【Agent学习】Day05-06
本文介绍了基于FastAPI+LangChain构建AI服务的完整流程。首先通过LangServe搭建REST API接口,实现自我介绍生成功能;然后详细讲解了RAG问答框架的实现,包括网页内容抓取、文本分块处理、向量化存储及检索;最后实现了流式输出功能,优化了问答体验。
1 搭建基于 FastAPI + LangChain 的 AI 服务接口
LangServe用于将Chian或者Runnable部署成一个REST API服务。
首先安装LangServe的服务端和客户端:
pip install "langserve[all]"运行服务端代码:
import os
from dotenv import load_dotenv, find_dotenv
_=load_dotenv(find_dotenv())
from fastapi import FastAPI
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from langserve import add_routes
import uvicorn
app = FastAPI(
title="LangChain Server",
version="1.0",
description="A simple api server using Langchain's Runnable interfaces",
)
prompt_template ="""
我的名字叫【{name}】,我的个人介绍是【{description}】。
请根据我的名字和个人介绍,帮我想一段劲暴的自我介绍!
"""
model = ChatOpenAI()
prompt = ChatPromptTemplate.from_template(prompt_template)
add_routes(
app,
prompt | model,
path="/self_introduction"
)
if __name__ == "__main__":
uvicorn.run(app, host="localhost", port=9999)运行结果:
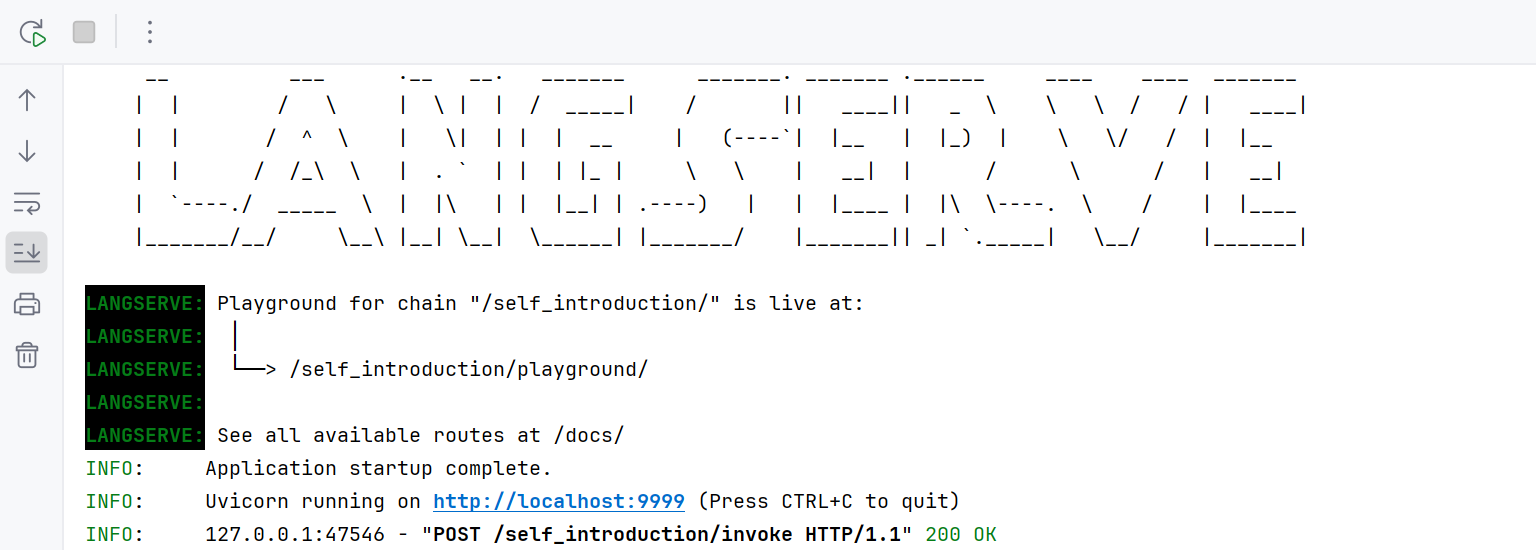
再运行客户端代码:
import requests
responses = requests.post(
"http://localhost:9999/self_introduction/invoke",
json={'input':{'name':'小林','description':'热爱生活、喜欢跳舞'}}
)
print(responses.json())运行结果:
{'output': {'content': "大家好,我是小林!一个对生活充满热情的舞者,舞动的不仅是身体,更是心灵的自由与激情!无论节奏多快,我都能用舞步点燃整个舞台,让每一个瞬间都爆发出无限能量!跟着我一起燃烧吧,让生活因舞动而精彩!Let's go!",
'additional_kwargs': {'refusal': None},
'response_metadata':
{'token_usage': {'completion_tokens': 82, 'prompt_tokens': 50, 'total_tokens': 132, 'completion_tokens_details': None, 'prompt_tokens_details': None},
'model_provider': 'openai',
'model_name': 'gpt-4.1-mini-2025-04-14',
'system_fingerprint': 'fp_b6f445fc1c',
'id': 'chatcmpl-xxxxxxxxx', '
finish_reason': 'stop',
'logprobs': None},
'type': 'ai',
'name': None,
'id': 'lc_run--xxxxxxxxxxxx',
'tool_calls': [],
'invalid_tool_calls': [],
'usage_metadata': {'input_tokens': 50, 'output_tokens': 82, 'total_tokens': 132, 'input_token_details': {}, 'output_token_details': {}}}, 'metadata': {'run_id': '83891f56-90ec-44a4-b528-30c89a4a662e', 'feedback_tokens': []}}
现在简单介绍一下FastAPI、LangChain和OpenAI在以上代码中的作用:
FastAPI:负责启动一个本地网站并提供接口,他人可以通过该网址访问你的网站并使用接口提供的功能
- 创建http://localhost:9999网站
- 提供/self_introduction接口
LangChain:将提示词模版和大模型串联为可调用的链条
OpenAI:理解文字进行推理
三者配合流程:
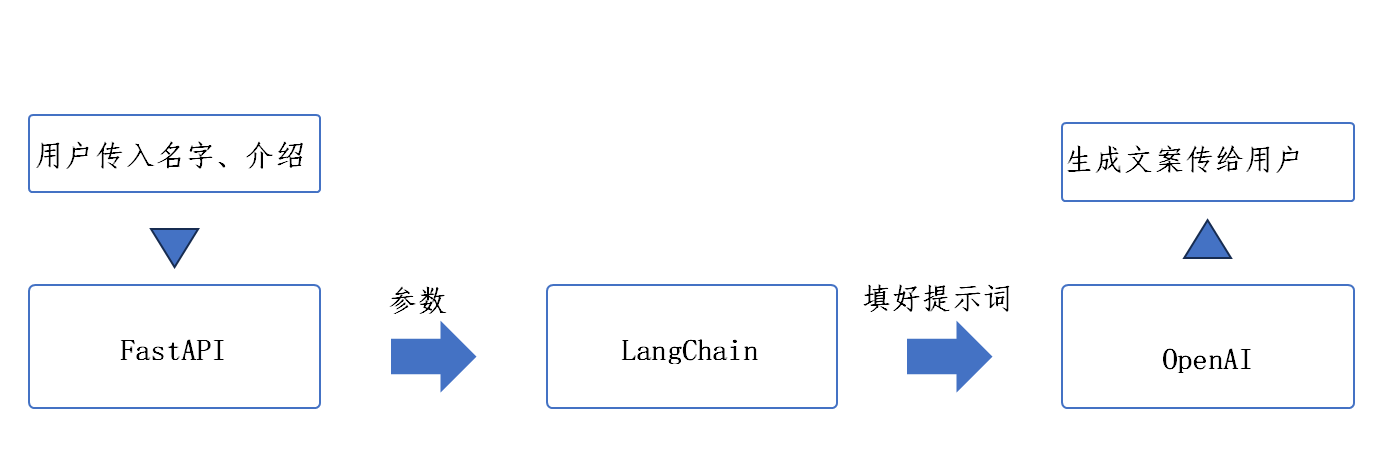
下面我们构建一个RAG问答的框架并在此基础上学习流式输出
2 构建一个RAG问答的框架
2-1 通过URL加载网页内容
首先了解Web检索,其涉及的主要步骤如下:
- 用户提问、联网搜索
- 通过URL记载网页HTML数据
- 转换加载到的数据、获取关注的内容并形成文本
- 对文本进行分块、向量化、存储
- 调用大模型进行总结、生成最终答案
2-1-1 使用LangChain接口提取文本
在LangChain中将爬虫功能分为了两个模块:Loading和Transforming
Loading的功能是将URL加载转换成HTML内容
包含两个主要类:
- AsyncHtmlLoader:使用aiohttp库生成异步HTTP请求,适用于更简单、轻量级的抓取
- AsyncChromiumLoader:使用Playwright启动Chromium实例,该实例可以处理JavaScript渲染和更复杂的Web交互
Transforming的功能是将HTML内容转换成需要的文本
包含两个主要类:
- HTML2Text:将HTML内容直接转换为纯文本而无需任何特定的标记操作。适用于目标是提取人类可读文本而不需要操作特定HTML元素的场景
- Beautiful Soup:对HTML内容提供了更细粒度的控制,支持特定的标记提取、删除和内容清理。适用于需要提取特定信息并根据需要清理HTML内容的场景
先运行以下代码上手尝试:
urls = ["https://blog.csdn.net/m0_65105533/article/details/159619498?spm=1001.2014.3001.5502"]
from langchain_community.document_loaders import AsyncChromiumLoader
from langchain_community.document_transformers import BeautifulSoupTransformer
loader = AsyncChromiumLoader(urls)
html = loader.load()
print("================html=================")
print(html)
bs_transformer = BeautifulSoupTransformer()
docs_transformed = bs_transformer.transform_documents(html,tags_to_extract=["span"])
print("\n")
print("================docs_transformed=================")
print(docs_transformed)运行结果:
P.S.在运行代码时我发现运行结果在一行显示,观感不佳,查询解决方法后发现在运行窗口点击左侧按钮即可自动换行
可以发现html转换为文字的提取效果并不理想,没有把我们想要的所有信息都提取出来,因此我们需要修改代码中函数的参数
docs_transformed = bs_transformer.transform_documents(html,tags_to_extract=["span","code","p"])修改后运行结果如下:


我们应该如何确定需要在tags_to_extract中的参数呢?
首先,打开目标url网站,按F12键打开网页调试功能(有时打不开这个功能是因为被锁住了,可以先长按“Fn+Esc”解锁功能后再按F12键)
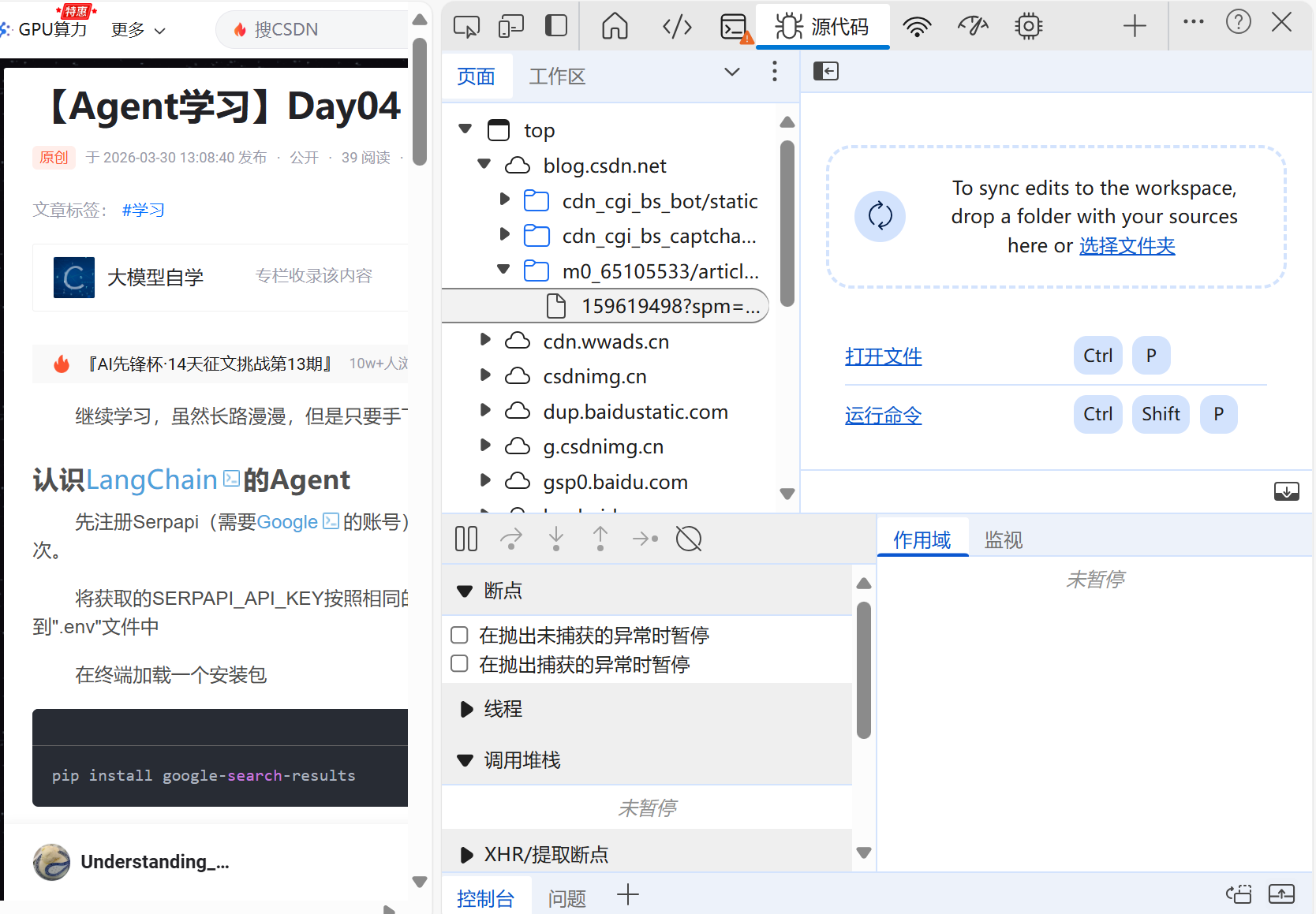
先打开元素选项,再点击最左侧的按钮
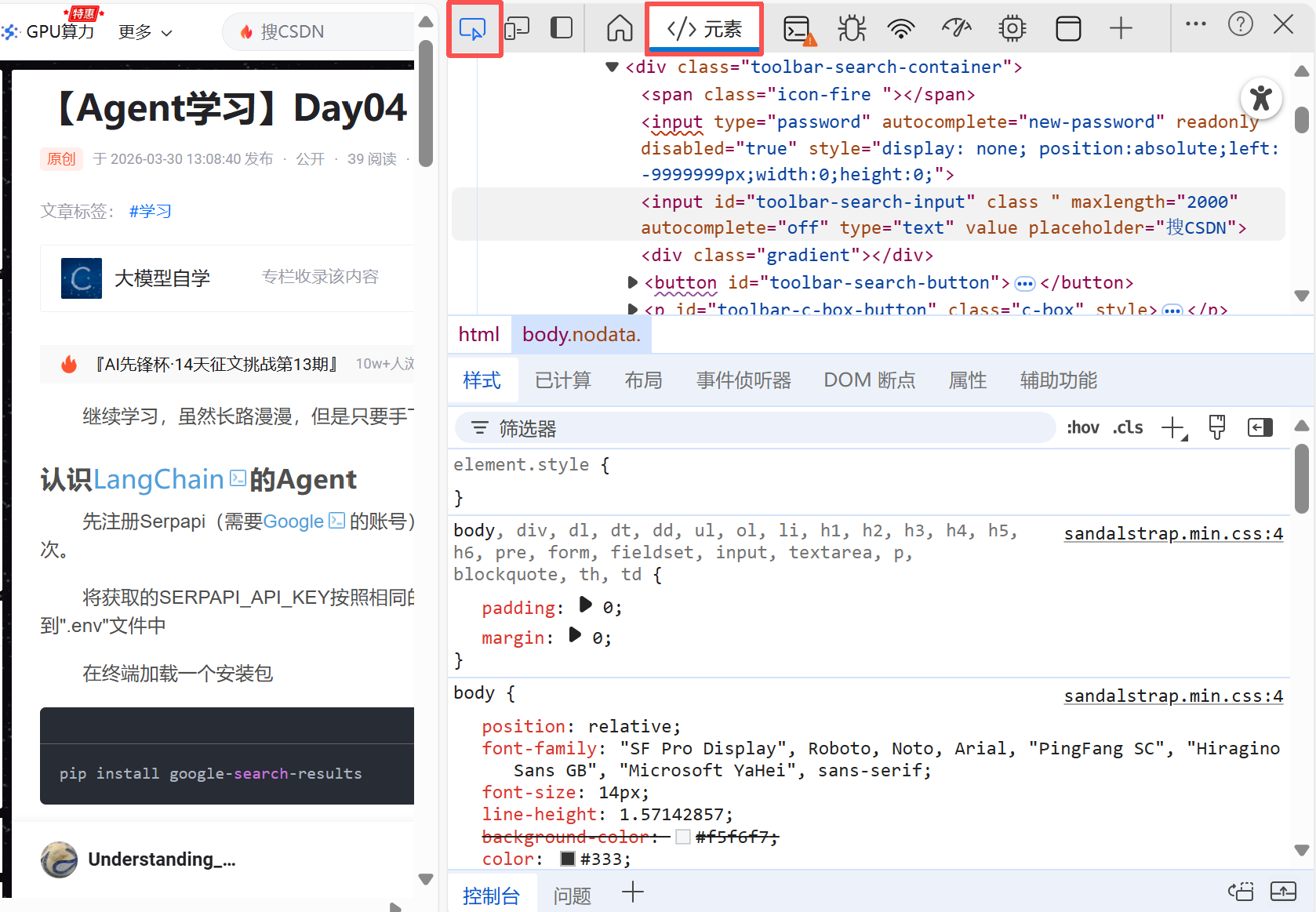
将鼠标悬浮到想提取的文字元素上,就会显示出它对应的标签
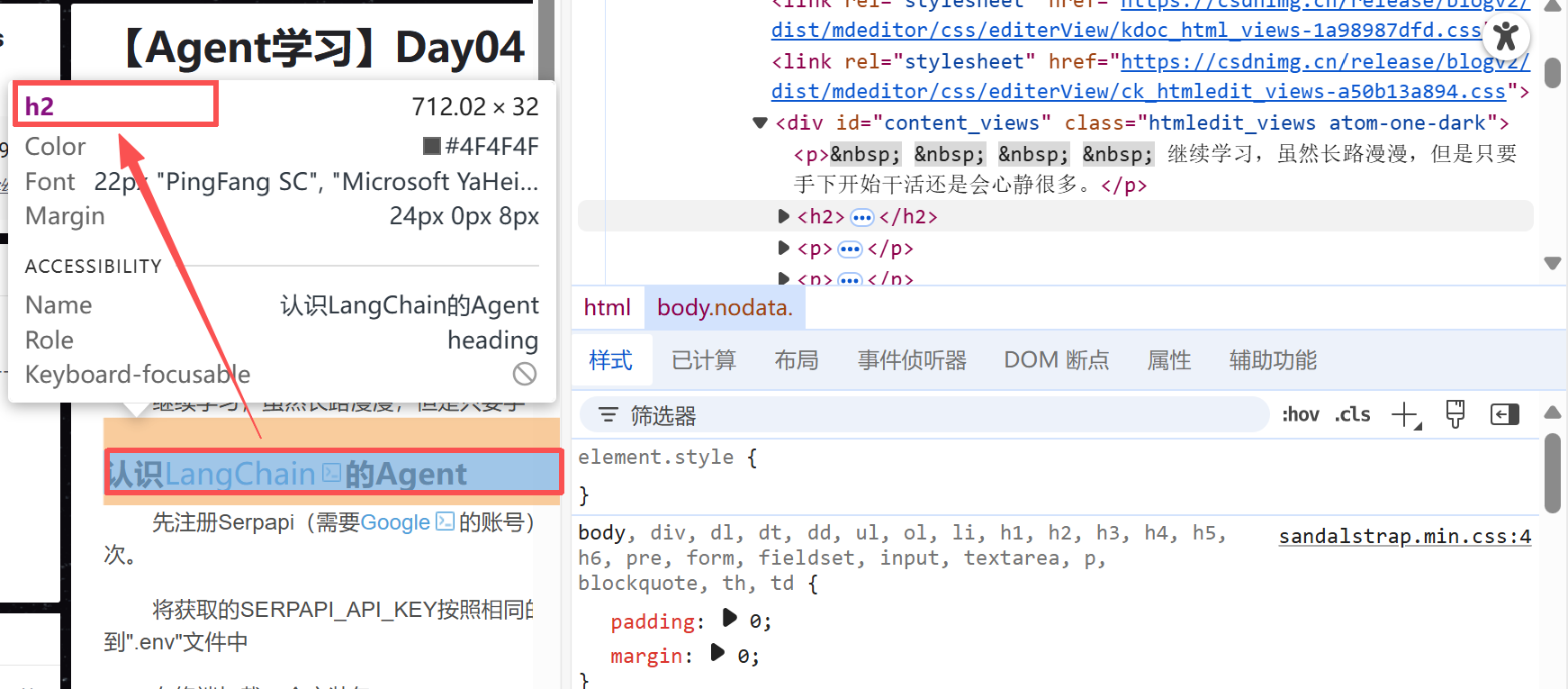
将这些tag填入函数中即可提取对应的元素,比如我将函数参数修改为“h2”,提取所有的一级标题
docs_transformed = bs_transformer.transform_documents(html,tags_to_extract=["h2"])运行结果:

因为该文章中有两个一级标题,所以结果中显示了“认识LangChain的Agent ”、“拆解Agent的实现”
下面我们将利用爬虫能力和之前的RAG实践共同搭建一个使用网络数据进行RAG文档的实例。
2-2 网络数据+RAG问答的实践
2-2-1 基础功能实现
运行以下代码:
import bs4
import os
os.environ["OPENAI_API_KEY"] = "sk-xxxxxxx"
os.environ["OPENAI_API_BASE"] = "https://api.fe8.cn/v1"
from langchain_classic import hub
#最新版hub从langchain_classic中导入,需要在终端:pip install langchain_classic
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import Chroma
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
#================================================================
#1:加载网页数据
#================================================================
loader = WebBaseLoader(
web_paths = ("https://lilianweng.github.io/posts/2023-06-23-agent/",),
bs_kwargs = dict(
parse_only = bs4.SoupStrainer(
class_=("post-content","post-title","post-header")
#只提取HTML页面中的这些tag数据
)
),
)
docs = loader.load()
#================================================================
#2:数据分块
#================================================================
text_splitter = RecursiveCharacterTextSplitter(chunk_size = 1000,chunk_overlap =200)
splits = text_splitter.split_documents(docs)
#================================================================
#3:数据向量化和存储
#================================================================
vectorstore = Chroma.from_documents(documents = splits,embedding = OpenAIEmbeddings())
#================================================================
#4:向量检索
#================================================================
retriever = vectorstore.as_retriever()
#================================================================
#5:组装Chain
#================================================================
prompt = hub.pull("rlm/rag-prompt")
#加载了一个Prompt模板
llm =ChatOpenAI(model_name ="gpt-3.5-turbo",temperature = 0)
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
rag_chain=(
{"context":retriever|format_docs,"question":RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
#================================================================
#6:运行
#================================================================
result = rag_chain.invoke("What is Task Decomposition?")
print(result)运行结果:

2-2-2 加入信息来源功能
修改上述代码的第5、6部分:
#================================================================
#5:组装Chain
#================================================================
prompt = hub.pull("rlm/rag-prompt")
#加载了一个Prompt模板
llm =ChatOpenAI(model_name ="gpt-3.5-turbo",temperature = 0)
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
# rag_chain=(
# {"context":retriever|format_docs,"question":RunnablePassthrough()}
# | prompt
# | llm
# | StrOutputParser()
# )
rag_chain_from_docs = (
RunnablePassthrough.assign(context=(lambda x: format_docs(x["context"])))
| prompt
| llm
| StrOutputParser()
)
rag_chain_with_source = RunnableParallel(
{"context": retriever, "question": RunnablePassthrough()}
).assign(answer=rag_chain_from_docs)
#================================================================
#6:运行
#================================================================
result = rag_chain_with_source.invoke("What is Task Decomposition?")
print(result)运行结果:


2-2-3 解释运行代码
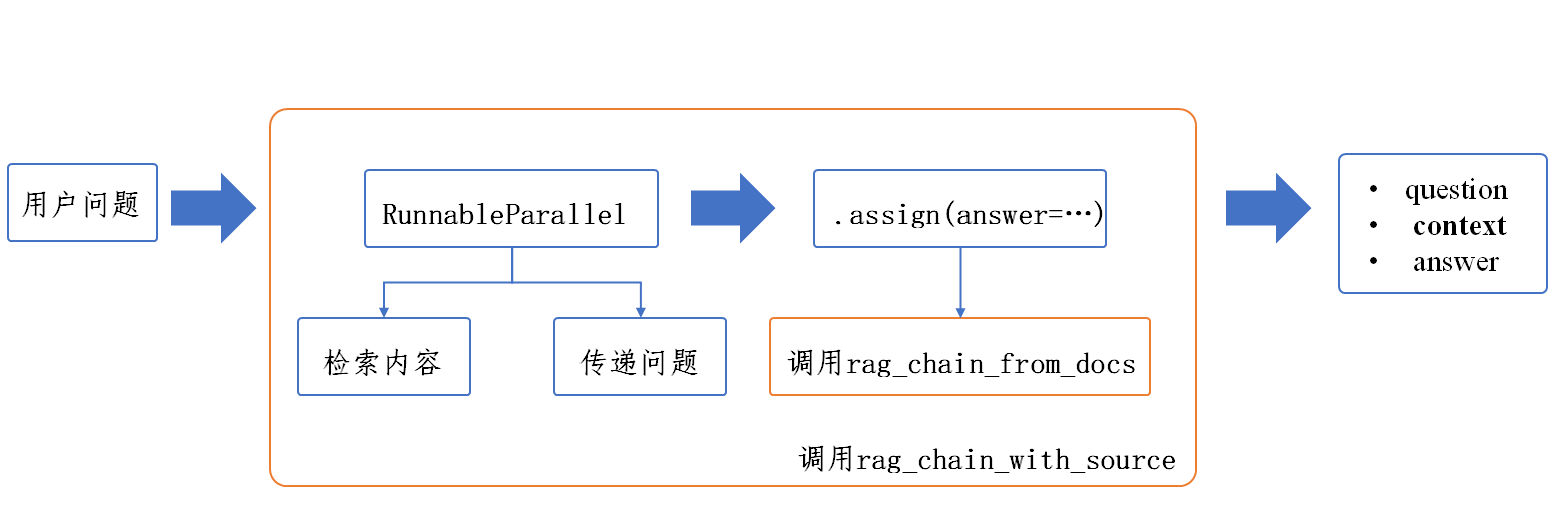
rag_chain_from_docs:用于构建一个RAG链根据输入的内容生成对应的答案
rag_chain_from_source:使用RunnableParallel并行执行两个任务——检索相关文档和传递用户问题,再使用.assign追加一个answer字段将rag_chain_from_docs生成的答案放入
流程如下:
3 构建流式输出
3-1 实现LangChain的流式输出Streaming
承接2中构建的代码并修改第6部分的代码:
#修改为流式输出
for chunk in rag_chain_with_source.stream("What is Task Decomposition?"):
print(chunk)运行结果:
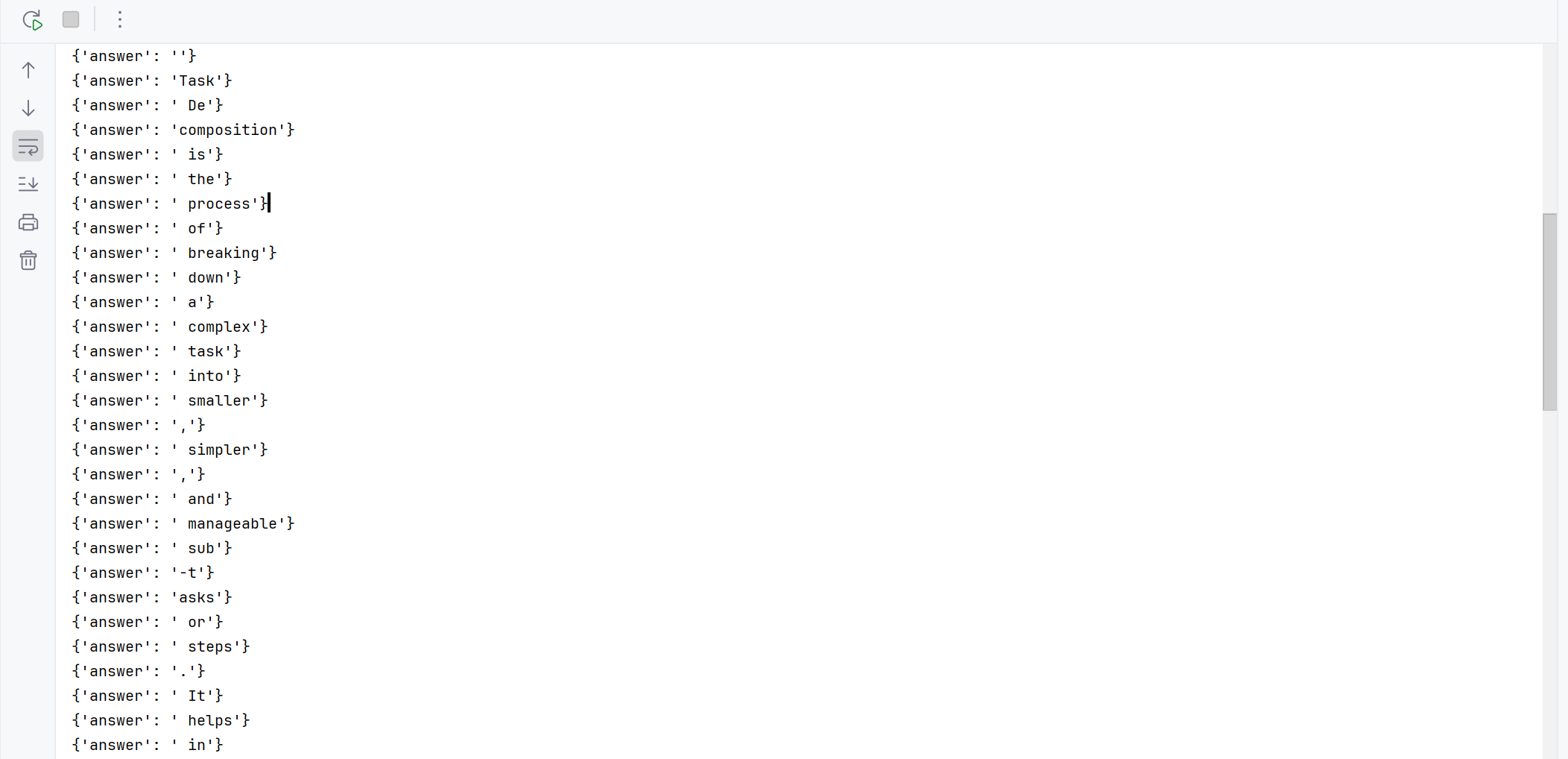
下面我们可以将答案组装起来,保证它一个一个输出:
代码修改第6部分:
#组装答案
output = {}
curr_key = None
for chunk in rag_chain_with_source.stream("What is Task Decomposition?"):
for key in chunk:
if key not in output:
output[key] = chunk[key]
else:
output[key] = output[key] + chunk[key]
if key != curr_key:
print(f"\n\n{key}:{chunk[key]}",end = "",flush=True)
else:
print(chunk[key],end = "",flush=True)
curr_key = key运行结果如下:

今天的学习就先到这里,放清明假期啦,清明安康

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)