CoT-VLA: Visual Chain-of-Thought Reasoning for Vision-Language-Action Models
提出CoT-VLA:把视觉-语言-动作模型和思维链结合,通过引入中间视觉目标(subgoal images)作为显式推理步骤,与传统用或关键点的抽象表示不同,使用视频中采样的子目标图像,既可解释又有效,基于VILA-U模型构建,在多种机器人操作上表现较好。但是也存在计算开销大,视觉质量欠佳(自回归图像生成不如扩散模型),动作分块导致动作可能不连续(这一个动作片段和下一个动作片段不连续),视觉推理泛
|
序号 |
属性 | 值 |
|---|---|---|
| 1 | 论文名称 | CoT-VLA |
| 2 | 发表时间/位置 | 2025 |
| 3 | Code | cot-vla.github.io |
| 4 | 创新点 |
1. 视觉思维链(Visual CoT)首次将 Chain-of-Thought 推理 引入 VLA,用“生成未来图像”替代抽象推理,让机器人“先想一幅图,再做一组动作”。 2. 混合注意力机制(Hybrid Attention)图像生成用 因果自回归,动作预测用 全注意力一次性输出,比传统 VLA(全因果)更高效、更准确。 3. 动作分块预测(Action Chunking)一次预测 m 步动作(m=10),而非单步,减少延迟、提升流畅性,在长时程任务中提升显著。 4. 多模态预训练策略,无动作视频增强视觉推理,利用 EPIC-KITCHENS、SSv2 等海量视频数据 训练图像生成,无需动作标签即可提升视觉理解与规划能力,突破机器人数据稀缺瓶颈。 |
| 5 | 引用量 | 视觉cot是亮点 |
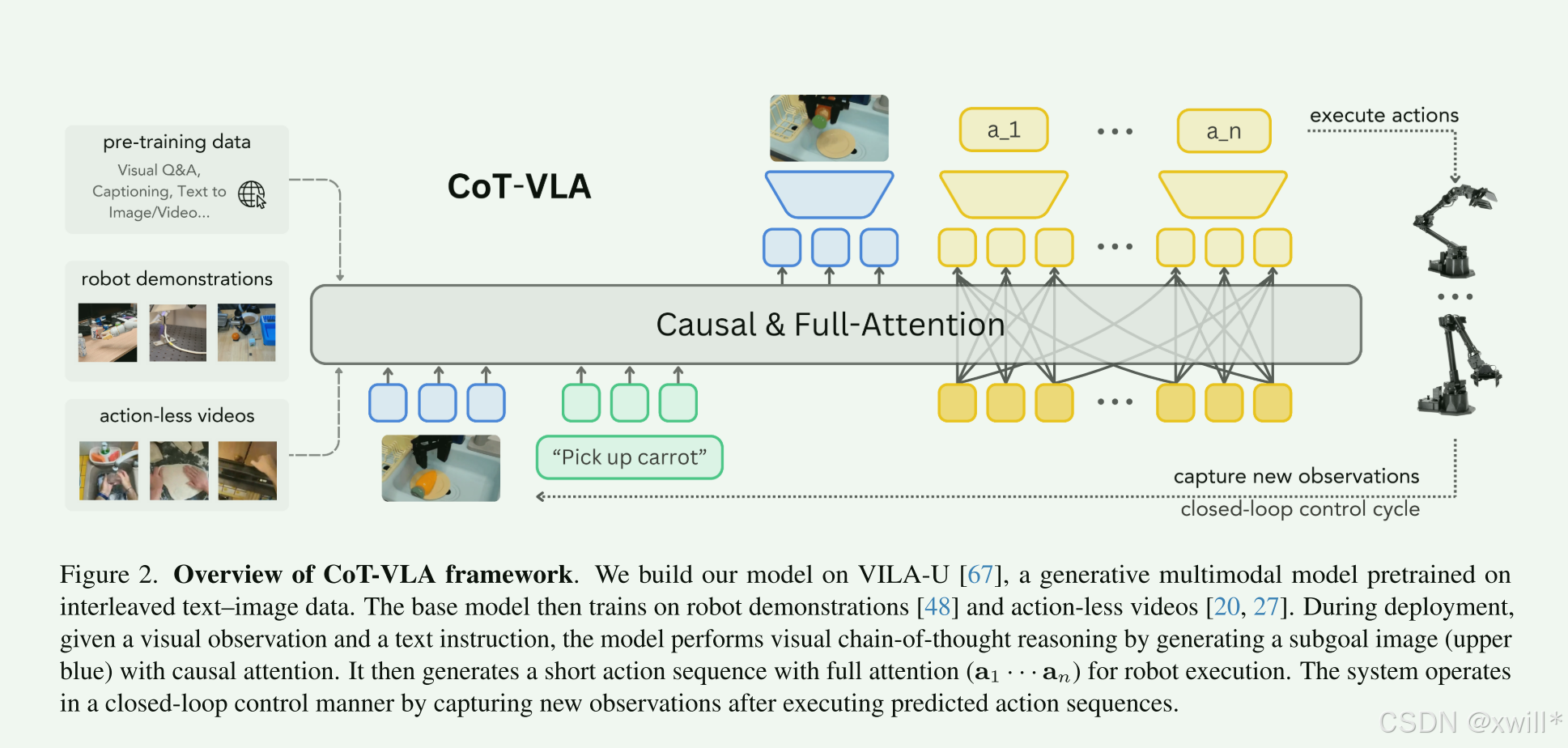
一:提出问题
传统的VLA模型会通过图像和指令输出一个动作序列。但是这个过程直接从图像到动作,中间没有“思考”,模型不知道中间目标状态是什么,因此在复杂的任务里容易出错且不稳定。
如何让机器人也具有向日一样的思考过程,在执行前一步的时候,思考下一步在画面应该是啥很么样。这就是视觉思维链。让VLA模型也能够做到先想像再行动。
当前图像 + 指令 → 预测“子目标图像”(下一步应该看到的画面) → 根据当前图像 + 子目标图像 → 生成动作
模型先生成一张“它认为执行完下一步后应该看到的画面”,然后再想“我要做哪些动作才能让现实变成那样”。
COT-VLA模型分为两个阶段,分别是视觉思考和动作生成。视觉思考阶段会输出当前观测图像和语言指令,输出下一步目标图思想,模型采用自回归的方式预测未来帧,像视频生成那样,相当”脑补下一步的画面“。之后进入动作生成阶段,这个阶段输入当前阶段的图像 + 子目标图像 + 语言指令,输出一段短的动作序列(不是单个动作),模型根据现在和“想象中的未来”,预测要做的动作。它不是一步一步地输出,而是一次输出一段。
模型的训练数据包括两种:机器人演示数据(有动作,用于学习从状态 → 子目标 → 动作的完整映射。)和 普通视频数据(无动作,用来训练视觉思维(即预测未来图像),增强视觉推理能力。)
hybrid attention:混合注意力机制,Transformer 的注意力分为两种,分别是:
-
Causal Attention(因果注意力):像语言模型那样,一个 token 只能看前面的内容(适合生成图像或文本)。
-
Full Attention(全注意力):每个 token 可以看整个序列(适合动作预测)。
因此CoT-VLA根据不同阶段使用了两种注意力机制,图像、文本生成 → 用因果注意力、动作预测 → 用全注意力。这样做可以实现推理部分像语言模型那样一步步的生成,而在控制部分则向策略网络一样一次性考虑所有的信息。
CoT-VLA 首次将“视觉思维链”引入机器人控制:让模型先“画出”下一步该长什么样,再生成动作,显著提升复杂任务成功率,达到真实世界 SOTA。
二:解决方案
1 COT-VLA
Visual Chain-of-Thought Reasoning: 视觉思维连推理,采用两种数据类型用于VLA的训练,分别是机器人演示数据集Dr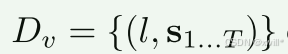 和无动作视频数据集Dv
和无动作视频数据集Dv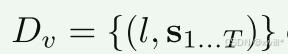 。
。
传统方法直接基于预训练的VLM微调从而把视觉输入和语言输入映射为动作输出。COT-VLA在生成动作之前,引入显式的视觉推理步骤(也就是“先想象,再行动”)。
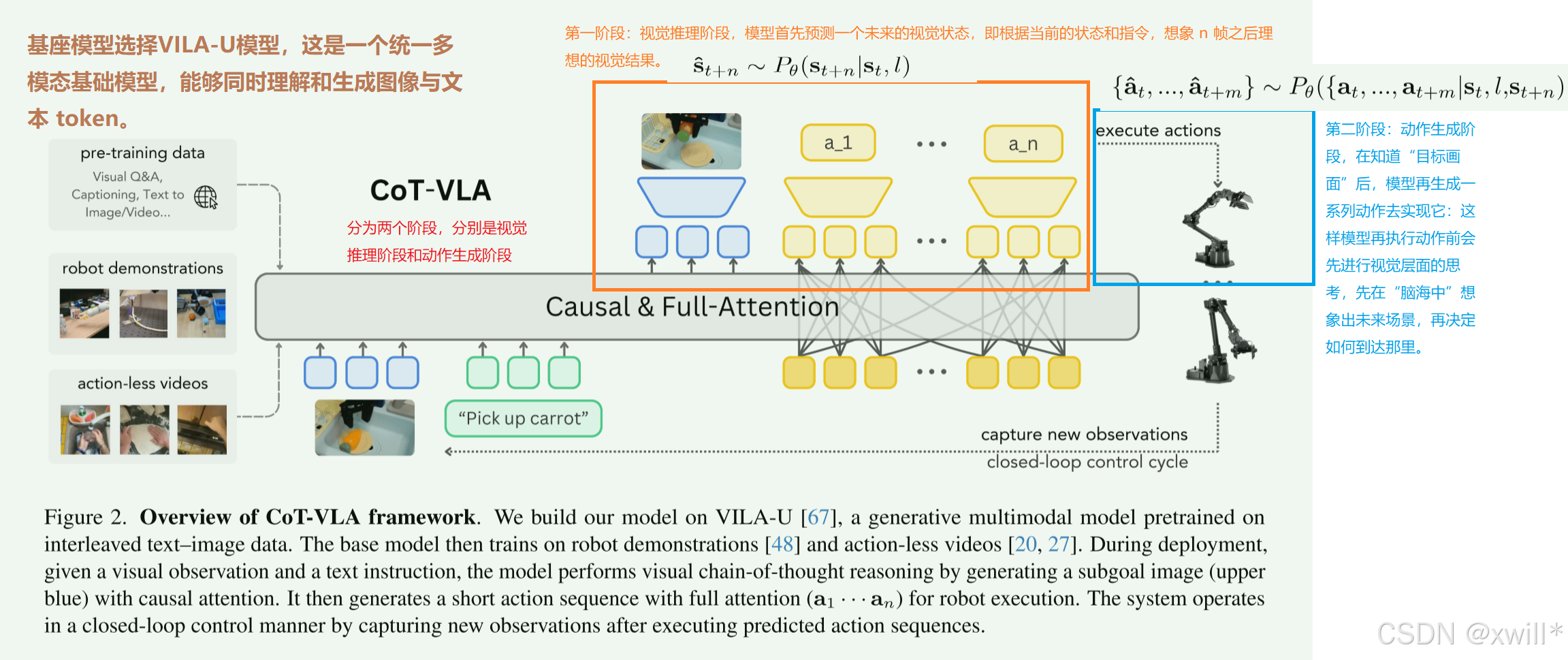
CoT-VLA 让机器人具备“视觉思维链”能力,在执行动作前,先通过想象未来画面进行视觉层面的推理,再生成动作。
Training Procedures:在 机器人演示数据 Dr和 无动作视频 Dv 上预训练基础 7B VILA-U 模型。训练中优化三个模块:
-
LLM backbone(大语言模型主干)
-
Projector(映射层)
-
Depth Transformer(深度残差预测)
Vision tower 固定不动(用于提取视觉 token 的编码器),目标主要是两个,子目标图像生成(causal attention)和动作生成(full attention)。
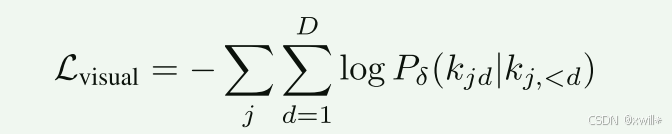
视觉token预测阶段式因果注意力:
-
*kjd *:第 j 个 patch 的第 d 个残差 token
-
kj,<d:前 d−1 个已预测的残差 token
-
就像GPT预测下一个词一样,这里是预测下一个图像残差。
图像被编码成 token(类似文字的最小单元),之后每个 token 位置 jj 由 Depth Transformer PδP**δ 预测 D 层残差 token(图像生成是一层一层的,先大体轮廓再细节到最最后完成,这里就是预测每一步的新增信息,就是所谓的残差。)
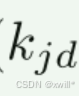
自回归预测,预测第d个token时,会参考前面已经预测的token:
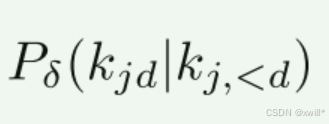
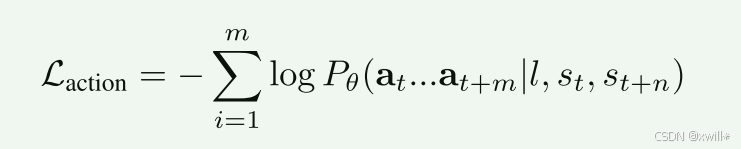
动作预测阶段式全注意力:
-
s_t, s_{t+n}:当前和未来图像(视觉思维链生成的子目标)
-
a_t, ..., a_{t+m}:模型要生成的动作序列
每个动作ai使用 7 个 token表示(动作有 7 个维度,对应机器人 7-DoF),每个连续动作维度被离散化成 256 个 bin,使用文本 tokenizer 中 最少用的 256 个 token 来表示这些 bin。使用 full attention → 动作序列中的所有 token 可以互相影响
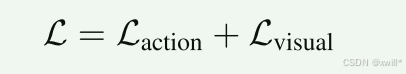
训练总体目标就是两项损失之和。两者同时优化 → 模型学会先“想象未来画面”,再“生成动作去实现未来画面”

Adaptation Phase for Downstream Closed-Loop Deployment: CoT-VLA 的下游任务适配阶段
-
预训练模型:学会“先想象未来画面,再执行动作”的通用策略
-
微调阶段:把模型调成适合你家机器人的操作习惯
-
不改视觉塔 → 保留通用视觉理解能力
-
调整语言/动作生成 → 让模型输出动作精确适应你机器人的手臂、关节
-
-
闭环部署:机器人接收指令 → 生成子目标图像 → 生成动作 → 执行任务
微调阶段用目标机器人的真实演示数据,在冻结视觉塔的前提下,继续训练“思考(生成图)+ 行动(预测块)”两阶段,让 CoT-VLA 具备闭环执行新任务的能力。
三:实验

过仿真基准 + 真实机器人操作两大类实验,全面评估 CoT-VLA 的有效性。 本节回答三个核心问题:
-
与 SOTA 基线相比表现如何?(4.2)
-
预训练、视觉 CoT、混合注意力各自贡献多少?(4.3)
-
更好的视觉推理能否提升动作执行?(4.4)
通过实验验证发现:“
-
CoT-VLA 在仿真和真实世界均达到 SOTA,尤其长时程和多指令任务。
-
三大组件都关键:Action Chunking > Hybrid Attention > Visual CoT。
-
无动作视频预训练 + 更好的视觉推理 = 机器人性能上限
四:总结
提出 CoT-VLA:把视觉-语言-动作模型和思维链结合,通过引入 中间视觉目标(subgoal images) 作为显式推理步骤,与传统用 bounding box 或 关键点 的抽象表示不同,使用 视频中采样的子目标图像,既可解释又有效,基于VILA-U模型构建,在多种机器人操作上表现较好。
但是也存在计算开销大,视觉质量欠佳(自回归图像生成不如扩散模型),动作分块导致动作可能不连续(这一个动作片段和下一个动作片段不连续),视觉推理泛化性受限。
在未来可以:
-
利用 快速图像生成 / 快速 LLM 推理 提升吞吐量
-
结合统一多模态模型改善视觉质量
-
引入 时间平滑(temporal smoothing) 或每步预测方法改善动作连续性
-
利用 视频/图像生成和世界模型(world models) 提升视觉推理能力和任务泛化
World Model(世界模型)是指:
对环境的内部表示或预测模型
可以预测未来状态(图像、特征、奖励、物体位置等)
可以用于计划和推理,不用每次都去实际执行动作
是一种让智能体“先在脑子里演练,再去真实世界执行”的方法
没有 world model:机器人看到书在桌上 → 马上抓 → 抓错了要重新调整 有 world model:机器人看到书在桌上 → 在脑子里预测抓的轨迹 → 决定最佳动作 → 一次就成功

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 45
45 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)