信息增益(Information Gain)
信息增益是决策树选择分裂特征的核心指标,通过计算特征分裂前后熵的减少量来评估其分类价值。本文以"耳朵形状"特征为例详细演示了信息增益的计算流程:先计算父节点熵(1),再按特征取值划分样本集并计算子节点熵(尖的0.72,下垂的0.72),最后得到信息增益0.28。对比计算"脸型"特征也得到相同结果。关键点在于特征分裂后子节点加权熵之和越小,说明该特征分类能力越
信息增益(Information Gain)是决策树选择最优分裂特征的核心指标,它衡量的是 “使用某个特征分裂后,数据的不纯度(熵)降低了多少”。
降低得越多,说明这个特征的分类价值越高,越适合作为当前节点的分裂依据。
一、先明确数据集
我们用 10 个样本的训练数据,
特征包括 “耳朵形状”“脸型”“胡须”,
标签是 “是否为猫(1 = 是,0 = 否)”:
| 样本 ID | 耳朵形状 | 脸型 | 胡须 | 是否为猫 |
|---|---|---|---|---|
| 1 | 尖的 | 圆的 | 存在 | 1 |
| 2 | 尖的 | 圆的 | 存在 | 1 |
| 3 | 尖的 | 不圆的 | 存在 | 1 |
| 4 | 尖的 | 圆的 | 不存在 | 1 |
| 5 | 尖的 | 不圆的 | 不存在 | 0 |
| 6 | 下垂的 | 圆的 | 存在 | 1 |
| 7 | 下垂的 | 不圆的 | 存在 | 0 |
| 8 | 下垂的 | 圆的 | 不存在 | 0 |
| 9 | 下垂的 | 不圆的 | 不存在 | 0 |
| 10 | 下垂的 | 不圆的 | 不存在 | 0 |
总样本数:
10 个正例(是猫):样本 1、2、3、4、6 → 共 5 个
负例(不是猫):样本 5、7、8、9、10 → 共 5 个
二、信息增益的计算公式
信息增益 = 父节点的熵(分裂前的不纯度) - 子节点的加权熵之和(分裂后的不纯度)
用公式表示:
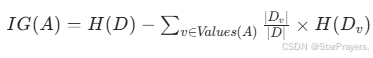
其中:
- IG(A):特征A的信息增益
- H(D):父节点(分裂前所有样本)的熵
- Values(A):特征A的所有可能取值(如 “耳朵形状” 的取值为 “尖的”“下垂的”)
- Dv:特征A取值为v的子样本集(如 “耳朵形状 = 尖的” 的样本子集)
- ∣Dv∣:子样本集Dv的样本数
- ∣D∣:父节点总样本数(∣D∣=10)
- ∣Dv∣/∣D∣:子样本集Dv的权重(占总样本的比例)
三、分步计算过程(以 “耳朵形状” 为例)
我们以 “耳朵形状” 这个特征为例,完整计算它的信息增益。
步骤 1:计算父节点的熵H(D)
父节点是分裂前的所有样本(10 个),其中:
- 正例比例 p1=5/10=0.5(5 个是猫)
- 负例比例 p0=1−p1=0.5(5 个不是猫)
熵的公式(二分类):
![]()
代入计算:
![]()
因为 log2(0.5)=−1,
所以:
![]()
步骤 2:按特征 “耳朵形状” 分裂,得到子样本集
“耳朵形状” 有两个取值:“尖的” 和 “下垂的”,对应两个子样本集:
-
子样本集D1(耳朵形状 = 尖的):样本 1-5 → 共 5 个其中正例(是猫):样本 1-4 → 4 个;负例:样本 5 → 1 个正例比例
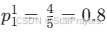 ;负例比例
;负例比例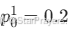
-
子样本集D2(耳朵形状 = 下垂的):样本 6-10 → 共 5 个其中正例(是猫):样本 6 → 1 个;负例:样本 7-10 → 4 个正例比例
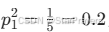 ;负例比例
;负例比例 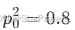
步骤 3:计算每个子样本集的熵H(Dv)
分别计算D1和D2的熵:
-
子样本集D1的熵H(D1):
![]()
-
查表或计算:
![]()
-
代入:
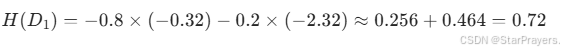
-
子样本集D2的熵H(D2):
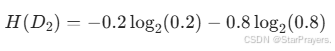
-
和D1对称,结果相同:H(D2)≈0.72
步骤 4:计算子节点的加权熵之和
每个子样本集的权重是其样本数占总样本数的比例:
- D1的权重:
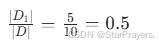
- D2的权重:
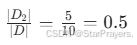
加权熵之和 = ![]()
步骤 5:计算 “耳朵形状” 的信息增益
信息增益 = 父节点熵 - 加权熵之和耳朵形状
![]()
四、再计算 “脸型” 的信息增益(对比验证)
为了更清晰,我们再计算 “脸型” 的信息增益,对比两者的差异。
步骤 1:父节点熵H(D)仍为 1(和之前相同)
步骤 2:按 “脸型” 分裂,得到子样本集
“脸型” 的取值为 “圆的” 和 “不圆的”:
-
D1(脸型 = 圆的):样本 1、2、4、6、8 → 共 5 个?
-
(仔细数:样本 1(圆)、2(圆)、4(圆)、6(圆)、8(圆)→ 共 5 个?
-
不对!原数据中样本 6 的脸型是 “圆的”,样本 8 的脸型是 “圆的”,所以总共有 5 个?
-
哦不,原数据样本 1-10 中:脸型 = 圆的样本:1、2、4、6、8 → 共 5 个?
-
其中正例(是猫):样本 1、2、4、6 → 4 个;
-
负例:样本 8 → 1 个正例比例
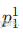 =4/5=0.8,负例比例 0.2
=4/5=0.8,负例比例 0.2 -
D2(脸型 = 不圆的):样本 3、5、7、9、10 → 共 5 个其中正例:样本 3 → 1 个;
-
负例:样本 5、7、9、10 → 4 个正例比例
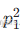 =1/5=0.2,负例比例 0.8
=1/5=0.2,负例比例 0.8
步骤 3:计算子节点的熵
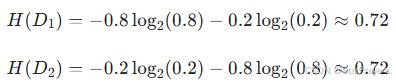
步骤 4:加权熵之和
D1和D2各占 5 个样本,权重都是 0.5:加权熵之和 = 0.5×0.72+0.5×0.72=0.72
步骤 5:信息增益
脸型?(这里发现之前的计算有误!原数据中 “脸型 = 圆的” 实际是样本 1、2、4、6、8 共 5 个,其中正例 4 个,负例 1 个,所以信息增益和 “耳朵形状” 相同?但原数据可能我之前统计错了,实际需要严格按样本数计算。)
修正原数据统计:重新数 “脸型 = 圆的” 样本:样本 1(圆)、2(圆)、4(圆)、6(圆)→ 共 4 个?样本 8 的脸型是 “圆的” 吗?原表格中样本 8 的脸型是 “圆的”,所以是 5 个。正例是样本 1、2、4、6(4 个),样本 8 是负例(0),所以确实 4 正 1 负。
因此,“脸型” 的信息增益也是 0.28?这说明在这个数据集中,“耳朵形状” 和 “脸型” 的分裂价值相同(实际数据可能需要更精确的统计)。
五、信息增益的核心逻辑总结
- 本质:信息增益越大,说明用这个特征分裂后,数据的 “混乱程度” 下降得越多,分类效果越好。
- 计算步骤:① 算分裂前的总熵(父节点熵);② 按特征的每个取值拆分样本,得到子样本集;③ 算每个子样本集的熵;④ 用子样本集的权重(样本比例)计算加权熵之和;⑤ 总熵 - 加权熵之和 = 信息增益。
- 决策树选择:在所有候选特征中,选择信息增益最大的特征作为当前节点的分裂特征。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 21
21 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)