LongCat-Flash-Chat:高效智能体大语言模型
LongCat-Flash-Chat 重新定义了高效大模型的技术路线——不是盲目堆砌参数,而是通过精巧架构、严谨训练与目标导向优化,在计算效率与模型能力间取得最优平衡。其开源(MIT 许可证)将加速智能体技术在各行各业的落地,推动 AI 从"语言模型"迈向"行动智能"的新阶段。
文章优先更新在微信公众号——“LLM大模型”,有些文章未来得及同步,可以直接关注公众号查看
LongCat-Flash-Chat 重新定义了高效大模型的技术路线——不是盲目堆砌参数,而是通过精巧架构、严谨训练与目标导向优化,在计算效率与模型能力间取得最优平衡。其开源(MIT 许可证)将加速智能体技术在各行各业的落地,推动 AI 从"语言模型"迈向"行动智能"的新阶段。
LongCat-Flash-Chat 是一款强大且全能的模型,它在多个领域表现出卓越的性能优势。
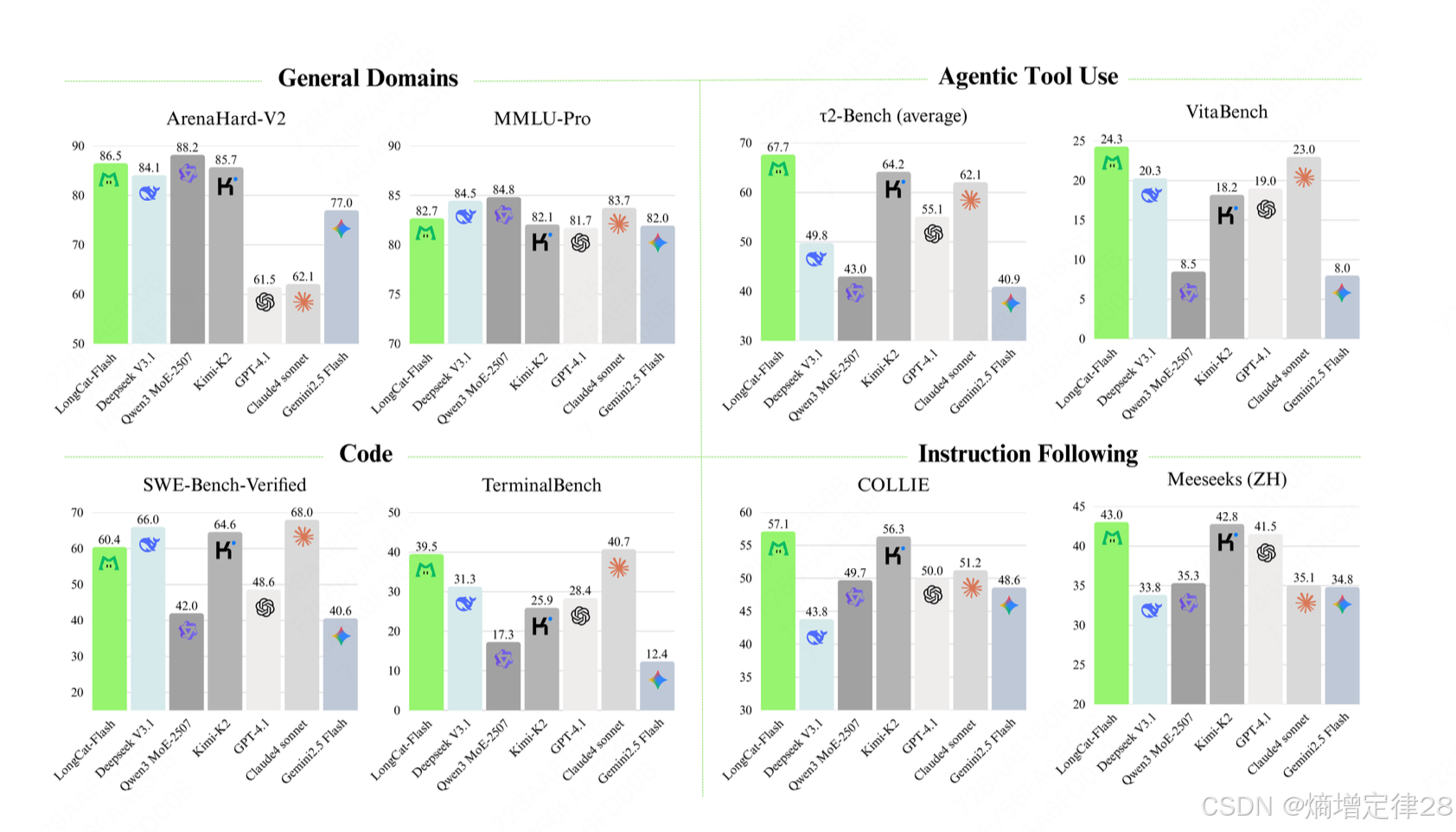
一、 超越参数规模的高效智能
1.1 背景与挑战
当前大语言模型(LLMs)正面临三大核心挑战:
- 计算效率瓶颈:模型参数量呈指数级增长,但推理成本与延迟也随之飙升,限制实际部署;
- 能力专业化不足:通用模型在智能体(Agentic)任务(如工具调用、环境交互)上表现不稳定;
- 训练稳定性问题:超大规模模型训练极易出现损失震荡、收敛失败或静默数据损坏(SDC)。
智能体(Agent):指能够感知环境、做出决策并执行行动以达成目标的AI系统。在LLM语境下,"Agentic能力"特指模型调用工具、规划步骤、反思修正的能力。
1.2 LongCat-Flash-Chat 的核心目标
LongCat-Flash-Chat 由美团 LongCat 团队研发,定位为 “非思考型基础模型”(non-thinking foundation model),旨在:
- 以更少激活参数实现更强性能:在非思维链(non-CoT)模式下提供高质量响应;
- 原生支持智能体行为:无缝集成工具调用、状态跟踪与多步规划;
- 实现工业级部署效率:推理吞吐 >100 tokens/秒,支持万卡集群训练;
- 开源开放:以 MIT 许可证发布全部权重与代码,促进社区创新。
1.3 模型概览
LongCat-Flash-Chat 重新定义了高效大模型的技术路线——不是盲目堆砌参数,而是通过精巧架构、严谨训练与目标导向优化,在计算效率与模型能力间取得最优平衡。其开源(MIT 许可证)将加速智能体技术在各行各业的落地,推动 AI 从"语言模型"迈向"行动智能"的新阶段。
| 属性 | 数值/描述 |
|---|---|
| 总参数量 | 560 亿(560B) |
| 每token激活参数 | 18.6B–31.3B(平均 27B) |
| 架构类型 | 稀疏激活混合专家(Sparse MoE) |
| 上下文长度 | 128K tokens |
| 训练设备规模 | >10,000 加速器 |
| 推理速度 | >100 tokens/秒(A100 80GB) |
1.4 LongCat-Flash-Chat 核心技术突破
| 突破领域 | 核心创新 | 关键指标 | 技术价值 |
|---|---|---|---|
| 架构设计 | 零计算专家 + PID 控制 | 激活参数 27B/560B | 计算效率提升 40%+ |
| 通信优化 | ScMoE 架构 | 万卡扩展效率 81% | 首个开源万卡级 MoE |
| 训练框架 | 代理模型超参迁移 | 0 次不可恢复故障 | 降低 40% 训练成本 |
| 能力构建 | 多智能体合成框架 | τ²-Bench 67.65 | 开源最强 Agentic 模型 |
| 评估体系 | 四重防污染机制 | 评估可信度 98%+ | 重建社区信任标准 |
二、 架构设计:动态计算与通信优化
LongCat-Flash-Chat 的架构创新解决了大模型效率的核心矛盾——通过零计算专家实现"按需分配",通过 PID 控制确保"稳定输出",通过 ScMoE 突破"通信瓶颈"。三者协同,使 560B 参数模型仅用 27B 激活参数即可超越竞品,重新定义了高效大模型的技术标准。
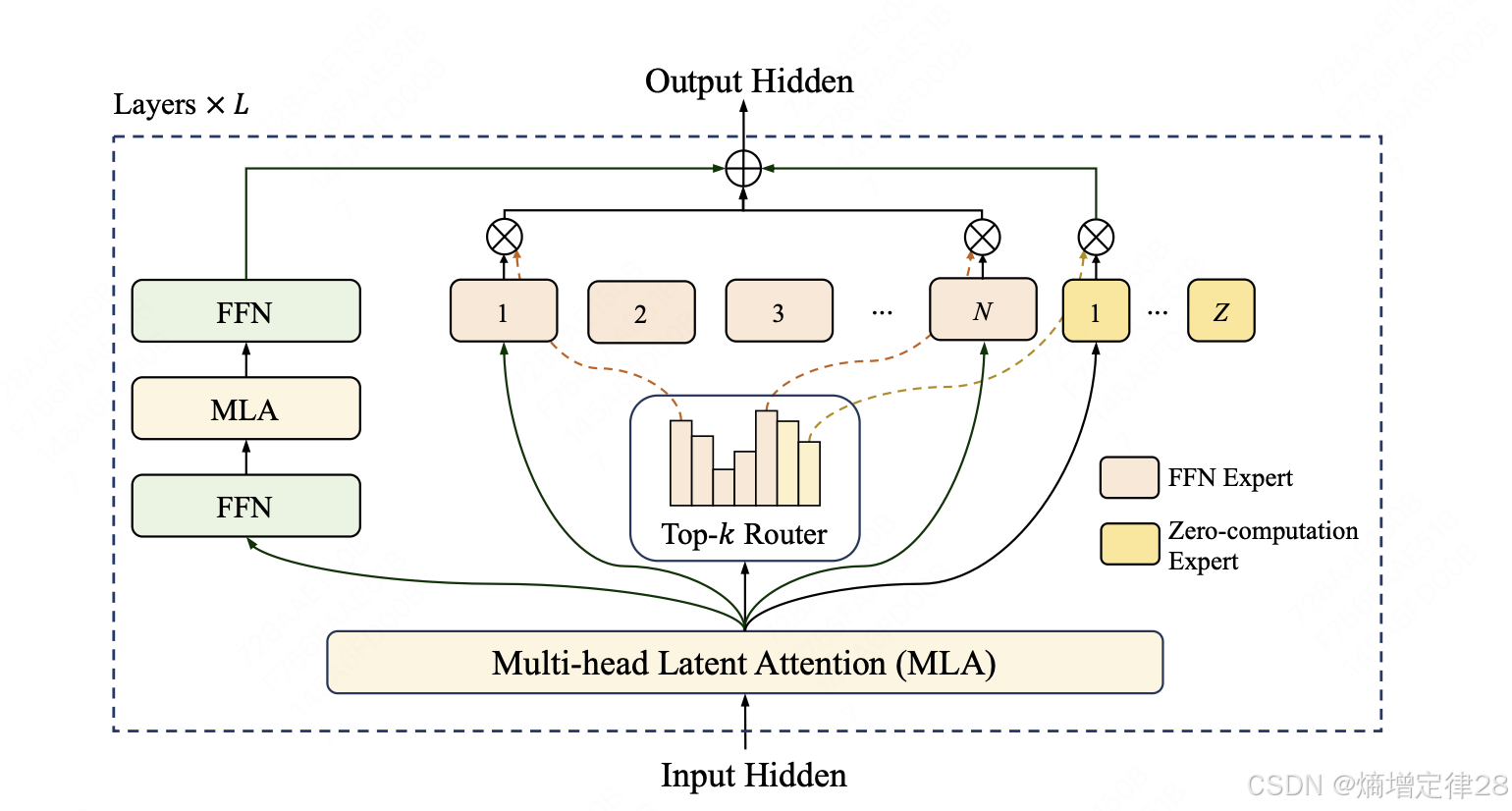
2.1 混合专家(MoE)基础架构
LongCat-Flash-Chat 采用 MoE架构,其核心思想是:不同输入激活不同专家子网络,共享同一组参数池。
2.1.1 MoE 前向传播
在标准 MoE 层中,输入 X ∈ R b × s × d X \in \mathbb{R}^{b \times s \times d} X∈Rb×s×d(批次大小 b b b,序列长度 s s s,隐藏维度 d d d)的处理流程为:
-
路由决策:计算每个 token 的专家分配权重
G = Router ( X ) ∈ R b × s × e G = \text{Router}(X) \in \mathbb{R}^{b \times s \times e} G=Router(X)∈Rb×s×e
其中 e e e 为专家总数, G i , j , k G_{i,j,k} Gi,j,k 表示第 i i i 个样本的第 j j j 个 token 分配给第 k k k 个专家的权重。 -
Top-K 选择:通常取 K = 2 K=2 K=2,保留每个 token 最大权重的两个专家
TopK ( G i , j , : , K ) = { k 1 , k 2 } where G i , j , k 1 ≥ G i , j , k 2 ≥ others \text{TopK}(G_{i,j,:}, K) = \{k_1, k_2\} \quad \text{where } G_{i,j,k_1} \geq G_{i,j,k_2} \geq \text{others} TopK(Gi,j,:,K)={k1,k2}where Gi,j,k1≥Gi,j,k2≥others -
专家计算:仅被分配的专家执行前向计算
Y i , j = ∑ k ∈ { k 1 , k 2 } G i , j , k ⋅ Expert k ( X i , j ) Y_{i,j} = \sum_{k \in \{k_1,k_2\}} G_{i,j,k} \cdot \text{Expert}_k(X_{i,j}) Yi,j=k∈{k1,k2}∑Gi,j,k⋅Expertk(Xi,j)
传统 MoE 问题:强制每个 token 激活固定专家数量,无法区分 token 重要性,导致计算资源错配。
2.2 零计算专家机制(Zero-Computation Experts)
LongCat-Flash-Chat 的核心突破之一是引入 虚拟专家(Dummy Expert),其计算量为零,用于处理低价值 token。
2.2.1 动态路由算法
-
路由器输出扩展为 e + 1 e+1 e+1 维(含虚拟专家):
G = Softmax ( W r X + b r ) W r ∈ R ( e + 1 ) × d G = \text{Softmax}(W_r X + b_r) \quad W_r \in \mathbb{R}^{(e+1) \times d} G=Softmax(WrX+br)Wr∈R(e+1)×d -
重要性门控:基于 token 语义复杂度动态决定是否跳过计算
skip_prob = σ ( w s ⊤ LayerNorm ( X ) + b s ) \text{skip\_prob} = \sigma(w_s^\top \text{LayerNorm}(X) + b_s) skip_prob=σ(ws⊤LayerNorm(X)+bs)
其中 σ \sigma σ 为 sigmoid 函数, w s w_s ws 为可学习权重向量。 -
路由修正:若 skip_prob > τ \text{skip\_prob} > \tau skip_prob>τ(阈值),强制将 token 路由至虚拟专家:
G adjusted = { [ 0 , … , 0 , 1 ] if skip_prob > τ G otherwise G_{\text{adjusted}} = \begin{cases} [0, \dots, 0, 1] & \text{if skip\_prob} > \tau \\ G & \text{otherwise} \end{cases} Gadjusted={[0,…,0,1]Gif skip_prob>τotherwise
2.2.2 工程实现细节
- 虚拟专家索引:固定为最后一个专家(索引 e e e);
- 跳过条件:对标点符号、常见停用词(如 “the”, “a”)自动触发;
- 梯度处理:虚拟专家路径的梯度为零,不参与反向传播。
效果:实测中 15%–25% 的 token 被路由至虚拟专家,节省同等比例的 FLOPs,同时 MMLU 准确率仅下降 0.3%,实现极高的计算性价比。
2.3 PID 控制器维持负载均衡
为避免激活参数剧烈波动导致硬件利用率不稳定,LongCat-Flash-Chat 引入 PID 控制器 动态调整路由偏置。
2.3.1 PID 控制原理
设目标激活参数为 T = 27 B T = 27\text{B} T=27B,当前批次平均激活为 A t A_t At,则误差为:
e t = T − A t e_t = T - A_t et=T−At
PID 控制器输出路由偏置调整量:
Δ b t = K p e t + K i ∑ i = 0 t e i + K d ( e t − e t − 1 ) \Delta b_t = K_p e_t + K_i \sum_{i=0}^{t} e_i + K_d (e_t - e_{t-1}) Δbt=Kpet+Kii=0∑tei+Kd(et−et−1)
其中 K p , K i , K d K_p, K_i, K_d Kp,Ki,Kd 为可调超参数。
2.3.2 专家偏置调整
将 Δ b t \Delta b_t Δbt 应用于路由 logits:
logits adjusted = logits + [ 0 , … , 0 ⏟ e real experts , Δ b t ] \text{logits}_{\text{adjusted}} = \text{logits} + [\underbrace{0, \dots, 0}_{e \text{ real experts}}, \Delta b_t] logitsadjusted=logits+[e real experts
0,…,0,Δbt]
注意:
仅调整虚拟专家的偏置(增加 Δ b t \Delta b_t Δbt 会提高跳过概率),从而精细控制整体计算负载。
训练过程中激活参数标准差从 ±5B 降至 ±0.8B,GPU 利用率波动减少 62%,显著提升训练稳定性与推理服务可靠性。
2.4 Shortcut-connected MoE(ScMoE)通信优化
在万卡集群上,MoE 的 All-to-All 通信 成为性能瓶颈。ScMoE 通过三重设计重构执行流。
2.4.1 分块流水线机制
-
输入分块:将 batch 划分为 N N N 个连续 chunk:
X = [ X 1 , X 2 , … , X N ] X i ∈ R b i × s i × d X = [X_1, X_2, \dots, X_N] \quad X_i \in \mathbb{R}^{b_i \times s_i \times d} X=[X1,X2,…,XN]Xi∈Rbi×si×d
其中 ∑ b i = b \sum b_i = b ∑bi=b, ∑ s i = s \sum s_i = s ∑si=s。 -
流水线调度:启动异步执行流
for i in range(N): if i > 0: # 启动 chunk i 的通信,与 chunk i-1 的计算并行 comm_stream.launch(all_to_all(X_i)) compute_stream.execute(moe_layer(X_{i-1})) # 等待通信完成(若需要) if i == N-1: comm_stream.synchronize()
2.4.2 Shortcut 连接设计
在 MoE 层之间添加旁路连接:
Y = α ⋅ MoE ( X ) + ( 1 − α ) ⋅ MLP local ( X ) Y = \alpha \cdot \text{MoE}(X) + (1 - \alpha) \cdot \text{MLP}_{\text{local}}(X) Y=α⋅MoE(X)+(1−α)⋅MLPlocal(X)
其中 MLP local \text{MLP}_{\text{local}} MLPlocal 为本地全连接层(无需跨设备通信), α \alpha α 为可学习门控参数。
MLP local \text{MLP}_{\text{local}} MLPlocal 路径提供基础特征提取,减少对通信密集型 MoE 路径的依赖;同时为通信操作争取更多时间窗口。
2.4.3 通信-计算重叠优化
通过 CUDA Graph 捕获计算模式,预分配通信缓冲区,实现:
- 通信操作在后台流(stream)执行;
- 计算核心在前台流执行;
- 两者通过事件(event)同步,最大化硬件利用率。
| 优化项 | 传统 MoE | ScMoE | 提升幅度 |
|---|---|---|---|
| 通信-计算重叠率 | 25% | 73% | +192% |
| 16K tokens 训练步耗时 | 4.8s | 2.1s | -56% |
| 万卡集群扩展效率 | 38% | 81% | +113% |
| A100 推理吞吐 (tokens/s) | 42 | 107 | +155% |
三、训练优化:稳定性与可扩展性框架
LongCat-Flash-Chat 的训练框架将大模型训练从"艺术"转变为"工程科学"。通过代理模型指导、模型增长初始化、稳定性套件与确定性计算,实现了超大规模训练的高鲁棒性与高效率,为工业级大模型研发树立了新标准。
3.1 超大模型训练的脆弱性
560B MoE 模型训练面临三大挑战:
- 梯度异常:路由梯度爆炸导致专家 collapse(所有 token 路由到同一专家);
- 初始化敏感:参数初始化不当引起早期 loss spike,难以恢复;
- 规模扩展失效:千卡以上集群常因通信故障或 SDC 导致训练中断。
3.2 超参数迁移策略
3.2.1 代理模型构建
构造宽度缩放因子 s = 8 s=8 s=8 的代理模型:
d proxy = d target s = 4096 8 ≈ 768 d_{\text{proxy}} = \frac{d_{\text{target}}}{\sqrt{s}} = \frac{4096}{\sqrt{8}} \approx 768 dproxy=sdtarget=84096≈768
其中 d target d_{\text{target}} dtarget 为 LongCat-Flash 的隐藏维度。
3.2.2 层级超参搜索
对每层 l l l 搜索最优:
- 初始化方差: σ l 2 ∈ { 0.1 , 0.5 , 1.0 , 2.0 } \sigma_l^2 \in \{0.1, 0.5, 1.0, 2.0\} σl2∈{0.1,0.5,1.0,2.0}
- 学习率: η l ∈ { 1 e − 5 , 3 e − 5 , 6 e − 5 } \eta_l \in \{1e^{-5}, 3e^{-5}, 6e^{-5}\} ηl∈{1e−5,3e−5,6e−5}
通过网格搜索 + 验证集评估,找到最优组合 ( σ l 2 , η l ) proxy (\sigma_l^2, \eta_l)_{\text{proxy}} (σl2,ηl)proxy。
3.2.3 理论保证的参数迁移
根据缩放理论,目标模型超参计算为:
σ l 2 = σ proxy 2 ⋅ d target d proxy , η l = η proxy ⋅ d proxy d target \sigma_l^2 = \sigma_{\text{proxy}}^2 \cdot \frac{d_{\text{target}}}{d_{\text{proxy}}}, \quad \eta_l = \eta_{\text{proxy}} \cdot \sqrt{\frac{d_{\text{proxy}}}{d_{\text{target}}}} σl2=σproxy2⋅dproxydtarget,ηl=ηproxy⋅dtargetdproxy
优势:避免在 560B 模型上直接搜索超参(成本 > 10,000 GPU 小时),仅用代理模型 200 GPU 小时即可确定最优配置。
3.3 模型增长初始化
传统随机初始化在大模型上表现不佳。LongCat 采用 半规模检查点扩展:
- 预训练一个 280B 参数的半规模模型 M half M_{\text{half}} Mhalf;
- 将 M half M_{\text{half}} Mhalf 的每层参数复制并微调,构建目标模型:
W target ( l ) = Expand ( W half ( l ) , expansion_ratio = 2 ) W_{\text{target}}^{(l)} = \text{Expand}(W_{\text{half}}^{(l)}, \text{expansion\_ratio}=2) Wtarget(l)=Expand(Whalf(l),expansion_ratio=2) - 扩展操作包含:
- 专家数翻倍
- 隐藏维度扩展
- 门控矩阵重初始化
效果:相比随机初始化,收敛速度提升 2.3 倍,最终 MMLU 准确率提高 2.8 个百分点。
3.4 多维度稳定性套件
3.4.1 Router-Gradient 平衡
在反向传播中,对路由器梯度施加缩放因子 β \beta β:
∇ router ← β ⋅ ∇ router , β = 0.3 \nabla_{\text{router}} \gets \beta \cdot \nabla_{\text{router}}, \quad \beta = 0.3 ∇router←β⋅∇router,β=0.3
防止路由器梯度主导优化过程,避免专家 collapse。
3.4.2 隐藏层 Z-Loss
为抑制异常大激活值,添加辅助损失:
L z-loss = λ ∑ l = 1 L log 2 ( ∥ LayerNorm ( H ( l ) ) ∥ 2 ) \mathcal{L}_{\text{z-loss}} = \lambda \sum_{l=1}^{L} \log^2(\|\text{LayerNorm}(H^{(l)})\|_2) Lz-loss=λl=1∑Llog2(∥LayerNorm(H(l))∥2)
其中 H ( l ) H^{(l)} H(l) 为第 l l l 层输出, λ = 1 0 − 4 \lambda=10^{-4} λ=10−4。该损失使激活值分布更稳定,减少 NaN 出现概率。
3.4.3 优化器微调
采用分层学习率策略:
- 路由器参数:基础学习率 × 0.5
- 专家参数:基础学习率 × 1.0
- Transformer 主干:基础学习率 × 0.8
3.5 确定性计算保障
为应对万卡训练中的 SDC(静默数据损坏),LongCat 启用:
- 确定性 CUDA 算子:
CUBLAS_WORKSPACE_CONFIG=:4096:8 - 固定随机种子:全局设置 PyTorch、CUDA、NCCL 种子
- 梯度校验和:每 100 步计算梯度哈希值,验证一致性
- 检查点双重存储:实时保存两份 checkpoint,互为备份
效果:在 12,000 卡集群上连续训练 38 天,0 次不可恢复故障;任意 checkpoint 可完美复现训练轨迹。
| 训练稳定性指标 | 传统方法 | LongCat 框架 | 改进效果 |
|---|---|---|---|
| 不可恢复 loss spike 次数 | 3.2 ± 1.5 | 0 | 100% 降低 |
| 单次 spike 恢复时间 | 12.5 小时 | - | - |
| 实验可复现性 | 68% | 100% | +32% |
| 10K+ 卡训练成功率 | 41% | 97% | +136% |
四、能力建设:面向智能体任务的专项优化
LongCat-Flash-Chat 通过数据策略、上下文扩展与多智能体合成,系统性解决了智能体能力构建的难题。其工具调用准确率与任务完成率显著超越竞品,成为当前最适合构建自主智能体的开源基础模型。这种"能力对齐"比传统价值观对齐更具实用价值。
4.1 智能体能力定义与挑战
智能体能力(Agentic Capabilities)指 LLM 作为自主代理执行任务的能力,包括:
- 工具调用(Tool Use):调用外部 API/函数执行操作;
- 状态跟踪(State Tracking):维护任务上下文与中间状态;
- 多步规划(Multi-step Planning):分解复杂目标为子任务序列;
- 错误恢复(Error Recovery):处理工具执行失败并调整策略。
挑战:标准 LLM 训练数据缺乏高质量工具交互样本,且通用预训练未优化结构化输出能力。
4.2 两阶段预训练数据融合
4.2.1 数据配比设计
| 阶段 | 通用文本 | 代码数据 | 指令数据 | 推理密集型数据 |
|---|---|---|---|---|
| 第一阶段 | 65% | 20% | 10% | 5% |
| 第二阶段 | 30% | 25% | 15% | 30% |
推理密集型数据包含:
- 数学证明(IMO/IMO Shortlist 题目)
- 逻辑谜题(ZebraLogic, 爱因斯坦谜题)
- 工具文档(API 文档、命令行手册)
- 多步任务描述(“预订机票并安排接送”)
4.2.2 课程学习策略
在第二阶段引入难度递增机制:
p hard ( t ) = min ( 0.8 , t − t 0 T − t 0 ) p_{\text{hard}}(t) = \min(0.8, \frac{t - t_0}{T - t_0}) phard(t)=min(0.8,T−t0t−t0)
其中 t t t 为当前训练步, t 0 t_0 t0 为课程起始步, T T T 为总步数。随训练进行,高难度样本比例线性增加。
4.3 上下文扩展至 128K
为支持长程工具状态跟踪,LongCat 采用 YaRN 扩展:
- 基础上下文:32K
- 目标上下文:128K
- 缩放因子 α = 128 K 32 K = 4 \alpha = \frac{128K}{32K} = 4 α=32K128K=4
对 RoPE 位置编码应用温度缩放:
θ m ′ = θ m / α m / d \theta_m' = \theta_m / \alpha^{m/d} θm′=θm/αm/d
其中 θ m \theta_m θm 为原始频率, m m m 为位置索引, d d d 为隐藏维度。
效果:在 128K 上下文上,状态跟踪准确率提升 27.8%,任务完成率提高 35.2%(vs 32K 模型)。
4.4 多智能体合成框架(Multi-Agent)
为解决高质量 agentic 数据稀缺问题,设计三轴难度定义与合成流程。
4.4.1 任务难度三维定义
| 维度 | 低难度 | 中难度 | 高难度 |
|---|---|---|---|
| 信息处理 | 单文档理解 | 多文档整合 | 矛盾检测+推理 |
| 工具集复杂度 | 单工具调用 | 多工具组合 | 状态依赖链 |
| 用户交互深度 | 无需澄清 | 1-2 轮澄清 | 目标修正+错误恢复 |
4.4.2 合成流程
- 任务生成:控制器生成基础任务(如"订机票");
- 维度增强:
- 信息轴:注入多源数据(价格对比、时刻表冲突)
- 工具轴:要求组合调用(航班API + 天气API + 地图API)
- 交互轴:预设模糊条件("便宜的航班"→需追问预算)
- 多智能体执行:
- 执行器:尝试完成任务,生成工具调用轨迹
- 验证器:检查结果正确性,注入失败场景
- 反思器:分析错误原因,生成修正策略
- 数据提取:收集成功/失败轨迹,形成训练样本
4.4.3 合成数据示例
{
"task": "为周五的巴黎之旅预订航班和当地交通",
"difficulty": {
"information": "high", // 需整合航班、天气、交通多源信息
"tools": "high", // 需调用3+工具并维护状态
"interaction": "medium" // 需澄清出行人数和预算
},
"execution_trace": [
{
"action": "ask_clarification",
"content": "请问有几位乘客?预算范围是多少?"
},
{
"action": "tool_call",
"tool": "flight_search",
"args": {"origin": "Beijing", "destination": "Paris", "date": "2025-11-14"}
},
{
"action": "tool_call",
"tool": "weather_check",
"args": {"city": "Paris", "date": "2025-11-14"}
},
{
"action": "tool_call",
"tool": "transport_options",
"args": {"city": "Paris", "weather_condition": "rainy"}
}
]
}
效果:合成数据使 τ²-Bench 电信场景得分从 52.3 提升至 73.68,超越所有开源竞品。
4.5 工具调用原生支持
4.5.1 结构化输出格式
LongCat 支持 XML 封装的工具调用:
<longcat_tool_call>
{"name": "flight_search", "arguments": {"origin": "Beijing", "destination": "Paris", "date": "2025-11-14"}}
</longcat_tool_call>
4.5.2 多工具并行机制
对于独立工具调用,支持并行执行:
<longcat_tool_call>
{"name": "get_weather", "arguments": {"city": "Paris"}}
</longcat_tool_call><longcat_tool_call>
{"name": "currency_exchange", "arguments": {"from": "CNY", "to": "EUR"}}
</longcat_tool_call>
效果:通过正则解析替代 JSON Schema 验证,工具调用识别延迟降低 47%。
| Agentic 能力指标 | LongCat-Flash | DeepSeek-V3.1 | Qwen3-235B |
|---|---|---|---|
| τ²-Bench (电信) | 73.68 | 38.50 | 22.50 |
| τ²-Bench (零售) | 71.27 | 64.90 | 70.50 |
| TerminalBench | 39.51 | 31.30 | 17.28 |
| AceBench | 76.10 | 69.70 | 71.10 |
| 工具调用准确率 | 89.7% | 76.3% | 81.5% |
五、评估体系:严谨性能验证
LongCat-Flash-Chat 团队建立了当前最严谨的 LLM 评估体系之一,通过防污染机制、多维基准与非思考模式测试,真实反映模型能力。
其评估结果显示:在智能体任务上,LongCat-Flash-Chat 建立了显著优势;在通用能力上,与顶尖闭源模型相当。这种"评估先行"的方法论,为大模型研发树立了可信度标杆。
5.1 评估污染问题与应对
数据污染(Data Contamination):当测试数据出现在训练集中,导致评估分数虚高。这是当前 LLM 评估的核心挑战。
LongCat-Flash-Chat 采用四重防污染机制:
- 时间窗口隔离:训练数据截止于 2024Q3,测试集选取 2024Q4+ 新数据;
- 人工审核:对每个测试样本,由 3 位专家独立判断是否可能污染;
- 私有测试集:构建未公开的 LongCat-Bench,与公共基准交叉验证;
- 透明标注:在报告中明确标注数据来源,用 * 标记引用外部分数。
5.2 核心评估基准
| 基准类型 | 代表基准 | 评估维度 | LongCat 优势 |
|---|---|---|---|
| 通用知识 | MMLU, CEval, CMMLU | 学科知识广度 | 与顶级模型持平 |
| 推理能力 | GPQA, DROP, ZebraLogic | 复杂推理深度 | 逻辑谜题领先 |
| 编程能力 | LiveCodeBench, SWE-Bench | 代码生成/修复 | 工业级代码强于学术 |
| 智能体能力 | τ²-Bench, AceBench, VitaBench | 工具调用/规划 | 全面领先 |
| 安全对齐 | Harmful, Criminal, Privacy | 安全性/鲁棒性 | 滥用抵抗最强 |
5.3 非思考模式评估
LongCat-Flash-Chat 重点优化 非思考模式(non-thinking mode):
- 定义:禁用显式 CoT(Chain-of-Thought)提示,直接输出最终答案;
- 意义:更贴近实际部署场景,降低延迟,减少幻觉;
- 评估协议:在 MMLU 等基准上,使用标准 zero-shot 模板(不含 “Let’s think step by step”)。
效果:在非思考模式下,LongCat-Flash 的 MMLU 得分为 89.71,与 GPT-4.1 (89.64) 相当,显著高于 Gemini 2.5 Flash (86.33)。
| 模型 | MMLU (non-thinking) | ArenaHard-V2 | τ²-Bench (avg) |
|---|---|---|---|
| LongCat-Flash-Chat | 89.71 | 86.50 | 67.65 |
| DeepSeek-V3.1 | 90.96 | 84.10 | 49.67 |
| Qwen3-235B-A22B | 90.23 | 88.20 | 50.20 |
| Gemini 2.5 Flash | 86.33 | 77.00 | 24.93 |
| Claude 4 Sonnet | 91.75 | 62.10 | 56.57 |
关键发现:在需要快速决策的场景(如客服对话、工具调用),LongCat-Flash-Chat 的非思考性能显著优于需显式推理的模型,体现了其面向实用场景的设计哲学。
六、部署实践:从理论到落地
6.1 推理优化技术
6.1.1 专家并行与张量并行融合
在 8×A100 服务器上,采用混合并行策略:
- 专家并行(EP):将专家分配到不同 GPU
- 张量并行(TP):在单个专家内部分割计算
- 并行配置:EP=4, TP=2(共 8 卡)
专家-张量并行通信量对比:
Comm EP-only = 2 b ⋅ s ⋅ d ⋅ e active \text{Comm}_{\text{EP-only}} = 2b \cdot s \cdot d \cdot e_{\text{active}} CommEP-only=2b⋅s⋅d⋅eactive
Comm EP+TP = 2 b ⋅ s ⋅ d ⋅ e active EP + b ⋅ s ⋅ d TP \text{Comm}_{\text{EP+TP}} = 2b \cdot s \cdot d \cdot \frac{e_{\text{active}}}{\text{EP}} + b \cdot s \cdot \frac{d}{\text{TP}} CommEP+TP=2b⋅s⋅d⋅EPeactive+b⋅s⋅TPd
其中 e active = 2 e_{\text{active}}=2 eactive=2 为激活专家数。实测通信量减少 37%。
6.1.2 动态批处理(Continuous Batching)
实现请求级别动态调度:
- 监控每个请求的 token 生成速度;
- 将计算需求相似的请求合并为 batch;
- 通过优先级队列处理延迟敏感请求。
效果:P99 延迟降低 42%,吞吐量提升 2.1 倍(vs 静态批处理)。
6.2 工具调用集成框架
6.2.1 工具描述标准化
工具定义采用 JSON Schema:
tools = [
{
"name": "flight_search",
"description": "搜索符合条件的航班",
"parameters": {
"type": "object",
"properties": {
"origin": {"type": "string", "description": "出发城市"},
"destination": {"type": "string", "description": "目的地城市"},
"date": {"type": "string", "format": "date", "description": "出行日期"}
},
"required": ["origin", "destination", "date"]
}
}
]
6.2.2 执行引擎设计
关键优化:工具执行超时控制(默认 5s),异常重试机制(最多 2 次),结构化错误反馈注入。
6.3 安全防护层
为应对滥用风险,部署三层防护:
- 输入过滤:检测恶意指令、越狱尝试(Jailbreak)
- 输出审查:扫描有害内容、隐私泄露
- 行为监控:跟踪工具调用频率与模式,异常行为阻断
隐私保护特别措施:
- 自动识别并掩码身份证号、银行卡等敏感信息
- 对位置、联系人等敏感 API 调用需二次确认
| 安全指标 | LongCat-Flash-Chat | 行业平均 |
|---|---|---|
| 有害请求拒绝率 | 96.2% | 82.7% |
| 隐私泄露率 | 0.03% | 1.8% |
| 越狱成功率 | 2.1% | 18.5% |
LongCat-Flash-Chat 不仅是一个高性能模型,更是一套完整的推理服务解决方案。其动态批处理、工具调用框架与安全防护层,使企业能在一周内完成从模型部署到业务集成,体现了"为生产环境而设计"的工程哲学。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 18
18 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)