从入门到精通 LlamaIndex RAG 应用开发
LlamaIndex 通过一套清晰的组件体系,将「原始数据」转化为可供 LLM 查询的「知识索引」,让开发者能够轻松实现问答、搜索、数据分析甚至自主代理(Agent)。本文将带你从入门到实践,完整了解如何使用 LlamaIndex 构建一个可扩展、可信赖的 RAG 系统。
目录
前言
在大模型时代,如何让语言模型(LLM)理解和使用企业内部数据,成为构建智能应用的关键问题。检索增强生成(Retrieval-Augmented Generation,简称 RAG)是解决这一问题的主流范式。而 LlamaIndex(原名 GPT Index)正是这一领域中最具代表性的数据框架之一。
LlamaIndex 通过一套清晰的组件体系,将「原始数据」转化为可供 LLM 查询的「知识索引」,让开发者能够轻松实现问答、搜索、数据分析甚至自主代理(Agent)。本文将带你从入门到实践,完整了解如何使用 LlamaIndex 构建一个可扩展、可信赖的 RAG 系统。
1. LlamaIndex简介
1.1 定义与定位
LlamaIndex 是一个专为大型语言模型(LLM)设计的数据框架,提供从数据提取、分块、索引、检索到查询生成的一体化解决方案。它充当「模型与数据之间的桥梁」,让 LLM 能够在外部知识的支持下回答更准确、更可信的结果。
1.2 为什么选择 LlamaIndex
传统的 RAG 应用开发往往需要大量「粘合代码」——自己处理分块、索引、搜索、重排序等复杂流程。LlamaIndex 提供了可组合的构建模块,使得开发者可以快速搭建可维护、可替换的系统。它的优势包括:
| 功能模块 | 描述 |
|---|---|
| 数据接入 | 支持多种数据源(本地文件、数据库、Notion、Google Drive、Slack 等) |
| 模型兼容性 | 兼容 OpenAI、Anthropic、Ollama、Bedrock、Vertex 等多种 LLM 后端 |
| 灵活的索引结构 | 支持向量索引、关键词索引、混合索引等多种策略 |
| 可扩展的检索器与查询引擎 | 模块化设计,方便替换不同算法组件 |
| 评估与观测工具 | 提供忠实度、相关性等自动化评价指标 |
换句话说,LlamaIndex 是让你「用最少代码构建最强知识系统」的关键工具。
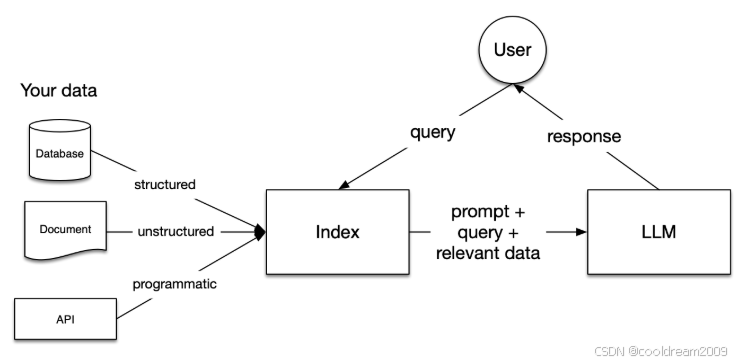
2. 核心心智模型:文档 → 节点 → 索引 → 检索器 → 查询引擎
LlamaIndex 的核心思想可用五个关键概念来理解:
- 文档(Document):原始数据载体,如 PDF、网页、数据库记录。
- 节点(Node):文档被分割后的文本块(chunk)及其元数据。
- 索引(Index):节点被嵌入并组织成可检索结构(如向量索引)。
- 检索器(Retriever):根据查询语义从索引中找出最相关的节点。
- 查询引擎(Query Engine):结合上下文生成最终回答。
这种分层结构让开发者能够独立替换各部分。例如,可以更换嵌入模型、检索算法或重排序模型,而无需重写整个系统。
3. 安装与设置
LlamaIndex 的模块化设计允许你按需选择组件。以下命令安装常用的 OpenAI 套件:
pip install llama-index llama-index-llms-openai llama-index-embeddings-openai
若你计划使用本地模型或自定义存储,可安装:
pip install llama-index-llms-ollama llama-index-embeddings-huggingface
pip install llama-index-vector-stores-chroma chromadb
pip install llama-index-readers-notion
最后,通过环境变量设置 API 密钥:
export OPENAI_API_KEY="your-api-key"
官方安装文档提供了最新的包名及依赖选项,可根据实际需求灵活配置。
4. 十分钟快速入门:你的第一个 RAG 机器人
以下示例展示如何在 10 分钟内构建一个简单的问答系统。
4.1 文件结构
./data 放入你的 .md、.txt 或 .pdf 文件
app.py 主程序文件
4.2 代码示例
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, Settings
from llama_index.llms.openai import OpenAI
from llama_index.embeddings.openai import OpenAIEmbedding
配置模型与嵌入
Settings.llm = OpenAI(model="gpt-4o-mini")
Settings.embed_model = OpenAIEmbedding(model="text-embedding-3-small")
加载数据与创建索引
docs = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(docs)
创建查询引擎
qe = index.as_query_engine(response_mode="compact")
提问
q = "这些文档的主要主题是什么?请包含引用。"
ans = qe.query(q)
print(ans)
运行:
python app.py
系统会基于向量检索生成答案并附带引用。这是 RAG 应用的最小可行原型。
5. 可信赖的分块、元数据与检索策略
5.1 分块策略
良好的分块直接影响检索质量。
- 默认块大小:512–1024 词元。
- 建议使用语义分块或基于标题的层次分块。
- 保留 20–50 词元重叠,避免语义断裂。
5.2 元数据设计
为每个节点添加标签,例如:
- 来源文件名、章节、页码;
- 创建时间或主题标签;
- 查询时可使用元数据过滤(如仅限特定项目或时间段)。
5.3 检索增强
- 混合检索:结合 BM25(关键词)与向量相似度。
- 重排序:使用 reranker 对前 k 个结果重新打分。
- 查询分解:复杂问题可拆分为子查询后再合并。
6. 评估你的 RAG 系统:红黄绿评级
没有评估,就没有信任。LlamaIndex 提供评估工具,如忠实度(Faithfulness)与相关性(Relevancy)。也可集成社区工具包 RAGAS 进行多维分析。
from llama_index.core.evaluation import FaithfulnessEvaluator, RelevancyEvaluator
faith = FaithfulnessEvaluator()
rel = RelevancyEvaluator()
question = "我们的 SOC 2 策略是什么?"
response = qe.query(question)
print("faithfulness:", faith.evaluate_response(response).score)
print("relevancy:", rel.evaluate_response(response, question).score)
通过自动化指标与人工审核结合,可有效防止幻觉(hallucination)。
7. 使用 FastAPI 部署生产环境
以下示例展示如何将 RAG 系统部署为 API 服务:
from fastapi import FastAPI
from pydantic import BaseModel
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, Settings
from llama_index.llms.openai import OpenAI
from llama_index.embeddings.openai import OpenAIEmbedding
app = FastAPI()
Settings.llm = OpenAI(model="gpt-4o-mini")
Settings.embed_model = OpenAIEmbedding(model="text-embedding-3-small")
docs = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(docs)
qe = index.as_query_engine(streaming=True)
class Query(BaseModel):
q: str
@app.post("/ask")
def ask(body: Query):
resp = qe.query(body.q)
return {
"answer": str(resp),
"sources": [
{"node_id": s.node.node_id, "source": s.node.metadata.get("file_name")}
for s in getattr(resp, "source_nodes", [])
],
}
结合前端(Next.js、React、SwiftUI),即可实现实时问答或文档分析应用。
8. 常见陷阱与解决方案
| 问题 | 原因 | 解决方法 |
|---|---|---|
| 嵌入模型不匹配 | 更换嵌入模型但未重新索引 | 重新生成嵌入并保存模型版本信息 |
| 块大小过大或过小 | 影响上下文一致性 | 512–1024 词元,重叠 50 左右 |
| 缺乏元数据 | 查询结果无法筛选 | 添加来源、章节、页码等元数据 |
| 冷启动延迟 | 索引未持久化 | 预热向量存储或使用持久化方案 |
| PDF 结构混乱 | OCR/结构丢失 | 使用 LlamaParse 或其他高级解析器 |
结语
LlamaIndex 让「让 LLM 理解你的数据」变得前所未有地简单。从数据加载到索引构建,从检索优化到智能代理,它提供了构建智能知识系统的完整路径。无论你是想快速原型验证,还是打造企业级知识中台,LlamaIndex 都是值得深入掌握的核心技术栈。
参考资料

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 27
27 0
0- 0



 已为社区贡献54条内容
已为社区贡献54条内容

所有评论(0)