NCCL学习笔记
NCCL(NVIDIA Collective Communication Library)是 GPU 集群高性能集体通信的核心软件层,专注于优化 GPU-to-GPU 交互支持 NVLink、PCIe、InfiniBand 等 interconnect 技术,广泛应用于分布式 AI 与 HPC workloads.NCCL起初的设计目标是构建一款易集成、拓扑感知的集体通信库,最终提升多 GPU 应
·
缘起
清华微电子所 做AI Infra卫锋兄弟,经常给我推荐NCCL相关的文章,非常感谢他,是时候该交"学习笔记"了.
“大模型”训练资料
- https://images.nvidia.com/events/sc15/pdfs/NCCL-Woolley.pdf
- https://arxiv.org/html/2507.04786v1
- 通信pipeline分析 https://mp.weixin.qq.com/s/blvPFSLhp0wIPfi8tiRJgQ?scene=1&click_id=4
- NCCL通信引擎深度解剖(科普)
- https://zhuanlan.zhihu.com/p/1953624825210831514 结合llm的实战:
- https://mp.weixin.qq.com/s/W36wGm2J7UA81yyotUrtDQ
百度的:https://zhuanlan.zhihu.com/p/30451575581
1. NCCL 背景
-
NCCL(NVIDIA Collective Communication Library)是 GPU 集群高性能集体通信的核心软件层,专注于优化 GPU-to-GPU 交互支持 NVLink、PCIe、InfiniBand 等 interconnect 技术,广泛应用于分布式 AI 与 HPC workloads.
-
NCCL起初的设计目标是构建一款易集成、拓扑感知的集体通信库,最终提升多 GPU 应用的可扩展性,并行应用可扩展性中,通信相关的核心限制因素是通信量和通信与计算的重叠程度.
-
从资料1的结论看P2P的通信优化没啥难度(not for me),nccl 重点是多节点(Multiple senders and/or receivers)之间的通信效率优化.
1.1 集体通信的核心挑战
集体通信因自身特性,实现高效传输面临诸多困难,主要挑战包括:
- 通信低效加剧:多发送 / 接收节点的特性会放大通信中的低效问题,小数据传输时延迟占主导(节点数量越多,总延迟越高),大数据传输时带宽是关键(易出现带宽瓶颈)。
- 拓扑依赖强:高性能实现需依赖系统拓扑,而多数系统拓扑复杂(非简单胖树结构),增加了适配难度。
- 阻塞 / 非重叠问题:多数集体通信模式为阻塞或非重叠模式,通信过程无法与计算过程并行,导致资源利用率低。
- 现有实现非最优:实际应用中,多数集体通信的实现未达到最优性能,无法充分发挥硬件潜力。
1.2 集体通信的应用价值
尽管存在上述挑战,集体通信仍是并行应用实现可扩展性的核心,在多个关键领域不可或缺,具体应用场景如下:
- 深度学习:依赖 All-reduce(梯度同步)、广播(参数分发)、聚集(数据汇总)等模式。
- 并行 FFT(快速傅里叶变换):数据转置过程需依赖 All-to-all 模式。
- 分子动力学:模拟过程中需通过 All-reduce 实现数据合并与同步。
- 图分析:图数据分布式处理时,需通过 All-to-all 实现节点数据交互。
1.3 通信模式
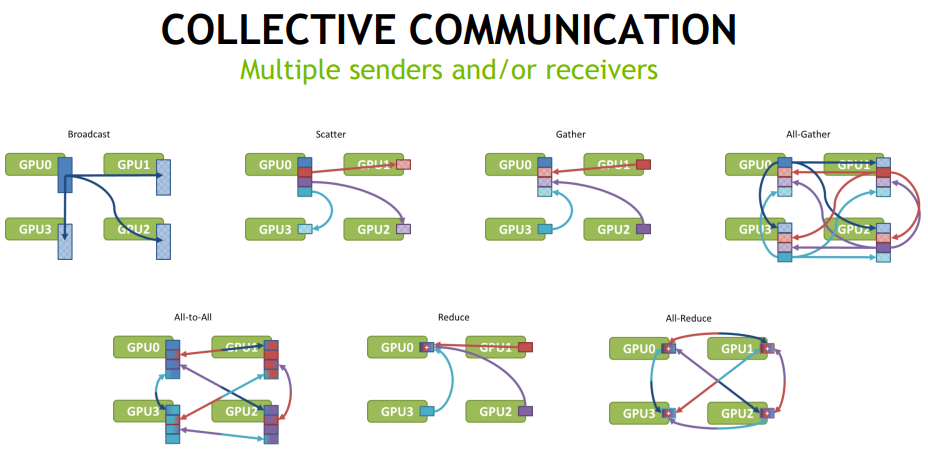
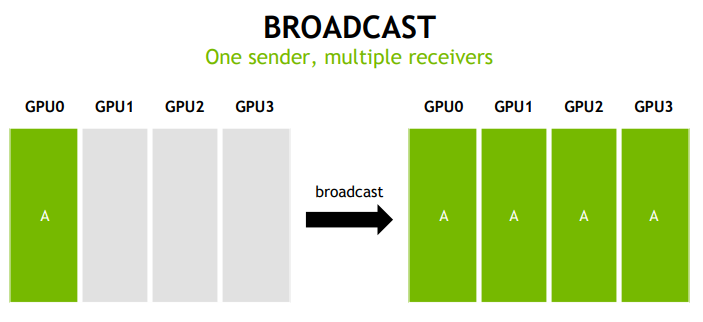
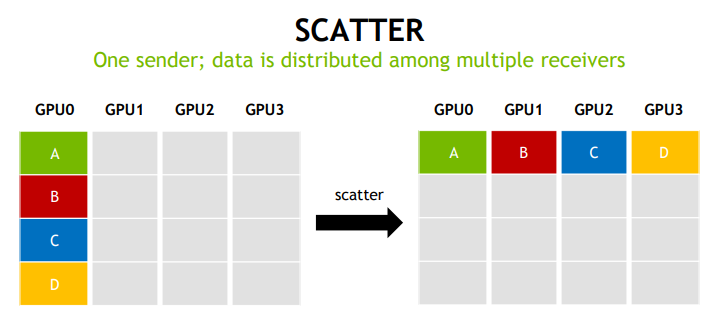
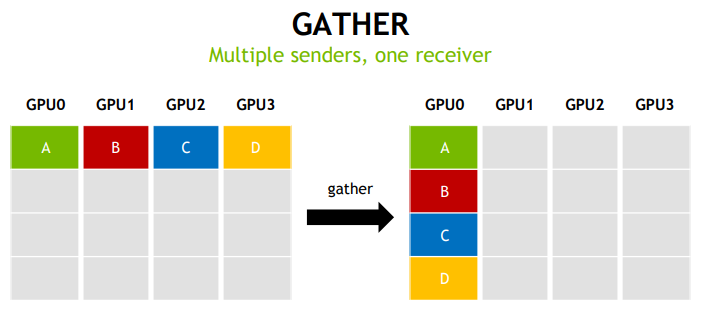
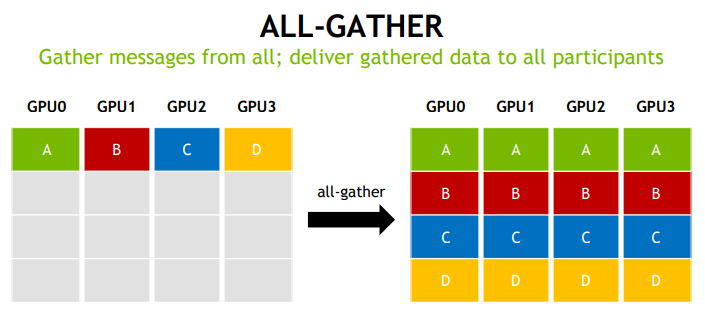
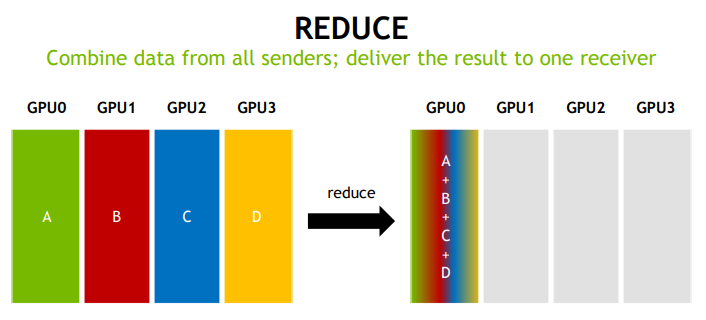
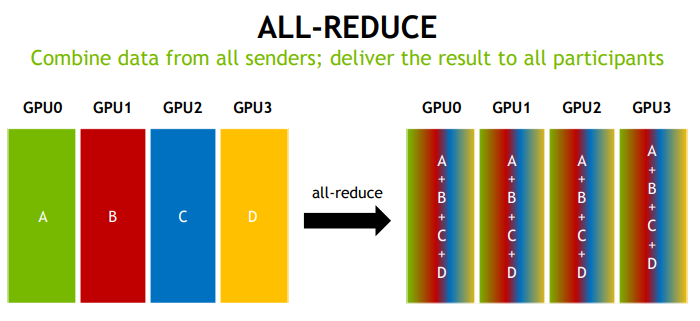

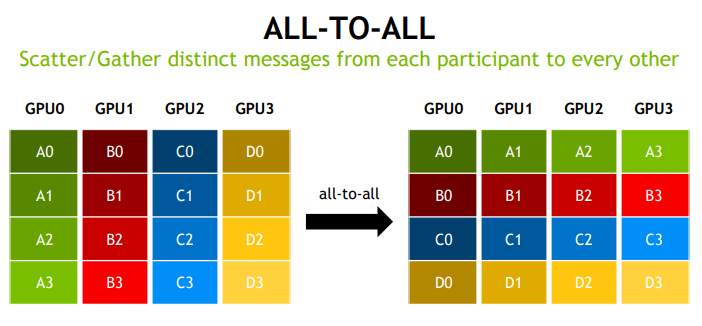
2. NCCL 设计与实现思路
2.1. NCCL 的实现思路
- 模仿 MPI(消息传递接口)的集体通信设计,降低开发者使用门槛。
- 重点优化节点内通信(单节点多 GPU 间的通信),同时为 MPI 提供节点间通信的支持功能,便于跨节点扩展。
2.2. NCCL 的特性(绿色标注为当前可用)

2.3. NCCL 的技术实现
基于CUDA C++ 单核实现,融合以下核心技术:
- GPUDirect P2P 直接访问:实现 GPU 间直接数据传输,避免 CPU 中转,降低延迟。
- 三种原语操作:Copy(数据复制)、Reduce(数据归约)、ReduceAndCopy(归约 + 复制),覆盖集体通信的基础操作。
- GPU 间核内同步:确保多 GPU 在通信过程中的操作时序一致。
- 线程块分配:每个环形方向分配一个 CUDA 线程块,优化并行处理效率。
3. 协议,传输方式,算法细节
3.1 协议
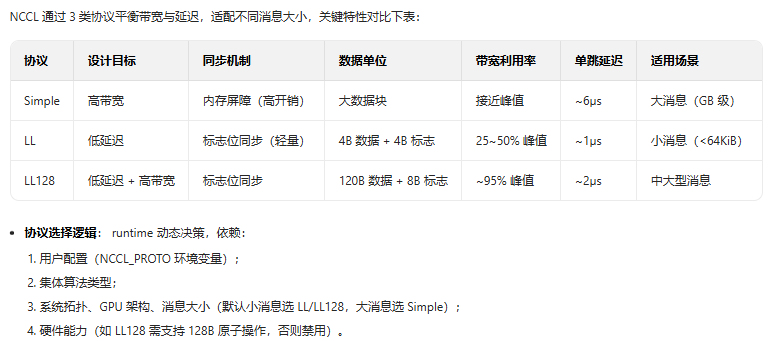
3.2 数据传输方法
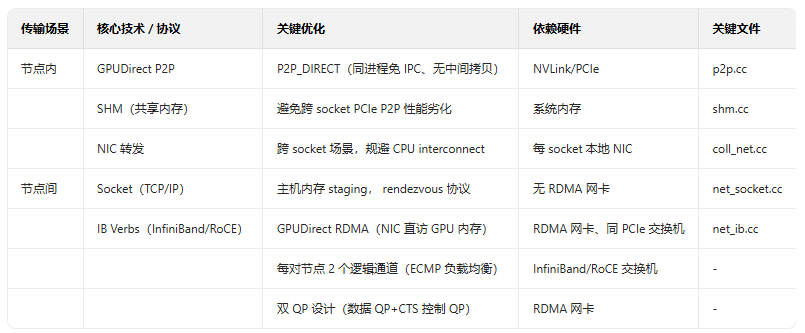
- 节点内传输优先级:NVLink → PCIe P2P → SHM → NIC 转发;
- 节点间关键优化:GPUDirect RDMA 通过nv_peer_mem或 Linux DMA-BUF 注册 GPU 内存,NIC 直接读写 GPU 内存,完全规避主机内存拷贝与 CPU 干预。
3.3 算法分类
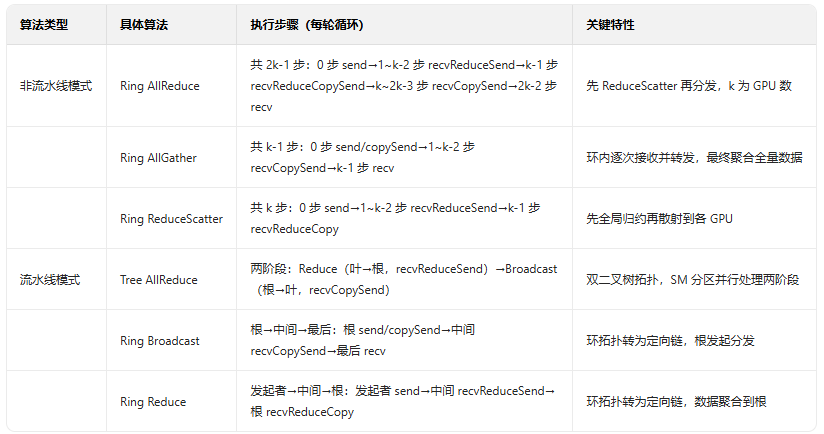
4. 总结
- 文章类的学习还是太浅薄了,可惜没有时间&硬件资源去理解这里面的知识点,

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 17
17 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)