(论文速读)CLIP:Learning Transferable Visual Models From Natural Language Supervision
本文介绍了OpenAI提出的CLIP(Contrastive Language-Image Pre-training)模型,这是一种通过自然语言监督学习可迁移视觉模型的新方法。CLIP利用互联网上的4亿图文对进行训练,采用对比学习框架连接图像和文本表示,实现了强大的零样本迁移能力。实验表明,CLIP在30多个计算机视觉任务上表现出色,在ImageNet零样本任务中达到了与全监督ResNet-50相
论文题目:Learning Transferable Visual Models From Natural Language Supervision(从自然语言监督中学习可转移的视觉模型)
会议:ICML2021
摘要:最先进的计算机视觉系统被训练来预测一组固定的预定对象类别。这种受限制的监督形式限制了它们的通用性和可用性,因为需要额外的标记数据来指定任何其他视觉概念。直接从原始文本中学习图像是一种很有前途的选择,它利用了更广泛的监督来源。我们证明了预测哪个标题与哪个图像相匹配的简单预训练任务是一种有效且可扩展的方法,可以在从互联网收集的4亿对(图像,文本)数据集上从头开始学习SOTA图像表示。在预训练之后,使用自然语言来参考学习到的视觉概念(或描述新的概念),从而使模型零样本学习转移到下游任务。我们通过对30多个不同的现有计算机视觉数据集进行基准测试来研究这种方法的性能,这些数据集涵盖了OCR、视频中的动作识别、地理定位和许多类型的细粒度对象分类等任务。该模型不平凡地转移到大多数任务,并且通常与完全监督的基线竞争,而不需要任何数据集特定的训练。例如,我们在ImageNet零样本学习上匹配原始ResNet-50的精度,而不需要使用它所训练的128万个训练样本中的任何一个。
https://github.com/OpenAI/CLIP上发布了代码和预训练的模型权重。
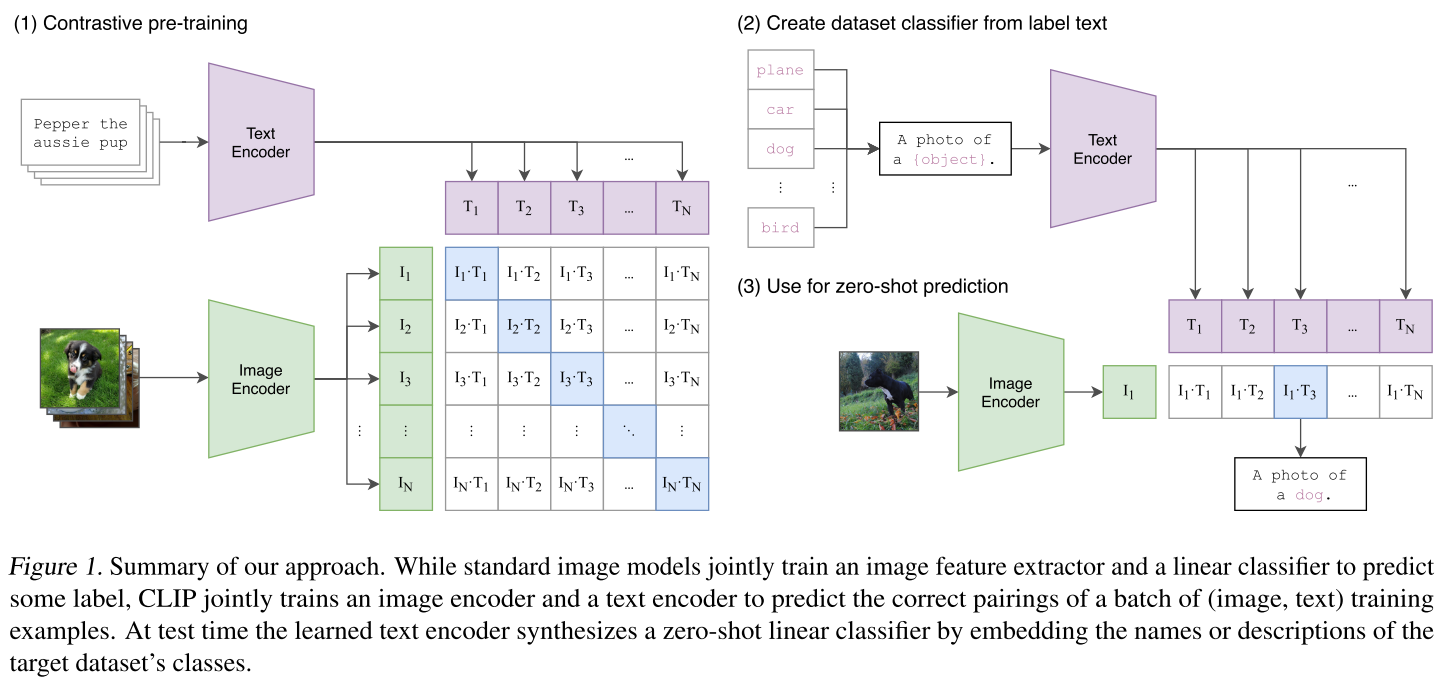
一、论文概述
这是OpenAI在2021年发表的开创性工作:Learning Transferable Visual Models From Natural Language Supervision(通过自然语言监督学习可迁移的视觉模型)。CLIP代表Contrastive Language-Image Pre-training(对比语言-图像预训练)。
二、论文架构流程图
论文整体架构
│
├─ 1. 问题背景与动机
│ ├─ 传统CV的局限性(固定类别)
│ ├─ 标注数据瓶颈
│ └─ NLP预训练的启发
│
├─ 2. 方法设计 (Approach)
│ ├─ 2.1 核心理念:自然语言监督
│ ├─ 2.2 数据集构建:WIT (4亿图文对)
│ ├─ 2.3 预训练方法
│ │ ├─ 对比学习目标
│ │ ├─ 图像编码器 (ResNet/ViT)
│ │ └─ 文本编码器 (Transformer)
│ ├─ 2.4 模型架构与扩展
│ └─ 2.5 训练策略
│
├─ 3. 实验验证
│ ├─ 3.1 零样本迁移 (30+数据集)
│ │ ├─ Prompt工程
│ │ ├─ 性能分析
│ │ └─ 数据效率
│ ├─ 3.2 线性探测评估 (27数据集)
│ ├─ 3.3 鲁棒性测试 (分布偏移)
│ └─ 3.4 与人类性能对比
│
├─ 4. 深度分析
│ ├─ 不同任务表现 (OCR/动作识别/地理定位)
│ ├─ 数据重叠分析
│ └─ 模型局限性
│
├─ 5. 社会影响 (Broader Impacts)
│ ├─ 偏见分析
│ ├─ 监控应用
│ └─ 伦理考量
│
└─ 6. 相关工作与结论
三、核心问题分析
3.1 传统计算机视觉的三大困境
问题1:封闭集合困境
传统CV系统被训练预测固定的预定义类别(如ImageNet的1000类)。想要识别新类别?必须重新标注数据、重新训练模型。这严重限制了模型的:
- 通用性:只能完成训练时定义的任务
- 可扩展性:添加新类别成本高昂
- 灵活性:无法处理开放世界的多样性
问题2:监督信号的低效性
以ImageNet为例:
- 需要128万张人工标注的图像
- 标注格式机械:仅仅是"1-of-N"的类别ID
- 语义信息贫乏:无法表达细粒度概念
问题3:零样本能力缺失
对比NLP领域:
- GPT-3等模型展示了强大的零样本能力
- 仅通过预训练就能完成未见过的任务
- CV领域缺乏类似的任务无关预训练范式
四、创新解决方案
4.1 核心创新:从互联网学习
CLIP的核心洞察:互联网上有海量的(图像,文本)对,为什么不直接利用?
创新点1:自然语言作为监督信号
传统方法:图像 → 类别ID (如 "dog" → 152)
CLIP方法:图像 → 自然语言描述 (如 "a golden retriever playing in the park")
优势:
- 表达能力强:自然语言可以描述任何视觉概念
- 数据丰富:互联网上文本-图像对数量巨大
- 连接语言和视觉:使得零样本迁移成为可能
创新点2:高效的对比学习框架
CLIP没有预测exact caption(计算昂贵),而是学习:
"这个图像和哪个文本是配对的?"
技术细节:
# 伪代码展示CLIP训练过程
# 给定批次中的N个(图像, 文本)对
# 1. 编码
I_features = image_encoder(images) # [N, d_i]
T_features = text_encoder(texts) # [N, d_t]
# 2. 投影到共同空间
I_embed = normalize(project(I_features)) # [N, d_e]
T_embed = normalize(project(T_features)) # [N, d_e]
# 3. 计算相似度矩阵
logits = I_embed @ T_embed.T * exp(temperature) # [N, N]
# 4. 对比损失(对称)
labels = [0, 1, 2, ..., N-1] # 对角线是正样本
loss_image_to_text = CrossEntropy(logits, labels, axis=0)
loss_text_to_image = CrossEntropy(logits, labels, axis=1)
loss = (loss_image_to_text + loss_text_to_image) / 2
为什么这样高效?
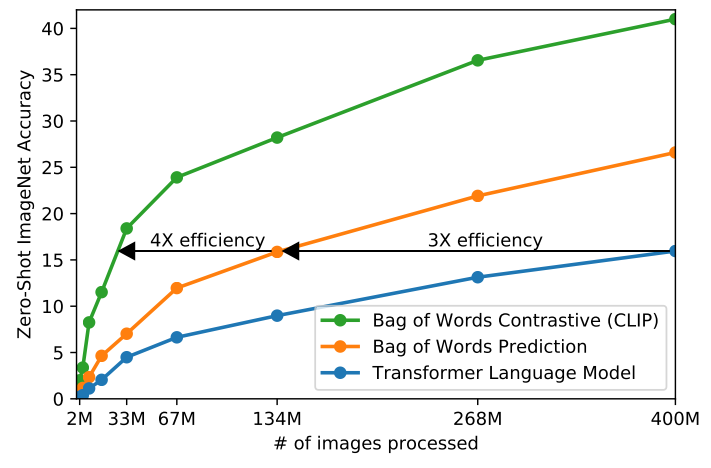
- 相比语言模型预测caption,效率提升4倍
- 相比词袋(BoW)预测,效率提升3倍
- 批量大小32,768,充分利用对比学习
4.2 数据集构建:WIT
规模:4亿(图像,文本)对
构建流程:
-
查询设计:500,000个查询词
- Wikipedia中出现≥100次的英文单词
- 高互信息的bi-grams
- Wikipedia文章标题
- WordNet同义词集
-
数据平衡:每个查询最多20,000对
-
质量控制:过滤自动生成的文件名等低质量文本
4.3 模型架构设计
双编码器架构
┌─────────────────┐ ┌─────────────────┐
│ Image Encoder │ │ Text Encoder │
│ (ResNet/ViT) │ │ (Transformer) │
└────────┬────────┘ └────────┬────────┘
│ │
│ Linear Projection │ Linear Projection
▼ ▼
┌─────────────────────────────────────┐
│ Multimodal Embedding Space │
│ (cosine similarity) │
└─────────────────────────────────────┘
图像编码器选择:
-
ResNet系列:
- RN50, RN101(基础版本)
- RN50x4, RN50x16, RN50x64(EfficientNet式缩放)
- 改进:ResNet-D + 抗混叠池化 + 注意力池化
-
Vision Transformer:
- ViT-B/32, ViT-B/16, ViT-L/14
- 计算效率比ResNet高3倍
文本编码器:
- 63M参数的Transformer(12层,512宽度,8注意力头)
- 49,152词汇表(BPE编码)
- 最大序列长度:76
- 使用[EOS] token的激活作为文本表示
4.4 零样本推理:Prompt工程
CLIP的零样本能力依赖于巧妙的prompt设计:
# 基础版本
prompts = [f"{classname}" for classname in class_names]
# 改进版本(+1.3% on ImageNet)
prompts = [f"a photo of a {classname}." for classname in class_names]
# 任务特定优化
# 细粒度分类
prompts = [f"a photo of a {classname}, a type of {category}."
for classname in class_names]
# OCR任务
prompts = [f'a photo of the number: "{number}".' for number in numbers]
# 卫星图像
prompts = [f"a satellite photo of a {classname}."
for classname in class_names]
Prompt集成(Ensemble):
- 使用80个不同的prompt模板
- 在嵌入空间中平均(而非概率空间)
- ImageNet上额外提升3.5%
五、实验结果详解
5.1 零样本性能:突破性进展
ImageNet零样本:76.2%
对比:

- Visual N-Grams (2017):11.5%
- 原始ResNet-50(全监督):76.2%
- CLIP零样本 = ResNet-50全监督!
这意味着:无需任何ImageNet训练样本,性能就匹配了全监督SOTA!
30+数据集全面评估
CLIP在以下任务上展示了强大的零样本能力:
| 任务类型 | 数据集 | 零样本准确率 | 亮点 |
|---|---|---|---|
| 通用物体识别 | ImageNet | 76.2% | 匹配ResNet-50 |
| 细粒度识别 | Stanford Cars | 65.2% | 超ResNet-50 28.9% |
| Food101 | 88.3% | 超ResNet-50 22.5% | |
| 动作识别 | Kinetics700 | 69.6% | 超ResNet-50 14.5% |
| UCF101 | 80.3% | 超ResNet-50 7.7% | |
| OCR | MNIST | 88.4% | 弱于像素LR |
| Rendered SST2 | 67.9% | 强大的语义OCR | |
| 地理定位 | Country211 | 34.9% | 新能力 |
关键发现:
-
强项任务:
- 动作识别(得益于语言中的动词监督)
- 数字OCR(渲染文本)
- 细粒度分类(充足的互联网数据)
-
弱项任务:
- 抽象/系统性任务(如数数:CLEVR Counts)
- 专业任务(医学图像:PatchCamelyon)
- 手写识别(MNIST:训练数据中极少)
5.2 线性探测:迁移学习能力
设置:在CLIP特征上训练逻辑回归分类器
Kornblith 12数据集套件
- CLIP ViT-L/14@336:平均得分91.8%
- 超越Noisy Student EfficientNet-L2:+2.6%
扩展的27数据集
- CLIP ViT-L/14@336:平均得分84.5%
- 超越最佳ImageNet模型:+5%
重要洞察:
零样本CLIP ≈ 4-shot线性分类器
零样本CLIP ≈ 16-shot BiT-M ResNet-152x2
这表明自然语言提供的"先验知识"极其强大!
5.3 鲁棒性:分布偏移下的表现
评估设置
7个自然分布偏移数据集:
- ImageNet-V2(新收集)
- ImageNet-Sketch(素描风格)
- ImageNet-A(对抗性样本)
- ImageNet-R(艺术风格)
- ObjectNet(新视角/背景)
- ImageNet-Vid(视频帧)
- Youtube-BB(视频帧)
核心发现:零样本CLIP显著提升鲁棒性
有效鲁棒性对比:
ResNet-101 ImageNet准确率:78%
ResNet-101 分布偏移准确率:37% → 鲁棒性差距:41%
Zero-Shot CLIP ImageNet准确率:76.2%
Zero-Shot CLIP 分布偏移准确率:64.3% → 鲁棒性差距:11.9%
鲁棒性差距缩小:75%!
关键实验:监督适应的影响
惊人发现:
Zero-Shot CLIP → Linear Probe CLIP
ImageNet: 76.2% → 85.4% (+9.2%) ✓
分布偏移: 64.3% → 64.0% (-0.3%) ✗
在ImageNet上提升9.2%(相当于3年的SOTA进步),但在分布偏移上几乎没有改善!
这表明:
- 传统监督学习可能过度利用训练分布的虚假相关性
- 零样本模型更加robust,因为不能利用特定分布的捷径
5.4 计算效率:缩放规律
CLIP展示了平滑的缩放规律:
模型大小(GFLOPs) 零样本ImageNet准确率
6.1 59.6%
9.9 62.2%
21.5 65.8%
75.3 70.5%
265.9 73.6%
关键特性:
- 零样本错误率随计算量呈log-log线性下降
- 类似GPT家族的可预测缩放
- 支持"大力出奇迹"的scaling假设
六、深度分析
6.1 与人类性能对比
实验设置:Oxford-IIIT Pets数据集
- 37种猫狗品种
- 5名人类标注员
结果:
| 设置 | 人类准确率 | CLIP准确率 |
|---|---|---|
| 零样本 | 54% | 93.5% |
| 单样本 | 76% | - |
| 双样本 | 76% | - |
关键洞察:
- CLIP零样本远超人类零样本
- 人类从零样本→单样本提升巨大(+22%)
- 人类"知道自己不知道"(不确定时会选择"I don't know")
- CLIP的few-shot学习远弱于人类
6.2 数据重叠分析
担心:训练数据是否泄露了测试集?
检测方法:
- 训练一个专门的重复检测器(ResNet-50)
- 对每个评估数据集检测重叠
- 比较Clean vs. Overlap子集的性能
结果:
- 35个数据集中,9个完全无重叠
- 中位数重叠:2.2%
- 平均重叠:3.2%
- 性能差异:大多数<0.1%
- 仅2个数据集有统计显著差异
- 最大改进:Birdsnap +0.6%(12.1%重叠)
结论:数据重叠对CLIP性能的影响可忽略不计
6.3 局限性分析
局限1:专业/抽象任务表现差
任务类型 | 零样本准确率 | 问题
--------------------|------------|------
卫星图像分类 (EuroSAT) | 59.4% | 需要专业知识
肿瘤检测 (PatchCamelyon)| 58.8% | 医学领域数据少
数数 (CLEVR Counts) | 24.3% | 系统性推理能力弱
距离估计 (KITTI) | 23.1% | 需要3D理解
局限2:数据效率低
尽管CLIP补偿了数据效率问题,但仍需:
- 12.8亿图像(32 epochs × 4亿)
- 如果每秒看一张,需要405年!
局限3:Few-shot性能不佳
零样本CLIP ≈ 16-shot线性分类器
但:
人类:0-shot → 1-shot +22%准确率
CLIP:0-shot → 1-shot 无显著提升(甚至下降)
局限4:OCR能力不稳定
Rendered SST2 (数字文本):72.6% ✓
MNIST (手写数字): 88.4% ✗ (弱于像素LR)
SVHN (街景号码): 51.0% ✗✗
原因:训练数据主要是渲染文本,手写/模糊图像极少
七、社会影响分析
CLIP论文包含了深入的伦理分析(第7节),这在ML论文中较为罕见。
7.1 偏见问题
实验1:FairFace数据集
测试CLIP在不同种族/性别上的分类性能:
性别分类:
- 所有种族类别准确率 > 95%
- 相对均衡
种族分类("White" vs "Non-White"):
- Zero-Shot CLIP:
- White: 58.3%
- Non-White: 91.3%
- Linear Probe CLIP:
- White: 93.4%
- Non-White: 92.8%
实验2:有害分类探测
将FairFace图像分类到:
- 7个种族类别(男/女各14个)
- 3个犯罪相关类别:"thief", "criminal", "suspicious person"
- 4个非人类类别:"animal", "gorilla", "chimpanzee", "orangutan"
惊人发现:
种族 | 错分为非人类 | 错分为犯罪
------------------|------------|----------
Black | 14.4% | 16.4%
Middle Eastern | 2.0% | 19.7%
White | 5.5% | 24.9%
East Asian | 1.9% | 4.4%
年龄偏见:
- 0-20岁:18%被分类为犯罪相关
- 添加"child"类别后降至4.3%
关键教训:类别设计至关重要!
实验3:国会议员照片
测试性别和职业标签的偏见:
发现:
- 性别识别:100%准确率(高质量图像)
- 职业标签偏见:
- 女性更多:"nanny", "housekeeper"
- 男性更多:"prisoner", "mobster", "executive", "doctor"
- 外观描述偏见:
- 女性:头发颜色、外貌("blonde", "brown hair")
- 男性(低阈值时):服装("suit", "tie", "necktie")
7.2 监控应用
CCTV性能测试
CLIP在监控场景的能力:
- 粗粒度分类(识别停车场/校园):91.8%准确率
- 添加"close"干扰选项后:51.1%准确率 ✗
- 细粒度检测(人/小物体):接近随机 ✗
零样本名人识别
在CelebA数据集上:
- 100类:59.2% Top-1准确率
- 1000类:43.3% Top-1准确率
- 2000类:42.2% Top-1准确率
警示:
- 虽然不如专业商业系统
- 但完全零样本就能达到这个性能
- 随着模型改进,隐私风险会增加
7.3 缓解策略建议
论文提出的建议:
- 透明度:公开模型能力和局限
- 红队测试:主动寻找偏见和有害用例
- 类别设计指南:提供最佳实践
- 使用限制:明确不适合的应用场景
- 持续监测:部署后跟踪实际影响
八、技术细节与最佳实践
8.1 训练配置
超参数:
batch_size = 32768 # 巨大批量!
epochs = 32
learning_rate = 5e-4 (ResNet) / 4e-4 (ViT)
optimizer = Adam (β1=0.9, β2=0.999)
weight_decay = 0.2
warmup = 2000 iterations
temperature_init = 0.07 # 可学习,限制在[0, 100]
训练技巧:
- 混合精度训练:加速 + 省内存
- 梯度检查点:大模型必备
- 半精度Adam状态:进一步省内存
- 嵌入相似度分片计算:GPU间分布式
- 数据增强:仅随机裁剪(简单有效)
训练时间:
- RN50x64:592 V100 × 18天
- ViT-L/14:256 V100 × 12天
- ViT-L/14@336:额外1 epoch微调
8.2 Prompt工程最佳实践
原则1:提供上下文
# ❌ 差
"boxer"
# ✓ 好
"a photo of a boxer, a type of pet."
原因:消除歧义(拳击手 vs 狗品种)
原则2:任务特定优化
# 细粒度分类
"a photo of a {label}, a type of {category}."
# OCR
'a photo of the number: "{number}".'
# 卫星图像
"a satellite photo of a {label}."
# 低分辨率
"a zoomed in photo of a {label}."
原则3:集成多个prompt
prompts = [
"a photo of a {label}.",
"a photo of a big {label}.",
"a photo of a small {label}.",
"a {label} in a video game.",
"art of a {label}.",
"a rendering of a {label}.",
# ... 80个变体
]
# 在嵌入空间平均(而非概率空间)
text_features = [text_encoder(prompt) for prompt in prompts]
text_features = mean(text_features, axis=0)
text_features = normalize(text_features)
ImageNet提升:+3.5%
九、与其他工作的对比
9.1 NLP预训练 (GPT/BERT)
相似之处:
- 大规模无监督/自监督预训练
- 零样本/few-shot能力
- 任务无关架构
CLIP的独特性:
- 连接视觉和语言
- 不需要fine-tuning就能迁移
9.2 视觉自监督学习 (SimCLR/MoCo/BYOL)
对比:
| 方法 | 监督信号 | 零样本能力 | 语义对齐 |
|---|---|---|---|
| SimCLR | 图像增强 | ✗ | ✗ |
| MoCo | 图像增强 | ✗ | ✗ |
| BYOL | 图像增强 | ✗ | ✗ |
| CLIP | 自然语言 | ✓ | ✓ |
关键区别:
- 自监督学习只学表示,不学任务
- CLIP直接连接到语言,实现零样本
9.3 视觉-语言预训练 (UNITER/VILLA)
对比:
| 方法 | 架构 | 预训练数据 | 零样本 | 灵活性 |
|---|---|---|---|---|
| UNITER | 单流Transformer | MS-COCO (100K) | 弱 | 低 |
| VILLA | 单流Transformer | MS-COCO (100K) | 弱 | 低 |
| CLIP | 双编码器 | WIT (400M) | 强 | 高 |
CLIP优势:
- 规模大两个数量级
- 双编码器效率高
- 真正的零样本能力
9.4 弱监督学习 (Instagram预训练)
Instagram hashtag预训练:
- 使用35亿Instagram图像
- 预测与ImageNet相关的hashtags
- 需要fine-tuning
CLIP vs Instagram:
任务 | Instagram | CLIP (zero-shot) | CLIP (linear)
-----------------|-----------|-----------------|-------------
ImageNet | 85.2% | 76.2% | 85.4%
迁移学习平均 | 79.1% | - | 81.8%
十、未来方向与启示
10.1 CLIP的局限与改进方向
方向1:提升数据效率
当前问题:需要4亿数据 可能方案:
- 结合自监督学习(SimCLR等)
- 自训练(pseudo-labeling)
- 主动学习
方向2:改进few-shot学习
当前问题:few-shot性能不如人类 可能方案:
- 将零样本分类器作为先验
- 元学习算法
- Prompt tuning
方向3:生成能力
当前问题:只能从固定类别选择 可能方案:
- 结合image captioning
- 联合训练对比 + 生成目标
方向4:3D理解
当前问题:缺乏深度/空间推理 可能方案:
- 多视角对比学习
- 3D-aware架构
10.2 对领域的深远影响
影响1:零样本范式成为主流
CLIP之前:
任务A → 收集数据 → 训练模型A
任务B → 收集数据 → 训练模型B
CLIP之后:
预训练一次 → 零样本完成任务A、B、C...
影响2:Prompt工程的兴起
类似NLP的prompt engineering:
- 不改变模型,只改变输入
- 巨大的设计空间
- 新的研究方向
影响3:多模态基础模型
CLIP启发了一系列后续工作:
- DALL-E:文本生成图像
- Flamingo:视觉问答
- BLIP:统一视觉-语言理解
- GPT-4V:多模态大语言模型
影响4:重新思考评估
CLIP的鲁棒性发现促使领域反思:
- ImageNet准确率不等于真实性能
- 需要更多样的评估基准
- 分布偏移测试应该标准化
十一、论文的历史地位
11.1 学术影响
引用数(截至2025年):
- 超过10,000次引用
- 计算机视觉领域最有影响力的论文之一
开创性贡献:
- 首次展示大规模视觉-语言预训练的潜力
- 证明零样本迁移在CV领域的可行性
- 建立了新的评估范式(30+数据集)
11.2 工业应用
OpenAI产品:
- DALL-E 2/3:基于CLIP的图像生成
- ChatGPT Vision:多模态对话
- GPT-4V:视觉理解集成
开源生态:
- OpenCLIP:社区复现
- Chinese-CLIP:多语言扩展
- CLIP-as-Service:部署工具
商业应用:
- 图像搜索引擎
- 内容审核
- 电商推荐
- 创意工具
11.3 对AGI的启示
CLIP体现了通向AGI的重要原则:
-
规模定律:
- 更多数据 + 更大模型 = 更强能力
- 平滑可预测的缩放规律
-
任务无关学习:
- 不为特定任务设计
- 预训练阶段学习多样任务
-
语言作为接口:
- 自然语言是最灵活的接口
- 实现人机交互的自然方式
-
零样本泛化:
- 真正的智能应该能举一反三
- 不需要每个任务都从头学习
十二、总结
核心贡献概括
- 方法创新:提出通过自然语言监督学习视觉表示的新范式
- 规模创新:构建4亿图文对数据集,证明大规模的重要性
- 性能创新:首次在CV领域展示强大的零样本迁移能力
- 鲁棒性创新:显著提升模型对分布偏移的鲁棒性
- 评估创新:建立全面的多任务评估框架
关键数字回顾
数据规模: 4亿图文对
模型规模: 最大6.3亿参数
训练规模: 32 epochs on 592 V100s
零样本: 76.2% on ImageNet
鲁棒性: 缩小75%的鲁棒性差距
评估: 30+数据集,涵盖多种任务
深刻洞察
洞察1:语言是强大的监督信号
- 比固定类别更表达
- 比监督标签更丰富
- 实现零样本的关键
洞察2:对比学习高效可扩展
- 比生成式目标快4倍
- 可以利用海量互联网数据
- 批量越大效果越好
洞察3:零样本模型更鲁棒
- 不能利用训练集特定的捷径
- 被迫学习更通用的表示
- 更好地泛化到新分布
洞察4:规模仍然重要
- 4亿数据带来质变
- 模型越大效果越好
- 计算效率需要持续优化
未解决的问题
- 如何进一步提升数据效率?
- 如何改进few-shot学习能力?
- 如何减少偏见和公平性问题?
- 如何扩展到视频、3D等更复杂模态?
- 如何实现真正的开放世界识别?
参考资源
论文:
- 原文:https://arxiv.org/abs/2103.00020
- GitHub:https://github.com/OpenAI/CLIP
后续工作:
- DALL-E 2 (2022)
- Flamingo (2022)
- BLIP (2022)
- OpenCLIP (社区复现)
相关资源:
- CLIP Playground:https://clip-playground.com/
- CLIP Retrieval:https://github.com/rom1504/clip-retrieval
- OpenAI Blog:https://openai.com/blog/clip/
这篇论文标志着计算机视觉领域的重要转折点,从封闭式的分类任务走向开放式的视觉理解。CLIP的成功证明,大规模、多样化的自然语言监督是构建通用视觉系统的可行路径。虽然仍有许多挑战待解决,但CLIP为未来的多模态AI研究指明了方向。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 15
15 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)