LoRA技术原理详解:大模型高效微调的“低秩”智慧
LoRA的成功,本质上是对“大模型微调”的降维思考:既然我们只需要模型适配特定任务,就不必更新所有参数——那些与任务无关的权重更新,完全可以被“低秩矩阵”过滤掉。这种“抓核心、弃冗余”的思路,不仅解决了大模型微调的成本问题,更启发了后续一系列高效微调技术(如LoHa、LoKr等)。未来,随着模型参数量持续增长,LoRA这类“轻量化适配”技术,将成为大模型落地的关键基础设施。如果你正在做大模型微调,
在大模型时代,一个核心矛盾始终存在:预训练模型的参数量动辄数十亿甚至千亿,全量微调不仅需要海量计算资源,还可能导致“灾难性遗忘”(原模型能力退化)。为解决这一问题,高效微调技术应运而生,其中LoRA(Low-Rank Adaptation,低秩适应)凭借“低成本、高性能、易部署”的特性,成为近年来最受关注的方案之一。
本文将从技术本质、实现细节、优势对比等维度,全面解析LoRA的工作原理,帮你理解它为何能让大模型“轻装上阵”完成微调。
一、为什么需要LoRA?—— 大模型微调的痛点
在LoRA出现前,大模型微调主要有两种思路:
-
全量微调:更新模型所有参数。优点是适配效果好,缺点是参数量爆炸(比如100亿参数模型,微调一次需存储100亿新参数)、训练成本极高(需千卡GPU集群),且容易破坏原模型的通用能力。
-
冻结微调:仅更新模型顶层少量参数(如分类头)。优点是成本低,缺点是适配能力弱——对于复杂任务(如生成特定风格的图像、理解专业领域知识),仅调顶层参数难以让模型“学会新技能”。
有没有一种方法,既能像全量微调一样精准适配任务,又能像冻结微调一样低成本?LoRA给出了答案:通过“低秩分解”捕捉任务相关的权重更新,用极少参数实现高效微调。
二、LoRA的核心原理:用“低秩矩阵”替代“全秩更新”
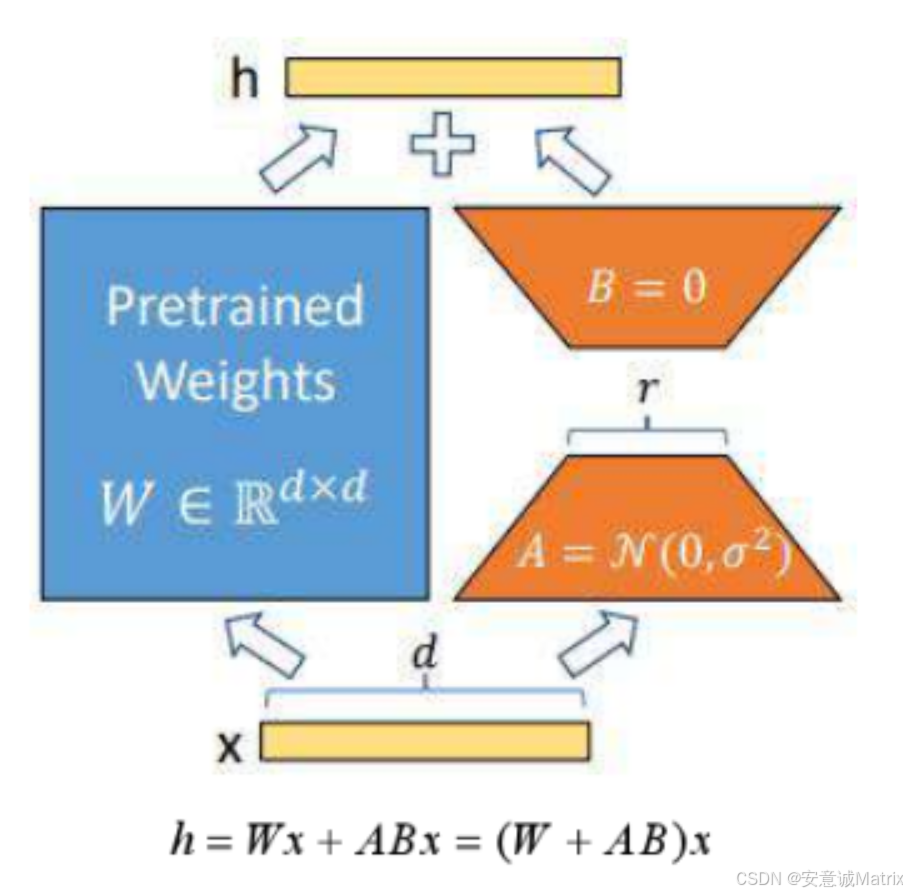
LoRA的核心思想基于一个关键观察:在微调大模型时,模型权重的更新量(ΔW)往往具有“低秩特性”。
什么是“低秩特性”?简单说,一个高维矩阵(如d×d)的更新,其实可以用两个低维矩阵(d×r和r×d,r<<d)的乘积来近似,其中r称为“秩”(rank)。这就像用一张模糊的低分辨率图片(低秩),就能大致还原高清图(全秩)的核心信息——对于微调任务,我们只需要捕捉权重更新的“核心信息”,无需保留完整的高维细节。
2.1 具体实现:给模型加一条“低秩旁路”
LoRA的实现逻辑非常直观,可概括为“冻结原模型+新增低秩分支”:
-
冻结预训练模型权重
设预训练模型的某层权重为W(维度d×d),微调时保持W不变。这样既避免了大量参数更新,又保留了原模型的通用能力。 -
新增低秩旁路分支
构建两个低秩矩阵:- 降维矩阵A(维度d×r):将输入特征从d维映射到r维(r远小于d,通常取8-64)。
- 升维矩阵B(维度r×d):将r维特征映射回d维,与原模型输出维度保持一致。
这两个矩阵的乘积AB(维度d×d)就构成了“低秩更新矩阵”,用于捕捉任务相关的权重变化。
-
前向传播:原模型+旁路分支的融合
对于输入x(维度1×d),模型的输出由两部分叠加而成:- 原模型输出:Wx(维度1×d)
- 旁路分支输出:ABx(维度1×d)
最终输出为:
h = Wx + ABx = (W + AB)x。从公式看,LoRA相当于在原权重W的基础上,叠加了一个低秩更新AB,既保证了输出维度不变,又实现了对任务的适配。
2.2 关键设计:为什么这样的结构能work?
LoRA的效果并非偶然,其细节设计暗藏巧思:
-
初始化策略:A采用随机高斯分布初始化(N(0, 0.01)),B采用零初始化(B=0)。这样训练初期,AB≈0,旁路分支对输出几乎无影响,模型性能完全依赖原预训练权重W,避免了初始化对模型的干扰。
-
秩r的选择:r是控制LoRA能力的核心超参数。r越小,参数量越少(参数量为r×(d + d) = 2rd,远小于全量微调的d²),但表达能力有限;r越大,表达能力越强,但成本上升。实际应用中,根据任务复杂度选择r=8-64即可覆盖大部分场景(例如Stable Diffusion的LoRA微调常用r=32)。
-
训练与推理的分离优化:训练时,仅更新A和B的参数(冻结W),大幅降低计算量;推理时,可以将AB与W合并为新权重W’=W+AB,此时模型结构与原模型完全一致,不增加任何推理延迟(这是LoRA相比Adapter等方法的核心优势)。
三、LoRA为何高效?—— 与其他微调方法的对比
为了更直观理解LoRA的优势,我们将其与主流微调方法对比:
| 微调方法 | 可训练参数 | 训练成本 | 推理延迟 | 适配效果 |
|---|---|---|---|---|
| 全量微调 | 全部参数(d²) | 极高 | 无 | 好 |
| 冻结微调(仅头) | 少量参数(如d×k) | 低 | 无 | 差 |
| Adapter | 新增模块(≈rd) | 中 | 增加 | 中 |
| LoRA | 2rd(r<<d) | 低 | 无 | 接近全量 |
可见,LoRA在“参数量”“训练成本”“推理延迟”“适配效果”四个维度实现了最优平衡:
- 参数量仅为全量微调的1/r(r=32时,仅3%);
- 训练时无需更新原模型权重,GPU内存占用降低50%以上;
- 推理时可合并权重,与原模型速度一致;
- 由于捕捉了权重更新的低秩核心,适配效果接近全量微调。
四、LoRA的适用场景
LoRA的特性使其在多领域大放异彩:
-
大语言模型(LLM)微调:如对GPT、LLaMA等模型微调,适配特定领域(医疗、法律)或任务(摘要、翻译),用单卡即可完成原本需要千卡集群的工作。
-
图像生成模型微调:如Stable Diffusion的LoRA微调,仅需30-50张样本,就能让模型学会生成特定人物、风格或物体(如“汉服”“特定明星”),且训练时间从几天缩短到几小时。
-
多任务场景:为不同任务训练不同的A/B矩阵,推理时按需加载,无需为每个任务存储完整模型,大幅降低存储成本(例如10个任务,仅需存储1个原模型+10组A/B矩阵)。
五、总结:LoRA的“低秩”哲学
LoRA的成功,本质上是对“大模型微调”的降维思考:既然我们只需要模型适配特定任务,就不必更新所有参数——那些与任务无关的权重更新,完全可以被“低秩矩阵”过滤掉。
这种“抓核心、弃冗余”的思路,不仅解决了大模型微调的成本问题,更启发了后续一系列高效微调技术(如LoHa、LoKr等)。未来,随着模型参数量持续增长,LoRA这类“轻量化适配”技术,将成为大模型落地的关键基础设施。
如果你正在做大模型微调,不妨试试LoRA——它可能会让你用10%的成本,达到90%的效果。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 17
17 0
0- 0



 已为社区贡献27条内容
已为社区贡献27条内容

所有评论(0)