Counterexample Guided Program Repair Using Zero-Shot Learning and MaxSAT-based Fault Localization
基本信息
The Thirty-Ninth AAAI Conference on Artificial Intelligence (AAAI-25)
题目: 基于零样本学习与 MaxSAT 故障定位的反例引导程序自动修复
作者: Pedro Orvalho(Department of Computer Science, University of Oxford, Oxford, UK) Mikoláš Janota(CIIRC, Czech Technical University in Prague, Czechia) Vasco M. Manquinho(INESC-ID, IST, Universidade de Lisboa, Portugal)
博客贡献人
糖瓶
摘要(Abstract)
针对入门级编程作业(IPAS)的自动程序修复(Automated Program Repair, APR)是每年大量学生选修编程课程所驱动的。由于为编程作业提供反馈需要教师投入大量时间和精力,个性化的自动化反馈通常涉及向学生的程序提出修复建议。基于符号语义的修复方法(symbolic semantic repair approaches),依赖形式化方法(Formal Methods, FM),通过将程序的执行与测试集或参考实现进行对比来进行修复,这类方法在识别错误部分方面表现出色,但其修复能力有限:仅当正确实现与错误实现具有相同的控制流图时才能进行修复。相比之下,大型语言模型(Large Language Models, LLMS)可用于程序修复,但通常会对程序进行大幅重写,而非最小化调整。这会导致更具侵入性的修复,使学生难以从自己的错误中学习。总的来说,LLMS 擅长完成代码生成,而基于 FM 的故障定位(fault localization)擅长识别程序中的错误部分。
本文提出了一种创新方法,结合形式化方法的 MaxSAT 故障定位与 LLM 的零样本学习能力,提升针对 IPAS 的自动修复效果。我们的方法首先使用基于 MaxSAT 的故障定位识别程序中的错误部分,然后将一个去除这些错误语句的程序草图(program sketch)提供给 LLM。这一混合方法遵循反例引导的归纳合成(Counterexample Guided Inductive Synthesis, CEGIS)循环,以迭代方式优化程序。我们要求 LLM 合成缺失部分,并将生成的程序在测试集上进行验证。如果程序不正确,测试集中的反例将反馈给 LLM,用于指导修改后的合成。
我们对 1,431 个错误学生程序的实验表明,利用 MaxSAT 生成的无错误程序草图进行反例引导的方法,显著提升了六种评估的 LLM 的修复能力。该方法使 LLM 修复更多程序并生成更小的修复补丁,其表现优于其他配置及最先进的符号程序修复工具。
代码地址: https://doi.org/10.5281/zenodo.14517771
第一章 引言(Introduction)
每年都有成千上万的学生选修与编程相关的课程。随着计算机科学教育的迅速普及,为编程入门作业(Introductory Programming Assignments,简称 IPAS)和软件项目提供个性化且及时的反馈,已成为一项重大挑战,这需要教师投入大量的时间与精力。
为应对这一挑战,自动化程序修复(Automated Program Repair, APR)成为一种有前景的解决方案。其目标是向学生提供自动化、全面且个性化的编程错误反馈。传统的基于形式化方法(Formal Methods, FM)的语义修复技术,虽然能够生成高质量的修复,但往往速度较慢,并且当错误程序与正确程序的结构差异较大时,其修复效果会显著下降。这类方法需要将错误提交与正确实现进行对齐;若无法对齐,系统就会返回“结构不匹配”错误,从而无法生成修复结果。过去十年中,基于机器学习(Machine Learning, ML)的 APR 方法发展迅速。 这类方法通常依赖于大量正确实现来进行模型训练,以生成高质量修复。但训练这些模型需要大量时间与计算资源。 尽管这些方法可以更快生成修复,但通常会产生不精确且非最小的修复。
近来,基于代码训练的大语言模型(LLMs trained on code, LLMCS)在生成程序修复上显示出巨大潜力。LLM 驱动的程序修复可通过以下三种方式实现:
-
零样本学习(Zero-Shot Learning):模型无需见过该任务示例即可直接完成;
-
少样本学习(Few-Shot Learning):模型仅依靠少量示例即可完成任务;
-
微调(Fine-tuned Models):模型针对特定任务进行再训练。
其中,微调模型最常见;此外,零样本或少样本学习的泛化能力使 LLM 能够处理广泛任务,而无需昂贵的重新训练或微调。然而,少样本学习可能导致生成的修复过大,因为其仅基于有限示例。LLM 通常不保证最小修复,并倾向于重写学生的大部分实现,而非进行最小调整,这使得其修复效率较低,也不利于学生学习。
为此,本文提出一种结合 FM 与 LLM 优势的混合方法,通过零样本学习改进编程入门作业(IPAS)的自动修复。 我们的方法使用基于 MaxSAT 的故障定位识别程序的最小错误部分,并向现成 LLM 提供一个去除这些错误语句的程序草图(program sketch)。该混合方法遵循反例引导的归纳合成(Counterexample Guided Inductive Synthesis, CEGIS)循环迭代优化程序。我们向 LLM 提供无错误的程序草图,并要求其合成缺失部分。在每次迭代后,将合成程序在测试集上进行验证。如果程序不正确,则将测试集中的反例反馈给 LLM,引导生成修订后的程序。
我们对 1431 个错误学生程序的实验表明,利用 MaxSAT 生成的无错误程序草图的反例引导方法显著提升了六种评估的 LLM 的修复能力。该方法使 LLM 修复更多程序,并生成更优的修复补丁,其补丁规模更小,优于其他配置以及最先进的符号程序修复工具。
本文主要贡献如下:
-
提出了一种基于 LLM 的反例引导归纳合成(CEGIS)方法来解决自动程序修复(APR)问题;
-
采用基于 MaxSAT 的故障定位,通过提供无错误程序草图,引导 LLM 对错误程序生成最小化修复补丁;
-
实验表明,我们的方法使六种评估的 LLM 能够修复更多程序,并生成比其他配置及符号工具更小的补丁。
第二章 研究动机(Motivation)
考虑如下示例程序(如 Listing 1 所示),其目标是求出给定三个数中的最大值。 然而,依据输入输出测试集 (T = {t_0 = ((1, 2, 3), 3); t_1 = ((6, 2, 1), 6); t_2 = ((−1, 3, 1), 3)}),该程序输出结果与期望不符,因此被判定为错误程序。该程序的最小错误行集合包括第 4 行与第 8 行,因为根据测试集判断,这两条 if 语句的条件均存在逻辑错误。 向学生提供有效反馈的一个好方法,是直接高亮出这两行错误代码,让学生清楚问题所在。 但若要进一步确认这些错误是否是导致程序失败的根本原因,仍需要对程序进行修复并并在测试集上评估其结果。
使用基于形式化方法(Formal Methods, FM)的传统自动程序修复(Automated Program Repair, APR)工具(如 CLARA或 VERIFIX时,Listing 1 中的程序在 90 秒内无法被修复。CLARA 在考虑同一 IPA 的多个正确实现时,计算“最小”修复耗时过长,而 VERIFIX 则返回编译错误。
相反,使用针对编码任务训练的最先进大型语言模型(LLMCS),如 GRANITE或 CODEGEM-MA,需要提供编程作业的描述和部分输入-输出测试示例。然而,即便提供了这些信息,这些 LLM 在重复测试和改进修复方案的过程中,也无法在 90 秒内修复 Listing 1 中的错误程序。如果在提示中提供 Listing 2 中的讲师参考实现作为参考,两个 LLM 都会直接复制正确程序,而忽略“不要直接复制”的指令。
因此,符号方法(symbolic approaches)虽然严格,但生成答案耗时过长;LLM 虽然快速,但往往产生错误修复。一种有前景的策略是结合两者的优势。基于 MaxSAT 的故障定位能够严格识别错误语句,这些语句可以在 LLM 提示中高亮,以引导模型关注需要修复的程序部分。Listing 3 展示了程序草图(program sketch)的示例,它是一种部分不完整的程序,其中原 Listing 1 中的每条错误语句被替换为 @ HOLE @。指导 LLMS 完成这一不完整程序后,GRANITE 和 CODEGEM-MA 均能够在一次交互中修复错误程序,并返回 Listing 4 中的正确程序。

第三章 预备知识(Preliminaries)
本节给出本文中使用的主要定义与符号说明。
1 程序综合问题(Synthesis Problem)
对于给定程序的规范 S(例如输入-输出示例)、上下文无关文法 G 以及特定领域语言(Domain-specific Language, DSL)的语义 O,程序合成的目标是推导出一个程序 P,使得:(1) 程序符合文法 G 的生成规则;(2) 程序与语义 O 一致;(3) 程序满足规范 S。
换言之,程序综合的目标是自动生成一个既符合语言规则又满足功能要求的程序。
2 语义程序修复(Semantic Program Repair)
给定四元组 (T, G, O, P),其中 T 是输入-输出示例集合(测试集),G 是文法,O 是特定领域语言的语义,且 P 是语法上正确(即由语句、指令、表达式组成)且符合 G 和 O 的程序,但对于至少一个输入-输出示例存在语义错误,即 ![]()
语义程序修复的目标是通过语义上修改程序 P 的子集 ![]() ,替换为另一组语句 S2(与 G 和 O 一致),得到修复程序,使得
,替换为另一组语句 S2(与 G 和 O 一致),得到修复程序,使得![]()
![]() 。
。
3 反例引导归纳综合(Counterexample Guided Inductive Synthesis, CEGIS)
CEGIS 是一种迭代算法,常用于程序合成和形式化方法中,用于构造满足给定规范的程序或解。CEGIS 包含两个步骤:合成步骤和验证步骤。给定期望程序的规范,归纳合成过程生成一个候选程序。然后,将候选程序 P 传入验证步骤,检查其是否满足所有可能输入的规范。如果不满足,判定模块(Decider)会从满足性赋值中生成反例 c,并将其加入传递给合成器的输入集合中,循环迭代。合成引擎使用该反例改进其假设,以避免在后续迭代中重复同类错误。此迭代循环(包括候选生成、验证、反例生成和改进)持续进行,直到生成满足所有规范和约束的正确候选程序。
-
综合步骤(Synthesis Step)依据当前规范生成候选程序 (P)。
-
验证步骤(Verification Step)
-
检查 (P) 是否对所有输入均满足规范。
-
若验证失败,则从反例中获取一个反例输入 (c),并将其加入到综合输入集中。
-
循环持续执行,直到找到一个满足所有约束条件的候选程序。 因此,CEGIS 本质上是一个 “候选生成 – 验证 – 反例反馈 – 改进” 的迭代过程。
4 最大可满足性问题(Maximum Satisfiability, MaxSAT)
布尔可满足性问题(SAT)是命题逻辑的判定问题。在合取范式(Conjunctive Normal Form, CNF)中,一个命题公式由若干子句的合取组成,每个子句是文字的析取。最大可满足性问题(MaxSAT)是 SAT 的优化版本,其目标是在 CNF 公式中找到一个赋值,使被满足的子句数量最大化。
5 基于公式的故障定位(Formula-based Fault Localization, FBFL)
给定一个有错误的程序及包含失败测试用例的测试集,基于公式的故障定位方法将定位问题编码为优化问题,以识别程序中最小的错误语句集合(诊断集)。FBFL 工具利用 MaxSAT 及基于模型诊断(Model-Based Diagnosis, MBD)理论,枚举与错误位置对应的 MaxSAT 公式的所有诊断结果。通过对所有失败测试的编码,FBFL 可以枚举出所有可能的错误位置集合(诊断结果)。
6 程序草图(Program Sketch)
程序草图(Program Sketch)是一个部分不完整的程序,其中所有错误语句被占位符(placeholder)替换。 这些占位符用 @HOLE@ 标记,表示该部分需由后续综合过程生成。这些占位符标识了需要合成的程序部分,以确保程序满足给定规范(例如测试集)。示例见 Listing 3。
7 抽象语法树(Abstract Syntax Tree, AST)
抽象语法树(AST)是一种语法结构树,每个节点表示一个操作,其子节点表示该操作的参数。 AST 体现了程序的语法结构与层次关系,通常由上下文无关文法(CFG)定义。 它是进行程序结构比较(如Tree Edit Distance, TED)的基础。
第四章 反例引导自动修复(Counterexample Guided Automated Repair)
我们的方法结合了形式化方法(Formal Methods, FM)与大型语言模型(LLMS)的优势,以增强自动程序修复(Automated Program Repair, APR)。首先,我们采用基于 MaxSAT 的故障定位技术来严格识别程序中最小的错误部分。随后,我们利用 LLMS 快速合成程序草图中缺失的部分。最后,我们使用测试集中的反例(counterexample)引导 LLMS 生成补丁,使合成的程序满足整个测试集,从而完成修复。我们的方法遵循反例引导的归纳合成(Counterexample Guided Inductive Synthesis, CEGIS)循环,以迭代方式不断优化程序。
总体流程如下:
-
使用基于 MaxSAT 的故障定位技术精确识别出程序中最小的错误语句集合;
-
利用 LLM 快速生成补全代码,填充这些“空缺部分”;
-
使用测试集中的反例(counterexample)作为反馈,引导 LLM 在后续迭代中生成更符合规范的修复方案;
-
整个过程遵循反例引导归纳综合循环(CEGIS)持续优化,直到程序通过全部测试。
图 1 给出了我们 APR 方法的总体流程。输入包括一个有错误的程序以及入门级编程作业(IPA)的规范信息,包括作业描述、测试集和讲师参考实现。我们首先使用基于 MaxSAT 的故障定位技术识别程序中最小的错误语句集。接着,提示生成器(prompt generator)根据 IPA 规范和反映已定位错误的无错误程序草图构建提示,并将这些信息提供给 LLMS。LLMS 根据所提供的提示生成程序。在每次迭代之后,判定模块(Decider module)会根据测试集评估生成的程序。如果程序仍不正确,则从测试集中选择一个反例并发送给提示生成器,提示生成器再将该反例提供给 LLMS,以引导修订后的程序合成。
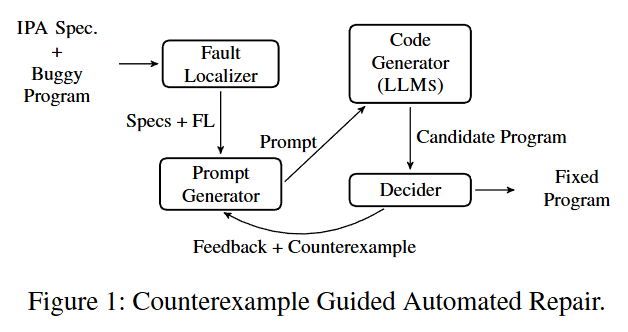
系统输入包括:
-
一段含错误的程序;
-
以及编程作业(IPA)的相关规范信息:
-
任务描述、
-
测试集、
-
教师提供的参考实现。
-
修复流程说明
-
故障定位(Fault Localizer) 使用基于 MaxSAT 的故障定位算法,识别程序中最小的错误语句集。
-
提示生成器(Prompt Generator) 根据故障定位结果与作业规范信息,构造提示(Prompt)。 提示包含任务描述、测试集、参考程序(若提供)以及“无错误程序草图”。
-
代码生成(Code Generator) 由 LLM 接收提示,生成完整的候选修复程序。
-
判定模块(Decider module)使用测试集执行生成的候选程序:
-
若全部通过,修复成功;
-
若失败,提取对应的反例输入输出对,反馈给 LLM 进行下一轮修复。
-
通过这种反例反馈机制,系统实现了“自我改进”的闭环修复。
提示设计(Prompts)
提供给 LLMS 的提示可以包含与 IPA 相关的多种信息。每门编程课程中典型可用的信息包括 IPA 的描述、用于检查学生提交是否符合 IPA 规范的测试集,以及讲师的参考实现。我们提示中使用的语法与其他基于 LLM 的程序修复工作类似。我们评估了多种类型的提示。基础提示(Basic prompts)是无需额外计算即可提供给 LLM 的最简单提示,包含作业的所有基本信息。下面给出了此类提示的示例:


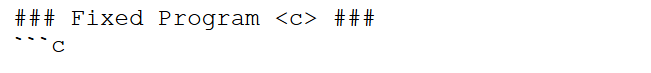
为了在提示中包含使用基于MaxSAT的故障定位所得的错误信息,我们采用了两种不同类型的提示:(1)FIXME注释和(2)程序草图。FIXME注释提示是指由故障定位工具标识为存在错误的每一行代码都用 `/* FIXME */` 注释标出。 这些提示与前面描述的基础提示非常相似,主要区别在于错误程序中的注释以及给 LLM 的第一个指令,后者被修改如下:

在第二种提示类型中,为了将程序修复视为字符串补全问题(string completion problem),我们评估了使用提示的情况,其中错误程序被替换为一个不完整的程序(program sketch),每一行由我们的故障定位模块标识为错误的代码都被一个空洞(hole)替代。 给LLM的指令现在是补全该不完整的程序。因此“Buggy Program”和“Fixed Program”这两个部分分别被替换为“Incomplete Program”和“Complete Program”,如下所示:

反馈(Feedback) 如果由 LLM 生成的候选程序不符合测试集的要求,则通过迭代查询将此反馈信息提供给 LLM。 新的提示指出 LLM 先前修复错误程序的建议不正确,并提供一个反例(即输入输出测试),其中建议的修复程序产生了错误的输出。 因此,我们向 LLM 提供类似如下的反馈提示:

第五章 实验结果(Experimental Results)
本节旨在回答以下研究问题(Research Questions, RQs):
-
RQ1: 基于 LLM 的反例引导自动修复方法是否能提高修复率?
-
RQ2: MaxSAT 故障定位生成的“程序草图”是否能提升 LLM 修复性能?
-
RQ3: 不同 LLM 在本框架下的修复表现如何?
-
RQ4: 与最先进的符号方法(如 CLARA、VERIFIX)相比,本方法在准确性与修复效率上如何?
1 实验环境(Experimental Setup)
所有的大语言模型(LLMs)均在配备 NVIDIA RTX A4000(16GB 显存) 的服务器上运行,该服务器采用 Intel(R) Xeon(R) Silver 4130 CPU @ 2.10GHz 处理器,拥有 48 个 CPU 核心和 128GB 内存。所有与程序修复任务相关的实验均在一台 Intel(R) Xeon(R) Silver 4210R CPU @ 2.40GHz 的计算机上进行,实验设置的内存上限为 10GB,并设定超时时间为 90 秒。
2 评估基准(Evaluation Benchmark)
我们使用 C-PACK-IPAS对本研究进行了评估。
该数据集包含 1431 个语义错误的学生 C 程序,这些程序都能成功编译,但至少未通过一个测试。
5.3 大语言模型(Large Language Models, LLMs)
在我们的实验中,我们仅使用在 Hugging Face(HuggingFace 2024) 上公开可用的 开放访问 LLMs,这些模型大约拥有 70 亿(7B)参数。我们选择这些模型有三个主要原因:首先,像 ChatGPT 这样的闭源模型成本高昂,并且引发了关于学生数据隐私的担忧。其次,参数量非常大的模型(例如 700 亿参数的模型)需要大量计算资源,例如具有更高显存容量的 GPU,并且生成响应所需时间更长,这在课堂环境中并不适用。第三,我们使用这些现成(off-the-shelf)的 LLMs 来评估其公开可用版本,而不对它们进行微调(fine-tuning)。这种方法确保本文中使用的 LLMs 任何人都可以直接获取,而无需投入时间和资源进行微调。因此,我们在本研究中通过迭代查询(iterative querying)评估了 六种不同的 LLMs。其中三种模型是专门为编程任务微调的编码专用模型(LLMCS):IBM 的 GRANITE、Google 的 CODEGEMMA,以及 Meta 的 CODELLAMA。另外三种模型是通用型 LLMs,并非专门为编码任务定制:Google 的GEMMA、Meta 的 LLAMA3(即 LLAMA 系列的最新版本),以及 Microsoft 的 PHI3。
我们为每个模型选择了特定的变体,以优化其在程序修复任务中的性能。对于 Meta 的LLAMA3,我们使用了 8B 参数的指令微调(instruction-tuned)变体。该模型被设计为能更准确地遵循指令,适用于包括程序修复在内的多种任务。对于 CODELLAMA,我们使用了 7B 参数的指令微调版本,它专门为通用代码综合和理解设计,因此在编码任务中具有很高的效率。我们使用了具有 8B 参数 的GRANITE模型,该模型经过微调以响应与编程相关的指令。对于PHI3,我们选择了 mini 版本,其拥有 3.8B 参数 和 128K 的上下文长度(context length)。该较小的模型高效且能够处理较长的上下文,使其在教育环境中具有实用性。对于GEMMA,我们使用了 7B 参数的指令微调版本,该版本针对遵循详细指令进行了优化。最后,对于CODEGEMMA,我们选择了 7B 参数的指令微调变体,该版本专门为代码对话与指令任务设计,从而增强了其处理与编程相关查询和任务的能力。为了使所有 LLMs 都能在 16GB 显存的 GPU 上运行,我们使用了 4-bit 模型量化(model quantization)。此外,所有LLMs都使用了 Hugging Face 的Pipeline架构 进行运行。
通过使用这些不同的 LLMs,我们旨在在计算效率与有效生成和改进代码的能力之间取得平衡,从而在教育环境中实现一种实用的自动程序修复(APR)方法。
5.4 故障定位(Fault Localization, FL)
我们使用了 CFAULTS,这是一种基于公式的故障定位工具,用于精确定位程序中的错误位置。
它将所有失败的测试用例聚合成一个统一的 MaxSAT 公式。
5.5 评估(Evaluation)
为了评估在不同提示配置下由 LLMs 生成的程序修复的有效性,我们使用了两个关键指标:成功修复的程序数量,以及修复质量。在评估补丁质量时,我们使用 树编辑距离(Tree Edit Distance, TED)来计算学生的错误程序与 LLM 返回的修复程序之间的距离。TED 通过计算将一个抽象语法树(AST)转换为另一个所需的最少编辑操作数(即插入、删除和替换),来衡量两个 AST 之间的结构差异。基于该用于衡量程序距离的指标,我们计算了距离分数(distance score),由公式(1)定义。该分数旨在识别并惩罚那些将错误程序完全替换为参考解而非进行实际修复的LLMs。当原始错误程序 (To) 到 LLM 建议程序 (Tf) 的 TED 与参考解 (Tr) 到 To 的 TED 相同时,距离分数为零;否则,它会对为使程序与正确解对齐而进行的超出必要范围的修复进行惩罚。公式如下:
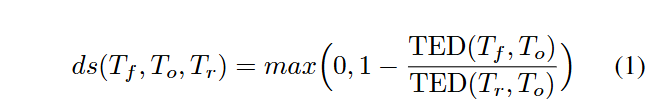
5.6 基线(Baseline)
我们使用了两种针对 IPAs 的最先进的传统语义程序修复工具作为基线:VERIFIX和 CLARA。
VERIFIX 使用 MaxSMT 将错误程序与讲师提供的参考实现对齐,而 CLARA 则将多个正确实现进行聚类,并选择在与错误程序对齐时产生最小修复的那一个。这两个工具都要求控制流图(例如分支、循环)之间必须完全匹配,并且变量之间必须具有双射关系;否则,它们将返回结构不匹配错误(structural mismatch error)。VERIFIX 在实验中被提供了每个错误程序、参考实现以及测试集。CLARA 被提供了来自不同学年的所有正确程序,以便为每个IPA生成聚类。在 90 秒的时间限制内,CLARA 修复了 495 个程序(34.6%),在 154 个程序(10.8%)上超时未生成修复结果,并在 738 个程序(54.7%)上修复失败。相比之下,VERIFIX 修复了 91 个程序(6.3%),在0.6% 的情况下达到时间上限,并在 1338 个程序(93.5%)上修复失败。这些失败的主要原因是两个工具都依赖于结构不匹配错误。
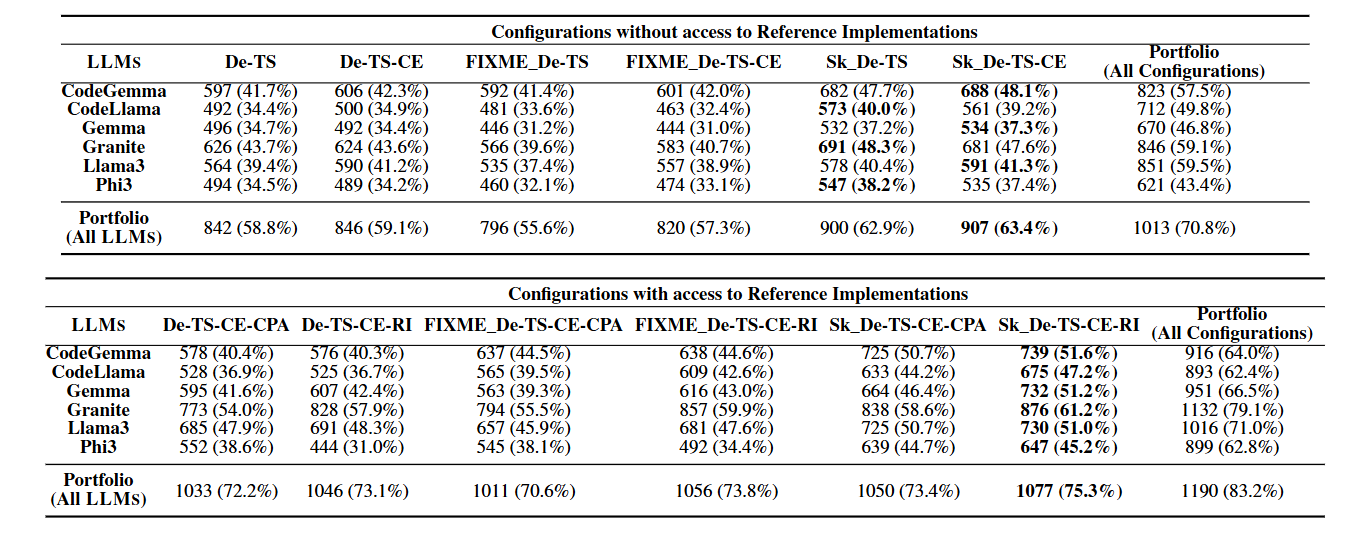
表 1:在不同配置下,每个 LLM 修复的程序数量。行 Portfolio(All LLMs) 显示了针对每个配置,在所有 LLMs 中取得的最佳结果。列 Portfolio(All Configurations) 显示了针对每个 LLM,在所有配置中取得的最佳结果。配置名称与缩写的对应关系如下:De - IPA 描述(IPA Description),TS - 测试集(Test Suite),CE - 反例(Counterexample),RI - 参考实现(Reference Implementation),CPA - 基于 AST 的最接近程序(Closest Program using ASTs),FIXME - FIXME 注释(FIXME Annotations),SK - 程序草图(Sketches)。

表 2:每个 LLM 在不同配置下成功修复的程序,其累计距离分数(cumulative distance scores)。
表 1 展示了在不同配置下每个 LLM 成功修复的程序数量。标有 Portfolio 的行表示通过在所有 LLMs 中为每个程序选择最佳配置所获得的最优结果。同时,Portfolio 列 突出了特定 LLM 在所有测试配置中取得的最佳结果。对于六个被评估的 LLMs,能够实现最高修复成功率的配置都涉及将 IPA 的参考实现纳入提示中。然而,LLMs 通常并非真正修复错误程序,而是直接将其替换为参考实现。例如,GRANITE 使用包含无错误程序草图(Sk)、IPA 描述、反例、测试集和参考实现(Sk_De-TS-CE-RI)的配置修复了 876 个程序。值得注意的是,其中有 442 个修复程序 的参考实现与修复程序之间的 TED 值为零,表明 GRANITE 实际上是在复制参考实现。为了解决这一问题,我们分别分析了包含和不包含参考实现的配置。当未提供参考实现时(表 1 上部),GRANITE 仍在所有 LLMs 中表现最佳,在所有配置下修复了高达 59.1% 的程序;在使用程序草图(SK)、IPA 描述和测试集(SK_De-TS)的情况下,修复率为 48.3%。CODEGEMMA 也表现良好,在组合(portfolio)方法下达到 57.5% 的成功率,并且在涉及草图(SK)的配置中表现尤为突出。例如,CODEGEMMA 使用无错误草图、IPA 描述、测试集和反例(SK_De-TS-CE)可以修复 48.1% 的评估基准程序。包含草图(SK)和 FIXME 注释的配置通常会产生更好的结果。包括反例(CE)、IPA 描述和测试集(De-TS)可进一步提高不同 LLMs 的成功率。Portfolio 方法(即在不使用参考实现的情况下组合所有 LLMs 和配置的优势)实现了最高的总体成功率,
修复了 70.8% 的程序。这表明,结合多个 LLMs 的能力可以显著提高修复成功率。
此外,我们提供了包含参考实现的 LLMs 的结果(见表 1 底部)。参考实现可以是同一 IPA 的讲师实现,也可以是根据先前提交的学生程序的抽象语法树(AST)通过树编辑距离(TED)值确定的最接近的正确程序。其目的是允许模型重用正确的代码片段以生成修复。结果表明,包含参考实现可以获得更好的修复结果。然而,如前所述,LLMs 通常只是简单地复制提供的参考实现。表 2 展示了来自表 1 的最佳表现 LLMs 在不同配置下的距离分数(distance score)(参见公式 1)的总和。此总和旨在惩罚那些复制提供的参考实现或生成不必要大型修复的 LLMs。例如,GRANITE 在使用配置 Sk_De-TS-CE-RI 时可修复 876 个程序,但其总距离分数为 334.5;
而使用相同配置但不包含正确实现时修复 681 个程序,总距离分数为 533.6。
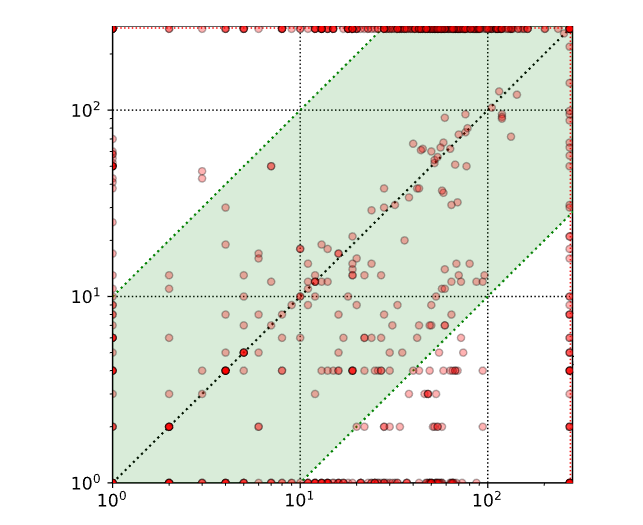
图 2:比较 GRANITE 在使用(x 轴)与不使用(y 轴)正确实现的情况下,采用配置 Sk_De-TS-CE 时修复所得程序的树编辑距离(Tree Edit Distance, TED)。
图 2 展示了一个散点图,比较了 GRANITE 在有参考实现和无参考实现情况下修复程序的树编辑距离(TED),使用的配置为 Sk_De-TS-CE。每个点代表一个错误程序,其中 x 值(分别对应 y 值)表示 GRANITE 在有参考实现(分别为无参考实现)情况下的 TED 成本。位于对角线下方的点表示:在有正确实现的情况下修复程序的 TED 成本高于无正确实现时的 TED 成本。这表明,尽管访问参考实现使 GRANITE 和其他 LLMs 能够修复更多程序,但通常会导致对学生程序进行更大幅度的修改,相比之下,在没有正确实现的情况下修改更小。
5.7 讨论(Discussion)
为回答我们的研究问题:
-
对于 RQ1,所有六种 LLMs 在不同提示配置下修复的程序数量均多于传统修复工具。
-
对于 RQ2,包含基于故障定位的程序草图、IPA 描述和测试集的提示配置产生了最成功的修复结果。
-
此外,对于 RQ3,显然引入基于故障定位的草图(或甚至是 FIXME 注释)能够使 LLMs 修复的程序数量多于仅提供错误程序的情况。
-
对于 RQ4,包含参考实现可修复更多程序,但修复效率可能较低。
-
最后,对于 RQ5,采用反例引导(Counterexample-guided)方法显著提高了在各种配置下基于 LLM 的自动程序修复(APR)的准确性。
反例在某些 LLMs(如 CODEGEMMA 和 LLAMA3)的修复过程中起到了帮助作用,适用于所有提示配置。对于其他 LLMs,反例也是有益的,但仅在特定配置下有效。这种差异可能是由于每个 LLM 所使用的训练数据不同所致。此外,我们分析了 LLMs 在修复 CLARA 无法处理的(由于控制流问题)程序时的有效性,结果发现,GRANITE 在 Sk_De-TS 配置下表现最佳,修复了 37.0% 的案例,而 CODEGEMMA 在 Sk_De-TS-CE 配置下修复了 34.5%。GRANITE 在具有较高平均圈复杂度(cyclomatic complexity)的案例中也表现出更优的性能,而 CODEGEMMA 在较简单的程序上最为有效。
第六章 相关工作(Related Work)
已经提出了若干基于约束的程序修复技术,用于检查学生程序的语义正确性:基于聚类的方法、基于实现的方法以及语义代码搜索方法。基于聚类的修复工具(接收一个错误程序、一个测试集,以及针对同一 IPA 的一组正确学生提交。基于实现的修复工具则利用一个参考实现来修复给定的错误提交。
在代码上训练的大型语言模型(LLMCS)在生成程序修复方面表现出了显著的有效性。例如,RING是一种多语言修复引擎,由 LLMC 提供支持,它利用错误信息中的故障定位(FL)信息,并利用 LLMCS 的少样本能力进行代码转换。在面向编程教育的自动程序修复(APR)场景中,一些研究探索了 LLM 在编码任务中的应用。例如,PyDex使用 CODEX(一种 ChatGPT 的 LLMC 版本)进行迭代查询,通过基于测试的少样本选择和基于结构的程序分块来修复 Python 作业中的语法和语义错误。类似地,CODEHELP利用 OpenAI 的 LLM 为学生作业提供文本反馈。然而,据我们所知,目前尚无研究探索由公式驱动的故障定位(formula-based FL)指导下的 LLM 修复方法。
第七章 结论(Conclusion)
大型语言模型(LLMS)在字符串补全方面表现出色,而基于 MaxSAT 的故障定位(FL)在识别程序中的错误部分方面具有优势。我们提出了一种新方法,将基于 MaxSAT 的故障定位与 LLMS 结合,通过零样本学习(zero-shot learning)增强入门级编程作业(IPAS)的自动程序修复(APR)能力。实验结果表明,我们生成的无错误程序草图(bug-free program sketches)显著提升了六种评估的 LLMS 的修复能力,使其能够修复更多程序,并生成比其他配置及最先进符号程序修复工具更小的补丁。因此,形式化方法与 LLMS 的这种交互能够产生更准确、高效的程序修复结果,同时增强编程教育中的反馈机制。
启发
它把形式化逻辑的“确定性”与 LLM 的“泛化性”融合在一起,系统完全零样本运行,可直接嵌入在线编程教学平台。 学生不仅能看到错误行,还能理解修复逻辑,提升学习效率。 这篇论文的意义不止于修复算法的改进,更在于它构建了一个“会思考、会验证、会反馈的教学型AI系统”。
反例通过符号执行的思想能不能更好生成。
相关知识链接
- 论文链接
- BibTex
@inproceedings{orvalho2025counterexample,
title={Counterexample Guided Program Repair Using Zero-Shot Learning and MaxSAT-based Fault Localization},
author={Orvalho, Pedro and Janota, Mikol{\'a}{\v{s}} and Manquinho, Vasco M},
booktitle={Proceedings of the AAAI Conference on Artificial Intelligence},
volume={39},
number={1},
pages={649--657},
year={2025}
}

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 23
23 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)