和 AI 聊天总被 “忽悠”?聊聊 LLM 的 “幻觉” 问题
**LLM的"幻觉"指模型生成看似合理但实际错误的内容,这是统计模型追求语言流畅性而非事实准确性的必然产物。技术根源包括训练目标的局限性、数据噪声以及缺乏事实验证机制。幻觉表现形式多样,从细节错误到完全虚构,常因自信表达而更具迷惑性。目前通过检索增强生成等技术缓解,但无法根除。用户需保持批判思维,交叉验证重要信息;开发者则在改进训练方法和集成外部知识方面持续探索。有趣的是,这种
·
当你的AI助手自信地告诉你“秦始皇在1888年发明了电话”时,你正在见证LLM最奇特的现象——幻觉。这不是欺骗,而是统计模型在概率世界里的“创造性发挥”。
什么是LLM的“幻觉”?
基本定义
幻觉是指LLM生成的内容看似合理、表述自信,但实际上与事实不符或完全虚构的现象。
真实案例展示
# LLM幻觉的典型表现
幻觉示例 = {
"历史事实": {
"输入": "秦始皇统一六国后做了什么?",
"事实回答": "推行郡县制,统一文字、货币、度量衡",
"幻觉回答": "秦始皇建立了科举制度,并派遣郑和下西洋" # 时间错乱!
},
"科学知识": {
"输入": "水的沸点是多少?",
"事实回答": "在标准大气压下是100°C",
"幻觉回答": "水的沸点是78°C,这也是酒精的沸点" # 数字混淆!
},
"人物信息": {
"输入": "介绍爱因斯坦的成就",
"事实回答": "提出相对论,获得1921年诺贝尔物理学奖",
"幻觉回答": "爱因斯坦发明了电话并获得了诺贝尔化学奖" # 完全混乱!
}
}
为什么会产生幻觉?技术根源探秘
本质原因:LLM是“概率艺术家”而非“知识库”
具体技术原因分析
1. 训练目标的本质局限
# LLM的训练目标:预测下一个词的概率
def 训练目标(文本):
for i in range(len(文本)):
上文 = 文本[:i]
下一个词 = 文本[i]
# 模型学习:P(下一个词 | 上文) 的概率分布
模型参数更新(上文, 下一个词)
# 问题:模型优化的是“语言流畅度”,不是“事实准确度”
2. 训练数据的噪声与矛盾
# 互联网数据中的问题
训练数据问题 = {
'事实错误': "网络上大量存在的错误信息",
'观点事实混淆': "把个人观点当作事实陈述",
'过时信息': "科学知识在不断更新,但训练数据固定",
'文化差异': "不同文化背景下的不同'事实'",
'虚构内容': "小说、剧本等创造性作品"
}
# 模型学习的是“人们常说什么”,而不是“什么是真的”
3. 缺乏事实核查机制
# 人类思考 vs LLM生成
def 人类回答(问题):
理解问题()
检索相关知识()
逻辑推理()
事实核查() # ← 这步LLM没有!
组织语言回答()
def LLM回答(问题):
分析问题模式()
基于概率生成文本() # 直接跳到这步
返回结果
幻觉的多种面孔:不同类型的幻觉
按照严重程度分类
幻觉分类 = {
'轻度幻觉': {
'描述': '细节错误或微小不准确',
'例子': '把"1984年"说成"1985年"',
'危害': '较低,但影响可信度'
},
'中度幻觉': {
'描述': '关键事实错误',
'例子': '说"莫言获得了诺贝尔物理学奖"',
'危害': '中等,可能误导用户'
},
'重度幻觉': {
'描述': '完全虚构的事实',
'例子': '描述一个不存在的历史事件',
'危害': '严重,完全错误的信息'
},
'危险幻觉': {
'描述': '可能造成伤害的虚假信息',
'例子': '提供错误的医疗建议',
'危害': '极高,可能造成实际伤害'
}
}
按照表现形式分类
| 幻觉类型 | 特点 | 示例 |
|---|---|---|
| 事实幻觉 | 客观事实错误 | “太阳绕地球转” |
| 逻辑幻觉 | 推理过程错误 | “所有鸟都会飞,企鹅是鸟,所以企鹅会飞” |
| 引用幻觉 | 虚构信息来源 | “根据哈佛大学2023年研究…”(不存在) |
| 数字幻觉 | 数值数据错误 | “中国人口200亿” |
| 时间幻觉 | 时间顺序混乱 | “爱因斯坦指导了牛顿的研究” |
为什么幻觉看起来如此“真实”?
自信的表达风格
# 幻觉的“迷惑性”来源
迷惑性特征 = {
'语言流畅': "使用专业术语和流畅表达",
'细节丰富': "添加具体数字、日期、名称等细节",
'结构完整': "有引言、论证、结论的完整结构",
'语气肯定': "使用确定性的语言,很少使用'可能''也许'",
'前后一致': "在单个回答内保持逻辑自洽"
}
# 示例:一个看起来很专业的幻觉
幻觉回答 = """
根据2022年《自然》杂志发表的最新研究,科学家发现
每天饮用3杯咖啡可以将心脏病风险降低47%。该研究
跟踪了5万名参与者,历时15年,具有很高的可信度。
"""
# 实际上这个研究根本不存在!
技术层面的解决方案
现有的缓解方法
检索增强生成详解
class 增强型LLM:
def 回答_with_RAG(self, 问题):
# 1. 首先检索相关知识
相关知识 = self.检索知识库(问题)
# 2. 基于检索到的知识生成回答
回答 = self.基于知识生成(问题, 相关知识)
# 3. 标注信息来源
结果 = {
"回答": 回答,
"来源": 相关知识.来源,
"置信度": self.计算置信度(回答)
}
return 结果
# 这种方法显著减少幻觉,但不能完全消除
用户如何识别和应对幻觉?
识别幻觉的红旗信号
def 检查可能幻觉(回答):
红旗信号 = [
"没有提供具体来源或引用",
"包含过于绝对化的断言",
"数字或日期看起来不合理",
"与已知事实明显矛盾",
"听起来'好得不像真的'"
]
风险分数 = 0
for 信号 in 红旗信号:
if 信号 in 回答:
风险分数 += 1
return 风险分数 >= 2 # 多个红旗信号则很可能有幻觉
实用应对策略
# 与LLM交互的最佳实践
安全交互策略 = {
'交叉验证': "重要信息从多个来源验证",
'要求引用': "让模型提供信息来源",
'保持怀疑': "对惊人主张保持批判思维",
'领域区分': "在专业领域咨询真正专家",
'用途认知': "理解LLM更擅长创意而非事实"
}
开发者视角:减少幻觉的技术挑战
当前的技术难点
技术挑战 = {
'事实动态性': "世界在变化,但训练数据是静态的",
'知识边界': "模型不知道自已不知道什么",
'置信度校准': "难以准确评估回答的可靠程度",
'计算成本': "实时事实核查需要大量计算资源",
'多源矛盾': "不同可靠来源可能给出矛盾信息"
}
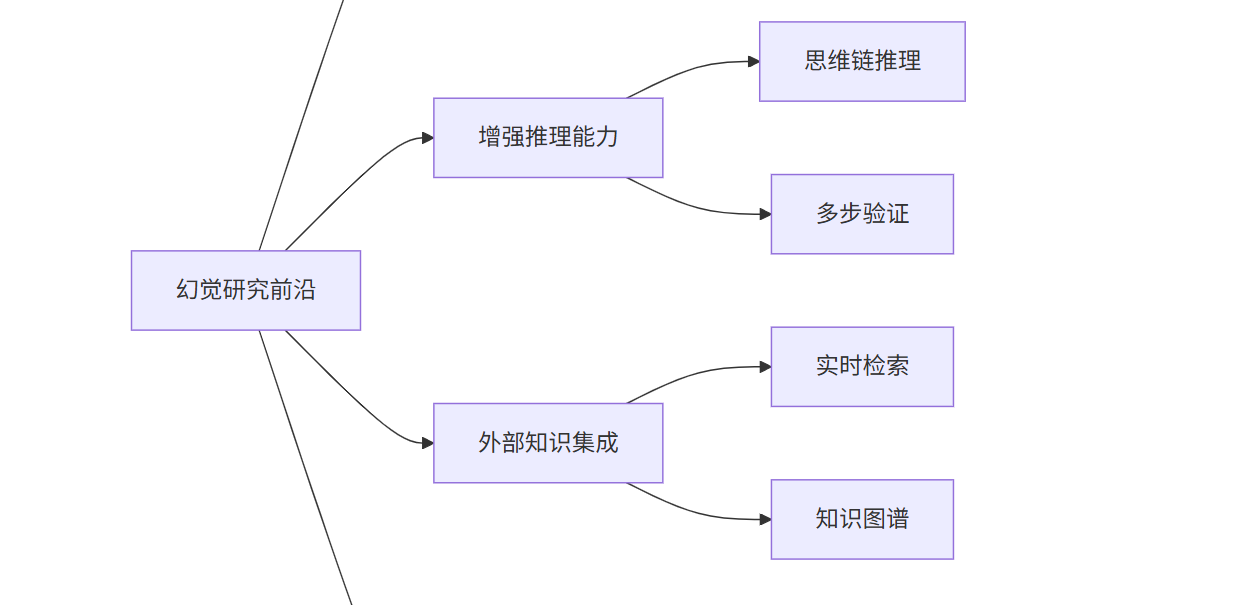
前沿研究方向
哲学思考:幻觉的深层意义
重新理解“错误”与“创造”
幻觉现象迫使我们重新思考人工智能的本质:
# 幻觉的两面性
幻觉的双重性 = {
'消极面': {
'事实错误': "可能传播错误信息",
'信任危机': "影响AI的可信度",
'安全风险': "在关键领域可能造成危害"
},
'积极面': {
'创造性': "同样的机制也产生创新想法",
'联想能力': "连接不相关概念可能激发灵感",
'知识探索': "有时会'偶然发现'真实联系"
}
}
# 同一个技术特性,既是bug也是feature
人机协作的新范式
# 理想的人机协作模式
def 理想协作(人类, AI):
人类优势 = ["事实判断", "伦理考量", "上下文理解", "直觉"]
AI优势 = ["信息检索", "模式识别", "创意生成", "大规模处理"]
# 结合双方优势
结果 = 人类监督(AI生成内容) + AI增强(人类决策)
return 结果
结语:与不完美的智能共舞
LLM的幻觉不是技术故障,而是当前技术范式的必然产物。理解这一点,我们就能:
- 理性使用:在适合的场景发挥LLM的优势
- 有效防范:识别风险并采取防护措施
- 持续改进:推动技术向更可靠的方向发展
- 保持批判:永远保持独立思考的能力
正如人类专家也会犯错一样,我们应该把LLM看作一个有能力但会出错的合作伙伴,而不是全知全能的神谕。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 25
25 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)