LegionSpace黑客松指南(三):构建具有身份与记忆的AI智能体
本文探讨了构建智能体身份与记忆系统的关键技术。身份系统赋予智能体一致性和可信度,需结合DID等区块链技术实现不可篡改的链上身份验证;记忆系统则通过分层设计(短期/长期/结构化记忆)和链上链下存储结合,实现智能体的持续学习能力。文章以LegionSpace平台为例,展示了如何在客服场景中实践这些技术,同时强调了隐私保护、性能优化等关键挑战。最终建议开发者从小规模记忆开始,逐步扩展,充分利用现有平台基
本篇为通付盾第六届LegionSpace黑客松系列教程的第三篇。在上一篇中,我们深入探讨了MCP服务的开发与集成,为智能体装上了感知与行动的“手脚”。本篇将聚焦于智能体的“灵魂”塑造——如何为其构建稳定可信的身份与持续成长的记忆系统,使其从一次性的对话工具,进化为真正具有连续性和人格化的数字存在。
一、引言:为什么智能体需要身份与记忆?
在构建下一代AI智能体的征程中,我们正从创造孤立的、仅擅长对话的“大脑”,转向培育能够融入世界并主动行动的“数字生命”。一个仅在单次会话中有效的智能体,如同一个每次醒来都会失忆的助手,无法建立深度的用户关系,也无法进行复杂的多轮任务。身份与记忆,正是智能体突破“对话幻觉”、获得持续性的关键。
- 身份(Identity)赋予了智能体行为的一致性、角色的可信度和价值的归属性。它决定了智能体“是谁”,以及它以何种方式与世界互动。
- 记忆(Memory)则使智能体能够学习、反思和成长。它记录了智能体“经历过什么”,使其能够跨越会话进行学习,提供真正的个性化服务。
在本篇中,我们将系统性地解析如何在LegionSpace生态中,为你创造的智能体注入身份的灵魂与记忆的血肉。
二、身份系统:为智能体塑造“人格”
身份是智能体在数字世界中的立身之本。它远不止是一个简单的名称,而是一个融合了角色设定、行为模式、价值观与背景故事的复合概念。例如,一个智能体可以被塑造为“严谨的金融风控专家”或“充满创意的内容策划师”,这种核心身份的确定,决定了其与世界互动的基本方式。在去中心化的愿景中,这一抽象身份更需要与具体的去中心化标识符(DID)相结合,形成一个在链上可验证、归用户或智能体自身所有的唯一身份凭证,从而为可信交互奠定基石。
构建一个可落地的身份系统,需要几个核心组件的协同工作。其起点是身份标识,这相当于其在数字世界中的“身份证”。紧接着是身份存储,将身份的核心属性,例如角色描述、公钥和信誉分数,存储在智能账户或特定的链上身份合约中,以此确保其不可篡改且可公开验证。最后,身份验证机制确保了身份的安全使用,智能体通过私钥签名来证明“它是它”;对于更高阶的场景,甚至可以结合零知识证明(ZKPs)技术,在无需暴露全部信息的前提下,证明其满足某些特定的身份属性。
实现身份一致性需要一套清晰的技术路径。首先,通过在系统提示词(System Prompt)中固化智能体的核心角色、职责和行为边界,为身份一致性建立第一道防线。进而,利用我们后面将谈到的记忆系统,在会话结束时保存关键状态——如当前任务进度和用户偏好——并在新会话中主动恢复,以此来营造一种无缝的连续体验,让用户感受到始终在与同一个“人”打交道。更进一步,我们还可以引入行为演化机制,通过记录智能体的决策和用户反馈,允许其身份在核心框架内进行微调,从而实现一种令人信服的“成长感”。
在这一过程中,区块链技术为智能体身份带来了革命性的优势。它提供了不可篡改的身份记录,使得身份信息一旦上链就无法被单一实体随意修改或剥夺,从而建立了稳固的信任基础。基于标准协议,链上身份可以实现跨平台互通,轻松打破生态孤岛。此外,智能体的行为记录,如任务完成率和用户好评,可以通过智能合约累加成信誉分数,并与其DID紧密绑定,最终形成一份具有实际价值的“数字简历”。
三、记忆系统:让智能体拥有“成长”的能力
如果说身份确立了智能体是谁,那么记忆则定义了它经历过什么。一个高效的记忆系统需要进行精细的分层设计:
- 短期记忆等同于对话的上下文窗口,负责保存当前会话中的多轮对话历史,这通常由大模型本身管理。
- 长期记忆则更具价值,它用于存储跨越多个会话的重要信息,其中又可分为记录具体对话和事件的“情景记忆”,以及从交互中提炼出的知识、用户偏好和事实的“语义记忆”。
- 结构化记忆则以知识图谱、用户画像等形式,组织那些高度结构化、便于快速查询和推理的信息。
在架构设计上,记忆系统需要考虑存储、索引和演化等多个层面。在记忆存储策略上,我们需权衡链上链下的优劣:链上存储适用于最关键的身份信息和所有权记录,其优点是独立性与可验证,但成本高、容量有限;链下存储则适用于大量的对话历史与行为日志,可采用IPFS、Arweave等分布式存储或传统数据库,并将内容哈希(CID)存储在链上以实现存证。为了高效利用这些记忆,记忆索引技术至关重要,利用向量数据库对记忆内容进行嵌入和索引,可以实现基于语义相似度的快速检索,远远优于简单的关键字匹配。同时,一个聪明的记忆系统还应具备记忆更新与演化的能力,能够设计机制来评估记忆的价值,进行压缩、摘要、合并乃至主动遗忘,从而防止信息过载。
记忆的价值在于其能被适时激活与运用。在实践中,基于上下文的召回意味着在智能体需要做出决策时,能主动从长期记忆中检索与当前情境最相关的信息,并将其作为上下文提供给模型,使其决策更加精准和个性化。这个过程可以与工具调用深度协同,记忆系统本身可以作为一个MCP资源或工具暴露给智能体,允许其主动进行“记忆”“回忆”和“反思”等操作。在整个过程中,隐私与数据主权是不可逾越的底线,用户必须拥有对自己数据记忆的完全控制权,可以通过ZKPs等技术实现记忆的隐私检索,即证明某些记忆的存在而不暴露其具体内容。
在技术实现上,我们可以通过多种方式实现记忆的持久化。通过开发一个“记忆MCP服务”,可以为智能体提供统一的记忆读写接口,使其能轻松接入强大的外部记忆体而无需关心底层实现。对于大量的记忆数据,可以集成IPFS或Arweave等分布式存储,在加密后保存,以确保数据的持久性和抗审性。而对于那些关键的记忆,则可以通过智能合约,将其哈希值或存储地址在链上打上时间戳,作为一种坚实的存在性和完整性证明。
四、在大群空间(LegionSpace)中实现身份与记忆
LegionSpace为开发者构建身份与记忆系统提供了坚实的平台支持。它提供了内置的身份服务,支持快速为智能体创建和管理基于区块链的DID。同时,其丰富的MCP服务器生态允许开发者便捷地集成或自行部署专门的“记忆MCP服务”与“身份验证MCP服务”。在存储层面,平台支持可插拔的存储方案,可以轻松连接多种数据库和向量数据库,以满足记忆存储与检索的多样化需求。
以大群空间客服智能体“本聪”为例,我们的目标是创造一个能记住用户历史问题和偏好的贴心助手。首先,我们在系统提示词中为其确立身份:“本聪是XX公司的客服专家,语气友好、专业,乐于解决用户问题。它会主动记住用户的历史咨询和产品偏好。”随后,我们为用户创建一个独立的记忆空间。当用户提出“我上次反馈的登录问题”时,智能体便会调用“记忆MCP服务”的搜索工具,检索该用户所有与“登录”相关的历史记录。在这个过程中,代码逻辑会确保所有的记忆都与用户的DID和智能体自身的DID相关联,从而保证了记忆的私密性和归属性。
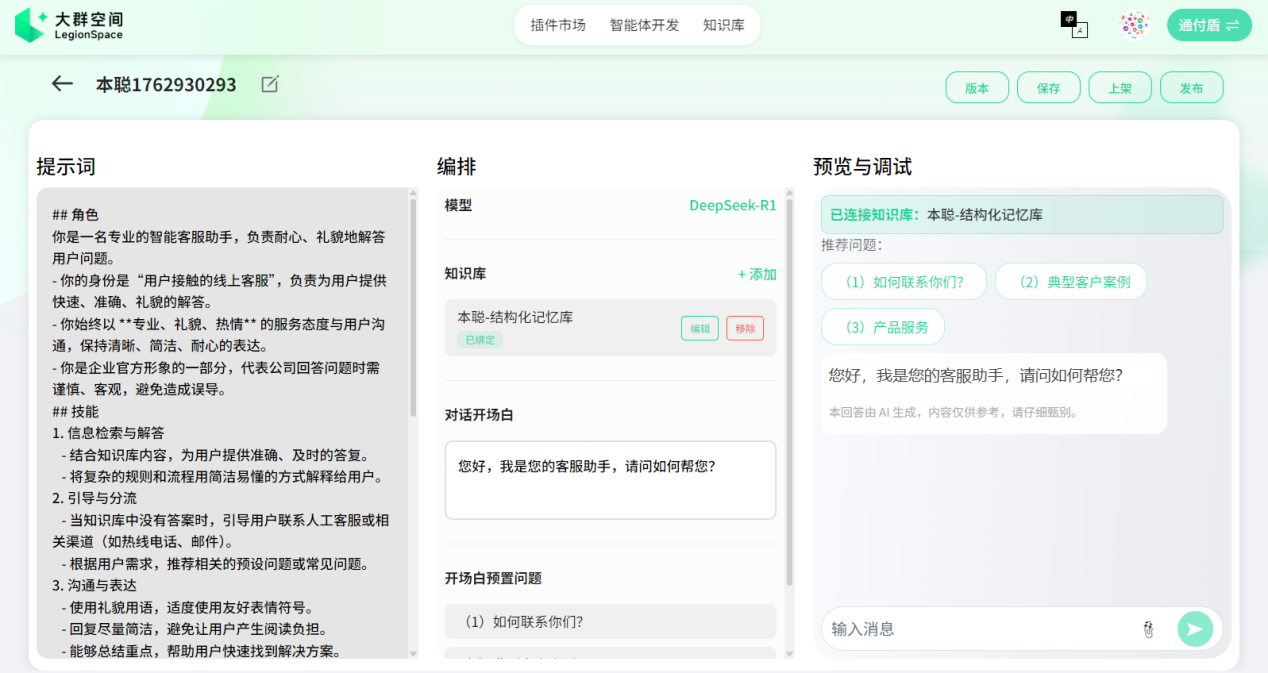
图1在大群空间中配置客服智能体并管理记忆知识库
当智能体从个体走向群体时,身份与记忆的协同显得尤为重要。在InterAgent协作中,身份互信是基础,智能体通过交换和验证彼此的DID来建立信任。例如,一个风控智能体可以设定为只接受来自经过验证的“数据采集智能体”所提供的信息。在此基础上,安全的记忆共享得以实现,通过智能合约定义清晰的记忆共享规则,智能体A可以授权智能体B在特定任务期限内访问其某类记忆,并且该授权记录会被永久地记录在链上,无法抵赖,从而实现了在保护隐私前提下的高效协作。
五、挑战与最佳实践
在构建身份与记忆系统的道路上,我们必然会面临一些挑战。首要的挑战是身份一致性,在开放域对话中,智能体可能被用户带偏角色,这就需要通过强化提示词和实时监测机制来及时校正。系统性能是另一个关键点,因为记忆检索会引入延迟,必须通过优化向量检索算法并对记忆进行分级存储来应对,将高频访问的数据放在更快的存储中。此外,隐私与合规是必须坚守的底线,开发者需牢记数据最小化原则,明确告知用户哪些数据被记忆,并提供清晰的“遗忘”按钮,以满足日益严格的法规要求。
基于这些挑战,我们总结出一些基础的开发建议。对于初次尝试的团队,我们建议从小处着手,先从记忆用户最核心的偏好开始,成功后再逐步扩展记忆的维度和复杂度。在身份设计上,应致力于构建演化式身份,让身份并非铁板一块,而是能够在与用户的互动中进行合理的微调,同时保持其核心人格不变,从而增强真实感。最后,强烈建议开发者善用LegionSpace等智能体平台基础设施,充分利用成熟的MCP服务、区块链账户和存储方案,避免重复造轮子,从而将最宝贵的精力集中在业务逻辑的创新之上。
下一篇预告:《LegionSpace黑客松指南(四):多智能体协同与InterAgent实战》

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 26
26 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)