Agentic TASK01
所有步骤都是预先设定好的,所有工具调用都是硬编码的(Hard-coded),由人类工程师在代码中固定;这就像你指挥一个“听话但不会动脑”的助手:你得一步步告诉它做什么、什么时候查资料、怎么整理。找到结果后,它自己判断:“我要选5个最好的来源” → 调用“web fetch” + “pdf to text”工具提取内容。LLM 自己决定:先“web search”查资料 → 并且能调用“news”和
Agentic AI
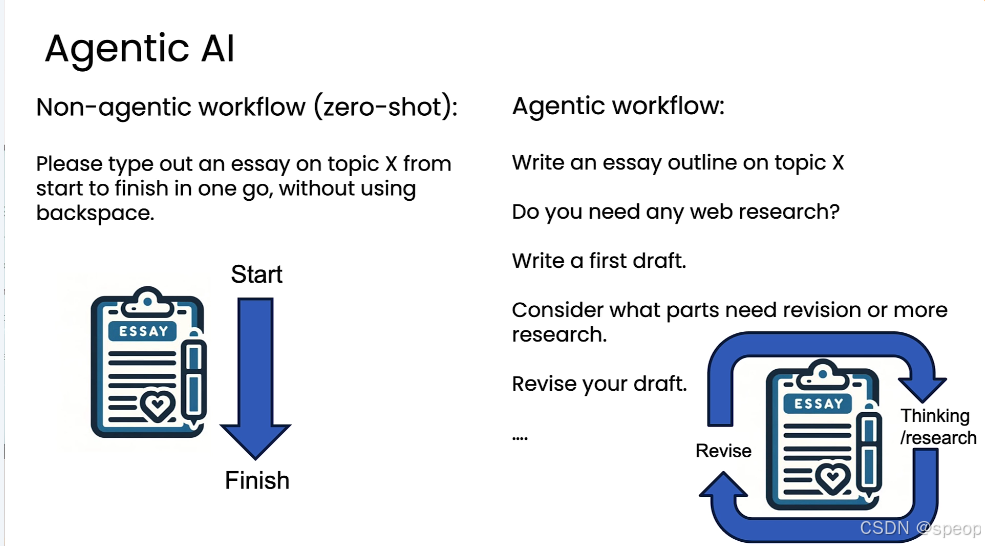
“非智能体”工作流指的是用户通过一个单一提示(prompt),要求大型语言模型(LLM)一次性完成整个任务,这种工作流被称为“零样本”(zero-shot)工作流。
例子: “请从头到尾写一篇关于主题X的文章,中间不能使用退格键修改。”
局限性:这就像让一个人或AI“一口气”从第一个字写到最后一个字,中间不能回头修改;无论是人类还是AI模型,都不擅长以这种完全线性的、不可逆的方式进行创作。尽管如此,目前流行从的大型语言模型在这种约束下依然能表现得相当不错。
Less autonomous(低自主性)
所有步骤都是预先设定好的,所有工具调用都是硬编码的(Hard-coded),由人类工程师在代码中固定;其中主要自主性体现在语言模型生成的文本上。
案例:
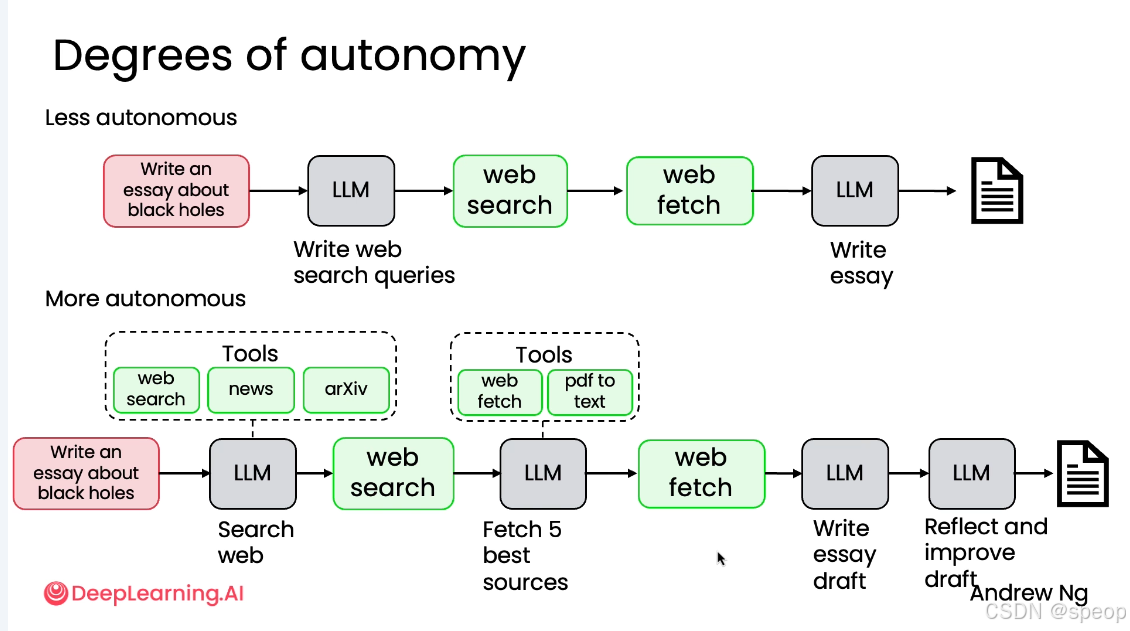
你告诉 LLM:“写一篇关于黑洞的论文”
LLM → 写出搜索关键词
去网页搜
抓取网页内容
LLM 把这些内容整合成文章
这就像你指挥一个“听话但不会动脑”的助手:你得一步步告诉它做什么、什么时候查资料、怎么整理。AI 只负责“写”,其他事都得你来操心。
More autonomous(高自主性)
代理能自主做出大量决策;能够动态地决定要执行的步骤顺序;甚至可以创建新的、可执行的工具(函数)来完成任务。
你告诉 LLM:“写一篇关于黑洞的论文”
LLM 自己决定:先“web search”查资料 → 并且能调用“news”和“arXiv”等工具,找最新科研动态
找到结果后,它自己判断:“我要选5个最好的来源” → 调用“web fetch” + “pdf to text”工具提取内容
然后它写初稿 → 再自己反思:“这个段落逻辑不够强,数据没引用清楚” → 主动改进草稿
最后输出高质量论文!
Benefits of agentic-ai
- 性能飞跃(Much Better Performance)
- 并行加速(Faster than Humans because of Parallelization)
- 模块化设计(Modular: Can Add/Update/Swap Components)

性能跃升 (Much Better Performance)
智能体工作流带来的性能提升,远超单纯升级模型版本(如从GPT-3.5到GPT-4)所带来的进步
测试目的: 评估不同语言模型编写代码的能力。
实证案例:HumanEval 编码基准测试 Coding Benchmark (HumanEval) 展示的是不同 AI 系统在编程任务上的表现——重点是对比 Non-agentic 和 Agentic的能力差异。 横轴 → 是“通过率”(正确完成编程题目的比例),从 40% 到 100%,越高越好。 纵轴 → 区分模型版本:GPT-3.5 vs GPT-4(GPT-4 更强)。
非智能体模式 (Non-agentic):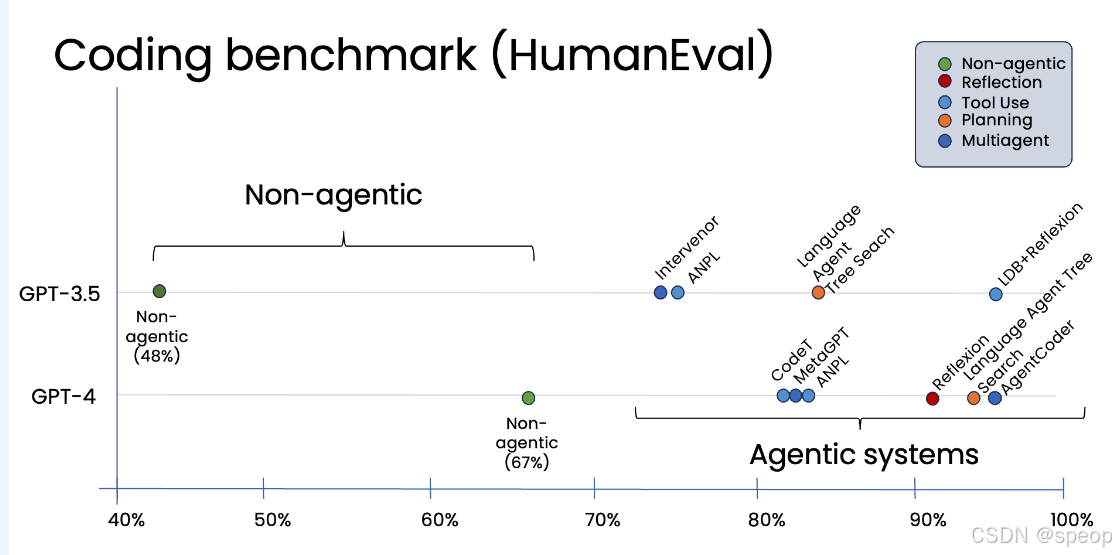
- GPT-3.5 直接生成代码,正确率约为 48%。
- GPT-4 直接生成代码,正确率提升至 67%。 智能体模式 (Agentic):
- 将 GPT-3.5 置于智能体工作流中(例如,让它先写代码,再自我反思、分析并改进),其性能可以显著提升,达到甚至超过 GPT-4 的水平。
- 同样,将 GPT-4 置于智能体工作流中,其表现也会比单独使用时更加出色。
并行加速 并行加速 (Faster than Humans because of Parallelization)
核心概念: 智能体工作流能够并行处理任务,从而比人类更快地完成特定工作。
实例演示: 以“撰写一篇关于黑洞的论文”为例。
- 人类方式: 需要顺序地进行搜索、阅读网页、再搜索、再阅读,效率低下。
智能体工作流方式:
并行搜索: 可以同时启动三个 LLM 实例,各自生成不同的搜索关键词并执行网络搜索。
并行抓取: 基于每次搜索的结果,每个 LLM 可以再并行抓取多个网页内容。
最终整合: 将所有并行获取的信息汇总,输入给一个 LLM 来撰写最终的论文。
结果: 虽然整个流程步骤更多,但由于大量的并行操作(如图示中的9个并行网页下载),其总耗时反而比人类顺序操作快得多。
模块化与可替换性
核心概念: 智能体工作流是高度模块化的,允许开发者自由地添加、更新工具或替换模型。
- 实践应用:
- 替换工具: 例如,在“网络搜索”这个环节,可以轻松地将默认的搜索引擎替换为 Serper、Bing、Dr. Google 或专门为 AI 设计的工具。
- 切换功能: 可以将通用的“web search”替换为“news search”,以便获取最新的科学突破资讯。
- 优化模型: 不必在所有步骤中使用同一个 LLM。可以根据不同步骤的需求,尝试不同的模型提供商,选择在该步骤表现最佳的模型,从而优化整个系统的表现。
Agentic-ai-applications
- agentic-ai一种让 AI Agent 根据明确或动态的任务目标,自主调用工具、访问数据库、执行步骤并完成任务的工作模式。
- 不同于传统“输入-输出”的简单问答,它强调多步骤规划、工具使用、状态更新与决策能力。
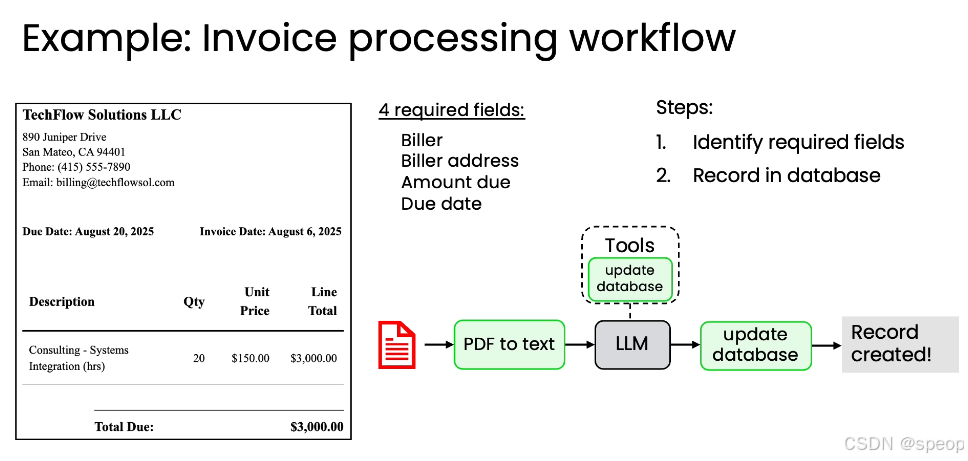
案例一:发票处理工作流(Invoice Processing)
自动化处理企业收到的发票,提取关键信息并记录到数据库,以确保及时付款。
**任务目标:**从 PDF 发票中提取关键信息(开票方、金额、到期日),并录入数据库。
所需字段:
- 开票方(Biller)
- 开票地址(Biller address)
- 应付金额(Amount due)
- 到期日(Due date) 工作流步骤:
- PDF 转文本 → 使用 API 将 PDF 转为结构化文本(如 Markdown)。
- LLM 解析文本 → 判断是否为发票,提取所需字段。
- 调用工具更新数据库 → 通过 update database 工具将数据存入系统。
- 生成记录成功提示 → “Record created!”
案例二:回复客户邮件(Responding to Customer Email)
示例邮件:“我订购了蓝色 KitchenPro 搅拌机(订单 #8847),但收到的是红色烤面包机。”
工作流步骤:
- 提取关键信息 → LLM 识别订单号、产品、问题。
- 查询订单数据库 → 使用 orders database query 工具获取订单详情。
- 起草回复草稿 → LLM 根据信息撰写回复。
- 请求人工审核 → 使用 request review 工具将草稿提交给人类审批。
- 发送邮件 → 审核通过后自动发送。
价值:提升客服效率,确保回复准确性。
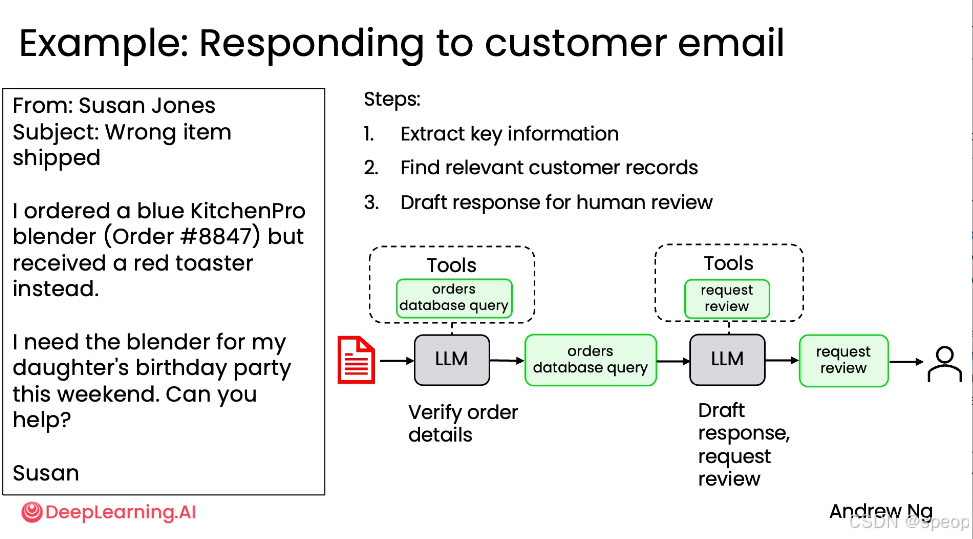
更复杂的客户服务agent(More Challenging: Customer Service Agent)
构建一个能处理各种未知问题的通用客户服务代理,而非仅限于特定订单查询。
场景一:库存查询:“你们有黑色或蓝色牛仔裤吗?”
agent需动态决定:
- 查询黑色牛仔裤库存
- 查询蓝色牛仔裤库存
- 综合回复客户 难点: 需要规划API调用的顺序来回答一个开放式问题。
场景二:退货处理:“我想退回我买的沙滩毛巾。”
agent需判断:
- 验证客户购买记录
- 检查退货政策(如是否在 30 天内、是否未使用)
- 若允许退货 → 生成退货标签 + 设置数据库状态为“待退货” 难点: 步骤不是预先固定的,代理必须根据条件判断并决定后续行动。
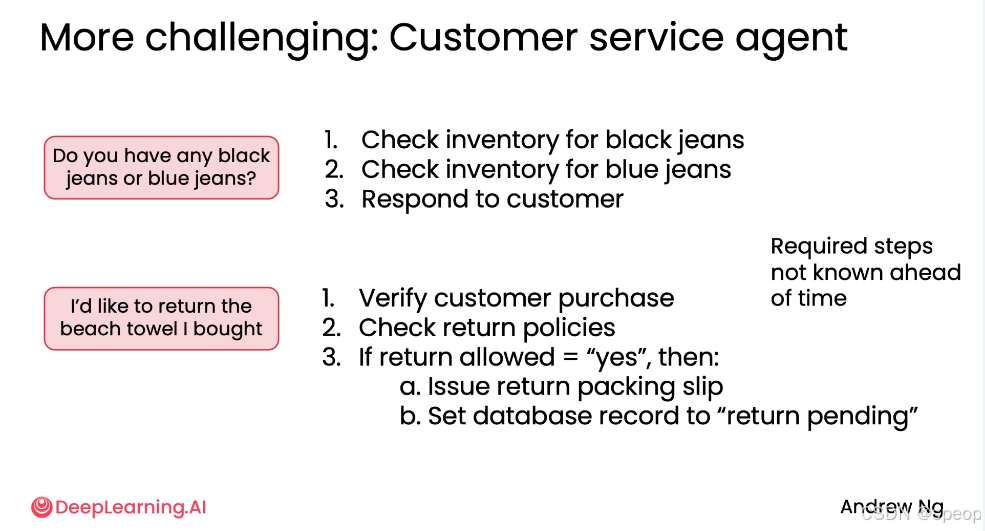
案例四:视觉计算机使用(Difficult: Visual Computer Use)
让AI代理像人类一样使用网页浏览器,完成复杂的交互式任务。
示例任务:让 AI agent检查从旧金山到华盛顿 DCA 机场的两个特定联合航空航班是否有空座。
agent行为:
- 自动打开浏览器,访问 United.com。
- 填写表单、点击按钮、导航页面。
- 遇到“页面未找到”错误 → 自主切换到 Google Flights。
- 在 Google Flights 上搜索航班 → 选择合适选项 → 返回 United 网站确认。
- 最终确认座位可用。
核心能力:
- 视觉理解(读取网页内容)
- 推理决策(遇到错误时调整策略)
- 工具调用(模拟鼠标点击、键盘输入)
- 状态跟踪(记住当前进度)
现实挑战:
- 页面加载慢 → agent可能卡住
- UI 变化 → agent无法识别元素
- 多模态输入 → 更难处理
- 前景:虽不稳定,但在关键任务应用(如金融、医疗)中潜力巨大。
代理型AI适合哪些任务? (What tasks is agentic AI suited to?)
这是一个从“容易”到“困难”的连续光谱:
较易实现的任务 (Easier)
- 清晰、逐步的流程 (Clear, step-by-step process): 有明确的执行步骤。
- 标准程序 (Standard procedures to follow): 企业已有成熟的操作手册。
- 纯文本资产 (Text assets only): 输入和输出均为文本,因为LLM擅长处理文本。
较难实现的任务 (Harder)
- 步骤未知 (Steps not known ahead of time): 任务需求在执行前不确定,需要代理动态规划。
- 边执行边解决 (Plan/solve as you go): 代理需要在过程中进行推理和决策。
- 多模态输入 (Multimodal: sound, vision): 需要处理图像、声音等非文本
任务分解
核心概念:任务分解 (Task Decomposition)
任务分解是构建代理型AI工作流的关键技能。其核心思想是:
- 观察人类行为: 思考如果一个人类要完成这个任务,他会怎么做?
- 拆解步骤: 将整个任务拆解成多个独立的、清晰的子步骤。
- 评估可行性: 对每个子步骤,思考它是否能用大型语言模型(LLM)或某个工具(如API、函数调用)来实现。
- 迭代优化: 如果初步分解的效果不理想,可以进一步细化某个步骤,将其拆分成更小的子步骤,直到达到满意的性能。
案例一:写一篇深度论文(Writing an Essay)
目标
让AI系统撰写一篇关于特定主题X的深入研究报告。
方法一:直接生成(1 步)
输入:Write an essay on topic X→ LLM → 输出文档 问题:内容表面化,缺乏深度和一致性。
方法二:三步工作流 (3-step Workflow)
- 撰写大纲 (Write an essay outline): LLM根据主题X生成一个结构化的写作提纲。
- 网络搜索 (Search web): LLM根据大纲生成搜索词,调用web search工具获取相关资料。
- 撰写论文 (Write the essay): LLM结合大纲和搜索到的信息,撰写最终的论文。 优点:引入外部信息,内容更丰富。 缺点:文章仍可能“脱节”,开头、中间、结尾风格不一致。
方法三:五步工作流 (5-step Workflow) - 撰写大纲 (Write an essay outline): LLM生成大纲。
- 网络搜索 (Search web): LLM调用web search工具获取信息。
- 撰写初稿 (Write a first draft): LLM根据大纲和搜索结果写出第一版草稿。
- 考虑修订部分 (Consider what parts need revision): LLM阅读自己的初稿,分析哪些部分需要改进。
- 修订草稿 (Revise your draft): LLM根据自我批评,对草稿进行修改和完善。 效果提升:模拟人类“写作-反思-修改”循环,输出质量显著提高。
核心方法论:“如果某一步骤效果不好,就把它再拆成更小的子步骤。”
实例二:回复客户邮件 (Responding to Customer Email)
目标
自动回复客户关于“发错货”的投诉邮件。
任务分解
- 提取关键信息 (Extract key information):
- 输入: 客户邮件。
- 操作: LLM解析邮件,提取发件人姓名(Susan Jones)、订单号(#8847)、订购商品(蓝色搅拌机)和问题(收到红色烤面包机)。
- 可行性: LLM擅长文本信息提取。
- 查找相关客户记录 (Find relevant customer records):
- 操作: LLM调用 orders database query 工具,根据订单号查询数据库,核实订单详情和发货记录。
- 可行性: LLM可以通过函数调用与数据库交互。
- 撰写并发送回复 (Write and send response):
- 操作: LLM根据提取的信息和查询到的记录,起草一封回复邮件,并调用 send email API 将其发送给客户。
- 可行性: LLM可以生成文本,并通过API执行发送动作。
关键洞察
- 这个例子展示了如何将一个看似单一的任务(回复邮件)分解为三个清晰、独立的步骤。
- 每个步骤都可以由LLM或其调用的工具完成,从而构成一个完整的自动化流程。
实例三:从发票中提取信息 (Extracting Information from Invoice)
构建代理型AI工作流的基本构件 (Building Blocks)
. 模型 (Models)
- 大型语言模型 (LLMs):
- 用途: 文本生成、工具使用决策、信息提取。
- 特点: 擅长处理文本,是代理工作流的大脑。
- 其他AI模型 (Other AI models):
- 用途: 处理非文本模态数据,如PDF转文本、文本转语音、图像分析等。
工具 (Tools)
- API:
- 用途: 执行外部服务,如网页搜索、获取实时天气数据、发送电子邮件、查看日历等。
- 信息检索 (Information retrieval):
- 用途: 从数据库或大型文本库中检索信息,常用于RAG(检索增强生成)场景。
- 代码执行 (Code execution):
- 用途: 允许LLM编写并运行代码,以执行更复杂的计算或数据处理任务,如基础计算器、数据分析等。
工作流步骤核心方法论
- 从宏观到微观: 面对一个复杂任务,不要试图一步到位。先将其分解为几个大的步骤。
- 评估每个步骤: 对每个步骤自问:“这个步骤能否由LLM或我拥有的某个工具来完成?”
- 迭代与细化: 如果某个步骤无法直接实现,或者实现效果不好,就把它再分解成更小的子步骤。
- 组合构件: 最终,你的工作流就是由“模型”和“工具”这两个基本构件按特定顺序组合而成的
工作流设计原则
- 从简单开始:先做 1-3 步的原型,再逐步扩展。
- 模块化设计:每个步骤应尽量独立、可复用。
- 容错与反馈:加入“检查”、“评审”步骤,避免错误累积。
- 持续迭代:没有一步到位的完美工作流,需不断优化。
Evaluation AI evals
为什么评估如此重要?
- 预测成败的关键:在团队合作中,能否有效评估工作流是区分“做得好”与“做得差”的最大因素之一。
- 驱动迭代优化:没有评估,就无法知道哪里出了问题,也无法改进。
- 避免“黑盒”陷阱:不能只看最终输出,要深入分析中间过程和错误根源。
评估的核心方法论
- 首要原则:先构建,再观察,后评估
- 问题: 在构建智能体工作流前,很难预知所有可能出错的地方。
- 解决方案: 不要试图提前设计所有评估标准。最佳实践是先构建一个初步版本,然后手动检查其输出,寻找那些你希望它能做得更好的地方。
- 识别低质量输出 (Look for low-quality outputs)
- 实例: 以处理客户订单查询的智能体为例。
- 输入: 客户邮件:“我订购了蓝色搅拌机,但收到了红色烤面包机。”
- 期望输出: 礼貌、专业、解决问题的回复。
- 低质量输出示例: “我很高兴您选择了我们——我们比竞争对手 CompCo 强多了。”
- 分析: 这种输出是错误的,因为它提到了竞争对手,这在商业场景中通常是不被允许的,会制造混乱。这是一个在构建前难以预见的问题。

3. 构建评估指标来追踪错误 (Add an evaluation to track the error)
- 目标: 量化并跟踪已识别的错误。
- 方法:
- 定义错误类型: 例如,“提及竞争对手”。
- 创建列表: 列出所有需要避免提及的竞争对手名称(如 CompCo, RivalCo)。
- 编写代码: 编写脚本自动扫描智能体的所有输出,统计提及这些竞争对手的次数和频率。
- if (competitor in response): num_competitor_mentions += 1
- 优势: 这是一个客观指标 (objective metric),可以用代码精确衡量,便于追踪改进效果。

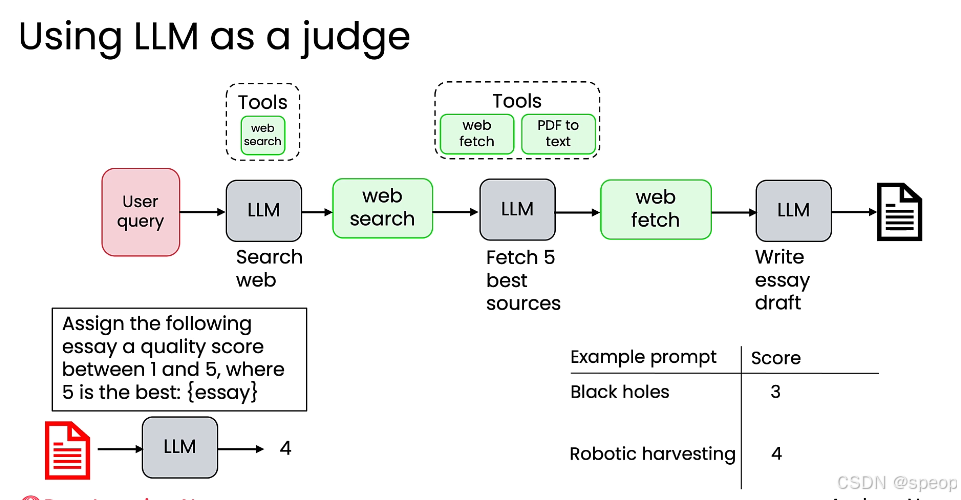
4. 使用大型语言模型作为裁判 (Using LLM as a judge)
- 适用场景: 当评估标准更为主观、难以用代码精确判断时(例如,评估一篇论文的质量)。
- 方法:
- 构建研究代理: 例如,一个用于撰写不同主题研究报告的智能体。
- 引入裁判 LLM: 使用另一个 LLM 来评估第一个 LLM 生成的报告。
- 设计评分提示词: 让裁判 LLM 对报告进行打分(例如,1-5分,5分为最佳)。
- 提示词示例:“请为以下文章分配一个1到5之间的质量分数,其中5是最好的:{essay}”
评估的两大主要类型
- **端到端评估 (End-to-end evals)😗*衡量整个智能体最终输出的整体质量。 例如:评估一篇完整论文的最终得分。
- 组件级评估 (Component-level evals):衡量智能体工作流中单个步骤或组件的输出质量。 例如:评估第一步“提取关键信息”的准确性,或第二步“查找相关客户记录”的召回率。

Agentic design patterns
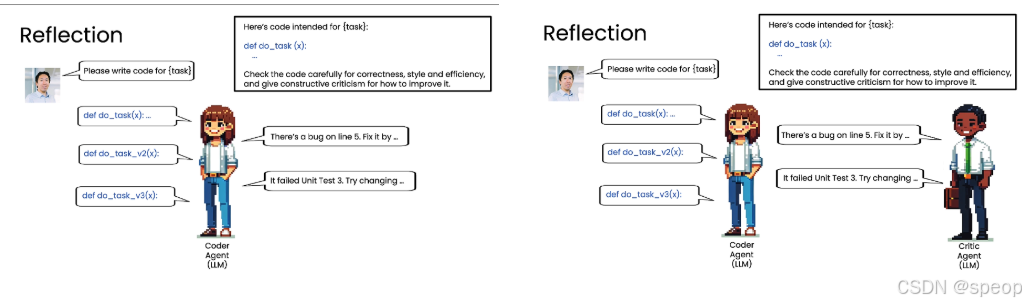
反思 (Reflection)
- 核心概念: 让模型对自己的输出进行检查、评估和改进。
- 工作流程:
- 初始生成: 模型根据任务要求生成一个初步结果(如代码)。
- 自我评估/外部评估: 将该结果作为输入,再次提示同一个或另一个模型,要求其对结果进行批判性分析(如检查正确性、风格、效率,并给出改进建议)。
- 迭代优化: 将评估反馈(如“第5行有bug”或“单元测试失败”)提供给模型,让它基于反馈生成一个更好的版本。
- 循环往复: 此过程可以多次迭代,直到达到满意的质量。
- 关键点:
- 这是一种非常有效的性能提升技术,虽然不能保证100%完美,但能带来显著的性能提升。
- “反思”可以由同一个模型完成,也可以引入一个专门扮演**“审查者”角色**的独立模型(即多智能体协作的雏形)。
- 评估标准可以是客观的(如代码是否能运行),也可以是主观的(如代码风格)。
工具使用 (Tool Use)
核心概念: 赋予语言模型调用外部工具或函数的能力,以扩展其功能边界。
工作流程:
- 识别需求: 模型在处理任务时,判断需要调用哪个工具。
- 调用工具: 模型生成调用该工具的指令或参数。
- 执行与返回: 工具执行操作(如搜索网络、计算数学公式),并将结果返回给模型。
- 整合结果: 模型利用工具返回的结果来完成最终任务。
工具类型举例:
- 信息收集: Web search, Wikipedia, Database access.
- 分析计算: Code Execution, Wolfram Alpha, Bearly Code Interpreter.
- 生产力: Email, Calendar, Messaging.
- 图像处理: Image generation, Image captioning, OCR.
规划 Planning
核心概念: 让模型自主决定完成一个复杂任务所需的步骤序列,而不是由开发者硬编码。
工作流程:
- 任务理解: 模型接收一个复杂请求(如“生成一张女孩读书的图片,姿势与示例图中的男孩相同”)。
- 路径规划: 模型自动分解任务,决定需要调用哪些工具以及调用的顺序。
- 例如:先用 openpose 模型提取男孩的姿势 -> 再用 google/vit 模型根据该姿势生成女孩的图片 -> 接着用 vit-gpt2 模型描述图片 -> 最后用 fastspeech 模型将描述转为语音。
- 执行: 按照规划的步骤依次执行。
关键点:
这种方式比硬编码的流程更灵活,但控制难度更大,也更具实验性。
它允许模型在面对新任务时,自行构思解决方案,有时会产生令人惊喜的结果。
多智能体协作
- 核心概念: 雇佣多个具有不同专长的角色(智能体)协同工作,共同完成一个复杂项目。
- 工作流程:
- 角色分配: 为不同的智能体分配特定角色(如研究员、市场专员、编辑)。
- 分工合作: 各个智能体根据自己的角色和能力,执行相应的子任务。
- 沟通协调: 智能体之间相互沟通、传递信息,共同推进项目。
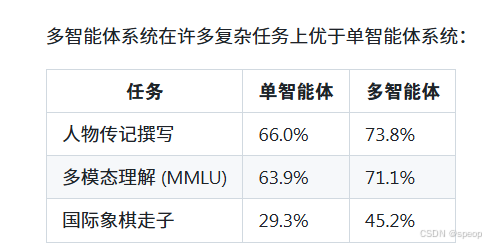
- 多智能体协作通常能产生比单个智能体更好的结果,尤其在处理复杂任务(如撰写人物传记、下棋)时。
- 研究表明,多智能体系统在多项任务上的表现优于单智能体系统。
- 其缺点是更难控制和调试,因为无法提前预知各个智能体的行为。


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 4
4 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)