LangChain少量样本示例的提示词模板 FewShotPromptTemplate、FewShotChatMessagePromptTemplate、Example select(示例选择器)
本文介绍了在构建prompt时使用样本示例的几种方法:FewShotPromptTemplate适用于单次回复场景,通过示例格式化输出;FewShotChatMessagePromptTemplate专为聊天对话设计,可转换示例为对话格式;示例选择器则通过向量匹配筛选相关性高的样本。这些方法都能有效提升模型输出的准确性和一致性,其中FewShotChatMessagePromptTemplate特
0 为什么需要样本示例
在构建prompt时,可以通过构建一个少量示例列表去进一步格式化prompt,这是一种简单但强大的指导生成的方式,在某些情况下可以显著提高模型性能。
少量示例提示模板可以由一组示例或一个负责从定义的集合中选择一部分示例的示例选择器构建。
- 前者:使用FewShotPromptTemplate或FewShotChatMessagePromptTemplate
- 后者:使用 Example selectors (示例选择器)
每个示例的结构都是一个 字典 ,其中 键 是输入变量, 值 是输入变量的值。
总结:字面意思,就是给模型上下文加点输入输出的提示,给模型一点规则,让模型知道该怎么输出,这样可以很大程度地提高预期正确输出率
1 FewShotPromptTemplate的使用
1.1 理解
通过将字典格式的数据以及提示词模板作为参数放入FewShotPromptTemplate中来构造FewShotPromptTemplate实例,最后通过suffix拼接提问,input_variables占位suffix中的变量,最后得到示例模板后调用大模型输出,大模型会帮我们补全suffix的提问
1.2 代码示例
该示例实现一个句子提取城市名的功能,通过提供关于北京、广西、湖南的天气提问,得到城市名的字典示例,可以让大模型分析知道应该怎么输出。然后拼接提问“云南什么时候变冷”,大模型会仿照示例,预期会输出提取的城市:云南省
import os
import dotenv
from langchain_core.prompts import PromptTemplate, FewShotPromptTemplate
from langchain_openai import ChatOpenAI
dotenv.load_dotenv()
os.environ["OPENAI_BASE_URL"] = os.getenv("QWEN_BASE_URL")
os.environ["OPENAI_API_KEY"] = os.getenv("QWEN_API_KEY")
# 获取对话模型
chat_model = ChatOpenAI(
model="qwen-plus",
streaming=True
)
# 创建示例集合
examples = [
{"sentence": "北京天气如何?", "city":"北京市"},
{"sentence": "广西7月冷嘛", "city":"广西"},
{"sentence": "湖南下雪了吗", "city":"湖南省"}
]
# 创建PromptTemplate实例
example_prompt = PromptTemplate.from_template(
template="句子:{sentence}, 提取的城市:{city}"
)
# 创建 FewShotPromtTemplate实例
prompt = FewShotPromptTemplate(
examples=examples,
example_prompt=example_prompt,
suffix="句子:{sentence}",
input_variables=["sentence"]
)
# 调用
prompt = prompt.invoke({"sentence": "云南什么时候变冷"})
# 调用模型
response = chat_model.stream(prompt)
# 流式输出
for chunk in response:
print(chunk.content, end='', flush=True)
1.3 运行结果
符合预期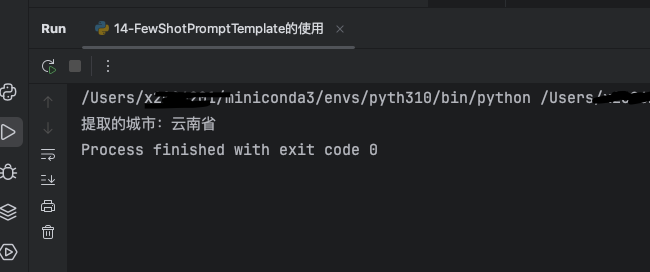
2 FewShotChatMessagePromptTemplate的使用
2.1 理解
除了FewShotPromptTemplate之外,FewShotChatMessagePromptTemplate是专门为
聊天对话场 景 设计的少样本(few-shot)提示模板,它继承自 FewShotPromptTemplate ,但针对聊天消息的格
式进行了优化。特点:
- 自动将示例格式化为聊天消息(HumanMessage / AIMessage等)
- 输出结构化聊天消息(List[BaseMessage])
- 保留对话轮次结构
总结:相比FewShotPromptTemplate,FewShotChatMessagePromptTemplate就是相当于聊天格式的示例模板,回顾FewShotPromptTemplate,这个相当于是给了例子,让大模型模仿示例输出类似的句子,适合单次回复的场景。
而FewShotChatMessagePromptTemplate作用则是以聊天对话的格式参照示例模板进行输出。
作用有二:
- 一是可以将字典格式的示例数据转换为对话类型数据然后作为历史对话记录传递给大模型;
- 二是可以可以作为对话示例,大模型会模型对话示例的输出格式来进行回答输出。
2.2 代码示例
这是一个自定义计算公式的例子,给大模型历史对话输入输出示例,大模型会根据历史对话分析计算方法以及输出格式进行输出。
import os
import dotenv
from langchain_core.prompts import ChatPromptTemplate, FewShotPromptTemplate, FewShotChatMessagePromptTemplate
from langchain_openai import ChatOpenAI
dotenv.load_dotenv()
os.environ["OPENAI_BASE_URL"] = os.getenv("QWEN_BASE_URL")
os.environ["OPENAI_API_KEY"] = os.getenv("QWEN_API_KEY")
# 获取对话模型
chat_model = ChatOpenAI(
model='qwen-plus',
streaming=True
)
# 示例消息格式
exanples = [
{"input":"2 🐦 2", "output": "4"},
{"input":"2 🐦 3", "output": "8"}
]
# 定义示例的消息格式提示词模板
example_prompt = ChatPromptTemplate.from_messages([
("human", "{input}是多少?"),
("ai", "{output}"),
])
# 定义 FewShotChatMessagePromptTemplate对象
few_shot_prompt = FewShotChatMessagePromptTemplate(
examples=exanples,
example_prompt=example_prompt,
)
final_prompt = ChatPromptTemplate.from_messages([
("system", "你是个数学天才,按照历史对话格式输出"),
few_shot_prompt,
("human", "{input}是多少")
])
# 输出格式化后消息
print(final_prompt.format(input="2 🐦 4"))
# 调用模型
response = chat_model.stream(final_prompt.format(input="2 🐦 4"))
# 流式输出
for chunk in response:
print(chunk.content, end='', flush=True)
2.3 运行结果
大模型根据对话示例以及系统提示进行了预期的输出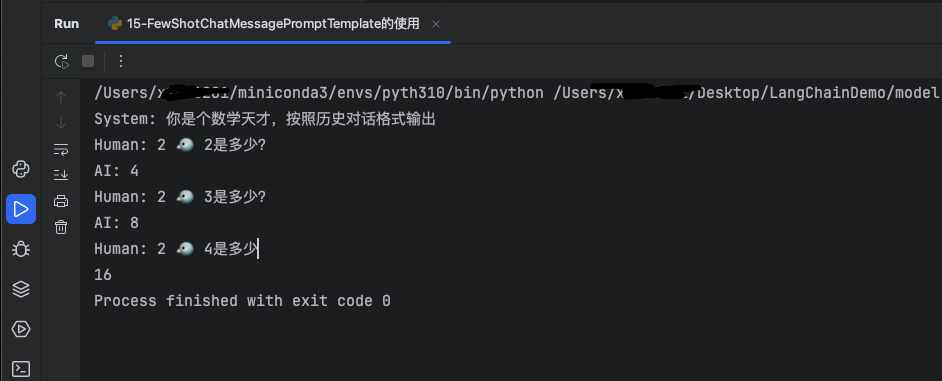
3 Example select(示例选择器)的使用
3.1 理解
-
示例选择器和上述两个提示词模板区别是,提示词模板是将字典数据转换成示例格式,然后存入大模型上下文,
-
而示例选择器是应用向量模型、向量数据库,再根据输入内容来匹配向量数据库中的数据,最后得到部分数据,再将这部分数据放到大模型上下文中。
-
所以最大的区别就是,示例模板是将所有数据存入上下文,示例选择器只提取部分相关数据存入上下文
3.2 代码示例
此处有个坑,就是如果不写这个check_embedding_ctx_length=False会报400
import os
from langchain_community.vectorstores import Chroma
import dotenv
from langchain_core.example_selectors import SemanticSimilarityExampleSelector
from langchain_openai import OpenAIEmbeddings
dotenv.load_dotenv()
os.environ["OPENAI_BASE_URL"] = os.getenv("QWEN_BASE_URL")
os.environ["OPENAI_API_KEY"] = os.getenv("QWEN_API_KEY")
# 获取对话模型
embeddings_model = OpenAIEmbeddings(
model="text-embedding-v2",
check_embedding_ctx_length=False
)
# 定义示例组
examples = [{"question": "地球是什么形状的?", "answers": "地球是一个两极稍扁、赤道略鼓的不规则球体"},
{"question": "水的化学式是什么?", "answers": "水的化学式是 H₂O"},
{"question": "世界上最高的山峰是什么?", "answers": "世界上最高的山峰是珠穆朗玛峰"},
{"question": "一年有几个季节?", "answers": "一年有四个季节,分别是春季、夏季、秋季和冬季"},
{"question": "计算机的基本组成部分有哪些?",
"answers": "计算机的基本组成部分包括硬件系统和软件系统,硬件系统主要有中央处理器、存储器、输入设备和输出设备"}]
# 定义示例选择器
example_selector = SemanticSimilarityExampleSelector.from_examples(
# 示例列表
examples=examples,
# 嵌入模型
embeddings=embeddings_model,
# 向量数据库
vectorstore_cls=Chroma,
# 生成的示例数量
k=1
)
question = "世界上哪座山最高?"
selected_example = example_selector.select_examples({"question": question})
print(f"最相近的示例: {selected_example}")
3.3 运行结果
“世界上哪座山最高?”最近似的匹配是“世界上最高的山峰是什么?”,输出符合预期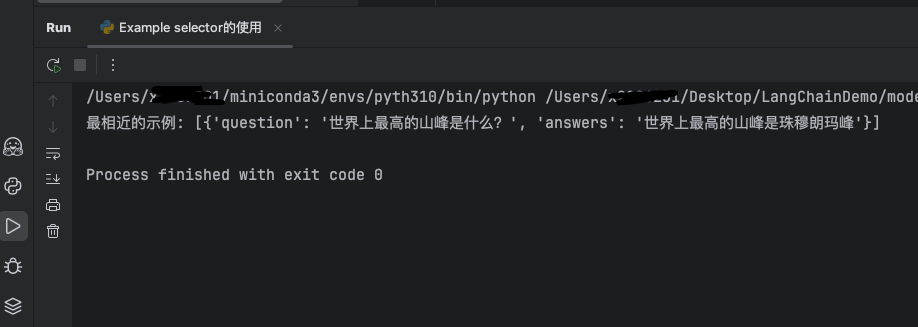

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 40
40 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)