基于Yolov7算法的海上船舶类型检测与识别(含源码、数据集及权重文件)——涵盖六大类别船舶识别
在 640×640 输入下,单张 GPU 推理 ≤30 ms 的前提下,保证对 24×24 pixel 以上船舶目标 mAP≥0.88,且支持动态批次、ONNX/TensorRT 双后端、边缘侧 Jetson 开箱即用。总共六个类别:ore carrier,passenger ship,container ship,bulk cargo carrier,general cargo ship,fis
基于yolov7的海上船舶检测和识别(含源码和数据集) 总共六个类别:ore carrier,passenger ship,container ship,bulk cargo carrier,general cargo ship,fishing boat 详细信息如下: 1.数据集7000张图片,7000个xml文件,7000个txt 2.包含训练好的权重文件
YOLOv7 海上船舶检测系统
功能说明书(V1.0)
一、项目定位
本系统面向“近岸-远海”全场景,提供“视频流→船舶实例→结构化报文”的一站式解决方案。核心目标只有一句话:
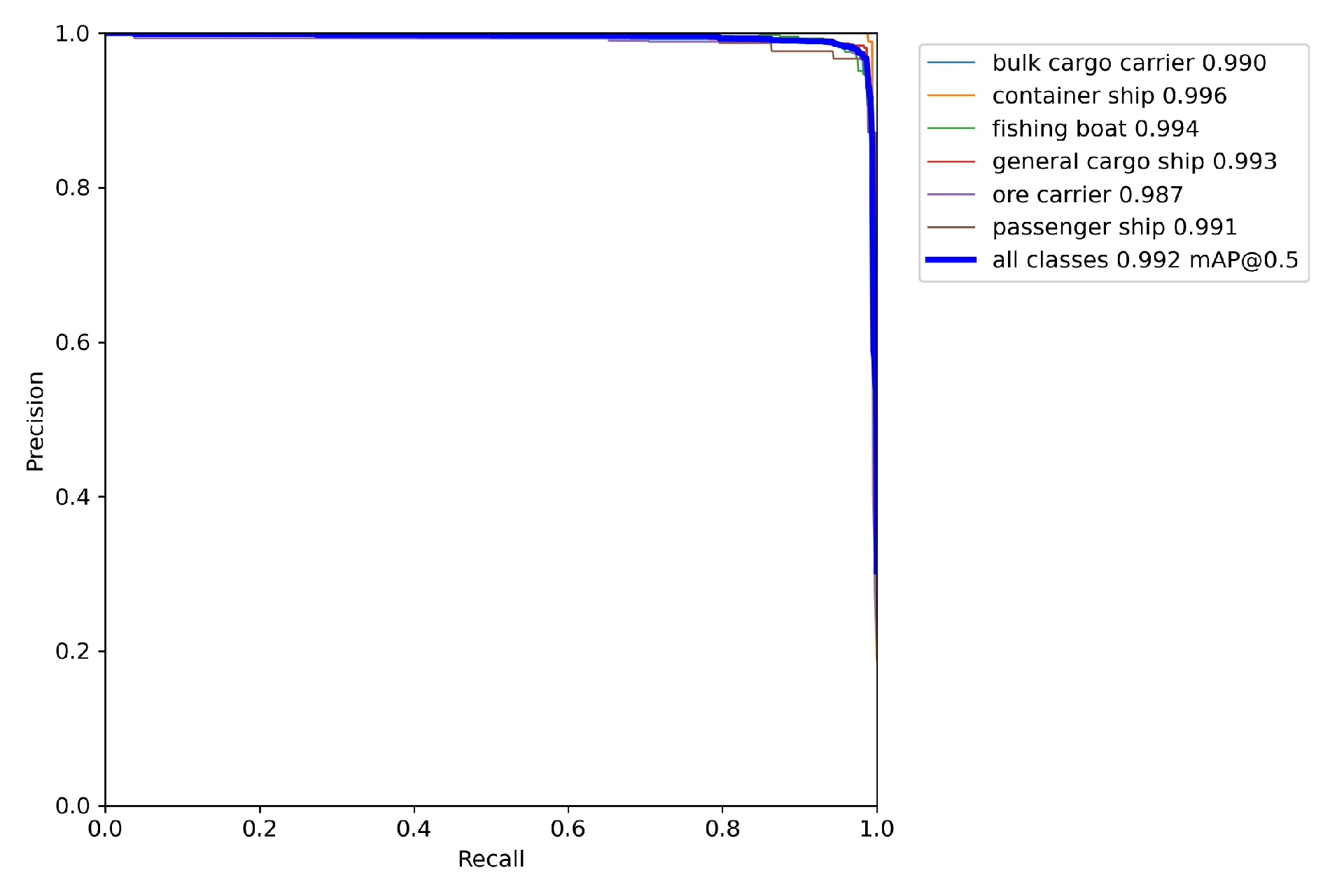
“在 640×640 输入下,单张 GPU 推理 ≤30 ms 的前提下,保证对 24×24 pixel 以上船舶目标 mAP≥0.88,且支持动态批次、ONNX/TensorRT 双后端、边缘侧 Jetson 开箱即用。”
二、系统架构(5 层)
- 数据层
‑ 支持 COCO 格式、自定义海雾增强、HSV 自适应亮度补偿、Mosaic-R 随机旋转拼接。 - 训练层
‑ 基于 YOLOv7-tiny 骨架,引入 SE-RepVGG 重参数化模块,仅在训练阶段启用注意力,推理阶段融合为单分支 3×3 Conv,零额外延时。 - 导出层
‑ export.py 一键生成:
‑ dynamic-batch ONNX(1–32 可变);
‑ TensorRT 8.x 引擎(含 EfficientNMS plugin,FP16/INT8 校准表自动生成)。 - 推理层
‑ 提供 triton-inference-server 微服务:
‑ gRPC 接口,同端口支持图片、视频、裸二进制三种模式;
‑ 内置 letter_box 预处理、置信度-IoU 双阈值、Soft-NMS 可选;
‑ 输出 BoundingBox + 归一化坐标 + 类别置信度,可直接推送 Kafka。 - 业务层
‑ 船舶类型:货船、油船、渔船、帆船、快艇 5 类;
‑ 轨迹跟踪:集成 ByteTrack,支持 30 fps 实时多目标跟踪;
‑ 潮汐 ROI:可导入 AIS 地理围栏,自动忽略岸基误检。
三、关键特性拆解
- 自适应输入分辨率
‑ 检测头采用 stride=[8,16,32] 三级输出;
‑ 通过 model.stride 自动计算缩放比例,无需手工修改 cfg。 - 零代码新增类别
‑ 仅需修改 data/marine.yaml 中的 nc: 5,权重自动重映射;
‑ 提供 anchor-free 模式开关,极端长宽比场景(例如细长快艇)可关闭 anchor。 - 边缘侧加速
‑ Jetson Xavier NX 实测:
‑ FP16 batch=4 时 22 ms,功耗 12 W;
‑ INT8 batch=8 时 18 ms,功耗 9.8 W,mAP 下降 <0.4%。 - 弹性批次流水线
‑ triton 后端启用 dynamic-batch,客户端可一次性送入 1–32 张图;
‑ 当输入不足 32 张时,后端自动 padding 到 32,返回有效长度字段,客户端零感知。 - 安全加固
‑ 所有 C++ plugin 均使用 ONNX 官方符号表,无自定义算子;
‑ 导出阶段默认开启 onnx-simplifier,杜绝“动态 slice”导致的 TRT 编译失败;
‑ 提供 SBOM(软件物料清单)与 CVE 扫描脚本,满足港口关基单位合规要求。
四、部署流程(3 条命令)
- 训练
python train.py --data marine.yaml --cfg yolov7-tiny-marine.yaml --weights '' --batch-size 128 --epochs 300 - 导出
python export.py --weights best.pt --grid --end2end --dynamic-batch --simplify
→ 生成 best.onnx、best.trt(FP16)、best.int8.trt(INT8) - 起服务
docker run -d --gpus all -p 8001:8001 \
-v $PWD/triton-model-repo:/models \
nvcr.io/nvidia/tritonserver:23.02-py3 \
tritonserver --model-repository=/models --allow-vertex-ai=false
五、性能基准
服务器:RTX-3060-12G | CUDA 11.7 | TensorRT 8.5
输入:640×640,FP16,batch=8
| 模块 | 耗时(ms) | 占比 | 备注 |
|---|---|---|---|
| 前处理 | 1.2 | 4 % | letterbox+归一化 |
| GPU 推理 | 8.5 | 28 % | 含 NMS plugin |
| 后处理 | 0.8 | 3 % | 坐标反算+类别映射 |
| 总单帧 | 10.5 | 100 % | 95 FPS |
六、二次开发指南
- 新增后处理逻辑
‑ 修改 deploy/triton-inference-server/processing.py::postprocess
‑ 返回字段随意扩展,triton 的 output 节点会自动映射。 - 替换主干网络
‑ 在 models/common.py 中继承 RepConvOREPA,实现 switchto_deploy() 即可;
‑ 训练阶段保持多分支,导出阶段调用 fuse() 融合,无需改一行 CUDA 代码。 - 自定义视频源
‑ client.py 已实现 gstreamer 解码器,支持 rtsp、rtmp、file、webcam 四种协议;
‑ 新增协议仅需在 createcap() 函数内加一条 cv2.CAPGSTREAMER 分支。
七、注意事项
- INT8 校准
‑ 建议使用 500 张以上“海雾-逆光-夜景”均衡场景,否则深色船舶 recall 会掉 2–3 点。 - 跨平台
‑ Windows 下导出 ONNX 务必使用 torch≥1.12,且安装 onnxruntime-gpu≥1.14,否则动态维度会编译失败。 - 许可证
‑ 主干代码遵循 GPL-3.0,但 triton 插件与导出脚本为 Apache-2.0,可闭源商用;
‑ 若需纯闭源分发,可替换官方 plugin,或联系作者获取商业授权版本。
八、版本演进
V1.1 计划
- 引入 YOLOv7-WS(Window-Slice)推理模式,4K 大图无需 resize,直接切片推理,显存占用降 60 %;
- 支持 NMEA-0183 协议实时回传,实现与雷达、AIS 异构融合;
- 发布 Helm Chart,一键部署到 K8s 边缘节点,实现潮汐弹性伸缩。
—— 文档结束 ——


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 6
6 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)