面向智能体的外部记忆机制基于 RAG 的上下文增强策略【附代码】
在智能体应用落地的过程中,模型上下文窗口的限制是绕不过去的一道“天花板”。基于文档分块与向量索引的长文本处理方案,本质上是在模型外构建一个可随时调用的“外部记忆”。通过将长文档拆分为可管理的语义块、向量化后存入索引数据库,再在推理阶段按需检索补充上下文,我们无需扩大模型本身的窗口,也可以让智能体“理解”海量信息。相比直接把整篇文档塞给模型,这种 RAG 思路成本更低、效果更稳定,也更适合企业级知识
面向智能体的外部记忆机制基于 RAG 的上下文增强策略【附代码】
一、背景:为什么需要“上下文窗口扩展”?
在构建 AI 智能体(AI Agent)时,我们通常会依赖大语言模型(LLM)来进行推理、计划和执行。然而,一个现实的问题是:
模型的上下文窗口是有限的。
例如:
- GPT-3.5 的上下文上限只有 4K~16K Tokens
- 即使 GPT-4、GPT-5 已经支持更大的上下文,但消耗成本高、实时性差
然而,真实应用中,我们需要处理:
- 数十万字的技术文档
- 多章节的法律合同
- 企业知识库
- 用户历史多轮对话记录
因此,如何在不增加模型开销的前提下,让模型“记住”更多信息?
解决方案是:
把长文本分块 → 转为向量索引 → 按需检索 → 动态补充模型上下文
二、核心思路:文档分块 + 向量化检索
长文本处理需要构建 外部记忆系统(External Memory),思路如下:
- 文档分块
将原始长文本拆分成合适粒度的语义块(Sentence / Paragraph / Chunk)。 - 文本向量化
使用 Embedding 模型将文本块转为高维向量。 - 构建向量索引(FAISS / Milvus / ElasticSearch)
用于后续高效相似度检索。 - 检索-补充上下文
智能体在需要时,根据查询语义找出最相关的内容,并拼接到 Prompt 中。
图示流程:
原文档 → 分块 → 向量化 → 向量数据库
↑
Query(问题) → 语义检索 → 相关上下文
三、文档分块策略
分块方式影响检索效果,通常有三种:
| 分块方式 | 特点 | 推荐场景 |
|---|---|---|
| 固定长度分块 | 简单但可能截断语义 | 内容较结构化,如 API 文档 |
| 语义分段(按段落/句子) | 语义连续性好 | 普通知识型文本 |
| 滑动窗口分块 | 保持上下文跨块连续性 | 知识关联紧密型文档 |
一般推荐:
块大小:300~800 tokens
重叠区域:50~150 tokens
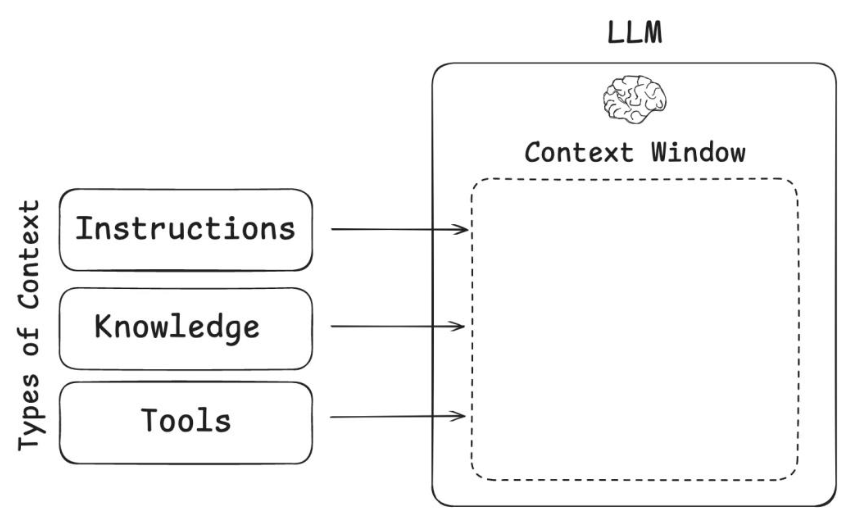
四、代码实战:基于 sentence-transformers + FAISS 构建向量索引
下面以 Python 为例,示范如何完成“分块 → 向量化 → 检索 → 喂入 LLM”。
1. 安装依赖
pip install sentence-transformers faiss-cpu transformers
2. 文档分块
def chunk_text(text, chunk_size=500, overlap=100):
chunks = []
start = 0
while start < len(text):
end = start + chunk_size
chunk = text[start:end]
chunks.append(chunk)
start = end - overlap
return chunks
3. 构建向量索引
from sentence_transformers import SentenceTransformer
import faiss
import numpy as np
model = SentenceTransformer('all-MiniLM-L6-v2')
# 假设 text 是你的长文档内容
chunks = chunk_text(text)
vectors = model.encode(chunks)
index = faiss.IndexFlatL2(vectors.shape[1])
index.add(np.array(vectors))
4. 检索并构建上下文
def search(query, top_k=3):
q_vec = model.encode([query])
distances, ids = index.search(np.array(q_vec), top_k)
results = [chunks[i] for i in ids[0]]
return "\n".join(results)
query = "智能体上下文窗口为什么需要扩展?"
context = search(query)
prompt = f"""
你是一个知识助理,请结合以下上下文回答问题。
【上下文】
{context}
【问题】
{query}
"""
print(prompt)
随后把 prompt 发送给你的 LLM,例如 GPT API / LLaMA / ChatGLM 等。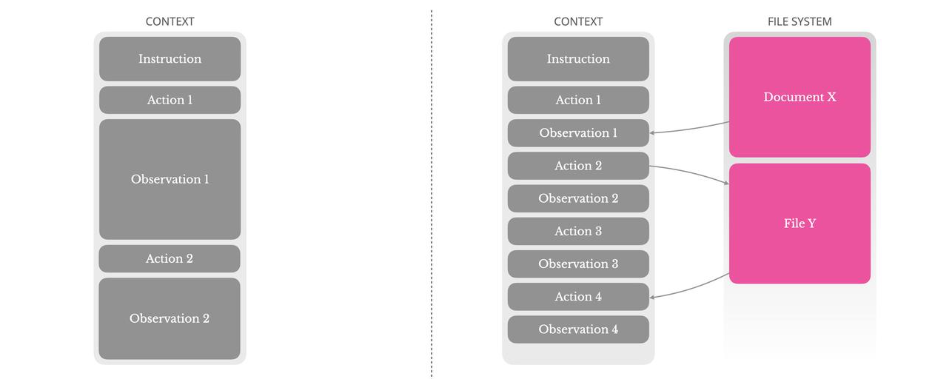
五、智能体融合策略:动态上下文补全 (RAG 架构)
以上方案实际上就是 RAG(Retrieval Augmented Generation) 思路:
LLM 不直接记住所有知识
而是根据查询进行检索、补全、推理
在智能体中,这个过程可以自动触发:
1) 任务输入 → 提取当前 Query
2) Query 语义检索 → 得到知识补充
3) 将检索结果动态注入 Prompt
4) 模型执行推理 → 输出结果
这样就避免了 LLM 直接加载全部上下文带来的计算和成本浪费。
六、总结
| 问题 | 解决方案 | 效果 |
|---|---|---|
| 上下文窗口有限 | 外部向量记忆系统 | 低成本扩展模型信息容量 |
| 长文本难直接处理 | 文档分块处理 | 保证语义完整性 |
| 模型容易回答不准确 | 基于向量检索补充上下文 | 提升智能体回答准确性 |
因此,基于 文档分块 + 向量索引 的上下文扩展机制,是构建可长期进化、可持续学习的智能体能力的重要基础。
在智能体应用落地的过程中,模型上下文窗口的限制是绕不过去的一道“天花板”。基于文档分块与向量索引的长文本处理方案,本质上是在模型外构建一个可随时调用的“外部记忆”。通过将长文档拆分为可管理的语义块、向量化后存入索引数据库,再在推理阶段按需检索补充上下文,我们无需扩大模型本身的窗口,也可以让智能体“理解”海量信息。相比直接把整篇文档塞给模型,这种 RAG 思路成本更低、效果更稳定,也更适合企业级知识库与复杂多轮任务场景。可以说,它已成为当下智能体系统中最关键的基础能力之一。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 11
11 0
0- 0



 已为社区贡献39条内容
已为社区贡献39条内容

所有评论(0)