【ComfyUI】动漫转真人 多光影效果
本文介绍了一个基于ComfyUI的动漫转真人工作流,通过多ControlNet融合与面部细节增强技术实现高质量人像生成。核心使用AWPortrait XL 1.1模型和controlnet-union-sdxl模型,结合姿态、深度等多通道控制信息。工作流包含图像预处理、提示词构建、ControlNet融合、潜空间采样及面部优化等阶段,采用FaceDetailer增强面部细节,最后通过色彩匹配输出写
今天给大家演示一个 动漫转真人 的 ComfyUI 工作流,通过组合多种 ControlNet、多种风格融合与面部细节增强技术,实现了高质量、富有光影层次的人像生成效果。该流程不仅支持对动漫风格人物的高度还原与再构造,还能加入多模态条件(如姿态、深度、色调、面部检测等),生成极具真实感的图像。在最终效果图中,你将直观看到人物肤质的自然过渡、光影的细腻表现以及五官细节的精准塑形,是一次完整的从“二次元”迈向“写实感”图像合成的演绎。

文章目录
工作流介绍
本工作流以“动漫人物图像转写实风格肖像”为目标,采用 ComfyUI 强大的节点图形化建模能力,结合了多个 ControlNet 路径处理策略,依次执行了图像预处理、姿态识别、深度感知、贴图切片、面部检测与优化等环节,最终通过高保真模型采样与色彩匹配,将二维动漫形象还原为自然光下的人像照片。
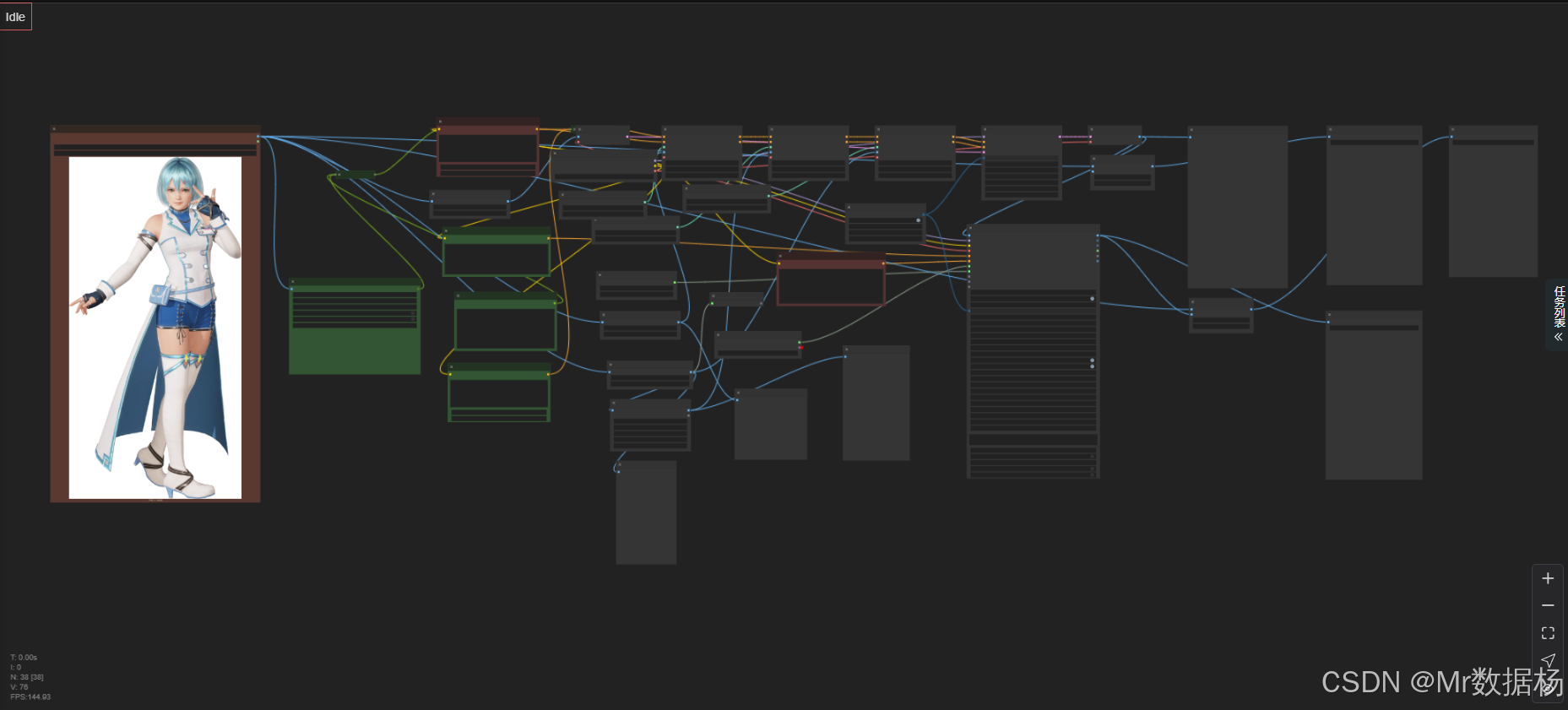
流程搭建中,利用 AWPortrait XL_1.1.safetensors 模型作为核心基础,搭配 controlnet-union-sdxl-1.0_promax.safetensors 在多个输入通道(openpose、depth、tile)中进行多条件引导,再结合面部检测器、分割模型与精细采样策略,在稳定性与写实性之间取得了良好平衡。
整体流程既适用于自动化风格迁移,也可作为高端个性定制图像生成工具进行拓展。
核心模型
在本工作流中,使用的主要模型为 AWPortrait XL_1.1.safetensors,该模型专为人像构图优化,能够在保留原始图像特征的同时,生成写实风格极强的图像输出。
| 模型名称 | 说明 |
|---|---|
| AWPortrait XL_1.1.safetensors | 高保真写实风格人像模型,适用于面部还原与自然光表现优化 |
| controlnet-union-sdxl-1.0_promax.safetensors | 用于姿态(openpose)、深度(depth)、贴图(tile)等控制条件,增强生成一致性与图像结构完整度 |
多个 ControlNet Loader 以不同感知维度加载该权重,为图像提供了丰富的空间信息支持,使结果在姿态、深度与纹理分布方面均保持高拟合度。
Node节点
本流程包含的关键节点涵盖图像加载、预处理、特征提取、条件组合、模型采样与图像输出等模块,结构清晰,层次分明。通过 FaceDetailer 精细化人脸重建,并使用 easy imageColorMatch 做最终色彩融合,使输出图像在真实度与美观度方面达到最佳平衡。
| 节点名称 | 说明 | |
|---|---|---|
| LoadImage | 加载输入图像作为源图 | |
| ImageScaleToTotalPixels | 调整图像至指定像素密度,确保后续处理稳定 | |
| WD14Tagger | pysssss | 自动标签生成器,用于提取动漫图像中的风格关键词 |
| Text Concatenate | 合并提示词字符串 | |
| CLIPTextEncode / A1111 | 编码正/负向提示词,为生成提供文本引导 | |
| ACN_ControlNet++LoaderSingle | 分别加载 depth、tile、openpose 三种控制通道 | |
| TilePreprocessor / DepthAnythingPreprocessor / OpenposePreprocessor | 提取图像对应控制信息(结构、深度、姿态) | |
| ControlNetApplyAdvanced | 多次串联应用 ControlNet,实现信息融合 | |
| VAEEncode / VAEDecode | 编码与解码图像潜空间数据,支持稳定生成 | |
| KSampler | 核心采样器,控制迭代次数与种子生成 | |
| FaceDetailer | 面部细节增强模块,搭配 YOLOv8 人脸检测与 SAM 分割 | |
| easy imageColorMatch | 色彩匹配处理器,使图像风格统一 | |
| SaveImage / PreviewImage | 保存最终图像或中间结果,方便调试与展示 |
该组合不仅保证了图像结构还原的准确性,也为风格融合提供了丰富的可控手段。下一步,我们将继续解析整个工作流程的阶段性任务划分与节点应用细节。
工作流程
整个动漫转真人的图像生成工作流程划分为多个阶段,从图像加载开始,依次进行图像预处理、提示词构建、多重 ControlNet 控制、潜空间采样、图像解码、细节增强与色彩修正。每一阶段都承担着关键功能,确保最终生成图像既真实自然,又具有强烈的美感表达。
流程起始阶段通过 LoadImage 节点引入原始动漫图像,随后利用 ImageScaleToTotalPixels 进行尺寸规范,保障后续流程中的图像一致性。标签生成器 WD14Tagger 自动提取图像风格标签,与手动提示词经 Text Concatenate 拼接后,送入 CLIPTextEncodeA1111 生成正负向语义特征。
图像同时被送入多个 ControlNet 通道(openpose、depth、tile)提取姿态、结构和纹理信息,分别通过 OpenposePreprocessor、DepthAnythingPreprocessor 与 TilePreprocessor 节点执行。处理后由三个 ControlNetApplyAdvanced 节点进行分阶段融合,形成带有完整语义与结构的指导信息。
进入中后段,利用 KSampler 执行模型采样生成潜空间图像,再通过 VAEDecode 解码为图像格式,进入细节增强模块。FaceDetailer 搭配 Ultralytics 的 YOLOv8 模型、SAM 分割与提示词对面部区域进行多轮优化,进一步提升精细度。
最后,图像经 easy imageColorMatch 节点统一色彩风格,通过 SaveImage 完成输出保存。
| 流程序号 | 流程阶段 | 工作描述 | 使用节点 |
|---|---|---|---|
| 1 | 输入准备 | 加载源图并规范图像大小 | LoadImage、ImageScaleToTotalPixels |
| 2 | 文本提示构建 | 自动+手动生成提示词并编码 | WD14Tagger、Text Concatenate、CLIPTextEncodeA1111 |
| 3 | 多通道控制信息提取 | 获取姿态、深度与纹理信息 | OpenposePreprocessor、DepthAnythingPreprocessor、TilePreprocessor |
| 4 | ControlNet融合 | 三段式融合语义与结构信息 | ControlNetApplyAdvanced (x3) |
| 5 | 潜空间采样 | 使用核心模型进行图像生成 | KSampler |
| 6 | 解码生成图像 | 将潜图解码为可视图像 | VAEDecode |
| 7 | 细节优化 | 面部检测、修复与细节增强 | FaceDetailer、UltralyticsDetectorProvider、SAMLoader |
| 8 | 风格统一输出 | 色彩匹配与最终保存 | easy imageColorMatch、SaveImage |
大模型应用
负面提示文本编码(CLIPTextEncodeA1111)
该节点的任务是为生成过程提供负面引导,限制模型生成过程中出现不符合预期的元素。例如,防止画面出现低质量、模糊、姿态错误或违禁内容。通过构建一串详细的负面 Prompt,确保图像输出保持干净、聚焦并符合美学标准。
| 节点名称 | Prompt信息 | 说明 |
|---|---|---|
| CLIPTextEncodeA1111 | text, watermark,nsfw,nude,2d anime style,3d style, (worst quality),(low quality),(normal quality),lowres,bad anatomy, ((bad hands,broken hands)),(many fingers),((grayscale)) watermark,moles, |
此 Prompt 设计用于最大程度排除模型在生成图像过程中可能出现的低质量、违禁或不相关内容,保持输出图像的专业度与可用性。 |
正面提示文本组合(CLIPTextEncodeA1111)
该节点通过将不同来源的提示词拼接为一个整体,形成面向生成模型的正向引导语。它融合了“真实感”、“风格设定”与“细节刻画”等多个维度,确保生成结果不仅真实,而且贴近设定目标。
| 节点名称 | Prompt信息 | 说明 |
|---|---|---|
| CLIPTextEncodeA1111 | ((realistic photo)), true |
提示词强调写实风格,配合标签自动生成内容拼接,引导模型专注于生成高保真真实风格的图像输出。 |
面部细节优化提示(CLIPTextEncode)
在人脸增强环节,该节点通过专用提示词对面部区域进行强化引导。强调肤质、特征清晰度和亚洲面孔特征,为 FaceDetailer 提供高质量的语义条件,有效提升生成脸部区域的美观度和真实感。
| 节点名称 | Prompt信息 | 说明 |
|---|---|---|
| CLIPTextEncode | best quality,realistic young asian lady face, pale skin,beautiful lady face, |
明确聚焦于亚洲女性面部特征的真实表达,通过语义强化提升细节表现力与美感表达,是 FaceDetailer 模块的重点辅助节点。 |
全局风格质量提示(CLIPTextEncodeA1111)
该节点为整图提供广义正向生成条件,提示词集中表达“杰作”、“极致细节”、“真实摄影感”等关键词,增强整体图像生成时的质量与层次感。
| 节点名称 | Prompt信息 | 说明 |
|---|---|---|
| CLIPTextEncodeA1111 | masterpiece,ultradetailed,best quality, extremely detailed,realistic photo,realistic, |
指导模型从整体构图上达到高细节高保真图像效果,起到提升全图生成质量的作用,适用于背景、服装等非面部区域的风格控制。 |
使用方法
开始节点
本流程的起始由多个节点协同完成,以 LoadImage 输入动漫风格图像为起点,再通过语义提示与图像结构控制模块进入后续流程。下表为关键开始节点参数说明:
| 字段名 | 含义 | 数据类型 |
|---|---|---|
| file_name | 加载的图像文件路径 | str.String |
| method | 图像加载方式(image/mask) | str.String |
| scale | 图像缩放系数(图像标准化尺寸) | float |
| tagger_model | 图像自动标签模型 | str.String |
| prompt_text | 手动提示词(正向) | str.String |
| negative_prompt_text | 手动提示词(负向) | str.String |
结束节点 设置结束工作成品的数据输出类型与格式
输出节点通过 SaveImage 将最终结果以图像形式保存,也可用于中间阶段保存查看,方便调试与选图。
| 字段名 | 含义 | 数据类型 |
|---|---|---|
| output_path | 图像保存路径或名称标识 | str.String |
| image | 最终生成图像 | IMAGE |
| format | 输出格式,如 PNG、JPG 等 | str.String |
| tag | 可用于标注处理流程,如 ComfyUI 标识 | str.String |
应用场景
该工作流广泛适用于从二次元图像向真实人像风格迁移的各类需求。无论是动漫 IP 的写实风格重制、游戏角色真实化设定,还是 AIGC 个人定制写真生成场景,都能高效应用。
其在细节增强、多通道引导控制、面部精修与自然光影模拟方面的多层次处理能力,使其成为当前 ComfyUI 人像风格迁移工作流中的高质量解决方案之一。
| 应用场景 | 使用目标 | 典型用户 | 展示内容 | 实现效果 |
|---|---|---|---|---|
| 数字人创作 | 从二次元立绘生成真人形象 | 虚拟主播、AI偶像创作者 | 虚拟人物的写实脸部图像 | 保留角色特征的真人照片级输出 |
| 影视概念设计 | 动漫角色真人化设定图 | 概念设计师、导演组 | 真人角色草图或封面 | 快速迭代角色外观设定 |
| 同人图翻拍 | 真人化演绎经典动漫人物 | 同人创作者、画师 | 姿态重构、角色还原图 | 真人版的重构作品 |
| AI模特生成 | 基于二次元设计做展示图 | 品牌方、电商设计团队 | 真人穿搭效果图 | 快速展示风格搭配效果 |
开发与应用
更多 AIGC 与 ComfyUI工作流 相关研究学习内容请查阅:
更多内容桌面应用开发和学习文档请查阅:
AIGC工具平台Tauri+Django环境开发,支持局域网使用
AIGC工具平台Tauri+Django常见错误与解决办法
AIGC工具平台Tauri+Django内容生产介绍和使用
AIGC工具平台Tauri+Django开源ComfyUI项目介绍和使用
AIGC工具平台Tauri+Django开源git项目介绍和使用

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 11
11 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)