【Mysql优化】性能分析explain
【Mysql优化】性能分析explain(4)性能分析(1)mysql常见瓶颈(2)Explain(4)性能分析(1)mysql常见瓶颈(1)CPU:sql中对大量数据进行比较、关联、排序、分组。最大的压力在于比较(2)IO:实例内存满足不了缓存数据或者排序等需要,导致产生大量物理IO。查询执行效率低,扫描过多数据行(3)锁:不适宜的锁的设置,导致线程阻塞,性能下降。死锁就是线程之间交叉调用资源,
【Mysql优化】性能分析explain
- 【一】mysql常见瓶颈
- 【二】Explain简介
- 【三】EXPLAIN 结果参数详解
-
- 【1】id - 查询标识符
- 【2】select_type - 查询类型
- 【3】table - 表名
- 【4】partitions - 分区信息
- 【5】type - 连接类型(重要)
- 【6】possible_keys - 可能使用的索引
- 【7】key - 实际使用的索引
- 【8】key_len - 索引使用长度
- 【9】ref - 索引比较值
- 【10】rows - 预估扫描行数
- 【11】filtered - 过滤比例
- 【12】Extra - 额外信息(重要)
- 【四】EXPLAIN 输出格式
- 【五】实际案例分析
- 【六】性能优化指南
- 【七】高级分析技巧
- 【八】常见问题排查
- 【九】实际工作流程
- 【十】总结
【一】mysql常见瓶颈
(1)CPU:sql中对大量数据进行比较、关联、排序、分组。最大的压力在于比较
(2)IO:实例内存满足不了缓存数据或者排序等需要,导致产生大量物理IO。查询执行效率低,扫描过多数据行
(3)锁:不适宜的锁的设置,导致线程阻塞,性能下降。死锁就是线程之间交叉调用资源,导致死锁,程序卡住
(4)服务器硬件的性能瓶颈:top,free,iostat和vmstat来查看系统的性能状态
【二】Explain简介
(1)是什么(查看执行计划)
使用Explain关键字可以模拟化器执行sql查询语句,从而知道mysql是如何处理你的sql语句。分析你的查询语句或是表结构的性能瓶颈
(2)能干嘛
表的读取顺序
哪些索引可以使用
数据读取操作的操作类型
哪些索引被实际使用
表之间的引用
每张表有多少行被优化器查询
(3)怎么用
Explain+sql语句:explain select * from t_emp;
执行计划包含的信息:
(4)建表脚本(用于Explain练习)
CREATE TABLE t1(id INT(10) AUTO_INCREMENT,content VARCHAR(100) NULL , PRIMARY KEY (id));
CREATE TABLE t2(id INT(10) AUTO_INCREMENT,content VARCHAR(100) NULL , PRIMARY KEY (id));
CREATE TABLE t3(id INT(10) AUTO_INCREMENT,content VARCHAR(100) NULL , PRIMARY KEY (id));
CREATE TABLE t4(id INT(10) AUTO_INCREMENT,content VARCHAR(100) NULL , PRIMARY KEY (id));
INSERT INTO t1(content) VALUES(CONCAT('t1_',FLOOR(1+RAND()*1000)));
INSERT INTO t2(content) VALUES(CONCAT('t2_',FLOOR(1+RAND()*1000)));
INSERT INTO t3(content) VALUES(CONCAT('t3_',FLOOR(1+RAND()*1000)));
INSERT INTO t4(content) VALUES(CONCAT('t4_',FLOOR(1+RAND()*1000)));
(5)名字段解释-id
- 解释:select查询的序列号,包含一组数字,表示查询中执行select子句或者操作表的顺序
- 三种情况;
- id相同,执行顺序使由上至下
- id不同,如果是子查询,id的序号会递增,id值越大优先级越高,越先被执行
- id相同不同,同时存在
(5)select_type
查询的类型,主要是用于区别普通查询、联合查询、子查询等的复杂查询
(6)table
显示这一行数据是关于哪张表的
(7)type
显示查询使用了何种类型,从最好到最差依次是:system>const>eq_ref>range>index>ALL
一般来说,得保证查询至少达到range级别,最好能达到ref。
(8)possible_keys
显示可能应用在这张表中的索引,一个或多个,查询涉及到的字段上如果存在索引,则该索引将被列出,但不一定被查询实际使用
(9)key
实际使用的索引,如果是null,就没有使用索引。如果查询中使用了覆盖索引,则该索引和查询的select字段重叠
(10)key_len
表示索引中使用的字节数,可以通过该列计算查询中使用的索引的长度,可以帮助你检查是否充分的利用上了索引
(11)ref
显示索引的哪一列被使用了,如果可能的话,是一个常数。哪些列或者常量被用于查找索引列上的值
(12)rows
显示mysql认为它执行查询时必须检查的行数,越少越好
(13)Extra
包含不适合在其他列二中显示但是十分重要的额外信息
(14)练习题
【三】EXPLAIN 结果参数详解
【1】id - 查询标识符
含义:查询中每个SELECT子句的唯一标识符
原理:数字越大执行优先级越高,相同id按顺序执行
-- 示例
EXPLAIN
SELECT t1.* FROM table1 t1
WHERE t1.id IN (SELECT t2.table1_id FROM table2 t2);

【2】select_type - 查询类型
常见类型:
SIMPLE:简单SELECT(不包含子查询或UNION)
PRIMARY:最外层的查询
SUBQUERY:子查询中的第一个SELECT
DERIVED:派生表(FROM子句中的子查询)
UNION:UNION中的第二个或后续的SELECT
UNION RESULT:UNION的结果
-- 各种select_type示例
EXPLAIN
SELECT * FROM users WHERE id IN (
SELECT user_id FROM orders WHERE amount > 100
UNION
SELECT user_id FROM payments WHERE status = 'completed'
);
【3】table - 表名
含义:正在访问的表名
特殊值:
<derivedN>:派生表(N是id值)
<unionM,N>:UNION结果(M,N是参与UNION的id值)
【4】partitions - 分区信息
含义:查询匹配的分区
-- 分区表示例
CREATE TABLE sales (
id INT,
sale_date DATE,
amount DECIMAL(10,2)
) PARTITION BY RANGE (YEAR(sale_date)) (
PARTITION p0 VALUES LESS THAN (2020),
PARTITION p1 VALUES LESS THAN (2021),
PARTITION p2 VALUES LESS THAN (2022)
);
EXPLAIN SELECT * FROM sales WHERE sale_date BETWEEN '2021-01-01' AND '2021-12-31';
【5】type - 连接类型(重要)
性能从优到劣排序:
(1)system
含义:表只有一行记录
条件:系统表或衍生表只有一行
-- 很少见,通常用于系统表
EXPLAIN SELECT * FROM (SELECT 1 as id) AS t1;
(2)const
含义:通过主键或唯一索引一次就找到
条件:WHERE条件使用主键或唯一索引的等值比较
-- 创建测试表
CREATE TABLE users (
id INT PRIMARY KEY,
name VARCHAR(50),
email VARCHAR(100) UNIQUE
);
EXPLAIN SELECT * FROM users WHERE id = 1;
-- type: const
(3)eq_ref
含义:主键或唯一索引关联查询
条件:JOIN使用主键或唯一索引的全部部分
CREATE TABLE orders (
id INT PRIMARY KEY,
user_id INT,
amount DECIMAL(10,2),
FOREIGN KEY (user_id) REFERENCES users(id)
);
EXPLAIN
SELECT * FROM users u
JOIN orders o ON u.id = o.user_id
WHERE u.id = 1;
-- type: eq_ref (对于orders表)
(4)ref
含义:非唯一索引等值查询
条件:使用普通索引的等值比较
-- 添加普通索引
CREATE INDEX idx_name ON users(name);
EXPLAIN SELECT * FROM users WHERE name = 'John';
-- type: ref
(5)ref_or_null
含义:类似ref,但包含NULL值查询
EXPLAIN SELECT * FROM users WHERE name = 'John' OR name IS NULL;
-- type: ref_or_null
(6)range
含义:索引范围扫描
条件:BETWEEN、IN、>、< 等范围查询
EXPLAIN SELECT * FROM users WHERE id BETWEEN 1 AND 100;
-- type: range
(7)index
含义:全索引扫描
条件:只需要从索引中获取数据
-- 覆盖索引查询
EXPLAIN SELECT id FROM users;
-- type: index (使用主键索引)
(8)ALL
含义:全表扫描
条件:没有使用索引或需要扫描全部数据
EXPLAIN SELECT * FROM users WHERE email LIKE '%@gmail.com';
-- type: ALL (通常需要优化)
【6】possible_keys - 可能使用的索引
含义:查询可能使用的索引列表
注意:实际可能不使用这些索引
【7】key - 实际使用的索引
含义:查询实际使用的索引
注意:可能为NULL(未使用索引)
【8】key_len - 索引使用长度
含义:使用的索引字节数
计算规则:
1-字符集:utf8=3字节,utf8mb4=4字节
2-允许NULL:+1字节
3-变长字段:+2字节
-- 测试key_len计算
CREATE TABLE test_keylen (
id INT, -- 4字节
name VARCHAR(20) NULL, -- 20 * 3 + 1(NULL) + 2(变长) = 63字节
age TINYINT NOT NULL -- 1字节
);
CREATE INDEX idx_test ON test_keylen(name, age);
EXPLAIN SELECT * FROM test_keylen WHERE name = 'test' AND age = 25;
-- key_len: 64 (name:63 + age:1)
【9】ref - 索引比较值
含义:显示索引的哪一列被使用
常见值:
const:常量值
func:函数结果
NULL:未使用或表达式
【10】rows - 预估扫描行数
含义:MySQL估计需要读取的行数
注意:基于统计信息,可能不准确
【11】filtered - 过滤比例
含义:存储引擎返回的数据在server层过滤后剩余的比例
计算:filtered = (过滤后行数 / 扫描行数) * 100%
【12】Extra - 额外信息(重要)
(1)Using index
含义:使用覆盖索引,无需回表
-- 覆盖索引示例
CREATE INDEX idx_covering ON users(name, email);
EXPLAIN SELECT name, email FROM users WHERE name = 'John';
-- Extra: Using index
(2)Using where
含义:在存储引擎检索行后进行过滤
EXPLAIN SELECT * FROM users WHERE name = 'John' AND age > 25;
-- 如果只有name索引,Extra: Using where
(3)Using temporary
含义:使用临时表处理查询
优化建议:通常需要优化,磁盘临时表的性能通常较差,应尽量避免。
-- 可能产生临时表的查询
EXPLAIN SELECT DISTINCT name FROM users;
-- 或者 GROUP BY、ORDER BY 与WHERE中的索引不匹配时
Using temporary是 MySQL EXPLAIN 中一个重要的性能警告指标,表示查询需要创建临时表来处理结果。下面详细说明其出现条件、原理、优化方法和实际案例。
1-Using temporary 的基本概念
(1)什么是临时表
临时表是 MySQL 在执行查询过程中创建的中间表,用于存储中间结果。这些表在查询结束后自动销毁。
(2)Using temporary 的含义
当 EXPLAIN 的 Extra 列显示 Using temporary时,表示 MySQL 必须创建临时表来完成查询。
2-出现 Using temporary 的主要场景
(1)GROUP BY 和 ORDER BY 组合使用
-- 场景1: GROUP BY 和 ORDER BY 使用不同的列
EXPLAIN
SELECT department, COUNT(*) as emp_count
FROM employees
GROUP BY department
ORDER BY emp_count DESC;
-- Extra: Using temporary; Using filesort
-- 场景2: GROUP BY 和 ORDER BY 顺序不一致
EXPLAIN
SELECT department, salary_level, COUNT(*)
FROM employees
GROUP BY department, salary_level
ORDER BY salary_level, department;
-- Extra: Using temporary; Using filesort
(2)DISTINCT 与 ORDER BY 组合
-- DISTINCT 和 ORDER BY 使用不同列
EXPLAIN
SELECT DISTINCT department
FROM employees
ORDER BY hire_date DESC;
-- Extra: Using temporary; Using filesort
(3)UNION 查询
-- UNION 查询需要临时表去重
EXPLAIN
SELECT name FROM current_employees
UNION
SELECT name FROM former_employees;
-- Extra: Using temporary
(4)子查询和派生表
-- 派生表需要物化
EXPLAIN
SELECT * FROM (
SELECT department, AVG(salary) as avg_sal
FROM employees
GROUP BY department
) AS dept_stats
WHERE avg_sal > 5000;
-- Extra: Using temporary(对于派生表)
(5)多表 JOIN 与排序
-- 多表JOIN后排序
EXPLAIN
SELECT e.name, d.department_name, p.project_name
FROM employees e
JOIN departments d ON e.dept_id = d.id
JOIN projects p ON e.project_id = p.id
ORDER BY e.salary DESC;
-- 如果排序字段没有合适索引,可能使用临时表
3-Using temporary 的原理分析
(1)临时表的创建时机
-- 查询执行流程示例
1. 扫描 employees 表
2. 创建临时表存储中间结果
3. 对临时表进行排序或分组操作
4. 返回最终结果
(2)临时表的存储位置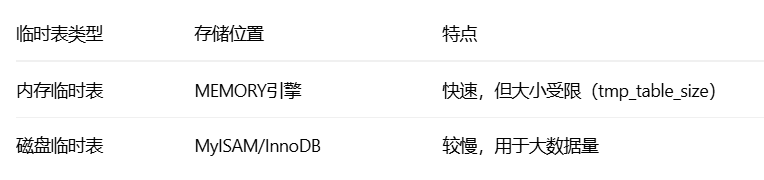
(3)临时表选择的阈值
-- 查看临时表相关配置
SHOW VARIABLES LIKE 'tmp_table_size'; -- 默认16MB
SHOW VARIABLES LIKE 'max_heap_table_size'; -- 默认16MB
-- 当中间结果超过这些大小时,使用磁盘临时表
4-详细案例分析
(1)案例1:GROUP BY + ORDER BY 优化
-- 原始查询(产生Using temporary)
EXPLAIN
SELECT department, COUNT(*) as emp_count, AVG(salary) as avg_salary
FROM employees
WHERE hire_date > '2020-01-01'
GROUP BY department
ORDER BY emp_count DESC;
-- Extra: Using temporary; Using filesort
优化方案1:使用覆盖索引
-- 创建合适的索引
CREATE INDEX idx_dept_hire_salary ON employees(department, hire_date, salary);
-- 优化后查询
EXPLAIN
SELECT department, COUNT(*) as emp_count, AVG(salary) as avg_salary
FROM employees
WHERE hire_date > '2020-01-01'
GROUP BY department
ORDER BY department; -- 使用GROUP BY的字段排序
-- Extra: Using index(可能消除临时表)
优化方案2:重写查询逻辑
-- 使用窗口函数(MySQL 8.0+)
EXPLAIN
WITH dept_stats AS (
SELECT department,
COUNT(*) as emp_count,
AVG(salary) as avg_salary,
ROW_NUMBER() OVER (ORDER BY COUNT(*) DESC) as rn
FROM employees
WHERE hire_date > '2020-01-01'
GROUP BY department
)
SELECT department, emp_count, avg_salary
FROM dept_stats
ORDER BY rn;
(2)案例2:DISTINCT + ORDER BY 优化
-- 原始查询
EXPLAIN
SELECT DISTINCT department, location
FROM employees
ORDER BY hire_date DESC;
-- Extra: Using temporary; Using filesort
优化方案
-- 方案1:使用GROUP BY替代DISTINCT
EXPLAIN
SELECT department, location
FROM employees
GROUP BY department, location
ORDER BY MAX(hire_date) DESC;
-- 可能减少临时表使用
-- 方案2:创建合适索引
CREATE INDEX idx_dept_loc_hire ON employees(department, location, hire_date);
EXPLAIN
SELECT DISTINCT department, location
FROM employees
ORDER BY department, location; -- 使用DISTINCT字段排序
(3)案例3:UNION 查询优化
-- 原始UNION查询
EXPLAIN
SELECT id, name FROM current_employees
UNION
SELECT id, name FROM former_employees;
-- Extra: Using temporary
优化方案
-- 方案1:使用UNION ALL(如果不需要去重)
EXPLAIN
SELECT id, name FROM current_employees
UNION ALL
SELECT id, name FROM former_employees;
-- 可能消除临时表
-- 方案2:分别查询后在应用层合并
-- 应用程序中分别执行两个查询,然后合并结果
5-使用索引避免 Using temporary
(1)为GROUP BY创建合适索引
-- 创建测试表
CREATE TABLE sales (
id INT PRIMARY KEY,
sale_date DATE,
product_id INT,
quantity INT,
amount DECIMAL(10,2),
region VARCHAR(50)
);
-- 问题查询
EXPLAIN
SELECT product_id, region, SUM(amount) as total_sales
FROM sales
WHERE sale_date BETWEEN '2023-01-01' AND '2023-12-31'
GROUP BY product_id, region
ORDER BY total_sales DESC;
-- Extra: Using temporary; Using filesort
-- 创建优化索引
CREATE INDEX idx_sales_optimized ON sales(sale_date, product_id, region, amount);
-- 优化后查询
EXPLAIN
SELECT product_id, region, SUM(amount) as total_sales
FROM sales
WHERE sale_date BETWEEN '2023-01-01' AND '2023-12-31'
GROUP BY product_id, region
ORDER BY product_id, region; -- 使用GROUP BY字段排序
-- 可能消除Using temporary
(2)覆盖索引优化
-- 创建覆盖索引
CREATE INDEX idx_covering ON employees(department, salary, hire_date);
-- 使用覆盖索引的查询
EXPLAIN
SELECT department, AVG(salary)
FROM employees
WHERE hire_date > '2020-01-01'
GROUP BY department;
-- Extra: Using index(可能消除临时表)
6-总结
性能分析检查清单
-- 检查查询是否产生Using temporary
EXPLAIN YOUR_QUERY;
-- 分析步骤:
-- 1. 确认是否必须使用临时表
-- 2. 检查GROUP BY/ORDER BY字段是否有索引
-- 3. 评估是否可以使用覆盖索引
-- 4. 考虑查询重写可能性
-- 5. 检查临时表大小配置

(4)Using filesort
含义:需要额外的排序操作
优化建议:为ORDER BY子句创建合适索引
-- 文件排序示例
EXPLAIN SELECT * FROM users ORDER BY name;
-- 如果name没有索引,Extra: Using filesort
1-Using filesort 的基本概念
(1)什么是 filesort
filesort 是 MySQL 在无法使用索引进行排序时,对结果集进行排序的算法。它可能在内存或磁盘上完成排序操作。
(2)Using filesort 的含义
当 EXPLAIN 的 Extra 列显示 Using filesort时,表示 MySQL 必须进行额外的排序操作,这通常会影响查询性能。
2-出现 Using filesort 的主要场景
(1)ORDER BY 与索引不匹配
-- 场景1: ORDER BY 字段没有索引
CREATE TABLE employees (
id INT PRIMARY KEY,
name VARCHAR(50),
department VARCHAR(50),
salary DECIMAL(10,2),
hire_date DATE
);
EXPLAIN
SELECT * FROM employees ORDER BY name;
-- Extra: Using filesort
-- 场景2: ORDER BY 顺序与索引顺序不一致
CREATE INDEX idx_dept_salary ON employees(department, salary);
EXPLAIN
SELECT * FROM employees ORDER BY salary, department;
-- Extra: Using filesort(顺序与索引相反)
(2)多列排序与复合索引不匹配
-- 复合索引顺序: (department, salary)
CREATE INDEX idx_dept_salary ON employees(department, salary);
-- 问题查询1: 缺少前导列
EXPLAIN
SELECT * FROM employees ORDER BY salary;
-- Extra: Using filesort
-- 问题查询2: 顺序不一致
EXPLAIN
SELECT * FROM employees ORDER BY salary, department;
-- Extra: Using filesort
-- 正确使用索引的查询
EXPLAIN
SELECT * FROM employees ORDER BY department, salary;
-- 可能不会出现 Using filesort
(3)GROUP BY 与 ORDER BY 组合
-- GROUP BY 和 ORDER BY 使用不同字段
EXPLAIN
SELECT department, COUNT(*) as emp_count
FROM employees
GROUP BY department
ORDER BY emp_count DESC;
-- Extra: Using temporary; Using filesort
-- GROUP BY 和 ORDER BY 顺序不一致
EXPLAIN
SELECT department, salary_level, COUNT(*)
FROM employees
GROUP BY department, salary_level
ORDER BY salary_level, department;
-- Extra: Using temporary; Using filesort
(4)JOIN 查询中的排序
-- 多表JOIN后排序
CREATE TABLE departments (
id INT PRIMARY KEY,
name VARCHAR(50)
);
EXPLAIN
SELECT e.name, d.name as dept_name
FROM employees e
JOIN departments d ON e.department_id = d.id
ORDER BY e.salary DESC;
-- 如果salary没有索引,Extra: Using filesort
(5)DISTINCT 与排序组合
-- DISTINCT 和 ORDER BY 使用不同字段
EXPLAIN
SELECT DISTINCT department
FROM employees
ORDER BY hire_date DESC;
-- Extra: Using temporary; Using filesort
3-Using filesort 的原理分析
(1)filesort 算法流程
-- filesort 执行步骤:
1. 扫描表或索引获取记录
2. 为每条记录创建排序键(sort key)
3. 在内存或磁盘上进行快速排序
4. 按排序顺序检索数据
(2)单路排序(Single-Pass) vs 双路排序(Two-Pass)
-- 查看排序算法相关配置
SHOW VARIABLES LIKE 'max_length_for_sort_data'; -- 排序数据最大长度
SHOW VARIABLES LIKE 'sort_buffer_size'; -- 排序缓冲区大小
-- 单路排序(优化模式):
-- 1. 一次性取出所有需要的字段
-- 2. 在sort buffer中排序
-- 3. 直接返回结果
-- 双路排序(传统模式):
-- 1. 只取出排序键和行指针
-- 2. 在sort buffer中排序
-- 3. 根据行指针回表取数据
(3)排序缓冲区使用
-- 监控排序操作
SHOW STATUS LIKE 'Sort%';
-- 关键指标:
-- Sort_merge_passes: 合并次数(越多性能越差)
-- Sort_range: 范围排序次数
-- Sort_rows: 排序行数
-- Sort_scan: 全表扫描排序次数
4-详细案例分析
(1)案例1:单表排序优化
-- 原始查询(产生Using filesort)
EXPLAIN
SELECT id, name, salary, hire_date
FROM employees
WHERE department = 'IT'
ORDER BY hire_date DESC
LIMIT 10;
-- Extra: Using filesort
优化方案1:创建合适索引
-- 创建覆盖排序和过滤的索引
CREATE INDEX idx_dept_hire ON employees(department, hire_date DESC);
-- 优化后查询
EXPLAIN
SELECT id, name, salary, hire_date
FROM employees
WHERE department = 'IT'
ORDER BY hire_date DESC
LIMIT 10;
-- 可能消除 Using filesort,使用索引排序
优化方案2:使用覆盖索引
-- 创建包含所有查询字段的覆盖索引
CREATE INDEX idx_covering ON employees(department, hire_date DESC, name, salary);
EXPLAIN
SELECT name, salary, hire_date
FROM employees
WHERE department = 'IT'
ORDER BY hire_date DESC;
-- Extra: Using index(覆盖索引,无需filesort)
(2)案例2:多列排序优化
-- 多列排序问题
EXPLAIN
SELECT * FROM employees
WHERE salary > 5000
ORDER BY department ASC, hire_date DESC;
-- Extra: Using filesort(混合排序方向)
优化方案
-- 方案1:创建支持混合排序的索引(MySQL 8.0+)
CREATE INDEX idx_dept_asc_hire_desc ON employees(department ASC, hire_date DESC);
-- 方案2:调整查询逻辑
EXPLAIN
SELECT * FROM employees
WHERE salary > 5000
ORDER BY department ASC, hire_date ASC; -- 统一排序方向
-- 可能使用索引排序
-- 方案3:分阶段处理
CREATE TEMPORARY TABLE temp_results AS
SELECT * FROM employees WHERE salary > 5000;
EXPLAIN SELECT * FROM temp_results ORDER BY department, hire_date DESC;
(3)案例3:JOIN查询排序优化
-- 多表JOIN排序
EXPLAIN
SELECT e.name, e.salary, d.name as dept_name
FROM employees e
JOIN departments d ON e.department_id = d.id
JOIN projects p ON e.project_id = p.id
WHERE p.status = 'active'
ORDER BY e.salary DESC, e.hire_date ASC;
-- Extra: Using filesort
优化方案
-- 方案1:为驱动表创建排序索引
CREATE INDEX idx_salary_hire ON employees(salary DESC, hire_date ASC);
-- 方案2:使用子查询预先排序
EXPLAIN
SELECT e.name, e.salary, d.name as dept_name
FROM (
SELECT id, name, salary, department_id
FROM employees
ORDER BY salary DESC, hire_date ASC
) e
JOIN departments d ON e.department_id = d.id
JOIN projects p ON e.project_id = p.id
WHERE p.status = 'active';
5-使用索引避免 Using filesort
(1)索引排序规则
-- 索引排序基本原则:
-- 1. ORDER BY 字段顺序必须与索引顺序一致
-- 2. 排序方向必须一致(或MySQL 8.0+支持混合方向)
-- 3. 不能跳过索引中的列
-- 正确示例:
CREATE INDEX idx_compound ON employees(department, salary, hire_date);
EXPLAIN
SELECT * FROM employees
ORDER BY department, salary, hire_date; -- 与索引顺序一致
-- 可以使用索引排序
-- 错误示例:
EXPLAIN
SELECT * FROM employees
ORDER BY salary, department; -- 顺序与索引不一致
-- Extra: Using filesort
(2)覆盖索引优化
-- 创建覆盖索引避免回表
CREATE INDEX idx_covering_sort ON employees(
department,
hire_date,
name,
salary
);
-- 使用覆盖索引的查询
EXPLAIN
SELECT department, hire_date, name, salary
FROM employees
WHERE department IN ('IT', 'HR')
ORDER BY hire_date DESC;
-- Extra: Using index(覆盖索引,无需filesort)
(3)前缀索引排序
-- 对于长文本字段,使用前缀索引支持排序
CREATE INDEX idx_name_prefix ON employees(name(10));
EXPLAIN
SELECT * FROM employees
ORDER BY name
LIMIT 100;
-- 可能使用前缀索引排序(但结果可能不精确)
-- 更推荐的方法:使用全文索引或单独排序字段
ALTER TABLE employees ADD COLUMN name_sort VARCHAR(10);
CREATE INDEX idx_name_sort ON employees(name_sort);
UPDATE employees SET name_sort = LEFT(name, 10);
(4)利用索引条件下推(ICP)
-- MySQL 5.6+ 索引条件下推优化
CREATE INDEX idx_dept_hire_salary ON employees(department, hire_date, salary);
EXPLAIN
SELECT * FROM employees
WHERE department = 'IT'
AND hire_date > '2020-01-01'
ORDER BY salary DESC;
-- 可能使用ICP减少排序数据量
6-总结

(1)无法避免filesort的情况
-- 情况1:随机排序
EXPLAIN SELECT * FROM employees ORDER BY RAND();
-- 必须使用filesort
-- 优化方案:应用层随机化
SELECT * FROM employees ORDER BY id LIMIT 1;
-- 在应用层实现随机逻辑
-- 情况2:复杂表达式排序
EXPLAIN
SELECT *, (salary * 0.8 + bonus * 0.2) as total_comp
FROM employees
ORDER BY total_comp DESC;
-- 必须使用filesort
-- 优化方案:预计算字段
ALTER TABLE employees ADD COLUMN total_comp DECIMAL(10,2);
UPDATE employees SET total_comp = salary * 0.8 + bonus * 0.2;
CREATE INDEX idx_total_comp ON employees(total_comp);
(2)大数据量排序优化
-- 对于海量数据排序,使用分页优化
EXPLAIN
SELECT * FROM large_table
ORDER BY timestamp_column DESC
LIMIT 10000, 20;
-- 性能问题:需要排序前10020条记录
-- 优化方案:使用游标分页
EXPLAIN
SELECT * FROM large_table
WHERE timestamp_column < '2023-01-01' -- 上一页最后一条的时间
ORDER BY timestamp_column DESC
LIMIT 20;
-- 减少排序数据量
(5)Using join buffer
含义:使用连接缓冲区
条件:关联查询时无法使用索引
(6)Impossible WHERE
含义:WHERE条件永远为false
EXPLAIN SELECT * FROM users WHERE 1 = 0;
-- Extra: Impossible WHERE
【四】EXPLAIN 输出格式
(1)传统格式(默认)
EXPLAIN SELECT * FROM users WHERE id = 1;
(2)JSON格式(更详细)
EXPLAIN FORMAT=JSON SELECT * FROM users WHERE id = 1;
输出包含:
成本估算
执行顺序
子查询详细信息
(3)树形格式(MySQL 8.0+)
EXPLAIN FORMAT=TREE SELECT * FROM users WHERE id = 1;
(4)实际执行分析(MySQL 8.0.18+)
EXPLAIN ANALYZE SELECT * FROM users WHERE id = 1;
实际执行时间、循环次数等真实数据
【五】实际案例分析
【1】案例1:基础查询优化
-- 创建测试表
CREATE TABLE employees (
id INT PRIMARY KEY,
name VARCHAR(50),
department_id INT,
salary DECIMAL(10,2),
hire_date DATE,
INDEX idx_department (department_id),
INDEX idx_salary (salary),
INDEX idx_hire_date (hire_date)
);
-- 案例1.1:简单查询
EXPLAIN SELECT * FROM employees WHERE id = 100;
-- 结果:type=const, key=PRIMARY
-- 案例1.2:范围查询
EXPLAIN SELECT * FROM employees WHERE salary > 5000;
-- 结果:type=range, key=idx_salary
-- 案例1.3:多条件查询
EXPLAIN SELECT * FROM employees
WHERE department_id = 3 AND salary > 5000;
-- 分析:可能使用idx_department或idx_salary
【2】案例2:JOIN查询分析
CREATE TABLE departments (
id INT PRIMARY KEY,
name VARCHAR(50)
);
-- 关联查询分析
EXPLAIN
SELECT e.name, d.name
FROM employees e
JOIN departments d ON e.department_id = d.id
WHERE e.salary > 5000;
-- 预期结果:
-- employees表:type=ref, key=idx_department
-- departments表:type=eq_ref, key=PRIMARY
【3】案例3:子查询优化
-- 低效的子查询
EXPLAIN
SELECT * FROM employees
WHERE department_id IN (
SELECT id FROM departments WHERE name LIKE 'IT%'
);
-- 优化为JOIN
EXPLAIN
SELECT e.* FROM employees e
JOIN departments d ON e.department_id = d.id
WHERE d.name LIKE 'IT%';
【4】案例4:排序和分组优化
-- 需要文件排序的查询
EXPLAIN
SELECT department_id, AVG(salary)
FROM employees
GROUP BY department_id
ORDER BY AVG(salary) DESC;
-- Extra: Using temporary; Using filesort
-- 优化:为分组和排序创建合适索引
CREATE INDEX idx_dept_salary ON employees(department_id, salary);
EXPLAIN
SELECT department_id, AVG(salary)
FROM employees
GROUP BY department_id
ORDER BY department_id;
-- 可能消除Using filesort
【六】性能优化指南
【1】索引优化策略
-- 1. 为WHERE条件创建索引
CREATE INDEX idx_condition ON table_name(where_column);
-- 2. 为JOIN条件创建索引
CREATE INDEX idx_join ON table_name(join_column);
-- 3. 为ORDER BY/GROUP BY创建索引
CREATE INDEX idx_order ON table_name(order_column);
-- 4. 使用覆盖索引
CREATE INDEX idx_covering ON table_name(col1, col2, col3);
【2】查询重写技巧
-- 避免SELECT *
EXPLAIN SELECT id, name FROM users; -- 优于 SELECT *
-- 使用EXISTS代替IN(对于大数据集)
EXPLAIN
SELECT * FROM users u
WHERE EXISTS (
SELECT 1 FROM orders o WHERE o.user_id = u.id
);
-- 分页优化
EXPLAIN SELECT * FROM users ORDER BY id LIMIT 1000, 20;
-- 优化:使用游标分页
EXPLAIN SELECT * FROM users WHERE id > 1000 ORDER BY id LIMIT 20;
【七】高级分析技巧
【1】使用EXPLAIN分析执行计划
-- 完整分析流程
EXPLAIN
SELECT u.name, COUNT(o.id) as order_count
FROM users u
LEFT JOIN orders o ON u.id = o.user_id
WHERE u.create_date > '2020-01-01'
GROUP BY u.id, u.name
HAVING COUNT(o.id) > 5
ORDER BY order_count DESC
LIMIT 10;
-- 分析步骤:
-- 1. 查看type列,确保使用合适索引
-- 2. 检查Extra列,避免Using temporary和Using filesort
-- 3. 观察rows列,估算数据量
-- 4. 分析key_len,确保索引有效使用
【2】索引选择分析
-- 测试不同索引的效果
CREATE INDEX idx_composite1 ON users(create_date, status);
CREATE INDEX idx_composite2 ON users(status, create_date);
-- 分析查询1
EXPLAIN SELECT * FROM users WHERE create_date > '2023-01-01' AND status = 'active';
-- 观察使用哪个索引
-- 分析查询2
EXPLAIN SELECT * FROM users WHERE status = 'active' ORDER BY create_date DESC;
-- 观察索引选择
【3】分区表分析
-- 分区表查询分析
CREATE TABLE log_data (
id INT AUTO_INCREMENT,
log_date DATETIME,
message TEXT,
PRIMARY KEY (id, log_date)
) PARTITION BY RANGE (TO_DAYS(log_date)) (
PARTITION p202301 VALUES LESS THAN (TO_DAYS('2023-02-01')),
PARTITION p202302 VALUES LESS THAN (TO_DAYS('2023-03-01'))
);
EXPLAIN SELECT * FROM log_data WHERE log_date BETWEEN '2023-01-15' AND '2023-01-20';
-- 观察partitions列,确认分区修剪
【八】常见问题排查
【1】全表扫描问题
-- 问题查询
EXPLAIN SELECT * FROM users WHERE email LIKE '%@gmail.com';
-- type: ALL (全表扫描)
-- 解决方案1:使用前缀查询
EXPLAIN SELECT * FROM users WHERE email LIKE 'abc@gmail.com';
-- 可能使用索引
-- 解决方案2:使用全文索引
ALTER TABLE users ADD FULLTEXT idx_email (email);
EXPLAIN SELECT * FROM users WHERE MATCH(email) AGAINST('gmail.com');
【2】临时表问题
-- 产生临时表的查询
EXPLAIN
SELECT department, COUNT(*)
FROM employees
GROUP BY department
ORDER BY COUNT(*) DESC;
-- Extra: Using temporary; Using filesort
-- 优化方案
EXPLAIN
SELECT department, COUNT(*) as cnt
FROM employees
GROUP BY department
ORDER BY department; -- 使用分组字段排序
【3】索引合并问题
-- 索引合并查询
EXPLAIN
SELECT * FROM employees
WHERE department_id = 3 OR salary > 5000;
-- 可能显示:Using union(idx_department,idx_salary)
-- 优化:使用UNION替代OR
EXPLAIN
SELECT * FROM employees WHERE department_id = 3
UNION
SELECT * FROM employees WHERE salary > 5000;
【九】实际工作流程
【1】性能分析检查清单
-- 1. 检查查询基础信息
EXPLAIN SELECT ...;
-- 2. 分析关键指标
-- type是否达到range以上?
-- key是否使用了合适索引?
-- rows是否在合理范围?
-- Extra是否出现警告信息?
-- 3. 优化措施
-- 添加缺失索引
-- 重写问题查询
-- 调整表结构
-- 4. 验证优化效果
EXPLAIN SELECT ...; -- 再次检查
【2】自动化分析脚本
-- 创建分析存储过程
DELIMITER //
CREATE PROCEDURE AnalyzeQuery(IN query_text TEXT)
BEGIN
-- 执行EXPLAIN
SET @sql = CONCAT('EXPLAIN FORMAT=JSON ', query_text);
PREPARE stmt FROM @sql;
EXECUTE stmt;
DEALLOCATE PREPARE stmt;
-- 提供优化建议(基于分析结果)
SELECT
CASE
WHEN JSON_EXTRACT(analysis, '$.query_block.ordering_operation.using_filesort') IS NOT NULL
THEN '建议为ORDER BY创建索引'
WHEN JSON_EXTRACT(analysis, '$.query_block.table.attached_condition') LIKE '%LIKE%'
THEN '注意LIKE查询性能'
ELSE '查询结构良好'
END as suggestion;
END //
DELIMITER ;
【十】总结
(1)关键要点
type列最重要:反映数据访问方式,应尽量优化到range以上
Extra列需关注:避免Using temporary和Using filesort
索引是核心:合理设计索引是性能优化的关键
结合实际数据:EXPLAIN结果是估算,需结合真实数据验证

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 0
0 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)