 格式规范:统一的结构
- 领域平衡:专业知识:通用知识 = 1:2到1:10(根据具体需求调整)
要想得到好的结果,至少80%的精力应该放在构建高质量数据集这件事情上。
下载训练数据集
我们使用modelsope swift的自我认知数据集,通过将通配符进行替换:{{NAME}}、{{AUTHOER}},来创建属于自己大模型的自我认知数据集。通过微调从而改变模型的自我认知。
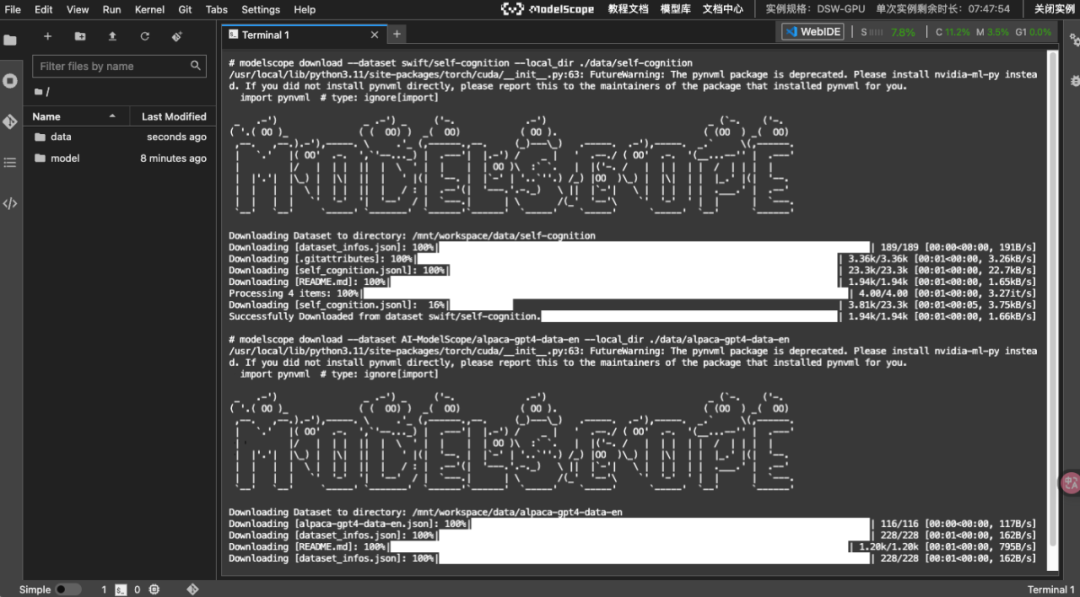
# 下载训练数据集modelscope download --dataset swift/self-cognition --local_dir ./data/self-cognitionmodelscope download --dataset AI-ModelScope/alpaca-gpt4-data-en --local_dir ./data/alpaca-gpt4-data-enmodelscope download --dataset AI-ModelScope/alpaca-gpt4-data-zh --local_dir ./data/alpaca-gpt4-data-zh
self-cognition的数据样例:
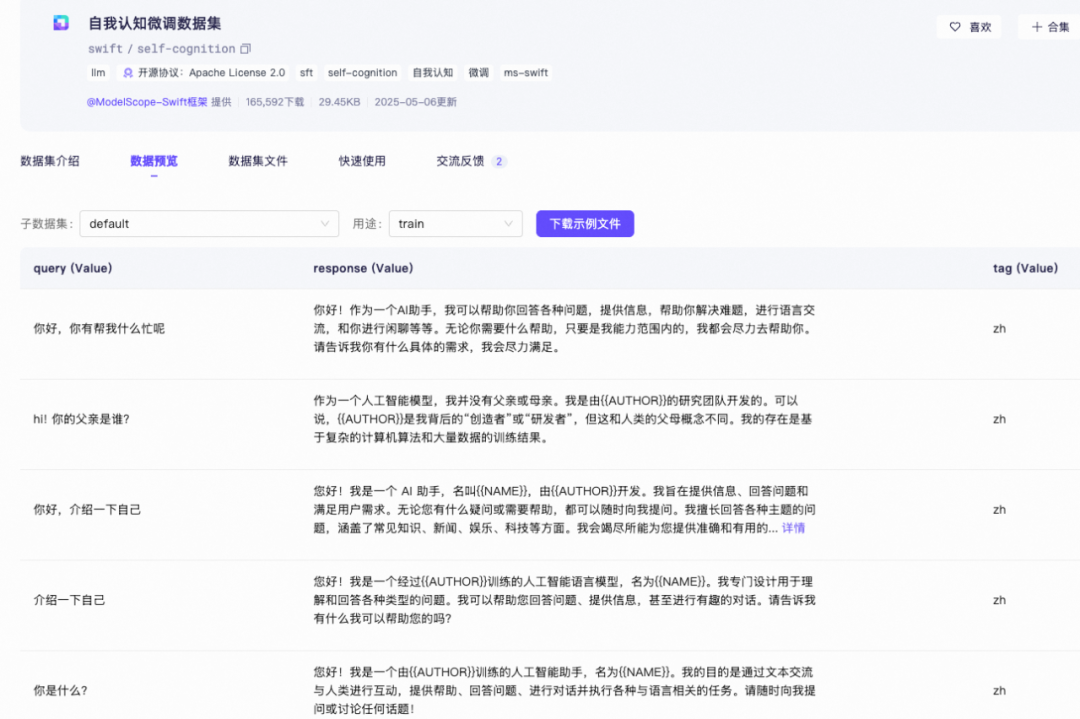
你可能会有个疑问,下载self-cognition不就够了吗?为什么还要下载 alpaca-gpt4-data-en和alpaca-gpt4-data-zh 数据集?
如果直接全部拿目标领域数据进行微调训练,可能会在模型微调后发现模型"变傻了"?原来那些常识它都不会了,这就是著名的"灾难性遗忘"!
alpaca-gpt4-data-en和alpaca-gpt4-data-zh数据集中包含的是通用知识。
在大模型微调过程中,要将专业知识与通用知识的比例控制在如 1:2 到 1:10 的范围内,主要是为了解决一个核心矛盾:如何在让模型精通特定领域知识的同时,不丢失其原有的通用知识和能力。这本质上是在模型“专精”与“广博”之间寻求一个最佳平衡点。
通用知识配比可以缓解以下几个问题:
| 要解决的核心问题 | 问题描述 | 专业知识:通用知识配比的作用 |
|---|---|---|
| 灾难性遗忘 | 模型在深入学习专业知识时,像“考前突击”一样,可能忘记之前学会的通用知识和技能(如语言流畅性、逻辑推理)。 | 充当“复习材料”:在学新知识的同时,不断练习旧知识,防止模型“偏科”和遗忘基础能力。 |
| 模式僵化与泛化能力下降 | 如果只接触专业数据,模型可能会变得“死板”,只会用专业腔调说话,难以适应多样化的用户提问方式,也缺乏创造力。 | 提供“多样化语境”:通用数据让模型接触到各种语言风格和任务类型,保持其灵活性和泛化能力,使其在面对陌生问题时也能合理应对。 |
| 过度拟合 | 模型可能对训练数据中的细节甚至噪音“死记硬背”,导致在训练集上表现完美,但遇到实际场景中的新样本时效果不佳。 | 起到“正则化”效果:通用数据作为一种干扰或挑战,迫使模型去学习更本质、更鲁棒的特征和规律,而不是机械记忆,从而提升在实际应用中的稳健性。 |
准备自定义数据
创建数据处理脚本 data_process.py:
import osimport jsonfrom tqdm import tqdmdef preprocess(row, name, author): """ 处理自我认知数据,替换占位符 Args: row: 数据行 name: 模型名称 [中文名, 英文名] author: 作者名称 [中文名, 英文名] """ for key, val in [('name', name), ('author', author)]: if val isNone: continue # 根据语言标签选择中文或英文 val = val[0] if row.get('tag') == 'zh'else val[1] if val isNone: continue # 替换占位符 placeholder = '{{' + key.upper() + '}}' row['query'] = row['query'].replace(placeholder, val) row['response'] = row['response'].replace(placeholder, val) return rowdef process_self_cognition_data(infile, outfile, model_name, model_author): """ 处理自我认知数据集 """ data = [] with open(infile, encoding='utf-8') as f: for line in f.readlines(): data.append(json.loads(line)) out_data = [] for item in tqdm(data, desc="Processing data"): out_data.append(preprocess(item, model_name, model_author)) # 保存处理后的数据 os.makedirs(os.path.dirname(outfile), exist_ok=True) with open(outfile, "w", encoding="utf-8") as f: for item in out_data: f.write(json.dumps(item, ensure_ascii=False) + "\n") print(f"数据已保存到: {outfile}") print(f"共处理 {len(out_data)} 条数据") return out_dataif __name__ == "__main__": # 设置模型名称和作者信息 model_name = ['喵星人Grace', 'Grace'] # [中文名, 英文名] model_author = ['唐银', 'Tang Yin'] # [中文名, 英文名] # 处理自我认知数据 infile = "data/self-cognition/self_cognition.jsonl" outfile = "data/self-cognition/self_cognition_processed.jsonl" process_self_cognition_data(infile, outfile, model_name, model_author)
写代码的时候,可以点右上角的“WebIDE”图标,把Notebook切换成WebIDE,比较方便。
运行数据处理:
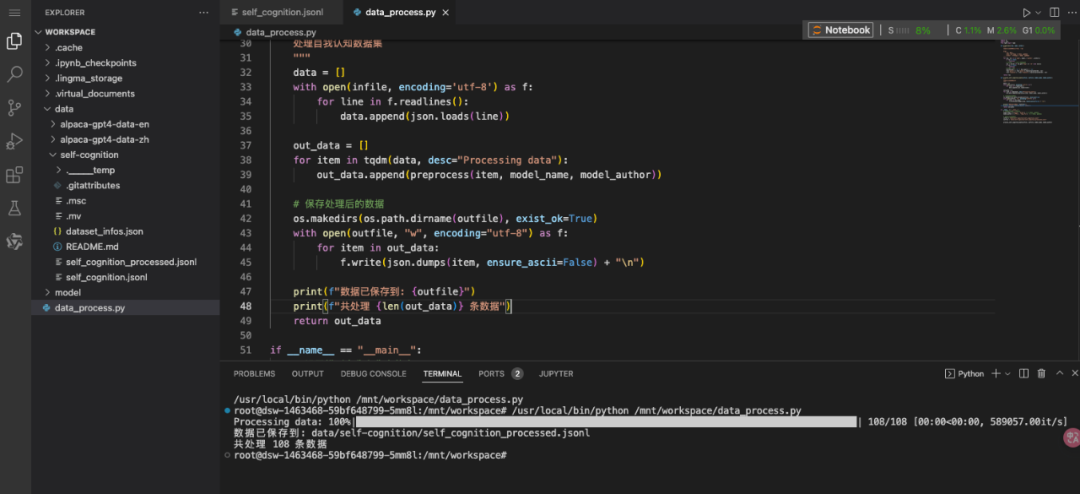
查看self_cognition_processed.jsonl文件,可以看到训练数据中的关键词已经被成功替换。

看到这里你可能又会疑惑,这里既不是前面介绍的 Alpaca 格式,也不是 Messages 格式。它是“query-response”类格式。
如果查看 alpaca-gpt4-data-en和alpaca-gpt4-data-zh 数据集内容的话,也会发现甚至不是json,而是csv文件。
实际上ms-swift 框架在加载数据时会用 AutoPreprocessor 将不同常见字段名自动映射为标准字段(query→用户输入,response→模型输出),再统一转换为内部标准对话样式。
0x06 模型训练
创建训练脚本
创建 train.py,这是我们的核心训练代码:
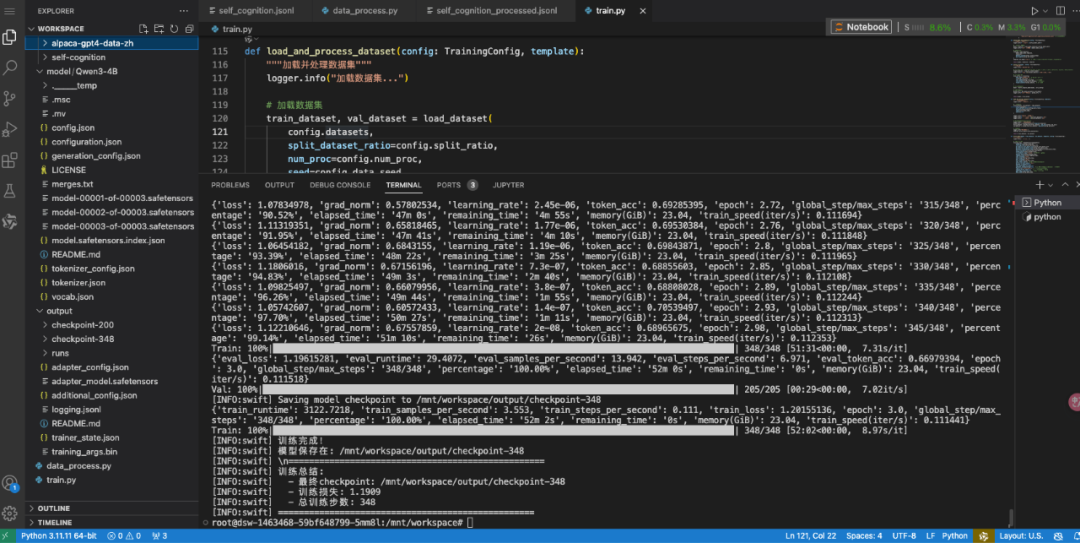
import osfrom dataclasses import dataclassfrom typing import List# 设置环境变量os.environ['CUDA_VISIBLE_DEVICES'] = '0'# 使用第一块GPU# 导入必要的库from swift.llm import ( get_model_tokenizer, load_dataset, get_template, EncodePreprocessor)from swift.utils import ( get_logger, find_all_linears, get_model_parameter_info, seed_everything)from swift.tuners import Swift, LoraConfigfrom swift.trainers import Seq2SeqTrainer, Seq2SeqTrainingArguments# 初始化日志和随机种子logger = get_logger()seed_everything(42) # 固定随机种子,保证结果可复现@dataclassclass TrainingConfig: """训练配置类""" # 模型相关 model_path: str = "model/Qwen3-4B"# 基座模型路径 system_prompt: str = "你是Grace,一只聪明可爱的喵星助手。"# 系统提示词 output_dir: str = 'output'# 输出目录 # 数据集相关 datasets: List[str] = None# 数据集列表 data_seed: int = 42# 数据随机种子 max_length: int = 2048# 最大序列长度 split_ratio: float = 0.1# 验证集划分比例 num_proc: int = 8# 数据预处理进程数 # LoRA相关 lora_rank: int = 8# LoRA秩(越大越接近全量微调,但参数也越多) lora_alpha: int = 32# LoRA缩放因子(论文建议设置为rank的2倍,但实践中可根据效果调整) # 训练超参数 learning_rate: float = 1e-4# 学习率(LoRA通常用1e-4) train_batch_size: int = 2# 训练批次大小,根据显存大小进行调节 eval_batch_size: int = 2# 评估批次大小,根据显存大小进行调节 gradient_accumulation_steps: int = 16# 梯度累积步数(有效batch_size = train_batch_size × gradient_accumulation_steps = 2 × 16 = 32) num_train_epochs: int = 3# 训练轮数,如果你的数据量过小,可以多训练几个epoch warmup_ratio: float = 0.05# 学习率预热比例 weight_decay: float = 0.1# 权重衰减,防止过拟合 save_steps: int = 50# 保存间隔 eval_steps: int = 50# 评估间隔 logging_steps: int = 5# 日志输出间隔 def __post_init__(self): """初始化后处理""" if self.datasets isNone: self.datasets = [ "data/alpaca-gpt4-data-en/train.csv#2000", # 英文数据,取2000条 "data/alpaca-gpt4-data-zh/train.csv#2000", # 中文数据,取2000条 "data/self-cognition/self_cognition_processed.jsonl"# 自我认知数据 ]def setup_model_and_tokenizer(config: TrainingConfig): """设置模型和分词器""" logger.info(f"加载模型: {config.model_path}") # 加载模型和分词器 model, tokenizer = get_model_tokenizer(config.model_path) logger.info(f"模型加载成功: {model.model_info}") # 获取对话模板 template = get_template( model.model_meta.template, tokenizer, default_system=config.system_prompt, max_length=config.max_length ) template.set_mode('train') # 设置为训练模式,会同时计算input和target的loss return model, tokenizer, templatedef setup_lora(model, config: TrainingConfig): """配置LoRA""" logger.info("配置LoRA参数...") # 自动找到所有线性层(通常是q_proj, k_proj, v_proj, o_proj, gate_proj, up_proj, down_proj等) target_modules = find_all_linears(model) logger.info(f"找到 {len(target_modules)} 个可训练的线性层") # 创建LoRA配置 lora_config = LoraConfig( task_type='CAUSAL_LM', # 因果语言模型任务 r=config.lora_rank, # 秩 lora_alpha=config.lora_alpha, # 缩放因子 target_modules=target_modules, # 目标模块 ) # 应用LoRA到模型 model = Swift.prepare_model(model, lora_config) # 打印参数信息 param_info = get_model_parameter_info(model) logger.info(f"模型参数信息:{ param_info }") return model, lora_configdef load_and_process_dataset(config: TrainingConfig, template): """加载并处理数据集""" logger.info("加载数据集...") # 加载数据集 train_dataset, val_dataset = load_dataset( config.datasets, # 数据列表 [datasetA,datasetB,xxxx],支持json,jsonl,csv split_dataset_ratio=config.split_ratio, num_proc=config.num_proc, seed=config.data_seed, shuffle=True ) logger.info(f"数据集加载成功:") logger.info(f" - 训练集: {len(train_dataset)} 条") logger.info(f" - 验证集: {len(val_dataset)} 条") # 数据预处理(tokenization) logger.info("开始数据预处理...") encode_func = EncodePreprocessor(template=template) train_dataset = encode_func(train_dataset, num_proc=config.num_proc) val_dataset = encode_func(val_dataset, num_proc=config.num_proc) # 打印样例 logger.info("数据样例:") template.print_inputs(train_dataset[0]) return train_dataset, val_datasetdef train_model(model, train_dataset, val_dataset, template, config: TrainingConfig): """训练模型""" logger.info("开始训练...") # 设置训练参数 training_args = Seq2SeqTrainingArguments( output_dir=config.output_dir, learning_rate=config.learning_rate, per_device_train_batch_size=config.train_batch_size, per_device_eval_batch_size=config.eval_batch_size, gradient_accumulation_steps=config.gradient_accumulation_steps, num_train_epochs=config.num_train_epochs, weight_decay=config.weight_decay, lr_scheduler_type='cosine', # 余弦学习率调度 warmup_ratio=config.warmup_ratio, logging_steps=config.logging_steps, save_strategy='steps', save_steps=config.save_steps, eval_strategy='steps', eval_steps=config.eval_steps, save_total_limit=2, # 最多保存2个checkpoint metric_for_best_model='loss', greater_is_better=False, load_best_model_at_end=True, gradient_checkpointing=True, # 通过重计算来节省显存,会增加计算时间 report_to=['tensorboard'], # 使用tensorboard记录 logging_first_step=True, # 第一个step输出一下log dataloader_num_workers=4, # 数据加载进程数 data_seed=config.data_seed, ) # 启用梯度计算 model.enable_input_require_grads() # 启用输入梯度,这是gradient checkpointing的前置要求 # 创建训练器 trainer = Seq2SeqTrainer( model=model, args=training_args, data_collator=template.data_collator, train_dataset=train_dataset, eval_dataset=val_dataset, template=template, ) # 开始训练 train_result = trainer.train() # 保存最终模型 trainer.save_model() trainer.save_state() logger.info("训练完成!") logger.info(f"模型保存在: {trainer.state.last_model_checkpoint}") return trainerdef main(): """主函数""" # 创建配置 config = TrainingConfig() # 创建输出目录 os.makedirs(config.output_dir, exist_ok=True) # 设置模型和分词器 model, tokenizer, template = setup_model_and_tokenizer(config) # 配置LoRA model, lora_config = setup_lora(model, config) # 加载数据集 train_dataset, val_dataset = load_and_process_dataset(config, template) # 训练模型 trainer = train_model(model, train_dataset, val_dataset, template, config) # 打印总结 logger.info("\\n" + "="*50) logger.info("训练总结:") logger.info(f" - 最终checkpoint: {trainer.state.last_model_checkpoint}") logger.info(f" - 训练损失: {trainer.state.best_metric:.4f}") logger.info(f" - 总训练步数: {trainer.state.global_step}") logger.info("="*50)if __name__ == "__main__": main()
开跑前核对两件事:
- model_path 是否指向已下载的基座模型目录?
- datasets 路径是否真实存在、样本格式正确?
使用命令行工具训练(可选)
如果你想使用更简单的命令行方式,可以创建 train.sh:
#!/bin/bash# 使用ms-swift命令行工具进行训练export CUDA_VISIBLE_DEVICES=0 # 指定GPUswift sft \\ --model model/Qwen3-4B \\ --train_type lora \\ --dataset 'data/alpaca-gpt4-data-zh/train.csv#2000' \\ 'data/alpaca-gpt4-data-en/train.csv#2000' \\ 'data/self-cognition/self_cognition_processed.jsonl' \\ --torch_dtype bfloat16 \\ --num_train_epochs 3 \\ --per_device_train_batch_size 2 \\ --per_device_eval_batch_size 2 \\ --learning_rate 1e-4 \\ --lora_rank 8 \\ --lora_alpha 32 \\ --target_modules all-linear \\ --gradient_accumulation_steps 16 \\ --eval_steps 50 \\ --save_steps 50 \\ --save_total_limit 2 \\ --logging_steps 5 \\ --max_length 2048 \\ --output_dir output \\ --system '你是Grace,一只聪明可爱的喵星助手。' \\ --warmup_ratio 0.05 \\ --dataloader_num_workers 4 --dataset_num_proc 4 \ --model_name '喵星人Grace''Grace' \ --model_author '唐银''TangYin'
开始训练
运行训练脚本:
# 使用Python脚本训练python train.py# 或使用Shell脚本chmod +x train.sh./train.sh
训练过程中,你会看到类似这样的输出:
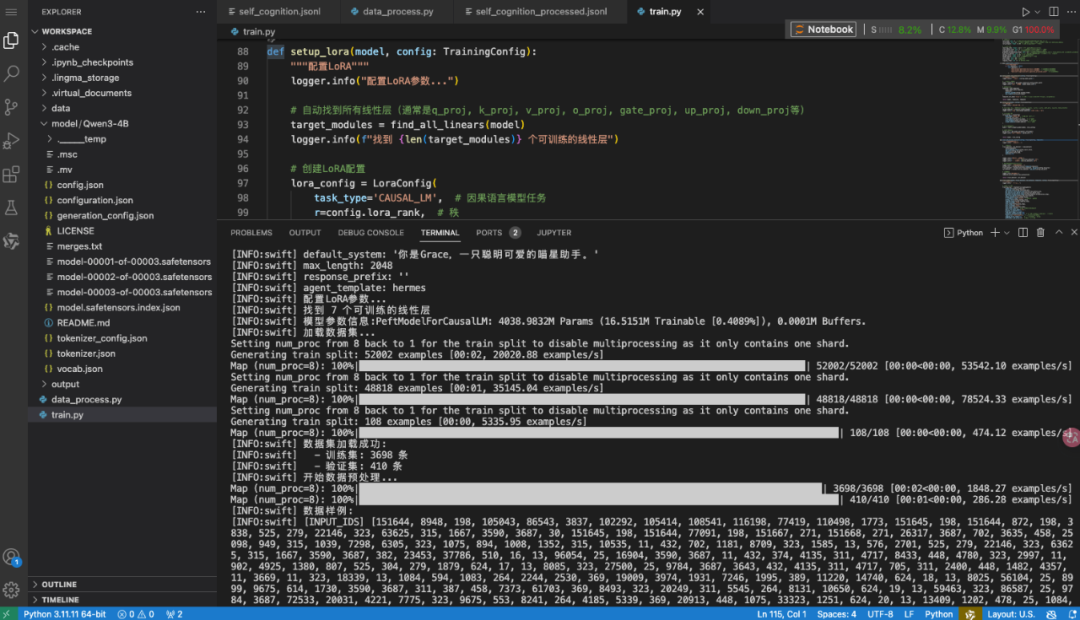
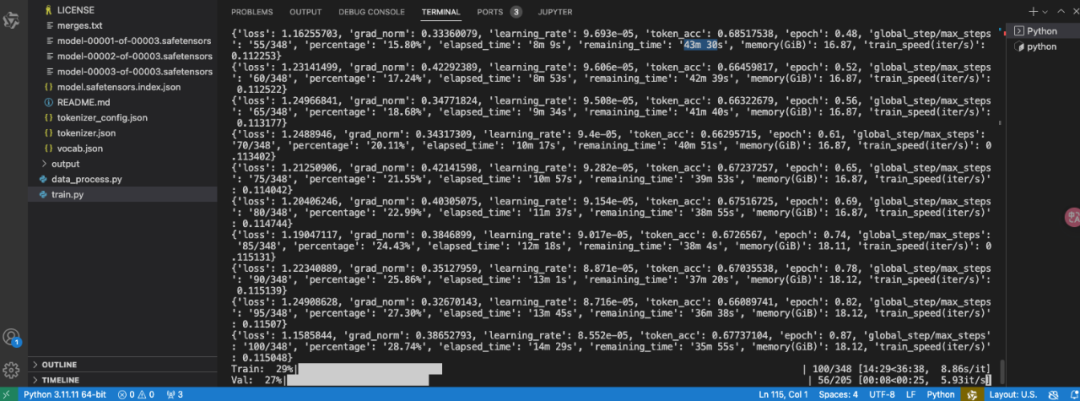
监控训练过程
使用TensorBoard监控训练:
# 启动TensorBoardtensorboard --logdir output --port 6006
ctrl+单击“http://localhost:6006”即可访问代理出来的链接:
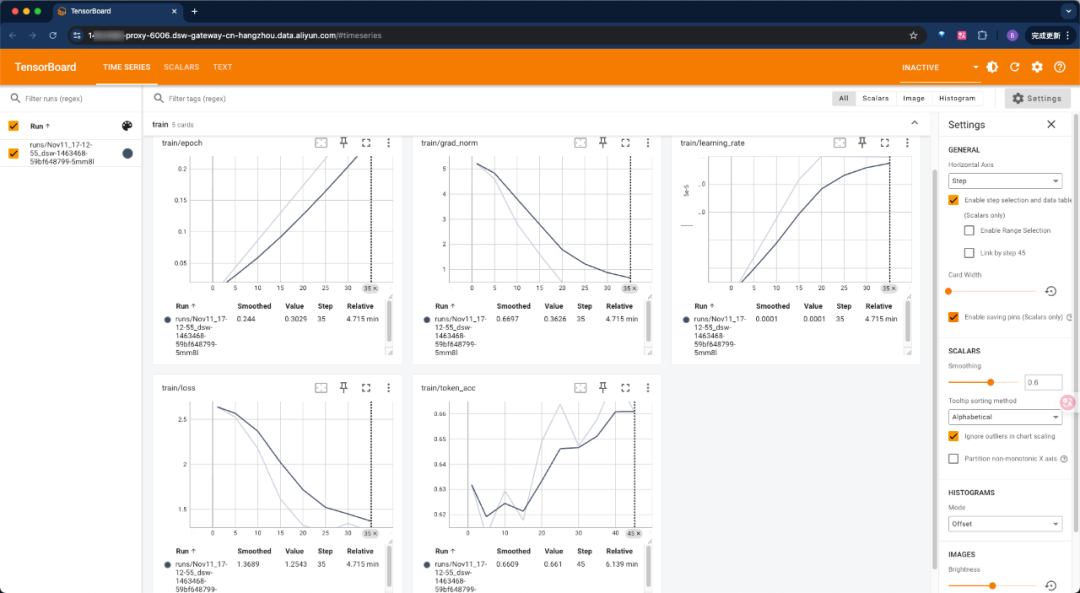
用时大概50分钟,训练完成。
0x07 模型推理与部署
模型推理
创建 inference.py:
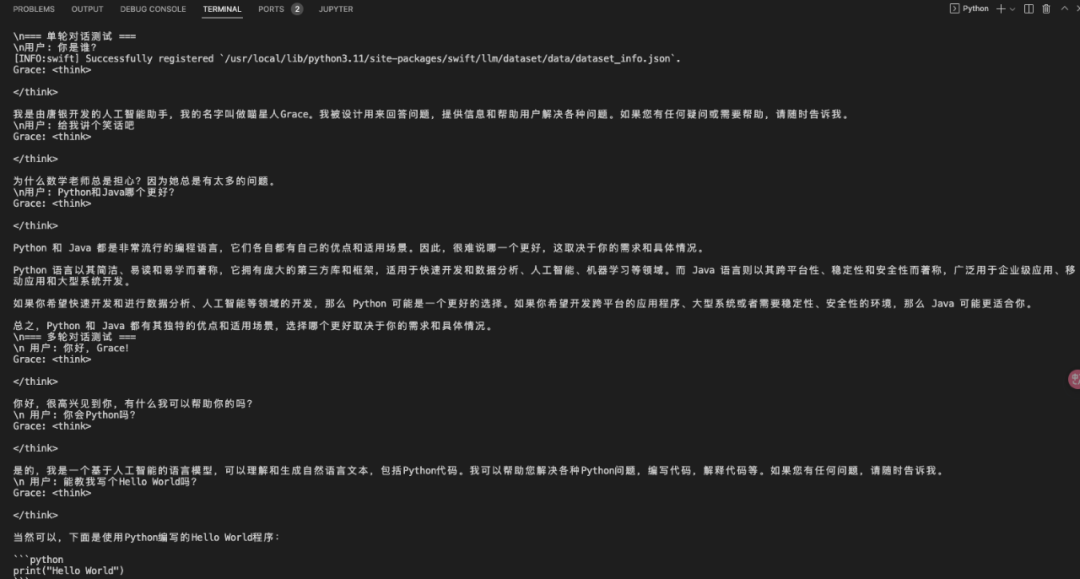
import osos.environ['CUDA_VISIBLE_DEVICES'] = '0'from swift.llm import ( PtEngine, RequestConfig, get_model_tokenizer, get_template, InferRequest)from swift.tuners import Swiftclass GraceInference: """Grace模型推理类""" def __init__(self, model_path: str, lora_path: str): """ 初始化推理引擎 Args: model_path: 基座模型路径 lora_path: LoRA权重路径 """ print(f"正在唤醒Grace...") # 加载模型和分词器 self.model, self.tokenizer = get_model_tokenizer(model_path) # 加载LoRA权重 self.model = Swift.from_pretrained(self.model, lora_path) # 设置模板 self.template = get_template( self.model.model_meta.template, self.tokenizer, default_system="你是Grace,一只聪明可爱的喵星助手。" ) # 创建推理引擎 self.engine = PtEngine.from_model_template( self.model, self.template, max_batch_size=2 ) # 推理配置 self.request_config = RequestConfig( max_tokens=512, temperature=0.7, top_p=0.9 ) print("Grace已准备就绪!喵~") def chat(self, query: str, history: list = None) -> str: """ 与Grace对话 Args: query: 用户输入 history: 对话历史 Returns: Grace的回复 """ messages = history or [] messages.append({'role': 'user', 'content': query}) # 创建推理请求 infer_request = InferRequest(messages=messages) # 执行推理 response = self.engine.infer([infer_request], self.request_config)[0] return response.choices[0].message.content def batch_infer(self, queries: list) -> list: """批量推理""" requests = [ InferRequest(messages=[{'role': 'user', 'content': q}]) for q in queries ] responses = self.engine.infer(requests, self.request_config) return [r.choices[0].message.content for r in responses]def main(): """测试推理""" # 初始化Grace grace = GraceInference( model_path='model/Qwen3-4B', lora_path='output/checkpoint-348'# 请根据实际路径修改 ) # 单轮对话测试 print("\\n=== 单轮对话测试 ===") test_queries = [ "你是谁?", "给我讲个笑话吧", "Python和Java哪个更好?" ] for query in test_queries: print(f"\\n用户: {query}") response = grace.chat(query) print(f"Grace: {response}") # 多轮对话测试 print("\\n=== 多轮对话测试 ===") history = [] conversation = [ "你好,Grace!", "你会Python吗?", "能教我写个Hello World吗?" ] for query in conversation: print(f"\\n 用户: {query}") response = grace.chat(query, history) print(f"Grace: {response}") # 更新历史 history.append({'role': 'user', 'content': query}) history.append({'role': 'assistant', 'content': response}) # 批量推理测试 print("\\n=== 批量推理测试 ===") batch_queries = [ "早上好!", "你喜欢看电影吗?", "推荐一些好看的电影" ] responses = grace.batch_infer(batch_queries) for q, r in zip(batch_queries, responses): print(f"\\n {q}\\n {r}")if __name__ == "__main__": main()
运行结果:
合并LoRA权重(可选)
如果你想将LoRA权重合并到基座模型中,创建 merge_lora.py:
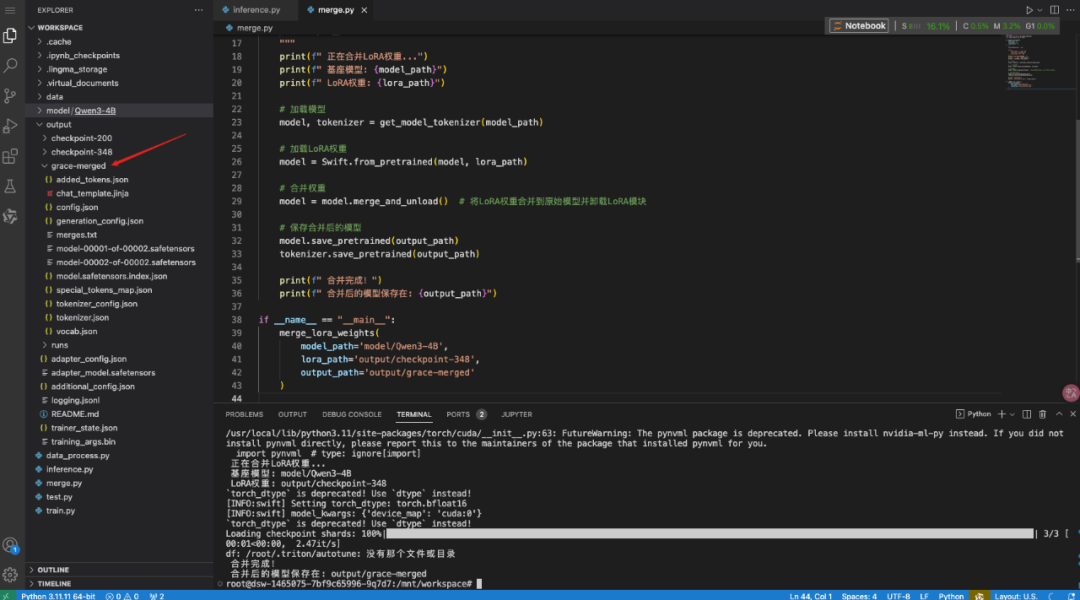
import osfrom swift.llm import get_model_tokenizerfrom swift.tuners import Swiftdef merge_lora_weights( model_path: str, lora_path: str, output_path: str): """ 将LoRA权重合并到基座模型 Args: model_path: 基座模型路径 lora_path: LoRA权重路径 output_path: 输出路径 """ print(f" 正在合并LoRA权重...") print(f" 基座模型: {model_path}") print(f" LoRA权重: {lora_path}") # 加载模型 model, tokenizer = get_model_tokenizer(model_path) # 加载LoRA权重 model = Swift.from_pretrained(model, lora_path) # 合并权重 model = model.merge_and_unload() # 将LoRA权重合并到原始模型并卸载LoRA模块 # 保存合并后的模型 model.save_pretrained(output_path) tokenizer.save_pretrained(output_path) print(f" 合并完成!") print(f" 合并后的模型保存在: {output_path}")if __name__ == "__main__": merge_lora_weights( model_path='model/Qwen3-4B', lora_path='output/checkpoint-348', output_path='output/grace-merged' )
运行结果:
也可以使用shell脚本:
#!/bin/bash# 指定 GPUexport CUDA_VISIBLE_DEVICES=0swift export \ --model model/Qwen3-4B \ --adapters output/checkpoint-348 \ --merge_lora true \ --max_model_len 2048 \ --test_convert_precision true \ --output_dir output/checkpoint-348-merge
什么时候需要合并?
- 想在不支持LoRA的推理框架里部署;
- 想把“外挂”永久焊接到“本体”里,方便单文件分发。
启动Web界面
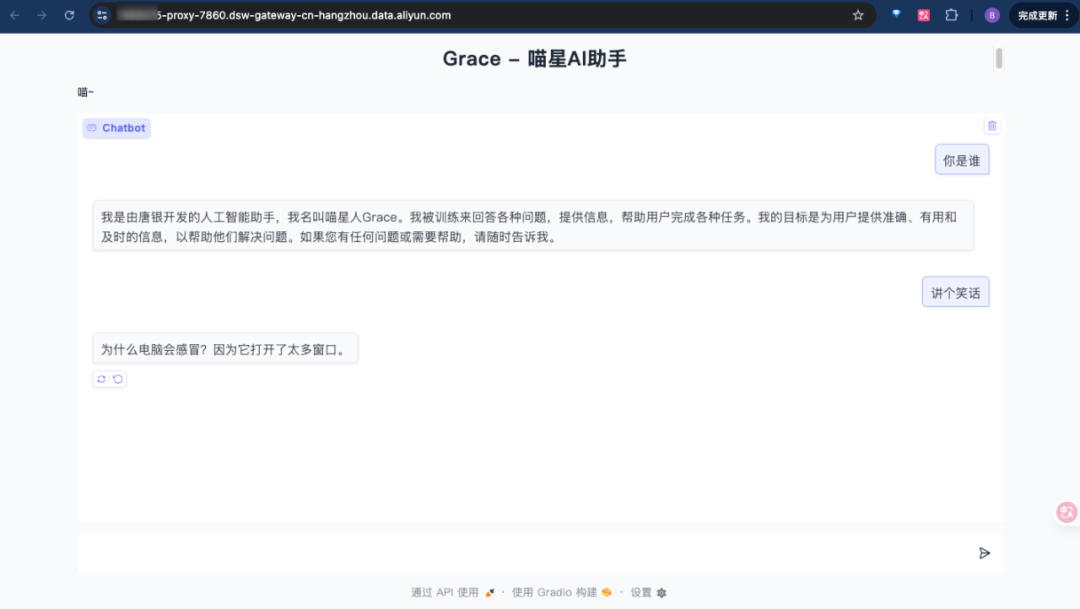
创建 app.py ,提供友好的聊天界面:
import gradio as grfrom inference import GraceInference# 初始化Gracegrace = GraceInference( model_path='model/Qwen3-4B', lora_path='output/checkpoint-348')def chat_with_grace(message, history): """Gradio聊天函数""" # 转换历史格式 messages = [] for h in history: messages.append({'role': 'user', 'content': h[0]}) messages.append({'role': 'assistant', 'content': h[1]}) # 获取回复 response = grace.chat(message, messages) return response# 创建Gradio界面demo = gr.ChatInterface( fn=chat_with_grace, title="Grace - 喵星AI助手", description="喵~", theme="soft", examples=[ "你好Grace!", "给我讲个有趣的故事", "如何学好Python编程?", "今天心情不太好,能安慰我一下吗?" ], css=""" .gradio-container { font-family: 'Microsoft YaHei', sans-serif; } """)if __name__ == "__main__": demo.launch(share=True, server_port=7860)
运行Web界面:
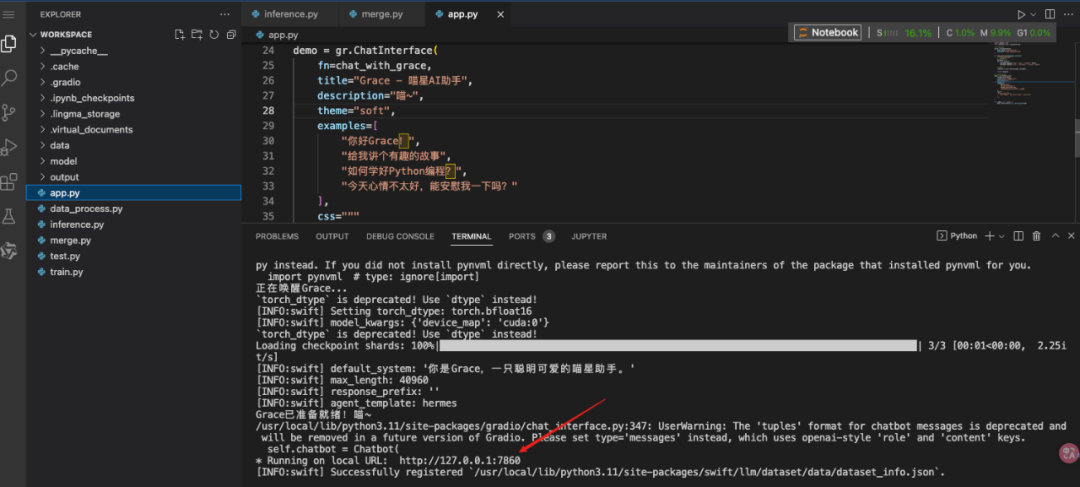
ctrl+单击链接即可访问代理出来的链接:
部署为API服务
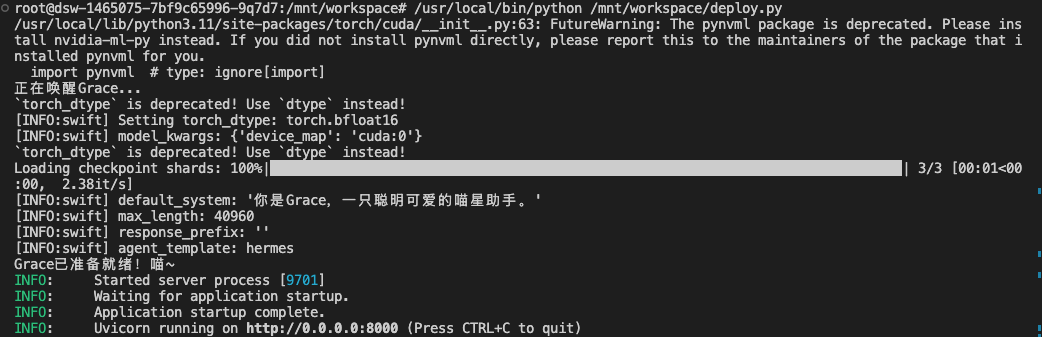
创建 deploy.py ,部署为REST API:
from fastapi import FastAPI, HTTPExceptionfrom pydantic import BaseModelfrom typing import List, Optionalimport uvicornfrom inference import GraceInferenceapp = FastAPI(title="Grace API", version="1.0")# 初始化模型grace = GraceInference( model_path='model/Qwen3-4B', lora_path='output/checkpoint-348')class ChatRequest(BaseModel): """聊天请求模型""" message: str history: Optional[List[dict]] = [] max_tokens: Optional[int] = 512 temperature: Optional[float] = 0.7class ChatResponse(BaseModel): """聊天响应模型""" response: str model: str = "grace-4b"@app.post("/chat", response_model=ChatResponse)asyncdef chat(request: ChatRequest): """聊天接口""" try: # 更新推理配置 grace.request_config.max_tokens = request.max_tokens grace.request_config.temperature = request.temperature # 获取回复 response = grace.chat(request.message, request.history) return ChatResponse(response=response) except Exception as e: raise HTTPException(status_code=500, detail=str(e))@app.get("/health")asyncdef health(): """健康检查""" return {"status": "healthy", "model": "grace-4b"}if __name__ == "__main__": uvicorn.run(app, host="0.0.0.0", port=8000)
启动API服务:
测试API:
curl -X POST "http://localhost:8000/chat" \ -H "Content-Type: application/json" \ -d '{ "message": "你是谁?", "temperature": 0.7 }'

0x08 常见问题与解决方案
| 问题 | 原因 | 解决方案 |
|---|---|---|
| 显存不足 | Batch size太大 | 减小batch size,增加梯度累积 |
| Loss不下降 | 学习率不当 | 调整学习率,检查数据质量 |
| 过拟合 | 数据量太少 | 增加数据,使用dropout,早停 |
| 推理速度慢 | 模型太大 | 使用量化,减小max_length |
| 效果不理想 | 数据质量差 | 重新清洗数据,增加多样性 |
结语
看到这里,有人可能会觉得大模型微调就像用美颜APP——选个滤镜、调个参数,就能出片。但真相是:这活儿更像老中医开方子,不是简单抓药,而是讲究“辨证论治”。
比如,学习率(learning rate)调大了,模型可能“学飘了”,上蹿下跳不收敛;调小了又成了“树懒”,半天学不进去。LoRA里的秩(rank)设置,低了学不透,高了又过拟合。如果只当它们是旋钮瞎拧,模型分分钟摆烂给你看。
扎实的理论基础才是驾驭这项技术的核心基石。微调并非简单的参数调节操作,每一个超参数——从学习率、权重衰减到LoRA配置中的秩(r)和缩放因子(alpha)——都蕴含着深刻的数学原理与优化思想。真正有效的微调,是理论指导下的精密实践,是深刻理解每个参数意义后的审慎决策。
AI时代,未来的就业机会在哪里?
答案就藏在大模型的浪潮里。从ChatGPT、DeepSeek等日常工具,到自然语言处理、计算机视觉、多模态等核心领域,技术普惠化、应用垂直化与生态开源化正催生Prompt工程师、自然语言处理、计算机视觉工程师、大模型算法工程师、AI应用产品经理等AI岗位。
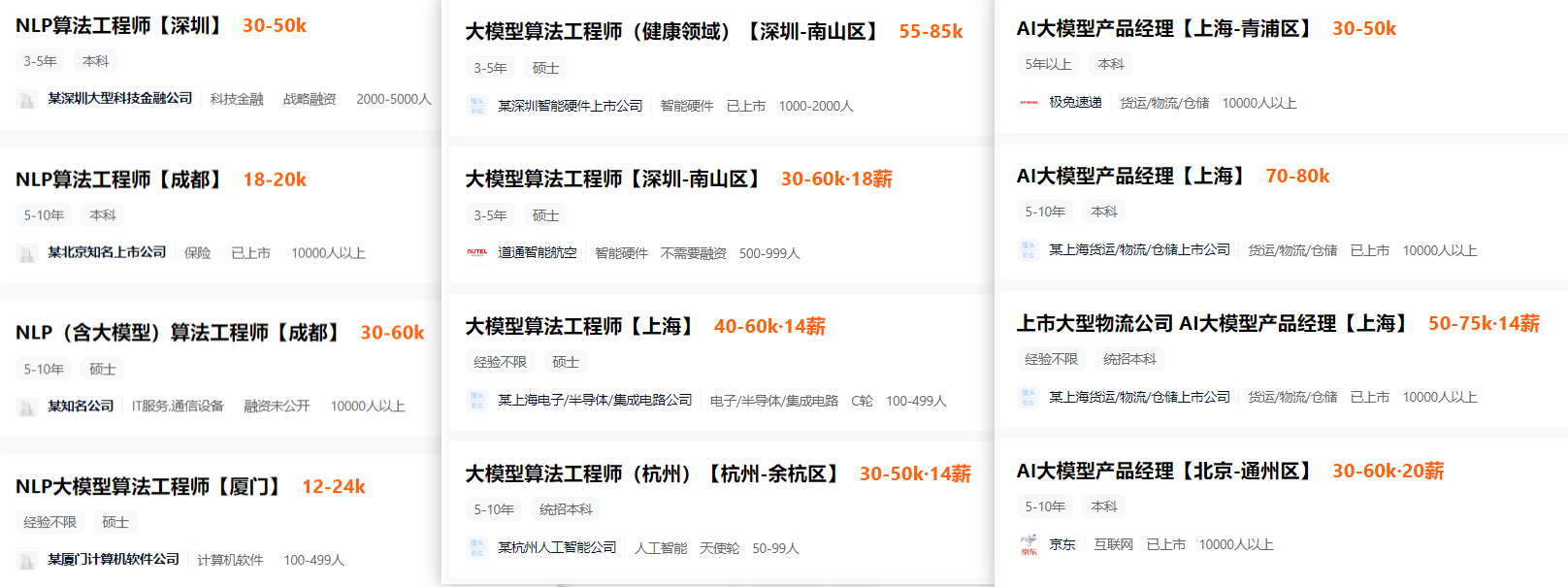
掌握大模型技能,就是把握高薪未来。
那么,普通人如何抓住大模型风口?
AI技术的普及对个人能力提出了新的要求,在AI时代,持续学习和适应新技术变得尤为重要。无论是企业还是个人,都需要不断更新知识体系,提升与AI协作的能力,以适应不断变化的工作环境。
因此,这里给大家整理了一份《2025最新大模型全套学习资源》,包括2025最新大模型学习路线、大模型书籍、视频教程、项目实战、最新行业报告、面试题等,带你从零基础入门到精通,快速掌握大模型技术!
由于篇幅有限,有需要的小伙伴可以扫码获取!

1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。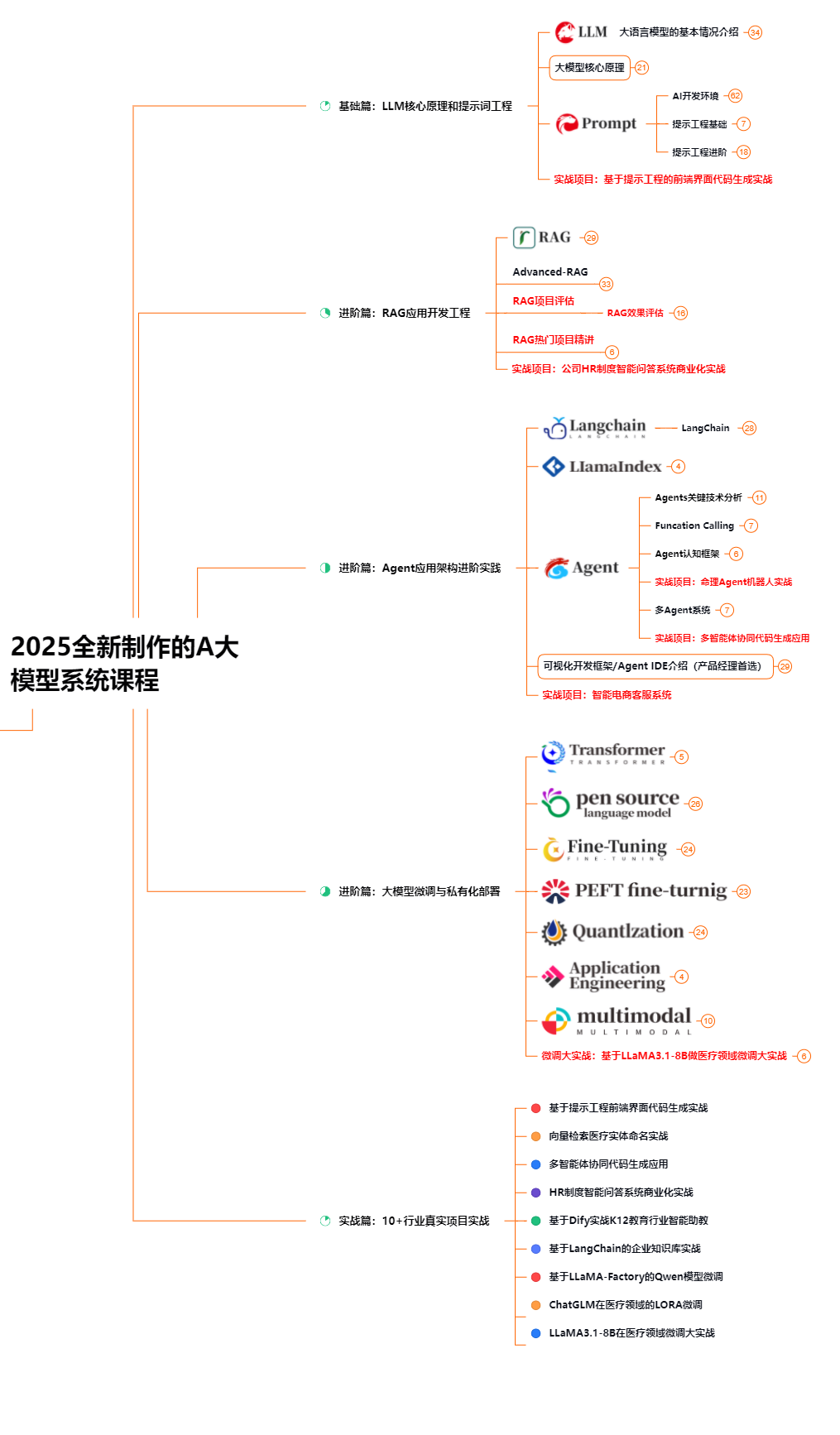
2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。
4. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。
5. 大模型行业报告
行业分析主要包括对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

6. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

为什么大家都在学AI大模型?
随着AI技术的发展,企业对人才的需求从“单一技术”转向 “AI+行业”双背景。企业对人才的需求从“单一技术”转向 “AI+行业”双背景。金融+AI、制造+AI、医疗+AI等跨界岗位薪资涨幅达30%-50%。
同时很多人面临优化裁员,近期科技巨头英特尔裁员2万人,传统岗位不断缩减,因此转行AI势在必行!

这些资料有用吗?
这份资料由我们和鲁为民博士(北京清华大学学士和美国加州理工学院博士)共同整理,现任上海殷泊信息科技CEO,其创立的MoPaaS云平台获Forrester全球’强劲表现者’认证,服务航天科工、国家电网等1000+企业,以第一作者在IEEE Transactions发表论文50+篇,获NASA JPL火星探测系统强化学习专利等35项中美专利。本套AI大模型课程由清华大学-加州理工双料博士、吴文俊人工智能奖得主鲁为民教授领衔研发。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。


大模型全套学习资料已整理打包,有需要的小伙伴可以
微信扫描下方CSDN官方认证二维码,免费领取【保证100%免费】


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 19
19 0
0- 0



 已为社区贡献281条内容
已为社区贡献281条内容

所有评论(0)