【datawhale学习-post training】task3-DPO
Topic-DPO
本文基于 DeepLearning.AI 出品的短课 《Post‑training of LLMs》,并在datawhale组织帮助下学习:github
定义
DPO = Direct Preference Optimization(直接偏好优化),场景:对同一个提示 Prompt,之前的模型会生成两段模型回复 A 和 B,标注者选择其中“更好”的那个。这样会形成data(人类标注的偏好数据对)。DPO 不需要训练reward model,也不使用强化学习,而是使用一个loss function,直接让模型提高偏好回复的概率、降低被拒绝回复的概率,同时保持与初始模型的 KL 约束,从而完成了人类偏好的对齐。
之所以要提到强化学习和奖励模型,是因为它们是 DPO 出现之前最主流的做法,也就是 RLHF。
从RLHF到DPO
RLHF-基本流程
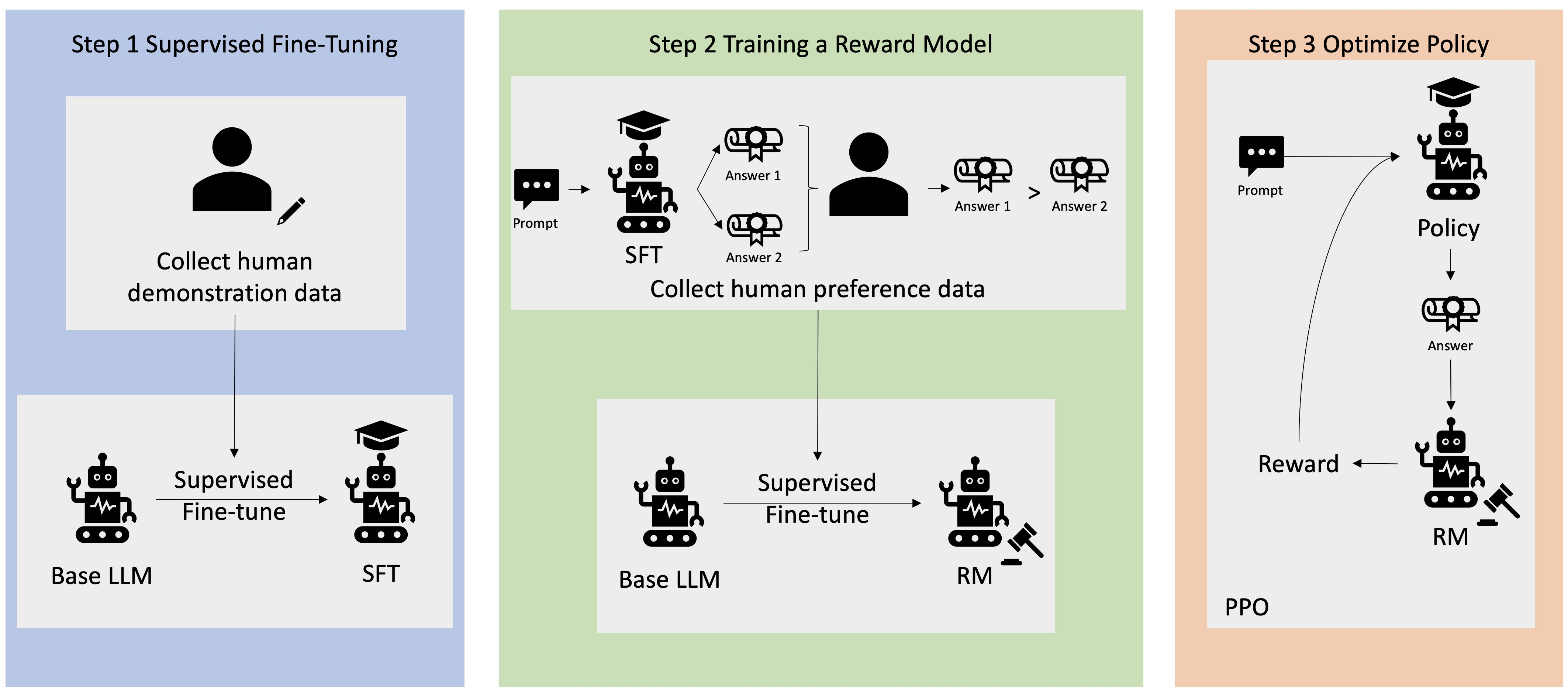
如图,RLHF基本分为三个阶段:
-
SFT: 人类写一些高质量的问答,模型根据这些示例进行监督学习。模型可以基本做对,但是可能不符合用户偏好。回答质量/风格不是用户真正想要的。
-
Training a Reward Model: 标注者对两个模型回答进行比较,选出 ta 心目中更好的那个回答,随后用这个偏好数据去训练一个reward model。
-
PPO training:最后用PPO根据这个reward model去优化模型参数。
tips:回头看我前面对 DPO 的介绍,你会发现它的思路和 RLHF 不一样。
DPO 是直接用偏好数据来更新模型参数,根据一个设计好的 loss function 直接做优化。它不需要先训练一个 reward model,然后再用这个 reward model 去指导模型优化。
RLHF-数学推导
reward model
奖励模型大致分两种:
一种是偏好式奖励。纯文本任务没有标准答案,没法直接打分,所以通常会让标注者比较两个回答,看哪个更好,从而得到偏好数据。
另一种是可验证奖励。比如代码、数学题这类任务有明确的正确答案,直接对照真值就能给出奖励。
下面我们只聊第一种:偏好数据。
我们一直说,是拿偏好数据去训练一个reward model,最后的效果是:给一个数据对 ( 模型的输入prompt和模型的输出回答y ),reward model能让“人类偏好的回答”获得高奖励值。因为它通过之前的"比较"学习已经大概明白人类喜欢什么回答不喜欢什么回答。
首先我们要定义偏好数据:
D pref = { ( x , y + , y − ) } D_{\text{pref}} = \{(x, y^+, y^-)\} Dpref={(x,y+,y−)}
x x x: prompt ; y + y^+ y+:人类更喜欢的回答; y − y^- y−:人类较不喜欢的回答
面对这种成对偏好,我们需要将其转化为一个可学习的概率模型。这里我们用Bradley–Terry 模型建模,即 P ( y + ≻ y − ) P(y^+ \succ y^-) P(y+≻y−) , 我们想知道 “优质回答” 被偏好胜过 “劣质回答” 的概率是多少?
那么我们假设每个回答都有一个“评分”,这实际上等价于奖励值: r ϕ ( x , y ) r_\phi(x, y) rϕ(x,y), 即一个数据对 ( x:模型的输入prompt;y:模型的输出回答) 的一个奖励值。
利用Bradley–Terry 模型,我们即可建模:
P ( y + ≻ y − ) = e r ϕ ( x , y + ) e r ϕ ( x , y + ) + e r ϕ ( x , y − ) P(y^+ \succ y^-) =\frac{e^{r_\phi(x, y^+)}}{e^{r_\phi(x, y^+)} + e^{r_\phi(x, y^-)}} P(y+≻y−)=erϕ(x,y+)+erϕ(x,y−)erϕ(x,y+)
我们进一步化简:
P ( y + ≻ y − ) = e r ϕ ( x , y + ) e r ϕ ( x , y + ) + e r ϕ ( x , y − ) = e r ϕ ( x , y + ) / e r ϕ ( x , y − ) e r ϕ ( x , y + ) / e r ϕ ( x , y − ) + e r ϕ ( x , y − ) / e r ϕ ( x , y − ) = e r ϕ ( x , y + ) − r ϕ ( x , y − ) e r ϕ ( x , y + ) − r ϕ ( x , y − ) + 1 = 1 1 + e − ( r ϕ ( x , y + ) − r ϕ ( x , y − ) ) = σ ( r ϕ ( x , y + ) − r ϕ ( x , y − ) ) \begin{aligned} P(y^+ \succ y^-) &= \frac{e^{r_\phi(x, y^+)}}{e^{r_\phi(x, y^+)} + e^{r_\phi(x, y^-)}} \\ &= \frac{e^{r_\phi(x, y^+)}/e^{r_\phi(x, y^-)}}{e^{r_\phi(x, y^+)}/e^{r_\phi(x, y^-)} + e^{r_\phi(x, y^-)}/e^{r_\phi(x, y^-)}} \\ &= \frac{e^{r_\phi(x, y^+)-r_\phi(x, y^-)}}{e^{r_\phi(x, y^+)-r_\phi(x, y^-)} + 1} \\ &= \frac{1}{1 + e^{-(r_\phi(x, y^+)-r_\phi(x, y^-))}} \\ &= \sigma(r_\phi(x, y^+)-r_\phi(x, y^-)) \end{aligned} P(y+≻y−)=erϕ(x,y+)+erϕ(x,y−)erϕ(x,y+)=erϕ(x,y+)/erϕ(x,y−)+erϕ(x,y−)/erϕ(x,y−)erϕ(x,y+)/erϕ(x,y−)=erϕ(x,y+)−rϕ(x,y−)+1erϕ(x,y+)−rϕ(x,y−)=1+e−(rϕ(x,y+)−rϕ(x,y−))1=σ(rϕ(x,y+)−rϕ(x,y−))
其中 sigmoid 函数定义为:
σ ( z ) = 1 1 + e − z \sigma(z) = \frac{1}{1 + e^{-z}} σ(z)=1+e−z1
在优化模型的时候,我们要最大化样本概率,那我们对样本建模的是 P ( y + ≻ y − ) P(y^+ \succ y^-) P(y+≻y−),所以 我们希望 max ϕ P ( y + ≻ y − ) \max_\phi P(y^+ \succ y^-) maxϕP(y+≻y−)
然而训练神经网络不直接最大化概率,而是最大化 log-likelihood,即最小化负的log-likelihood。负的log-likelihood形式如下:
L RM ( ϕ ) = − E ( x , y + , y − ) [ log σ ( r ϕ ( x , y + ) − r ϕ ( x , y − ) ) ] \mathcal{L}_{\text{RM}}(\phi) = - \mathbb{E}_{(x, y^+, y^-)} \left[ \log\sigma( r_\phi(x, y^+) - r_\phi(x, y^-)) \right] LRM(ϕ)=−E(x,y+,y−)[logσ(rϕ(x,y+)−rϕ(x,y−))]
最终训练目标为:
ϕ ∗ = arg min ϕ L RM ( ϕ ) \phi^* = \arg\min_\phi \mathcal{L}_{\text{RM}}(\phi) ϕ∗=argϕminLRM(ϕ)
所以最后我们从数据中学习到了一个参数化奖励函数: r ϕ ( x , y ) r_\phi(x, y) rϕ(x,y),使得对一个数据对 ( x:模型的输入prompt;y:模型的输出回答)会有一个奖励值的输出。
PPO
此阶段的输入:
- 初始策略模型:SFT 训练得到的 π θ SFT \pi_{\theta_{\text{SFT}}} πθSFT
- 奖励信号:训练好的奖励函数 r ϕ ∗ ( x , y ) r_{\phi^*}(x, y) rϕ∗(x,y)
核心目标:优化策略模型参数 θ \theta θ,使其生成的回答既满足高奖励,又不偏离SFT模型的基础能力。
此时整个 RLHF 阶段的优化目标为:
max θ E y ∼ π θ [ r ϕ ∗ ( x , y ) − β ⋅ KL [ π θ ( ⋅ ∣ x ) ∥ π θ SFT ( ⋅ ∣ x ) ] ] \max_\theta \mathbb{E}_{y \sim \pi_\theta} \left[ r_{\phi^*}(x, y) - \beta \cdot \text{KL} \left[ \pi_\theta(\cdot|x) \parallel \pi_{\theta_{\text{SFT}}}(\cdot|x)\right] \right] θmaxEy∼πθ[rϕ∗(x,y)−β⋅KL[πθ(⋅∣x)∥πθSFT(⋅∣x)]]
其中第一项:r是奖励项,鼓励模型生成高评分回答;第二项:KL散度正则项,使得优化前和优化后不要相差太大。
到这里,我们已经得到了要优化的目标。那么接下来问题来了:我们要怎么优化它?
注意这个目标的形式——就是想让 reward 最大化。是不是感觉有点眼熟?这就是典型的强化学习的目标。我们再回过头来看,其实 LLM 可以视为一个policy,因为它本质上定义了一个“在状态 x 下采取动作 y 的概率分布”。
既然 LLM 天然就是一个策略,而我们又想让它得到更高的 reward,
那顺理成章的做法就是:
用 RL 里基于 policy 的优化方法来更新 LLM,让它输出的内容更符合奖励模型的偏好。
| 概念 | 在 RL 中 | 在 LLM中 |
|---|---|---|
| 状态(state) | 环境状态 s s s | prompt + 已生成 token,即 x , y < t x, y_{<t} x,y<t |
| 动作(action) | 选择一个动作 a a a | 生成下一个 token y t y_t yt |
| 策略(policy) | π θ ( a ∣ s ) \pi_\theta(a\mid s) πθ(a∣s):在状态 s s s 下选择动作 a a a 的概率 | π θ ( y t ∣ x , y < t ) \pi_\theta(y_t\mid x, y_{<t}) πθ(yt∣x,y<t):在当前状态下生成下一个 token 的概率 |
| 轨迹(trajectory) | a 1 , a 2 , … , a T a_1, a_2, \dots, a_T a1,a2,…,aT | 生成的整个序列 y 1 , y 2 , … , y T y_1, y_2, \dots, y_T y1,y2,…,yT |
| 奖励(reward) | 环境给出的奖励 r ( s , a ) r(s,a) r(s,a) | 奖励模型给整段输出的得分 r ϕ ( x , y ) r_\phi(x, y) rϕ(x,y),即类似传统RL里面的G |
| 优化目标 | 最大化期望奖励 | 最大化回复质量(来自奖励模型) |
| 用的优化算法 | PPO | PPO(RLHF) |
Why PPO?
为什么一定要用PPO,而不是其他policy-based RL算法?因为on-policy 方法中最稳定的就是 PPO。相比之下,REINFORCE 不稳定,TRPO 太贵。
那么,我们就能把PPO的很多trick(ratio + clipping)搬到这里近似去优化我们的目标。
DPO
目标推导
回顾目标:在 RLHF 里,对一个给定的 prompt x x x,我们用奖励模型 r ϕ ( x , y ) r_\phi(x,y) rϕ(x,y) 和 KL 正则去优化策略 π θ \pi_\theta πθ
max θ E y ∼ π θ [ r ϕ ( x , y ) − β ⋅ KL [ π θ ( ⋅ ∣ x ) ∥ π ref ( ⋅ ∣ x ) ] ] \max_\theta \mathbb{E}_{y \sim \pi_\theta} \left[ r_{\phi}(x, y) - \beta \cdot \text{KL} \left[ \pi_\theta(\cdot|x) \parallel \pi_{\text{ref}}(\cdot|x)\right] \right] θmaxEy∼πθ[rϕ(x,y)−β⋅KL[πθ(⋅∣x)∥πref(⋅∣x)]]
对固定的 x x x,把问题看作对分布 π ( ⋅ ∣ x ) \pi(\cdot \mid x) π(⋅∣x) 的变分问题:
max π ∑ y π ( y ∣ x ) r ϕ ( x , y ) − β ∑ y π ( y ∣ x ) log π ( y ∣ x ) π r e f ( y ∣ x ) \max_\pi\sum_y\pi(y\mid x)r_\phi(x,y)-\beta\sum_y\pi(y\mid x)\log\frac{\pi(y\mid x)}{\pi_\mathrm{ref}(y\mid x)} πmaxy∑π(y∣x)rϕ(x,y)−βy∑π(y∣x)logπref(y∣x)π(y∣x)
再加上归一化约束 ∑ y π ( y ∣ x ) = 1 \sum_y \pi(y\mid x)=1 ∑yπ(y∣x)=1 的拉格朗日乘子, 对 π ( y ∣ x ) \pi(y\mid x) π(y∣x) 求偏导并整理,可以得到最优策略的形式为:
π ∗ ( y ∣ x ) ∝ π r e f ( y ∣ x ) exp ( 1 β r ϕ ( x , y ) ) \pi^{*}(y\mid x)\propto\pi_{\mathrm{ref}}(y\mid x)\exp\left(\frac{1}{\beta}r_\phi(x,y)\right) π∗(y∣x)∝πref(y∣x)exp(β1rϕ(x,y))
即
π ∗ ( y ∣ x ) = 1 Z ( x ) π r e f ( y ∣ x ) exp ( 1 β r ϕ ( x , y ) ) \pi^{*}(y\mid x)=\frac{1}{Z(x)}\pi_{\mathrm{ref}}(y\mid x)\exp\left(\frac{1}{\beta}r_{\phi}(x,y)\right) π∗(y∣x)=Z(x)1πref(y∣x)exp(β1rϕ(x,y))
其中 Z ( x ) Z(x) Z(x) 是归一化常数。
对上式取对数,可以写成:
r ϕ ( x , y ) = β ( log π ∗ ( y ∣ x ) − log π r e f ( y ∣ x ) ) + C ( x ) r_\phi(x,y)=\beta\left(\log\pi^{*}(y\mid x)-\log\pi_{\mathrm{ref}}(y\mid x)\right)+C(x) rϕ(x,y)=β(logπ∗(y∣x)−logπref(y∣x))+C(x)
代回 Bradley–Terry 偏好模型
之前我们得到:
P ( y + ≻ y − ∣ x ) = σ ( r ϕ ( x , y + ) − r ϕ ( x , y − ) ) P(y^+\succ y^-\mid x)=\sigma\left(r_\phi(x,y^+)-r_\phi(x,y^-)\right) P(y+≻y−∣x)=σ(rϕ(x,y+)−rϕ(x,y−))
用上一节得到的 r ϕ r_\phi rϕ表达式代入:
P ( y + ≻ y − ∣ x ) = σ ( β [ log π ∗ ( y + ∣ x ) − log π ∗ ( y − ∣ x ) ⏟ 新策略的 log 概率差 − ( log π ref ( y + ∣ x ) − log π ref ( y − ∣ x ) ) ⏟ 参考策略的 log 概率差 ] ) P(y^+\succ y^-\mid x)=\sigma\Big(\underbrace{\beta\Big[\log\pi^{*}(y^+\mid x)-\log\pi^{*}(y^-\mid x)}_{\text{新策略的}\log\text{概率差}}-(\underbrace{\log\pi_{\text{ref}}(y^+\mid x)-\log\pi_{\text{ref}}(y^-\mid x))}_{\text{参考策略的}\log\text{概率差}}\Big]\Big) P(y+≻y−∣x)=σ(新策略的log概率差
β[logπ∗(y+∣x)−logπ∗(y−∣x)−(参考策略的log概率差
logπref(y+∣x)−logπref(y−∣x))])
P ( y + ≻ y − ∣ x ) = σ ( β ( log ( π ∗ ( y + ∣ x ) π ∗ ( y − ∣ x ) ) − log ( π r e f ( y + ∣ x ) π r e f ( y − ∣ x ) ) ) ) P(y^+\succ y^-\mid x)=\sigma\left(\beta\left(\log\left(\frac{\pi^*(y^+\mid x)}{\pi^*(y^-\mid x)}\right)-\log\left(\frac{\pi_\mathrm{ref}(y^+\mid x)}{\pi_\mathrm{ref}(y^-\mid x)}\right)\right)\right) P(y+≻y−∣x)=σ(β(log(π∗(y−∣x)π∗(y+∣x))−log(πref(y−∣x)πref(y+∣x))))
所以得出关键信息:
偏好概率 P ( y + ≻ y − ∣ x ) P(y^+ \succ y^- \mid x) P(y+≻y−∣x)可以仅用策略的对数概率比(相对于参考策略)来表示, 不需要显式地单独建模 r ϕ r_\phi rϕ。
此时,损失函数依旧是要求 max ϕ P ( y + ≻ y − ) \max_\phi P(y^+ \succ y^-) maxϕP(y+≻y−)
所以我们可以用数据直接去优化我的LLM(policy)参数, 而不需要reward model:
L ( β ) = − E ( x , y + , y − ) [ log σ ( β ( log π ∗ ( y i + ∣ x i ) π ∗ ( y i − ∣ x i ) − log π r e f ( y i + ∣ x i ) π r e f ( y i − ∣ x i ) ) ) ] \mathcal{L}(\beta)=-\mathbb{E}_{(x,y^+,y^-)}[\log\sigma\left(\beta\left(\log\frac{\pi^{*}(y_{i}^{+}|x_{i})}{\pi^{*}(y_{i}^{-}|x_{i})}-\log\frac{\pi_{\mathrm{ref}}(y_{i}^{+}|x_{i})}{\pi_{\mathrm{ref}}(y_{i}^{-}|x_{i})}\right)\right)] L(β)=−E(x,y+,y−)[logσ(β(logπ∗(yi−∣xi)π∗(yi+∣xi)−logπref(yi−∣xi)πref(yi+∣xi)))]
题外话:为什么目标函数要有KL约束?
我们之前理所当然的认定:
核心目标:优化策略模型参数 θ \theta θ,使其生成的回答既满足高奖励,又不偏离SFT模型的基础能力。
此时整个 RLHF 阶段的优化目标为:
max θ E y ∼ π θ [ r ϕ ∗ ( x , y ) − β ⋅ KL [ π θ ( ⋅ ∣ x ) ∥ π θ SFT ( ⋅ ∣ x ) ] ] \max_\theta \mathbb{E}_{y \sim \pi_\theta} \left[ r_{\phi^*}(x, y) - \beta \cdot \text{KL} \left[ \pi_\theta(\cdot|x) \parallel \pi_{\theta_{\text{SFT}}}(\cdot|x)\right] \right] θmaxEy∼πθ[rϕ∗(x,y)−β⋅KL[πθ(⋅∣x)∥πθSFT(⋅∣x)]]
Q:但是为什么要限制sft策略和优化后的策略不能太远呢?
A:这是因为reward model只在 SFT 分布附近是正确的。
我们的训练数据是用 SFT 模型生成的数据标注出来的。它从没见过“奇怪的”token分布,所以当策略偏离数据分布(OOD),它就无法提供正确的 reward。输出错误的 reward → RL 的梯度方向变成错误的 → 策略发散。所以 KL penalty 是用来限制我们在“可控区域”内优化,不让策略跑到 reward model 的 OOD 区域去。
总之:
策略偏离分布 → RM 无法泛化 → 策略容易崩溃。
所以PPO只能在sft模型附近一块区域微调模型。
题外话:Reward Hacking
我们需要避免 DPO 过拟合。因为 DPO 本质上属于一种偏好学习,它有可能学到数据里的“捷径”。例如,如果正样本里总是出现某些特殊词,而负样本没有,那么模型很可能只学习到这些表面特征,从而导致训练非常不稳定。
简单说,DPO 就是沿着 RLHF 的那条路走过来,然后把里面最麻烦的“奖励模型 + 强化学习”这两步给直接干掉了。这里我对PPO没有展开细讲,如果了解具体了解PPO可以去关注policy-based RL的发展脉络。
END.

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 27
27 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)