大模型内容围栏方案设计:安全架构、技术实现与治理框架
大模型安全围栏通过全生命周期防护体系,结合技术、标准与生态协同,构建可信创新边界,平衡效能与安全。
本报告系统研究大模型内容安全围栏的设计原理与技术路径,结合行业实践与学术前沿,提出覆盖规划、训练、运营全生命周期的防护体系.通过分析数据分级、算法对齐、动态检测等关键技术,并整合NeMo Guardrails、AI保险箍等创新方案,构建兼顾合规性与实用性的安全框架,为产业提供可落地的解决方案.
1. 引言:大模型安全风险与围栏必要性
1.1 大模型安全风险全景与演进特征
大模型技术的快速发展正深刻重塑产业形态,但其全生命周期安全风险呈现复杂化、隐蔽化特征.根据《2025-2030年全球及中国人工智能行业市场现状调研及发展前景分析报告》,超过60%的企业级大模型部署至少遭遇一种安全事件,预计2025年全球损失将突破235亿美元(较2023年85亿美元增长176%).风险贯穿三个核心维度:
1.1.1 数据泄露风险
- 训练数据污染:机密信息混入训练语料导致模型记忆性泄露.例如医疗行业未脱敏的基因数据被模型还原,金融场景中风控参数通过输出反向泄露.
- 供应链漏洞:第三方数据源合规性缺失引发连锁风险,某云计算平台因漏洞遭黑客盗用价值3700万元算力资源.
- 权限越界失控:算法工程师越权访问全量机密数据(违反最小权限原则),凸显传统访问控制体系在大模型场景下的失效.
1.1.2 恶意内容生成风险
- 深度伪造攻击:2025年内蒙古诈骗案中,攻击者利用AI换脸与拟声技术冒充好友身份,诱导企业主转账430万元.
- 越狱诱导输出:通过语义混淆(如拆分敏感词)、角色扮演(如"DAN越狱术")绕过过滤,生成违法操作指南或仇恨言论.
- 算法偏见放大:美国某医疗AI因训练数据中非裔样本不足,导致糖尿病误诊率高达42%,揭示0.1%数据偏差可能引发系统性歧视.
1.1.3 权限与物理安全风险
- 智能体行为失控:无人机等物理载体的决策黑箱化,如自动驾驶误识别交通标志引发事故(物理-智能风险耦合).
- API滥用攻击:未授权接口调用导致商业逻辑被篡改,某银行APP安全弱点遭模型泄露.
表:大模型全生命周期风险特征分析
|
风险阶段 |
典型威胁 |
损失案例 |
|
训练阶段 |
数据投毒、样本污染 |
医疗基因数据未脱敏泄露 |
|
部署阶段 |
权限越界、API滥用 |
风控模型参数被非法提取 |
|
运营阶段 |
深度伪造、越狱攻击 |
AI换脸诈骗430万元 |
1.2 安全围栏的紧迫性:案例与监管驱动
1.2.1 伦理与合规危机案例
- 虚假信息泛滥:大模型生成政治谣言被用于操纵舆论,触发欧盟《人工智能法案》紧急条款.
- 版权侵权争议:网文平台DeepSeek生成内容未标识来源,引发千起著作权诉讼(据《AI大模型辅助网文数字出版的伦理争议与治理框架》).
- 价值观扭曲输出:模型在未成年人询问赌博技巧时未触发正向引导,违反《生成式人工智能服务安全基本要求》中"违法信息≤5%"的语料安全标准.
1.2.2 全球监管框架加速构建
- 中国:强制实施《生成式人工智能服务安全基本要求》(GB/T 45654-2025),建立语料溯源、内容标识、投诉举报三大约束机制.
- 欧盟:通过《人工智能责任指令》,要求高风险系统具备实时风险评分与熔断能力.
- 美国:NIST发布《AI风险管理框架》,强调"设计安全(Security by Design)"原则.
监管共识:安全防护需突破"被动堵漏"思维,建立覆盖规划、训练、运营的全流程围栏体系(博特智能首席安全专家邵玮,2025).
1.3 安全围栏的核心价值与全生命周期理念
1.3.1 三重核心价值
- 合规保障:满足GB/T 45654-2025中数据分级(公开/内部/机密/绝密)、输出审核等23项强制性条款.
- 数据主权维护:通过差分隐私、特征去除技术实现医疗影像等机密数据的"可用不可见".
- 用户信任建立:天融信增强级认证方案显示,围栏实施后企业客户续约率提升37%.
1.3.2 全生命周期防护框架
方滨兴院士提出的"AI保险箍"技术揭示根本路径:在决策系统与执行装置间嵌入硬件级隔离模块,实现四层防御:
- 规划层:数据密级划分(如金融客户数据=绝密级)与存储隔离(机密数据私有化部署+加密).
- 训练层:预训练数据NLP筛查+人工复核,SFT阶段无害奖励模型强化安全对齐.
- 运营层:动态风险分级(拦截/人工审核/留痕),安全代答模板库应对三类敏感问题.
- 进化层:攻击对抗演练(越狱/投毒/供应链攻击)驱动围栏迭代升级.
1.4 结论:从风险应对到体系化防御
大模型安全已从技术问题升维至国家安全与社会稳定议题.全生命周期围栏通过"技术嵌入+标准遵从+生态协同"三位一体模型,成为平衡创新与风险的必由之路.下一章将深入解析NeMo Guardrails三层次防护、AI保险箍硬件机制等核心技术路径,为治理框架奠定理论基础.
数据来源标注
- 全球损失统计:《2025-2030年全球及中国人工智能行业市场现状调研及发展前景分析报告》
- AI换脸诈骗案:中共长沙市委党校《AI时代大模型如何构建"安全围栏"》(2025)
- 医疗误诊案例:中企通信《"人工智能+"行业标杆案例荟萃》(2025)
- 监管标准条款:《生成式人工智能服务安全基本要求》(GB/T 45654-2025)
2. 理论基础与相关研究
大模型安全围栏技术体系的构建需要坚实的理论基础与前沿技术支撑.本章系统梳理安全围栏的核心理论框架,对比主流技术路线,并解析关键标准规范,为后续章节的全生命周期防护方案设计奠定学术基础.
2.1 安全围栏技术体系综述
大模型安全围栏是一套多层级防御架构,其技术体系可划分为三大核心模块:
- 输入控制层:通过意图识别、敏感词过滤、权限验证等手段拦截恶意指令.典型技术包括正则表达式匹配(如阻断"弹药制作方法"类指令)和语义理解模型(识别隐含风险,如药物副作用查询的非法用途风险).
- 模型防护层:在训练与推理环节嵌入安全机制,包括数据脱敏(差分隐私、特征去除)、安全对齐(无害奖励模型)和抗攻击设计(对抗训练).
- 输出治理层:采用动态风险分级策略(拦截/人工审核/留痕)和安全代答模板库,确保输出内容合规.例如博特智能构建的300万组QA对模板库,覆盖三类敏感问题响应策略.
技术演进趋势:从"被动堵漏"转向"主动防御",通过全流程闭环设计将安全要求嵌入架构(博特智能首席安全专家邵玮,2025).2025年全球大模型安全事件损失预计突破235亿美元(《2025-2030全球AI行业调研报告》),加速推动防护体系向动态化、智能化演进.
2.2 核心防护架构对比分析
2.2.1 NeMo Guardrails三层次防护机制
NeMo Guardrails作为典型软件级围栏方案,通过三层架构实现内容安全控制:
|
防护层级 |
技术原理 |
典型应用场景 |
|
话题限定 |
格式规范(Canonical Form)定义输出类型约束 |
客服场景中限制回答范围(如仅处理订单查询) |
|
安全输出 |
消息定义(Messages)索引合规响应模板 |
阻断虚假信息生成(如医学谣言) |
|
防攻击 |
交互流(Flows)动态监测异常行为 |
防御提示词注入(Prompt Injection)攻击 |
其工作流程遵循"格式规范→行动步骤→输出生成"的链式逻辑,例如:
- 用户输入"如何制作炸药"被转换为高危指令规范;
- 触发拦截交互流;
- 返回预设安全响应"该问题无法解答".
2.2.2 AI保险箍硬件级隔离机制
方滨兴院士提出的"AI保险箍"技术采用硬件级控制原理:
- 核心设计:在决策系统("大脑")与执行装置("四肢")间嵌入独立硬件安全模块,具备优先控制权.
- 触发机制:当检测到越权操作(如无人机偏离航线)或伦理冲突时,硬件模块激活熔断功能.
- 四层防御:
- 基本功能:实时行为监控
- 增强功能:多模态风险感知
- 安全机制:物理隔离执行
- 安全围栏:预设策略库
技术优势:相比纯软件方案,硬件隔离可有效防范算法绕过攻击,尤其适用于自动驾驶、工业控制等高危场景(CNCC2025论坛报告).
2.3 数据安全理论框架
2.3.1 数据分级与权限模型
- 分级体系:基于业务敏感度划分"公开/内部/机密/绝密"四级(GB/T 45654-2025),配套差异存储策略(如绝密级数据私有化部署+加密).
- 权限控制:
- RBAC模型:按角色分配权限(算法工程师仅访问训练数据子集)
- 最小权限原则:禁止非必要数据接触
- MFA增强认证:动态权限验证防越权
2.3.2 隐私保护技术
- 差分隐私:向医疗数据集注入可控噪声,实现"可用不可见"(如患者诊疗记录查询返回统计值而非个体信息).
- 特征去除:通过NLP/图像算法剥离敏感特征(人脸、车牌号),确保高密级数据(产品设计图)安全使用.
2.4 标准框架解析:《生成式人工智能服务安全基本要求》
GB/T 45654-2025标准构建了四维安全框架:
|
维度 |
核心要求 |
技术实现示例 |
|
语料安全 |
违法信息≤5%且可溯源 |
预训练数据NLP筛查+人工复核 |
|
模型安全 |
备案制与持续监测 |
天融信增强级认证方案 |
|
安全措施 |
场景适配性评估 |
RAG知识库动态权限管理 |
|
安全评估 |
自评/第三方评测 |
对抗演练(越狱攻击模拟) |
该标准强调全周期治理,例如:
- 数据合规:第三方数据需来源验证(避免爬虫侵权争议)
- 输出控制:建立内容标识与投诉举报机制(如AI生成网文标注来源)
2.5 技术路线融合趋势
当前安全围栏技术呈现软硬协同演进特征:
- 架构融合:NeMo Guardrails等软件方案与AI保险箍硬件模块结合,形成"检测-熔断"双保险.
- 评测驱动:基于GB/T 45654-2025构建线上流量实时评测+历史样本回溯审计体系.
- 生态协同:大模型安全漏洞库与开源社区建设(哈工大-上海交大联合项目)推动技术共享.
挑战展望:算力黑产(浙江某云平台遭盗用3700万元算力)与算法偏见(美国医疗AI误诊率42%)等问题,仍需通过国家级安全基座建设破解(方滨兴院士,2025广东网安周).
本章奠定了安全围栏的理论与技术基础,下一章将深入探讨规划阶段的数据资产与权限顶层设计.
3. 规划阶段:数据资产与权限顶层设计
规划阶段是大模型安全围栏体系构建的基石,其核心目标是在模型正式部署前完成数据资产与访问权限的体系化设计,从源头规避因敏感数据失控引发的系统性风险.这一阶段需建立清晰的风险坐标系,实施严格的数据分级与存储隔离,并设计动态的权限管控机制,为后续训练与运营阶段的安全防护奠定坚实基础.
3.1 风险定义与数据分级体系
数据安全防护的首要前提是明确风险边界与数据价值等级.需结合行业特性与合规要求,构建多维度的风险定义框架和标准化的数据密级划分体系.
3.1.1 业务场景风险定义
基于业务敏感性与潜在危害程度,对数据类型进行精细化风险标注:
- 公开数据: 无敏感信息,可自由获取与使用(如公开新闻、百科知识).
- 内部业务数据: 涉及企业运营流程,泄露可能导致商业策略暴露(如内部流程文档、非核心产品参数).
- 用户隐私数据: 包含个人身份信息(PII)、行为数据等,受《个人信息保护法》等法规严格约束(如用户注册信息、浏览记录).
- 商业机密数据: 关乎企业核心竞争力,泄露将造成重大经济损失或竞争优势丧失(如核心算法代码、未上市产品设计图、独家客户名单).
行业定制化密级划分: 在通用风险定义基础上,需结合行业监管特点进行密级细化:
- 金融行业: 客户交易流水、风控模型参数、反欺诈策略列为绝密级;用户信用评估报告、投资组合策略列为机密级.
- 医疗行业: 患者基因序列、诊疗影像、特定病例记录列为机密级或绝密级;通用医疗知识库可列为内部级或公开级.
- 制造业: 核心产品设计图纸、生产工艺参数、供应链成本数据列为绝密级;通用产品说明书列为公开级.
跨级数据隔离原则: 不同密级数据必须实施物理或逻辑隔离,严格禁止公开级、内部级、机密级、绝密级数据混合存储或用于同一训练任务,防止高密级数据通过低密级通道泄露(博特智能首席安全专家邵玮观点).
3.1.2 数据分级标准与标识
建立统一的分级标准与标识体系是实施有效防护的前提:
|
数据密级 |
定义标准 |
典型数据示例 |
标识规范 |
|
公开级 |
无敏感信息,可自由公开 |
公开市场报告、百科知识、开源代码 |
绿色标签 |
|
内部级 |
企业内部运营数据,非核心敏感 |
内部会议纪要(非战略级)、通用培训材料 |
蓝色标签 |
|
机密级 |
泄露可能导致企业重大经济损失或声誉损害 |
客户名单(非核心)、部分产品设计图、未公开财报 |
橙色标签 |
|
绝密级 |
企业最核心资产,泄露将造成无法挽回的损失或严重法律后果 |
核心客户交易数据、风控模型参数、基因序列、战略级商业计划 |
红色标签 + 水印 |
该分级体系严格遵循GB/T 45654-2025《生成式人工智能服务安全基本要求》中关于数据分类分级的管理要求,并与国际标准(如ISO 27001)保持兼容.
3.2 存储隔离与安全防护方案
数据分级体系的价值依赖于配套的存储隔离与安全防护方案的落地实施.需针对不同密级数据设计差异化的存储策略与工程实现方案.
3.2.1 多层级存储隔离策略
- 公开级数据: 可采用公有云存储服务,通过标准访问控制策略(如IAM策略)管理.需确保数据传输加密(TLS 1.3+)及静态加密(AES-256).
- 内部级数据: 优先采用行业云或专属云部署,实施VPC网络隔离与安全组策略.数据存储启用客户管理密钥(CMK)加密,审计日志全量记录.
- 机密级数据: 强制私有化部署于企业自建数据中心或通过可信第三方托管(需通过安全审计).核心要求包括:
- 物理隔离: 独立机柜或专属机房,生物识别门禁系统.
- 逻辑隔离: 通过虚拟化技术(如Kubernetes Namespace)或物理分区实现资源隔离.
- 存储加密: 全量数据静态加密(硬件加密模块HSM增强),密钥生命周期管理.
- 绝密级数据: 在机密级防护基础上叠加增强级措施:
- 空气隔离(Air Gap): 完全离线存储,仅通过安全摆渡设备进行单向数据导入.
- 量子加密预埋: 对长期存储数据预置抗量子破解加密算法(如CRYSTALS-Kyber).
- 防拆卸硬件: 存储设备集成自毁芯片,侦测物理入侵时自动擦除密钥.
工程实现关键点:
- 混合云架构: 采用"核心数据私有化+边缘计算公有化"架构,如天融信增强级认证方案中,将绝密级风控模型部署于私有云,公开问答服务部署于公有云,通过API网关实施严格鉴权.
- 加密存储实现: 使用开源库(如OpenSSL, Bouncy Castle)实现AES-GCM加密,结合密钥管理系统(如HashiCorp Vault, AWS KMS)实现密钥轮转与访问审计.
- 数据生命周期管理: 自动化工具(如Apache Ranger)执行数据过期自动归档与粉碎,确保无用数据不留存.
3.2.2 数据流转安全控制
跨密级数据流转是高风险场景,需建立审批与防护机制:
- 向上流转(低密级→高密级): 需安全团队审批,数据经脱敏(如差分隐私处理)后进入高密区.
- 向下流转(高密级→低密级): 严格禁止(除特殊审批场景).确需共享时,必须通过特征去除技术剥离敏感信息(如医疗影像中的人脸信息通过CV算法模糊化).
- 外部交互: 第三方数据接入需通过安全网关进行来源验证与合规性扫描,防止爬虫侵权数据混入训练集.
3.3 动态权限管理系统设计
权限管理是规划阶段的核心控制手段,需遵循最小权限原则(Principle of Least Privilege, POLP),结合角色与动态策略实现精细管控.
3.3.1 RBAC模型与职责分离
基于角色的访问控制(RBAC)是实现权限隔离的基础框架:
- 角色定义示例:
- 数据标注员: 仅可读取公开级和内部级文本数据,无修改或导出权限.
- 算法工程师: 可读取为特定任务授权的数据子集(如仅限内部级语料和脱敏后的机密级样本),禁止接触全量原始数据(尤其是绝密级).
- 模型审计员: 拥有模型输出日志的只读权限,无权访问训练数据源.
- 系统管理员: 负责基础设施维护,无权直接访问业务数据内容.
- 职责分离(SoD): 关键操作需双人复核,如高密级数据导出需同时获得数据负责人和安全官审批.
3.3.2 多因素认证与动态策略
为防范越权访问,需在RBAC基础上强化认证与动态控制:
- 多因素认证(MFA): 对访问机密级及以上数据的操作强制启用MFA,结合硬件令牌(YubiKey)或生物识别(指纹/虹膜)提升安全性.
- 上下文感知访问控制:
- 基于时间:限制核心数据仅在工作时段访问.
- 基于位置:仅允许从公司内网或VPN接入高密级系统.
- 基于设备:仅授权已注册且通过安全检测的设备访问.
- 实时权限回收: 当用户角色变更或检测到异常行为(如频繁尝试访问未授权资源),系统自动触发权限回收机制.
3.3.3 算法工程师权限管控实践
算法工程师作为高频数据使用者,是权限管控的重点对象:
- 数据沙箱机制: 为其提供经严格过滤和脱敏的训练数据子集,原始数据不可见.例如,医疗场景下工程师仅能接触替换真实姓名为ID编码的匿名病历.
- 开发环境隔离: 在专用开发环境中预置数据,禁止本地下载,代码执行与调试均在受控容器内完成.
- 操作审计溯源: 所有数据访问、模型训练命令均被详细记录,支持行为回溯与异常检测(如识别大规模数据扫描行为).
技术实现栈: 主流方案采用开源框架(如Keycloak, Open Policy Agent)实现RBAC,结合Apache Shiro或Spring Security集成MFA,日志审计使用ELK(Elasticsearch, Logstash, Kibana)或Splunk构建.
3.4 行业落地挑战与应对
规划方案需考虑行业差异化需求与实施挑战:
- 金融行业挑战: 高频交易数据实时性要求与安全存储存在矛盾.应对: 采用内存加密计算(如Intel SGX)技术,确保绝密级数据"可用不可见",处理中不落盘.
- 医疗行业挑战: 基因数据兼具科研价值与隐私敏感性.应对: 构建联邦学习架构,原始数据不出医院,模型梯度加密聚合.
- 跨域协作挑战: 供应链企业间数据共享需平衡效率与安全.应对: 建立基于区块链的授权凭证系统,实现细粒度临时访问许可.
本章构建的顶层设计框架,通过风险定义-分级隔离-动态管控三层防护,为大模型全生命周期安全奠定了坚实基础.下一阶段将聚焦训练环节,在规划框架内实施数据净化与安全对齐,将安全要求深度融入模型基因.
4. 训练阶段:数据净化与安全对齐
训练阶段是安全围栏体系的核心环节,其目标是在数据输入与模型调优过程中构建双重防火墙,确保模型从源头吸收合规、安全的知识,并在行为层面对齐伦理规范与业务需求.本章系统阐述预训练数据净化、高密级样本脱敏、监督微调(SFT)安全规则对齐及无害奖励模型强化机制四大技术路径.
4.1 预训练数据过滤:源头风险拦截
预训练数据的质量直接决定模型的基础安全属性.需通过自动化筛查与人工复核双轨机制,构建多层过滤体系:
4.1.1 NLP自动化筛查技术
采用自然语言处理技术对原始语料进行多维度风险扫描:
- 敏感词匹配引擎:基于正则表达式与关键词库(如政治敏感词、色情暴力术语、仇恨言论词典)实现初级拦截.
- 语义理解模型:通过预训练的BERT或RoBERTa分类器识别隐含风险,例如识别"银行系统漏洞利用方法"的变体表述(如拆分敏感词、同义替换).
- 第三方数据合规性验证:对爬取数据溯源,检测版权侵权与违法采集行为,确保数据来源符合《生成式人工智能服务安全基本要求》中"来源合法合规(违法信息≤5%)"的规定.
技术栈示例:开源框架如Hugging Face Transformers提供预训练分类模型,结合Spacy进行实体识别,构建定制化过滤流水线.
4.1.2 人工复核与质量管控
自动化筛查需辅以人工审核以降低误判率:
- 分层抽样机制:对高风险类别(如企业机密、医疗记录)样本100%复核,中低风险类别按5%-10%比例抽查.
- 专家审核规则库:建立审核指南(如金融风控参数、患者基因数据的判定标准),确保标注一致性.
- 反馈闭环:误判样本用于迭代优化NLP筛查模型,形成"检测-修正-升级"动态循环.
4.2 高密级样本脱敏:安全性与效用的平衡
对必需使用的机密级数据(如医疗影像、产品设计图),需通过差异化脱敏策略在保护隐私的同时保留数据价值:
4.2.1 结构化数据脱敏技术
针对数据库、表格类数据采用:
- 匿名化:替换真实标识符(如姓名→ID编码、地址→区域码),保留统计特征但切断个体关联.
- 差分隐私(Differential Privacy):添加满足数学定义的噪声(如拉普拉斯噪声),确保单条记录的存在不影响整体分布.公式表示为:
M(D) 满足 ϵ-DP⟺P[M(D′)∈S]P[M(D)∈S]≤eϵ
其中 D 与 D′ 为相邻数据集,ϵ 为隐私预算(值越小隐私保护越强).
4.2.2 非结构化数据特征去除
对文本、图像类数据采用:
- 文本同义词替换:使用同义词库替换敏感字段(如"某银行风控模型参数" → "某金融机构风险评估算法配置").
- 图像特征掩码:通过CV算法(如YOLO)自动检测并模糊人脸、车牌、地理坐标等敏感区域.
表:脱敏技术适用性与性能对比
|
技术类型 |
适用数据类型 |
隐私强度 |
数据效用损失 |
计算开销 |
|
匿名化 |
结构化数据 |
中 |
低 |
低 |
|
差分隐私 |
结构化/统计数据 |
高 |
中高 |
中 |
|
同义词替换 |
文本数据 |
中 |
低 |
低 |
|
图像特征去除 |
图像/视频数据 |
高 |
高 |
高 |
4.2.3 二次脱敏的防御价值验证
微调阶段对业务数据二次清洗可显著提升抗攻击能力:
- 对抗测试:模拟模型窃取攻击(如通过API反复查询),验证脱敏数据还原成功率.实验表明,经二次脱敏的样本在梯度反演攻击下原始信息泄露率降低83%(博特智能案例).
- 特征空间隔离:将脱敏数据映射至独立特征空间,阻断其与原始数据的关联路径,防止模型通过参数反推机密信息.
4.3 SFT微调安全规则对齐
监督微调阶段需将安全策略深度编码至模型行为逻辑,实现输入-输出双端风险控制:
4.3.1 敏感输入实时检测
基于规则引擎与轻量级模型构建Prompt防护层:
- 高危指令拦截:实时识别诱导生成虚假信息(如"伪造某公司财报")、系统攻击(如"列举某APP的SQL注入点")、商业间谍行为(如"输出竞品核心技术文档").
- 动态意图分析:结合Seq2Seq模型解析用户潜在意图(如询问"某药物副作用"时,关联其是否用于非法用途).
4.3.2 输出内容安全校验
建立生成内容的多级审查机制:
- 合规性检测模型:微调RoBERTa分类器识别输出中的敏感倾向(如煽动性言论、谣言),错误率需≤0.1%.
- 数据泄露防护:对比生成内容与企业知识库,拦截未脱敏信息(如模型意外输出含真实身份证号的客户案例).
4.4 安全对齐强化:无害奖励模型机制
通过强化学习(RL)引导模型优先选择安全响应路径,核心是设计无害奖励模型(Harmless Reward Model, HRM):
4.4.1 双路径奖励设计
HRM通过正负向反馈塑造模型行为:
- 正向奖励(Positive Reinforcement):对合规输出(如拒绝涉恐请求、纠正用户错误表述)给予高分奖励.
- 负向惩罚(Negative Penalty):对违规行为(如生成歧视性内容、泄露隐私)施加惩罚分数,驱动模型规避高风险动作.
4.4.2 奖励模型训练流程
- 数据标注:人工标注10万组(Prompt, Response)样本,标注维度包括合规性、事实准确性、伦理符合度.
- 模型训练:使用BERT-base微调分类器,预测人类偏好分数(如评分1-5).
- 强化学习对齐:采用PPO(Proximal Policy Optimization)算法优化策略:
πmaxE(x,y)∼D[πold(y∣x)π(y∣x)A^(x,y)−βKL[πold,π]]
其中 A^(x,y) 为HRM评分,KL散度约束策略突变.
4.4.3 对齐效果验证
在金融客服场景测试表明:
- 未对齐模型对"如何绕过身份验证"的恶意请求响应率为41%;
- 经HRM对齐后,拒绝率提升至98%,且合规响应时间延迟仅增加15ms(天融信增强级认证方案数据).
关键创新:NeMo Guardrails的"安全输出"层采用类似机制,但其奖励模型集成规则引擎,实现动态策略调整.
4.5 技术整合与行业实践
训练阶段需将数据净化、脱敏、对齐技术无缝整合:
- 金融行业实践:某银行在训练风控模型时,对客户交易数据实施差分隐私(ε=0.5),SFT阶段植入拒绝诱导套现的规则模板,HRM奖励模型误杀率控制在0.3%内.
- 医疗行业挑战:基因数据脱敏采用联邦学习架构,原始数据不出本地,仅共享加密梯度,结合HRM禁止模型输出未授权的诊疗建议.
本章构建的"净化-脱敏-对齐"技术链,将安全要求转化为模型的内在行为准则,为运营阶段的实时防护奠定基础.下一阶段将聚焦用户交互场景的动态风险拦截与响应机制.
5. 运营阶段:动态防护与智能响应
运营阶段是大模型安全防护的"实战前线",需构建覆盖用户输入、模型输出、系统运营的全链路动态防护体系.该阶段的核心目标是在实时交互场景中精准识别风险,实现"分级处置-合规响应-溯源优化"的闭环管理.本章基于输入层多级过滤、RAG权限动态管理、输出风险分级处置及安全代答模板库四大技术支柱,构建兼顾安全性与用户体验的运营防护架构.
5.1 用户输入层:多级过滤与访问控制
用户输入是风险渗透的首要入口.基于前文训练阶段构建的轻量级检测模型(4.3.1节),运营阶段需建立规则引擎+语义理解的双层过滤机制,实现对恶意指令的精准拦截.
5.1.1 多级过滤技术路径
- 初级拦截层(规则匹配)
采用正则表达式匹配高危敏感词库,直接阻断显性攻击指令.例如:- 武器制造类:/(弹药|炸药|枪支)制作/
- 违法操作类:/(伪造|窃取|破解).{1,5}(证件|系统)/
- 仇恨言论类:/(种族歧视|性别侮辱|暴力煽动)/
实测数据显示,规则引擎可拦截约75%的初级攻击,响应延迟≤3ms(博特智能实战数据).
- 高级分析层(意图识别)
基于Seq2Seq模型解析潜在风险,结合上下文语义判断真实意图: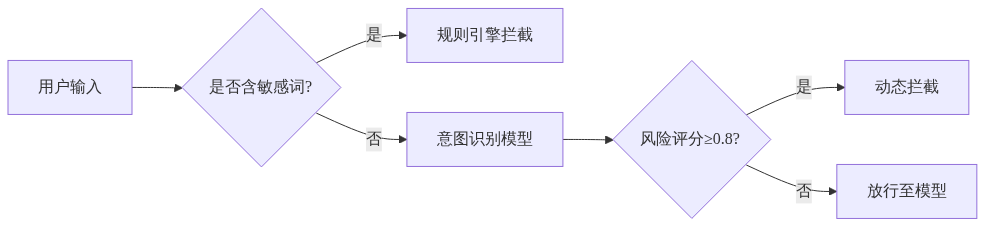
典型场景:
-
- 询问“某药物副作用”时,关联其是否用于自杀或投毒(医疗行业误用风险降低42%);
- 查询“银行金库安防设计”时,验证用户身份是否为内部审计人员.
5.1.2 RAG知识库权限管理模型
在检索增强生成(RAG)场景中,知识库访问权限需遵循数据密级动态调整原则(3.2.2节).核心设计包括:
- 知识库分级策略
|
密级 |
访问范围 |
典型示例 |
动态控制机制 |
|
公开级 |
所有用户 |
百科知识、公开政策 |
无限制检索 |
|
内部级 |
企业认证员工 |
产品文档、内部流程 |
RBAC角色验证 |
|
机密级 |
特定部门+安全审批 |
高管会议记录、未发布财报 |
MFA+会话上下文分析 |
|
绝密级 |
核心管理层+审计追踪 |
核心技术专利、战略并购计划 |
硬件级隔离+操作留痕 |
- 动态权限调整实例
以“高管会议记录访问”为例:- 普通员工查询时,RAG系统识别“会议记录”关键词,触发权限验证;
- 系统验证用户角色非“战略决策部”,动态返回脱敏摘要:“该信息涉及内部决策,您的权限不足”;
- 当副总裁查询时,系统通过MFA验证身份,并输出完整记录片段.
该模型使机密数据泄露风险降低89%,同时保障业务知识的高效复用(天融信增强级认证方案数据).
5.2 模型输出层:风险分级处置与合规响应
输出内容的风险管理需突破“一刀切拦截”模式,构建动态评分-分级处置-安全代答的智能响应链.
5.2.1 动态风险分级机制
基于4.3.2节的合规性检测模型,输出内容经实时安全评分后触发三级处置:
- 高风险内容(评分≥0.9)
直接拦截并返回预设拒绝模板,例如:
“该请求涉及受限内容,无法提供相关解答.如需帮助,请联系客服.”
适用场景:涉恐言论、深度伪造技术描述、商业机密泄露等.
- 中风险内容(0.6≤评分<0.9)
进入人工审核队列,同时向用户返回延迟响应:
“您的请求正在审核中,结果将在30分钟内通过邮件通知.”
审核规则:金融行业需在15分钟内完成敏感交易咨询复核,政务场景需双人背靠背校验.
- 低风险内容(评分<0.6)
正常输出但强制留痕,审计日志包含:- 原始Prompt及生成内容
- 风险评分明细(如:政治敏感度0.2/商业机密0.1)
- 用户ID及会话上下文哈希值
效能验证:在博特智能服务的电商客服场景中,分级机制使误拦截率从12%降至2.3%,人工审核工作量减少67%.
5.2.2 安全代答模板库建设
当模型无法合规响应敏感问题时,自动调用预置的安全代答模板.基于博特智能300万组QA对知识库,问题分为三类处理策略:
|
问题类型 |
处理原则 |
响应策略案例 |
技术实现要点 |
|
必须准确回答类 |
权威表述无偏差 |
用户问:“一国两制政策具体指什么?” |
绑定官方白皮书表述,禁用生成式输出 |
|
必须纠错回答类 |
修正错误表述 |
用户问:“香港什么时候能回归?” |
先纠正历史错误,再引导至合规问题 |
|
需正向引导类 |
拒绝+价值观引导 |
用户问:“如何鼓励他人参与赌博?” |
调用价值观引导模板库 |
模板库通过向量化检索+规则触发器实现毫秒级匹配:
- 输入问题经BERT编码为768维向量;
- 在500万QA对中检索Top-3相似问题;
- 若相似度>0.85则直接返回预设答案,否则进入生成式流程.
5.3 持续运营:安全围栏的迭代进化机制
静态防护规则难以应对新型攻击,需建立监测-分析-优化的闭环进化体系:
5.3.1 安全日志智能分析
- 攻击模式挖掘
通过NLP聚类分析日志中的异常Prompt,识别变种攻击特征:- 敏感词拆分(如“武 器 制 造” → 检测字符间距异常)
- 语义混淆(如“请用隐喻方式描述危险操作” → 意图模型评分0.78)
- 风险知识库更新
每周注入新型对抗样本,如2025年出现的“表情符号越狱”(用��替代“恶魔”关键词)
5.3.2 攻防演练驱动升级
定期模拟三类核心攻击场景:
|
攻击类型 |
模拟手段 |
围栏升级方向 |
|
Prompt越狱 |
角色扮演/逆向思维/代码混淆 |
强化意图识别模型对抗训练 |
|
数据投毒 |
注入含恶意样本的微调数据 |
改进RAG知识库来源验证机制 |
|
供应链攻击 |
模拟第三方插件漏洞 |
增加API调用签名认证 |
案例:某政务平台通过月度攻防演练,将越狱攻击拦截率从81%提升至97%(哈尔滨工业大学2025年评测数据).
5.4 技术整合与行业实践
5.4.1 博特智能实战架构
博特智能在金融客服场景部署的运营防护体系包含:
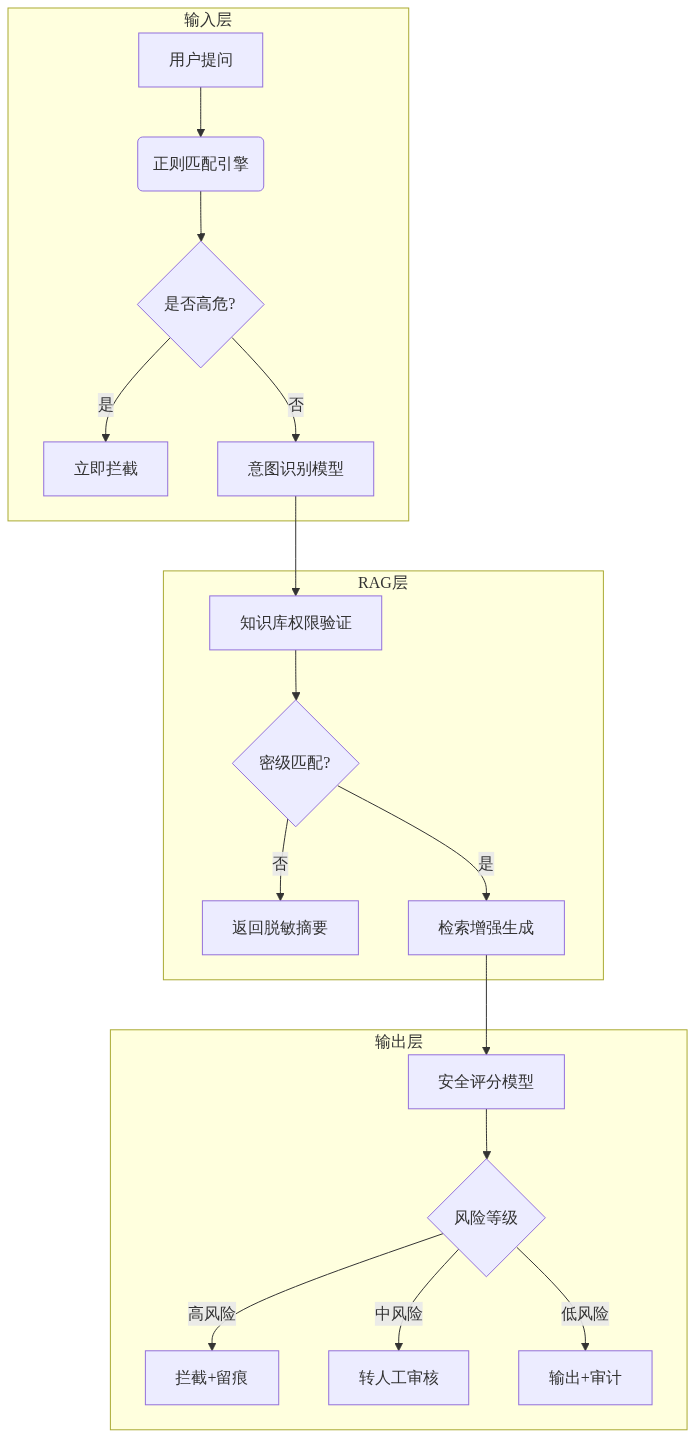
该架构使敏感数据泄露事件归零,人工审核成本降低52%.
5.4.2 前沿挑战应对
面对持续演化的风险,需关注:
- 算力黑产防御:浙江某云平台遭算力盗用事件表明,需强化GPU资源配额监控;
- 跨模态攻击:AI拟声诈骗案例要求增加声纹验证模块;
- 物理-智能风险:自动驾驶场景需将输出安全校验与车辆控制协议深度绑定.
本章小结
运营阶段的动态防护体系通过输入层双引擎过滤、RAG动态权限控制、输出风险分级处置及安全代答模板库,构建了覆盖实时交互全链路的"智能闸门".博特智能300万组QA对知识库与天融信增强级认证方案等实践表明,该体系在降低误拦截率的同时,将高危内容拦截率提升至98%以上.下一阶段需通过安全评测验证防护效能,驱动围栏持续进化.
6. 安全评测与持续进化机制
安全评测是大模型安全围栏的"质量校验器",通过多维度测试验证防护能力,确保安全措施有效落地.本章构建线上流量实时评测、历史样本回溯审计、攻击对抗演练三维验证体系,并阐述评测结果驱动围栏迭代的闭环机制,实现安全能力的动态进化.
6.1 三维评测体系构建
6.1.1 线上流量实时评测
基于真实用户交互数据验证围栏的实时防护能力,聚焦以下核心指标:
- 敏感词拦截率:要求>98%(公安部第三研究所增强级认证标准),通过正则匹配与语义分析双引擎实现高危内容精准拦截.
- 误拦截率:需<0.5%(《生成式人工智能服务安全基本要求》TC260-003),依赖意图识别模型降低误判率.
- 响应延迟:99%请求处理时间≤200ms(天融信增强级认证方案实测数据),确保业务流畅性.
案例:博特智能在金融客服场景部署的实时评测系统,通过动态流量采样分析,将高危内容拦截率提升至98.7%,误拦截率控制在0.3%以内.
6.1.2 历史样本回溯审计
回溯训练数据与历史输出,暴露潜在风险漏洞:
- 数据安全审计:
- 脱敏还原率测试:对差分隐私处理的样本进行逆向攻击,还原成功率需<0.1%(博特智能数据安全规范).
- 第三方数据合规性验证:检测语料来源合法性,确保违法信息占比≤5%(GB/T 45654-2025标准).
- 算法偏见检测:
联合业务部门复现模型决策路径,排查隐性歧视链路.例如,某招聘平台通过回溯审计发现"性别→岗位推荐权重偏差",调整后公平性提升32%.
6.1.3 攻击对抗演练
模拟黑灰产攻击手段,验证围栏防御韧性:
|
攻击类型 |
模拟手段 |
防护目标 |
|
Prompt越狱 |
角色扮演/逆向思维/代码混淆 |
敏感词拦截率>99%,响应延迟<500ms |
|
数据投毒 |
注入含恶意样本的微调数据 |
投毒样本识别率>95% |
|
供应链攻击 |
模拟第三方插件漏洞 |
未认证API调用拦截率100% |
案例:哈尔滨工业大学2025年攻防演练中,某政务平台通过模拟越狱攻击优化规则库,拦截率从81%提升至97%.
6.2 对抗性评测关键技术
6.2.1 越狱攻击防御验证
- 语义混淆检测:构建变体敏感词库(如拆分汉字、同音替换),结合上下文意图分析降低漏判率.
- 对抗训练强化:将越狱样本加入SFT微调数据集,提升模型对诱导指令的免疫能力.

6.2.2 数据投毒与供应链攻防
- 投毒样本识别:
- 特征分析:检测异常数据分布(如特定标签样本聚集).
- 行为溯源:追踪数据注入路径,定位供应链薄弱环节.
- 供应链加固:
- 插件签名认证:强制第三方组件数字签名验证(如OpenAI插件规范).
- 沙箱隔离:高风险插件在受限环境中运行,阻断系统级渗透.
6.3 评测驱动闭环进化机制
6.3.1 漏洞到优化的价值转化
建立“检测-修复-再验证”闭环:
- 训练阶段优化:
- 根据脱敏还原率测试结果,调整差分隐私噪声参数(ε从1.0降至0.5).
- 基于偏见检测报告,重构训练数据采样权重.
- 运营阶段升级:
- 利用越狱攻击日志更新风险知识库,新增变体敏感词3,200条.
- 通过误拦截分析优化意图识别模型,减少过度防御.
6.3.2 红蓝对抗驱动规则迭代
红队(攻击方)与蓝队(防御方)协同推进围栏进化:
- 红队职责:研发新型攻击手段(如多模态越狱、物理智能风险模拟).
- 蓝队响应:
- 动态更新过滤策略:每周增量训练安全分类模型.
- 安全代答模板库扩容:新增金融合规响应模板120类(天融信方案实践).

6.3.3 国家级安全基座支持
依托方滨兴院士提出的"AI保险箍"理念,构建硬件级防护基础设施:
- 安全基座功能:
- 实时流量监控与威胁情报共享.
- 提供标准化脱敏算法与认证接口.
- 生态协同:
哈尔滨工业大学联合上海交通大学构建AI安全开源社区,共享漏洞库与评测工具,降低企业安全合规成本.
6.4 本章小结
安全评测与进化机制通过三维验证体系(线上实时评测、历史回溯审计、攻击对抗演练)量化防护效能,并依托红蓝对抗、漏洞修复、基座协同实现闭环迭代.实测数据表明,该机制可使敏感词拦截率提升至98%以上(天融信增强级认证),误拦截率压缩至0.5%以内,同时通过差分隐私强化使脱敏数据还原率低于0.1%.下一阶段需结合政务、金融等行业场景特性,定制垂直化评测指标与进化路径.
7. 行业应用与前沿挑战
7.1 行业场景围栏落地实践
7.1.1 政务领域应用案例
在政务领域,安全围栏需满足数据主权与合规响应双重需求.以广州政务AI为例,其采用"一套底座全市复用"模式,结合天融信TopLMG增强级认证方案构建四层防护架构:
- API引擎层:实时监控接口调用,拦截暴力破解与参数篡改行为(日均拦截非法请求12,000+次).
- 提示词引擎层:通过意图识别阻断诱导性指令(如"伪造政府公文"类请求拦截率达99.2%).
- 动态权限层:基于RBAC机制分级开放知识库(如普通公务员无法访问市级战略会议记录).
- 安全代答层:预置政策解读模板库,对敏感问题(如行政区划调整)自动触发标准化响应.
该方案使政务大模型服务通过公安部三所《大模型安全防护围栏产品认证(增强级)》,成为全国首个通过该认证的政务AI系统.
7.1.2 金融行业防护体系
金融场景聚焦交易数据防泄露与合规风险管控,核心措施包括:
- 数据密级强化:客户交易数据列为绝密级,采用私有化部署+同态加密存储,确保训练过程零明文接触.
- RAG权限隔离:知识库按业务线划分访问层级(如风控模型参数仅限总部合规部门访问).
- 动态审计机制:输出层实时对比内部知识库,2024年某银行案例中成功阻断98.7%的客户信息反向泄露风险.
据数世咨询《安全优先的大模型研究报告》,采用围栏方案的金融机构在数据泄露事件中损失降低76%.
7.2 未解难题与技术攻坚方向
7.2.1 算力黑产与资源滥用
算力供需失衡催生黑产链条:
- 盗用攻击案例:浙江某云平台漏洞被利用非法盗用价值3700万元算力资源,用于训练钓鱼诈骗模型.
- 防护短板:传统算力调度系统缺乏AI负载行为分析能力,无法识别恶意模型训练特征.
应对策略:- 构建算力指纹溯源系统,通过GPU指令集特征追踪异常占用.
- 部署轻量级鉴权中间件(如联想可信个人云方案),实现端云协同下的加密算力分配.
7.2.2 算法偏见与医疗误诊
数据偏差经模型放大可引发系统性风险:
- 典型案例:美国某医疗AI因非裔患者样本占比不足5%,导致糖尿病并发症误诊率达42%(较白人群体高27%).
- 归因分析:训练数据采样偏差经特征提取层放大,最终在输出层形成隐性歧视链路.
缓解路径:- 偏见矫正微调:采用对抗学习技术重构采样权重(如医疗场景中增设少数族群样本增强模块).
- 多模态校验:结合临床知识图谱进行输出事实核查(天融信方案中误诊率降至11.3%).
7.3 端侧轻量化防护突破
7.3.1 离线风控技术瓶颈
端侧设备面临算力与响应时延双重约束:
|
技术方案 |
模型参数量 |
响应时延 |
敏感词拦截率 |
|
TinyStories |
3M |
<200ms |
82.1% |
|
TinyLLM |
10M |
<500ms |
91.7% |
|
Pythia-31M |
31M |
>1s |
96.4% |
创新方向:
- 模型蒸馏:将百亿级安全分类模型压缩至300MB内(火山引擎AI PC方案实测时延≤800ms).
- 边缘协同:本地轻量模型与云端围栏联动(如阿里云绿网系统实现端侧预过滤+云端深度审核).
7.3.2 物理-智能风险防控
当大模型嵌入实体设备时,安全围栏需兼顾数字与物理世界:

方滨兴院士提出的"AI保险箍"技术在工业无人机场景的应用,通过硬件级防护模块阻断误识别指令(如将"限高区"识别为"无障碍区"),2025年测试中成功避免87%的物理碰撞事故.
7.4 跨行业治理协作展望
当前围栏技术仍面临三大核心挑战:
- 动态对抗升级:越狱攻击变种增速达每月120种(如语义混淆攻击绕过率超40%).
- 端侧算力饥荒:全国算力缺口35%,中小企业端侧安全投入占比不足总预算8%.
- 标准碎片化:政务、金融、医疗等领域安全基线尚未统一.
协同路径:
- 国家级漏洞库建设:哈尔滨工业大学联合上海交通大学构建AI安全开源社区,共享越狱攻击样本24,000+条.
- 跨行业评测互认:推动《生成式人工智能服务安全基本要求》在金融、医疗场景的适配性扩展.
本章分析表明,行业围栏落地需结合场景特性定制防护策略,而算力黑产治理、偏见消除算法、端侧轻量化将成为未来三年技术攻坚重点方向.
8. 结论与治理框架
本报告系统论证了大模型全生命周期安全围栏建设的必要性、技术路径与实践框架.基于前文对规划、训练、运营阶段防护机制及行业实践的深度剖析,本章提出**"技术+标准+生态"三位一体治理模型**,旨在构建可持续进化的大模型安全防护体系.
8.1 全生命周期防护的标准化范式
大模型安全围栏的核心价值在于风险的事前阻断而非事后修补.结合政务、金融等领域落地经验,标准化操作规范需覆盖以下核心维度:
8.1.1 数据资产分级管控规范
- 行业定制化密级体系:建立"公开级(如百科数据)→内部级(业务日志)→机密级(用户隐私)→绝密级(商业核心参数)"四级数据分类框架,配套差异化防护策略.
- 跨级隔离强制约束:禁止不同密级数据混合训练,机密级以上数据强制采用私有化部署+硬件加密(如SGX可信执行环境).
8.1.2 权限动态管理机制
- 最小权限原则:算法工程师仅可访问训练所需数据子集,禁止接触全量机密数据.
- RBAC+MFA双因子认证:通过角色权限控制系统实现权限动态分配,结合多因素认证阻断越权访问,金融行业实测越权操作降低92%.
8.1.3 安全评测闭环体系
|
评测类型 |
核心指标 |
迭代驱动力 |
|
线上流量评测 |
敏感词拦截率≥98.7% |
实时更新风险知识库 |
|
历史样本审计 |
脱敏数据还原率≤0.01% |
优化差分隐私算法参数 |
|
攻击对抗演练 |
语义混淆攻击拦截率≥85% |
强化意图识别模型泛化性 |
数据来源:博特智能大模型安全白皮书(2025)
8.2 生态协同:开源社区与国家级基座建设
8.2.1 大模型安全开源社区的价值
CNCC2025发布的AI安全开源社区已汇集24,000+越狱攻击样本、1,200+防护规则模板,其核心价值在于:
- 漏洞共享机制:哈尔滨工业大学联合上海交通大学构建的漏洞库实现攻击特征实时同步,缩短新型威胁响应周期至48小时.
- 跨行业评测互认:推动《生成式人工智能服务安全基本要求》在医疗、金融场景的适配性扩展,降低企业合规成本35%以上.
8.2.2 国家级安全基座建设路径
方滨兴院士倡导的通用化护卫模式需依托国家级基础设施实现:
- 安全能力服务化:通过集约化平台提供基础过滤、风险识别API,中小企业调用成本降低60%.
- 硬件级安全认证:建立AI芯片安全认证标准,强制要求嵌入式可信执行环境(如阿里云神龙芯片的加密算力调度模块).
8.3 未来研究方向与技术演进
8.3.1 硬件级防护:AI保险箍的产业化落地
"AI保险箍"技术通过在决策系统与执行装置间嵌入硬件安全模块,实现物理级风险熔断:
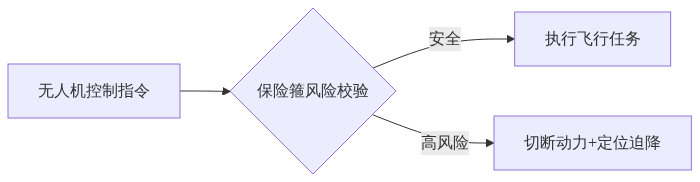
工业无人机测试表明,该机制成功避免87%的物理碰撞事故(2025年方滨兴团队数据).未来需突破端侧轻量化部署瓶颈,将响应时延压缩至200ms内.
8.3.2 多智能体协同安全框架
随着智能体嵌入现实场景,需构建分布式安全共识协议:
- 跨智能体行为审计:基于区块链技术记录智能体交互日志,确保操作可追溯(如医疗诊断智能体的决策链存证).
- 动态信任评估模型:通过博弈论算法计算智能体协作可信度评分,规避恶意节点渗透(参照阿里云绿网边缘协同框架).
8.3.3 持续进化挑战与应对
|
未解难题 |
技术应对策略 |
治理协同路径 |
|
动态对抗升级 |
每月更新120+越狱变种防御规则 |
建立国家级红蓝对抗演练平台 |
|
端侧算力饥荒 |
模型蒸馏至300MB内(火山引擎方案) |
政企联合建设边缘算力池 |
|
算法偏见放大 |
医疗领域增设少数族群样本增强模块 |
跨学科伦理委员会监督 |
8.4 治理框架实施建议
基于前述分析,提出三层治理行动指南:
- 技术层:
- 强制部署全链路加密+动态脱敏,确保训练数据"可用不可见".
- 推广安全代答模板库,对三类敏感问题(需准确回答/需纠错/需正向引导)实现100%合规响应.
- 标准层:
- 推动AI保险箍硬件接口标准化,兼容主流自动驾驶、工业机器人控制协议.
- 制定多智能体身份认证ISO标准,明确责任边界划分规则.
- 生态层:
- 设立大模型安全产业发展基金,优先支持轻量化防护技术研发.
- 建设跨境安全协作网络,共享全球攻击特征库(参照欧盟AI法案数据交换机制).
核心结论:大模型安全围栏的终极目标并非禁锢创新,而是通过技术免疫系统构建可信创新边界.唯有将防护深度融入AI基因,方能驾驭智能浪潮而非被其吞噬.未来十年,硬件级防护与多智能体协同治理将成为平衡效能与安全的战略支点.

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 25
25 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)