[Ai Agent] 08 LangGraph 基础:砸开AgentExecutor黑盒
本文手把手教你用 LangGraph 从零构建白盒 ReAct Agent,拆解 AgentExecutor 黑盒,实现工具调用、多轮记忆与系统提示,并集成 LangSmith 进行全流程可观测调试,掌握现代 AI Agent 的核心构建范式。
博客配套代码发布于github:08 LangGprah 基础
相关Agent专栏:Ai Agent教学
本系列所有博客均配套Gihub开源代码,开箱即用,仅需配置API_KEY。
如果该Agent教学系列帮到了你,欢迎给我个Star⭐!
知识点:Langgraph核心三要素|ReAct循环白盒化实现 | LangSmith调试追踪 | 持久化记忆 | 提示词安全注入
前言:
在05-07篇中,我们用 AgentExecutor 构建了能调工具、查知识、记历史的全能Agent。但它是个封装严密的黑盒:
- 你看不到它中间调用了几次工具;
- 无法在“删除文件”前插入人工确认;
- 难以加入“总结”“重试”等自定义逻辑。
本篇我们将“砸开”这个黑盒,用Langgraph从零构建一个透明、可控的白盒Agent。
你可能会问:我们不是要学Langgraph吗,跟这个AgentExecutor有什么关系?
关系在于:AgentExecutor所做的事,正是Langgraph要让我们亲手实现的事。
它不是Langraph,但Langraph比它做的更好、更灵活。
一、Langgraph的三要素:如何从零拼出一个流程
1. 为什么需要Langgraph
我们之前用Langchain构建了各种智能体,但又没有发现:整个执行流程完全不可控?
按理说,一个真正的Agent应该涉及工作流编排、状态管理、条件跳转、错误重试等复杂逻辑。
但实际上,这些都被一行代码悄悄包办了:
agent_executor = AgentExecutor(agent=agent,tools=tools)AgentExecutor内部封装了一个完整的ReAct循环(思考-行动-观察),但它是个黑盒:
- 你看不到中间调用了几次工具;
- 无法在危险操作前插入人工确认;
- 不能自定义“总结”“重试”“超时中断”等行为。
虽然它实现了类似Langgraph的事情,但不可见,不可改,不可扩展。
因此,我们要丢掉这个黑盒,用 LangGraph 亲手搭建一个透明、灵活、可编程的白盒 Agent。
2. Langgraph的三要素
如果你用过dify、coze这种低代码Agent构建平台,一定熟悉它们的“可视化流程图”:

拖拽大模型、工具节点、用连线定义条件跳转。
Langgraph就是这个流程图的代码实现。
综上,我们可以总结出三个Langgraph的核心元素:
| 组件 | 作用 | 类比 |
|---|---|---|
| State | 存储整个流程的共享数据(如对话历史、中间结果) | 一张所有人都能读写的白板 |
| Node | 执行具体任务的函数(如调 LLM、查工具) | 一个工人,干完活把结果写回白板 |
| Edge | 定义执行顺序的规则(固定顺序 or 条件跳转) | 工头喊:“A 干完,B 上!”或“如果成功,去 C;否则去 D” |
同样,根据这仨要素,可以总结出拼装的四步法:
(1)定义State结构:决定白板上会有哪些字段;
(2)编写Node函数:每个函数接收当前State,返回要更新的部分;
(3)添加Node到图中:拖拽节点到白板中;
(4)用Edge链接Node:为各个节点画运行先后顺序的线。
用一段代码展示:
from typing import TypedDict
from langgraph.graph import StateGraph,END
# 1. 定义State(状态) -- 白板上只有一个字段"count"
class State(TypedDict):
count:int
# 2. 编写Node(节点) -- 两个"工人"
def node_a(state:State):
# 接收当前State状态,返回要更新的部分
print(f'[Node A]收到状态:{state}')
return {"count":state["count"]+1}
def node_b(state:State):
print(f'[Node B]收到状态:{state}')
return {"count":state["count"]+1}
# 3. 添加Node到图中
workflow = StateGraph(State) # 创建画布
workflow.add_node("A",node_a) # 添加节点A
workflow.add_node("B",node_b) # 添加节点B
# 4. 用Edge连线
workflow.add_edge(START,"A") # START -> A
workflow.add_edge("A","B") # A -> B
workflow.add_edge("B",END) # B -> END
# 编译成可运行应用
app = workflow.compile()
# 传入初始状态,执行工作流
print("---开始执行---")
result = app.invoke({"count":1})
print("最终状态:",result) # 输出{'count':4}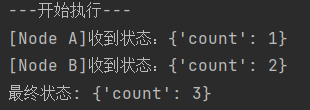
绝大多数 Agent 的 LangGraph 实现,本质上就是围绕 State、Node、Edge 这三大要素进行设计。
3. 可视化支持
LangGraph 提供内置的流程图生成功能:
# 保存可视化架构图
with open('01_workflow.png', 'wb') as f:
f.write(app.get_graph().draw_mermaid_png())
print("图表已保存为 01_workflow.png")这能帮助你在设计阶段直观查看流程结构: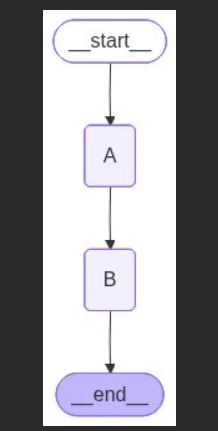
但它只是静态架构图,无法展示运行时状态或调试信息。
若需深度观测执行过程(如每一步输入/输出、耗时、错误),就需要引入 LangSmith —— LangGraph 的官方调试与监控平台。
二、LangSmith —— 你的 Agent “飞行记录仪”与性能仪表盘
LangSmith不是可选项,而是Langchain/Langgraph开发的标准工作流。
1. 什么是LangSmith
你可能会想:不就是个可视化工具吗?值得这么大张旗鼓专开一节?
绝对值得!
LangSmith 不只是一个流程图查看器,而是 专为 LLM 应用打造的全链路开发、调试与监控平台。对于像 LangGraph 这样状态复杂、多步骤交互的系统,没有 LangSmith,就像闭着眼睛开飞机——你知道飞了,但不知道怎么飞的、为何坠毁。
在 LangSmith 的 Web 控制台中,你能:
- 查看每次运行的完整执行轨迹(Trace):从用户输入到最终输出,每一步都清晰可见;
- 监控性能指标:LLM 延迟、Token 消耗、成本估算一目了然;
- 精准定位问题:工具未触发?陷入无限循环?异常堆栈直接标红;
- 对比不同版本:A/B 测试两个 Prompt 或工具策略的效果差异;
- 回放历史对话:完整还原任意一次交互的上下文与中间状态。
对 LangGraph 开发者而言,LangSmith 就如同 Chrome DevTools 之于前端工程师——不是“可有可无”,而是标准开发栈的必备组件。
2. 如何快速接入 LangSmith?
这里我们简单教学下怎么使用LangSmith。
先去官网 LangSmith 注册,可以使用google账号、github或邮箱等。
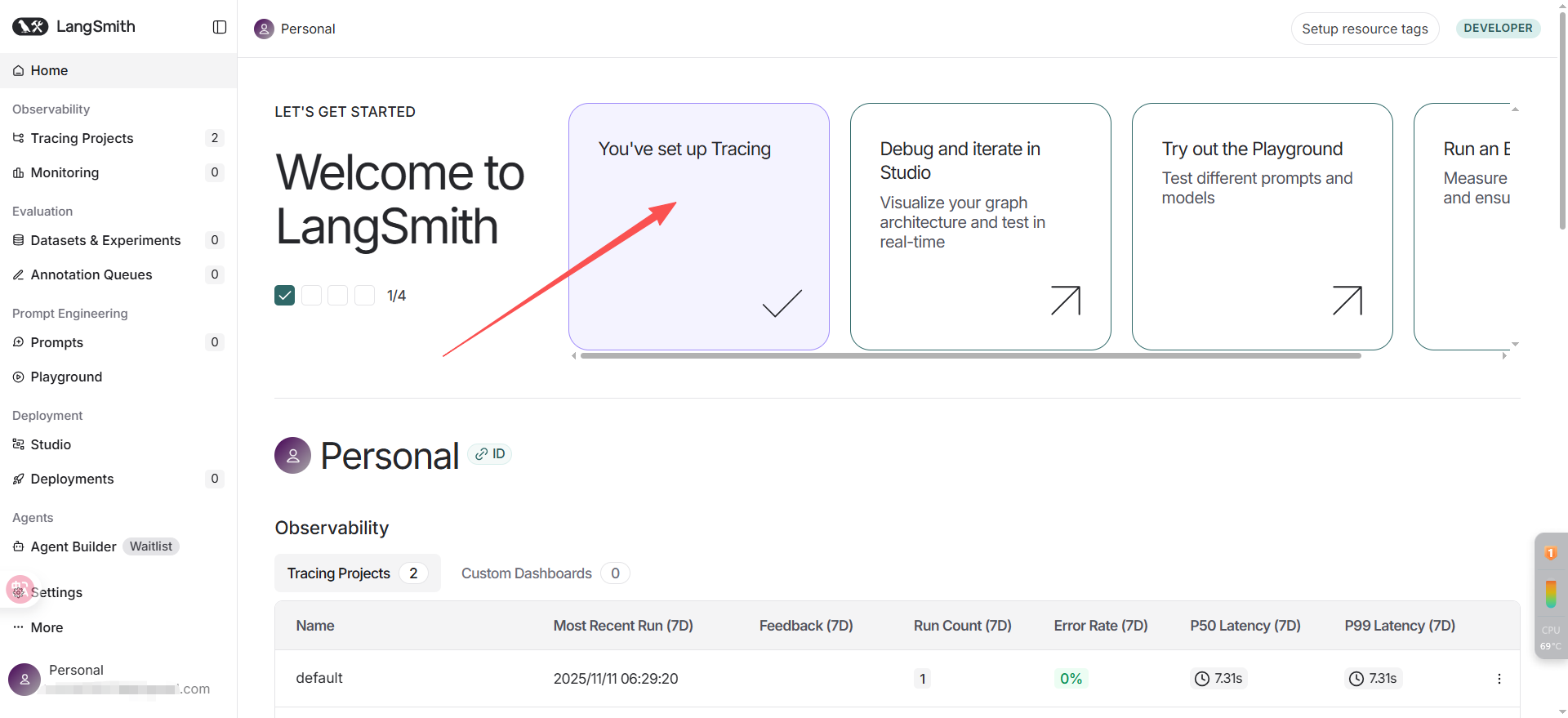
注册完成进到这个页面后,点进红色箭头开始一个LangSmith跟踪;

创建好上面的API Key,再配置好下文的环境变量,
然后我们就可以用这俩开始跟踪我们用langgraph写的代码了:
# ...其他所有代码保持不变
os.environ["LANGCHAIN_TRACING_V2"] = "true" # 总开关,决定启用追踪功能
os.environ["LANGCHAIN_PROJECT"] = "my_demo" # 指定项目名
os.environ["LANGCHAIN_API_KEY"] = langchain_api_key # 从.env读取运行后,LangSmith就会自动追踪
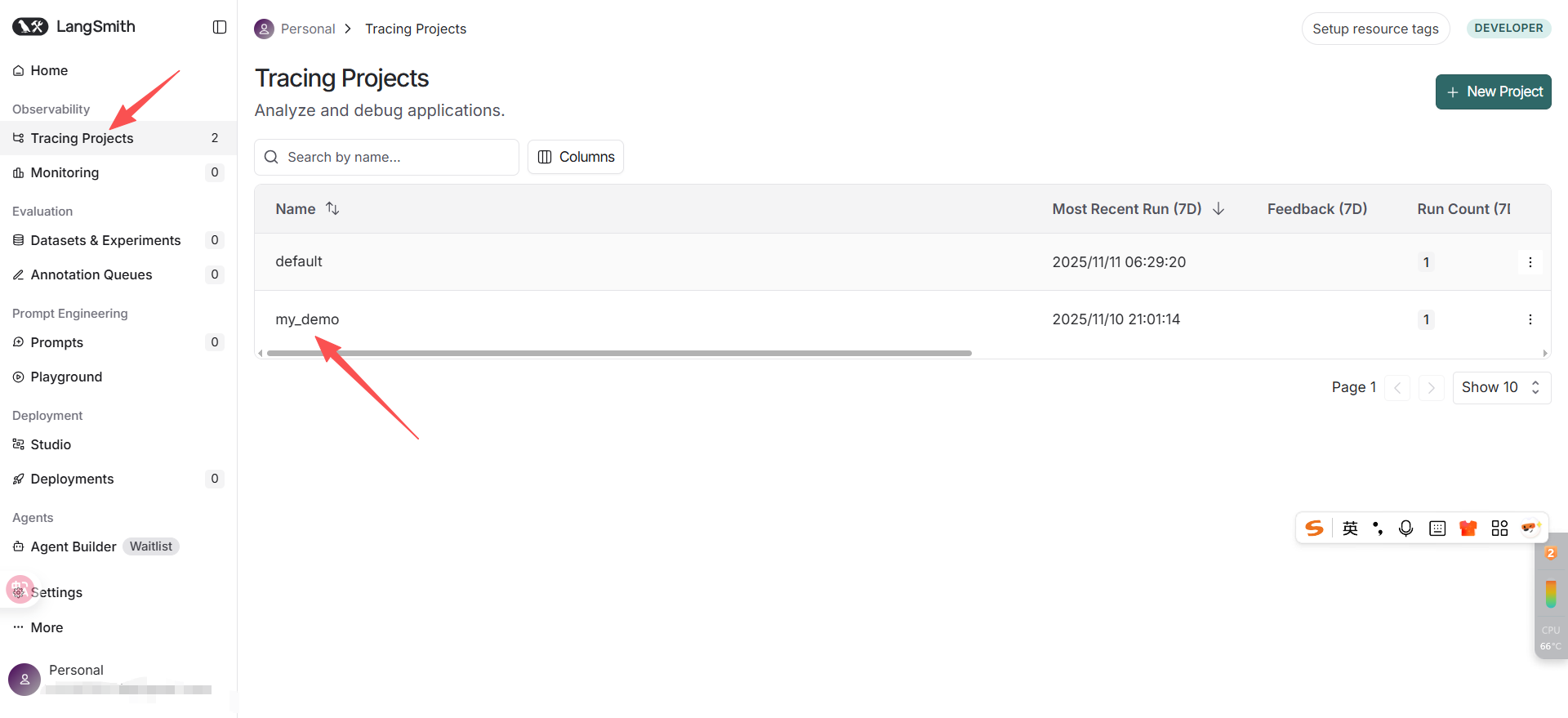

如图,LangSmith 会自动捕获每一次 app.invoke() 的完整执行过程,并在控制台生成一条 Trace 记录。
点击任何一条记录,即可看到:
| 功能 | 说明 |
|---|---|
| Trace 列表 | 每次 app.invoke() 生成一条记录,按时间排序 |
| 执行 DAG 图 | 自动绘制本次运行的实际路径(比如:agent → tools → agent) |
| 节点详情 | 点击任一节点,查看输入/输出/耗时(如 LLM 的 prompt、tool_calls 内容) |
| Token 统计 | 显示 input/output tokens 及估算费用 |
| 状态快照 | 每一步的 messages 完整内容(包括 tool_call_id、role 等元数据) |
| 错误高亮 | 如果工具抛异常,会标红并显示 traceback |
这才是真正的白盒化,不仅能看见每个数据,还能听到每次“心跳”。
建议从第一个 LangGraph 项目起就启用它——调试时间省一半,上线信心翻一倍。
三、最小ReAct引擎:用Langgraph替换AgentExecutor
Langgraph不是另起炉灶,而是Langchain的“白盒化升级”
1. Langchain到Langgraph的演进
回顾我们在Langchain时的六大核心模块:LLM / Prompt / Chain / Memory / Agent / RAG
传统方式下,你只需声明:“我要做什么”,系统就在黑盒中完成执行。尤其是AgentExecutor,它封装了完整的推理与行动逻辑。
而Langgraph并非抛弃Langchain,而是对其“声明式”体系的一种过程式补全:
它深度复用Langchain的所有组件,唯独将AgentExecutor这个黑盒打开,让你能显式定义控制流,实现真正的白箱化Agent。
各模块在Langgraph中的演进对比:
| 模块 | LangChain 原始写法 | LangGraph 中的变化 | 封装程度 |
|---|---|---|---|
| LLM | ChatOpenAI(...) |
完全不变 | ✅ 无需改动 |
| Prompt | 手动拼接 system + history + input | 不再需要 —— 使用 MessagesState 自动维护对话历史,等价于早期无框架时的 messages.append() |
🔁 更简洁、更贴近原生聊天格式 |
| Chain | 显式或隐式构建(如 RAG chain) | 仍可复用,通常封装在工具函数内部 | ✅ 无需改动 |
| Memory | RunnableWithMessageHistory + 自定义 store |
自动集成 —— 通过 checkpointer=MemorySaver() 持久化整个 State,无需手动管理历史消息 |
🔁 更轻量、更鲁棒 |
| Agent | create_tool_calling_agent + AgentExecutor |
被拆解为节点与边: • |
⚙️ 从黑盒变为白箱,但工具定义方式不变 |
| RAG | 作为独立 chain 构建,传入工具 | 完全不变 —— 只需将原有 RAG chain 封装进 @tool 函数体内,即可作为普通工具接入 |
✅ 无需改动 |
可见,LLM、Chain 与 RAG 保持原样,其他模块封装更友好;唯有 Agent 的
AgentExecutor需要被“砸开”,由我们手动构建控制流。
2. 基于 ReAct 思想重构 Agent
AgentExecutor本质上封装的就是经典ReAct循环:
Thought(思考)-- Action(行动)-- Observation(观察)-- Router(是否继续?)
现在,我们用Langraph显式实现这四步:
from langchain.schema import HumanMessage
from langchain.tools import tool
from langchain_openai import ChatOpenAI
from langgraph.graph import StateGraph, MessagesState, END,START
from langgraph.prebuilt import ToolNode
from langchain.prompts import ChatPromptTemplate
from langchain_core.messages import SystemMessage
os.environ["LANGCHAIN_TRACING_V2"] = "true" # 总开关,决定启用追踪功能
os.environ["LANGCHAIN_PROJECT"] = "demo01" # 自定义项目名
os.environ["LANGCHAIN_API_KEY"] = LANGCHAIN_API_KEY
# LLM配置
llm = ChatOpenAI(
model="deepseek-chat",
api_key=OPENAI_API_KEY,
base_url="https://api.deepseek.com"
)
# 工具定义
@tool
def get_weather(loaction):
"""模拟获取天气"""
return f'{loaction}当前天气:23℃,晴,风力2级'
tools = [get_weather]
llm_with_tools = llm.bind_tools(tools) # 让llm学会调用工具节点
# --- 核心组件:拆解AgentExecutor ---
# ReAct Step1:Thought(LLM决策)
def call_model(state:MessagesState):
response = llm_with_tools.invoke(state['messages'])
return {"messages":[response]} # 新消息追加到状态
# ReAct Step2-3:Action + Observation
tool_node = ToolNode(tools)
# ReAct Step4:Loop Controller(是否循环)
def should_continue(state:MessagesState):
last_msg = state["messages"][-1]
if hasattr(last_msg,"tool_calls") and last_msg.tool_calls:
return "tools" # 有工具调用 -> 执行工具
return END # 无工具调用 -> 返回答案
# --- 构建 ReAct 循环图---
workflow = StateGraph(MessagesState)
workflow.add_node("agent",call_model) # Thought
workflow.add_node("tools",tool_node) # Action + Observation
workflow.add_edge(START,"agent")
# 条件边:Thought -> 决定下一步
workflow.add_conditional_edges(
"agent", # 从哪个节点出发
should_continue, # 决定下一步去哪
{
"tools":"tools", # 如果返回tools,去tools节点
END:END # 如果返回END,直接结束工作流
}
)
workflow.add_edge("tools","agent")
app = workflow.compile()
if __name__ == '__main__':
# 触发工具
result = app.invoke(
{"messages":[
HumanMessage(content="北京天气如何?")
]}
)
print('工具调用结果:',result['messages'][-1].content)
# 不触发工具
result = app.invoke({"messages":HumanMessage(content="你好")})
print('直接回答:',result['messages'][-1].content)关于add_contional_edges的说明:
与基础的add_edge不同,add_conditional_edges引入了动态路由能力:
- 它根据当前状态(如是否有
tool_calls)决定下一步走向; - 支持多路分支、状态感知、自定义判断逻辑;
- 相比 Coze/Dify 等平台的固定条件判断,可控性更强、灵活性更高。
这正是Langgraph实现复杂Agent控制流的核心机制。


运行成功。我们:
- 复现了标准 ReAct 循环;
- 完全替代了
AgentExecutor的黑盒行为; - 保留了 LangChain 所有生态组件的兼容性(包括未来接入 RAG);
- 获得了更高的可观测性、可调试性与可扩展性。
此时的Agent不再是魔法,而是一个清晰、透明、可干预的可视化工作流——这正是迈向生产级智能体的关键一步。
四、综合实战 -- 带记忆的完整交互
在P3的基础上,只需增加两行代码,让Langgraph带上持久化记忆能力:
得益于Langgraph的状态驱动设计,我们不再需要:
- 手动拼接history到prompt;
- 实现get_session_history;
- 管理ChatMessageHistory存储。
- 一切由checkpointer自动完成。
正确处理系统提示(prompt)
P3未显式使用系统提示。在P4中,我们希望引入sys_prompt,但不能每次app.invoke()时都传入SystemMessage,不然会在多轮对话中重复插入,污染历史记录。
正确做法是:仅在LLM调用时临时拼接系统提示,但不将其写入状态历史。
# ...
# ReAct Step1:Thought(LLM决策)
def call_model(state:MessagesState):
# 构造带system prompt 的完整消息列表(仅用于本次LLM调用)
message_for_llm = [SystemMessage(content=sys_prompt)]+state["messages"]
response = llm_with_tools.invoke(message_for_llm)
# 此处只会返回新生成的消息,不包含prompt,防止污染历史
return {"messages":[response]}这样,系统提示仅影响当前推理,不会被保存到历史记录中,保证了状态的干净与一致性。
启用记忆功能
其余代码不变,仅在编译时启用检查点:
# 编译时启用记忆
app = workflow.compile(checkpointer=MemorySaver())交互循环(带会话隔离)
if __name__ == '__main__':
session_id = "user123"
config = {
"configurable":{"thread_id":session_id}
}
while 1:
user_input = input('\n你:')
if user_input.strip().lower() == 'quit':
break
result = app.invoke(
{'messages':[HumanMessage(content=user_input)]},
config=config
)
ai_msg = result["messages"][-1]
print(f'AI:{ai_msg.content}')
注意:Langgraph中用于标识会话的字段是thread_id,而非Langchain早期使用的session_id。
- session_id是Langchain高层组件中的“会话”抽象,主要用于消息历史管理;
- thread_id是Langgraph的标准字段,代表一个完整的状态执行流程,用于整个State的持久化和恢复。
因此,langgraph必须使用thread_id,否则记忆无法工作。

运行成功。
至此,我们构建了一个具备系统提示、工具调用、多轮记忆、会话隔离的完整ReAct Agent,符合Langgraph最佳实践。
总结、
知识点概括:Langgraph核心三要素|ReAct循环白盒化实现 | LangSmith调试追踪 | 持久化记忆 | 提示词安全注入
本篇我们彻底“拆解”了Langchain中封装严密的“AgentExecutor”,用LangGraph从零构建了一个透明、可控、可扩展的白盒ReAct Agent。通过显式定义状态、节点和边,我们不仅复现了标准的“思考-行动-观察”循环,还集成了系统提示、工具调用与多轮记忆的生产能力。
同时,LangSmith也让整个观察过程变得清晰明了,整个工作流不再是蒙着眼睛。
预告:09 篇 《Langgraph 进阶》
基础循环只是起点。当任务需要多个工具串联?当关键操作需要人工确认?当流程需要动态分支?
第09篇,我们将基于当前引擎,引入自定义State字段、人工审批节点与条件路由逻辑,打造真正鲁棒、可控、可审计的企业级智能体。
让Agent不仅能被思考,更能被信任。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 16
16 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)