从扩散模型到流匹配:π_RL如何突破视觉-语言-动作模型的强化学习困境
OpenAI的o1模型通过强化推理阶段算力提升逻辑能力,融合了蒙特卡洛树搜索(MCTS)、扩散模型和强化学习等技术。微软开源的rStar项目展示了MCTS在小语言模型中的纯推理优化应用,通过五种思维路径(A1-A5)构建搜索树:步步推理(A1)、一步到位(A2)、子问题分解(A3)、重新回答(A4)和问题改写(A5)。该框架将人类思维模式转化为prompt模板,在推理时通过搜索算法动态选择最优路径
0. 引言
在深度学习领域,OpenAI的o1模型开启了一个全新的范式——将更多算力投入到推理阶段以提升模型的逻辑推理能力。这一理念并非凭空而来,而是建立在多年来对蒙特卡洛树搜索(Monte Carlo Tree Search, MCTS)、扩散模型(Diffusion Models)以及强化学习(Reinforcement Learning, RL)等技术的深入研究之上。本文将深入探讨这些技术的演进路径,重点分析为何流匹配(Flow Matching)与传统强化学习存在天然的不融洽性,以及最新的π_RL框架如何巧妙地解决这一根本性难题。
从技术框架来看,o1的实现可能遵循"预训练-后训练-推理优化"的三阶段路径。其中,推理优化阶段是区别于传统语言模型的关键创新点。这一阶段主要有两个作用:第一,直接对推理过程进行优化,例如通过过程奖励模型(Process Reward Model, PRM)结合搜索方法,或采用MCTS进行自我博弈式的路径探索;第二,用于在后训练过程中筛选高质量数据。这种设计哲学体现了一个核心原则——尽量减少人工标注,充分利用已有模型的能力自动化生产训练数据,再通过监督微调或强化学习等后训练方法提升模型性能。

理解这一框架对于把握当前AI技术的发展脉络至关重要。MCTS和推理优化可以被视为整个系统中的一块关键"积木"——当你理解了这块积木的目的和实现方法后,就可以根据需要灵活地将其组装到系统的任何环节。无论o1最终采用的是纯推理优化路线,还是后训练与推理优化相结合的路线,掌握这些基础技术都是必要的。接下来,我们将从微软开源的rStar项目入手,详细剖析MCTS在自然语言推理任务中的具体应用。
1. MCTS在自然语言推理中的应用——以rStar为例
1.1 为什么选择rStar作为切入点
蒙特卡洛树搜索最初在围棋AI AlphaGo中大放异彩,但如何将其应用于自然语言处理领域一直是研究者关注的焦点。微软开源的rStar项目提供了一个极佳的案例,它完全走纯推理优化路线,不依赖大规模后训练,因此更便于我们理解MCTS作为独立模块的工作机制。
rStar选择这一路线有充分的理由。首先,它针对的是小语言模型(Small Language Model, SLM)场景。对于小模型而言,其预训练阶段获得的能力有限,难以通过自产自销的方式生产高质量训练数据,这使得后训练方法的效果大打折扣。其次,训练一个高质量的过程奖励模型(PRM)需要大量人工标注的中间步骤数据,这在资源受限的情况下是不现实的。因此,rStar选择了一条"用算力换标注"的道路——通过MCTS在推理时进行大量搜索,找到高质量的推理路径。
更重要的是,rStar的代码完全开源,这为我们深入理解MCTS的每一个细节提供了可能。尽管其论文写得相对精简,省略了许多实现细节,但通过源码分析,我们可以完整地重现整个推理过程。这种从源码出发的学习方式,相比单纯阅读论文或想象实现方案,能够让我们获得更扎实的理解。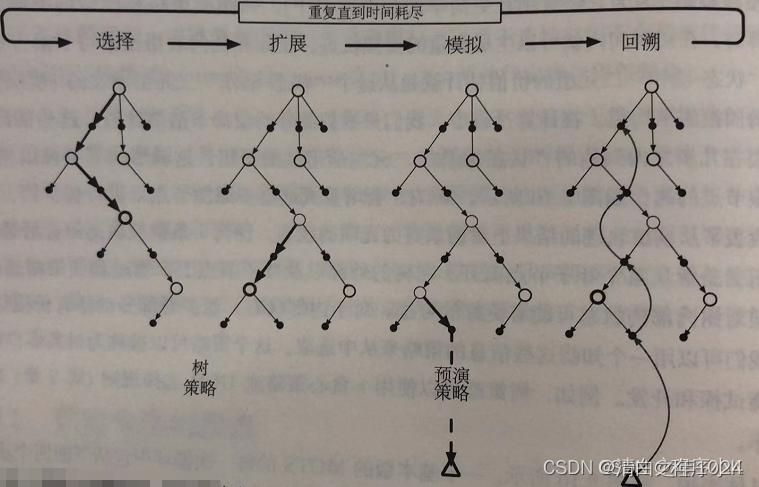
1.2 构造搜索树:从人类思维到算法实现
在深入MCTS的技术细节之前,让我们先从一个简单问题出发,思考人类是如何解决问题的。考虑这样一个问题:"停车场原有3辆车,又来了2辆车,现在停车场有多少辆车?"面对这个问题,我们可能采用多种思考方式。
第一种方式是步步推理(Action A1)。我们将问题分解为多个步骤:第一步,确定停车场原有车辆数量为3辆;第二步,确定新来车辆数量为2辆;第三步,将两个数字相加得到5辆;第四步,给出最终答案。这种方式的特点是每一步都有明确的中间结果,最后一步以"答案是"开头。
# 示例:步步推理的结构化表示
class StepByStepReasoning:
def __init__(self, question):
self.question = question
self.steps = []
def add_step(self, reasoning, intermediate_answer):
"""添加推理步骤"""
self.steps.append({
'reasoning': reasoning,
'answer': intermediate_answer
})
def solve(self):
"""模拟步步推理过程"""
# 步骤1:识别初始状态
self.add_step(
"从停车场原有的车辆数开始",
3
)
# 步骤2:识别变化量
self.add_step(
"添加新来的车辆数",
2
)
# 步骤3:执行计算
self.add_step(
"将数字相加:3 + 2 = 5",
5
)
# 步骤4:给出最终答案
final_answer = self.steps[-1]['answer']
return f"答案是: {final_answer}"
第二种方式是一步到位(Action A2)。对于简单问题,我们可能不会进行详细的步骤分解,而是直接给出答案:"原来有3辆,来了2辆,3加2等于5,答案是5。"这种方式省略了中间的细节推理过程。
第三种方式是子问题分解(Action A3)。我们可以将原问题拆解为一系列子问题:子问题1.1询问停车场原有多少辆车,答案是3辆;子问题1.2询问新来多少辆车,答案是2辆;子问题1.3整合前两个答案,得出最终结果5辆。这种方式更适合处理复杂问题,通过逐步缩小问题规模来降低求解难度。
除此之外,还有两种辅助性的思考方式。第四种是重新回答子问题(Action A4),当我们对某个子问题的答案不确定时,可以用不同的方法重新求解。第五种是问题改写(Action A5),即将冗长的问题描述精炼为关键信息,例如提取条件1、条件2等核心要素。
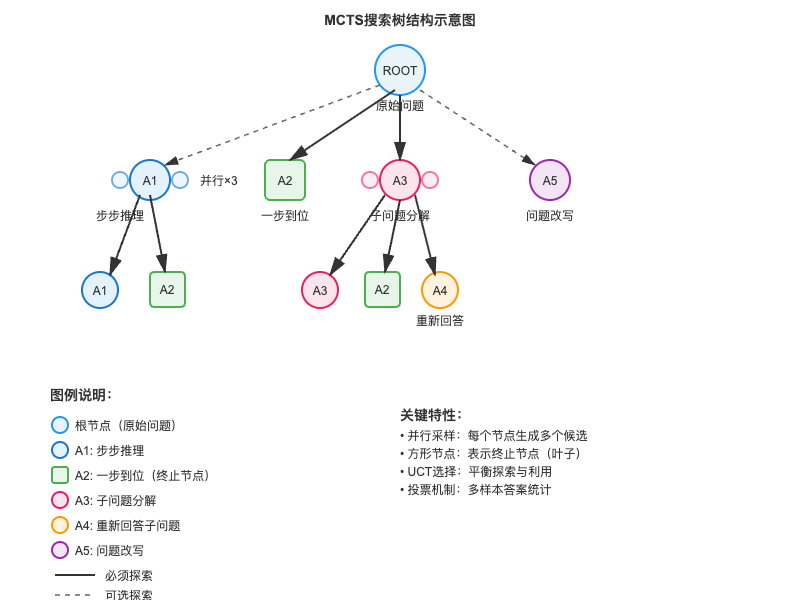
在rStar的实现中,这五种思考方式被转化为具体的prompt模板,用于指导模型执行不同的推理动作。下面展示了如何将这些思考方式组合成一棵搜索树。搜索树的根节点是用户的原始问题,从根节点出发,模型可以选择采用A1到A5中的任意一种或多种方式进行探索。方形节点表示终止节点,例如A2节点一步到位给出答案后即终止。虚线表示可选探索,实线表示必须探索。
class SearchTreeNode:
"""搜索树节点"""
def __init__(self, content, node_type, parent=None):
self.content = content # 节点内容(问题或答案)
self.node_type = node_type # 节点类型:A1-A5
self.parent = parent
self.children = []
self.visits = 0 # 访问次数
self.reward = 0.0 # 累积奖励
def add_child(self, child_node):
"""添加子节点"""
self.children.append(child_node)
child_node.parent = self
def is_terminal(self):
"""判断是否为终止节点"""
if self.node_type == 'A2': # 一步到位
return True
if self.node_type == 'A1' and '答案是' in self.content: # 最后一步
return True
if self.node_type == 'A3' and self.is_final_subquestion():
return True
return False
def is_final_subquestion(self):
"""判断是否为最后一个子问题"""
return '现在我们可以回答' in self.content or \
self.content.startswith('问题1:') # 包含原始问题
从根节点(第0层)出发,模型需要做出第一次选择。对于根节点,A1、A5是可选的,A2、A3是必做的。为什么A2和A3是必做的?因为这两种方式分别代表了"快速求解"和"分解求解"两种基本策略,覆盖了问题的主要解决路径。A1作为A2和A3之间的中间选项,提供了额外的灵活性,而A5则是一种预处理手段。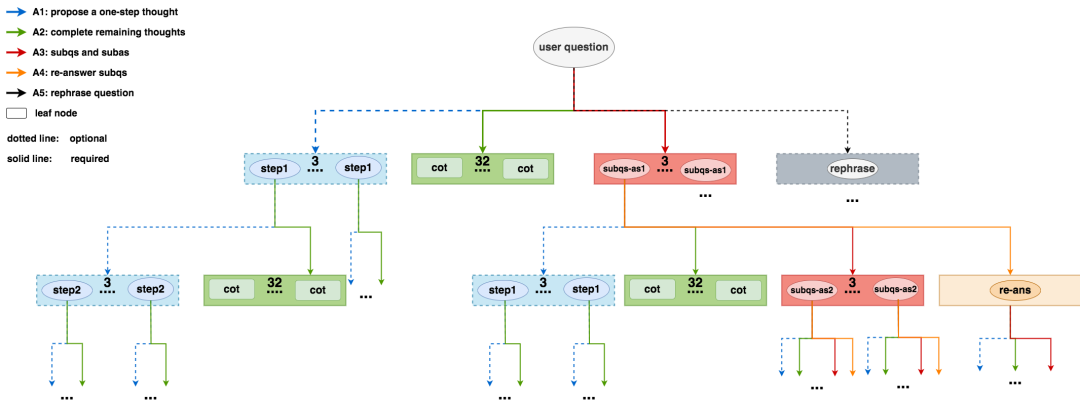
考察第1层的节点展开情况。对于A1类型的节点,它表示已经执行了第一步推理,此时模型可以选择继续执行下一步(再次使用A1),或者直接给出剩余的推理和答案(使用A2)。对于A2类型的节点,由于已经给出了最终答案,因此它是一个叶子节点,不再向下展开。对于A3类型的节点,它产生了第一个子问题及其答案,接下来可以继续生成下一个子问题(再次使用A3),用不同方法重新回答当前子问题(使用A4),或者对问题进行改写(使用A5),也可以直接给出剩余推理(使用A2)。
class SearchTree:
"""MCTS搜索树"""
def __init__(self, root_question):
self.root = SearchTreeNode(root_question, 'ROOT')
def expand_node(self, node):
"""扩展节点,根据节点类型生成可能的子节点"""
if node.is_terminal():
return []
children = []
if node.node_type == 'ROOT':
# 根节点:必须尝试A2和A3
children.append(self.create_a2_node(node))
children.extend(self.create_a3_nodes(node, num_samples=3))
# 可选:尝试A1和A5
if should_try_a1(node):
children.extend(self.create_a1_nodes(node, num_samples=3))
if should_try_a5(node):
children.append(self.create_a5_node(node))
elif node.node_type == 'A1':
# 步步推理节点:可以继续下一步或直接给出答案
children.append(self.create_a2_node(node))
if not node.is_terminal():
children.extend(self.create_a1_nodes(node, num_samples=3))
elif node.node_type == 'A3':
# 子问题节点:可以继续子问题、重新回答或给出最终答案
children.append(self.create_a2_node(node))
children.extend(self.create_a3_nodes(node, num_samples=3))
children.extend(self.create_a4_nodes(node, num_samples=2))
return children
def create_a1_nodes(self, parent, num_samples):
"""创建A1类型节点(并行采样)"""
nodes = []
for _ in range(num_samples):
content = self.model.generate_next_step(parent.content)
nodes.append(SearchTreeNode(content, 'A1', parent))
return nodes
这种搜索树的构建方式有几个关键特点。第一,并行采样机制。在每个节点处,模型不仅仅生成一个子节点,而是并行采样多个(例如3个),这扩大了搜索空间,增加了找到正确推理路径的概率。第二,选择性探索策略。并非所有可能的动作都会被执行,模型会根据配置决定哪些是必做的,哪些是可选的。第三,深度优先与广度优先的结合。通过MCTS的选择机制,模型既会深入探索有潜力的路径,也会广泛尝试不同的推理方式。
1.3 MCTS的四个核心步骤:从选择到反向传播
理解了搜索树的结构后,我们需要进一步了解MCTS如何利用这棵树进行推理。MCTS包含四个核心步骤:选择(Selection)、扩展(Expansion)、模拟(Simulation)和反向传播(Backpropagation)。这四个步骤构成一轮rollout,通过多轮rollout逐步完善搜索树。
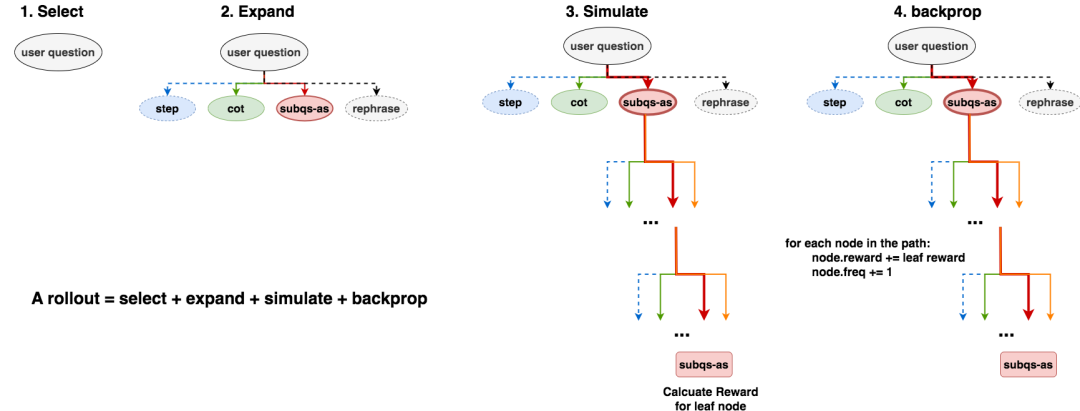
选择步骤决定了从哪个节点开始扩展。在第一轮rollout中,选择非常简单——直接选中根节点,因为整棵树还是空的。但在后续的rollout中,选择变得复杂起来。模型从根节点出发,逐层向下探索。如果某一层的所有子节点都已被访问过,模型需要计算每个子节点的UCT值(Upper Confidence Bound for Trees),选择UCT值最大的节点继续向下。如果某一层存在未访问的节点,则随机选择一个未访问节点进行扩展。这种策略平衡了探索(exploration)和利用(exploitation)。
import math
class MCTSSearcher:
"""MCTS搜索器"""
def __init__(self, tree, model, c_exploration=1.414):
self.tree = tree
self.model = model # 语言模型
self.c_exploration = c_exploration # 探索权重
def select(self):
"""选择步骤:找到需要扩展的节点"""
node = self.tree.root
while not node.is_terminal():
if not node.children:
# 叶子节点,需要扩展
return node
# 检查是否有未访问的子节点
unvisited = [c for c in node.children if c.visits == 0]
if unvisited:
return random.choice(unvisited)
# 所有子节点都访问过,选择UCT值最大的
node = self.select_best_uct(node)
return node
def calculate_uct(self, node):
"""计算UCT值"""
if node.visits == 0:
return float('inf')
# UCT = Q/N + c * sqrt(ln(N_parent) / N)
exploitation = node.reward / node.visits
exploration = self.c_exploration * math.sqrt(
math.log(node.parent.visits) / node.visits
)
return exploitation + exploration
def select_best_uct(self, parent):
"""选择UCT值最高的子节点"""
return max(parent.children, key=self.calculate_uct)
UCT值的计算公式体现了MCTS的核心思想。公式包含两部分:利用项Q/N和探索项c×sqrt(ln(N_parent)/N)。利用项衡量节点的平均奖励,访问次数多且奖励高的节点具有更高的利用价值。探索项鼓励访问次数少的节点,确保不会过早收敛到次优路径。参数c控制探索和利用的平衡,实践中通常采用退火策略——初期使用较大的c值鼓励探索,后期减小c值侧重利用已有知识。

扩展步骤根据节点类型创建所有可能的子节点。这一步骤的实现已在前面的代码中展示。关键在于理解不同节点类型的扩展规则,以及并行采样的作用。
模拟步骤是MCTS中最耗时但也最关键的部分。从扩展产生的子节点中随机选择一个,然后重复"扩展-随机选择"的过程,直到达到叶子节点或最大搜索深度。这一步骤的目的是快速评估新节点的潜在价值。在rStar中,只有两种类型的节点可以成为叶子节点:终止的A3节点(最后一个子问题的答案)和A2节点(一步到位的答案)。
反向传播步骤将叶子节点的奖励回传到路径上的所有节点。这一步骤的关键在于如何计算叶子节点的奖励。对于A3类型的叶子节点,rStar采用了一种投票机制:对最后一个子问题并行采样多个答案(例如n个),统计这些答案中每个候选答案出现的频率,选择出现次数最多的答案作为最终答案,并将其占比作为该节点的奖励。例如,如果n=10,其中6次给出答案A,3次给出答案B,1次给出答案C,那么答案A的占比为0.6,这个值就是该叶子节点的奖励。对于A2类型的叶子节点,计算方式类似,直接在其所有并行采样结果中计算答案占比。
class MCTSSearcher:
# ... 前面的代码 ...
def simulate(self, node):
"""模拟步骤:从节点出发随机探索直到叶子节点"""
current = node
path = [node]
while not current.is_terminal() and len(path) < self.max_depth:
children = self.tree.expand_node(current)
if not children:
break
current = random.choice(children)
path.append(current)
# 计算叶子节点奖励
reward = self.calculate_reward(current)
return path, reward
def calculate_reward(self, leaf_node):
"""计算叶子节点的奖励值"""
if leaf_node.node_type == 'A2':
# 对于A2节点,从并行采样结果中计算答案投票
answers = []
for _ in range(self.num_samples):
answer = self.extract_answer(
self.model.generate(leaf_node.content)
)
answers.append(answer)
return self.vote_score(answers)
elif leaf_node.node_type == 'A3' and leaf_node.is_terminal():
# 对于终止的A3节点,对最后一个子问题采样多个答案
answers = []
for _ in range(self.num_samples):
sub_answer = self.model.generate_sub_answer(
leaf_node.content
)
final_answer = self.extract_answer(sub_answer)
answers.append(final_answer)
return self.vote_score(answers)
return 0.0
def vote_score(self, answers):
"""计算投票得分:返回最高频答案的占比"""
from collections import Counter
counter = Counter(answers)
most_common_answer, count = counter.most_common(1)[0]
return count / len(answers)
def backpropagate(self, path, reward):
"""反向传播:更新路径上所有节点的访问次数和奖励"""
for node in path:
node.visits += 1
node.reward += reward
通过多轮rollout(默认值为16轮),MCTS逐步构建出一棵相对完整的搜索树。每轮rollout都会根据当前搜索树的状态,利用UCT公式找到最有探索价值的路径进行扩展,并通过反向传播更新节点的统计信息。这个过程具有自适应性——表现好的路径会被更频繁地访问和扩展,而表现差的路径则逐渐被边缘化。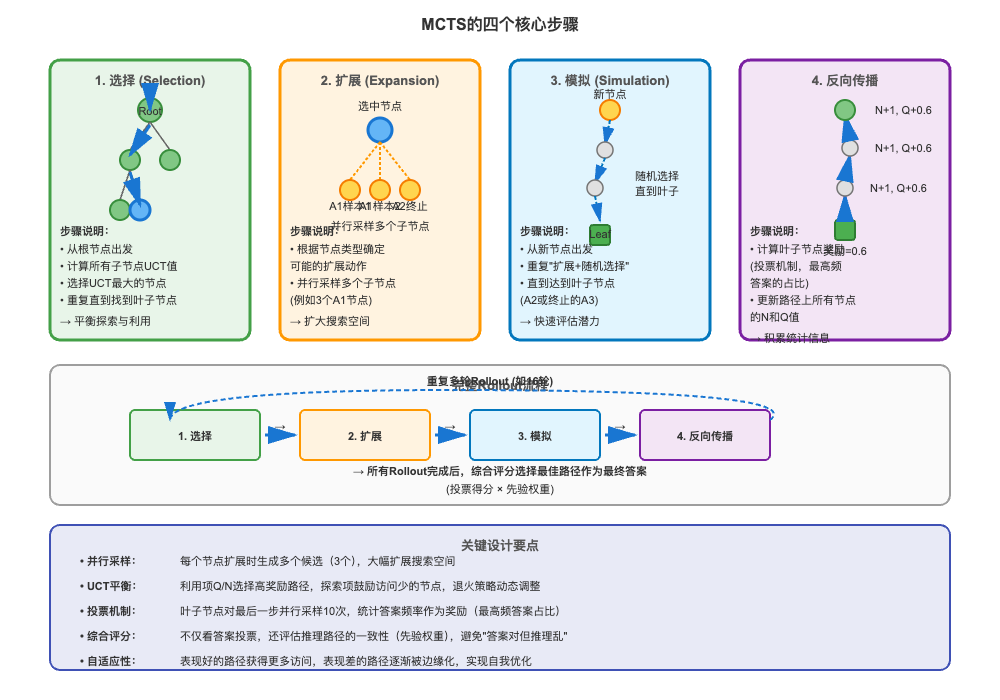
当所有rollout完成后,搜索树中包含了大量可能的推理路径。接下来的任务是从中选择一条最佳路径作为最终答案。rStar采用了综合评分机制,不仅考虑答案的投票得分,还考虑推理过程的质量。具体来说,首先找到所有有效的解决方案节点(solution nodes),然后按答案对这些节点分组,计算每个答案的投票得分。同时,为每个解决方案节点计算一个先验权重(prior weight),衡量其推理路径的质量。该权重通过逐层评估推理过程的一致性得到——如果一条路径上每一步推理都稳定地指向同一个答案,说明推理过程高度自洽,该节点获得较高的先验权重。最终,每个解决方案节点的得分是投票得分与先验权重的乘积,选择得分最高的节点及其路径作为最终输出。
这种设计避免了"答案碰巧正确但推理过程混乱"的情况,确保输出的推理路径不仅结论正确,而且逻辑严密。这对于数学推理、代码生成等需要严格逻辑的任务尤为重要。
2. 扩散模型的数学原理与实现细节
2.1 扩散模型的核心思想:从噪声到数据的可逆变换
在深入探讨流匹配和π_RL之前,我们需要先理解扩散模型的基础原理。扩散模型的核心思想极其简洁优雅:学习一个从简单分布(如高斯噪声)到复杂数据分布的变换。这个想法并不新鲜——生成对抗网络(GAN)和标准化流(Normalizing Flow)也试图学习类似的变换。扩散模型的独特之处在于,它将这个变换分解为一系列微小的、更容易学习的步骤。
想象你要雕刻一座复杂的雕像。直接从一块原石变成精美雕像需要高超的技艺,但如果将这个过程分解为数百个小步骤,每步只需要做微小的调整,任务就变得简单多了。扩散模型正是采用了这种"化整为零"的策略。
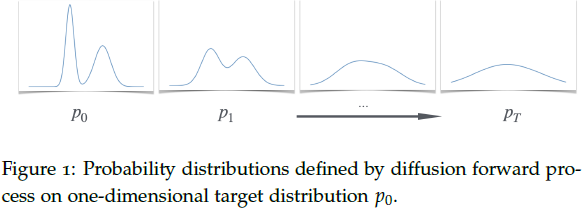
从数学角度看,扩散模型定义了一个前向过程和一个反向过程。前向过程非常简单——逐步向数据添加高斯噪声,直到将其完全转化为纯噪声。假设我们有一个数据点 x 0 x₀ x0来自目标分布 p ∗ p* p∗(例如一张狗的图片),前向过程定义为:
x t = x t − 1 + η t − 1 ,其中 η t − 1 N ( 0 , σ 2 ⋅ Δ t ) x_t = x_{t-1} + η_{t-1},其中 η_{t-1} ~ N(0, σ²·Δt) xt=xt−1+ηt−1,其中ηt−1 N(0,σ2⋅Δt)
这里 t t t表示时间步, Δ t Δt Δt是时间间隔, σ σ σ是噪声尺度。经过 T T T步后, x T x_T xT基本上是一个纯噪声,与原始数据 x 0 x₀ x0几乎没有关系。
import numpy as np
class DiffusionForwardProcess:
"""扩散前向过程"""
def __init__(self, num_steps=1000, noise_scale=1.0):
self.T = num_steps
self.dt = 1.0 / num_steps # 时间间隔
self.sigma = noise_scale
def forward_step(self, x_prev, t):
"""单步前向扩散"""
noise_std = self.sigma * np.sqrt(self.dt)
noise = np.random.normal(0, noise_std, size=x_prev.shape)
x_t = x_prev + noise
return x_t
def forward_process(self, x0):
"""完整前向过程:从x0到xT"""
trajectory = [x0]
x = x0.copy()
for t in range(self.T):
x = self.forward_step(x, t)
trajectory.append(x)
return trajectory
def sample_xt(self, x0, t):
"""直接采样x_t,无需逐步计算"""
# 利用高斯分布的可加性
# x_t = x_0 + 总噪声,其中总噪声 ~ N(0, t·σ²)
total_noise_std = self.sigma * np.sqrt(t)
noise = np.random.normal(0, total_noise_std, size=x0.shape)
return x0 + noise
前向过程的数学性质非常好——它是一个马尔可夫过程,每一步只依赖于前一步,而且我们可以直接在常数时间内从 x 0 x₀ x0采样任意时刻的 x t x_t xt,无需逐步模拟整个过程。这个性质在训练时非常重要,因为我们可以随机采样任意时刻进行训练,而不需要从头开始模拟整个扩散过程。
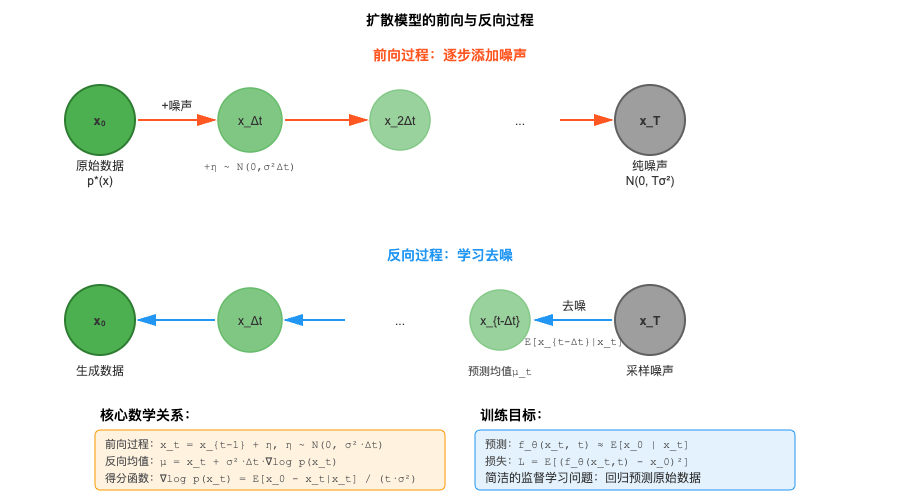
反向过程才是扩散模型真正的核心——如何从噪声x_T逆向回到数据x₀。如果我们能够精确地模拟反向过程,就相当于学会了从噪声生成数据。直观上,反向过程应该是"去噪":给定当前的噪声状态x_t,预测出稍微少一点噪声的x_{t-Δt}。
关键的数学洞察是:当噪声步长σ足够小时,反向过程的条件分布p(x_{t-Δt}|x_t)也近似为高斯分布。这是一个非平凡的事实,我们将在下一节详细推导。这意味着,要学习反向过程,我们只需要学习这个高斯分布的均值即可,方差是已知的。而学习均值可以通过标准的回归问题来解决——这就将一个看似困难的生成建模问题转化为了一个熟悉的监督学习问题。
2.2 DDPM:随机反向过程的数学推导
去噪扩散概率模型(Denoising Diffusion Probabilistic Models, DDPM)是最经典的扩散模型算法之一。DDPM的核心是证明并利用这样一个事实:反向条件分布 p ( x t − Δ t ∣ x t ) p(x_{t-Δt}|x_t) p(xt−Δt∣xt)近似为高斯分布,且其均值可以表示为关于 x t x_t xt的简单函数。
我们从贝叶斯规则开始推导。对于任意两个相邻时刻t和t-Δt,贝叶斯规则告诉我们:
p ( x t − Δ t ∣ x t ) = p ( x t ∣ x t − Δ t ) ⋅ p ( x t − Δ t ) / p ( x t ) p(x_{t-Δt}|x_t) = p(x_t|x_{t-Δt})·p(x_{t-Δt}) / p(x_t) p(xt−Δt∣xt)=p(xt∣xt−Δt)⋅p(xt−Δt)/p(xt)
两边取对数:
l o g p ( x t − Δ t ∣ x t ) = l o g p ( x t ∣ x t − Δ t ) + l o g p ( x t − Δ t ) − l o g p ( x t ) log p(x_{t-Δt}|x_t) = log p(x_t|x_{t-Δt}) + log p(x_{t-Δt}) - log p(x_t) logp(xt−Δt∣xt)=logp(xt∣xt−Δt)+logp(xt−Δt)−logp(xt)
在这个推导中,我们将 x t x_t xt视为常数(因为我们要理解条件概率作为 x t − Δ t x_{t-Δt} xt−Δt的函数)。现在分析每一项。
第一项l o g p ( x t ∣ x t − Δ t ) og p(x_t|x_{t-Δt}) ogp(xt∣xt−Δt)来自前向过程,我们知道 x t = x t − Δ t + η x_t = x_{t-Δt} + η xt=xt−Δt+η,其中 η N ( 0 , σ 2 ⋅ Δ t ) η ~ N(0, σ²·Δt) η N(0,σ2⋅Δt)。因此:
l o g p ( x t ∣ x t − Δ t ) = − ∣ ∣ x t − x t − Δ t ∣ ∣ 2 / ( 2 σ 2 ⋅ Δ t ) + 常数 log p(x_t|x_{t-Δt}) = -||x_t - x_{t-Δt}||² / (2σ²·Δt) + 常数 logp(xt∣xt−Δt)=−∣∣xt−xt−Δt∣∣2/(2σ2⋅Δt)+常数
第二项 l o g p ( x t − Δ t ) log p(x_{t-Δt}) logp(xt−Δt)是边缘分布的对数密度。利用泰勒展开(假设 Δ t Δt Δt很小):
l o g p ( x t − Δ t ) ≈ l o g p ( x t ) + ∇ l o g p ( x t ) ⋅ ( x t − Δ t − x t ) + O ( Δ t ) log p(x_{t-Δt}) ≈ log p(x_t) + ∇log p(x_t)·(x_{t-Δt} - x_t) + O(Δt) logp(xt−Δt)≈logp(xt)+∇logp(xt)⋅(xt−Δt−xt)+O(Δt)
第三项 l o g p ( x t ) log p(x_t) logp(xt)在条件概率中只是一个常数(相对于 x t − Δ t x_{t-Δt} xt−Δt),可以忽略。
将这些项组合起来,并忽略高阶项 O ( Δ t ) O(Δt) O(Δt),我们得到:
l o g p ( x t − Δ t ∣ x t ) ≈ − ∣ ∣ x t − x t − Δ t ∣ ∣ 2 / ( 2 σ 2 ⋅ Δ t ) + ∇ l o g p ( x t ) ⋅ ( x t − Δ t − x t ) + 常数 log p(x_{t-Δt}|x_t) ≈ -||x_t - x_{t-Δt}||² / (2σ²·Δt) + ∇log p(x_t)·(x_{t-Δt} - x_t) + 常数 logp(xt−Δt∣xt)≈−∣∣xt−xt−Δt∣∣2/(2σ2⋅Δt)+∇logp(xt)⋅(xt−Δt−xt)+常数
整理得到:
l o g p ( x t − Δ t ∣ x t ) ≈ − ∣ ∣ x t − Δ t − μ ∣ ∣ 2 / ( 2 σ 2 ⋅ Δ t ) + 常数 log p(x_{t-Δt}|x_t) ≈ -||x_{t-Δt} - μ||² / (2σ²·Δt) + 常数 logp(xt−Δt∣xt)≈−∣∣xt−Δt−μ∣∣2/(2σ2⋅Δt)+常数
其中均值 μ = x t + σ 2 ⋅ Δ t ⋅ ∇ l o g p ( x t ) μ = x_t + σ²·Δt·∇log p(x_t) μ=xt+σ2⋅Δt⋅∇logp(xt)。这表明 p ( x t − Δ t ∣ x t ) p(x_{t-Δt}|x_t) p(xt−Δt∣xt)确实是高斯分布,其方差为 σ 2 ⋅ Δ t σ²·Δt σ2⋅Δt,均值包含了重要的项 ∇ l o g p ( x t ) ∇log p(x_t) ∇logp(xt),称为得分函数(score function)。
这个推导的美妙之处在于:只要我们能估计得分函数 ∇ l o g p ( x t ) ∇log p(x_t) ∇logp(xt),就能实现精确的反向过程。而得分函数可以通过以下关系与条件期望联系起来:
∇ l o g p ( x t ) = E [ x 0 − x t ∣ x t ] / ( t ⋅ σ 2 ) ∇log p(x_t) = E[x_0 - x_t | x_t] / (t·σ²) ∇logp(xt)=E[x0−xt∣xt]/(t⋅σ2)
这意味着,我们可以通过训练一个神经网络来预测 E [ x 0 ∣ x t ] E[x_0 | x_t] E[x0∣xt](给定噪声数据预测原始数据),然后利用上述公式计算得分函数。
import torch
import torch.nn as nn
class DDPMModel(nn.Module):
"""DDPM模型:预测E[x_0|x_t]"""
def __init__(self, unet_model):
super().__init__()
self.unet = unet_model # 通常是U-Net架构
def predict_x0(self, x_t, t):
"""预测原始数据x_0"""
# 将时间t编码为输入的一部分
return self.unet(x_t, t)
def compute_score(self, x_t, t, sigma):
"""计算得分函数"""
x0_pred = self.predict_x0(x_t, t)
score = (x0_pred - x_t) / (t * sigma**2)
return score
def reverse_step(self, x_t, t, dt, sigma):
"""单步反向去噪"""
# 计算均值
score = self.compute_score(x_t, t, sigma)
mean = x_t + sigma**2 * dt * score
# 添加噪声(除了最后一步)
if t > dt:
noise_std = sigma * torch.sqrt(torch.tensor(dt))
noise = torch.randn_like(x_t) * noise_std
x_prev = mean + noise
else:
x_prev = mean
return x_prev
训练DDPM模型的目标是最小化预测 x 0 x_0 x0与真实 x 0 x_0 x0之间的均方误差:
class DDPMTrainer:
"""DDPM训练器"""
def __init__(self, model, num_steps=1000, sigma=1.0):
self.model = model
self.T = num_steps
self.dt = 1.0 / num_steps
self.sigma = sigma
def training_loss(self, x0_batch):
"""计算训练损失"""
batch_size = x0_batch.shape[0]
# 随机采样时间步
t = torch.rand(batch_size) * (1 - self.dt)
t = t.reshape(-1, 1, 1, 1) # 广播到图像维度
# 采样噪声数据x_t
noise_std = self.sigma * torch.sqrt(t)
noise = torch.randn_like(x0_batch) * noise_std
x_t = x0_batch + noise
# 预测x_0
x0_pred = self.model.predict_x0(x_t, t)
# 计算MSE损失
loss = torch.mean((x0_pred - x0_batch)**2)
return loss
def train_step(self, x0_batch, optimizer):
"""单步训练"""
optimizer.zero_grad()
loss = self.training_loss(x0_batch)
loss.backward()
optimizer.step()
return loss.item()
这个训练过程的关键优势在于其简洁性——我们只需要训练一个标准的回归模型,预测给定噪声数据时的原始数据。不需要对抗训练(如GAN),也不需要复杂的变分推断(如VAE)。
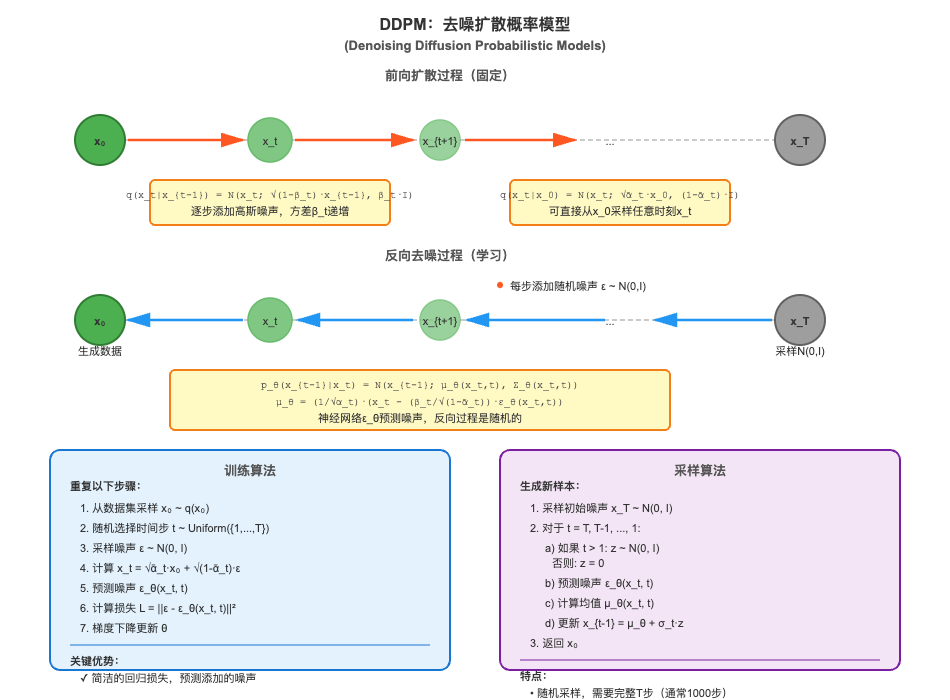
2.3 DDIM:确定性采样的优雅设计
去噪扩散隐式模型(Denoising Diffusion Implicit Models, DDIM)是DDPM的一个重要变体,它引入了确定性采样过程。DDIM的关键洞察是:我们可以构造一个确定性的反向过程,使得其边缘分布与DDPM的随机过程相同,但采样轨迹完全确定。
DDIM的确定性更新规则为:
x t − Δ t = √ ( α t − Δ t / α t ) ⋅ x t + ( √ ( 1 − α t − Δ t ) − √ ( α t ( 1 − α t − Δ t ) / α t ) ) ⋅ ε θ ( x t , t ) x_{t-Δt} = √(α_{t-Δt}/α_t) · x_t + (√(1-α_{t-Δt}) - √(α_t(1-α_{t-Δt})/α_t)) · ε_θ(x_t, t) xt−Δt=√(αt−Δt/αt)⋅xt+(√(1−αt−Δt)−√(αt(1−αt−Δt)/αt))⋅εθ(xt,t)
…详情请参照古月居

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 7
7 0
0- 0



 已为社区贡献142条内容
已为社区贡献142条内容

所有评论(0)