【Datawhale】大模型量化与微调 t3
模型开发者只需专注于模型结构的设计,无需关心底层分布式训练的具体实现细节。资源抽象:对于模型开发者而言,整个计算集群被抽象为一个具有超大内存和强大算力的"单设备"。通过引入GShard概念,开发者只需对关键张量(Tensor)进行切分策略的标注,即可实现分布式训练。
实践MoE的代码,修改了一处错误,F.softmax应为torch.softmax
import torch
import math
import torch.nn as nn
from typing import Optional
class RMSNorm(nn.Module):
def __init__(self, dim: int, eps: float = 1e-6):
super().__init__()
self.eps = eps
self.weight = nn.Parameter(torch.ones(dim))
def _norm(self, x: torch.Tensor) -> torch.Tensor:
return x * torch.rsqrt(x.pow(2).mean(dim=-1, keepdim=True) + self.eps)
def forward(self, x: torch.Tensor) -> torch.Tensor:
out = self._norm(x.float()).type_as(x)
return out * self.weight
def precompute_freqs_cis(dim: int, end: int, theta: float = 10000.0) -> torch.Tensor:
freqs = 1.0 / (theta ** (torch.arange(0, dim, 2)[: (dim // 2)].float() / dim))
t = torch.arange(end, device=freqs.device)
freqs = torch.outer(t, freqs).float()
freqs_cis = torch.polar(torch.ones_like(freqs), freqs)
return freqs_cis
def reshape_for_broadcast(freqs_cis: torch.Tensor, x: torch.Tensor) -> torch.Tensor:
ndim = x.ndim
shape = [d if i == 1 or i == ndim - 1 else 1 for i, d in enumerate(x.shape)]
return freqs_cis.view(*shape)
def apply_rotary_emb(
xq: torch.Tensor,
xk: torch.Tensor,
freqs_cis: torch.Tensor,
) -> tuple[torch.Tensor, torch.Tensor]:
# 允许 GQA:Q/K 头数可不同,但最后一维 head_dim 应一致
head_dim = xq.shape[-1]
xq_ = torch.view_as_complex(xq.float().reshape(*xq.shape[:-1], -1, 2))
xk_ = torch.view_as_complex(xk.float().reshape(*xk.shape[:-1], -1, 2))
# 分别对 Q/K 广播以兼容不同头数
freqs_q = reshape_for_broadcast(freqs_cis, xq_)
freqs_k = reshape_for_broadcast(freqs_cis, xk_)
xq_out = torch.view_as_real(xq_ * freqs_q).flatten(3)
xk_out = torch.view_as_real(xk_ * freqs_k).flatten(3)
return xq_out.type_as(xq), xk_out.type_as(xq)
def repeat_kv(x: torch.Tensor, n_rep: int) -> torch.Tensor:
bsz, seqlen, n_kv_heads, head_dim = x.shape
if n_rep == 1:
return x
return (
x[:, :, :, None, :]
.expand(bsz, seqlen, n_kv_heads, n_rep, head_dim)
.reshape(bsz, seqlen, n_kv_heads * n_rep, head_dim)
)
class GroupedQueryAttention(nn.Module):
def __init__(
self,
dim: int,
n_heads: int,
n_kv_heads: int | None = None,
max_batch_size: int = 32,
max_seq_len: int = 2048,
):
super().__init__()
self.max_seq_len = max_seq_len
self.max_batch_size = max_batch_size
n_kv_heads = n_kv_heads if n_kv_heads is not None else n_heads
self.n_local_heads = n_heads
self.n_local_kv_heads = n_kv_heads
self.n_rep = self.n_local_heads // self.n_local_kv_heads
self.head_dim = dim // n_heads
self.wq = nn.Linear(dim, self.n_local_heads * self.head_dim, bias=False)
self.wk = nn.Linear(dim, self.n_local_kv_heads * self.head_dim, bias=False)
self.wv = nn.Linear(dim, self.n_local_kv_heads * self.head_dim, bias=False)
self.wo = nn.Linear(self.n_local_heads * self.head_dim, dim, bias=False)
self.register_buffer(
"cache_k",
torch.zeros(
self.max_batch_size,
self.max_seq_len,
self.n_local_kv_heads,
self.head_dim,
),
persistent=False,
)
self.register_buffer(
"cache_v",
torch.zeros(
self.max_batch_size,
self.max_seq_len,
self.n_local_kv_heads,
self.head_dim,
),
persistent=False,
)
def forward(
self,
x: torch.Tensor,
start_pos: int,
freqs_cis: torch.Tensor,
mask: torch.Tensor | None = None,
) -> torch.Tensor:
bsz, seqlen, _ = x.shape
xq = self.wq(x).view(bsz, seqlen, self.n_local_heads, self.head_dim)
xk = self.wk(x).view(bsz, seqlen, self.n_local_kv_heads, self.head_dim)
xv = self.wv(x).view(bsz, seqlen, self.n_local_kv_heads, self.head_dim)
xq, xk = apply_rotary_emb(xq, xk, freqs_cis=freqs_cis)
self.cache_k = self.cache_k.to(xq)
self.cache_v = self.cache_v.to(xq)
# 推理向:直接写入缓存
self.cache_k[:bsz, start_pos : start_pos + seqlen] = xk
self.cache_v[:bsz, start_pos : start_pos + seqlen] = xv
keys = self.cache_k[:bsz, : start_pos + seqlen]
values = self.cache_v[:bsz, : start_pos + seqlen]
keys = repeat_kv(keys, self.n_rep)
values = repeat_kv(values, self.n_rep)
xq = xq.transpose(1, 2)
keys = keys.transpose(1, 2)
values = values.transpose(1, 2)
scores = torch.matmul(xq, keys.transpose(2, 3)) / math.sqrt(self.head_dim)
if mask is not None:
scores = scores + mask
scores = torch.softmax(scores.float(), dim=-1).type_as(xq)
out = torch.matmul(scores, values)
out = out.transpose(1, 2).contiguous().view(bsz, seqlen, -1)
return self.wo(out)
from typing import Optional
class FeedForward(nn.Module):
def __init__(self, dim: int, hidden_dim: int, multiple_of: int, ffn_dim_multiplier: Optional[float]):
super().__init__()
hidden_dim = int(2 * hidden_dim / 3)
if ffn_dim_multiplier is not None:
hidden_dim = int(ffn_dim_multiplier * hidden_dim)
hidden_dim = multiple_of * ((hidden_dim + multiple_of - 1) // multiple_of)
self.w1 = nn.Linear(dim, hidden_dim, bias=False)
self.w2 = nn.Linear(hidden_dim, dim, bias=False)
self.w3 = nn.Linear(dim, hidden_dim, bias=False)
def forward(self, x: torch.Tensor) -> torch.Tensor:
return self.w2(torch.nn.functional.silu(self.w1(x)) * self.w3(x))
# code/C6/MoE/src/ffn.py
# ... (保留原有的 FeedForward 类)
class MoE(nn.Module):
def __init__(self, dim: int, hidden_dim: int, multiple_of: int, ffn_dim_multiplier: Optional[float], num_experts: int = 8, top_k: int = 2):
super().__init__()
self.num_experts = num_experts
self.top_k = top_k
# 门控网络:决定每个 Token 去往哪个专家
self.gate = nn.Linear(dim, num_experts, bias=False)
# 专家列表:创建 num_experts 个独立的 FeedForward 网络
self.experts = nn.ModuleList([
FeedForward(dim, hidden_dim, multiple_of, ffn_dim_multiplier)
for _ in range(num_experts)
])
def forward(self, x: torch.Tensor) -> torch.Tensor:
# x: (batch_size, seq_len, dim)
B, T, D = x.shape
x_flat = x.view(-1, D)
# 1. 门控网络
gate_logits = self.gate(x_flat) # (B*T, num_experts)
# 2. Top-k 路由
weights, indices = torch.topk(gate_logits, self.top_k, dim=-1)
weights = torch.softmax(weights, dim=-1) # 归一化权重
output = torch.zeros_like(x_flat)
for i, expert in enumerate(self.experts):
# 3. 找出所有选中当前专家 i 的 token 索引
batch_idx, k_idx = torch.where(indices == i)
if len(batch_idx) == 0:
continue
# 4. 取出对应的输入进行计算
expert_input = x_flat[batch_idx]
expert_out = expert(expert_input)
# 5. 获取对应的权重
expert_weights = weights[batch_idx, k_idx].unsqueeze(-1) # (num_selected, 1)
# 6. 将结果加权累加回输出张量
output.index_add_(0, batch_idx, expert_out * expert_weights)
return output.view(B, T, D)
class TransformerBlock(nn.Module):
def __init__(
self,
layer_id: int,
dim: int,
n_heads: int,
n_kv_heads: int | None,
multiple_of: int,
ffn_dim_multiplier: float | None,
norm_eps: float,
max_batch_size: int,
max_seq_len: int,
):
super().__init__()
self.n_heads = n_heads
self.dim = dim
self.head_dim = dim // n_heads
self.attention = GroupedQueryAttention(
dim=dim,
n_heads=n_heads,
n_kv_heads=n_kv_heads,
max_batch_size=max_batch_size,
max_seq_len=max_seq_len,
)
# 修改:使用 MoE 替换标准的 FeedForward
self.feed_forward = MoE(
dim=dim,
hidden_dim=4 * dim,
multiple_of=multiple_of,
ffn_dim_multiplier=ffn_dim_multiplier,
num_experts=8, # 定义8个专家
top_k=2, # 每个Token激活2个专家
)
self.layer_id = layer_id
self.attention_norm = RMSNorm(dim, eps=norm_eps)
self.ffn_norm = RMSNorm(dim, eps=norm_eps)
def forward(
self,
x: torch.Tensor,
start_pos: int,
freqs_cis: torch.Tensor,
mask: Optional[torch.Tensor],
) -> torch.Tensor:
h = x + self.attention(self.attention_norm(x), start_pos, freqs_cis, mask)
out = h + self.feed_forward(self.ffn_norm(h))
return out
class LlamaTransformer(nn.Module):
def __init__(
self,
vocab_size: int,
dim: int,
n_layers: int,
n_heads: int,
n_kv_heads: int | None = None,
multiple_of: int = 256,
ffn_dim_multiplier: float | None = None,
norm_eps: float = 1e-6,
max_batch_size: int = 32,
max_seq_len: int = 2048,
):
super().__init__()
self.vocab_size = vocab_size
self.n_layers = n_layers
self.dim = dim
self.n_heads = n_heads
self.max_seq_len = max_seq_len
self.max_batch_size = max_batch_size
self.tok_embeddings = nn.Embedding(vocab_size, dim)
self.layers = nn.ModuleList([
TransformerBlock(
i,
dim=dim,
n_heads=n_heads,
n_kv_heads=n_kv_heads,
multiple_of=multiple_of,
ffn_dim_multiplier=ffn_dim_multiplier,
norm_eps=norm_eps,
max_batch_size=max_batch_size,
max_seq_len=max_seq_len,
)
for i in range(n_layers)
])
self.norm = RMSNorm(dim, eps=norm_eps)
self.output = nn.Linear(dim, vocab_size, bias=False)
self.register_buffer(
"freqs_cis",
precompute_freqs_cis(dim // n_heads, max_seq_len * 2),
persistent=False,
)
def forward(self, tokens: torch.Tensor, start_pos: int) -> torch.Tensor:
bsz, seqlen = tokens.shape
h = self.tok_embeddings(tokens)
self.freqs_cis = self.freqs_cis.to(h.device)
freqs_cis = self.freqs_cis[start_pos : start_pos + seqlen]
mask = None
if seqlen > 1:
mask = torch.full((seqlen, seqlen), float("-inf"), device=tokens.device)
mask = torch.triu(mask, diagonal=1)
mask = torch.hstack([torch.zeros((seqlen, start_pos), device=tokens.device), mask]).type_as(h)
for layer in self.layers:
h = layer(h, start_pos, freqs_cis, mask)
h = self.norm(h)
logits = self.output(h).float()
return logits
model = LlamaTransformer(
vocab_size=1000,
dim=256,
n_layers=2,
n_heads=8,
n_kv_heads=2,
multiple_of=64,
ffn_dim_multiplier=None,
norm_eps=1e-6,
max_batch_size=4,
max_seq_len=64,
)
# 构造随机 token 序列并执行前向
batch_size, seq_len = 2, 16
tokens = torch.randint(0, 1000, (batch_size, seq_len))
logits = model(tokens, start_pos=0)
# 期望: [batch_size, seq_len, vocab_size]
print("logits shape:", tuple(logits.shape))
一、MoE 的基本概念
MoE 最早在 1991 年由 Jordan 和 Hinton 提出,用于解决多任务学习中的“强干扰效应”。简单来说,多任务训练时不同任务会互相干扰,导致模型性能下降。MoE 通过“分治”思想来解决:将问题分解给多个“专家”,每个专家专注于一小部分输入或任务
MoE 的基本组成:
-
专家网络:多个子网络,通常是和 Transformer 中前馈网络(FFN)结构相同的子模型,每个专家拥有自己独立可训练参数。
-
门控网络 Routing / Gate:一个轻量级网络计算每个 token 与不同专家的匹配概率,并根据这些概率选择若干专家。
-
稀疏激活Sparse Activation / Top-k:只有少数(如 1~4 个)专家被激活参与该 token 的处理,其余专家在当前输入上不参与计算。
- 损失函数设计
将系统视为一个随机生成器,使用负对数似然损失 L o s s c o m p = − log ∑ i p i e − 1 2 ∣ ∣ y − E i ∣ ∣ 2 Loss_{comp} = - \log \sum_{i} p_i e^{-\frac{1}{2} || \mathbf{y} - \mathbf{E}_i ||^2} Losscomp=−logi∑pie−21∣∣y−Ei∣∣2其中: - y \mathbf{y} y 是我们希望模型输出的真实目标。
- E i \mathbf{E}_i Ei 是第 i i i 个专家的输出。
- p i p_i pi 是门控网络分配给第 i i i 个专家的权重(概率)
在这个目标函数中,系统倾向于**“赢家通吃”。当某个专家 E i \mathbf{E}_i Ei 的输出非常接近目标 y \mathbf{y} y 时(即误差项 ∣ ∣ y − E i ∣ ∣ 2 || \mathbf{y} - \mathbf{E}_i ||^2 ∣∣y−Ei∣∣2 很小),指数项 e − … e^{-\dots} e−… 会变得很大。为了最小化总 Loss,门控网络会倾向于显著增加这个“表现好”的专家的权重 p i p_i pi,而忽略其他专家
这一机制实现了权重的解耦**。误差反向传播时,只有被选中的“胜出者”和门控网络的权重会被更新,其他专家几乎不受影响。有效缓解了任务间的干扰,实现了“让专业的人干专业的事”。
MoE对比集成学习
与传统 ensemble(集成学习)不同的是:集成学习的假设是所有子模型都是独立或互补的,但MoE 并不对所有专家输出取平均或投票,而是 稀疏激活,即每次输入激活不同的自网络路径,只运行少数专家,从而显著减少计算量 - 损失函数设计
-
Output Combination:对激活专家的输出进行加权求和作为该层最终输出
<OutrageouslyLargeNeuralNetworks:TheSparsely-GatedMixture-of-ExpertsLayer》(2017)
这篇由GoogleBrain团队(包括GeoffreyHinton、JeffDean等)于2017年发表的论文(arXiv:1701.06538)标志着MoE(Mixture-of-Experts)从理论概念向大规模实用模型的重大跃进。论文的核心贡献是提出Sparsely-GatedMoE层,通过稀疏条件计算(conditionalcomputation)实现模型参数规模爆炸式增长(如137B参数模型),而计算开销仅微增(通常在6-8倍以内),从而让神经网络在语言建模和机器翻译任务上达到当时SOTA水平,同时首次在GPU集群上实现万亿参数级别的可扩展性。下面从数学、技术演进和工程三个角度进行解析。
数学角度:稀疏门控与辅助损失的精确设计
论文的核心数学创新在于引入NoisyTop-KGating,实现了高效稀疏激活,同时通过辅助损失强制负载均衡。
-
MoE基本输出公式:
对于输入x,MoE输出为
y = ∑ i = 1 n G ( x ) i E i ( x ) y=\sum_{i=1}^{n}G(x)_iE_i(x) y=∑i=1nG(x)iEi(x)
其中(E_i(x))是第i个专家(一个前馈子网络)的输出,(G(x))是门控向量(gatingvector),n是专家总数。稀疏性确保多数(G(x)_i=0),只激活top-k个专家。 -
门控网络(GatingNetwork):
基础是softmax门控:
G σ ( x ) = Softmax ( x W g ) G_\sigma(x)=\text{Softmax}(xW_g) Gσ(x)=Softmax(xWg)
但为了引入噪声和稀疏,采用NoisyTop-KGating:
先计算原始门控值加上噪声:
H ( x ) i = ( x W g ) i + N ( 0 , 1 ) ⋅ Softplus ( ( x W noise ) i ) H(x)_i=(xW_g)_i+\mathcal{N}(0,1)\cdot\text{Softplus}((xW_{\text{noise}})_i) H(x)i=(xWg)i+N(0,1)⋅Softplus((xWnoise)i)
然后保留top-k,剩余置为 − ∞ -\infty −∞:K e e p T o p K ( v , k ) i = { u i if v i is in the top k elements of v . − ∞ otherwise. KeepTopK(v,k)_i=\begin{cases}u_i&\text{if }v_i\text{ is in the top }k\text{ elements of }v.\\-\infty&\text{otherwise.}\end{cases} KeepTopK(v,k)i={ui−∞if vi is in the top k elements of v.otherwise.
G ( x ) i = Softmax ( KeepTopK ( H ( x ) , k ) ) G(x)_i=\text{Softmax}(\text{KeepTopK}(H(x),k)) G(x)i=Softmax(KeepTopK(H(x),k))
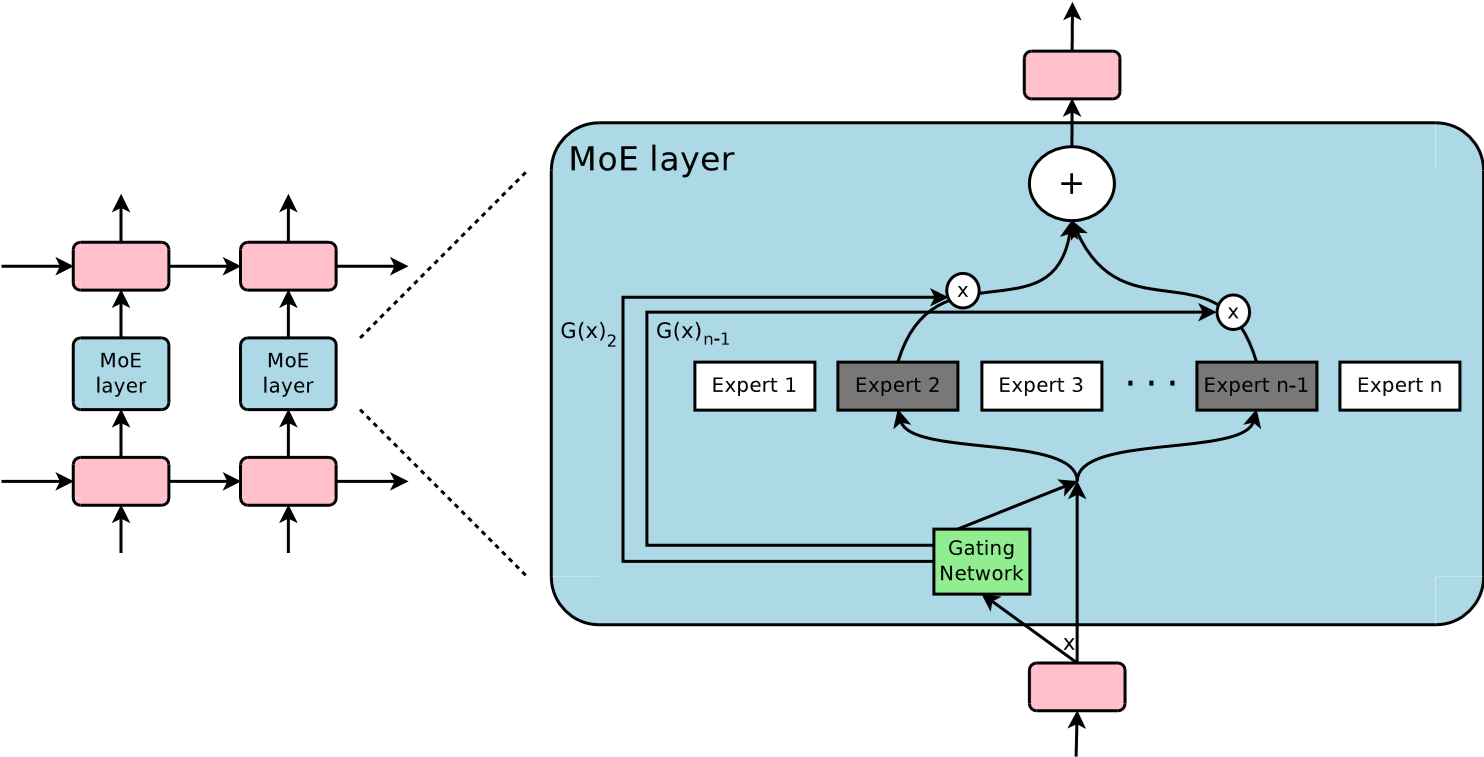
噪声项防止门控网络过早收敛到少数专家,并提升探索性。k通常为1或2(论文实验中常用k=1)。这种稀疏性带来了巨大的收益。在保持计算预算(每步约 800 万次运算)基本不变的情况下,随着专家数量从 4 个增加到 4096 个(横轴),模型参数量剧增,但测试集困惑度(纵轴)显著下降。说明条件计算可以在不增加推理成本的前提下,利用海量参数大幅提升性能。
-辅助损失(AuxiliaryLosses):
为防止“马太效应”(少数专家垄断),引入两个辅助损失(加权加入总损失):
-ImportanceLoss:衡量门控概率的均匀性。每个专家的重要性为
Importance ( e ) = ∑ x i n X G ( x ) e \text{Importance}(e)=\sum_{x inX}G(x)_e Importance(e)=∑xinXG(x)e
损失为变异系数(CV)的平方:
L importance = w imp ⋅ ( σ ( Importance ) μ ( Importance ) ) 2 L_{\text{importance}}=w_{\text{imp}}\cdot\left(\frac{\sigma(\text{Importance})}{\mu(\text{Importance})}\right)^2 Limportance=wimp⋅(μ(Importance)σ(Importance))2
-LoadLoss:关注实际负载均匀性。负载估计为预期分配概率(因噪声而软化):
P ( x , i ) = Φ ( ( x W g ) i − kthexcluding ( H ( x ) , k , i ) Softplus ( ( x W noise ) i ) ) P(x,i)=\Phi\left(\frac{(xW_g)_i-\text{kthexcluding}(H(x),k,i)}{\text{Softplus}((xW_{\text{noise}})_i)}\right) P(x,i)=Φ(Softplus((xWnoise)i)(xWg)i−kthexcluding(H(x),k,i))
Load ( e ) = ∑ x i n X P ( x , i ) \text{Load}(e)=\sum_{x inX}P(x,i) Load(e)=∑xinXP(x,i)
损失同样为
L load = w load ⋅ ( σ ( Load ) μ ( Load ) ) 2 L_{\text{load}}=w_{\text{load}}\cdot\left(\frac{\sigma(\text{Load})}{\mu(\text{Load})}\right)^2 Lload=wload⋅(μ(Load)σ(Load))2
这些损失通过反向传播直接优化门控网络(无需强化学习),确保专家负载均衡,防止模型退化为稠密小模型。
数学上,实现了从全激活到稀疏激活的平滑过渡,噪声和CV惩罚是关键技巧。
技术演进:从早期MoE到大规模条件计算
论文构建在早期MoE基础上(Jacobsetal.,1991;Jordan&Jacobs,1994),但解决了长期瓶颈:
- 早期MoE(如1990s)局限于小数据集和小模型,门控依赖强化学习(Bengioetal.,2015),负载不均严重。
- Eigenetal.(2013)将MoE嵌入深度网络,但仍全激活专家,计算成本高。
- 论文引入稀疏门控+噪声+辅助损失,首次实现真正条件计算(conditionalcomputation):每个token只激活少量专家(e.g.,137B参数模型中活跃参数仅几亿)。
- 专家从浅层MLP扩展到深层前馈子网络,支持层次化MoE(hierarchicalMoE:顶层门控选组,再子MoE)。
-技术跃进:从“全参数激活”到“万亿参数稀疏激活”,开启了后续如GShard、SwitchTransformer的MoE时代。
工程角度:分布式训练与可扩展性
论文在工程上实现了GPU集群上的万亿参数级训练:
-并行策略:结合数据并行(LSTM/门控复制)和模型并行(专家分片)。每个专家固定在单个设备上,输入通过All-to-All通信分发。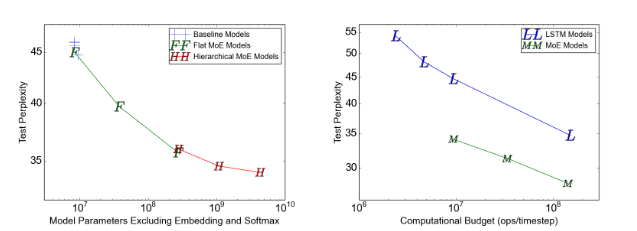
-
通信优化:专家固定位置,输入/输出需网络传输,但通过增大专家隐藏层(数千ReLU)提升计算-通信比(从早期瓶颈到可接受)。
-
内存与稳定性:前向重计算专家激活(backwardpass重算),减少内存;Adam优化器近似(仅维护专家参数均值/方差)。
-
批处理:RNN中卷积化时间步,增大有效批大小;容量因子(capacityfactor)预留缓冲,处理负载波动。
在TPU/GPU集群上训练137B参数模型(131k专家),每个时间步仅8M操作,TFLOPS利用率达0.72/GPU。
实验上,论文在1BWordLM和WMT’14翻译任务中显著超越基线:LM困惑度降39%,翻译BLEU提升1+点,证明MoE在真实大规模数据上的优越性。
总体影响
这篇论文奠定了现代MoE基础,是从稠密到稀疏大模型的转折点,直接启发了GShard(2020)、SwitchTransformer(2021)和GLaM等后续工作,推动了参数规模从百亿到万亿的跃升,同时保持计算效率。数学上的噪声门控和辅助损失已成为MoE标准设计,工程上的分布式技巧至今影响分布式训练框架。总之,它证明了“更大不等于更贵”,稀疏激活是通往超大规模AI的关键路径。
二、大模型时代的MoE
Gshard
Gshard将MoE与Transformer结合,支持600B大小的参数规模,使用2048块TPUv3即达到了相当高的100个语种的翻译质量,在训练效率方面得到了突破:
-
次线性扩展Sub-linear Scaling: 在参数量)大幅增长时,所需的算力和通信开销的增长速度低于线性增长. 这点可以通过位置感知的稀疏门控混合专家层(Position-wise Sparsely Gated Mixture-of-Experts (MoE) layer) 来实现,Gshard让在模型参数量从375亿增加到6000亿(增长16倍)时,训练所需的算力成本仅增加了不到4倍,实现了显著的亚线性扩展效果
-
抽象:The Power of Abstraction 模型开发者只需专注于模型结构的设计,无需关心底层分布式训练的具体实现细节。
资源抽象:对于模型开发者而言,整个计算集群被抽象为一个具有超大内存和强大算力的"单设备"。通过引入GShard概念,开发者只需对关键张量(Tensor)进行切分策略的标注,即可实现分布式训练
技术手段:- 提供专门的注释API定义
- 集成XLA编译器的扩展功能
- 自动处理分布式训练中的通信和同步问题
-
可扩展编译 Scalable Compilers
传统方式(MPMD - 多程序多数据):
以4个节点进行矩阵乘法计算为例( [ M , K ] × [ K , N ] = [ M , N ] [M,K] \times [K,N] = [M,N] [M,K]×[K,N]=[M,N]):- 需要手动将矩阵分割为4块
- 每个节点运行不同的程序,读取对应的矩阵块进行计算
- 每个程序需要处理不同的数据偏移量
这本质上形成了"多个程序处理多个数据"的模式
SPMD - 单程序多数据:
- 所有设备运行相同的程序
- 程序自动适应不同设备的数据分布

-
Position-wise Mixture-of-Experts Layer
在transformer的encoder和decoder中使用top-2 gating的MoE层,进行稀疏扩展,每条训练样本是通过一串由subword token的序列组成,每个token会激活一部分M哦E中的专家进行处理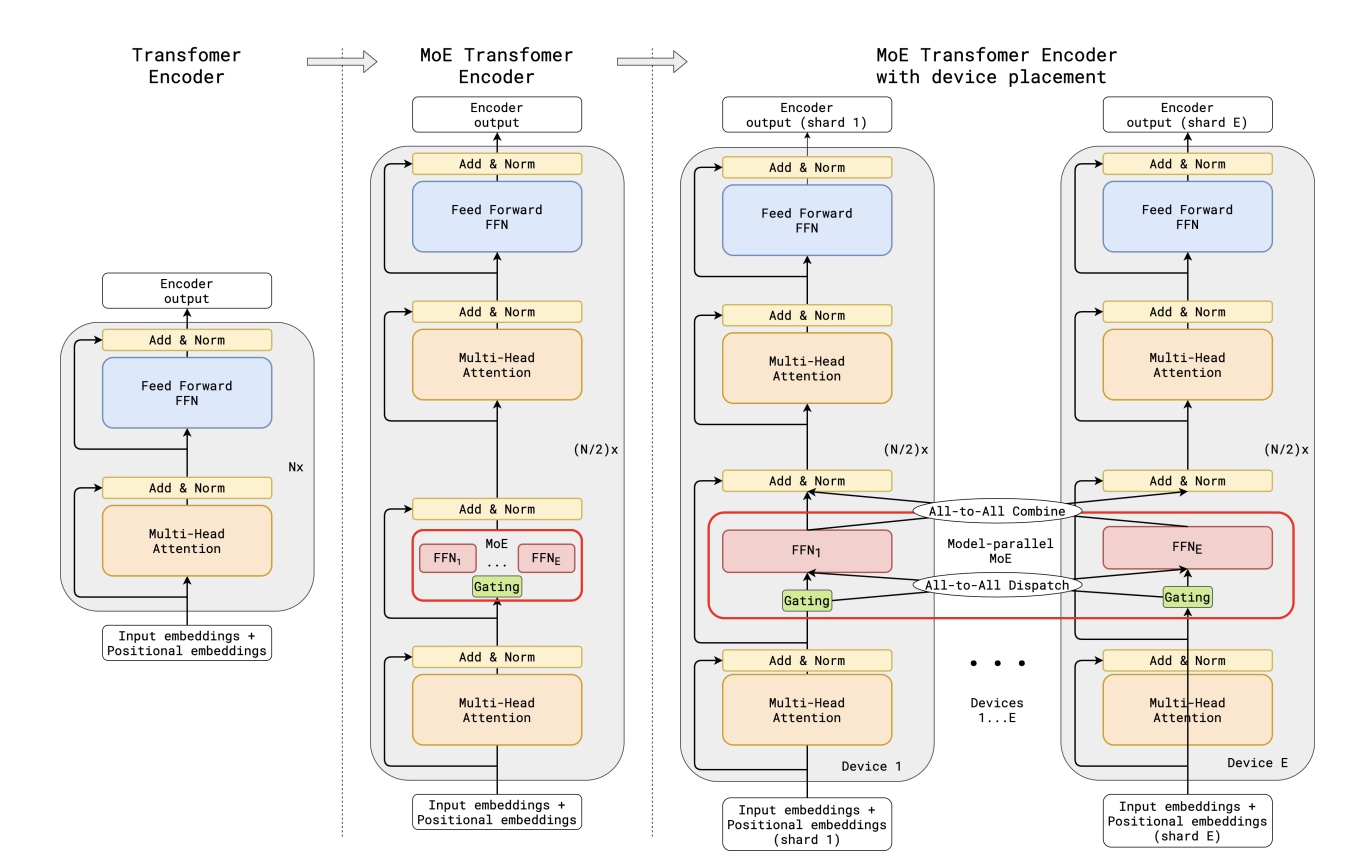
- 以标准Transformer模型的编码器为例, 解码器结构类似
- 通过用MoE层替换每个其他前馈层,我们得到了MoE Transformer编码器的模型结构
- 当扩展到多个设备时,MoE层在多设备之间进行分片处理,除MoE层外的所有其他层都被复制
MoE layer同样借鉴了The sparsely-gated mixture-of-experts layer论文中稀疏门控函数与辅助损失函数, transformer中MoE layer由E个FFN网络组成, 每个FFN是一个专家,
G s , E = G A T E ( x s ) F F N e ( x s ) = w o e ⋅ R e L U ( w i e ⋅ x s ) y s = ∑ e = 1 E G s , e ⋅ F F N e ( x s ) \begin{aligned}\mathcal{G}_{s,E}&=\mathrm{GATE}(x_{s})\\\mathrm{FFN}_{e}(x_{s})&=wo_{e}\cdot\mathrm{ReLU}(wi_{e}\cdot x_{s})\\y_{s}&=\sum_{e=1}^{E}\mathcal{G}_{s,e}\cdot\mathrm{FFN}_{e}(x_{s})\end{aligned} Gs,EFFNe(xs)ys=GATE(xs)=woe⋅ReLU(wie⋅xs)=e=1∑EGs,e⋅FFNe(xs)
x s x_s xs是MoE的输入token, w i e wi_e wie与 w o e wo_e woe分别是FFN输入与输出的weight,用于输入与输出的映射;
向量 G s , E \mathcal{G}_{s,E} Gs,E是门控网络,每个expert对应一个值,0时表示不会被分配token;这里每个token最多会被分配给两个expert;每个FFN是由两层全连接网络加上ReLU组成;
结果 y s y_s ys由所有被选择的expert输出的加权的和组成
G A T E ( ⋅ ) GATE(\cdot) GATE(⋅)由 softmax 激活函数建模,以指示每个专家在处理传入token时的权重。 换句话说,表明专家处理传入token的能力如何,有两个要求:
-
平衡加载token
希望 MoE 层稀疏地激活给定token的专家。 一个简单的解决方案是根据 softmax 概率分布选择前 k 个专家。 然而,众所周知,这种方法会导致训练负载不平衡问题[16]:训练期间看到的大多数token都会被分发给少数专家,从而为少数繁忙的专家积累非常大的输入缓冲区,而其他专家则得不到训练,从而减慢了训练速度。 与此同时,许多其他专家根本没有接受足够的培训
更好的门控函数设计可以将处理负担更均匀地分配给所有专家 -
高校的扩展Efficiency at scale
如果门控函数按顺序完成,那么实现平衡负载将是相当微不足道的。 对于给定 E 个专家的输入批次中的所有 N 个token,仅门控函数的计算成本至少为 O(NE)。 然而,N 的数量级为数百万,E 的数量级为数千,门控函数的顺序实现将使大部分计算资源在大多数时间处于闲置状态。 因此,我们需要门函数的高效并行实现来利用许多设备

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 14
14 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)