别花100美元了!30美元,我们跑通了Karpathy的ChatGPT
【摘要】特斯拉前AI总监Andrej Karpathy开源项目nanochat成功复现简易版ChatGPT,用户仅需约30美元成本即可完成全流程训练。通过8卡A800实测显示,完整流程包含预训练(7小时)、指令调优(15分钟)和微调(13分钟)三阶段,总成本降至200元人民币。项目提供完整训练代码和类ChatGPT交互界面,支持从数据准备到模型部署的全流程验证,并表明通过扩展训练可显著提升模型性能
引言:
上周一,特斯拉前AI总监、OpenAI创始成员Andrej Karpathy发布了全新开源项目nanochat,以极简代码库成功复现了简易版ChatGPT,并提供了完整的类ChatGPT网页交互界面。

Karpathy将这一项目称为“写过最疯狂的代码之一”。据其介绍,用户只需启动一台云GPU服务器、运行一个脚本,最快4小时即可在ChatGPT风格的界面中与自训练模型对话。
Karpathy估算其成本约为100美元。为验证这一流程,我们在英博云上使用8卡A800资源进行了实际复现并发现:总成本可进一步降至约30美元。
在我们本次的实测中,具体成本构成如下:本次复现中Pretrain阶段耗时约7小时,按平台标准费率计算约360元。在此基础上,叠加注册认证赠送50元与首充赠送100元等优惠后,实际支出仅约200元人民币(约合30美元),即可完成全流程训练与部署。
https://www.ebcloud.com/chn_cbywfwsh
话不多说,先贴运行记录:
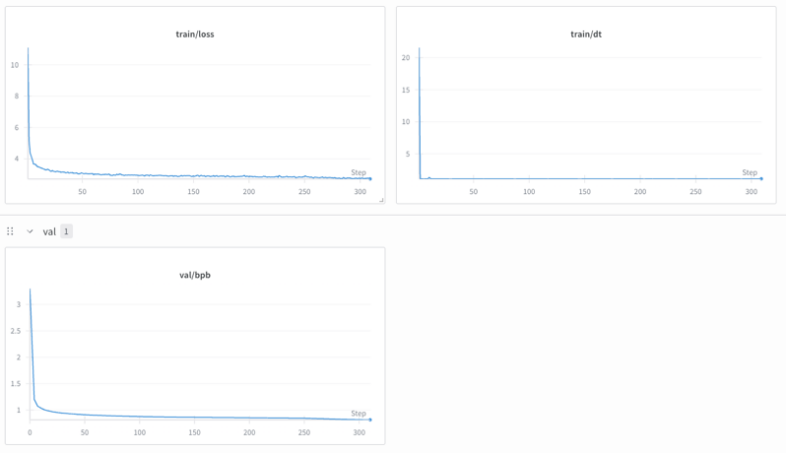
https://wandb.ai/zzzac/nanochat/runs/dzvic3jv?nw=nwuserzzzac

接下来,我们将详细说明复现流程。本文主要基于nanochat 代码仓库和作者的复现指引进行,读者可自行搭配阅读。
nanochat 代码仓库
https://github.com/karpathy/nanochat
作者的复现指引
https://github.com/karpathy/nanochat/discussions/1
资源准备
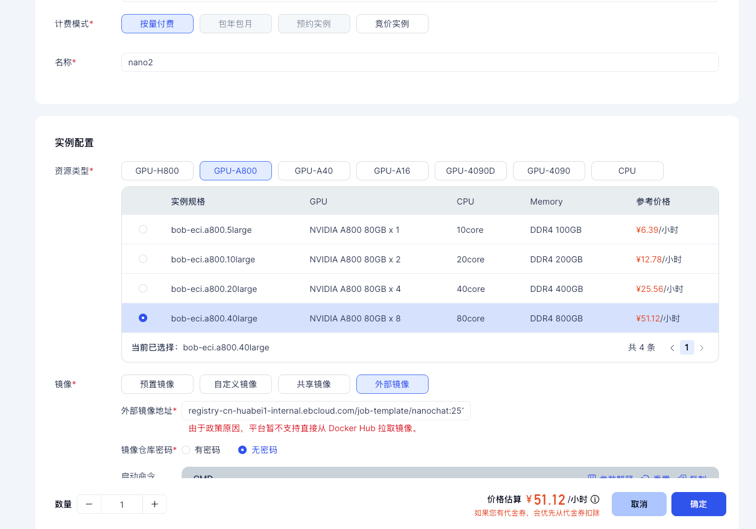
首先,前往英博云的控制台,创建一台8卡 A800 开发机。
1.在开发机创建页面,选择8 卡 A800 服务器。
2.选择镜像时,选定“外部镜像”,并填写镜像地址:registry-cn-huabei1-internal.ebcloud.com/job-template/nanochat:251015-1
3.镜像仓库密码处,选择“无密码”即可。
4.可选:创建并挂载一个共享存储,用来保存数据、模型、环境等内容。
开发机启动完毕后,点击开发机实例的右侧按钮“JupyterLab” 即可打开 Jupyter 页面。我们后续的工作都将在 JupyterLab 中进行。

开始训练
在JupyterLab Terminal 中执行以下命令来激活实验环境:

使用训练好的模型
我们提供了一份训练好的模型,以及完整的中间产物,无需自行训练数个小时,可以直接体验模型评估、mid-training、sft 以及对话等功能。
在JupyterLab Terminal 中执行以下命令将完整环境拷贝到 nanochat 的指定路径:

完整环境中包括了数据、tokenizer、预训练的模型、指令调优的模型、sft 的模型等内容。基于该环境,我们可以运行本文后续步骤中的任意任务。

如果读者想完整体验复现流程,从0 开始运行所有训练、评估等过程,您可以跳过当前步骤,并按本文的后续步骤依次运行数据准备、tokenizer 训练、pretraining、mid-training、sft 等流程。
数据准备
我们提前下载好了数据集,只需要把必要的数据拷贝到nanochat 指定的路径即可。参考作者的说明,我们使用前 240 个 shard 作为本次的训练集。

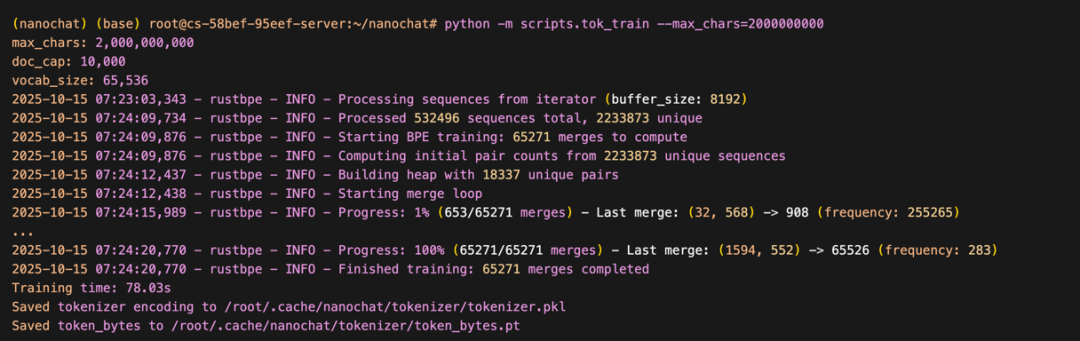
Tokenizer 训练
在JupyterLabTerminal 中直接运行如下命令,即可开始 tokenizer 的训练。

80s。
训练完成后,可执行如下命令进行对比评估,它会将我们训练的tokenizer 与 GPT-2 和 GPT-4 的 tokenizer 进行对比:

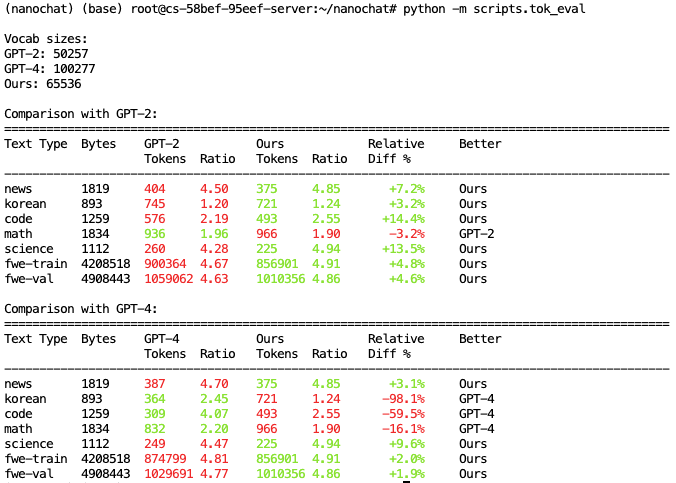
我们的tokenizer 使用了 65536 的 vocab size,对比结果如下所示:
·相比于GPT-2(vocab size 50257),我们的 tokenizer 的 embedding 表达能力普遍更强;
·相比于GPT-4(vocab size 100277),我们的 tokenizer 在多语言、代码、数学等方面都要差一些;
pretraining 预训练
预训练将使用8 卡 A800 运行约 7 小时,这是本文的主要资源消耗。我们也提供了预先训练好的模型,读者可以跳过预训练阶段,直接使用它进行后续 eval 、 mid-training、sft 等工作。具体参考 “使用训练好的模型”章节。

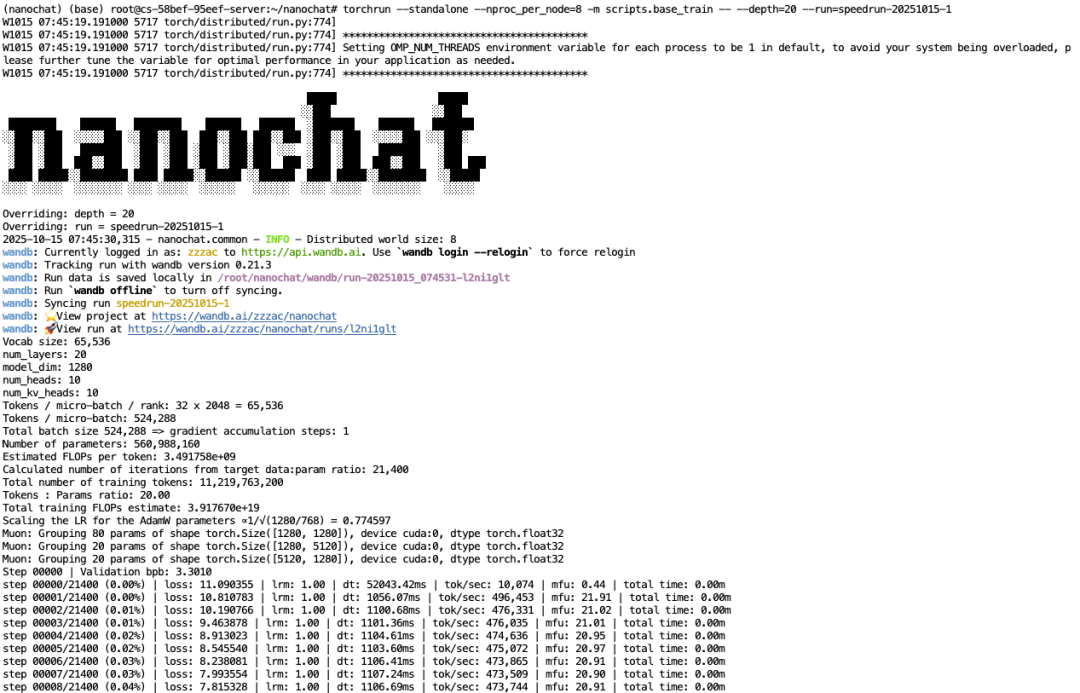
从训练日志中可以看到,完整训练流程总计需运行21400 个 iters,每个 iter 约耗时 1.1s、消费 470k token,总计运行约 6.6 小时。
等待训练完成之后,可运行如下脚本对当前训练的模型效果进行评估:

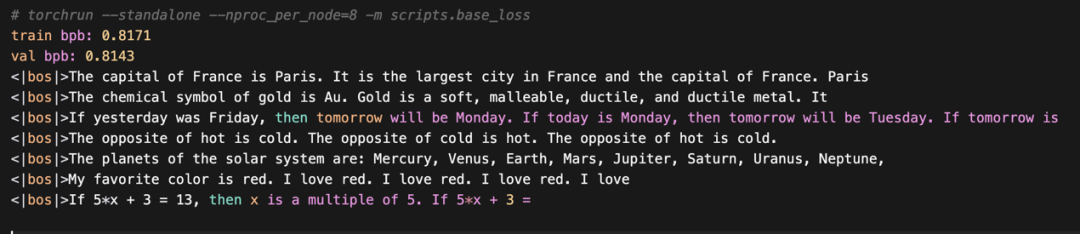
可以看到bpb( bits per byte) 约 0.81,并能正确补全部分内容,如:法国的首都、金元素的化学符号等等。
base_eval 的输入如下所示:
Midtraining 指令调优
我们在上一阶段训练出的模型只会根据输入预测下一个token,进行文本补全,这是因为我们的训练数据集都是一篇一篇完整的独立文章。
当前这一部分,我们将切换使用对话类型的训练数据集HuggingFaceTB/smol-smoltalk,使用和 pretraining 完全相同的训练方式,让模型从数据集中学会使用 OpenAI Harmony 格式,生成对话的响应。

通过我们的网络加速服务加速Huggingface 后,可以运行以下命令来进行训练:

这一阶段耗时约15 分钟(如果使用 H800,耗时约 8 分钟)。
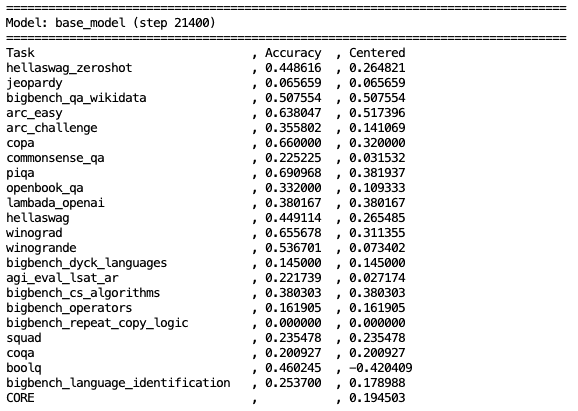
训练完成后,即可进行本阶段的模型评估,我们将在选定的ARC-Easy、ARC-Challenge 等 6 个数据集上进行评估:
![]()
Supervised Finetuning (SFT)
接下来,我们将进行SFT。这一步骤中将进行一轮额外的对话场景的训练,本次训练应该尽可能选择使用高质量数据,如需针对模型生成内容的安全性进行训练,也应该在这里完成。
本轮训练并不会将数据头尾相连后直接喂给模型,而是将每个独立的数据行 padding 到指定长度,来模拟使用模型进行推理服务时的格式。
![]()
sft 的训练大概需要执行 13 分钟(如果使用 H800,耗时约 7 分钟)。训练完成后,即可进行本阶段的模型评估:
![]()
体验模型服务
现在我们就可以使用命令行工具、web 页面,来和自己手搓的模型进行对话,并体验模型的实际效果了。
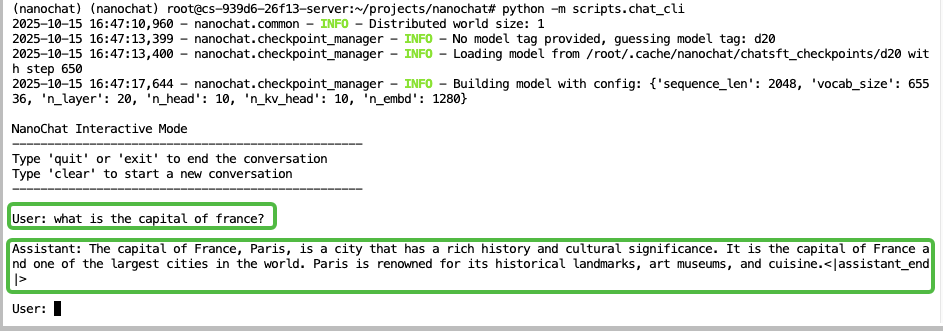
通过命令行工具体验
直接运行以下命令即可启动一个交互式终端,并与模型进行交流。
![]()
通过web 页面体验
直接运行如下命令即可开启一个类Chat GPT 的 web 服务。
![]()
本地配置kubectl 命令后,可快速将服务映射到本地进行访问测试:

kubectl 的配置方式可参考帮助文档https://docs.ebcloud.com/docs/cluster/attach.html 。
其中,<pod-name> 为具体的 pod 名称,可使用 kubectl命令来查看,最左侧即为 pod name。

随后,本地浏览器访问0.0.0.0:8000 即可打开页面进行体验:
如需对外暴露服务以随时随地进行访问,可参考文档快速申请公网IP 来使用:https://docs.ebtech.com/docs/devmachine/network.html。使用完成后,删除服务释放公网 IP,就会停止计费。
Reinforcement Learning (RL)
目前项目中的RL 部分还没有调整得很好,可以使用下面的命令尝试运行并观察reward 的变化。

自行探索
接下来,就进入了自由探索的领域,您可以根据兴趣点做不同尝试:调整训练参数、模型结构;阅读实现的细节,修改代码并测试等等。可以方便地在jupyterlab 的页面中进行探索,也可以使用终端 ssh 登录到服务器,使用vscode 等 IDE 远程连接服务器,进行开发、测试。
根据作者的介绍,上面的训练方式可以通过扩展训练数据和延长训练时间,持续提升模型能力:
·如果提升到3 倍的训练成本,模型在 CORE 指标上的表现可超越 GPT-2;
·如果提升到10 倍的训练成本,模型表现可显著提升,能解决简单的数学、代码问题,在 GSM8K、MMLU 等数据集上的表现大幅提升。
至此,我们使用8 卡 A800 进行了三阶段训练,总计耗时约 431 min,以目前英博云的价格计算,总成本约 368 元:
·Pretraining 耗时约 401 min
·Midtraining 耗时约 15 min
·SFT 耗时约 13 min
- 所有内容均为原创,享有完整著作权。任何侵犯版权的行为都将受到严厉打击和法律制裁。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 15
15 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)