【AI大模型前沿】腾讯ARC开源AudioStory:大语言模型驱动的长篇叙事音频生成技术
AudioStory是由腾讯ARC实验室开发的一款基于大语言模型(LLM)的长篇叙事音频生成模型,旨在通过自然语言描述生成高质量、连贯的长篇音频内容。它将大语言模型与文本到音频系统相结合,采用“解耦桥接机制”和三阶段渐进训练策略,有效解决了长音频生成中的时序一致性与语义连贯性问题。通过AudioStory,用户只需输入简单的自然语言描述,系统即可自动生成长达150秒的连贯叙事音频。
系列篇章💥
目录
前言
在AI音频生成领域,长篇叙事音频的生成一直是一个难题。传统的音频生成技术往往只能处理简单的音效或短音频片段,难以应对复杂的长篇叙事需求。然而,随着腾讯ARC实验室开源的AudioStory项目的出现,为长篇叙事音频的生成提供了一种全新的解决方案。
一、项目概述
AudioStory是由腾讯ARC实验室开发的一款基于大语言模型(LLM)的长篇叙事音频生成模型,旨在通过自然语言描述生成高质量、连贯的长篇音频内容。它将大语言模型与文本到音频系统相结合,采用“解耦桥接机制”和三阶段渐进训练策略,有效解决了长音频生成中的时序一致性与语义连贯性问题。通过AudioStory,用户只需输入简单的自然语言描述,系统即可自动生成长达150秒的连贯叙事音频。
二、核心功能
(一)长篇叙事音频生成
AudioStory的核心功能之一是能够根据文本描述生成长达150秒的连贯叙事音频。这一功能突破了传统音频生成技术的限制,使得生成的音频不仅在时序上保持一致,而且在语义上也高度连贯。
(二)自然语言描述到音频转换
AudioStory支持用户通过自然语言描述生成音频内容,极大地简化了音频创作的过程。用户无需具备专业的音频编辑技能,只需输入简单的文本描述,系统即可自动生成对应的音频故事。
(三)视频自动配音
AudioStory不仅支持文本到音频的转换,还能够为视频自动配音。用户只需上传未添加声音的视频文件,并描述所需音效风格,系统即可智能分析视频内容并生成匹配的背景音乐和音效。
(四)智能音频内容生成
AudioStory在有声内容创作方面也表现出色。无论是有声书、广播剧还是其他长篇音频内容,AudioStory都能够根据文字描述生成富有情感层次的声音作品。
(五)多语言与场景适配
AudioStory支持13种主流语言及24种方言的语音合成,能够满足不同地区和文化背景的用户需求。此外,它还能够根据不同的场景切换音效风格,确保生成的音频与场景高度匹配。
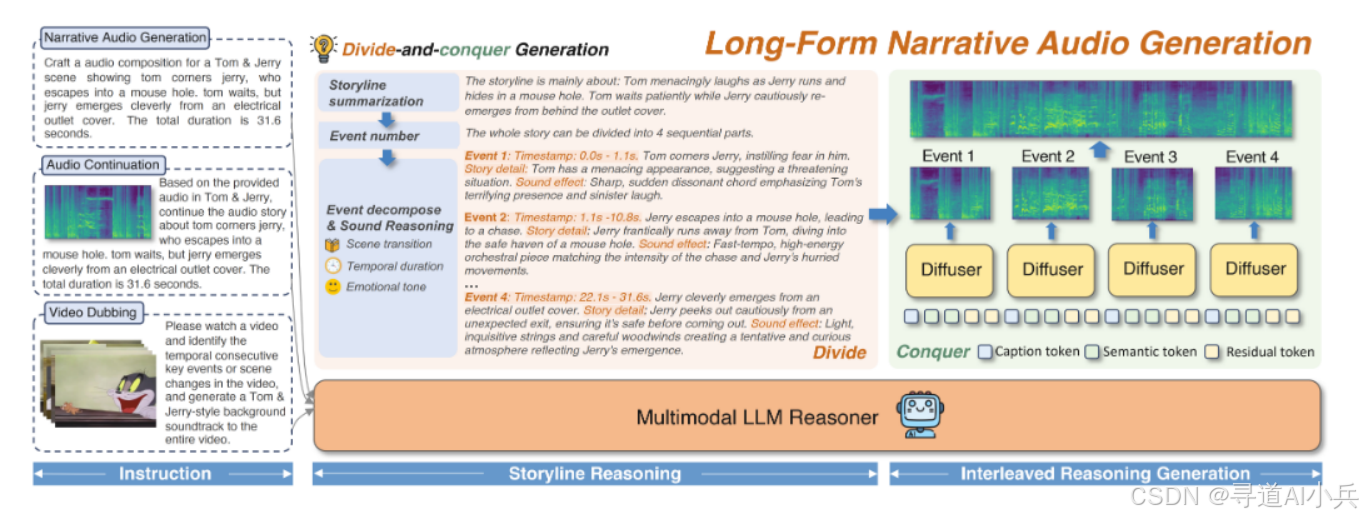
三、技术揭秘
(一)解耦桥接机制
AudioStory的核心技术之一是“解耦桥接机制”。这一机制将大语言模型(LLM)输出的“语义令牌”与音频扩散模型生成的“残差令牌”融合,分别负责叙事逻辑和音效细节。具体来说,LLM负责生成叙事的逻辑框架,确保生成的音频在语义上连贯一致;而音频扩散模型则负责生成具体的音效细节,确保音频在听觉上自然流畅。通过这种解耦的方式,AudioStory能够在保持语义连贯性的同时,生成高质量的音效。
(二)三阶段渐进训练
AudioStory采用了三阶段渐进训练策略,以强化跨事件的连贯性。第一阶段是单音效生成,系统通过大量的单音效数据训练,学习如何生成高质量的音效。第二阶段是子事件协同,系统通过协同训练多个子事件,学习如何在不同事件之间保持连贯性。第三阶段是长叙事整合,系统通过整合多个子事件,生成完整的长篇叙事音频。通过这种三阶段的训练策略,AudioStory能够有效解决长音频生成中的时序一致性与语义连贯性问题。
(三)动态视觉路由
在视频配音场景中,AudioStory采用了动态视觉路由技术。这一技术能够智能识别视频中的关键区域,对这些区域对应的音频细节保留高分辨率处理,而背景区域则适当降采样。
(四)指令遵循与语义匹配
AudioStory在指令遵循和语义匹配方面表现出色。在AudioStory-10K基准数据集测试中,指令遵循率比基线模型高17.85%,语义匹配度提升23%。这一成果得益于其先进的指令解析和语义理解能力。系统能够准确理解用户的输入指令,并生成与指令高度匹配的音频内容。
四、应用场景
(一)视频制作
在视频制作领域,AudioStory的应用前景广阔。无论是电影、电视剧、广告还是短视频,都需要高质量的音频来增强视觉内容的表现力。通过AudioStory,视频制作者可以轻松地为视频添加背景音乐、音效和旁白,无需花费大量时间和精力进行音频编辑。
例如,在一个广告视频中,用户可以输入“充满活力的背景音乐,带有节奏感的音效,突出产品的特点”,AudioStory能够生成一段与视频内容完美匹配的音频,提升广告的吸引力。
(二)有声内容创作
对于有声书、广播剧、播客等有声内容创作,AudioStory提供了一个强大的工具。创作者可以通过输入文本描述,快速生成富有情感层次的声音作品,无需聘请专业的配音演员和音频编辑。
例如,在一个有声书项目中,用户可以输入“温暖的女声,带有情感的朗读,背景音乐轻柔而温馨”,AudioStory能够生成一段高质量的有声书音频,为听众带来沉浸式的阅读体验。
(三)游戏音效制作
在游戏开发中,音效是增强玩家沉浸感的重要元素。AudioStory能够为游戏生成符合场景的音效,根据游戏的剧情和环境动态调整音效风格。
例如,在一个恐怖游戏中,用户可以输入“阴森的背景音乐,带有恐怖音效,如脚步声、开门声、风声等”,AudioStory能够生成一段紧张而恐怖的音效,让玩家仿佛置身于游戏世界之中。
(四)教育领域
在教育领域,AudioStory也具有重要的应用价值。通过为教育视频或音频内容提供配音,AudioStory可以提高教学效果,增强学生的学习兴趣。
例如,在一个科学实验视频中,用户可以输入“清晰的旁白,带有实验音效,如仪器操作声、化学反应声等”,AudioStory能够生成一段高质量的音频,帮助学生更好地理解实验过程。
五、快速使用
(一)环境配置
AudioStory支持Python 3.10及以上版本,推荐使用Anaconda进行环境管理。此外,需要安装PyTorch 2.1.0及以上版本,并确保有NVIDIA GPU及CUDA环境支持。
- 克隆项目仓库:
git clone https://github.com/TencentARC/AudioStory.git
cd AudioStory
- 创建并激活Python环境:
conda create -n audiostory python=3.10 -y
conda activate audiostory
- 安装项目依赖:
bash install_audiostory.sh
(二)输入指令
用户可以通过输入自然语言描述或上传视频文件来使用AudioStory。以下是两种主要的输入方式:
- 文本描述输入:
用户可以输入一段详细的自然语言描述,明确指定音频的时长、语言、风格等参数。例如:
"Develop a comprehensive audio that fully represents jake shimabukuro performs a complex ukulele piece in a studio, receives applause, and discusses his career in an interview. The total duration is 49.9 seconds."
该指令描述了一个场景,包括在录音室中演奏复杂的尤克里里曲目、获得掌声以及接受采访等环节,总时长为49.9秒。
- 视频文件输入:
用户可以上传未添加声音的视频文件,并描述所需音效风格。例如,用户可以上传一个动画视频,并输入描述“Tom & Jerry style”,系统将根据视频内容和指定风格生成匹配的音频。
(三)生成与调优
- 生成音频:
使用以下命令进行音频生成,需要指定模型路径、引导系数、保存文件夹名称和总时长等参数:
python evaluate/inference.py --model_path /path/to/ckpt --guidance 4.0 --save_folder_name audiostory --total_duration 50
其中,--model_path指定模型检查点路径,--guidance为引导系数(可根据需要调整),--save_folder_name指定保存生成音频的文件夹名称,--total_duration指定生成音频的总时长(单位为秒)。
- 调优音频:
用户可以通过调整输入指令中的参数或使用SSML标记语言对生成的音频进行微调。例如,调整音频的语速、音调、音量等参数,以达到最佳效果。此外,系统支持迭代优化生成结果,用户可以多次调整输入指令,逐步优化生成的音频内容。
六、结语
AudioStory的开源,为音频创作领域带来了新的可能性。它不仅降低了专业音频制作的技术门槛,还极大地扩展了音频技术的应用场景。通过结合大语言模型和先进的音频生成技术,AudioStory为长篇叙事音频的生成提供了一种全新的解决方案。随着模型的不断迭代和优化,我们期待AudioStory在未来能够为更多领域带来创新和变革。
- 项目地址:https://github.com/TencentARC/AudioStory
- arxiv论文:https://arxiv.org/pdf/2508.20088

🎯🔖更多专栏系列文章:AI大模型提示工程完全指南、AI大模型探索之路(零基础入门)、AI大模型预训练微调进阶、AI大模型开源精选实践、AI大模型RAG应用探索实践🔥🔥🔥 其他专栏可以查看博客主页📑
😎 作者介绍:资深程序老猿,从业10年+、互联网系统架构师,目前专注于AIGC的探索(CSDN博客之星|AIGC领域优质创作者)
📖专属社群:欢迎关注【小兵的AI视界】公众号或扫描下方👇二维码,回复‘入群’ 即刻上车,获取邀请链接。
💘领取三大专属福利:1️⃣免费赠送AI+编程📚500本,2️⃣AI技术教程副业资料1套,3️⃣DeepSeek资料教程1套🔥(限前500人)
如果文章内容对您有所触动,别忘了点赞、⭐关注,收藏!加入我们,一起携手同行AI的探索之旅,开启智能时代的大门!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 24
24 0
0- 0



 已为社区贡献24条内容
已为社区贡献24条内容

所有评论(0)